Cosmos OpenSSD--greedy_ftl1.2.0(三)
我们来假设模拟一个小型的模型来分析写和垃圾回收的过程
假设只有一个die,4个block,每个block4个page,每个page8KB
那么PageMap就是Page[0][0]到Page[0][15]
BlockMap就是Block[0][0]到Block[0][3]
GcMap就是GC[0][0]到GC[0][4]
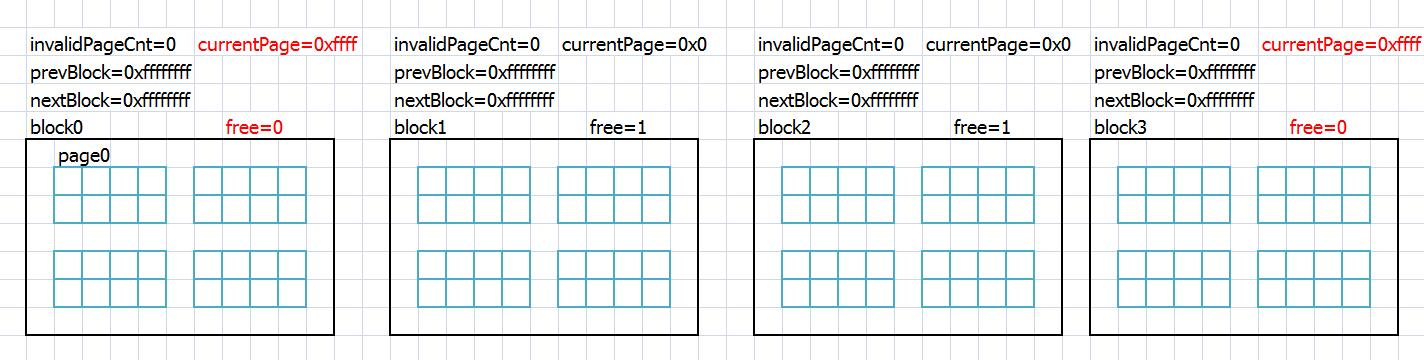
那么最初就会如下图:第零块用来保留元数据,最后一块保留作为垃圾回收合并块
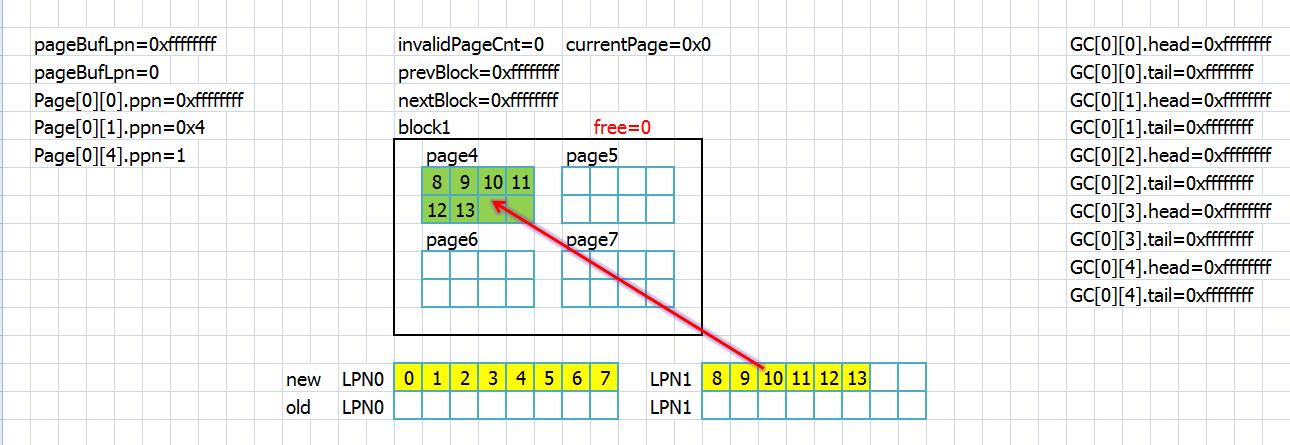
接下来从上层来了数据,黄色部分表示更改的数据,红色部分表示更新的数据,最左侧是流程
在这里,lpn0的内容作为page缓存留在SDRAM里面,只把lpn1的内容存入flash
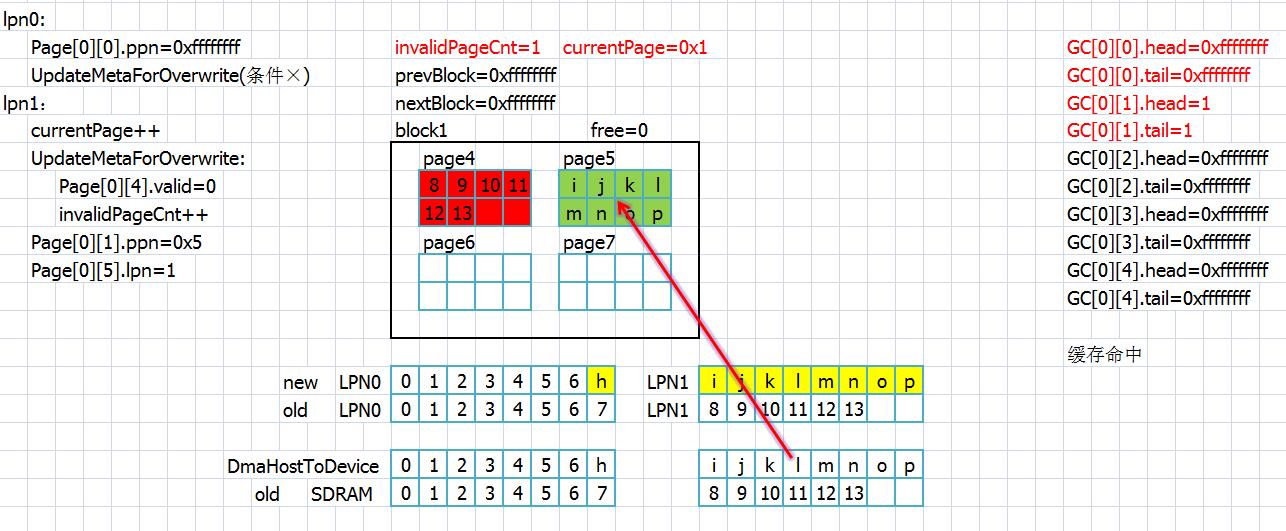
接下来更改的数据缓存命中了,所以lpn0的内容直接在SDRAM里面修改,此时数据末尾刚好占据了一个页,所以直接存入flash,并把之前的保存页无效,此时GC表开始变化
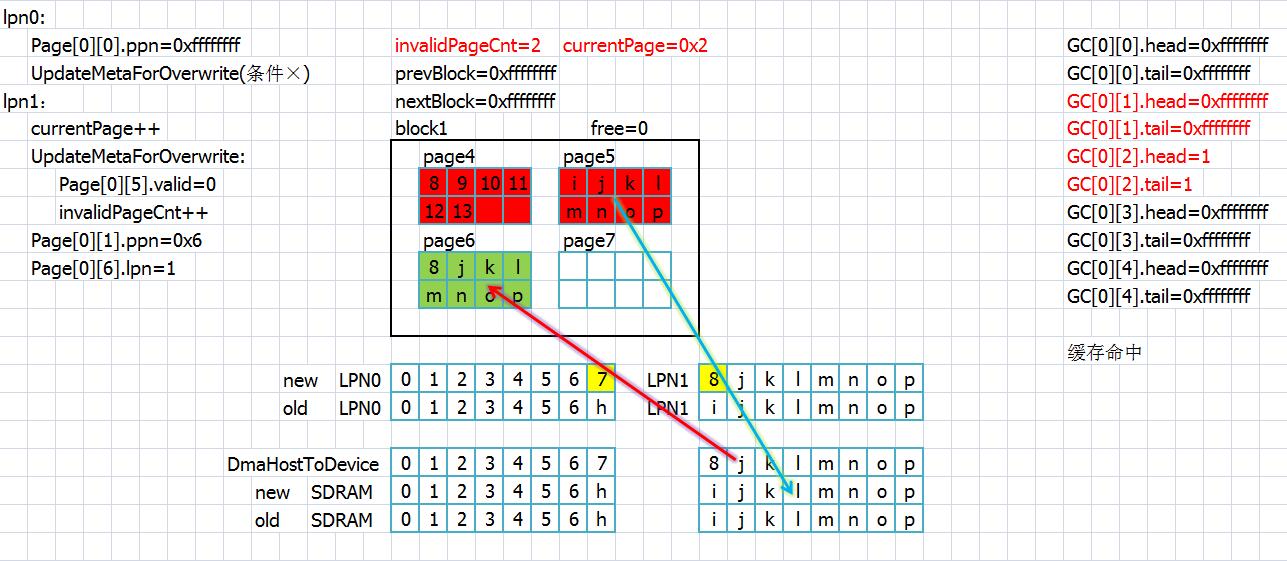
接下来依旧缓存命中,但是请求最后一页并不是完整的一页,于是先预读出其中的内容,修改之后寻找新页再保存进flash
这一次的缓存并没有命中,所以先把SDRAM里面的内容flush进SDRAM里面,因为请求并不满足一页,所以执行read-modify-write,此时lpn1作为新的page缓存,并不直接存进flash而是保留在SDRAM中
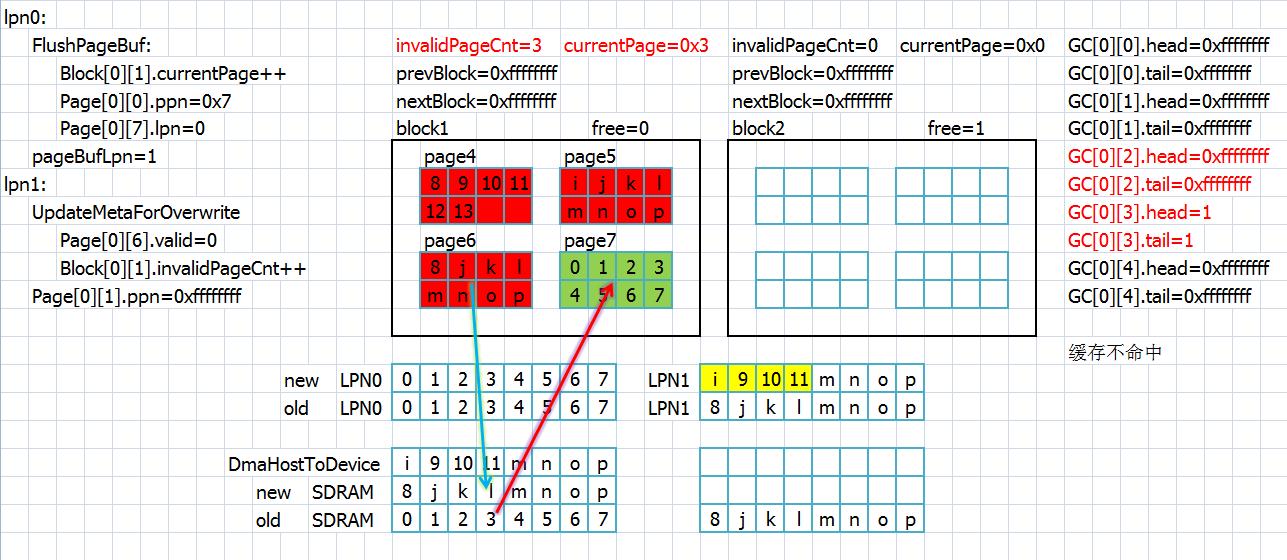
缓存依旧不命中,此时block1已经没有页面可用了,于是找到了下一个空闲block,先flush,然后更新page缓存,将lpn1的内容存入flash
