第十章:Python の 网络编程基础(二)
本課主題
- Python中的作用域补充
- socketserver 源码
- 线程的介绍和操作实战
- 进程的介绍和操作实战
- 协程的介绍和操作实战
- 本周作业
Python中的作用域补充
- Python世界里沒有块级作用域的:在 Java/C+ 世界里没法打印 name。
# 在 Java/C+ 世界里没法打印 name
# 但在 Python/ JavaScript 世界里可以打印 name
>>> if 1 == 1:
... name = 'Janice'
...
>>> print(name)
JanicePython中无块级作用域(小知识点一)
>>> for i in range(10):
... name = i
...
>>> print(name)
9Python中无块级作用域(小知识点二)
- 但在 Python/ JavaScript 世界里可以打印 name。在 Python 中是以函数作为作用域。
>>> del name
>>> def func():
... name = 'Janice'
...
>>> print(name)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'name' is not definedPython 中是以函数作为作用域(小知识点三)
- Python是有作用域链条,对于作用域来说,在函数没有执行之前,它的作用域已经确定啦,作用域链也已经确定啦
>>> name = 'alex' # 这是 f1()是作用域,它是一个内部的作用域
>>> def f1():
... print(name)
... # 这是 f2()是作用域
>>> def f2():
... name = 'eric'
... f1()
... >>> f2()
alexPython是有作用域链条(小知识点四)
>>> name = 'alex' # 这是 f1()是作用域,它是一个内部的作用域
