分布式文件系统:HDFS
学习Hadoop,两个东西肯定是绕不过,MapReduce和HDFS,上一篇博客介绍了MapReduce的处理流程,这一篇博客就来学习一下HDFS。
HDFS是一个分布式的文件系统,就是将多台机器的存储当做一个文件系统来使用,因为在大数据的情景下,单机的存储量已经完全不够用了,所以采取分布式的方法来扩容,解决本地文件系统在文件大小、文件数量、打开文件数等的限制问题。我们首先来看一下HDFS的架构
HDFS架构
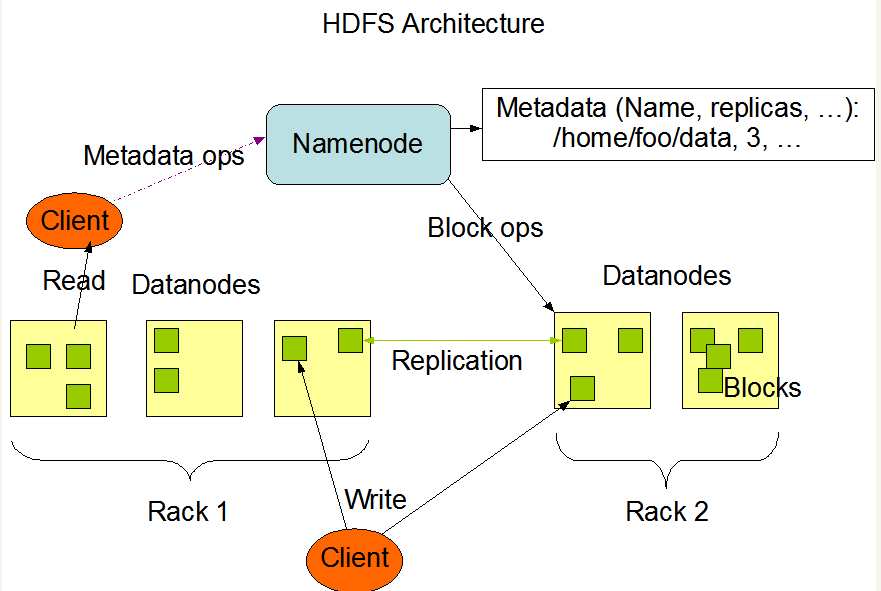
从上图可以看到,HDFS的主要组成部分为Namenode、Datanodes、Client,还有几个名词:Block、Metadata、Replication 、Rack,它们分别是什么意思呢?
对于分布式的文件系统,数据存储在很多的机器上,而Datanode代表的就是这些机器,是数据实际存储的地方,数据存好之后,我们需要知道它们具体存在哪一个Datanode上,这就是Namenode做的工作,它记录着元数据信息(也就是Metadata,其主要内容就是哪个数据块存在哪个Datanode上的哪个目录下,这也是为什么HDFS不适合存大量小文件的原因,因为 为了响应速度,Namenode 把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由 Namenode 的内存大小来决定。一般来说,每一个文件、文件夹和 Block 需要占据 150 字节左右的空间,如果存100 万个小文件,至少需要 300MB内存,但这么多小文件实际却没有存太多数据,这样就太浪费内存了),有了元数据信息,我们就能通过Namenode来查到数据块的具体位置了,而与Namenode打交道的工具就是Client,Client给我们用户提供存取数据的接口,我们可以通过Client进行数据存取的工作。
而剩下来的几个名词,Block表示的是数据块,因为存在HDFS上的一般都是很大的文件,我们需要将它拆成很多个数据块进行存储;Replication是副本的意思,这是为了数据的可靠性,如果某个数据块丢失了,还能通过它的副本找回来,HDFS默认一个数据块存储三份;Rack表示的是机架的意思,可以理解为存放多个Datanode的地方。
总结一下就是,数据存在Datanode上,并且有副本,而Namenode知道数据及其副本具体存在哪个Datanode上,我们想要找数据或者写数据的时候就通过Client来和Namenode联系,由它来告诉我们应该把数据存在哪里或者到哪里去取。
HDFS读写流程
看完了HDFS的架构,我们来看一下HDFS具体是怎么存取数据的。首先是写流程:
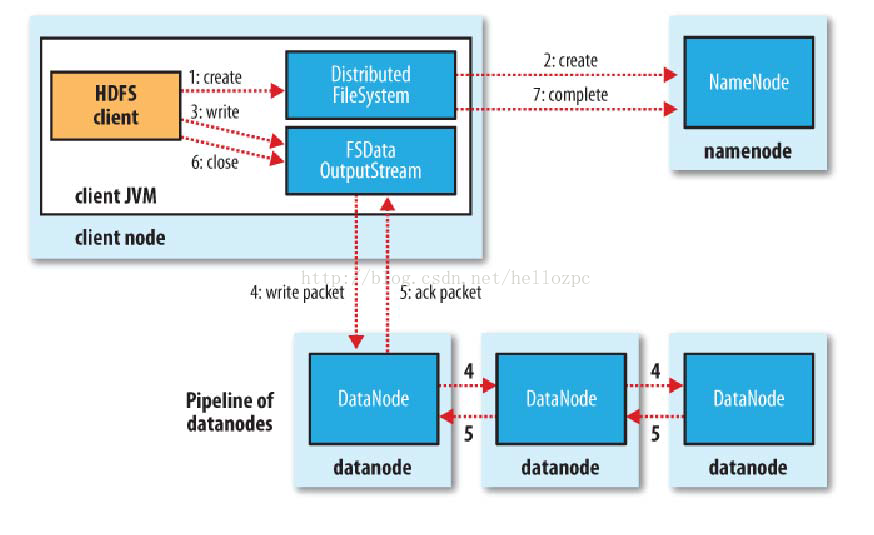
注:以下步骤并不严格对应如中的发生顺序
1)使用HDFS提供的客户端开发库,向远程的Namenode发起请求;
