File I/O
File I/O
Introduction
File Descriptors
With FreeBSD 8.0, Linux 3.2.0, Mac OS X 10.6.8, and Solaris 10, the limit is essentially infinite, boundedby the amount of memory on the system, the size of an integer, and any hard and soft limits configured by the system administrator.
open and openat Functions
#include <fcntl.h>
int open(const char *path,int oflag,... /* mode_t mode */ );
int openat(int fd,const char *path,int oflag,... /* mode_t mode */ );
Both return: file descriptor if OK, −1 on error
| O_RDONLY | Open for reading only. |
| O_WRONLY | Open for writing only. |
| O_RDWR | Open for reading and writing. |
Most implementations define O_RDONLY as 0, O_WRONLY as 1, and O_RDWR as 2, for compatibilitywith older programs. |
|
| O_EXEC | Open for execute only. |
| O_SEARCH | Open for search only (applies to directories). |
The purpose of the O_SEARCH constant is to evaluatesearch permissions at the time a directory is opened. Further operations using the directory’s file descriptor will not reevaluate permission to search the directory. None of the versions of the operating systems covered in this book support O_SEARCH yet. |
|
| O_APPEND | Append to the end of file on each write. We describe this option in detail in Section 3.11. |
| O_CLOEXEC | Set the FD_CLOEXEC file descriptor flag. We discuss file descriptor flags in Section 3.14. |
| O_CREAT | Create the file if it doesn’t exist. This option requires a third argument to the open function (a fourth argument to the openat function) — the mode, which specifiesthe access permission bits of the new file. (When we describe a file’s access permission bits in Section 4.5, we’ll see how to specifythe mode and how it can be modified by the umask value of a process.) |
| O_DIRECTORY | Generate an error if path doesn’t refer toa directory. |
| O_EXCL | Generate an error if O_CREAT is also specified and the file already exists. This test for whether the file already exists and the creation of the file if it doesn’t exist is an atomicoperation. We describe atomicoperations in more detail in Section 3.11. |
| O_NOCTTY | If path refers to a terminal device, do not allocate the device as the controlling terminal for this process. We talk about controlling terminals in Section 9.6. |
| O_NOFOLLOW | Generate an error if path refers to a symbolic link. We discuss symbolic links in Section 4.17. |
| O_NONBLOCK | If path refers to a FIFO, a block special file, or a character special file, this option sets the nonblocking mode for both the opening of the file and subsequent I/O. We describe this mode in Section 14.2. |
In earlier releases of System V, the O_NDELAY (no delay) flag was introduced. This option is similar to the O_NONBLOCK (nonblocking) option, but an ambiguitywas introduced in the return value from a read operation. The no-delay option causes a read operation to return 0 if there is no data to be read from a pipe, FIFO, or device, but this conflicts with a return value of 0, indicating an end of file. SVR4-based systems still support the no-delay option, with the old semantics, but new applications should use the nonblocking option instead. |
|
| O_SYNC | Have each write wait for physical I/O to complete, including I/O necessary to update file attributes modified as a result of the write. We use this option in Section 3.14. |
| O_TRUNC | If the file exists and if it is successfully opened for either write-only or read–write, truncateits length to 0. |
| O_TTY_INIT | When opening a terminal device that is not already open, set the nonstandard termios parameters to values that result in behavior that conforms to the Single UNIX Specification. We discuss the termios structure when we discuss terminal I/O in Chapter 18. |
| O_DSYNC | Have each write wait for physical I/O to complete, but don’t wait for file attributes to be updated if they don’t affect the ability to read the data just written. |
The O_DSYNC and O_SYNC flags are similar, but subtlydifferent. The O_DSYNC flag affects a file’s attributes only when they need to be updated to reflect a change in the file’s data (for example, update the file’s size to reflect more data). With the O_SYNC flag, data and attributes are always updated synchronously. When overwriting an existing part of a file opened with the O_DSYNC flag, the file times wouldn’t be updated synchronously. In contrast, if we had opened the file with the O_SYNC flag, every write to the file would update the file’s times before the write returns,regardless of whether we were writing over existing bytes or appending to the file. |
|
| O_RSYNC | Have each read operation on the file descriptor wait until any pending writes for the same portion of the file are complete. |
Solaris 10 supports all three synchronizationflags. Historically, FreeBSD (and thus Mac OS X) have used the O_FSYNC flag, which has the same behavior as O_SYNC. Because the two flags are equivalent, they define the flags to have the same value. FreeBSD 8.0 doesn’t support the O_DSYNC or O_RSYNC flags. Mac OS X doesn’t support the O_RSYNC flag, but defines the O_DSYNC flag, treating it the same as the O_SYNC flag. Linux 3.2.0 supports the O_DSYNC flag, but treats the O_RSYNC flag the same as O_SYNC. |
|
Filename and Pathname Truncation
Whether an error is returned is largely historical. For example, SVR4-based systems do not generate an error for the traditional System V file system, S5. For the BSD-style file system (known as UFS), however, SVR4-based systems do generate an error. Figure 2.20 illustrates another example: Solaris will return an error for UFS, but not for PCFS, the DOS-compatible file system, as DOS silently truncatesfilenames that don’t fit in an 8.3 format. BSD-derived systems and Linux always return an error.