>>> def f1():
... print(name)
... # 这是 f2()是作用域
>>> def f2():
... name = 'eric'
... return f1
... >>> ret = f2()
>>> ret() # 这相当于运行 f1()
alexPython是有作用域链条(小知识点五)
- For 循环,然后把每一个元素都加1,最后生成一个列表
# 它会执行一个 For 循环,然后把每一个元素都加1,最后生成一个列表 li = [x+1 for x in range(10) if x > 6]
print(li)Python lambda + for 循环(小知识点六)
>>> li2 = [lambda :x for x in range(10)]
>>> ret = li2[0]()
>>> print(ret)
9Python lambda + for 循环(小知识点七)
>>> li = []
>>> for i in range(10):
... def f1(x=i):
... return x
...
... li.append(f1)
...
>>> print(li[0]())
0
>>> print(li[1]())
1
>>> print(li[2]())
2Python lambda + for 循环(小知识点八)
socketserver 源码
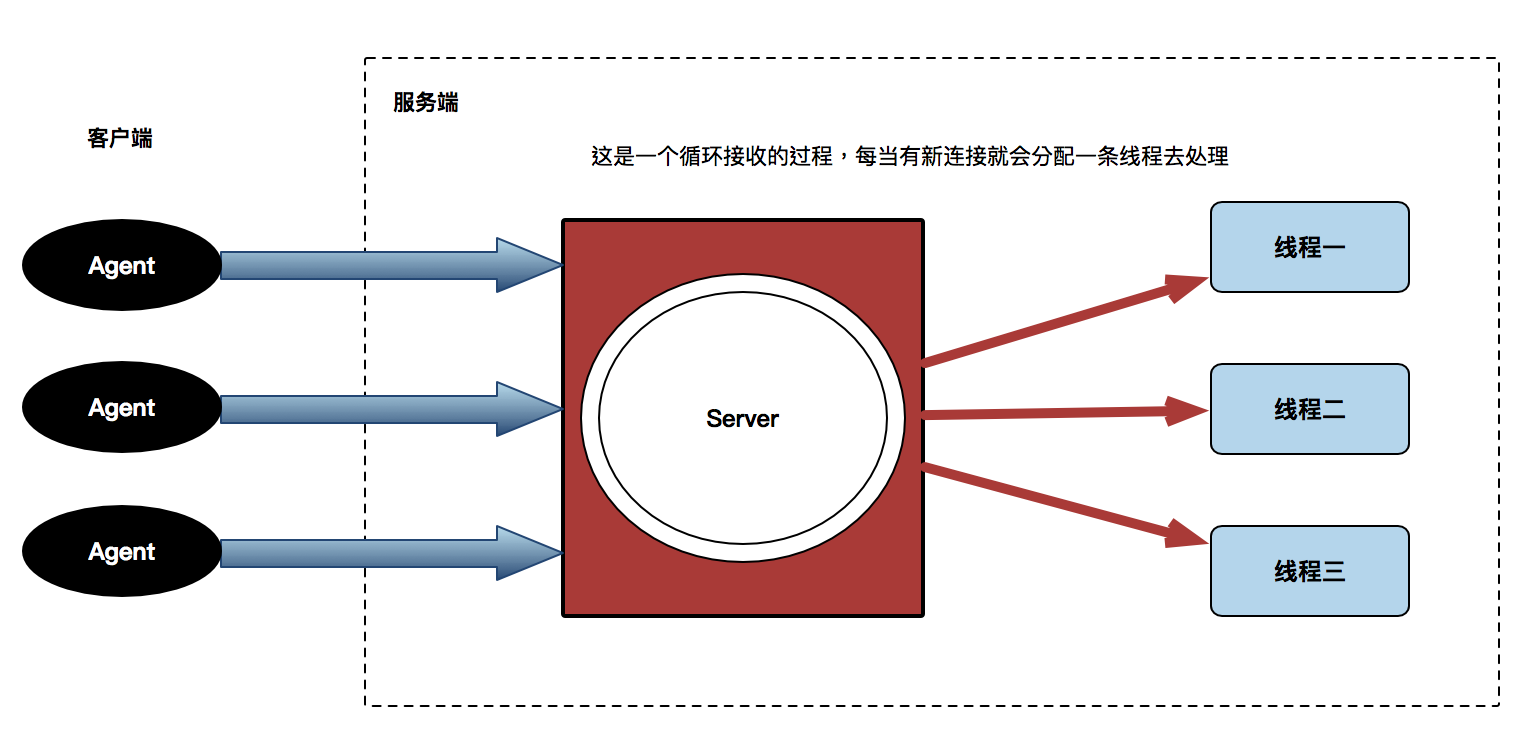
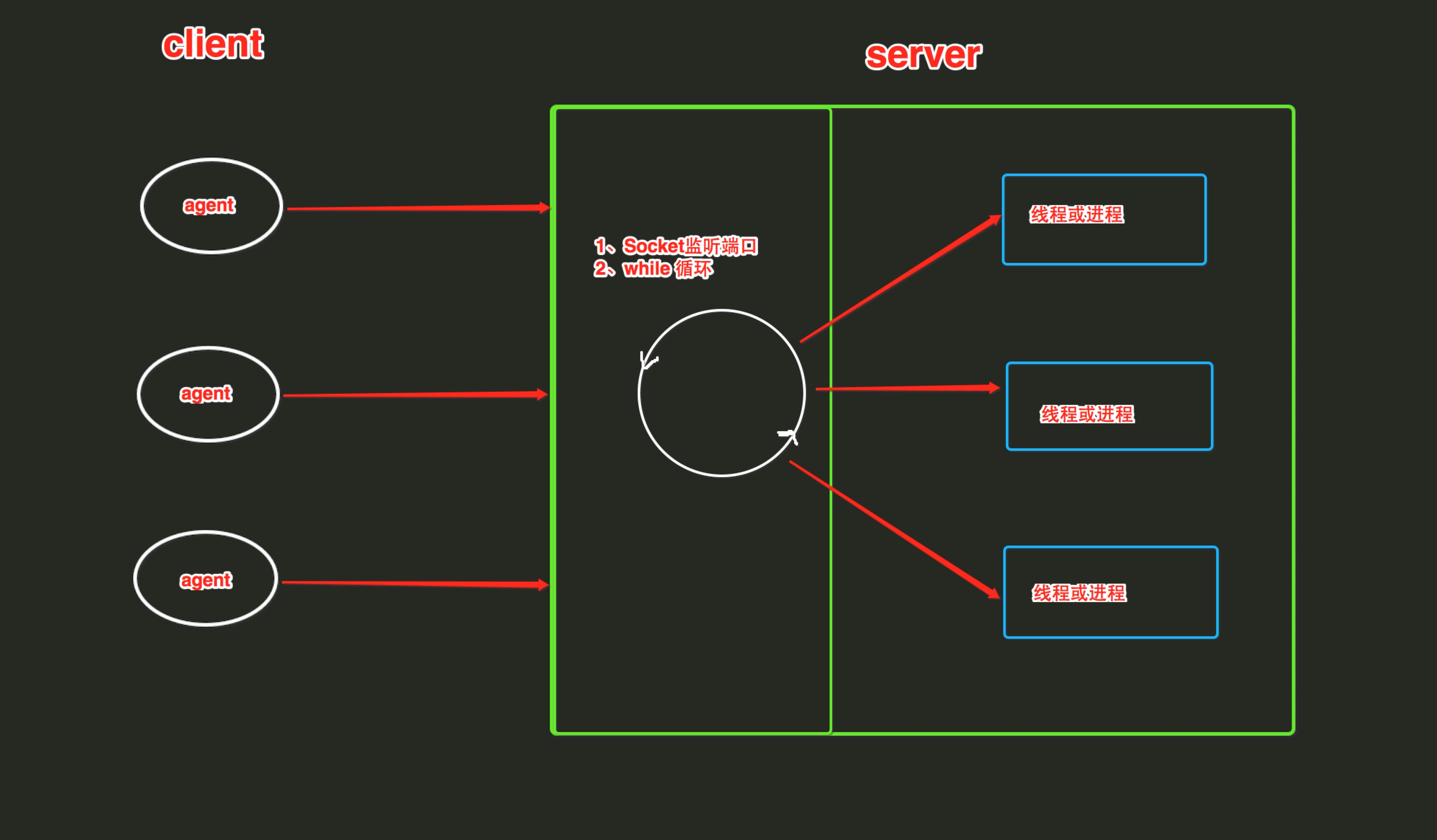{kind=link}
IO操作就是输入输出,其实它不会一直占用 CPU 的,这个IO多路复用目的是在管理IO操作,用来监听socket 对象的内部是否变化了,如果有一个机制可以同时监听多个客户端的连接,就可以实现接受多连接,IO多路复用主要是用 select, poll 和 epoll 来实现这个功能。
Socket内部什么时候会有变化?