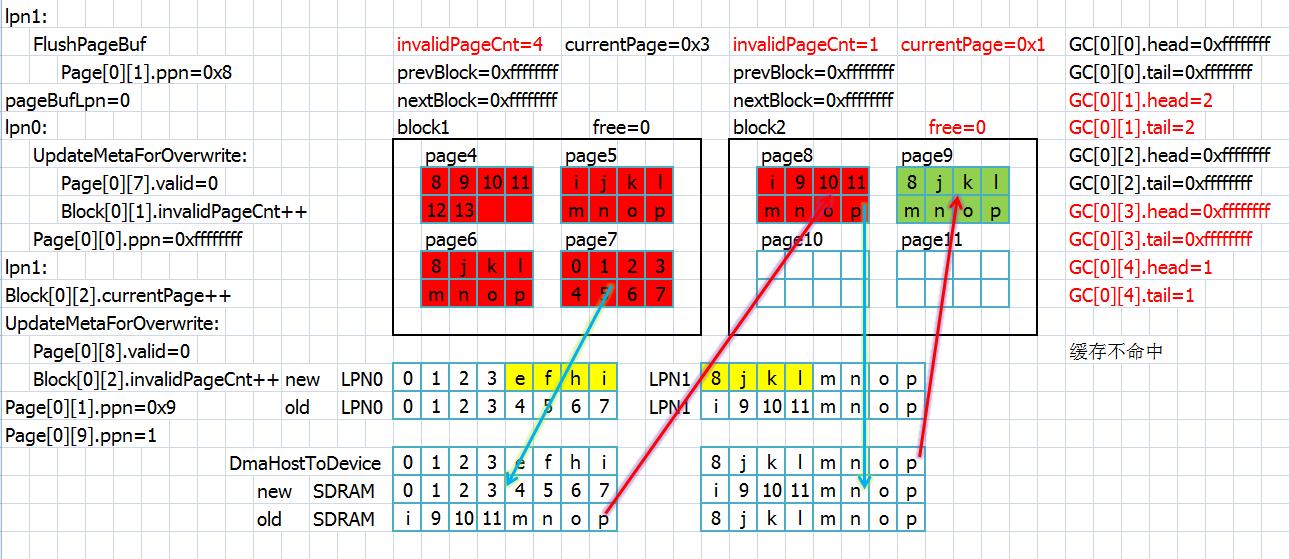
接下来缓存不命中,并且消耗掉了所有的页面,于是lpn3的内容无处存取,引发垃圾回收操作
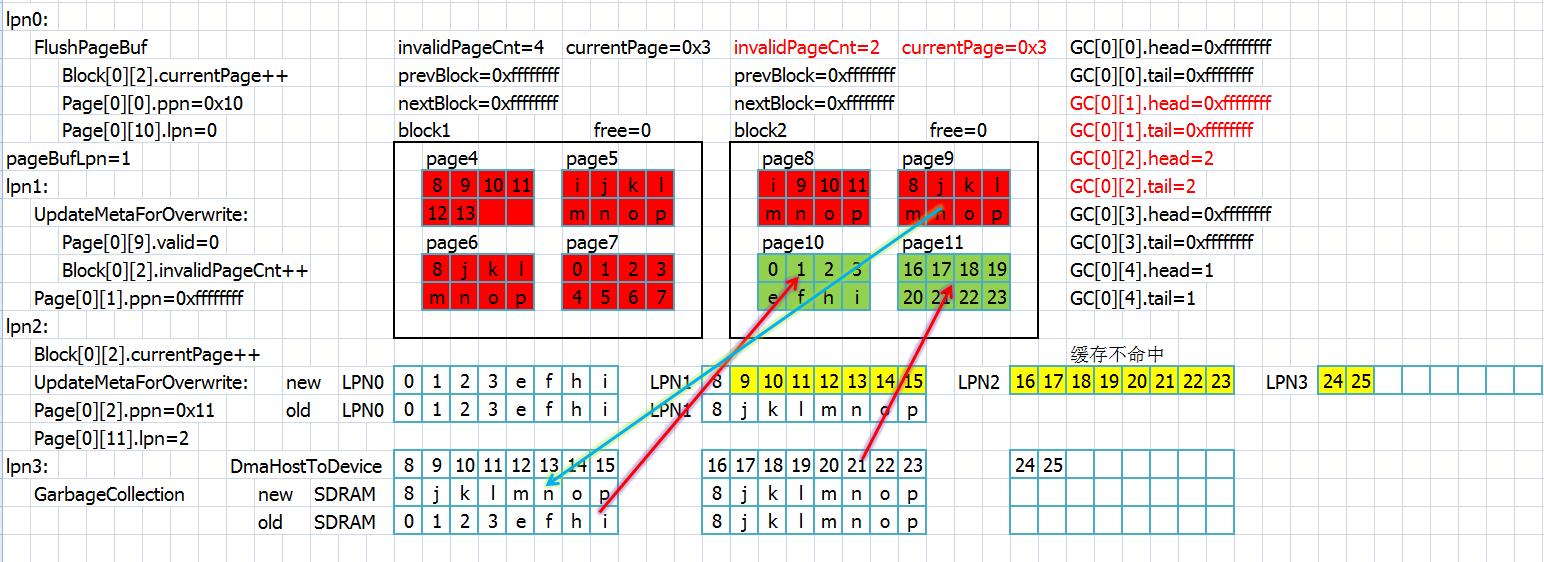
垃圾回收操作的依据是元数据的更新,因此我们来看元数据更新的代码
void UpdateMetaForOverwrite(u32 lpn)
{
pageMap = (struct pmArray*)(PAGE_MAP_ADDR);
blockMap = (struct bmArray*)(BLOCK_MAP_ADDR);
gcMap = (struct gcArray*)(GC_MAP_ADDR); u32 dieNo = lpn % DIE_NUM;
u32 dieLpn = lpn / DIE_NUM; if(pageMap->pmEntry[dieNo][dieLpn].ppn != 0xffffffff)
{
// GC victim block list management
u32 diePbn = pageMap->pmEntry[dieNo][dieLpn].ppn / PAGE_NUM_PER_BLOCK; // unlink
if((blockMap->bmEntry[dieNo][diePbn].nextBlock != 0xffffffff) && (blockMap->bmEntry[dieNo][diePbn].prevBlock != 0xffffffff))
{
blockMap->bmEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].prevBlock].nextBlock = blockMap->bmEntry[dieNo][diePbn].nextBlock;