2)Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
3)当客户端开始写入文件的时候,会将文件切分成多个packets(数据包),并在内部以“data queue”(数据队列)的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replication的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
4)开始以pipeline(管道)的形式将packet写入所有的replication中。先将packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
5)最后一个datanode成功存储之后会返回一个ack packet(确认包),在pipeline里传递至客户端,在客户端内部维护着“ack queue”(确认队列),成功收到datanode返回的ackpacket后会从“ack queue”移除相应的packet,代表该packet写入成功。
6)如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会在剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replication设定的数量。
接下来是读流程:
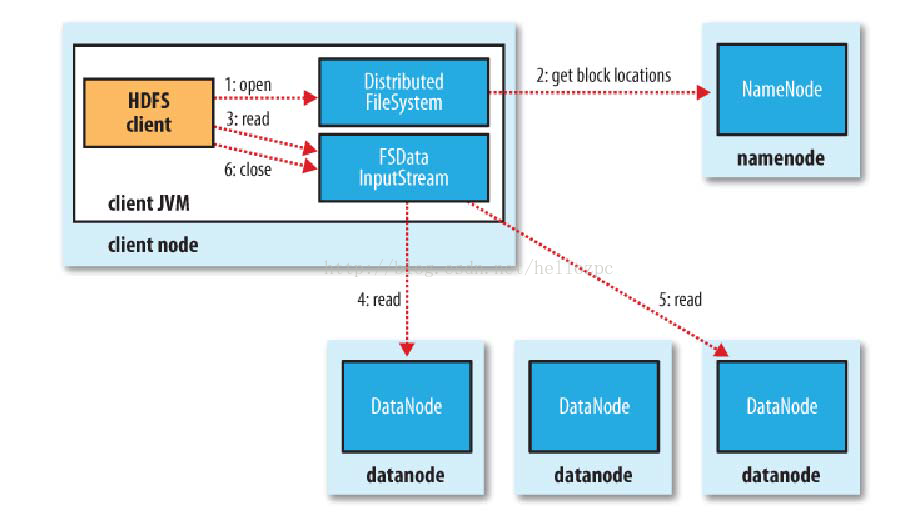
注:以下步骤并不严格对应如中的发生顺序
1)使用HDFS提供的客户端,向远程的Namenode发起请求;
2)Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的Datanode地址;
3)客户端会选取离客户端最接近的Datanode来读取block;
4)读取完当前block的数据后,关闭与当前的Datanode连接,并为读取下一个block寻找最佳的Datanode;
5)当读完列表的block后,且文件读取还没有结束,客户端会继续向Namenode获取下一批的block列表。
6)读取完一个block都会进行checksum(校验和)验证,看文件内容是否出错;另外,如果读取Datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷 贝的Datanode继续读。
以上便是HDFS的读写流程,了解这些之后,我们思考几个问题,对于分布式的文件系统,我们怎么保证数据的一致性?就是说如果有多个客户端向同一个文件写数据,那么我们该怎么处理?另外,我们看到Namenode在HDFS中非常重要,它保存着关键的元数据信息,但是从架构图中看到,Namenode只有一个,如果它挂掉了,我们怎么保证系统能够继续工作?
