Elasticsearch高级搜索排序( 中文+拼音+首字母+简繁转换+特殊符号过滤)
一、先摆需求:
1、中文搜索、英文搜索、中英混搜 如:“南京东路”,“cafe 南京东路店”
2、全拼搜索、首字母搜索、中文+全拼、中文+首字母混搜 如:“nanjingdonglu”,“njdl”,“南京donglu”,“南京dl”,“nang南东路”,“njd路”等等组合
3、简繁搜索、特殊符号过滤搜索 如:“龍馬”可通过“龙马”搜索,再比如 L.G.F可以通过lgf搜索,café可能通过cafe搜索
4、排序优先级为: 以关键字开头>包含关键字
二、生产效果图:
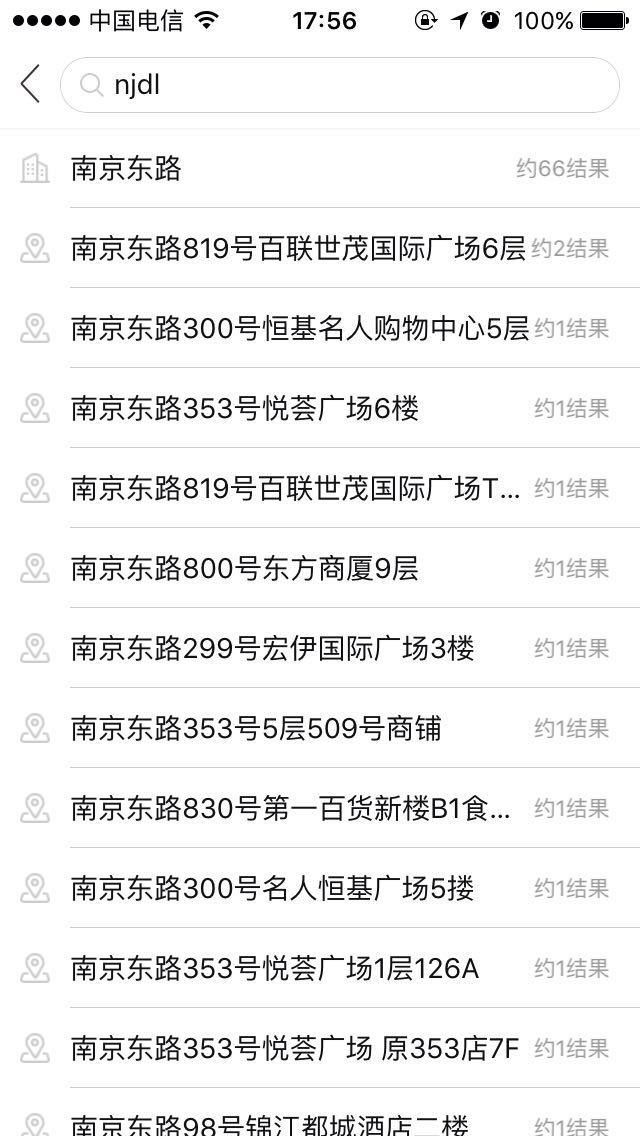
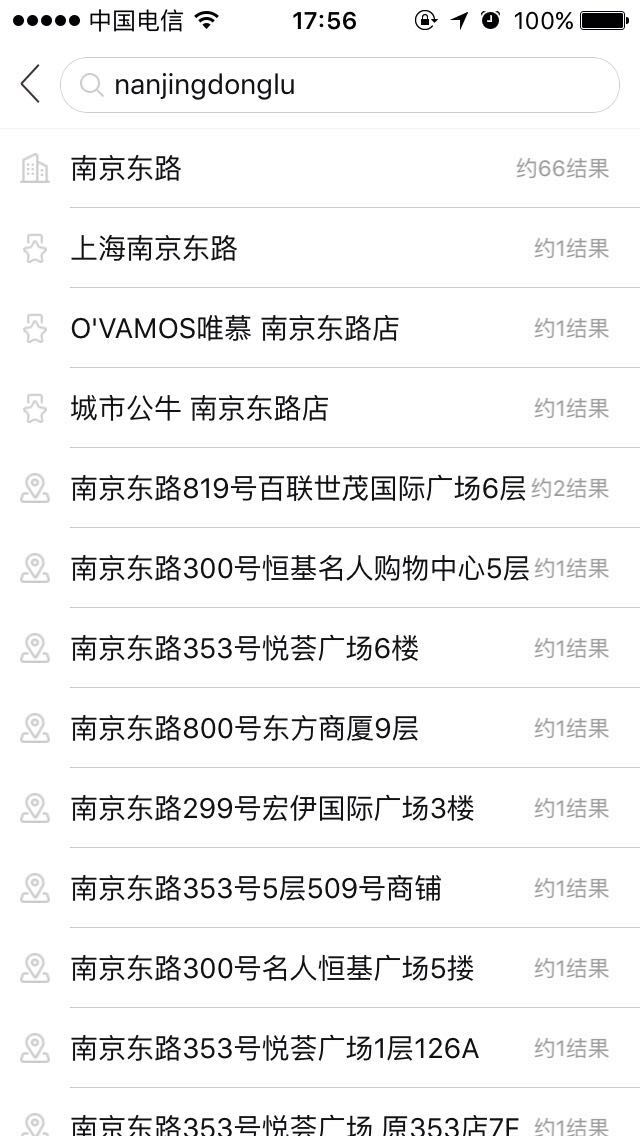
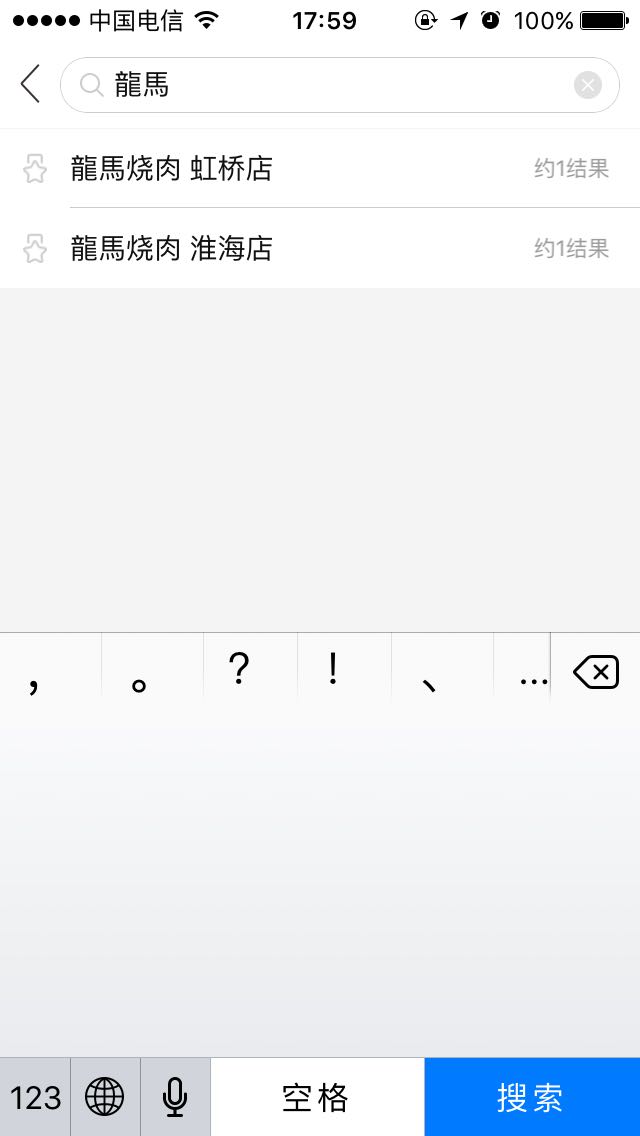

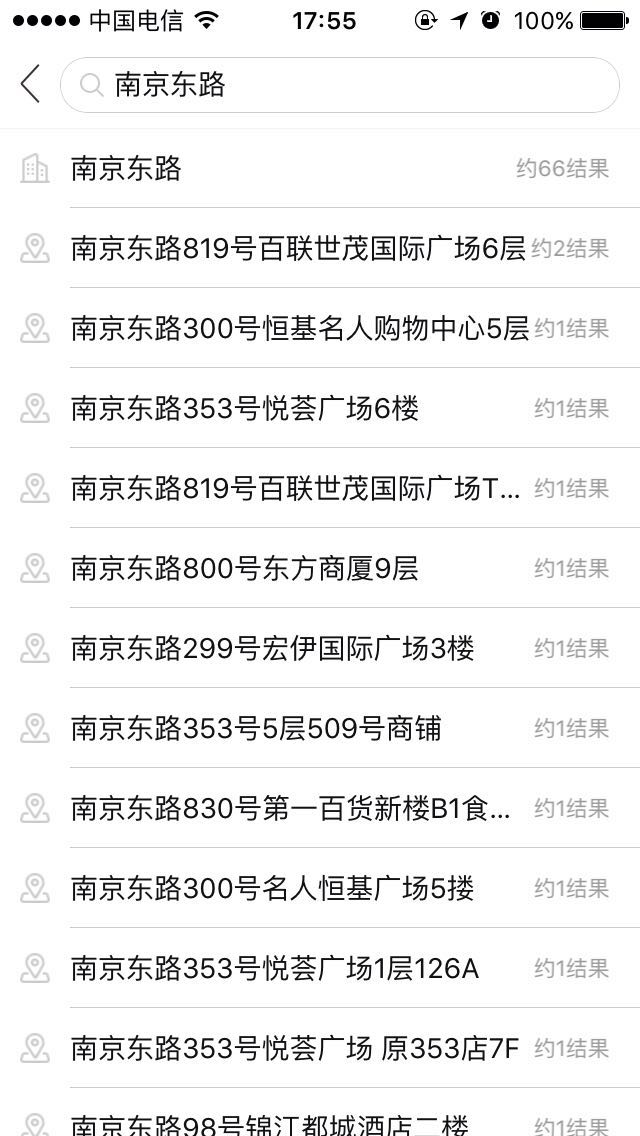

三、实现
1、索引设计
使用multi_field为搜索字段建立不同类型的索引,有全拼索引、首字母简写索引、Ngram索引以及IK索引,从各个角度分别击破,然后通过char-filter进行特殊符号与简繁转换。
curl -XPUT localhost:9200/search_words_index -d '{
"settings" : {
"refresh_interval" : "5s",
"number_of_shards" : 1,
"number_of_replicas" : 1,
"analysis" : {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"pinyin_simple_filter":{
"type" : "pinyin",
"keep_first_letter":true,
"keep_separate_first_letter" : false,
"keep_full_pinyin" : false,
"keep_original" : false,
"limit_first_letter_length" : 50,
"lowercase" : true
},
"pinyin_full_filter":{
"type" : "pinyin",
"keep_first_letter":false,
"keep_separate_first_letter" : false,
"keep_full_pinyin" : true,
"none_chinese_pinyin_tokenize":true,
"keep_original" : false,
"limit_first_letter_length" : 50,
"lowercase" : true
},
"t2s_convert":{
"type": "stconvert",
"delimiter": ",",
"convert_type": "t2s"
}
},
"char_filter" : {
"charconvert" : {
"type" : "mapping",
"mappings_path":"char_filter_text.txt"
}
},
"tokenizer":{
"ik_smart":{
"type":"ik",
"use_smart":true