blockMap->bmEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].nextBlock].prevBlock = blockMap->bmEntry[dieNo][diePbn].prevBlock;
}
else if((blockMap->bmEntry[dieNo][diePbn].nextBlock == 0xffffffff) && (blockMap->bmEntry[dieNo][diePbn].prevBlock != 0xffffffff))
{
blockMap->bmEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].prevBlock].nextBlock = 0xffffffff;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail = blockMap->bmEntry[dieNo][diePbn].prevBlock;
}
else if((blockMap->bmEntry[dieNo][diePbn].nextBlock != 0xffffffff) && (blockMap->bmEntry[dieNo][diePbn].prevBlock == 0xffffffff))
{
blockMap->bmEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].nextBlock].prevBlock = 0xffffffff;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].head = blockMap->bmEntry[dieNo][diePbn].nextBlock;
}
else
{
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].head = 0xffffffff;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail = 0xffffffff;
} // xil_printf("[unlink] dieNo = %d, invalidPageCnt= %d, diePbn= %d, blockMap.prevBlock= %d, blockMap.nextBlock= %d, gcMap.head= %d, gcMap.tail= %d\r\n", dieNo, blockMap->bmEntry[dieNo][diePbn].invalidPageCnt, diePbn, blockMap->bmEntry[dieNo][diePbn].prevBlock, blockMap->bmEntry[dieNo][diePbn].nextBlock, gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].head, gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail); // invalidation update
pageMap->pmEntry[dieNo][pageMap->pmEntry[dieNo][dieLpn].ppn].valid = ;
blockMap->bmEntry[dieNo][diePbn].invalidPageCnt++; // insertion
if(gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail != 0xffffffff)
{
blockMap->bmEntry[dieNo][diePbn].prevBlock = gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail;
blockMap->bmEntry[dieNo][diePbn].nextBlock = 0xffffffff;
blockMap->bmEntry[dieNo][gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail].nextBlock = diePbn;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail = diePbn;
}
else
{
blockMap->bmEntry[dieNo][diePbn].prevBlock = 0xffffffff;
blockMap->bmEntry[dieNo][diePbn].nextBlock = 0xffffffff;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].head = diePbn;
gcMap->gcEntry[dieNo][blockMap->bmEntry[dieNo][diePbn].invalidPageCnt].tail = diePbn;
}
}
}
其实从上面的写过程分析,我们可以大概了解到GC表其实就是把有相同无效页的block串联在一起
我们假设从block1到block7,其中无效页最终分别为100,120,110,100,110,120,100
当block1进行完之后,GC[0][100].head=1 GC[0][100].tail=1
当block2的无效页也到达100的时候,分析代码可知,GC[0][100].head=1 GC[0][100].tail=2,而且block1和block2会链接起来,但是block2的无效页会继续增加,于是当他的无效页增加的时候,block1和block2又会断开,指向无效的0xffffffff,而block2执行完毕之后GC[0][120].head=2 GC[0][120].tail=2.
