SQL SERVER大话存储结构(3)_数据行的行结构

1 引入
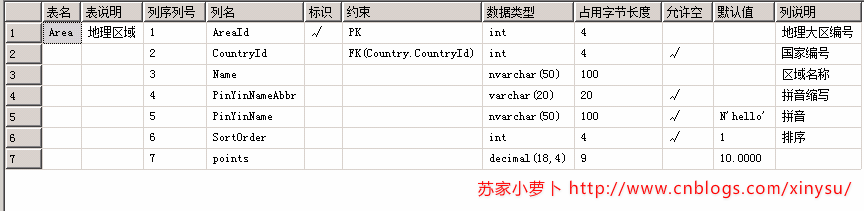
SELECT
表名 = CASE WHEN A.COLORDER=1 THEN D.NAME ELSE '' END,
表说明 = CASE WHEN A.COLORDER=1 THEN ISNULL(F.VALUE,'') ELSE '' END,
列序列号 = A.COLORDER,
列名 = A.NAME,
标识 = CASE WHEN COLUMNPROPERTY( A.ID,A.NAME,'ISIDENTITY')=1 THEN '√'ELSE '' END,
约束 = CASE WHEN EXISTS(
SELECT 1
FROM SYSOBJECTS
WHERE XTYPE='PK' AND PARENT_OBJ=A.ID AND NAME IN (
SELECT
NAME
FROM SYSINDEXES
WHERE INDID IN( SELECT INDID FROM SYSINDEXKEYS WHERE ID = A.ID AND COLID=A.COLID )
)
) THEN 'PK'
WHEN EXISTS (
SELECT 1 FROM sys.foreign_key_columns
WHERE parent_object_id=A.ID AND parent_column_id=A.COLID
) THEN 'FK'+'('+(SELECT OBJECT_NAME(referenced_object_id)+'.'+COL_NAME(referenced_object_id,referenced_column_id)+')' FROM sys.foreign_key_columns WHERE parent_object_id=A.ID AND parent_column_id=A.COLID)
ELSE '' END,
数据类型 = CASE WHEN B.NAME IN ('CHAR','NCHAR','VARCHAR','NVARCHAR') THEN B.NAME+'('+ISNULL(CAST(case when COLUMNPROPERTY(A.ID,A.NAME,'PRECISION')=-1 then null else COLUMNPROPERTY(A.ID,A.NAME,'PRECISION') end AS VARCHAR(10)),'MAX')+')'
WHEN B.NAME ='DECIMAL' THEN B.NAME+'('+CAST(COLUMNPROPERTY(A.ID,A.NAME,'PRECISION') AS VARCHAR(10))+','+CAST(ISNULL(COLUMNPROPERTY(A.ID,A.NAME,'SCALE'),0) AS VARCHAR(10))+')'
ELSE B.NAME END,
占用字节长度 = A.LENGTH,
--长度 = COLUMNPROPERTY(A.ID,A.NAME,'PRECISION'),
--小数位数 = ISNULL(COLUMNPROPERTY(A.ID,A.NAME,'SCALE'),0),
