flying-saucer + iText + Freemarker实现pdf的导出, 支持中文、css以及图片
前言
项目中有个需求,需要将合同内容导出成pdf。上网查阅到了 iText , iText 是一个生成PDF文档的开源Java库,能够动态的从XML或者数据库生成PDF,同时还可以对文档进行加密,权限控制,并且还支持Java/C#等,但是iText本身提供的HTML解析器还是不够强大,许多HTML标签和属性无法识别,更悲催的是简单的CSS它不认识,排版调整样式让人头大。那么有没有什么方式能够支持css呢,又查阅到了 flying-saucer, flying-saucer也是导出PDF的一种解决方案,并且是基于iText的开源API,并且实现了CSS解析器,能够很好的支持CSS2.1,以及少量的CSS。最终解决方案定为: flying-saucer + iText + Freemarker。
具体实现
流程如下
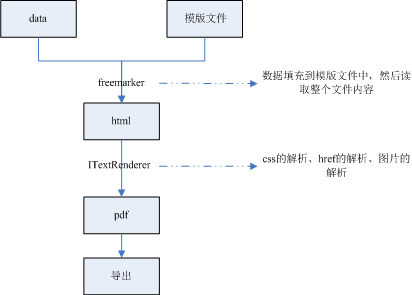 pom.xml
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yzb.lee</groupId>
<artifactId>itextpdf</artifactId>
<packaging>war</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>itextpdf Maven Webapp</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.20</version>
</dependency> <dependency>
<groupId>com.itextpdf.tool</groupId>
<artifactId>xmlworker</artifactId>
<version>5.5.1</version>
</dependency> <!-- 支持中文 -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
<!-- 支持css样式渲染 -->
<dependency>
<groupId>org.xhtmlrenderer</groupId>
<artifactId>flying-saucer-pdf-itext5</artifactId>
<version>9.0.3</version>
</dependency> <!-- https://mvnrepository.com/artifact/org.apache.commons/commons-lang3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.4</version>
</dependency> <dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<finalName>itextpdf</finalName>
</build>
</project>
1、html内容的输出
模版文件fileTemplate.html
<html>
<head>
<title>${title}</title>
<!-- link链接应该写文件服务器地址, 出于演示,这里用的localhost -->
<link type="text/css" rel="stylesheet" href="http://localhost:8080/itextpdf/css/pdf.css" />
<style>
@page {
size: 8.5in 11in;
@
bottom-center
{
content
:
"page "
counter(
page
)
" of "
counter(
pages
);
}
}
</style>
</head>
<body>
<h1>Just a blank page.</h1>
<div style="page-break-before: always;">
<div align="center">
<h1>${title}</h1>
<!-- src链接应该写文件服务器地址, 出于演示,这里用的localhost -->
<img alt="加载中..." src="http://localhost:8080/itextpdf/images/aloner.jpg" />
</div>
<table>
<tr>
<td><b>Name</b></td>
<td><b>Age</b></td>
<td><b>Sex</b></td>
</tr>
<#list userList as user>
<tr>
<td>${user.name}</td>
<td>${user.age}</td>
<td><#if user.sex = 1> male <#else> female </#if></td>
</tr>
</#list>
</table>
</div>
<div>
<a href="https://www.baidu.com/" target="_blank">百度</a>
</div>
</body>
</html>
动态数据的获取
public Map<String, Object> getContent() throws IOException {
// 从数据库中获取数据, 出于演示目的, 这里数据不从数据库获取, 而是直接写死
Map<String, Object> variables = new HashMap<String, Object>(3);
List<User> userList = new ArrayList<User>();
User tom = new User("Tom", 19, 1);
User amy = new User("Amy", 28, 0);
User leo = new User("Leo", 23, 1);
userList.add(tom);
userList.add(amy);
userList.add(leo);
variables.put("title", "用户列表");
variables.put("userList", userList);
return variables;
}
动态数据的绑定,html内容的输出
/**
* Generate html string.
*
* @param template
* the name of freemarker teamlate.
* @param variables
* the data of teamlate.