当连接或者是收发消息的时候,socket 内部会产生变化,当客户端连接服务器端时,服务器端接收的一刻 e.g. conn, addrs = sk.accept( )。它的 socket 对象就会产生变化,如果服务器端的socket对象发生变化,代表有新连接进来了,然后会创建一个新的 socket 对象。
select 模块
调用 select 模块中的方法来实现IO多路复用
rlist, wlist, e = select.select(inputs,outputs,[],1)
xxxxxx
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import socket
import select #select 中有一个功能就是用来监听socket 对象的内部是否变化了 sk = socket.socket()
sk.bind(("127.0.0.1",8088,))
sk.listen(5) # 这个 input 可以是 sk,或者是接受 message
inputs = [sk,]
outputs = []
message = {}
#message = {
# Janice: [message1, message2]
#} while True:
# 监听 sk(服务器端)对象,如果sk发生变化,表示有客户端来连接了,此时 rlist值为[sk]
# 监听 conn 对象,如果conn发生变化,表示客户端有新消息发送过来了,此时 rlist值为[客户端] # 第一个参数: select会监听sk,判断是否有新连接,有的话就会新增到 rlist,它获取的就是 socket 的对象列表
# 第二个参数: wlist 有所有给我发过消息的人
# 第三个参数: 是一个错误列表
# 第四个参数: 是超时时间 rlist, wlist, elist = select.select(inputs,outputs,[],1) print(len(inputs),len(rlist), len(wlist), len(outputs)) for r in rlist: if r == sk: # 因为只有 sk 才有 sk.accept()方法
# 新客户端来连接
conn, addr = r.accept() # 接受一个客户端的连接
#conn是什么? 其实也是一个 socket 对象
inputs.append(conn) #添加到 inputs 那个列表中 [sk,sk1]
message[conn] = []
conn.sendall(bytes('Hello client-side', encoding='utf-8'))
else:
# 接受消息
# 不是 sk 而且能加入 rlist,就表示有人给我发消息
print("=========") try:
ret = r.recv(1024)
# r.sendall(ret)
if not ret:
raise Exception("断开连接")
else:
outputs.append(r)
message[r].append(ret) except Exception as e: inputs.remove(r)
del message[r] # wlist 有所有给我发过消息的人
for w in wlist:
msg = message[w].pop()
resp = bytes("response: ",encoding = 'utf-8') + msg w.sendall(resp)
outputs.remove(w) sk.close()