}
},
"analyzer": {
"ngramIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": ["edge_ngram_filter","lowercase"],
"char_filter" : ["charconvert"]
},
"ngramSearchAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter":["lowercase"],
"char_filter" : ["charconvert"]
},
"ikIndexAnalyzer": {
"type": "custom",
"tokenizer": "ik",
"char_filter" : ["charconvert"]
},
"ikSearchAnalyzer": {
"type": "custom",
"tokenizer": "ik",
"char_filter" : ["charconvert"]
},
"pinyiSimpleIndexAnalyzer":{
"tokenizer" : "keyword",
"filter": ["pinyin_simple_filter","edge_ngram_filter","lowercase"]
},
"pinyiSimpleSearchAnalyzer":{
"tokenizer" : "keyword",
"filter": ["pinyin_simple_filter","lowercase"]
},
"pinyiFullIndexAnalyzer":{
"tokenizer" : "keyword",
"filter": ["pinyin_full_filter","lowercase"]
},
"pinyiFullSearchAnalyzer":{
"tokenizer" : "keyword",
"filter": ["pinyin_full_filter","lowercase"]
}
}
}
},
"mappings": {
"search_words_type": {
"properties": {
"words": {
"type": "multi_field",
"fields":{
"words": {
"type": "string",
"index": "analyzed",
"indexAnalyzer" : "ngramIndexAnalyzer"
},
"SPY": {
"type": "string",
"index": "analyzed",
"indexAnalyzer" : "pinyiSimpleIndexAnalyzer"
},
"FPY": {
"type": "string",
"index": "analyzed",
"indexAnalyzer" : "pinyiFullIndexAnalyzer"
},
"IKS": {
"type": "string",
"index": "analyzed",
"indexAnalyzer" : "ikIndexAnalyzer"
}
}
}
}
}
}
}'
拼音插件的使用请参考:https://github.com/medcl/elasticsearch-analysis-pinyin
2、搜索构建
以下是搜索实现代码(非完整代码,只摘录核心部分,主要是思路):