Most modern file systems support a maximum of 255 characters for filenames. Because filenames are usually shorter than this limit, this constraint tends to not present problems for most applications.
creat Function
#include <fcntl.h>
int creat(const char *path,mode_t mode);
Returns: file descriptor opened for write-only if OK, −1 on error
open(path,O_WRONLY | O_CREAT | O_TRUNC, mode);
Historically, in early versions of the UNIX System, the second argument to open could be only 0, 1, or 2. There was no way to open a file that didn’t already exist. Therefore, a separatesystem call, creat, was needed to create new files. With the O_CREAT and O_TRUNC options now provided by open,a separatecreat function is no longer needed.
open(path,O_RDWR | O_CREAT | O_TRUNC, mode);
close Function
#include <unistd.h>
int close(int fd);
Returns: 0 if OK, −1 on error
重定向和管道的命令行简介
重定向
$ ls images/*.png 1>file_list
$ ls images/*.png >file_list
wc -l 0<file_list
wc -l <file_list
sed -e 's/\.png$//g' <file_list >the_list
ls -R /shared >/dev/null 2>errors
管道

ls images/*.png | wc -l
注意:
1)管道命令只处理前一个命令正确输出(standard output),不处理错误输出(standard error)
2)管道命令右边命令,必须能够接收标准输入流(standard input)命令才行
ls images/*.png | sed -e 's/\.png$//g' >the_list
ls images/*.png | sed -e 's/\.png$//g' | less
lseek Function
#include <unistd.h>
off_t lseek(int fd,off_t offset,int whence);
Returns: new file offset if OK, −1 on error
- If whence is SEEK_SET, the file’s offset is set to offset bytes from the beginning of the file.
- If whence is SEEK_CUR, the file’s offset is set to its current value plus the offset. The offset can be positive or negative.
- If whence is SEEK_END, the file’s offset is set to the size of the file plus the offset. The offset can be positive or negative.
off_t currpos;
currpos = lseek(fd, 0, SEEK_CUR);
下列是较特别的使用方式:
欲将读写位置移到文件开头时: lseek(fd, 0, SEEK_SET);
欲将读写位置移到文件尾时: lseek(fd, 0, SEEK_END);
想要取得目前文件位置时: lseek(fd, 0, SEEK_CUR);
The three symbolic constants—SEEK_SET, SEEK_CUR, and SEEK_END—were introduced with System V. Priorto this, whence was specified as 0 (absolute), 1 (relative to the current offset), or 2 (relative to the end of file). Much software still exists with these numbers hard coded.
The character l in the name lseek means ‘‘long integer.’’ Before the introduction of the off_t data type, the offset argument and the return value were long integers. lseek was introduced with Version 7 when long integers were added to C. (Similar functionality was provided in Version 6 by the functions seek and tell.)
Example
/*** 文件名: fileio/seek.c* 内容:用于测试对其标准输入能否设置偏移量* 时间: 2016年 08月 23日 星期二 16:03:00 CST* 作者:firewaywei**/#include"apue.h"intmain(void){if(lseek(STDIN_FILENO,0, SEEK_CUR)==-1){printf("cannot seek\n");}else{printf("seek OK\n");}exit(0);}
$ ./a.out < /etc/passwd
seek OK
$ cat < /etc/passwd | ./a.out
cannot seek
$ ./a.out < /var/spool/cron/FIFO
cannot seek
The /dev/kmem device on FreeBSD for the Intel x86 processor supports negative offsets. Because the offset (off_t) is a signed data type (Figure 2.21), we lose a factor of 2 in the maximum file size. If off_t is a 32-bit integer,the maximum file size is 2^31−1bytes.
Example
/*** 文件名: fileio/hole.c* 内容:用于创建一个具有空洞的文件。* 时间: 2016年 08月 23日 星期二 16:03:00 CST* 作者:firewaywei*/#include"apue.h"#include<fcntl.h>char buf1[]="abcdefghij";char buf2[]="ABCDEFGHIJ";intmain(void){int fd;if((fd = creat("file.hole", FILE_MODE))<0){err_sys("creat error");}/* offset now = 10 */if(write(fd, buf1,10)!=10){err_sys("buf1 write error");}/* offset now = 16384 */if(lseek(fd,16384, SEEK_SET)==-1){err_sys("lseek error");}/* offset now = 16394 */if(write(fd, buf2,10)!=10){err_sys("buf2 write error");}exit(0);}
$ ./hole
$ ll file.hole
-rw-r--r-- 1 fireway fireway 16394 8月 23 16:18 file.hole
fireway:~/study/apue.3e/fileio$ od -c file.hole
0000000 a b c d e f g h i j \0 \0 \0 \0 \0 \0
0000020 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0 \0
*
0040000 A B C D E F G H I J
0040012
$

$ ls -ls file.hole file.nohole // 比较长度
8 -rw-r--r-- 1 fireway fireway 16394 8月 23 16:18 file.hole
20 -rw-r--r-- 1 fireway fireway 16394 8月 23 16:37 file.nohole
| Name of option | Description | name argument |
| _POSIX_V7_ILP32_OFF32 | int, long,pointer,and off_t types are 32 bits. | _SC_V7_ILP32_OFF32 |
| _POSIX_V7_ILP32_OFFBIG | int, long,and pointer types are 32 bits; off_t types are at least 64 bits. | _SC_V7_ILP32_OFFBIG |
| _POSIX_V7_LP64_OFF64 | int types are 32 bits; long,pointer, and off_t types are 64 bits. | _SC_V7_LP64_OFF64 |
| _POSIX_V7_LP64_OFFBIG | int types are at least 32 bits; long, pointer,and off_t types areat least 64 bits. | _SC_V7_LP64_OFFBIG |
Unfortunately, this is one area in which implementations haven’t caught up to the standards. If your system does not match the latest version of the standard, the system might support the option names from the previous version of the Single UNIX Specification: _POSIX_V6_ILP32_OFF32, _POSIX_V6_ILP32_OFFBIG, _POSIX_V6_LP64_OFF64, and _POSIX_V6_LP64_OFFBIG.