分布式领域CAP理论
CAP理论是分布式中一个经典的理论,具体内容如下:
Consistency(一致性):在分布式系统中的所有数据备份,在同一时刻是否同样的值。
Availability(可用性):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
Partition tolerance(分区容错性):系统应该能持续提供服务,即使系统内部有消息丢失(分区)。
一致性和可用性比较好理解,主要解释一下分区容错性,它的意思就是说因为网络的原因,可能是网络断开了,也可能是某些机器宕机了,网络延时等导致数据交换无法在期望的时间内完成。因为网络问题是避免不了的,所以我们总是需要解决这个问题,也就是得保证分区容错性。为了保证数据的可靠性,HDFS采取了副本的策略。
对于一致性,HDFS提供的是简单的一致性模型,为一次写入,多次读取一个文件的访问模式,支持追加(append)操作,但无法更改已写入数据。HDFS中的文件都是一次性写入的,并且严格要求在任何时候只能有一个写入者。什么时候一个文件算写入成功呢?对于HDFS来说,有两个参数:dfs.namenode.replication.min (默认为1) 和dfs.replication (默认为 3),一个文件的副本数大于等于参数dfs.namenode.replication.min 时就被标记为写成功,但是副本数要是小于参数dfs.replication,此文件还会标记为“unreplication”,会继续往其它Datanode里写副本,所以如果我们想要直到所有要保存数据的DataNodes确认它们都有文件的副本时,数据才被认为写入完成,我们可以将dfs.namenode.replication.min设置与dfs.replication相等。因此,数据一致性是在写的阶段完成的,一个客户端无论选择从哪个DataNode读取,都将得到相同的数据。
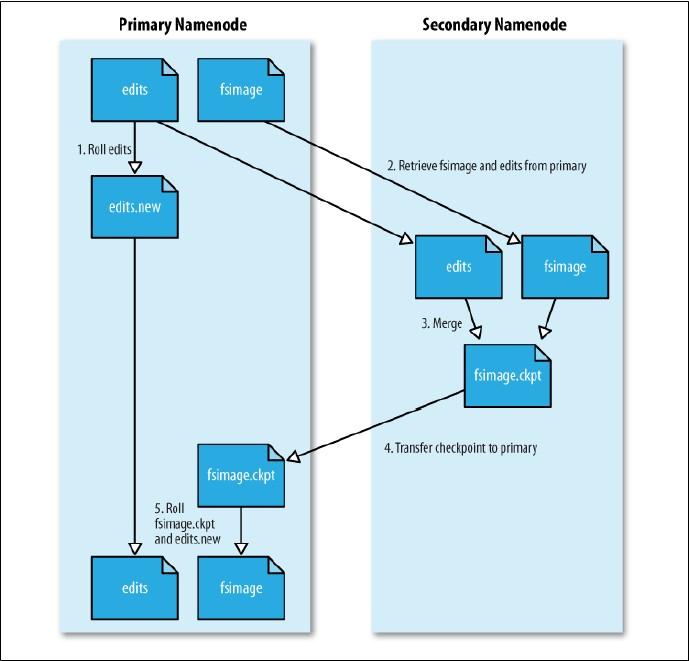