* @return htmlStr
* @throws Exception
*/
public static String generate(String template, Map<String, Object> variables)
throws Exception {
Configuration config = FreemarkerConfiguration.getConfiguation();
Template tp = config.getTemplate(template);
StringWriter stringWriter = new StringWriter();
BufferedWriter writer = new BufferedWriter(stringWriter);
tp.setEncoding("UTF-8");
tp.process(variables, writer);
String htmlStr = stringWriter.toString();
writer.flush();
writer.close();
return htmlStr;
}
2、pdf的导出
private void generatePdf(String htmlStr, OutputStream out)
throws IOException, DocumentException {
//final ServletContext servletContext = getServletContext(); Document document = new Document(PageSize.A4, 30, 30, 30, 30);
document.setMargins(30, 30, 30, 30);
PdfWriter writer = PdfWriter.getInstance(document, out);
document.open(); // html内容解析
HtmlPipelineContext htmlContext = new HtmlPipelineContext(
new CssAppliersImpl(new XMLWorkerFontProvider() {
@Override
public Font getFont(String fontname, String encoding,
float size, final int style) {
Font font = null;
if (fontname == null) {
//字体
String fontCn = getChineseFont();
BaseFont bf;
try {
//注意这里有一个,1
bf = BaseFont.createFont(fontCn+",1",
BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);
font = new Font(bf, size, style);
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} }
return font;
}
})) {
@Override
public HtmlPipelineContext clone()
throws CloneNotSupportedException {
HtmlPipelineContext context = super.clone();
try {
ImageProvider imageProvider = this.getImageProvider();
context.setImageProvider(imageProvider);
} catch (NoImageProviderException e) {
}
return context;
}
}; // 图片解析
htmlContext.setImageProvider(new AbstractImageProvider() { // String rootPath = servletContext.getRealPath("/"); @Override
public String getImageRootPath() {
return "";
} @Override
public Image retrieve(String src) {
if (StringUtils.isEmpty(src)) {
return null;
}
try {
// String imageFilePath = new File(rootPath, src).toURI().toString();
Image image = Image.getInstance(src);
image.setAbsolutePosition(400, 400);
if (image != null) {
store(src, image);
return image;
}
} catch (Throwable e) {
e.printStackTrace();
}
return super.retrieve(src);
}
});
htmlContext.setAcceptUnknown(true).autoBookmark(true)
.setTagFactory(Tags.getHtmlTagProcessorFactory()); // css解析
CSSResolver cssResolver = XMLWorkerHelper.getInstance()
.getDefaultCssResolver(true);
cssResolver.setFileRetrieve(new FileRetrieve() {
@Override
public void processFromStream(InputStream in,
ReadingProcessor processor) throws IOException {
try (InputStreamReader reader = new InputStreamReader(in,
CHARSET_NAME)) {
int i = -1;
while (-1 != (i = reader.read())) {
processor.process(i);
}
} catch (Throwable e) {
}
} // 解析href
@Override
public void processFromHref(String href, ReadingProcessor processor)
throws IOException {
// InputStream is = servletContext.getResourceAsStream(href);
URL url = new URL(href);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5 * 1000);
InputStream is = conn.getInputStream(); try (InputStreamReader reader = new InputStreamReader(is,
CHARSET_NAME)) {
int i = -1;
while (-1 != (i = reader.read())) {
processor.process(i);
}
} catch (Throwable e) {
e.printStackTrace();
}
}
}); HtmlPipeline htmlPipeline = new HtmlPipeline(htmlContext,
new PdfWriterPipeline(document, writer));
Pipeline<?> pipeline = new CssResolverPipeline(cssResolver,
htmlPipeline);
XMLWorker worker = null;
worker = new XMLWorker(pipeline, true);
XMLParser parser = new XMLParser(true, worker,
Charset.forName(CHARSET_NAME));
try (InputStream inputStream = new ByteArrayInputStream(
htmlStr.getBytes())) {
parser.parse(inputStream, Charset.forName(CHARSET_NAME));
}
document.close();
}
3、生成的pdf
注意点
1、博客中的代码不是一个完整工程,只依赖博客中的代码是运行不起来的;
2、文件路径的获取,本地文件与远程文件的获取是有区别的, 另外本地文件的获取又存在多种方式;
3、完整工程地址:itextpdf,仔细阅读readme.txt, 工程中存在多个版本, 而本博客对应的是版本4;
4、推荐将SIMSUN.TTC放到工程中, 这就不依赖操作系统了, 可移植性更强;
参考
freemarker+Flying sauser +Itext 整合生成PDF
flying-saucer + iText + Freemarker实现pdf的导出, 支持中文、css以及图片的更多相关文章
- iText + Freemarker实现pdf的导出,支持中文、css以及图片,页眉页脚,页眉添加图片
本文为了记录自己的实现过程,具体的实现步骤是参考博文 https://www.cnblogs.com/youzhibing/p/7692366.html 来实现的,只是在他的基础上添加了页眉页脚及页眉 ...
