Mysql基于GTID复制模式-运维小结 (完整篇)
先来看mysql5.6主从同步操作时遇到的一个报错:
mysql> change master to master_host='192.168.10.59',master_user='repli',master_password='repli@123',master_log_file='mysql-bin.000004',master_log_pos=49224392;
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
产生原因:主从数据库双方都开启了gtid功能(通过命令"show variables like '%gtid%';"查看),gtid功能是mysql5.6版本出来的新特性!
解决办法:
1)方法一: 提前执行下面语句
mysql> change master to master_auto_position=1;
mysql> change master to master_host='192.168.10.59',master_user='repli',master_password='repli@123',master_log_file='mysql-bin.000004',master_log_pos=49224392;
2)方法二: 在change语句后面添加
mysql> change master to master_host='192.168.10.59',master_user='repli',master_password='repli@123',master_port=3306,master_auto_position=1;
一、GTID概念介绍
GTID即全局事务ID (global transaction identifier), 其保证为每一个在主上提交的事务在复制集群中可以生成一个唯一的ID。GTID最初由google实现,官方MySQL在5.6才加入该功能。mysql主从结构在一主一从情况下对于GTID来说就没有优势了,而对于2台主以上的结构优势异常明显,可以在数据不丢失的情况下切换新主。使用GTID需要注意: 在构建主从复制之前,在一台将成为主的实例上进行一些操作(如数据清理等),通过GTID复制,这些在主从成立之前的操作也会被复制到从服务器上,引起复制失败。也就是说通过GTID复制都是从最先开始的事务日志开始,即使这些操作在复制之前执行。比如在server1上执行一些drop、delete的清理操作,接着在server2上执行change的操作,会使得server2也进行server1的清理操作。
GTID实际上是由UUID+TID (即transactionId)组成的。其中UUID(即server_uuid) 产生于auto.conf文件(cat /data/mysql/data/auto.cnf),是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增,所以GTID能够保证每个MySQL实例事务的执行(不会重复执行同一个事务,并且会补全没有执行的事务)。GTID在一组复制中,全局唯一。 下面是一个GTID的具体形式 :
mysql> show master status;
+-----------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-----------+----------+--------------+------------------+-------------------------------------------+
| on.000003 | 187 | | | 7286f791-125d-11e9-9a9c-0050568843f8:1-362|
+-----------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec) GTID:7286f791-125d-11e9-9a9c-0050568843f8:1-362
UUID:7286f791-125d-11e9-9a9c-0050568843f8