对于可用性,HDFS2.0对Namenode提供了高可用性(High Availability),这里提一下,Secondary NameNode不是HA,Namenode因为需要知道每个数据块具体在哪,所以为每个数据块命名,并保存这个命名文件(fsimage文件),只要有操作文件的行为,就将这些行为记录在编辑日志中(edits文件),为了响应的速度,这两个文件都是放在内存中的,但是随着文件操作额进行,edits文件会越来越大,所以Secondary NameNode会阶段性的合并edits和fsimage文件,以缩短集群启动的时间。当NameNode失效的时候,Secondary NameNode并无法立刻提供服务,Secondary NameNode甚至无法保证数据完整性,如果NameNode数据丢失的话,在上一次合并后的文件系统的改动会丢失。Secondary NameNode合并edits和fsimage文件的流程具体如下:
目前HDFS2中提供了两种HA方案,一种是基于NFS(Network File System)共享存储的方案,一种基于Paxos算法的方案Quorum Journal Manager(QJM),下面是基于NFS共享存储的方案
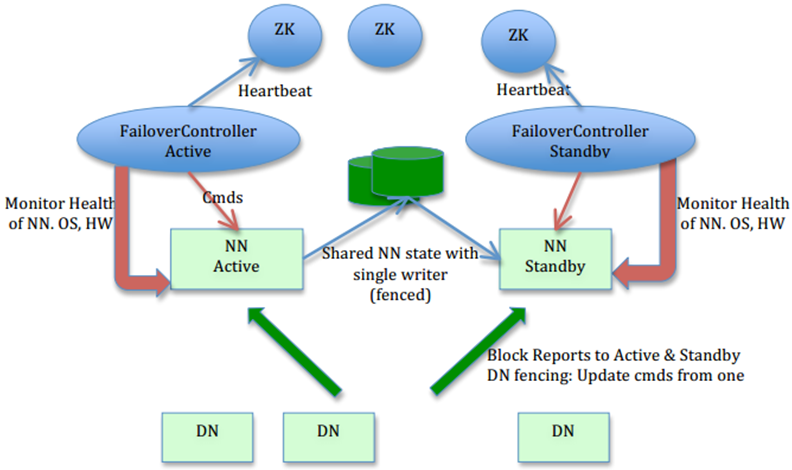
通过上图可知,Namenode的高可用性是通过为其设置一个Standby Namenode来实现的,要是目前的Namenode挂掉了,就启用备用的Namenode。而两个Namenode之间通过共享的存储来同步信息,以下是一些要点:
• 利用共享存储来在两个NameNode间同步edits信息。
• DataNode同时向两个NameNode汇报块信息。这是让Standby NameNode保持集群最新状态的必需步骤。
• 用于监视和控制NameNode进程的FailoverController进程(一旦工作的Namenode挂了,就启用切换程序)。
• 隔离(Fencing),防止脑裂,就是保证在任何时候只有一个主NameNode,包括三个方面:
• 共享存储fencing,确保只有一个NameNode可以写入edits。
• 客户端fencing,确保只有一个NameNode可以响应客户端的请求。
• DataNode fencing,确保只有一个NameNode可以向DataNode下发命令,譬如删除块,复制块,等等。
另一种是QJM方案:
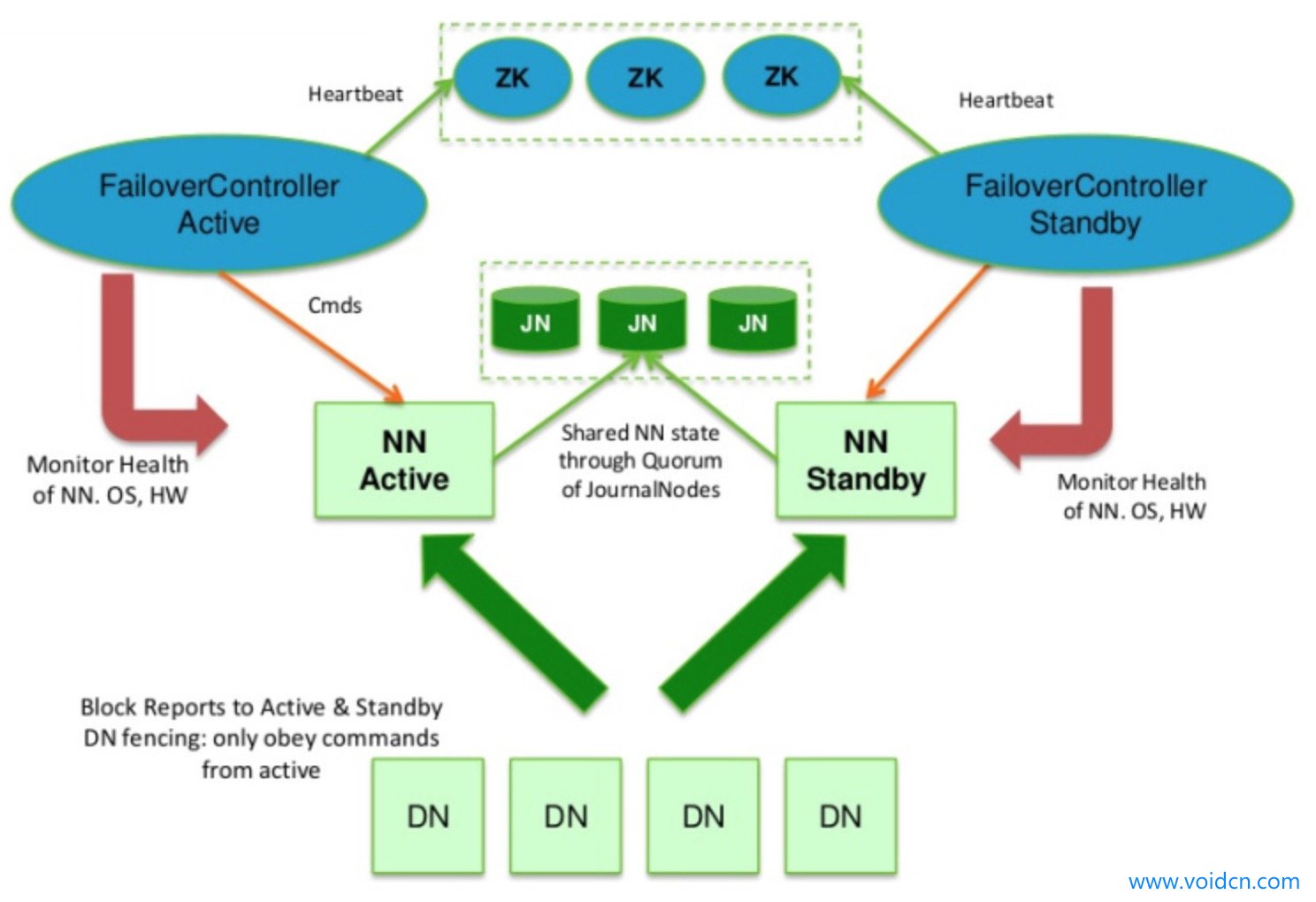
简单来说,就是为了让Standby Node与Active Node保持同步,这两个Node都与一组称为JNS(Journal Nodes)的互相独立的进程保持通信。它的基本原理就是用2N+1台JournalNode存储edits文件,每次写数据操作有大多数(大于等于N+1)返回成功时即认为该次写成功。因为QJM方案是基于Paxos算法的,而Paxos算法不是两三句就能说清楚的,有兴趣的可以看这个知乎专栏:Paxos算法或者参考官方文档。
总结
本篇博客主要介绍了HDFS的架构、读写流程和HDFS在CAP上的做法,帮助大家对HDFS的理解,如果想要更详细的技术细节,可以看看官方文档或者我在参考中列出的链接。
参考
《Hadoop权威指南》
http://www.cnblogs.com/youngerchina/p/5624459.html
http://blog.csdn.net/hguisu/article/details/7259716
http://www.cnblogs.com/codeOfLife/p/5375120.html
https://www.zybuluo.com/jewes/note/68185
分布式文件系统:HDFS的更多相关文章
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 你想了解的分布式文件系统HDFS,看这一篇就够了
1.分布式文件系统 计算机集群结构 分布式文件系统把文件分布存储到多个节点(计算机)上,成千上万的计算机节点构成计算机集群. 分布式文件系统使用的计算机集群,其配置都是由普通硬件构成的,与用多个处理器 ...