/**
* 纯中文搜索
* @return
*/
public List<Map> chineseSearch(String key,Integer cityId) throws Exception{
DisMaxQueryBuilder disMaxQueryBuilder=QueryBuilders.disMaxQuery();
//以关键字开头(优先级最高)
MatchQueryBuilder q1=QueryBuilders.matchQuery("words",key).analyzer("ngramSearchAnalyzer").boost(5);
//完整包含经过分析过的关键字
// boolean whitespace=key.contains(" ");
// int slop=whitespace?50:5;
QueryBuilder q2=QueryBuilders.matchQuery("words.IKS", key).analyzer("ikSearchAnalyzer").minimumShouldMatch("100%");
disMaxQueryBuilder.add(q1);
disMaxQueryBuilder.add(q2);
SearchQuery searchQuery=builderQuery(cityId,disMaxQueryBuilder);
return elasticsearchTemplate.queryForList(searchQuery,Map.class);
} /**
* 混合搜索
* @return
*/
public List<Map> chineseWithEnglishOrPinyinSearch(String key,Integer cityId) throws Exception{ DisMaxQueryBuilder disMaxQueryBuilder=QueryBuilders.disMaxQuery();
//是否有中文开头,有则返回中文前缀
String startChineseString=commonSearchService.getStartChineseString(key);
/**
* 源值搜索,不做拼音转换
* 权重* 1.5
*/
QueryBuilder normSearchBuilder=QueryBuilders.matchQuery("words",key).analyzer("ngramSearchAnalyzer").boost(5f); /**
* 拼音简写搜索
* 1、分析key,转换为简写 case: 南京东路==>njdl,南京dl==>njdl,njdl==>njdl
* 2、搜索匹配,必须完整匹配简写词干
* 3、如果有中文前缀,则排序优先
* 权重*1
*/
String analysisKey=commonSearchService.anaysisKeyAndGetMaxWords(SearchIndex.INDEX_NAME_SEARCHWORDSSTATISTICS,key,"pinyiSimpleSearchAnalyzer");
QueryBuilder pingYinSampleQueryBuilder=QueryBuilders.termQuery("words.SPY", analysisKey); /**