transactionId:1-362 在整个复制架构中GTID 是不变化的,即使在多个连环主从中也不会变。 例如:ServerA --->ServerB ---->ServerC
GTID从在ServerA ,ServerB,ServerC 中都是一样的。
了解了GTID的格式,通过UUID可以知道这个事务在哪个实例上提交的。通过GTID可以极方便的进行复制结构上的故障转移,新主设置,这就很好地解决了下面这个图所展现出来的问题。
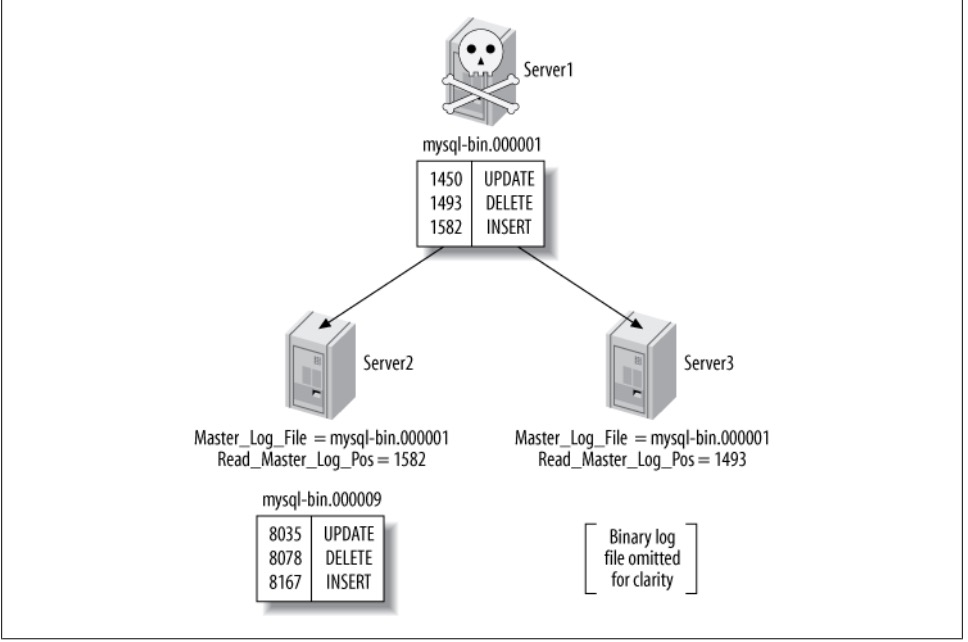
如图, Server1(Master)崩溃,根据从上show slave status获得Master_log_File/Read_Master_Log_Pos的值,Server2(Slave)已经跟上了主,Server3(Slave)没有跟上主。这时要是把Server2提升为主,Server3变成Server2的从。这时在Server3上执行change的时候需要做一些计算。
这个问题在5.6的GTID出现后,就显得非常的简单。由于同一事务的GTID在所有节点上的值一致,那么根据Server3当前停止点的GTID就能定位到Server2上的GTID。甚至由于MASTER_AUTO_POSITION功能的出现,我们都不需要知道GTID的具体值,直接使用CHANGE MASTER TO MASTER_HOST='xxx', MASTER_AUTO_POSITION命令就可以直接完成failover的工作。
====== GTID和Binlog的关系 ======
- GTID在binlog中的结构

- GTID event 结构

- Previous_gtid_log_event
Previous_gtid_log_event 在每个binlog 头部都会有每次binlog rotate的时候存储在binlog头部Previous-GTIDs在binlog中只会存储在这台机器上执行过的所有binlog,不包括手动设置gtid_purged值。换句话说,如果你手动set global gtid_purged=xx; 那么xx是不会记录在Previous_gtid_log_event中的。
- GTID和Binlog之间的关系是怎么对应的呢? 如何才能找到GTID=? 对应的binlog文件呢?
假设有4个binlog: bin.001,bin.002,bin.003,bin.004
bin.001 : Previous-GTIDs=empty; binlog_event有: 1-40
bin.002 : Previous-GTIDs=1-40; binlog_event有: 41-80
bin.003 : Previous-GTIDs=1-80; binlog_event有: 81-120
bin.004 : Previous-GTIDs=1-120; binlog_event有: 121-160
假设现在我们要找GTID=$A,那么MySQL的扫描顺序为:
- 从最后一个binlog开始扫描(即: bin.004)
- bin.004的Previous-GTIDs=1-120,如果$A=140 > Previous-GTIDs,那么肯定在bin.004中
- bin.004的Previous-GTIDs=1-120,如果$A=88 包含在Previous-GTIDs中,那么继续对比上一个binlog文件 bin.003,然后再循环前面2个步骤,直到找到为止.
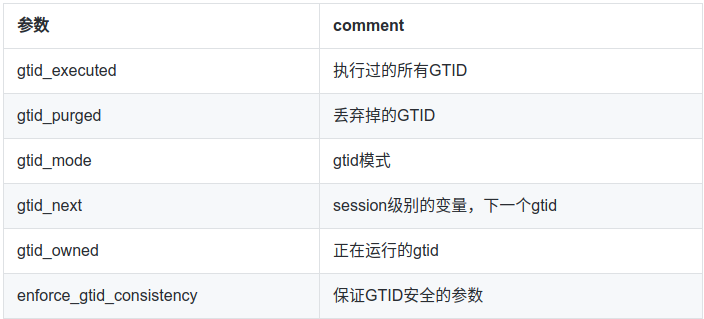
====== GTID 重要参数的持久化 =======
- GTID相关参数
- 重要参数如何持久化
1) 如何持久化gtid_executed (前提是log-bin=mysql-bin, log_slave_update=1 )
gtid_executed = mysql.gtid_executed #正常情况下
或者
gtid_executed = mysql.gtid_executed + last_binlog中最后没写到mysql.gtid_executed中的gtid_event #恢复情况下
2) 如何持久化重置的gtid_purged值?