只有当block4和block7的无效页最终停在100的时候,block1↔block4↔block7
既然已经了解GC表表示的什么意思,那么再看垃圾回收操作的代码就简单多了
u32 GarbageCollection(u32 dieNo)
{
xil_printf("GC occurs!\r\n"); pageMap = (struct pmArray*)(PAGE_MAP_ADDR);
blockMap = (struct bmArray*)(BLOCK_MAP_ADDR);
dieBlock = (struct dieArray*)(DIE_MAP_ADDR);
gcMap = (struct gcArray*)(GC_MAP_ADDR); int i;
for(i=PAGE_NUM_PER_BLOCK ; i> ; i--) //从无效页大的开始回收
{
if(gcMap->gcEntry[dieNo][i].head != 0xffffffff) //拥有这么多无效页的块存在的话,取出一块进行回收
{
u32 victimBlock = gcMap->gcEntry[dieNo][i].head; // GC victim block // link setting
if(blockMap->bmEntry[dieNo][victimBlock].nextBlock != 0xffffffff) //更新GC链表
{
gcMap->gcEntry[dieNo][i].head = blockMap->bmEntry[dieNo][victimBlock].nextBlock;
blockMap->bmEntry[dieNo][blockMap->bmEntry[dieNo][victimBlock].nextBlock].prevBlock = 0xffffffff;
}
else
{
gcMap->gcEntry[dieNo][i].head = 0xffffffff;
gcMap->gcEntry[dieNo][i].tail = 0xffffffff;
} // copy valid pages from the victim block to the free block
if(i != PAGE_NUM_PER_BLOCK) //如果整个块都是无效页就直接擦除就行了
{
int j;
for(j= ; j<PAGE_NUM_PER_BLOCK ; j++) //
{
if(pageMap->pmEntry[dieNo][(victimBlock * PAGE_NUM_PER_BLOCK) + j].valid)
{
// page copy process
u32 validPage = victimBlock*PAGE_NUM_PER_BLOCK + j;
u32 freeBlock = dieBlock->dieEntry[dieNo].freeBlock; //最开始有预留一个块
u32 freePage = freeBlock*PAGE_NUM_PER_BLOCK + blockMap->bmEntry[dieNo][freeBlock].currentPage; WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdRead(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, validPage, GC_BUFFER_ADDR); //将一个块里面的有效页读取到BUFFER里面
WaitWayFree(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM);
SsdProgram(dieNo % CHANNEL_NUM, dieNo / CHANNEL_NUM, freePage, GC_BUFFER_ADDR); //有效数据写入 // pageMap, blockMap update
u32 lpn = pageMap->pmEntry[dieNo][validPage].lpn; pageMap->pmEntry[dieNo][lpn].ppn = freePage; //更新页映射信息
pageMap->pmEntry[dieNo][freePage].lpn = lpn;
blockMap->bmEntry[dieNo][freeBlock].currentPage++;
}
}
} // erased victim block becomes the free block for GC migration
EraseBlock(dieNo, victimBlock);
blockMap->bmEntry[dieNo][victimBlock].free = ; u32 currentBlock = dieBlock->dieEntry[dieNo].freeBlock;
dieBlock->dieEntry[dieNo].freeBlock = victimBlock; //将刚擦出的块作为新的freeblock return currentBlock; // atomic GC completion
}
} // no free space anymore
assert(!"[WARNING] There are no free blocks. Abort terminate this ssd. [WARNING]");
return ;
}
Cosmos OpenSSD--greedy_ftl1.2.0(三)的更多相关文章
- Aurora 8B/10B、PCIe 2.0、SRIO 2.0三种协议比较
在高性能雷达信号处理机研制中,高速串行总线正逐步取代并行总线.业界广泛使用的Xilinx公司Virtex-6系列FPGA支持多种高速串行通信协议,本文针对其中较为常用的Aurora 8B/10B和PC ...
- [Android 4.4.3] 泛泰A860 Omni4.4.3 20140610 RC2.0 三版通刷 by syhost
欢迎关注泛泰非盈利专业第三方开发团队 VegaDevTeam (本team 由 syhost suky zhaochengw(z大) xuefy(大星星) tenfar(R大师) loogeo cr ...
- 13、Cocos2dx 3.0三,找一个小游戏开发3.0中间Director :郝梦主,一统江湖
重开发人员的劳动成果.转载的时候请务必注明出处:http://blog.csdn.net/haomengzhu/article/details/27706967 游戏中的基本元素 在曾经文章中,我们具 ...