* 拼音简写包含匹配,如 njdl可以查出 "城市公牛 南京东路店",虽然非南京东路开头
* 权重*0.8
*/
QueryBuilder pingYinSampleContainQueryBuilder=null;
if(analysisKey.length()>1){
pingYinSampleContainQueryBuilder=QueryBuilders.wildcardQuery("words.SPY", "*"+analysisKey+"*").boost(0.8f);
} /**
* 拼音全拼搜索
* 1、分析key,获取拼音词干 case : 南京东路==>[nan,jing,dong,lu],南京donglu==>[nan,jing,dong,lu]
* 2、搜索查询,必须匹配所有拼音词,如南京东路,则nan,jing,dong,lu四个词干必须完全匹配
* 3、如果有中文前缀,则排序优先
* 权重*1
*/
QueryBuilder pingYinFullQueryBuilder=null;
if(key.length()>1){
pingYinFullQueryBuilder=QueryBuilders.matchPhraseQuery("words.FPY", key).analyzer("pinyiFullSearchAnalyzer");
} /**
* 完整包含关键字查询(优先级最低,只有以上四种方式查询无结果时才考虑)
* 权重*0.8
*/
QueryBuilder containSearchBuilder=QueryBuilders.matchQuery("words.IKS", key).analyzer("ikSearchAnalyzer").minimumShouldMatch("100%"); disMaxQueryBuilder
.add(normSearchBuilder)
.add(pingYinSampleQueryBuilder)
.add(containSearchBuilder); //以下两个对性能有一定的影响,故作此判定,单个字符不执行此类搜索
if(pingYinFullQueryBuilder!=null){
disMaxQueryBuilder.add(pingYinFullQueryBuilder);
}
if(pingYinSampleContainQueryBuilder!=null){
disMaxQueryBuilder.add(pingYinSampleContainQueryBuilder);
} QueryBuilder queryBuilder=disMaxQueryBuilder; //关键如果有中文,则必须包含在内容中
if(StringUtils.isNotBlank(startChineseString)){
queryBuilder= QueryBuilders.filteredQuery(disMaxQueryBuilder,
FilterBuilders.queryFilter(QueryBuilders.queryStringQuery("*"+startChineseString+"*").field("words").analyzer("ngramSearchAnalyzer")));
queryBuilder=QueryBuilders.functionScoreQuery(queryBuilder)