允许空 = CASE WHEN A.ISNULLABLE=1 THEN '√'ELSE '' END,
默认值 = case when E.TEXT is not null then
case when substring(e.text,1,2)='((' then substring(e.text,3,len(e.text)-4)
when substring(e.text,1,1)='(' then substring(e.text,2,len(e.text)-2)
else e.text end
else '' end ,
列说明 = ISNULL(G.[VALUE],'')
FROM SYSCOLUMNS A LEFT JOIN SYSTYPES B ON A.XUSERTYPE=B.XUSERTYPE
INNER JOIN SYSOBJECTS D ON A.ID=D.ID AND D.XTYPE='U' AND D.NAME<>'DTPROPERTIES'
LEFT JOIN SYSCOMMENTS E ON A.CDEFAULT=E.ID
LEFT JOIN sys.extended_properties G ON A.ID=G.major_id AND A.COLID=G.minor_id
LEFT JOIN sys.extended_properties F ON D.ID=F.major_id AND F.minor_id=0
WHERE D.NAME IN ('area','','')
ORDER BY A.ID,A.COLORDER
查询表结构SQL
2 数据行
2.1 数据行结构
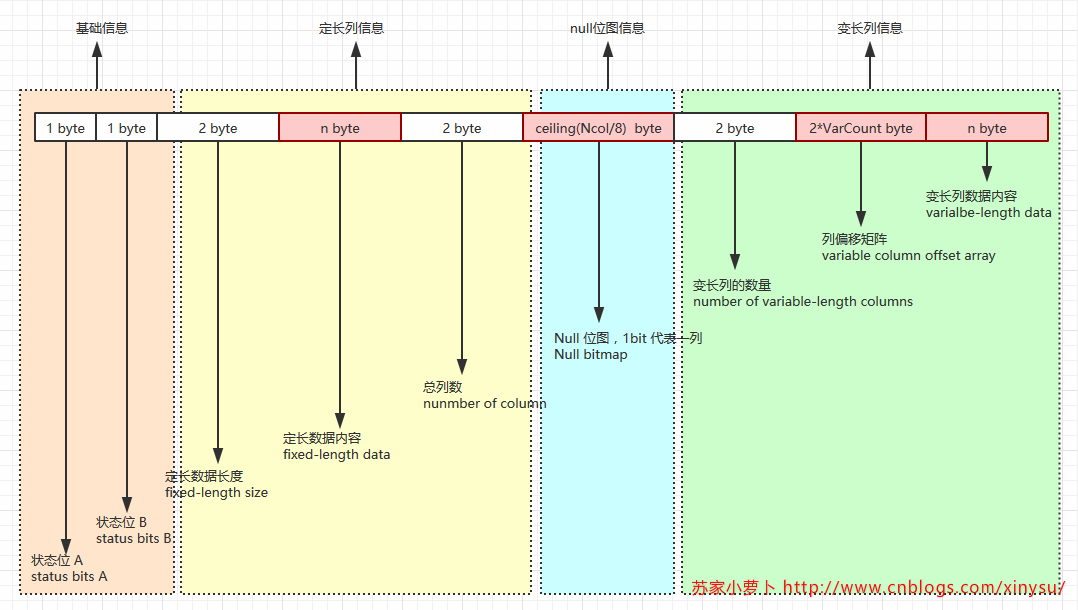
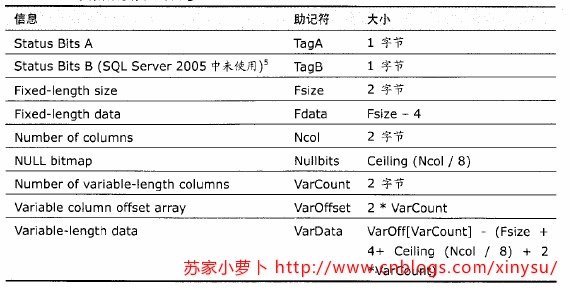
- 状态位A:表示行属性的位图,1字节,8bit
- Bit 0 位,版本信息
- Bits 1-3 位,行记录类型
- 0,primary record,主记录
- 1,forwarded record
- 2,forwarding stub
- 3,index record,索引记录
- 4,blob或者行溢出数据
- 5,ghost索引记录
- 6,ghost数据记录
- Bit 4 位,NULL位图
- Bit 5 位,表示行中有变长列
- Bit 6 位,保留
- Bit 7 位,ghost record(幽灵记录)
- 列偏移矩阵
- 如果一个表格,没有变长列,那么这个表格则不需要列偏移矩阵
- 一个变长列,有一个列偏移矩阵,一个列偏移矩阵2个字节,用于表示变长列中每个列的结束位置。
2.2 特殊情况(大对象、行溢出及forword)
2.2.1 大对象
2.2.2 行溢出
2.2.3 forword
3 测试存储情况
- 先建立一个只有2列非空定长列的堆表,然后INSERT一行数据,检查page页面存储内容
- 添加主键,检查存储页面内容
- 增加一列:可空变长列
- 增加一列:非空变长列+默认值(分大对象和非大对象)
- 删除无数据的列
- 删除有数据的列
- 行溢出
- forword
3.1 堆表分析