Toget around this, applications can set the _FILE_OFFSET_BITS constant to 64 to enable 64-bit offsets. Doing so changes the definition of off_t to be a 64-bit signed integer. Setting _FILE_OFFSET_BITS to 32 enables 32-bit file offsets. Be aware, however, that although all four platforms discussed in this text support both 32-bit and 64-bit file offsets, setting _FILE_OFFSET_BITS is not guaranteed to be portable and might not have the desired effect.
Figure 3.4 summarizes the size in bytes of the off_t data type for the platforms covered in this book when an application doesn’t define _FILE_OFFSET_BITS, as well as the size when an application defines _FILE_OFFSET_BITS to have a value of either 32 or 64.
| Operating system | CPU architecture | _FILE_OFFSET_BITS value | ||
| Undefined | 32 | 64 | ||
| FreeBSD 8.0 | x86 32-bit | 8 | 8 | 8 |
| Linux 3.2.0 | x86 64-bit | 8 | 8 | 8 |
| Mac OS X 10.6.8 | x86 64-bit | 8 | 8 | 8 |
| Solaris 10 | SPARC 64-bit | 8 | 4 | 8 |
read Function
#include <unistd.h>
ssize_t read(int fd,void *buf,size_t nbytes);
Returns: number of bytes read, 0 if end of file, −1 on error
- When reading from a regularfile, if the end of file is reached before the requested number of bytes has been read. For example, if 30 bytes remainuntil the end of file and we try to read 100 bytes, read returns 30. The next time we call read, it will return 0 (end of file).
- When reading from a terminal device. Normally, up to one line is read at a time. (We’ll see how to change this default in Chapter 18.)
- When reading from a network. Bufferingwithin the network may cause less than the requested amount to be returned.
- When reading from a pipe or FIFO. If the pipe contains fewer bytes than requested, read will return only what is available.
- When reading from a record-oriented device. Some record-oriented devices, such as magnetic tape, can return up to a single record at a time.
- When interrupted by a signal and a partialamount of data has already been read. We discuss this further in Section 10.5.
int read(int fd,char *buf,unsigned nbytes);
- First, the second argument was changed from char * to void * to be consistent with ISO C: the type void * is used for genericpointers.
- Next, the return value was required to be a signed integer (ssize_t) to return a positive byte count, 0 (for end of file), or −1(for an error).
- Finally, the third argument historicallyhas been an unsigned integer, to allow a 16-bit implementation to read or write up to 65,534 bytes at a time. With the 1990 POSIX.1 standard, the primitive system data type ssize_t was introducedto provide the signed return value, and the unsigned size_t was used for the third argument. (Recallthe SSIZE_MAX constant from Section 2.5.2.)
write Function
#include <unistd.h>
ssize_t write(int fd,const void *buf,size_t nbytes);
Returns: number of bytes written if OK, −1 on error
I/O Efficiency
/*** 文件名: fileio/mycat.c* 内容:只使用read和write函数复制一个文件.* 时间: 2016年 08月 25日 星期四 11:00:18 CST* 作者:firewaywei* 执行命令:* ./a.out < infile > outfile*/#include"apue.h"#define BUFFSIZE 4096intmain(void){int n;char buf[BUFFSIZE];while((n = read(STDIN_FILENO, buf, BUFFSIZE))>0){if(write(STDOUT_FILENO, buf, n)!= n){err_sys("write error");}}if(n <0){err_sys("read error");}exit(0);}
- It reads from standard input and writes to standard output, assuming that these have been set up by the shell before this program is executed. Indeed, all normal UNIX system shells provide a way to open a file for reading on standard input and to create (or rewrite) a file on standard output. This prevents the program from having to open the input and output files, and allows the user to take advantage of the shell’s I/O redirection facilities.
- The program doesn’t close the input file or output file. Instead, the program uses the feature of the UNIX kernel that closes all open file descriptors in a process when that process terminates.