reset master; set global gtid_purged=$A:a-b; ================================================================================================
1. 由于有可能手动设置过gtid_purged=$A:a-b, binlog.index中,last_binlog的Previous-GTIDs并不会包含$A:a-b
2. 由于有可能手动设置过gtid_purged=$A:a-b, binlog.index中,first_binlog的Previous-GTIDs肯定不会出现$A:a-b
3. 重置的gtid_purged = @@global.gtid_executed(mysql.gtid_executed:注意,考虑到这个表的更新触发条件,所以这里
用@@global.gtid_executed代替) - last_binlog的Previous-GTIDs - last_binlog所有的gtid_event
4. 下面就用 $reset_gtid_purged 来表示重置的gtid
3) 如何持久化gtid_purged (前提是log-bin=mysql-bin, log_slave_update=1 )
gtid_purged=binlog.index:first_binlog的Previous-GTIDs + $reset_gtid_purged
====== 开启GTID的必备条件 ======
- MySQL 5.6 版本,在my.cnf文件中添加:
gtid_mode=on (必选) #开启gtid功能
log_bin=log-bin=mysql-bin (必选) #开启binlog二进制日志功能
log-slave-updates=1 (必选) #也可以将1写为on
enforce-gtid-consistency=1 (必选) #也可以将1写为on
- MySQL 5.7或更高版本,在my.cnf文件中添加:
gtid_mode=on (必选)
enforce-gtid-consistency=1 (必选)
log_bin=mysql-bin (可选) #高可用切换,最好开启该功能
log-slave-updates=1 (可选) #高可用切换,最好打开该功能
====== 新的复制协议 COM_BINLOG_DUMP_GTID ======
- Slave sends to master range of identifiers of executed transactions to master
- Master send all other transactions to slave
- 同样的GTID不能被执行两次,如果有同样的GTID,会自动被skip掉。

slave1 : 将自身的UUID1:1 发送给 master,然后接收到了 UUID1:2,UUID1:3 event
slave2 : 将自身的UUID1:1,UUID1:2 发送给 master,然后接收到了UUID1:3 event
Binlog dump
最开始的时候,MySQL只支持一种binlog dump方式,也就是指定binlog filename + position,向master发送COM_BINLOG_DUMP命令。在发送dump命令的时候,我们可以指定flag为BINLOG_DUMP_NON_BLOCK,这样master在没有可发送的binlog event之后,就会返回一个EOF package。不过通常对于slave来说,一直把连接挂着可能更好,这样能更及时收到新产生的binlog event。在MySQL 5.6之后,支持了另一种dump方式,也就是GTID dump,通过发送COM_BINLOG_DUMP_GTID命令实现,需要带上的是相应的GTID信息.