- [Web Pdf] flying-saucer + iText + Freemarker生成pdf 跨页问题
转载于: https://blog.csdn.net/qq_31980421/article/details/79662988 flying-saucer + iText + Freemarker实 ...
- Java iText+FreeMarker生成PDF(HTML转PDF)
1.背景 在某些业务场景中,需要提供相关的电子凭证,比如网银/支付宝中转账的电子回单,签约的电子合同等.方便用户查看,下载,打印.目前常用的解决方案是,把相关数据信息,生成对应的pdf文件返回给用户. ...
- JS导出PDF插件(支持中文、图片使用路径)
在WEB上想做一个导出PDF的功能,发现jsPDF比较多人推荐,遗憾的是不支持中文,最后找到pdfmake,很好地解决了此问题.它的效果可以先到http://pdfmake.org/playgroun ...
- Java使用Flying Saucer实现HTML代码生成PDF文档
1.需要的jar包:org.xhtmlrenderer.flying-saucer-pdf-itext5,Maven依赖如下: <dependency> <groupId>or ...
- PDF 生成插件 flying saucer 和 iText
最近的项目中遇到了需求,用户在页面点击下载,将页面以PDF格式下载完成供用户浏览,所以上网找了下实现方案. 在Java世界,要想生成PDF,方案不少,所以简单做一个小结吧. 在此之前,先来勾画一下我心 ...
- [itext]Java生成PDF文件
一.前言 最近在做也导出试卷的功能,刚开始是导出为doc,可是导出来格式都有变化,最后说直接将word转为pdf,可是各种不稳定,各种报错.最后想到直接将文件写入pdf(参考:http://www.c ...
- Java利用模板生成pdf并导出
1.准备工作 (1)Adobe Acrobat pro软件:用来制作导出模板 (2)itext的jar包 2.开始制作pdf模板 (1)先用word做出模板界面 (2)文件另存为pdf格式文件 (3) ...
- 使用iText库创建PDF文件
前言 译文连接:http://howtodoinjava.com/apache-commons/create-pdf-files-in-java-itext-tutorial/ 对于excel文件的读 ...
随机推荐
- 社工数据搜索引擎搭建 - Build Social Engineer Evildata Search Engine
如何设计搭建一个社工库 从初起设计一个社工库,到现在的Beta,前前后后零零整整花了不下一个月的时间,林林总总记录下来,留给需要之人 泄露数据库格式不一,长相奇葩,因需将用户名.密码.邮箱.哈希等信息 ...
- 04面向对象编程-02-原型继承 和 ES6的class继承
1.原型继承 在上一篇中,我们提到,JS中原型继承的本质,实际上就是 "将构造函数的原型对象,指向由另一个构造函数创建的实例". 这里,我们就原型继承的概念,再进行详细的理解.首先 ...
- Java Map对象的遍历
一般情况下Map的实现类中用的最多的是 HashMap . Map的遍历也就是迭代 1. 在for-each循环中使用entries来遍历 (既要取键,又要取值) Map<String, St ...
- 从content-type设置看Spring MVC处理header的一个坑
我们经常需要在HttpResponse中设置一些headers,我们使用Spring MVC框架的时候我们如何给Response设置Header呢? Sooooooooooooo easy, 看下面的 ...
- WebSocket部署服务器外网无法连接解决方案
首先要说的是我遇见的问题: WebSocket connection to 'ws://www.xxxx.com/xxx/xx' failed: Error during WebSocket hand ...
- jsonp其实很简单【ajax跨域请求】
js便签笔记(13)——jsonp其实很简单[ajax跨域请求] 前两天被问到ajax跨域如何解决,还真被问住了,光知道有个什么jsonp,迷迷糊糊的没有说上来.抱着有问题必须解决的态度,我看了许多资 ...
- jenkins~集群分发功能和职责处理
jenkins的多节点集群 在进行自动化部署时,你可以按着它们的项目类型去进行分别部署,这样即可以达到负载均衡,又可以达到一种职责的明确,比如像java的项目你可以使用linux服务来进行部署(拉代码 ...
- vue-ajax小封装
1. js 文件: /** ajax封装:* 1. 引入文件* 2. new Vue().ajax.get(url,data,fn,ojson), 或 new Vue().ajax.post(url, ...
- Hive内置数据类型
Hive的内置数据类型可以分为两大类:(1).基础数据类型:(2).复杂数据类型.其中,基础数据类型包括:TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBL ...
- Oracle第一波
html,body,div,span,applet,object,iframe,h1,h2,h3,h4,h5,h6,p,blockquote,pre,a,abbr,acronym,address,bi ...