- This example works for both text files and binary files, since there is no difference between the two to the UNIX kernel.
| BUFFSIZE | User CPU(seconds) | System CPU(seconds) | Clock time(seconds) | Number of loops |
| 1 | 20.03 | 117.50 | 138.73 | 516,581,760 |
| 2 | 9.69 | 58.76 | 68.60 | 258,290,880 |
| 4 | 4.60 | 36.47 | 41.27 | 129,145,440 |
| 8 | 2.47 | 15.44 | 18.38 | 64,572,720 |
| 16 | 1.07 | 7.93 | 9.38 | 32,286,360 |
| 32 | 0.56 | 4.51 | 8.82 | 16,143,180 |
| 64 | 0.34 | 2.72 | 8.66 | 8,071,590 |
| 128 | 0.34 | 1.84 | 8.69 | 4,035,795 |
| 256 | 0.15 | 1.30 | 8.69 | 2,017,898 |
| 512 | 0.09 | 0.95 | 8.63 | 1,008,949 |
| 1,024 | 0.02 | 0.78 | 8.58 | 504,475 |
| 2,048 | 0.04 | 0.66 | 8.68 | 252,238 |
| 4,096 | 0.03 | 0.58 | 8.62 | 126,119 |
| 8,192 | 0.00 | 0.54 | 8.52 | 63,060 |
| 16,384 | 0.01 | 0.56 | 8.69 | 31,530 |
| 32,768 | 0.00 | 0.56 | 8.51 | 15,765 |
| 65,536 | 0.01 | 0.56 | 9.12 | 7,883 |
| 131,072 | 0.00 | 0.58 | 9.08 | 3,942 |
| 262,144 | 0.00 | 0.60 | 8.70 | 1,971 |
| 524,288 | 0.01 | 0.58 | 8.58 | 986 |
/dev/null设备文件只有一个作用,往它里面写任何数据都被直接丢弃。因此保证了该命令执行时屏幕上没有任何输出,既不打印正常信息也不打印错误信息,让命令安静地执行,这种写法在Shell脚本中很常见。
Beware when trying to measure the performance of programs that read and write files. The operating system will try to cache the file incore, so if you measure the performance of the program repeatedly, the successive timings will likely be better than the first. This improvement occurs because the first run causes the file to be entered into the system’s cache, and successive runs access the file from the system’s cache instead of from the disk. (The term incore means in main memory. Back in the day, a computer ’s main memory was built out of ferrite core. This is where the phrase ‘‘core dump’’ comes from: the main memory image of a program stored in a file on disk for diagnosis.)
In the tests reported in Figure 3.6, each run with a different buffer size was made using a different copy of the file so that the current run didn’t find the data in the cache from the previous run. The files are large enough that they all don’t remain in the cache (the test system was configured with 6 GB of RAM).
File Sharing
The following description is conceptual; it may or may not match a particular implementation. Refer to Bach [1986] for a discussion of these structures in System V. McKusick et al. [1996] describe these structures in 4.4BSD. McKusick and Neville-Neil [2005] cover FreeBSD 5.2. For a similar discussion of Solaris, see McDougall and Mauro [2007]. The Linux 2.6 kernel architecture is discussed in Bovet and Cesati [2006].
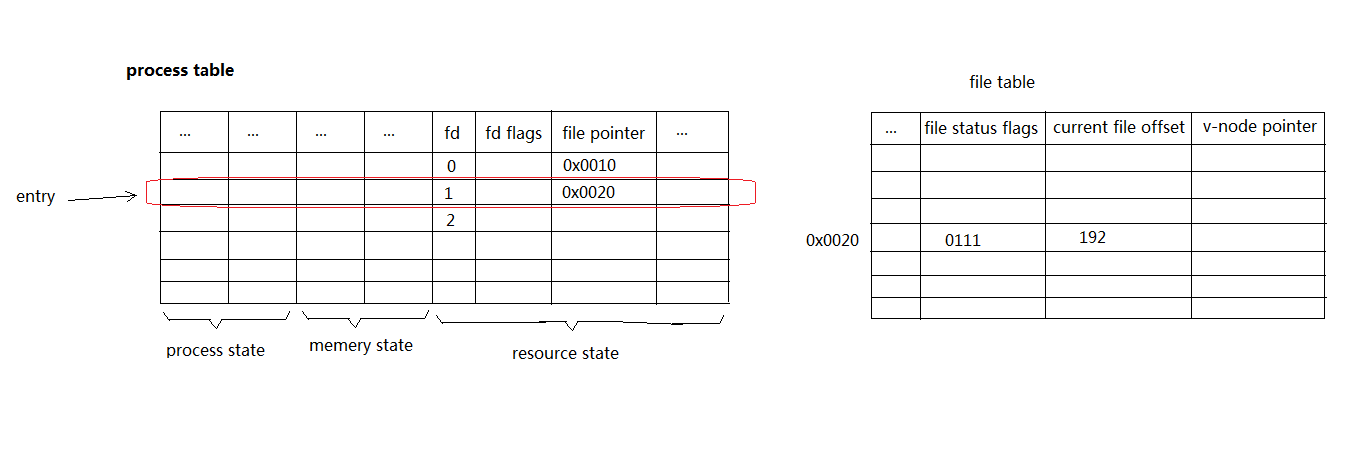
- The file descriptor flags (close-on-exec; refer to Figure 3.7 and Section 3.14)
- A pointer to a file table entry
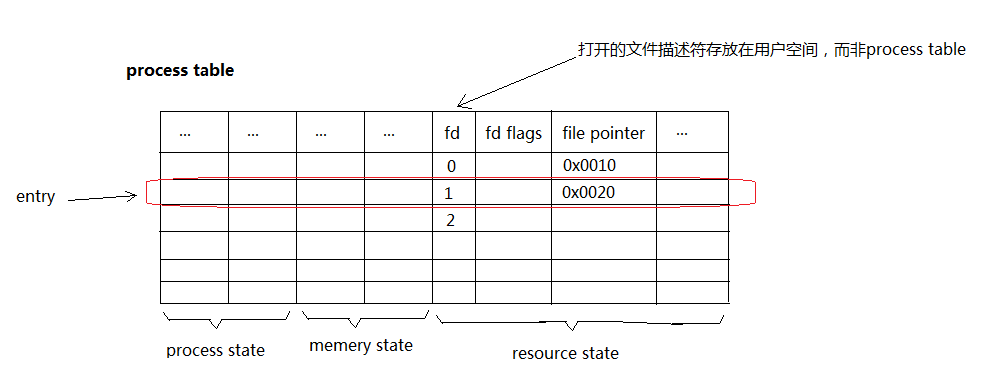
A table containing all of the information that must be saved when the CPU switches from running one process to another in a multitasking system.