二、GTID的工作原理
从服务器连接到主服务器之后,把自己执行过的GTID (Executed_Gtid_Set: 即已经执行的事务编码)<SQL线程> 、获取到的GTID (Retrieved_Gtid_Set: 即从库已经接收到主库的事务编号) <IO线程>发给主服务器,主服务器把从服务器缺少的GTID及对应的transactions发过去补全即可。当主服务器挂掉的时候,找出同步最成功的那台从服务器,直接把它提升为主即可。如果硬要指定某一台不是最新的从服务器提升为主, 先change到同步最成功的那台从服务器, 等把GTID全部补全了,就可以把它提升为主了。
GTID是MySQL 5.6的新特性,可简化MySQL的主从切换以及Failover。GTID用于在binlog中唯一标识一个事务。当事务提交时,MySQL Server在写binlog的时候,会先写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID,然后再写事务的Binlog。主从同步时GTID_Event和事务的Binlog都会传递到从库,从库在执行的时候也是用同样的GTID写binlog,这样主从同步以后,就可通过GTID确定从库同步到的位置了。也就是说,无论是级联情况,还是一主多从情况,都可以通过GTID自动找点儿,而无需像之前那样通过File_name和File_position找点儿了。
简而言之,GTID的工作流程为:
- master更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
- slave端的i/o 线程将变更的binlog,写入到本地的relay log中。
- sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录。
- 如果有记录,说明该GTID的事务已经执行,slave会忽略。
- 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog。
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
三、GTID的优缺点
GTID的优点
- 一个事务对应一个唯一ID,一个GTID在一个服务器上只会执行一次;
- GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置;
- 减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机;
GTID复制是怎么实现自动同步,自动对应位置的呢?
比如这样一个主从架构:ServerC <-----ServerA ----> ServerB
即一个主数据库ServerA,两个从数据库ServerB和ServerC
当主机ServerA 挂了之后 ,此时ServerB执行完了所有从ServerA 传过来的事务,ServerC 延时一点。这个时候需要把 ServerB 提升为主机 ,Server C 继续为备机;当ServerC 链接ServerB 之后,首先在自己的二进制文件中找到从ServerA 传过来的最新的GTID,然后将这个GTID 发送到ServerB ,ServerB 获得这个GTID之后,就开始从这个GTID的下一个GTID开始发送事务给ServerC。这种自我寻找复制位置的模式减少事务丢失的可能性以及故障恢复的时间。
GTID的缺点(限制)
- 不支持非事务引擎;
- 不支持create table ... select 语句复制(主库直接报错);(原理: 会生成两个sql, 一个是DDL创建表SQL, 一个是insert into 插入数据的sql; 由于DDL会导致自动提交, 所以这个sql至少需要两个GTID, 但是GTID模式下, 只能给这个sql生成一个GTID)
- 不允许一个SQL同时更新一个事务引擎表和非事务引擎表;
- 在一个复制组中,必须要求统一开启GTID或者是关闭GTID;
- 开启GTID需要重启 (mysql5.7除外);
- 开启GTID后,就不再使用原来的传统复制方式;
- 对于create temporary table 和 drop temporary table语句不支持;
- 不支持sql_slave_skip_counter;
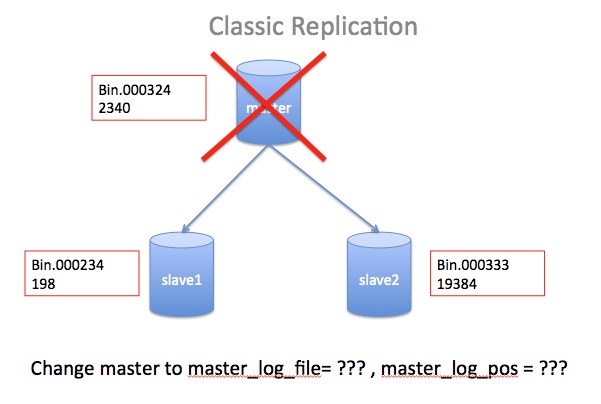
====== 那么到底为什么要用GTID呢?======
1. classic replication [传统复制 , 运维之痛]
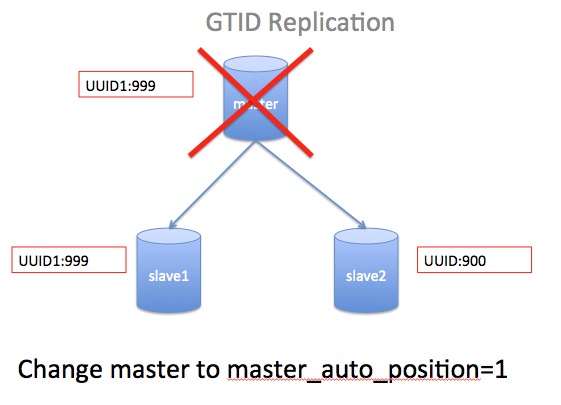
2. GTID replication [GTID复制,很简单]
3. GTID的Limitation (及应对措施)
- 不安全的事务
设置enforce-gtid-consistency=1
- MySQL5.7 GTID crash-safe