.add(FilterBuilders.queryFilter(QueryBuilders.matchQuery("words",startChineseString).analyzer("ngramSearchAnalyzer")), ScoreFunctionBuilders.weightFactorFunction(1.5f));
} SearchQuery searchQuery=builderQuery(cityId,queryBuilder); return elasticsearchTemplate.queryForList(searchQuery,Map.class);
}
注:以上JAVA示例代码皆以spring-data-elasticsearch框架为基础。
拼音插件安装:
1、下载拼音插件,官网地址:https://github.com/medcl/elasticsearch-analysis-pinyin 我下载的版本是:elasticsearch-analysis-pinyin-1.3.3。
把下载的 elasticsearch-analysis-pinyin-1.3.3.jar与nlp-lang-1.7.jar放于plugins目录下。
2、修改elasticsearch配置文件,在最后一行之下加入(里面包括IK配置,如果未安装IK可省略IK的配置):
index:
analysis:
analyzer:
ik:
alias: [news_analyzer_ik,ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_max_word:
type: ik
use_smart: false
ik_smart:
type: ik
use_smart: true
pinyin:
tokenizer: pinyin_tokenizer
filter: [standard,nGram]
tokenizer:
pinyin_tokenizer:
type: pinyin
first_letter: "prefix"
padding_char: ""
3、定制特殊符号及简繁转换文本:char_filter_text.txt,由于文件有点长,以下是部分内容,参考格式即可。
à=>a
á=>a
â=>a
ä=>a
À=>a
Â=>a
Ä=>a
è=>e
é=>e
ê=>e
ë=>e
È=>e
É=>e
Ê=>e
Ë=>e
î=>i
ï=>i
Î=>i
Ï=>i
ô=>o
ö=>o
Ô=>o
Ö=>o
ù=>u
û=>u
ü=>u
Ù=>u
Û=>u
Ü=>u
ç=>c
œ=>c
&=>
^=>
.=>
·=>
-=>
'=>
’=>
‘=>
/=>
醯壶=>醯壶
屢顧爾僕=>屡顾尔仆
見=>见
往裡=>往里
置言成範=>置言成范
捲動=>卷动
規=>规
齣電視=>出电视
覎=>觃
後堂=>后堂
4、重启elasticsearch,重建索引,看是否生效。
Elasticsearch高级搜索排序( 中文+拼音+首字母+简繁转换+特殊符号过滤)的更多相关文章
- excel 获取中文拼音首字母
excel 获取中文拼音首字母 CreateTime--2018年5月31日08:50:42 Author:Marydon 1.情景展示 想要获取姓名的拼音首字母 2.实现方式 通过使用excel ...
