hive入门(一)、什么是hive
1、Hive 基本概念
Hive是基于Hadoop的一个 数据仓库工具,可以将结构化的数据文件映射
成一张表,并提供类SQL查询功能;
Hive是构建在Hadoop 之上的数据仓库;
使用HQL作为查询接口;
使用HDFS存储;
使用MapReduce计算;
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapReduce去Hadoop上执行,这样就使得数据开发和分析人员很方便的使用SQL来完成海量数据的统计和分析,而不必使用编程语言开发MapReduce那么麻烦。
2、hive优缺点
优点: 入门简单,避免了去写MapReduce,减少开发人员的学习成本;
统一的元数据管理,可与impala/spark等共享元数据;
灵活性和扩展性比较好:支持UDF,自定义存储格式等;
适合离线数据处理
缺点: Hive的效率比较低,由于hive是基于hadoop,Hadoop本身是一个批处理,高延迟的计算框架
其计算是通过MapReduce来作业,具有高延迟性
Hive适合对非实时的、离线的、对响应及时性要求不高的海量数据批量计算,即查询,统计分析
3、Hive 架构
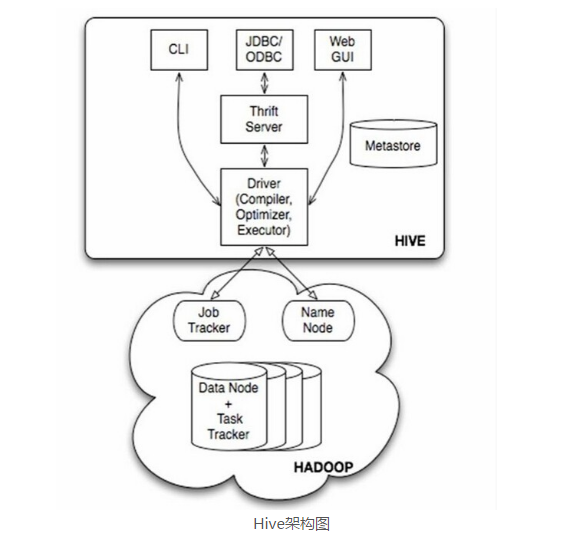
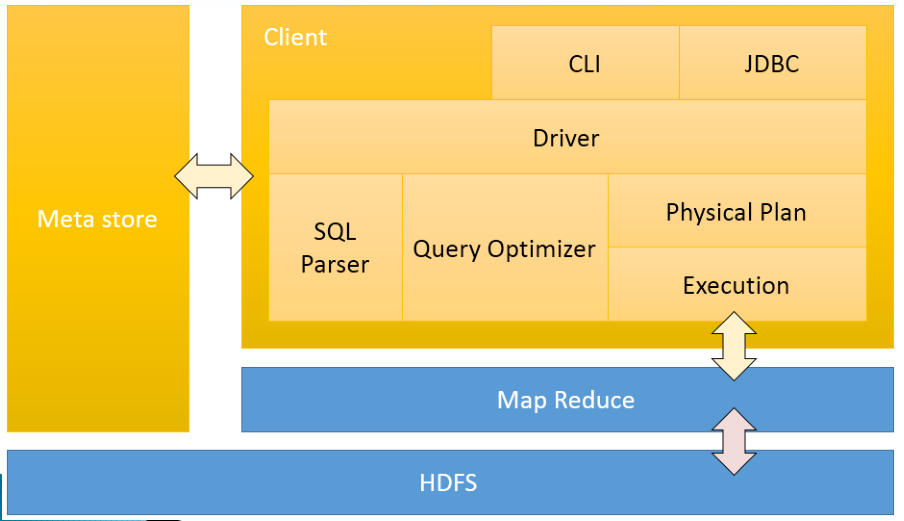
用户接口: Client
CLI(hive shell)、JDBC/ODBC(java访问hive),WEBUI(浏览器访问hive)
元数据: Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/
分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用采用MySQL存储Metastore;
Hadoop
使用HDFS进行存储,使用MapReduce进行计算;

hive入门(一)、什么是hive的更多相关文章
- hadoop笔记之Hive入门(什么是Hive)
Hive入门(一) Hive入门(一) 什么是Hive? Hive是个数据仓库,数据仓库就是数据库,但又与一般意义上的数据库有点区别 实际上,Hive是构建在hadoop HDFS上的一个数据仓库. ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- 4 weekend110的hive入门
查看企业公认的最新稳定版本: https://archive.apache.org/dist/ Hive和HBase都很重要,当然啦,各自也有自己的替代品. 在公司里,SQL有局限,大部 ...