- 14、Cocos2dx 3.0三,找一个小游戏开发Scene and Layer:游戏梦想
发人员的劳动成果,转载的时候请务必注明出处:http://blog.csdn.net/haomengzhu/article/details/30474393 Scene :场景 了解了Director ...
- 4、Cocos2dx 3.0三,找一个小游戏开发Hello World 分析
尊重开发人员的劳动成果.转载的时候请务必注明出处:http://blog.csdn.net/haomengzhu/article/details/27186557 Hello World 分析 打开新 ...
- Apache Spark 2.0三种API的传说:RDD、DataFrame和Dataset
Apache Spark吸引广大社区开发者的一个重要原因是:Apache Spark提供极其简单.易用的APIs,支持跨多种语言(比如:Scala.Java.Python和R)来操作大数据. 本文主要 ...
- II7.0 发布 MVC 4.0 三个小问题记录
1,403.14-Forbidden Web 服务器被配置为不列出此目录的内容 根据提示更改:使用 IIS 管理器启用目录浏览. 打开 IIS 管理器. 在“功能”视图中,双击“目录浏览”. 在“目录 ...
- Linux 下从头再走 GTK+-3.0 (三)
之前我们为窗口添加了一个按钮,接下来让这个按钮丰富一点.并给窗口加上图标. 首先创建 example3,c 的源文件. #include <gtk/gtk.h> static void a ...
- 8、Cocos2dx 3.0三,找一个小游戏开发3.0存储器管理的版本号
重开发人员的劳动成果,转载的时候请务必注明出处:http://blog.csdn.net/haomengzhu/article/details/27693365 复杂的内存管理 移动设备上的硬件资源十 ...
- Cosmos OpenSSD架构分析--FSC
接口速度: type bw read 75μs 1s/75μs*8k/1s=104m/s write 1300μs 1s/1300μs*8k/1s=6m/s erase 3.8ms 1s/ ...
随机推荐
- 201521123063 java第一周总结
20152112306 <Java程序设计>第一周学习总结 1.本周学习总结(2.20-2.26) java语言的特点: (1)简约且简单 (2)平台无关性 (3)面向对象 (4)多线程. ...
- 201521123096《Java程序设计》第九周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 1.常用异常 题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自己 ...
- Java第十二周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. 2. 书面作业 将Student对象(属性:int id, String name,int age,doubl ...
- chrome保存网页为单个文件(mht格式)
网页归档(英语:MIME HTML或MIME Encapsulation of Aggregate HTML Documents,又称单一文件网页或网页封存盘案)为以多用途互联网邮件扩展格式,将一个多 ...
- 小巧玲珑:机器学习届快刀XGBoost的介绍和使用
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:张萌 序言 XGBoost效率很高,在Kaggle等诸多比赛中使用广泛,并且取得了不少好成绩.为了让公司的算法工程师,可以更加方便的 ...
- 支持语音识别、自然语言理解的微信小程序(“遥知之”智能小秘)完整源码分享
记录自己搭建https的silk录音文件语音识别服务的调用过程,所有代码可在文中找链接打包下载 >>>>>>>>>>>>> ...
- JS中关于数组的内容
前 言 LIUWE 在网站制作过程中,数组可以说是起着举足轻重的地位.今天就给大家介绍一下数组的一些相关内容.例如:如何声明一个数组和在网站制作过程中我们常用的一些数组的方法.介绍的不好还请多多 ...
- Redis的安装以及在项目中使用Redis的一些总结和体会
第一部分:为什么我的项目中要使用Redis 我知道有些地方没说到位,希望大神们提出来,我会吸取教训,大家共同进步! 注册时邮件激活的部分使用Redis 发送邮件时使用Redis的消息队列,减轻网站压力 ...
- canvas浅谈 实现简单的自旋转下落
旋转和平移是2个基础的动画效果,也是复杂动画的基础. 如果是普通的页面只要设置transform属性很容易实现平移+旋转的组合效果,达到自旋转下落的效果.因为操作的直接是动作元素本身很容易理解. 但是 ...
- 修改NSMutableArray中的元素时的注意事项
最近做项目遇到从文件加载数组,并对数组中的元素进行操作的问题,特意写了个Demo,记录下要注意的东西: 代码如下: NSArray *array = @["]; NSMutableArray ...