1) 单线程复制
Non-GTID 推荐配置:
relay_log_recovery=1
relay_log_info_repository=TABLE
master_info_repository=TABLE GTID 推荐配置
MASTER_AUTO_POSITION=on
relay_log_recovery=0 2) 多线程复制
Non-GTID 推荐配置:
relay_log_recovery=1
sync_relay_log=1
relay_log_info_repository=TABLE
master_info_repository=TABLE GTID 推荐配置:
MASTER_AUTO_POSITION=on
relay_log_recovery=0
====== Mysql开启GTID时,需要注意的问题 ======
- slave不能执行任何sql,包括超级用户;
- read_only=on, slave必须要开启这个,避免业务执行sql;
- 保证当前slave的事务id为1;
当slave同步出现问题时,手动跳过,需要考虑的问题
- 执行的sql,不能记录事务id,否则slave切换为master时,会导致从同步失败,因为binglog早已删除。
- SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
- SET @@SESSION.SQL_LOG_BIN= 0;
需要执行的sql操作:
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;
查看当前数据的uuid
show GLOBAL VARIABLES like 'server_uuid';
查看当前数据库的已执行过的事务
show master status;
手动设置事务id
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
SET @@GLOBAL.GTID_PURGED='132028ab-abc5-11e6-b2f0-000c29a60c3d:1-45679';
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;
另外还需要注意
- 开启GTID以后,无法使用sql_slave_skip_counter跳过事务,因为主库会把从库缺失的GTID,发送给从库,所以skip是没有用的。
- 为了提前发现问题,在gtid模式下,直接禁止使用set global sql_slave_skip_counter =x。正确的做法: 通过set grid_next= 'aaaa'('aaaa'为待跳过的事务),然后执行BIGIN; 接着COMMIT产生一个空事务,占据这个GTID,再START SLAVE,会发现下一条事务的GTID已经执行过,就会跳过这个事务了
- 如果一个GTID已经执行过,再遇到重复的GTID,从库会直接跳过,可看作GTID执行的幂等性。
四、GTID测试解析
1) 复制的测试环境
因为支持GTID,所以5.6多了几个参数:
mysql> show variables like '%gtid%';
+----------------------------------+------------------------------------------+
| Variable_name | Value |
+----------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | d47f31fd-eba4-11e7-af2a-56b1d2e75ff8:1-9 |
| session_track_gtids | OFF |
+----------------------------------+------------------------------------------+
9 rows in set (0.00 sec)
这里简单说下几个常用参数的作用:
gtid_executed
在当前实例上执行过的 GTID 集合,实际上包含了所有记录到 binlog 中的事务。设置 set sql_log_bin=0 后执行的事务不会生成 binlog 事件,也不会被记录到 gtid_executed 中。执行 RESET MASTER 可以将该变量置空。
gtid_purged
binlog 不可能永远驻留在服务上,需要定期进行清理(通过 expire_logs_days 可以控制定期清理间隔),否则迟早它会把磁盘用尽。gtid_purged 用于记录本机上已经执行过,但是已经被清除了的 binlog 事务集合。它是 gtid_executed 的子集。只有 gtid_executed 为空时才能手动设置该变量,此时会同时更新 gtid_executed 为和 gtid_purged 相同的值。