3.2 添加主键


3.3 增加一列:可空变长列

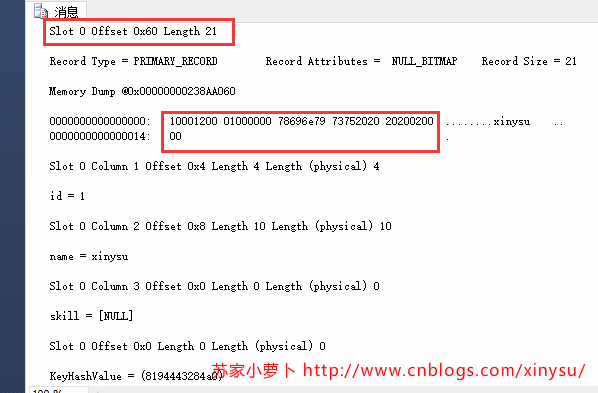
3.4 增加一列:非空变长列+默认值
3.4.1 非大对象列




3.5 删除无数据的列

3.6 删除有数据的列

3.7 行溢出


3.8 Forword


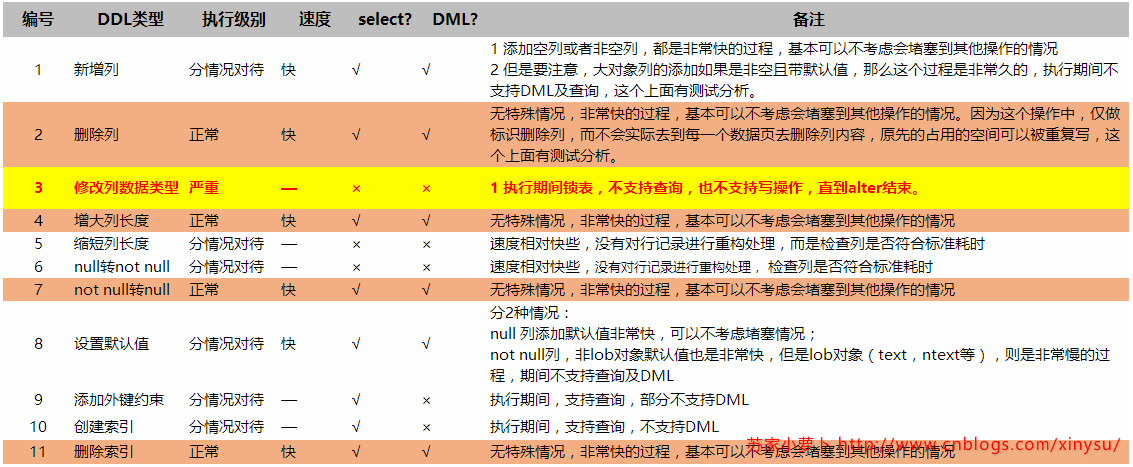
4 行结构与DDL
SQL SERVER大话存储结构(3)_数据行的行结构的更多相关文章
- SQL SERVER大话存储结构(6)_数据库数据文件
数据库文件有两大类:数据文件跟日志文件,每一个数据库至少各有一个数据文件或者日志文件,数据文件用来存储数据,日志文件用来存储数据库的事务修改情况,可用于恢复数据库使用. 这里分 ...
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- SQL SERVER大话存储结构(5)_SQL SERVER 事务日志解析
本系列上一篇博文链接:SQL SERVER大话存储结构(4)_复合索引与包含索引 1 基本介绍 每个数据库都具有事务日志,用于记录所有事物以及每个事物对数据库所作的操作. 日志的记录 ...
- SQL SERVER大话存储结构(1)_数据页类型及页面指令分析
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! SQLServer的数据页大 ...
- SQL SERVER大话存储结构(2)_非聚集索引如何查找到行记录
如果转载,请注明博文来源: www.cnblogs.com/xinysu/ ,版权归 博客园 苏家小萝卜 所有.望各位支持! 1 行记录如何存储 这里引入两个 ...
- 人人都是 DBA(VIII)SQL Server 页存储结构
当在 SQL Server 数据库中创建一张表时,会在多张系统基础表中插入所创建表的信息,用于管理该表.通过目录视图 sys.tables, sys.columns, sys.indexes 可以查看 ...
- 使用Spark加载数据到SQL Server列存储表
原文地址https://devblogs.microsoft.com/azure-sql/partitioning-on-spark-fast-loading-clustered-columnstor ...
- SQL Server 列存储索引强化
SQL Server 列存储索引强化 SQL Server 列存储索引强化 1. 概述 2.背景 2.1 索引存储 2.2 缓存和I/O 2.3 Batch处理方式 3 聚集索引 3.1 提高索引创建 ...
- SQL Server ---(CDC)监控表数据(转译)
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 实现过程(Realization) 补充说明(Addon) 参考文献(References) ...