The information in the process table allows the suspendedprocess to be restarted at a later time as if it had never been stopped. Every process has an entry in the table. These entries are known as process control blocks and contain the following information:
1) process state - information needed so that the process can be loaded into memory and run, such as the program counter, the stack pointer, and the values of registers.
2) memory state - details of the memory allocation such as pointers to the various memory areas used by the program
3) resource state - information regarding the status of files being used by the process such as user ID.
A process that has died but still has an entry in the process table is called a zombie process.
- The file status flags for the file, such as read, write, append, sync, and nonblocking; more on these in Section 3.14
- The current file offset
- A pointer to the v-node table entry for the file
Linux has no v-node. Instead, a generici-node structure is used. Although the implementations differ, the v-node is conceptuallythe same as a generic i-node. Both point to an i-node structure specificto the file system.
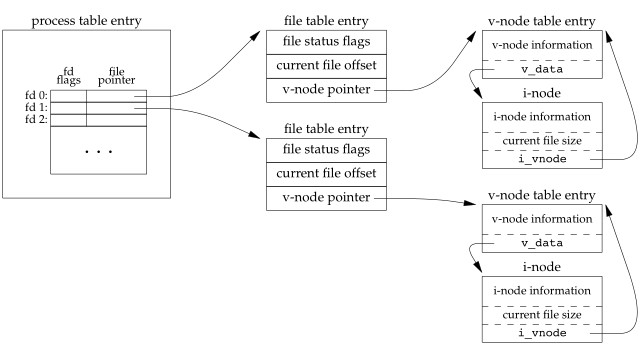
The v-node was invented to provide support for multiple file system types on a single computer system. This work was done independentlyby Peter Weinberger (Bell Laboratories) and Bill Joy (Sun Microsystems). Sun called this the Virtual File System and called the file system–independent portion of the i-node the v-node [Kleiman 1986]. The v-node propagatedthrough various vendor implementations as support for Sun’s Network File System (NFS) was added. The first release from Berkeley to provide v-nodes was the 4.3BSD Reno release, when NFS was added.
In SVR4, the v-node replaced the file system–independent i-node of SVR3. Solaris is derived from SVR4 and, therefore, uses v-nodes.
Instead of splitting the data structures into a v-node and an i-node, Linux uses a file system–independent i-node and a file system–dependent i-node.

- After each write is complete, the current file offset in the file table entry is incremented by the number of bytes written. If this causes the current file offset to exceed the current file size, the current file size in the i-node table entry is set to the current file offset (for example, the file is extended).
- If a file is opened with the O_APPEND flag, a correspondingflag is set in the file status flags of the file table entry. Each time a write is performed for a file with this append flag set, the current file offset in the file table entry is first set to the current file size from the i-node table entry. This forces every write to be appended to the current end of file.
- If a file is positionedto its current end of file using lseek, all that happens is the current file offset in the file table entry is set to the current file size from the i-node table entry. (Note that this is not the same as if the file was opened with the O_APPEND flag, as we will see in Section 3.11.)
- The lseek function modifies only the current file offset in the file table entry. No I/O takes place.
Atomic Operations
Appending to a File
if(lseek(fd,0L,2)<0)/* position to EOF */{err_sys("lseek error");}if(write(fd, buf,100)!=100)/* and write */{err_sys("write error");}
pread and pwrite Functions
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t nbytes, off_t offset);
Returns: number of bytes read, 0 if end of file, −1 on errorssize_t pwrite(int fd, const void *buf, size_t nbytes, off_t offset);
Returns: number of bytes written if OK, −1 on error
- There is no way to interrupt the two operations that occur when we call pread.
- The current file offset is not updated.