- Js中文排序(拼音首字母)
演示地址:http://lar5.sinaapp.com/ 1.index.html <html xmlns="http://www.w3.org/1999/xhtml"&g ...
- JS获取中文拼音首字母,并通过拼音首字母高速查找页面内的中文内容
实现效果: 图一: 图二: watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdGVzdGNzX2Ru/font/5a6L5L2T/fontsize/400/f ...
- python 获取中文拼音首字母;判断文件夹是否存在
1.如何获取中文字符串的首字母 import pinyin #输入name def get_pinyin_first_alpha(name): return "".join([i[ ...
- java获取中文拼音首字母
import net.sourceforge.pinyin4j.PinyinHelper; public class PinyinHelperUtil { /** * 得到中文首字母(中国 -> ...
- mysql 中文字段排序( 按拼音首字母排序) 的查询语句
在处理使用Mysql时,数据表采用utf8字符集,使用中发现中文不能直接按照拼音排序 如果数据表tbl的某字段name的字符编码是latin1_swedish_ci select * from `tb ...
- Oracle取得中文拼音首字母函数
CREATE ) ; V_RETURN ) ; FUNCTION F_NLSSORT (P_WORD IN VARCHAR2) RETURN VARCHAR2 AS BEGIN RETURN NLSS ...
- 【Solr】 solr对拼音搜索和拼音首字母搜索的支持
问:对于拼音和拼音首字母的支持,当你在搜商品的时候,如果想输入拼音和拼音首字母就给出商品的信息,怎么办呢? 实现方式有2种,但是他们其实是对应的. 用lucene实现 1.建索引, 多建一个索引字段 ...
- C#&Sql获取中文字符拼音首字母的方法
C#获取字符拼音首字母,可以存储在数据库中以备将来按字母搜索的需求. public static string GetAc(string s) { try { string temp = Servic ...
随机推荐
- iOS实现视频和图片的上传
关于iOS如何实现视频和图片的上传, 我们先理清下思路 思路: #1. 如何获取图片? #2. 如何获取视频? #3. 如何把图片存到缓存路径中? #4. 如何把视频存到缓存路径中? #5. 如何上传 ...
- .NET 发布网站步骤
本文章分为三个部分: web网站发布.IIS6 安装方法.ASP.NET v4.0 安装方法 一.web网站发布 1.打开 Visual Studio 2013 编译环境 2.在其解决方案上右击弹出重 ...
- C#:求1到100的和
using System;public class Program { public static void Main() { ...
- 第二期培训(PING问题定位指导)心得
一.什么是 PING DOS 命令,一般用于检测网络通与不通 ,也叫时延,其值越大,速度越慢 PING (Packet Internet Grope),因特网包探索器,用于测试网络连接量的程序.Pin ...
- 1230: [Usaco2008 Nov]lites 开关灯
1230: [Usaco2008 Nov]lites 开关灯 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 1162 Solved: 589[Sub ...
- oracle xe 数据库用户操作
在system账号登录获得system权限,然后对用户进行操作 --创建表空间create tablespace tablespace_name datafile 'D:\tablespace_nam ...
- Zabbix 2.2.x, 3.0.x SQL注射漏洞修复方法
1.漏洞测试 在您的zabbix的地址后面加上如下url: jsrpc.php?type=&method=screen.get×tamp=&pageFile=hist ...
- shell中的readonly
readonly用来定义只读变量,一旦使用readonly定义的变量在脚本中就不能更改 测试脚本 #!/bin/sh readonly a='haha' echo a a='xixi' //更改变量的 ...
- Windbg调试中遇到的问题
1.找不到符号文件 抓取完Dump后,打开WinDbg,Ctrl+D找到刚才抓取的Dump文件,报如下异常: *** ERROR: Symbol file could not be found. De ...
- JIRA6.36-7.23数据迁移文档
JIRA6.3.6-JIRA7.2.3数据迁移文档 安装JIRA7.2.3 安装包位于服务器/opt/SOFTWARE_PACKAGE目录下 建立JIRA安装的目录数据目录 cd /opt mkdir ...