IO多路复用(服务器端)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import socket sk=socket.socket()
sk.connect(("127.0.0.1",8088,)) data = sk.recv(1024)
print(data.decode()) while True: inp = input(">>> ") if inp == 'q': break sk.sendall(bytes(inp,encoding='utf-8'))
print(sk.recv(1024)) sk.close()
IO多路复用(客户端)
用到了IO多路复用:监听 socket 内部是否变化,在它连接 conn.accept( ) 或者是收发消息 conn.sendall( )/ conn.recv(1024) 的时候,内部会产生变化
多线程、多进程、协程
rlist 中获取的就是 socket的对象列表
线程的介绍和操作实战
什么是多线程
线程就是程序执行时的基本单位,我们平常写的一些脚本一般都是单线程单进程的应用程序,一个应用程序其实可以创建多条线程,以達到提高程序运行的并发度,就可以有更高的效率。在 Python 世界裡有一個叫全区解释器锁 GIL,如果你要占用 CPU 的话,默应每次只能用一个线程去处理。
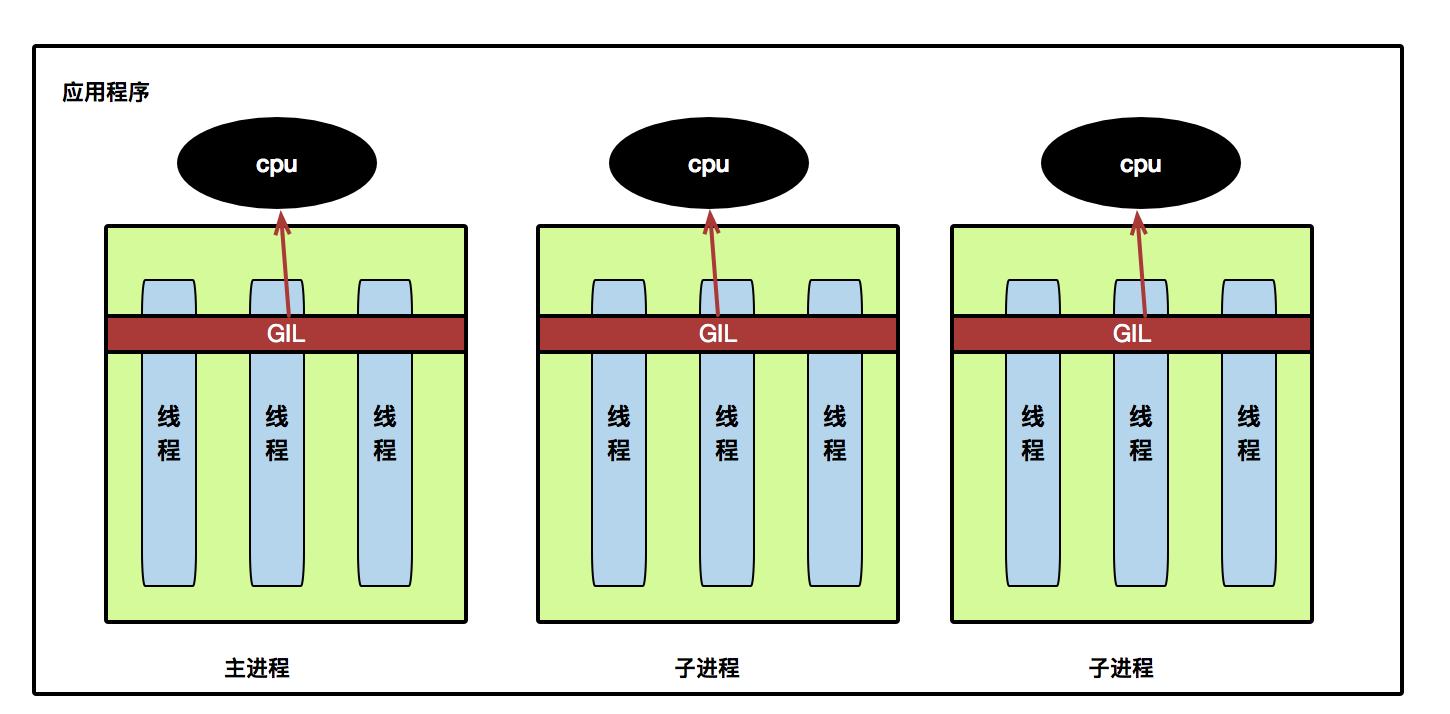
什么情况下用多线程,和多进程会发挥最大的效果?
一个应用程序可以有多线程和多进程,目的在于让CPU 能充份地运用,在Python 里有一个叫GIL,全区解释器锁,如果不用CPU 的话,在Python 就可以实现并发执行,因为IO 操作不占用CPU,一般用多线程;对于计算性操作一些需要占用CPU的,一般会使用多进程来提高并发。
创建线程有两种方法:
- 创建 threading.Thread( ) 方法
t=threading.Thread(target=f1, args=(123,))
t.start()创建线程(方法一)
- 自定义 MyThread,继承者threading.Thread( )
class MyThread(threading.Thread): def __init__(self, target, args):
self.target = target
self.args = args
super(MyThread,self).__init__() def run(self):
self.target(self.args) def f2(args):
print(args) obj = MyThread(target=f2, args=(123,))
obj.start()创建线程(方法二)
线程其他方法:
创建了 t = threading.Thread( )对象之后,可以使用一些方法根据你的逻辑,设计线程的调度。
- t.setDaemon( ):
- t.join(n):
import time def f1():
time.sleep(2)
print('f1') import threading
t = threading.Thread(target=f1) # 创建子线程
t.setDaemon(True) # True 表示主线程不等子线程,直接运行主线程的程序完毕就终止
t.start() t.join() # 它会先等子线程执行完毕,再运下它下面的代码,表不主线程到此等待,直到子线程执行完毕
t.join(2) # 参数表主线程在此最多等待n秒 print('end')
线程(其他小知识)
线程锁
什么是线程锁,线程锁就是锁定程序,当它被处理的时候,去确保只有一个线程在运理程序,这是用来确保数据一致性。有什麼作用呢?