Creating a File
if((fd = open(path, O_WRONLY))<0){if(errno == ENOENT){if((fd = creat(path, mode))<0){err_sys("creat error");}}else{err_sys("open error");}}
dup and dup2 Functions
#include <unistd.h>
int dup(int fd);
int dup2(int fd, int fd2);
Both return: new file descriptor if OK, −1 on error

newfd = dup(1);
dup(fd);
fcntl(fd, F_DUPFD, 0);
dup2(fd, fd2);
close(fd2);
fcntl(fd, F_DUPFD, fd2);
- dup2 is an atomicoperation, whereasthe alternateform involvestwo function calls. It is possible in the latter case to have a signal catcher called between the close and the fcntl that could modify the file descriptors. (We describe signals in Chapter 10.) The same problem could occur if a different thread changes the file descriptors. (We describe threads in Chapter 11.)
- There are some errno differences between dup2 and fcntl.
The dup2 system call originatedwith Version 7 and propagatedthrough the BSD releases. The fcntl method for duplicatingfile descriptors appeared with System III and continued with System V. SVR3.2 picked up the dup2 function, and 4.2BSDpicked up the fcntl function and the F_DUPFD functionality. POSIX.1 requires both dup2 and the F_DUPFD feature of fcntl.
sync, fsync, and fdatasync Functions
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
Returns: 0 if OK, −1 on error
void sync(void);
All four of the platforms described in this book support sync and fsync. However, FreeBSD 8.0 does not support fdatasync.
fcntl Function
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* int arg */ );
Returns: depends on cmd if OK (see following), −1 on error
- Duplicatean existing descriptor(cmd = F_DUPFD or F_DUPFD_CLOEXEC)
- Get/set file descriptorflags (cmd = F_GETFD or F_SETFD)
- Get/set file status flags (cmd = F_GETFL or F_SETFL)
- Get/set asynchronousI/O ownership(cmd = F_GETOWN or F_SETOWN)
- Get/set record locks (cmd = F_GETLK, F_SETLK, or F_SETLKW)
| F_DUPFD | Duplicate the file descriptor fd. The new file descriptor is returned as the value of the function. It is the lowest-numbered descriptor that is not already open, and that is greater than or equal to the third argument (taken as an integer). The new descriptor shares the same file table entry as fd. (Refer to Figure 3.9.) But the new descriptor descriptor flags, and its FD_CLOEXEC file descriptor flag is cleared. (This means that the descriptor is left open across an exec, which we discuss in Chapter 8.) |
| F_DUPFD_CLOEXEC | Duplicate the file descriptor and set the FD_CLOEXEC file descriptor flag associated with the new descriptor. Returns the new file descriptor. |
| F_GETFD | Return the file descriptor flags for fd as the value of the function. Currently, only one file descriptor flag is defined: the FD_CLOEXEC flag. |
| F_SETFD | Set the file descriptor flags for fd. The new flag value is set from the third argument (taken as an integer). |
Be aware that some existingprograms that deal with the file descriptor flags don’t use the constant FD_CLOEXEC. Instead, these programs set the flag to either 0 (don’t close-on-exec, the default) or 1 (do close-on-exec). |
|
| F_GETFL | Return the file status flags for fd as the value of the function. We described the file status flags when we described the open function. They are listed inFigure 3.10.
Unfortunately, the five access-mode flags—O_RDONLY, O_WRONLY, O_RDWR, O_EXEC, and O_SEARCH—are not separate bits that can be tested. (As we mentioned earlier, the first three often have the values 0, 1, and 2, respectively, for historicalreasons. Also, these five values are mutually exclusive; a file can have only one of them enabled.) Therefore, we must first use the O_ACCMODE mask to obtain the access-mode bits and then compare the result against any of the five values. |
| F_SETFL | Set the file status flags to the value of the third argument (taken as an integer). The only flags that can be changed are O_APPEND, O_NONBLOCK, O_SYNC, O_DSYNC, O_RSYNC, O_FSYNC, and O_ASYNC. |
| F_GETOWN | Get the process ID or process group ID currently receiving the SIGIO and SIGURG signals. We describe these asynchronousI/O signals in Section 14.5.2. |
| F_SETOWN | Set the process ID or process group ID to receive the SIGIO and SIGURG signals. A positive arg specifiesa process ID. A negative arg implies a process group ID equal to the absolute value of arg. |
