【Random Forest】林轩田机器学习技法
总体来说,林对于random forest的讲解主要是算法概况上的;某种程度上说,更注重insights。
林分别列举了Bagging和Decision Tree的各自特点:

Random Forest就是这二者的结合体。

1)便于并行化
2)保留了C&RT的优势
3)通过bagging的方法削弱了fully-grown tree的缺点
这里提到一个insights:如果各个分类器的diversity越大,aggregation之后的效果可能就越好。
因此,Random Forest不仅样本是boostrapping的,而且对于features的处理上也采用了类似的方式。

采用random subspace的好处就是:特征维度降低了,运算效率提高了。
更进一步,RF的作者又提出了一种延伸的思路:

任何一个low-dimension的feature空间都可以看成是由投影矩阵P对原来feature的变换,或者可以说对原features做了线性组合(combination)
一种特例就是:如果投影过后没有任何变化时,这个P就是natural basis。
RF的作者为了引入更多的randomness,建议在做每一次b(x)的时候,都考虑用投影矩阵来对features做变换。这样就真的是randomness everywhere了。
接下来,林介绍了如何针对RF的特点做模型Validation的问题。
首先,林给出了,在RF的每棵树的boostrapping的过程中,没有被用到(out-of-bag)的样本的比例大概是多少。

假设每棵树都boostrappingN次,那么还是会有1/3的样本是没有被这棵树抽中的。
对于每棵树来说,这些没有被boostrapping过程抽中的样本就叫Out-Of-Bag。
利用这种规律,RF模型的validation方式就有些飘逸了。

1)一种直观的验证思路是,用每棵树的OOB数据来验证gt;然并卵,RF模型并不看重每棵树的分类效果
2)第二种思路就来了,有点儿绕,但是也说得清(可以类比validation by one的验证方法)。
比如(x1,y1)这个数据,对于g2,g3是out of bag的,那么对于(x1,y1)这个样本的error,就可以用G(g2,g3)的average来验证。(如果只有(x1,y1)这一个点来验证,那就是validation by one的方法了)。
对于(x1,y1)~...(xN,yN)大部分都可以找到,以这些样本为OOG的G(gi...),分别求这些validation的值,再取一个平均就OK了。
第二种验证思路:
a. 既保证了测试的数据绝对没有在训练时被偷窥
b. 保证了不是验证单棵子树gt,而是着眼于G(gi...)的表现

这种validation的方式在实际中非常好用,不用re-training,省时省力。
接下来进入了feature selection的议题。
这个议题其实也比较自然,既然Random Forest每一步都需要randomness选特征,自然就要问:哪些特征更important?
首先回顾了线性模型:

线性模型学习过程的结果W,本身就是对变量重要性的度量:|wi|越大(不论正负)都对结果影响比较大,因此也更重要。

还有一种统计学方法,就是用permutation test的思路来做。
比如N个样本,每个样本d维度特征,要想衡量其中第i维特征的重要性,可以把这N个样本的第i维特征都洗牌打乱。再评价洗牌前和洗牌后的模型performance。
但是这样就有一个问题,必须不断地洗牌、训练,过程很繁琐。
于是RF的作者想到一种有些偷懒的trick,如下:

训练的时候,不玩儿permutation了;改在validation的时候玩儿permutation了:即把OOB测试样本的xn,i打乱洗牌,再进行评估验证。
这个trcik也算上是一个非常pratical的想法吧,学习了。
最后,林列举了几个RF模型在实际中的例子:
1)对于简单的数据集,RF模型倾向于得到平滑,置信区间大的分类器
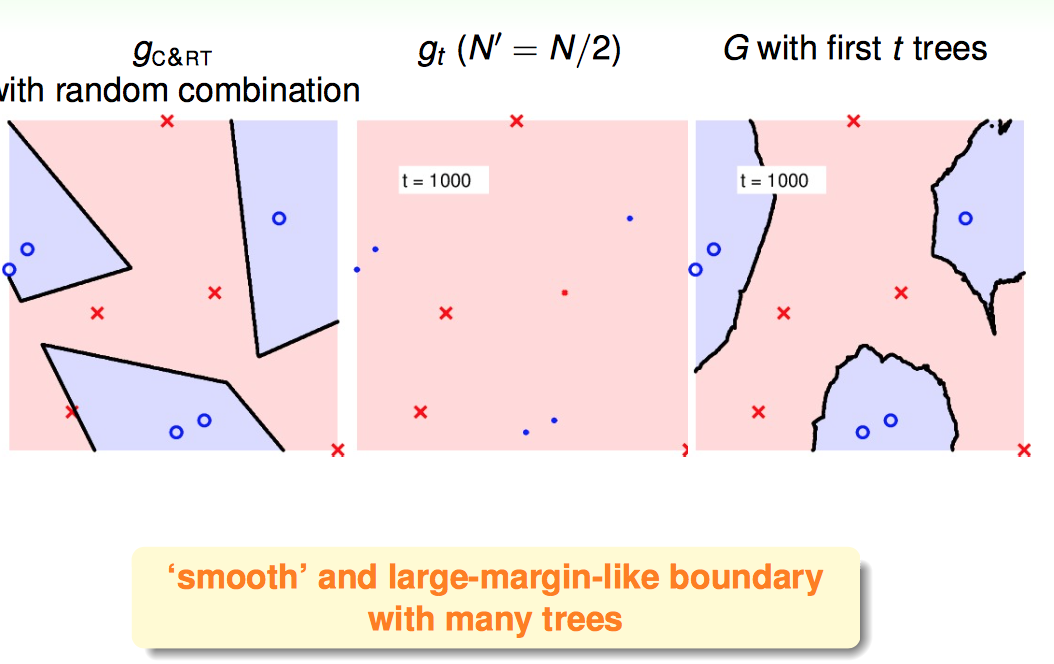
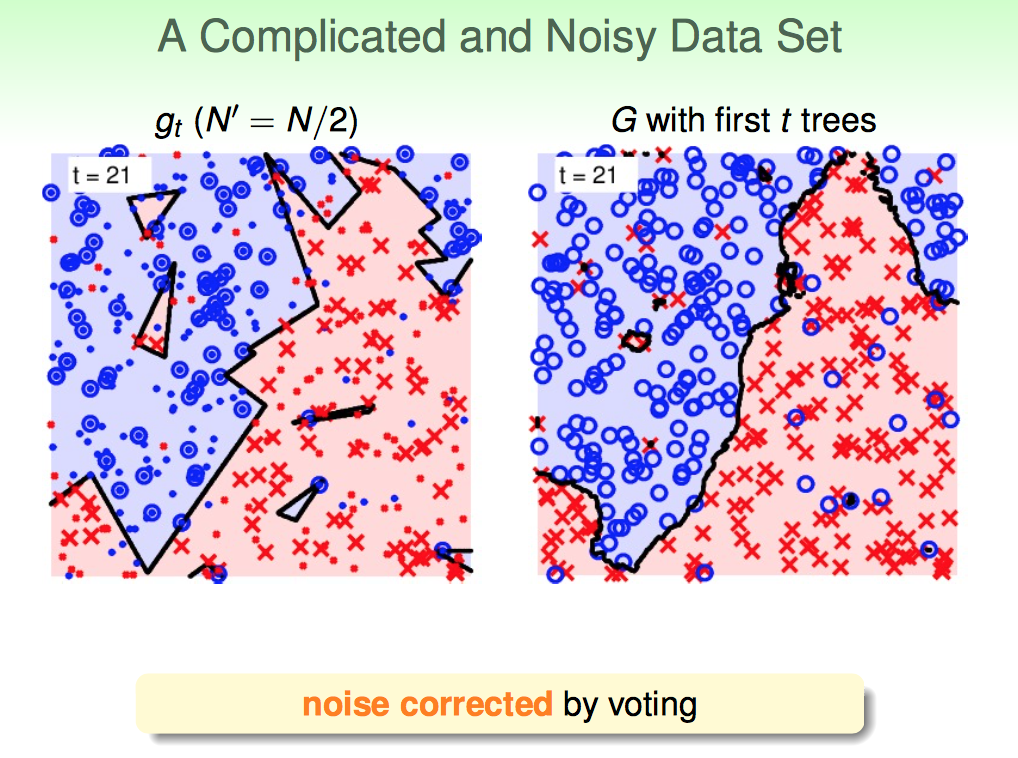
2)对于复杂有噪声的数据(决策树表现不好的),RF模型的降噪性很好
3)森林里选多少棵树比较好?