import threading
import time NUM = 10 def func():
global NUM
NUM -= 1 time.sleep(1)
print(NUM) for i in range(10):
t = threading.Thread(target=func)
t.start()
没有线程锁的程序
线程锁有以下几种:
- threading.Lock( ): 同一时刻只有一个线程来操作,它只能有一把锁。
import threading
import time NUM = 10 def func(l):
global NUM
l.acquire() # 上锁
NUM -= 1
time.sleep(1)
print(NUM)
l.release() # 开锁 lock = threading.Lock() # 只能锁一次 for i in range(10):
t = threading.Thread(target=func, args=(lock,))
t.start()线程锁 threading.Lock()
- threading.RLock( ):可以允许多层锁的嵌套。
import threading
import time NUM = 10 def func(l):
global NUM
l.acquire() # 上锁
NUM -= 1
l.acquire() # 上锁 l.release() # 开锁
time.sleep(1)
print(NUM)
l.release() # 开锁 lock = threading.RLock() # 多层锁的嵌套 for i in range(10):
t = threading.Thread(target=func, args=(lock,))
t.start()线程锁 threading.RLock()
- threading.BoundedSemaphore(n):信号量,允许一定数目(n)的线程同时执行
import threading
import time NUM = 10 def func(i, l):
global NUM
l.acquire() # 上锁
NUM -= 1
time.sleep(1)
print(NUM, i)
l.release() # 开锁 lock = threading.BoundedSemaphore(2) # 每次只放 X 個 for i in range(10):
t = threading.Thread(target=func, args=(i, lock,))
t.start()线程锁 threading.BoundedSemaphore(n)
- threading.Event( ):事件,批量将所有线程都挡住,这里要注意3个方法:event.wait( )、event.clear( ) 和 event.set( )
event.wait( ) #检查当前是什么灯,默应是红灯
event.clear() #主动设置成红灯
event.set() #主动设置成绿灯import threading def func(i,e):
print(i)
e.wait() # 检查当前是什么颜色的灯: 如果是红灯,停; 如果是绿灯,行。默应Flag是False 表示是 红灯
print(i + 100) event = threading.Event() for i in range(10):
t = threading.Thread(target=func, args=(i,event))
t.start() event.clear() # 设置成红灯 inp = input(">>> ")
if inp == '':
event.set() # 设置成绿灯线程锁 threading.Event()
- threading.Condition( ):满足自定义条件后,可以放出一条线程。
import threading def func(i, con):
print(i)
con.acquire() #上条件锁
con.wait()
print(i+100)
con.release() #开锁 c = threading.Condition() for i in range(10):
t = threading.Thread(target=func, args=(i,c))
t.start() while True:
inp = input(">>> ") if inp == 'q':
break
else:
c.acquire() #上锁
c.notify(int(inp)) # 放出多少数据
c.release() #开锁线程锁 threading.Condition( )方法一
import threading def condition():
ret = False
r = input(">>> ") if r:
ret = 'True'
else:
ret = 'False' return ret def func(i, con):
print(i)
con.acquire() #上锁
con.wait_for(condition)
print(i+100)
con.release() #开锁 c = threading.Condition() for i in range(10):
t = threading.Thread(target=func, args=(i,c))
t.start()线程锁 threading.Condition( )方法二
- threading.Timer( ):
import threading def hello():
print("hello world") t = threading.Timer(1, hello)
t.start() # 一秒之后 hello world 就会打印出来线程锁 threading.Timer( )
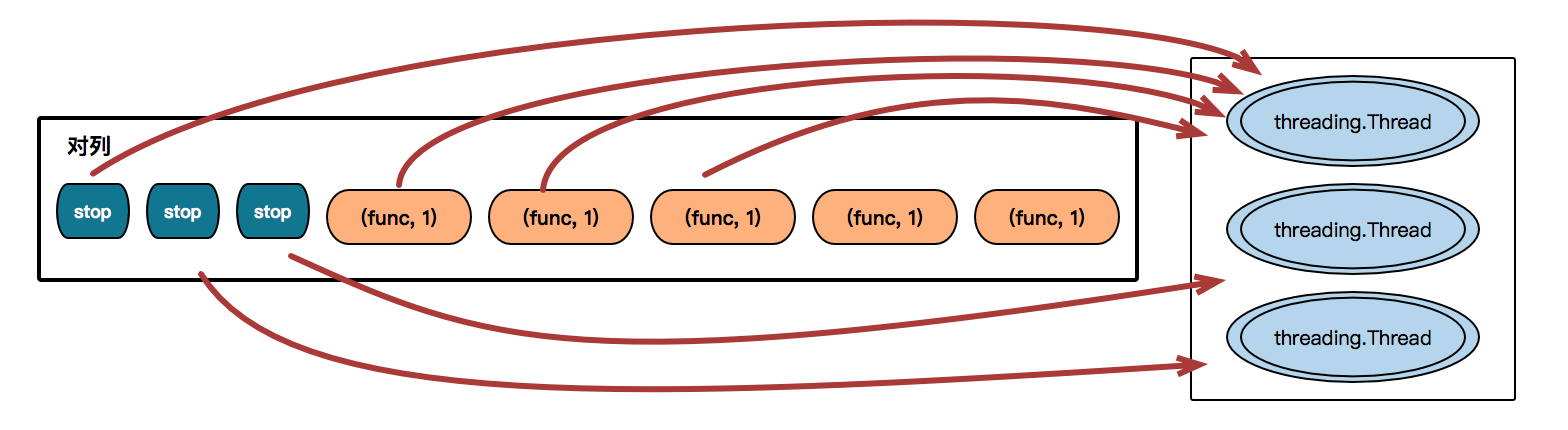
自定义线程池
线程其实不是愈多愈好,必需跟据系统的 CPU 的个数来定的。线程池的概念是需要维护一个池,可以允许特定人数的人来连接,如果已经到达线程池的上限的话,其他的运接就必需等待着,等到有空闲的线程才可以连接,就像排队一样。
什么是线程池,又有什么用呢?
自定义线程池有以下几个元素:
- 一个容器
- 取一个少一个
- 无线程时必须等待
- 线程执行完毕,交还线程
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng import queue
import threading
import time class ThreadPool: def __init__(self, maxsize):
self.maxsize = maxsize
self._q = queue.Queue(maxsize) for i in range(maxsize):
self._q.put(threading.Thread) # 添加threading.Thread的类到消息对列中 def get_thread(self):
return self._q.get() # 获取一个类 def add_thread(self):
self._q.put(threading.Thread) # 新增一个threading.Thread pool = ThreadPool(5)