| File status flag | Description |
| O_RDONLY | open for reading only |
| O_WRONLY | open for writing only |
| O_RDWR | open for reading and writing |
| O_EXEC | open for execute only |
| O_SEARCH | open directory for searching only |
| O_APPEND | append on each write |
| O_NONBLOCK | nonblocking mode |
| O_SYNC | wait for writes to complete (data and attributes) |
| O_DSYNC | wait for writes to complete (data only) |
| O_RSYNC | synchronize reads and writes |
| O_FSYNC | wait for writes to complete (FreeBSD and Mac OS X only) |
| O_ASYNC | asynchronous I/O (FreeBSD and Mac OS X only) |
Example
/*** 文件名: fileio/fileflags.c* 内容:程序的第1个参数指定文件描述符,并对于该描述符打印其所选择的文件标志说明* 时间: 2016年 08月 28日 星期日 21:24:48 CST* 作者:firewaywei*/#include"apue.h"#include<fcntl.h>intmain(int argc,char*argv[]){int val;if(argc !=2){err_quit("usage: a.out <descriptor#>");}if((val = fcntl(atoi(argv[1]), F_GETFL,0))<0){err_sys("fcntl error for fd %d", atoi(argv[1]));}switch(val & O_ACCMODE){case O_RDONLY:printf("read only");break;case O_WRONLY:printf("write only");break;case O_RDWR:printf("read write");break;default:err_dump("unknown access mode");}if(val & O_APPEND){printf(", append");}if(val & O_NONBLOCK){printf(", nonblocking");}if(val & O_SYNC){printf(", synchronous writes");}#if !defined(_POSIX_C_SOURCE) && defined(O_FSYNC) && (O_FSYNC != O_SYNC)if(val & O_FSYNC){printf(", synchronous writes");}#endifputchar('\n');exit(0);}
$ ./fileflags 0 < /dev/tty
read only
$ ./fileflags 1 > temp.foo
$ cat temp.foo
write only
$ ./fileflags 2 2>>temp.foo
write only, append
$ ./fileflags 5 5<>temp.foo
read write
Example
/*** 文件名: fileio/setfl.c* 内容:对于一个文件描述符设置一个或多个文件状态标志的函数* 时间: 2016年 08月 29日 星期一 13:00:12 CST* 作者:firewaywei*/#include"apue.h"#include<fcntl.h>voidset_fl(int fd,int flags)/* flags are file status flags to turn on */{int val;if((val = fcntl(fd, F_GETFL,0))<0){err_sys("fcntl F_GETFL error");}val |= flags;/* turn on flags */if(fcntl(fd, F_SETFL, val)<0){err_sys("fcntl F_SETFL error");}}
val &= ~falgs; /* turn flags off */
set_fl(STDOUT_FILENO, O_SYNC);
| Operation | User CPU (seconds) | System CPU (seconds) | Clock time (seconds) |
| read time from Figure 3.6 for BUFFSIZE = 4,096 | 0.03 | 0.58 | 8.62 |
| normal write to disk file | 0.00 | 1.05 | 9.70 |
| write to disk file with O_SYNC set | 0.02 | 1.09 | 10.28 |
| write to disk followed by fdatasync | 0.02 | 1.14 | 17.93 |
| write to disk followed by fsync | 0.00 | 1.19 | 18.17 |
| write to disk with O_SYNC set followed by fsync | 0.02 | 1.15 | 17.88 |
| Operation | User CPU (seconds) | System CPU (seconds) | Clock time (seconds) |
| write to /dev/null | 0.14 | 1.02 | 5.28 |
| normal write to disk file | 0.14 | 3.21 | 17.04 |
| write to disk file with O_SYNC set | 0.39 | 16.89 | 60.82 |
| write to disk followed by fsync | 0.13 | 3.07 | 17.10 |
| write to disk with O_SYNC set followed by fsync | 0.39 | 18.18 | 62.39 |
ioctl Function
#include <unistd.h>/* System V */
#include <sys/ioctl.h>/* BSD and Linux */
int ioctl(int fd, int request, ...);
Returns: −1 on error, something else if OK
The ioctl function was included in the Single UNIX Specification only as an extensionfor dealing with STREAMS devices [Rago 1993], but it was moved to obsolescentstatus in SUSv4. UNIX System implementations use ioctl for many miscellaneousdevice operations. Some implementations have even extendedit for use with regular files.
| Category | Constant names |
Header | Number of ioctls |
| disk labels | DIOxxx | <sys/disklabel.h> | 4 |
| file I/O | FIOxxx | <sys/filio.h> | 14 |
| mag tape I/O | MTIOxxx | <sys/mtio.h> | 11 |
| socket I/O | SIOxxx | <sys/sockio.h> | 73 |
| terminal I/O | TIOxxx | <sys/ttycom.h> | 43 |
/dev/fd
The /dev/fd feature was developed by Tom Duff and appeared in the 8th Edition of the Research UNIX System. It is supported by all of the systems described in this book: FreeBSD 8.0, Linux 3.2.0, Mac OS X 10.6.8, and Solaris 10. It is not part of POSIX.1.
fd = open("/dev/fd/0", mode);
fd = dup(0);
fd = open("/dev/fd/0", O_RDWR);
The Linux implementation of /dev/fd is an exception. It maps file descriptors into symboliclinks pointing to the underlyingphysical files. When you open /dev/fd/0, for example, you are really opening the file associatedwith your standard input. Thus the mode of the new file descriptor returned is unrelated to the mode of the /dev/fd file descriptor.