gtid_executed 为空意味着要么之前没有启动过基于 GTID 的复制,要么执行过 RESET MASTER。执行 RESET MASTER 时同样也会把 gtid_purged 置空,即始终保持 gtid_purged 是 gtid_executed 的子集。
gtid_next
会话级变量,指示如何产生下一个GTID。可能的取值如下:
- AUTOMATIC: 自动生成下一个 GTID,实现上是分配一个当前实例上尚未执行过的序号最小的 GTID。
- ANONYMOUS: 设置后执行事务不会产生GTID。
- 显式指定的GTID: 可以指定任意形式合法的 GTID 值,但不能是当前 gtid_executed 中的已经包含的 GTID,否则下次执行事务时会报错。
mysql5.6主从环境的搭建和5.5没有什么区别,唯一需要注意: 开启GTID需要在my.cnf配置文件中启用这三个参数(每个节点上都添加)
#GTID
gtid_mode = on #开启gtid功能
enforce_gtid_consistency = 1 #表示开启gtid的一些安全限制,也可以将1写成on
log_slave_updates = 1 #注意1表示打开该功能,也可以将1写成on
上面任意一个参数任意一个参数不开启则都会报错:
2017-08-09 02:33:57 6512 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 or UPGRADE_STEP_2 requires --log-bin and --log-slave-updates
2017-08-09 02:33:57 6512 [ERROR] Aborting 2017-08-09 02:39:58 9860 [ERROR] --gtid-mode=ON or UPGRADE_STEP_1 requires --enforce-gtid-consistency
2017-08-09 02:39:58 9860 [ERROR] Aborting
这里特意说下"log_slave_updates"这个参数选项,通常slave服务器从master服务器接收到的更新不记入slave的二进制日志。该参数选项告诉slave从服务器将其SQL线程执行的更新记入到slave服务器自己的二进制日志。为了使该选项生效,还必须启动binlog二进制日志功能!!比如:
A01和A02为主主复制,A01和B01为主从复制,在测试的过程中发现了以下问题:
- A01和A02的主主复制是没有问题的(从A01写入数据能同步到A02,从A02写入数据能够同步到A01);
- 主从同步的时候,当从A01写入的时候,数据可以写入到B01;
- 当从A02写入的时候,数据就不能写入到B01; 这个问题产生的原因:log_slave_updates参数的状态为NO
创建mysql三个实例(3306、3307、3308),启动之后,执行change时需要注意
各个实例的uuid:
3306:
mysql> select @@server_uuid;
+--------------------------------------+
| @@server_uuid |
+--------------------------------------+
| 4e659069-3cd8-11e5-9a49-001c4270714e |
+--------------------------------------+ 3307:
mysql> select @@server_uuid;
+--------------------------------------+
| @@server_uuid |
+--------------------------------------+
| 041d0e65-3cde-11e5-9a6e-001c4270714e |
+--------------------------------------+ 3308:
mysql> select @@server_uuid;
+--------------------------------------+
| @@server_uuid |
+--------------------------------------+
| 081ccacf-3ce4-11e5-9a95-001c4270714e |
+--------------------------------------+
使用5.6之前的主从change:
mysql> change master to master_host='127.0.0.1',master_user='rep',master_password='rep',master_log_file='mysql-bin3306.000001',master_log_pos=151
报错:
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.