# 添加5个 threading.Thread 的类
# [threading.Thread,threading.Thread,threading.Thread,threading.Thread,threading.Thread] def task(arg,p):
print(arg)
time.sleep(1)
p.add_thread() # 假设有100个任务
for i in range(100):
# threading.Thread 类
t = pool.get_thread() obj = t(target=task, args=(i,pool,)) #threading.Thread(target=func, args=(i,c))
obj.start()
自定义线程池(低级版本)
#!/usr/bin/env python
# -*- coding:utf-8 -*- import queue
import threading
import contextlib
import time StopEvent = object() class ThreadPool(object): def __init__(self, max_num, max_task_num = None):
if max_task_num:
self.q = queue.Queue(max_task_num)
else:
self.q = queue.Queue()
self.max_num = max_num
self.cancel = False
self.terminal = False
self.generate_list = []
self.free_list = [] def run(self, func, args, callback=None):
"""
线程池执行一个任务
:param func: 任务函数
:param args: 任务函数所需参数
:param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数)
:return: 如果线程池已经终止,则返回True否则None
"""
if self.cancel:
return
if len(self.free_list) == 0 and len(self.generate_list) < self.max_num:
self.generate_thread()
w = (func, args, callback,)
self.q.put(w) def generate_thread(self):
"""
创建一个线程
"""
t = threading.Thread(target=self.call)
t.start() def call(self):
"""
循环去获取任务函数并执行任务函数
"""
current_thread = threading.currentThread()
self.generate_list.append(current_thread) event = self.q.get()
while event != StopEvent: func, arguments, callback = event
try:
result = func(*arguments)
success = True
except Exception as e:
success = False
result = None if callback is not None:
try:
callback(success, result)
except Exception as e:
pass with self.worker_state(self.free_list, current_thread):
if self.terminal:
event = StopEvent
else:
event = self.q.get()
else: self.generate_list.remove(current_thread) def close(self):
"""
执行完所有的任务后,所有线程停止
"""
self.cancel = True
full_size = len(self.generate_list)
while full_size:
self.q.put(StopEvent)
full_size -= 1 def terminate(self):
"""
无论是否还有任务,终止线程
"""
self.terminal = True while self.generate_list:
self.q.put(StopEvent) self.q.queue.clear() @contextlib.contextmanager
def worker_state(self, state_list, worker_thread):
"""
用于记录线程中正在等待的线程数
"""
state_list.append(worker_thread)
try:
yield
finally:
state_list.remove(worker_thread) # How to use pool = ThreadPool(5) def callback(status, result):
# status, execute action status
# result, execute action return value
pass def action(i):
print(i) for i in range(30):
ret = pool.run(action, (i,), callback) time.sleep(5)
print(len(pool.generate_list), len(pool.free_list))
print(len(pool.generate_list), len(pool.free_list))
# pool.close()
# pool.terminate()
自定义线程池(武Sir的高级版本)
进程的介绍和操作实战
GIL 的存在使得 Python 中的多线程无法充分利用多核的优势来提高性能,因而提出了多进程来解决这个问题
每个进程里都有自己的内存空间,而且数据默应是不会共享的
基本使用
进程锁
进程锁跟线程锁也是一样的
from multiprocessing import Process
from multiprocessing import Array
from multiprocessing import RLock,Lock,Event,Condition import time def foo(i,lis, lc):
lc.acquire()
lis[0] = lis[0] - 1
time.sleep(1)
print('say hi',lis[0])
lc.release() if __name__=='__main__': li = Array('i',10)
li[0] = 10
lock = RLock()
for i in range(10):
p = Process(target=foo, args=(i,li,lock,))
p.start()
进程锁
默应数据不共享
如何让进程之间的数据可以共享?
