机器学习之二:K-近邻(KNN)算法
一、概述
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
二、原理
基本思路是:如果一个样本在特征空间中的 k 个最相似即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。该方法在分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
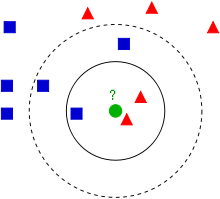
三、优缺点
1、优点:
1)精度高,对异常值不敏感、无数据输入假定;
2)KNN 算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。
3)由于 KNN 方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN 方法较其他方法更为适合。
4)KNN 算法不仅可以用于分类,还可以用于回归。
2、缺点:
1)计算复杂度高:KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
2)空间复杂度高:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
四、注意的问题
1、K的选择
K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,是预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
2、距离衡量
常用的欧氏距离,马氏距离,夹角余弦距离等。
3、分类样本平衡
当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。此时可压缩样本较多的数据类别,或者采用权重系数评判测试点属于哪个类别
五、算法步骤
1)算距离:计算已知类别数据集中的点与当前点之前的距离;
2)找邻居:找出距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻出现频率最高的类别作为测试对象的预测分类
六、示例代码(Python)
from numpy import *
import operator
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]
print 'dataSetSize=',dataSetSize
diffMat = tile(inX,(dataSetSize,1)) - dataSet
print tile(inX,(dataSetSize,1))
print 'diffMat=',diffMat
sqDiffMat = diffMat**2
print 'sqDiffMat=',sqDiffMat
sqDistances = sqDiffMat.sum(axis=1)
print 'sqDistances=',sqDistances
distances = sqDistances**0.5
print 'distances=',distances
sortedDistIndicies = distances.argsort()
print sortedDistIndicies
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
print sortedClassCount
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
group,labels = createDataSet()
print classify0([0,0],group,labels,3)
七、算法行业应用
八、算法的相关改进
KD树,样本压缩技术
九、参考文献
http://www.stanford.edu/~hastie/Papers/dann_IEEE.pdf
机器学习之二:K-近邻(KNN)算法的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- TensorFlow实现knn(k近邻)算法
首先先介绍一下knn的基本原理: KNN是通过计算不同特征值之间的距离进行分类. 整体的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于 ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
随机推荐
- mysql水平分表和垂直分表的优缺点
表分割有两种方式: 1.水平分割:根据一列或多列数据的值把数据行放到两个独立的表中. 水平分割通常在下面的情况下使用. •表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数 ...
- idea启动tomcat报错:Error during artifact deployment. See server log for details.
出现这种情况的原因老夫猜想是改变了artifact然而tomcat的配置中的artifact没有重新配就会出现这种报错 打开tomcat配置 删除原来的artifact 新添加artifact 保存 ...
- angular directive自定义指令
先来看一下自定义指令的写法 app.directive('', ['', function(){ // Runs during compile return { // name: '', // pri ...
- Java平台与.Net平台在服务器端前景预测
如果是服务器端, 毫无疑问C#是很难跟Java拼的. 就算将来,微软逆袭的机会也很渺茫了.就技术的先进性来说, Java平台是不如.Net平台, 但是, 程序员对于两个平台,直接接触的基本以语言为主, ...
- escape()、encodeURI()、encodeURIComponent()区别详解(转)
JavaScript中有三个可以对字符串编码的函数,分别是: escape,encodeURI,encodeURIComponent,相应3个解码函数:unescape,decodeURI,dec ...
- 记录maven 整合SSM框架
一.新建maven项目 建好的项目结构如下图: 还需要做以下配置: 勾选上这两项后,就会自动生成 "src/main/java" 和 "src/main/resour ...
- JavaWeb(二)会话管理之细说cookie与session
前言 前面花了几篇博客介绍了Servlet,讲的非常的详细.这一篇给大家介绍一下cookie和session. 一.会话概述 1.1.什么是会话? 会话可简单理解为:用户开一个浏览器,点击多个超链接, ...
- Easyui后台管理角色权限控制
最近需要做一个粗略的后台管理的权限,根据用户的等级来加载相应的菜单,控制到子菜单.使用的是Easyui这个框架. 1.我使用的mysql数据库.在这里我就建立四张表,角色表(tb_users),菜单表 ...
- 使用jsonp完美解决跨域问题
调用web接口,get请求,发现提示:No 'Access-Control-Allow-Origin' header is present on the requested resource. 这个和 ...
- __无标题栏的窗口拖动___javafx
遇到困难::添加mouseevent监听,我用的mouse_DragedDetected配合MouseEvent.Pressed,,闪的不行,后来借鉴swing的pressed,move,releas ...