- Hadoop 分布式文件系统 - HDFS
当数据集超过一个单独的物理计算机的存储能力时,便有必要将它分不到多个独立的计算机上.管理着跨计算机网络存储的文件系统称为分布式文件系统.Hadoop 的分布式文件系统称为 HDFS,它 是为 以流式数 ...
- 分布式文件系统HDFS体系
系列文件列表: http://os.51cto.com/art/201306/399379.htm 1.介绍 hadoop文件系统(HDFS)是一个运行在普通的硬件之上的分布式文件系统,它和现有的分布 ...
- 分布式文件系统-HDFS
HDFS Hadoop的核心就是HDFS与MapReduce.那么HDFS又是基于GFS的设计理念搞出来的. HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存 ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
随机推荐
- C++ 带有指针成员的类处理方式
在一个类中,如果类没有指针成员,一切方便,因为默认合成的析构函数会自动处理所有的内存.但是如果一个类带了指针成员,那么需要我们自己来写一个析构函数来管理内存.在<<c++ primer&g ...
- iOS最好用的弹出框
重构项目时发现有的时候需要弹出提示,比如登录成功,数据请求失败,还有选择相机或者相册来上传头像等等. 今天就自己写了一个弹出框,采用的是系统的UIAlertController,只不过自己有定义了一些 ...
- [.net 面向对象程序设计深入](26)实战设计模式——使用Ioc模式(控制反转或依赖注入)实现松散耦合设计(1)
[.net 面向对象程序设计深入](26)实战设计模式——使用IoC模式(控制反转或依赖注入)实现松散耦合设计(1) 1,关于IOC模式 先看一些名词含义: IOC: Inversion of con ...
- php线程安全与非线程安全版的区别
Thread Safe(线程安全)和 None Thread Safe(非线程安全) 背景: Linux/Unix系统采用多进程的工作方式,而Windows系统采用多线程的工作方式. CGI模式是建立 ...
- TCP/IP笔记(三)数据链路层
数据链路的作用 数据链路层的协议定义了通过通信媒介互连的设备之间传输的规范.通信媒介包括双绞线电缆.同轴电缆.光纤.电波以及红外线等介质.此外,各个设备之间有时也会通过交换机.网桥.中继器等中转数据. ...
- SQL AlawaysOn 之二:添加组织和域用户
1.在管理工具打开Active Directory 用户和计算机 2.在域控制器名称下面右键 选择 新建--组织单位, 3.输入组织名定,点确定 4.在组织右键--新建--用户 5.输入用户信息,点 ...
- Linux下快速搭建php开发环境
php开发环境快速搭建 一.Linux下快速搭建php开发环境 1.安装XAMPP for Linux XAMPP(Apache+MySQL+PHP+PERL)是一个功能强大的建站集成软件包,使用XA ...
- UNIX基础上
时光飞逝,转眼已经毕业快2年了,觉得自己学的东西多却不精.对此深深的思考一下,觉得有必要连载unix环境编程文章,以此激励自己学习.在此立贴为证,2天一篇博客从零开始阐述unix的环境编程. 参考书籍 ...
- hive 动态分区数设置
当对hive分区未做设置时,报错如下: Caused by: org.apache.hadoop.hive.ql.metadata.HiveFatalException: [Error 20004]: ...
- Android 学习笔记之 个人认为最简单的查看Android源码方案
相信很多人都会疑惑如何使用Eclipse ADT查看源码? 下面我们将介绍 如何查看Android源码. 本文有如下优点: 1.不用费心去找Android源码地址:一个字烦,网上的东西杂七杂八的... ...