- 对列的方式:queues.Queue
- 数组的方式:Array
from multiprocessing import Process
from multiprocessing import queues
import multiprocessing
from multiprocessing import Array def foo(i,arg):
arg[i] = i + 100
for item in arg:
print(item)
print("=============") if __name__=='__main__': li = Array('i',10) for i in range(10):
p = Process(target=foo, args=(i,li,))
#p.daemon=True
p.start()
#p.join()数组的方式
- 创建对象的方式:Manager( )
进程池
线程的生命周期分为 5 个状态:创建、就绪、运行、阻塞和终止、自线程创建到终止,线程便不断在就绪、运行和阻塞这三个状态之间转换直至销毁。而真正占有 CPU 的只有创建、运行和销毁这3个状态。一个线程的运行时间可以分为3部分
- 线程的启动时间 (Ts)
- 线程体的运行的时间 (Tr)
- 线程的销毁时间 (Td)
在多线程处理的场境下,如果线程不能被重用,就意味著每次创建都需要经过启动、运行和销毁这3个过程,这必然会增加系统的相应时间,降底效率。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Author: Janice Cheng from multiprocessing import Pool
import time def f1(arg):
time.sleep(1)
print(arg) if __name__=='__main__':
pool = Pool(5) # 最多有5个进程的进程池 for i in range(30): # 创建30个任务
# pool.apply(func=f1, args=(i,)) # 到进程池拿一个进程来进行穿形的操作处理数据
pool.apply_async(func=f1, args=(i,)) # pool.close() # 必须等待所有任务执行完毕才会终止程序。
time.sleep(1)
pool.terminate() # 立即终止程序,程序一遇到 terminate()就会立即终止程序。
# pool.join() # 状态必须是CLOSE, TERMINATE,如果不是就会报错。assert self._state in (CLOSE, TERMINATE) print('end')
进程池 Pool
协程的介绍和操作实战
协程的原理是利用一个线程,分解一个线程成为多个微线程,这是程序级别做的,它更适合于 IO操作。
- greenlet
from greenlet import greenlet
# 通过 greenlet 可以控制一下线程,让它先执行一个再执行下一个, def test1():
print('------12-------')
gr2.switch() # 转换并执行一下对象 gr2
print('------34-------')
gr2.switch() # 转换并执行一下对象 gr2 def test2():
print('------56-------')
gr1.switch() # 转换并执行一下对象 gr1
print('------78-------') gr1=greenlet(test1)
gr2=greenlet(test2) gr1.switch() # 转换并执行一下对象 gr1 """
------12-------
------56-------
------34-------
------78-------
"""greenlet例子
- gevent
import gevent def foo():
print("Running foo")
gevent.sleep(0)
print("Explicit context switch to foo again!") def bar():
print("Running bar")
gevent.sleep(0)
print("Explicit context switch back to bar") gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar)
]) """
Running foo
Running bar
Explicit context switch to foo again!
Explicit context switch back to bar
"""gevent例子
- xxxxx
本周作业
day10作业
參考資料
[1] 银角大王:Python之路【第六篇】:socket
[2] 银角大王:Python之路【第七篇】:线程、进程和协程
[3] 银角大王:Python之路 线程池参考例子
[4] 金角大王:
第十章:Python の 网络编程基础(二)的更多相关文章
- Python网络编程基础pdf
Python网络编程基础(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1VGwGtMSZbE0bSZe-MBl6qA 提取码:mert 复制这段内容后打开百度网盘手 ...
- python网络编程基础(线程与进程、并行与并发、同步与异步、阻塞与非阻塞、CPU密集型与IO密集型)
python网络编程基础(线程与进程.并行与并发.同步与异步.阻塞与非阻塞.CPU密集型与IO密集型) 目录 线程与进程 并行与并发 同步与异步 阻塞与非阻塞 CPU密集型与IO密集型 线程与进程 进 ...
