spark与hive的集成
一:介绍
1.在spark编译时支持hive

2.默认的db
当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库。

二:具体集成
1.将hive的配合文件hive-site.xml添加到spark应用的classpath中(相当于拷贝)

2.第二步集成
根据hive的配置参数hive.metastore.uris的情况,采用不同的集成方式
分别为(区别):
-1. hive.metastore.uris没有给定配置值,为空(默认情况)
SparkSQL通过hive配置的javax.jdo.option.XXX相关配置值直接连接metastore数据库直接获取hive表元数据
--1.1 需要将连接数据库的驱动添加到Spark应用的classpath中
-2. hive.metastore.uris给定了具体的参数值
SparkSQL通过连接hive提供的metastore服务来获取hive表的元数据
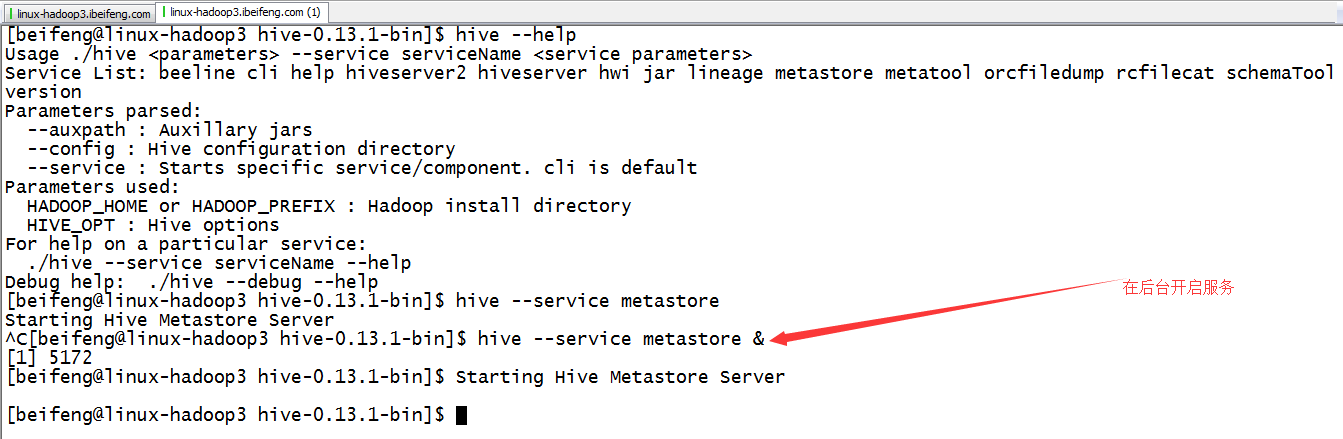
--2.1 直接启动hive的metastore服务即可完成SparkSQL和Hive的集成
$ hive --service metastore &
3.使用hive-site.xml配置的方式

4.启动hive service metastore服务
三:测试
1.spark-sql
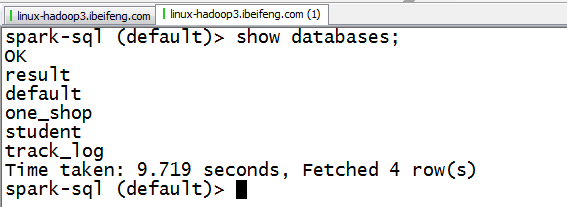
2.使用
四:特殊点(其他在hive中可以使用的sql,在spark-sql中都可以使用)
1.cache