总之是树越多越好,但是由于是随机森林的,random seed也很重要(这个就要看缘分了)。
【Random Forest】林轩田机器学习技法的更多相关文章
- 【Matrix Factorization】林轩田机器学习技法
在NNet这个系列中讲了Matrix Factorization感觉上怪怪的,但是听完第一小节课程就明白了. 林首先介绍了机器学习里面比较困难的一种问题:categorical features 这种 ...
- 【Deep Learning】林轩田机器学习技法
这节课的题目是Deep learning,个人以为说的跟Deep learning比较浅,跟autoencoder和PCA这块内容比较紧密. 林介绍了deep learning近年来受到了很大的关注: ...
- 【Adaptive Boosting】林轩田机器学习技法
首先用一个形象的例子来说明AdaBoost的过程: 1. 每次产生一个弱的分类器,把本轮错的样本增加权重丢入下一轮 2. 下一轮对上一轮分错的样本再加重学习,获得另一个弱分类器 经过T轮之后,学得了T ...
- 【Radial Basis Function Network】林轩田机器学习技法
这节课主要讲述了RBF这类的神经网络+Kmeans聚类算法,以及二者的结合使用. 首先回归的了Gaussian SVM这个模型: 其中的Gaussian kernel又叫做Radial Basis F ...
- 【Neural Network】林轩田机器学习技法
首先从单层神经网络开始介绍 最简单的单层神经网络可以看成是多个Perception的线性组合,这种简单的组合可以达到一些复杂的boundary. 比如,最简单的逻辑运算AND OR NOT都可以由多 ...
- 【Decision Tree】林轩田机器学习技法
首先沿着上节课的AdaBoost-Stump的思路,介绍了Decision Tree的路数: AdaBoost和Decision Tree都是对弱分类器的组合: 1)AdaBoost是分类的时候,让所 ...
- 【Linear Support Vector Machine】林轩田机器学习技法
首先从介绍了Large_margin Separating Hyperplane的概念. (在linear separable的前提下)找到largest-margin的分界面,即最胖的那条分界线.下 ...
- 【Support Vector Regression】林轩田机器学习技法
上节课讲了Kernel的技巧如何应用到Logistic Regression中.核心是L2 regularized的error形式的linear model是可以应用Kernel技巧的. 这一节,继续 ...
- 【Dual Support Vector Machine】林轩田机器学习技法
这节课内容介绍了SVM的核心. 首先,既然SVM都可以转化为二次规划问题了,为啥还有有Dual啥的呢?原因如下: 如果x进行non-linear transform后,二次规划算法需要面对的是d`+1 ...
随机推荐
- 检测浏览器中是否有Flash插件
由于IE和非IE浏览器检测方式不同,所以代码如下 function hasPlugin(name){ debugger; name = name.toLowerCase(); for(var i=0; ...
- IOS GCD(线程的 串行、并发 基本使用)
什么是GCD 全称是Grand Central Dispatch,可译为“牛逼的中枢调度器” 纯C语言,提供了非常多强大的函数 GCD的优势 GCD是苹果公司为多核的并行运算提出的解决方案 GCD会自 ...
- robotframework实战二---Jenkins连用
1.下载插件robot Jenkins环境搭建就不用说了,网上有很多帖子,你在使用时,你需要做以下几步 因为目前我已经安装了 2.新建项目 因为有重名的项目,所以会提示以下内容 你需要配置的内容就两处 ...
- WKWebView 屏蔽长按手势 - iOS
研究半天还跟正常套路不一样,WKWebView 需要将 JS 注入进去,套路啊 ... 查半天资料,为了后者们开发可以提高效率,特此分享一下,不到的地方多多包涵哈. 废话不多说,直接上 code,将如 ...
- PNChart,简洁高效有动画效果的iOS图表库
导入 pod导入相对简单,要手动导入这个库,先下载下来(https://github.com/kevinzhow/PNChart),解压后把PNChart文件夹拖入工程中 运行发现#import&qu ...
- 洛谷P1762 偶数(找规律)
题目描述 给定一个正整数n,请输出杨辉三角形前n行的偶数个数对1000003取模后的结果. 输入输出格式 输入格式: 一个数 输出格式: 结果 输入输出样例 输入样例#1: 复制 6 输出样例#1: ...
- hibernate系列之四
数据库中表之间的关系: 一对一.一对多.多对多 一对多的建表原则:在多的一方创建外键指向一的一方的主键: 多对多的建表原则:创建一个中间表,中间表中至少有两个字段作为外键分别指向多对多双方的主键: 一 ...
- mysql基础 日期类型
- sql常用函数instr()和substr()
Decode decode(条件,值1,翻译值1,值2,翻译值2,...,缺省值) 该函数与程序中的 If...else if...else 意义一样 NVL 格式:NVL( string1, rep ...
- HTML+CSS : H5+CSS3
HTML5语义化标签: header nav(导航) article section(章节) aside(侧边栏) footer------------------------------------ ...