- 好书推荐---Python网络编程基础
Python网络编程基础详细的介绍了网络编程的相关知识,结合python,看起来觉得很顺畅!!!
- Python网络编程基础|百度网盘免费下载|零基础入门学习资料
百度网盘免费下载:Python网络编程基础|零基础学习资料 提取码:k7a1 目录: 第1部分 底层网络 第1章 客户/服务器网络介绍 第2章 网络客户端 第3章 网络服务器 第4章 域名系统 第5章 ...
- Python 网络编程(二)
Python 网络编程 上一篇博客介绍了socket的基本概念以及实现了简单的TCP和UDP的客户端.服务器程序,本篇博客主要对socket编程进行更深入的讲解 一.简化版ssh实现 这是一个极其简单 ...
- Python网络编程基础 PDF 完整超清版|网盘链接内附提取码下载|
点此获取下载地址提取码:y9u5 Python网络编程最好新手入门书籍!175个详细案例,事实胜于雄辩,Sockets.DNS.Web Service.FTP.Email.SMTP.POP.IMAP. ...
- 第十三章:Python の 网络编程进阶(二)
本課主題 SQLAlchemy - Core SQLAlchemy - ORM Paramiko 介紹和操作 上下文操作应用 初探堡垒机 SQLAlchemy - Core 连接 URL 通过 cre ...
- python网络编程基础
一.客户端/服务器架构 网络中到处都应有了C/S架构,我们学习socket就是为了完成C/S架构的开发. 二.scoket与网络协议 如果想要实现网络通信我们需要对tcpip,http等很多网络知识有 ...
- 第九章:Python の 网络编程基础(一)
本課主題 何为TCP/IP协议 初认识什么是网络编程 网络编程中的 "粘包" 自定义 MySocket 类 本周作业 何为TCP/IP 协议 TCP/IP协议是主机接入互网以及接入 ...
随机推荐
- UITableView使用过程中可能遇到的问题
前言:记录一些UITableView使用过程中可能遇到的问题 环境:Xcode9 解决UITableViewStyleGrouped类型的TableView的cell距离顶部有距离的问题: table ...
- Java爬虫_资源网站爬取实战
对 http://bestcbooks.com/ 这个网站的书籍进行爬取 (爬取资源分享在结尾) 下面是通过一个URL获得其对应网页源码的方法 传入一个 url 返回其源码 (获得源码后,对源码进 ...
- POJ 2195Going Home(网络流之最小费用流)
题目地址:id=2195">POJ2195 本人职业生涯费用流第一发!!快邀请赛了.决定还是多学点东西.起码碰到简单的网络流要A掉.以后最大流费用流最小割就一块刷. 曾经费用流在我心目 ...
- JAVA入门[20]-Spring Data JPA简单示例
Spring 对 JPA 的支持已经非常强大,开发者只需关心核心业务逻辑的实现代码,无需过多关注 EntityManager 的创建.事务处理等 JPA 相关的处理.Spring Data JPA更是 ...
- M03 利用Accord 进行机器学习的第一个小例子
01 安装 Visual studio 2017. 不具备安装这个的话,也可安装,Microsoft Visual Studio Express (or equivalent) 02 创建 C# 的 ...
- 「mysql优化专题」高可用性、负载均衡的mysql集群解决方案(12)
一.为什么需要mysql集群? 一个庞大的分布式系统的性能瓶颈中,最脆弱的就是连接.连接有两个,一个是客户端与后端的连接,另一个是后端与数据库的连接.简单如图下两个蓝色框框(其实,这张图是我在悟空问答 ...
- JDBC中rs.beforeFirst()
写在前面: 最近的项目比较老,用到了jdbc查询数据,展示数据.有时候一个查询语句的ResultSet需要用到好几次,即需要遍历好几次同一个查询结果集,那要怎么办呢? 使用如下方式即可解决 其实这里理 ...
- DotNetCore跨平台~Moq框架实现模拟测试
回到目录 当我们进行软件开发时,一般会写单元测试,而对于业务情景来说,一般是测试它的业务逻辑准确性,对于你的测试数据是否来自数据库还是文件,是否为真实还是模拟,并不是很关心!我关心的就是我的业务逻辑是 ...
- 【CSS3】渐变
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- ios单独的页面支持横竖屏的状态调整,HTML5加载下(更新2)
单独的页面支持横竖屏的状态调整,HTML5加载下 工程中设置只支持竖屏状态,在加载HTML5的界面可以是横竖屏的,在不对工程其他界面/设置做调整的同时,可以这样去 #import "View ...