- hadoop笔记之Hive入门(Hive的体系结构)
Hive入门(二) Hive入门(二) Hive的体系结构 ○ Hive的元数据 Hive将元数据存储在数据库中(metastore),支持mysql.derby.oracle等数据库,Hive默认是 ...
- Hive入门学习--HIve简介
现在想要应聘大数据分析或者数据挖掘岗位,很多都需要会使用Hive,Mapreduce,Hadoop等这些大数据分析技术.为了充实自己就先从简单的Hive开始吧.接下来的几篇文章是记录我如何入门学习Hi ...
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- 第1章 Hive入门
第1章 Hive入门 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提 ...
- Hive Tutorial(上)(Hive 入门指导)
用户指导 Hive 指导 Hive指导 概念 Hive是什么 Hive不是什么 获得和开始 数据单元 类型系统 内置操作符和方法 语言性能 用法和例子(在<下>里面) 概念 Hive是什么 ...
- Hive入门学习
Hive学习之路 (一)Hive初识 目录 Hive 简介 什么是Hive 为什么使用 Hive Hive 特点 Hive 和 RDBMS 的对比 Hive的架构 1.用户接口: shell/CLI, ...
随机推荐
- Javascript 方法apply和call的差别
call与aplly都属于Function.prototype的一个方法.所以每一个function实例都有call.apply属性 同样点: call()方法和apply()方法的作用同样: 改变原 ...
- Java web轻量级开发面试教程的前言
本文来是从 java web轻量级开发面试教程从摘录的. 为什么要从诸多的Java书籍里选择这本?为什么在当前网络信息量如此大的情况下还要买这本书,而不是自己通过查阅网络资料学习?我已经会开发Java ...
- java爬虫简单实现
package WebSpider; import java.io.BufferedReader; import java.io.IOException; import java.io.InputSt ...
- 神经网络NN笔记
参考:http://www.cnblogs.com/subconscious/p/5058741.html 俗话说,好记性不如烂笔头~~~~ 边学边记,方便以后查找~~~~~ 一.介绍一下经典的神经网 ...
- 【java】对象变成垃圾被垃圾回收器gc收回前执行的操作:Object类的protected void finalize() throws Throwable
package 对象被回收前执行的操作; class A{ @Override protected void finalize() throws Throwable { System.out.prin ...
- 【批处理】shift用法举例
@echo off set sum=0 call :sub sum 1 2 3 4 echo sum=%sum% pause :sub set /a %1=%1+%2 shift /2 if not ...
- Vue.js(一)了解Vue
什么是Vue? 1.Vue.js是一个构建数据驱动的web界面的库.类似于Angularjs,在技术上,他重点集中在MVVM模式的View层,非常容易学习,非常容易和其他的库或已有的项目整合. 2.V ...
- linux系统下,安装centos7.0系统,配置网卡出现的问题(与centos5.x、centos6.x版本,有差异)
1.新建虚拟机时,自己下载的是centos64系统,选择系统时,默认选择centos,而未选择centos64位,导致犯了一个低级错误,导致后面网卡安装一直有问题 2.查看ip命令与centos5.x ...
- bzoj 1150: [CTSC2007]数据备份Backup
Description 你在一家 IT 公司为大型写字楼或办公楼(offices)的计算机数据做备份.然而数据备份的工作是枯燥乏味 的,因此你想设计一个系统让不同的办公楼彼此之间互相备份,而你则坐在家 ...
- Linux Centos 使用 yum 安装java
centos 使用 yum 安装java 首先,在你的服务器上运行一下更新. yum update 然后,在您的系统上搜索,任何版本的已安装的JDK组件. rpm -qa | grep -E '^op ...