随机推荐
- Kubernetes日志收集
关于kubernetes的日志分好几种,针对kubernetes本身而言有三种: 1.资源运行时的event事件.比如在k8s集群中创建pod之后,可以通过 kubectl describe pod ...
- OC--Runtime知识点整理
1.Runtime简介 因为Objc是一门动态语言,所以它总是想办法把一些决定工作从编译连接推迟到运行时.也就是说只有编译器是不够的,还需要一个运行时系统 (runtime system) 来执行编译 ...
- WebServiceWSDLWeb
WSDL 文档仅仅是一个简单的 XML 文档. 它包含一系列描述某个 web service 的定义. WSDL 文档是利用这些主要的元素来描述某个 web service 的: 元素 定义 < ...
- WPF之路一:相对路径图片显示
由于公司项目的需要,改为WPF开发,因此需要学习WPF,遇到的第一个问题就是在显示的图片的时候,写绝对路径,图片显示没有问题,但是写相对路径的时候,发现图片无法正常显示,在网上搜了一下,得到的答案是需 ...
- 关于html5调用手机相机(原创)
很久没写随笔了 从ios6开始,webview支持html <input type="file">标签,用来调取手机的相册和相机,但是没有权限提示,不知道是不是我写的有 ...
- 在mysql 5.6的环境下修改生产环境的表结构(在线ddl) ----工具pt-osc
随着需求的变化越来越快,在线修改表结构变得越来越需要. 在mysql5.6以前,mysql的修改表结构操作会锁表,这样就会造成开发人员或者DBA修改表结构必须要等到凌晨流量谷值或者停服修改.这样必定会 ...
- 几个地图(高德、百度、Apple、Google)URL API
移动应用中,如何在自己的App中调起第三方的原生地图App,并显示相关的信息,如显示指定的一个坐标位置,显示一个起点到终点的路线查询,等等. 目前几个主要的地图商都提供了自己的App通过URL调用的形 ...
- Java多线程学习笔记(二)——Executor,Executors,ExecutorService比较
Executor:是Java线程池的超级接口:提供一个execute(Runnable command)方法;我们一般用它的继承接口ExecutorService. Executors:是java.u ...
- 卷积神经网络CNN与深度学习常用框架的介绍与使用
一.神经网络为什么比传统的分类器好 1.传统的分类器有 LR(逻辑斯特回归) 或者 linear SVM ,多用来做线性分割,假如所有的样本可以看做一个个点,如下图,有蓝色的点和绿色的点,传统的分类器 ...
- linux C/C++ 日志打印函数
//宏定义日志文件名 #define PROCESSNAME "log_filename" //当日志文件大于5M时,会删除该文件,该接口使用方法 参照printfvoid Wr ...