当使用 MASTER_AUTO_POSITION 参数的时候,MASTER_LOG_FILE,MASTER_LOG_POS参数不能使用。
使用5.6之后的主从change:
mysql> change master to master_host='127.0.0.1',master_user='rep',master_password='rep',master_port=3306,master_auto_position=1;
在执行上面的命令的时候会报错2个warnings,主要的原因是复制账号安全的问题。
从总体上看来,由于要支持GTID,所以不需要手工确定主服务器的MASTER_LOG_FILE及MASTER_LOG_POS。要是不需要GTID则需要指定FILE和POS。在2个从上执行上面命令,到此主从环境搭建完成。GTID的主从完成之后可以通过show processlist查看:
mysql> show processlist\G;
*************************** 1. row ***************************
Id: 38
User: rep
Host: localhost:52321
db: NULL
Command: Binlog Dump GTID #通过GTID复制
Time: 48
State: Master has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
Rows_sent: 0
Rows_examined: 0
2) 测试复制的故障转移
server1(3306)挂了,服务器起不来了。需要把其中的一个从设置为主,另一个设置为其的从库:
server2(3307):
Master_Log_File: mysql-bin3306.000002
Read_Master_Log_Pos: 4156773
Exec_Master_Log_Pos: 4156773
server3(3308):
Master_Log_File: mysql-bin3306.000001
Read_Master_Log_Pos: 83795320
Exec_Master_Log_Pos: 83795320
相比之下server2完成的事务要比server3更接近或则等于server1,现在需要把server3设置为server2的从库。
在MySQL5.6之前,这里的计算会很麻烦,要计算之前主库的log_pos和当前要设置成主库的log_pos,很有可能出错。所以出现了一些高可用性的工具如MHA,MMM等解决问题。
在MySQL5.6之后,很简单的解决了这个难题。因为同一事务的GTID在所有节点上的值一致,那么根据server3当前停止点的GTID就能定位到server2上的GTID,所以直接在server3上执行change即可:
mysql> stop slave;
Query OK, 0 rows affected (0.02 sec) #千万不要执行 reset master,否则会从最先的GTID上开始执行。 mysql> change master to master_host='127.0.0.1',master_user='rep',master_password='rep',master_port=3307,master_auto_position=1; #指定到另一个比较接近主的从上。
Query OK, 0 rows affected, 2 warnings (0.02 sec) mysql> start slave; #成功的切换到新主
Query OK, 0 rows affected (0.03 sec)
主从结构已经变更,server2是Master,server3是Slave。因为不需要计算pos的值,所以通过GTID很简单的解决了这个问题。
3) 跳过复制错误:gtid_next、gtid_purged
① 从服务器跳过一个错误的事务
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin3306.000001
Read_Master_Log_Pos: 38260944
Relay_Log_File: mysqld-relay-bin3307.000002
Relay_Log_Pos: 369
Relay_Master_Log_File: mysql-bin3306.000001
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1008
Last_Error: Error 'Can't drop database 'mablevi'; database doesn't exist' on query. Default database: 'mablevi'. Query: 'drop database mablevi'
Skip_Counter: 0
Exec_Master_Log_Pos: 151
Relay_Log_Space: 38261371
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1008
Last_SQL_Error: Error 'Can't drop database 'mablevi'; database doesn't exist' on query. Default database: 'mablevi'. Query: 'drop database mablevi'
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4e659069-3cd8-11e5-9a49-001c4270714e
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0 #通过在change的时候指定,如:change master to master_delay=600,延迟10分钟同步。
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State:
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp: 150810 23:38:39
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:1-48
Executed_Gtid_Set:
Auto_Position: 1
在MySQL5.6之前,只需要执行:
mysql> set global sql_slave_skip_counter=1;
跳过一个错误的事务,就可以继续进行复制了。但在MySQL5.6之后则不行:
mysql> set global sql_slave_skip_counter=1;
ERROR 1858 (HY000): sql_slave_skip_counter can not be set when the server is running with @@GLOBAL.GTID_MODE = ON. Instead, for each transaction that you want to skip, generate an empty transaction with the same GTID as the transaction
分析:因为是通过GTID来进行复制的,也需要跳过这个事务从而继续复制,这个事务可以到主上的binlog里面查看:因为不知道找哪个GTID上出错,所以也不知道如何跳过哪个GTID。但在show slave status里的信息里可以找到在执行Master里的POS:151