五:使用spark-shell
1.启动
2.使用
六:补充说明:Spark应用程序第三方jar文件依赖解决方案
1. 将第三方jar文件打包到最终形成的spark应用程序jar文件中
这种使用的场景是,第三方的jar包不是很大的情况。
2. 使用spark-submit提交命令的参数: --jars
这个使用的场景:使用spark-submit命令的机器上存在对应的jar文件
至于集群中其他机器上的服务需要该jar文件的时候,通过driver提供的一个http接口来获取该jar文件的(http://192.168.187.146:50206/jars/mysql-connector-java-5.1.27-bin.jar Added By User)
$ bin/spark-shell --jars /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar
3. 使用spark-submit提交命令的参数: --packages
这个场景是:如果找不到jar会自动下载,也可以自己设定源。
--packages Comma-separated list of maven coordinates of jars to include on the driver and executor classpaths. Will search the local maven repo, then maven central and any additional remote repositories given by --repositories.
The format for the coordinates should be groupId:artifactId:version.
http://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.27
$ bin/spark-shell --packages mysql:mysql-connector-java:5.1.27 --repositories http://maven.aliyun.com/nexus/content/groups/public/
# 默认下载的包位于当前用户根目录下的.ivy/jars文件夹中
4.更改Spark的配置信息:SPARK_CLASSPATH, 将第三方的jar文件添加到SPARK_CLASSPATH环境变量中
使用场景:要求Spark应用运行的所有机器上必须存在被添加的第三方jar文件
做法:
-4.1 创建一个保存第三方jar文件的文件夹:
$ mkdir external_jars
-4.2 修改Spark配置信息
$ vim conf/spark-env.sh
SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/cdh-5.3.6/spark/external_jars/*
-4.3 将依赖的jar文件copy到新建的文件夹中
$ cp /opt/cdh-5.3.6/hive/lib/mysql-connector-java-5.1.27-bin.jar ./external_jars/
-4.4 测试
$ bin/spark-shell
scala> sqlContext.sql("select * from common.emp").show
备注:
如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:将第三方的jar文件copy到${HADOOP_HOME}/share/hadoop/common/lib文件夹中(Hadoop集群中所有机器均要求copy)
备注:如果spark on yarn(cluster),如果应用依赖第三方jar文件,最终解决方案:
spark与hive的集成的更多相关文章
- 035 spark与hive的集成
一:介绍 1.在spark编译时支持hive 2.默认的db 当Spark在编译的时候给定了hive的支持参数,但是没有配置和hive的集成,此时默认使用hive自带的元数据管理:Derby数据库. ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- 使用spark对hive表中的多列数据判重
本文处理的场景如下,hive表中的数据,对其中的多列进行判重deduplicate. 1.先解决依赖,spark相关的所有包,pom.xml spark-hive是我们进行hive表spark处理的关 ...
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 使用spark访问hive错误记录
在spark集群中执行./spark-shell时报以下错误: 18/07/23 10:02:39 WARN DataNucleus.Connection: BoneCP specified but ...
- Spark访问Hive表
知识点1:Spark访问HIVE上面的数据 配置注意点:. 1.拷贝mysql-connector-java-5.1.38-bin.jar等相关的jar包到你${spark_home}/lib中(sp ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Spark SQL -- Hive
使用Saprk SQL 操作Hive的数据 前提准备: 1.启动Hdfs,hive的数据存储在hdfs中; 2.启动hive -service metastore,元数据存储在远端,可以远程访问; 3 ...
随机推荐
- Sentry的安装搭建与使用
业务监控工具 Sentry 的搭建与使用 官方网址 Django Sentry 官网链接 Sentry 简介 Sentry 是一个开源的实时错误报告工具,支持 web 前后端.移动应用以及游戏,支持 ...
- Porita详解----Items
Items(项目) 一个item是指从目标网站上爬取的一条单独的数据.例如从京东网站上爬取的一款小米6手机的信息.大家应该对 item (项目)和 item definition(项目定义)做一个区分 ...
- 我的项目经验总结——CDN镜像:1(初探)
前言 其实,这个标题有些大,作为一个小白,只是在实际工作中经常听闻我司的CDN服务如何如何牛B……而且我司的云服务还拿到了工信部的CDN牌照……那么,作为一个研发仔,怎么能不去了解和熟悉呢?!不过,这 ...
- 很全面的Android面试题
Activity 什么是Activity 四大组件之一,一个和用户交的互界面就是一个activity,是所有 View 的容器 我开发常用的的有FragmentActivitiy,ListActivi ...
- python __name__ 变量的含义
python __name__ 变量的含义 if __name__ == '__main__': tf.app.run() 当python读入程序时,会初始化一些系统变量.如果当前程序是主程序,__n ...
- MySQL在高版本需要指明是否进行SSL连接问题
Java使用mysql-jdbc连接MySQL出现如下警告: Establishing SSL connection without server's identity verification is ...
- 九度OJ 1016 火星A+B AC版
#include <iostream> #include <string.h> #include <sstream> #include <math.h> ...
- 201521123005《java程序设计》第四周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. ·继承(是什么,意义) -父类(被继承的类) -子类(继承父类) -多态(解决重复代码的问题 ...
- 201521123100 《Java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 书面作业 1. 网络基础 1.1 比较ping www.baidu.com与ping cec.jmu ...
- Java程序设计-表达式运算(个人博客)
1.团队课程设计博客链接 洪亚文博客链接:http://www.cnblogs.com/201521123065hyw/ 郑晓丽博客链接:http://www.cnblogs.com/zxl3066/ ...