Beware of doing this on Linux. Because the Linux implementation uses symboliclinks to the real files, using creat on a /dev/fd file will result in the underlyingfile being truncated.
filter file2 | cat file1 - file3 | lpr
filter file2 | cat file1 /dev/fd/0 file3 | lpr
Summary
参考
- 《Advanced Programming in the UNIX Envinronment,》Third Edition Chapter 3. File I/O
- 重定向和管道,第 3 章 命令行简介 http://man.chinaunix.net/linux/mandrake/101/zh_cn/Command-Line.html/shell-pipes.html
附件列表
File I/O的更多相关文章
- 记一个mvn奇怪错误: Archive for required library: 'D:/mvn/repos/junit/junit/3.8.1/junit-3.8.1.jar' in project 'xxx' cannot be read or is not a valid ZIP file
我的maven 项目有一个红色感叹号, 而且Problems 存在 errors : Description Resource Path Location Type Archive for requi ...
- HTML中上传与读取图片或文件(input file)----在路上(25)
input file相关知识简例 在此介绍的input file相关知识为: 上传照片及文件,其中包括单次上传.批量上传.删除照片.增加照片.读取图片.对上传的图片或文件的判断,比如限制图片的张数.限 ...
- logstash file输入,无输出原因与解决办法
1.现象 很多同学在用logstash input 为file的时候,经常会出现如下问题:配置文件无误,logstash有时一直停留在等待输入的界面 2.解释 logstash作为日志分析的管道,在实 ...
- input[tyle="file"]样式修改及上传文件名显示
默认的上传样式我们总觉得不太好看,根据需求总想改成和上下结构统一的风格…… 实现方法和思路: 1.在input元素外加a超链接标签 2.给a标签设置按钮样式 3.设置input[type='file' ...
- .NET平台开源项目速览(16)C#写PDF文件类库PDF File Writer介绍
1年前,我在文章:这些.NET开源项目你知道吗?.NET平台开源文档与报表处理组件集合(三)中(第9个项目),给大家推荐了一个开源免费的PDF读写组件 PDFSharp,PDFSharp我2年前就看过 ...
- [笔记]HAproxy reload config file with uninterrupt session
HAProxy is a high performance load balancer. It is very light-weight, and free, making it a great op ...
- VSCode调试go语言出现:exec: "gcc": executable file not found in %PATH%
1.问题描述 由于安装VS15 Preview 5,搞的系统由重新安装一次:在用vscdoe编译go语言时,出现以下问题: # odbcexec: "gcc": executabl ...
- input type='file'上传控件假样式
采用bootstrap框架样式 <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> &l ...
- FILE文件流的中fopen、fread、fseek、fclose的使用
FILE文件流用于对文件的快速操作,主要的操作函数有fopen.fseek.fread.fclose,在对文件结构比较清楚时使用这几个函数会比较快捷的得到文件中具体位置的数据,提取对我们有用的信息,满 ...
- ILJMALL project过程中遇到Fragment嵌套问题:IllegalArgumentException: Binary XML file line #23: Duplicate id
出现场景:当点击"分类"再返回"首页"时,发生error退出 BUG描述:Caused by: java.lang.IllegalArgumentExcep ...
随机推荐
- windows2008(64位)下iis7.5中的url伪静态化重写(urlrewrite)
以前在windows2003里,使用的是iis6.0,那时常使用的URL重写组件是iisrewrite,当服务器升级到windows2008R2时,IIS成了64位的7.5,结果iisreite组件是 ...
- WPF 中模拟键盘和鼠标操作
转载:http://www.cnblogs.com/sixty/archive/2009/08/09/1542210.html 更多经典文章:http://www.qqpjzb.cn/65015.ht ...
- hs_err_pid
hs_err_pid这种文件,是JVM出现错误时dump下来的.记录了错误发生当时: 1)JVM的状态参数 2)Linux的状态参数 就以下面的文件为例: # # There is insuffici ...
- 更新——Canvas画布动画效果之实现倒计时
Hello,大家好! 小W复活啦!继续欢乐的给大家更博,输送新知识~~ 不开玩笑啦!秒进正题~~~ 上次更博,小W给大家介绍了Canvas画布的基础部分,以及实现了一个由7*10点阵图显示的倒计时的基 ...
- topN 算法 以及 逆算法(随笔)
topN 算法 以及 逆算法(随笔) 注解:所谓的 topN 算法指的是 在 海量的数据中进行排序从而活动 前 N 的数据. 这就是所谓的 topN 算法.当然你可以说我就 sort 一下 排序完了直 ...
- PHP windowns安装扩展包
1. php_msgpack.dll php.ini 添加 extension=php_msgpack.dll 下载dll: http://pecl.php.net/package/msgpack ...
- LINUX 笔记-ln 命令
给文件创建软链接 命令:ln -s log2013.log link2013 给文件创建硬链接 命令:ln log2013.log ln2013
- 06-从零玩转JavaWeb-数组在内存当中的存放形式
一.JVM的内存划分 想要了解数组的内存存储,先要了解JVM的整体内存划分,详细参见第04JVM内存详解 二.数组在JVM当中的存储详解 假如我们有如下代码: 上面代码当中,创建数组的过程我们可以把 ...
- mysql密码更改
1.用户修改密码: 方法一:mysqladmin -u用户 -p密码 password '新密码' mysqladmin -uroot -pdefault password 'zhouli.cn' 方 ...
- Angular5.0.0新特性
文章来自官网部分翻译https://blog.angular.io/version-5-0-0-of-angular-now-available-37e414935ced Angular5.0.0版本 ...