Exec_Master_Log_Pos: 151
的时候报错,所以通过mysqlbinlog找到了GTID:
# at 151
#150810 22:57:45 server id 1 end_log_pos 199 CRC32 0x5e14d88f GTID [commit=yes]
SET @@SESSION.GTID_NEXT= '4e659069-3cd8-11e5-9a49-001c4270714e:1'/*!*/;
找到这个GTID之后执行:必须按照下面顺序执行
mysql> stop slave;
Query OK, 0 rows affected (0.01 sec) mysql> set session gtid_next='4e659069-3cd8-11e5-9a49-001c4270714e:1'; #在session里设置gtid_next,即跳过这个GTID
Query OK, 0 rows affected (0.01 sec) mysql> begin; #开启一个事务
Query OK, 0 rows affected (0.00 sec) mysql> commit;
Query OK, 0 rows affected (0.01 sec) mysql> SET SESSION GTID_NEXT = AUTOMATIC; #把gtid_next设置回来
Query OK, 0 rows affected (0.00 sec) mysql> start slave; #开启复制
Query OK, 0 rows affected (0.01 sec)
查看复制状态:
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin3306.000001
Read_Master_Log_Pos: 38260944
Relay_Log_File: mysqld-relay-bin3307.000003
Relay_Log_Pos: 716
Relay_Master_Log_File: mysql-bin3306.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 38260944
Relay_Log_Space: 38261936
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4e659069-3cd8-11e5-9a49-001c4270714e
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0 #延迟同步
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:1-48
Executed_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:1-48
Auto_Position: 1
在此成功跳过了错误,同步继续。可以通过这个办法来处理复制失败的问题,这里还有个例子(从服务器中跳过一条语句/事务):
mysql > stop slave;
Query OK, 0 ROWS affected (0.05 sec)
mysql > CHANGE master TO MASTER_DELAY=600;
Query OK, 0 ROWS affected (0.27 sec)
mysql > START slave;
Query OK, 0 ROWS affected, 1 warning (0.06 sec) master 原本是正常的, 然后意外地执行了 truncate table: mysql > INSERT INTO t SET title='c';
Query OK, 1 ROW affected (0.03 sec)
mysql > INSERT INTO t SET title='d';
Query OK, 1 ROW affected (0.05 sec) mysql > SHOW master STATUS \G
*************************** 1. ROW ***************************
File: black-bin.000001
POSITION: 2817
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:1-10
1 ROW IN SET (0.00 sec) mysql > TRUNCATE TABLE t;
Query OK, 0 ROWS affected (0.15 sec) mysql > SHOW master STATUS \G
*************************** 1. ROW ***************************
File: black-bin.000001
POSITION: 2948
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:1-11
1 ROW IN SET (0.00 sec) slave有延迟, 虽然已经获取到了gtid及对应的events, 但是并未执行: mysql > SHOW slave STATUS \G
*************************** 1. ROW ***************************
Slave_IO_State: Waiting FOR master TO send event
.......
.......
SQL_Delay: 600
SQL_Remaining_Delay: 565
Slave_SQL_Running_State: Waiting until MASTER_DELAY seconds after master executed event
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:9-11
Executed_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:1-8
Auto_Position: 1
1 ROW IN SET (0.00 sec) 要想办法在slave中跳过 GTID:0c005b76-d3c7-11e2-a27d-274c063b18c4:11, 也就是那条truncate table语句 。
办法就是设置GTID_NEXT,然后提交一个空的事务。 mysql > stop slave;
Query OK, 0 ROWS affected (0.03 sec)
mysql > SET session gtid_next='0c005b76-d3c7-11e2-a27d-274c063b18c4:11';
Query OK, 0 ROWS affected (0.00 sec)
mysql > BEGIN; commit;
Query OK, 0 ROWS affected (0.00 sec)
Query OK, 0 ROWS affected (0.01 sec) mysql >SET SESSION GTID_NEXT = AUTOMATIC;
Query OK, 0 ROWS affected (0.00 sec)
mysql > START slave;
Query OK, 0 ROWS affected, 1 warning (0.07 sec) 查看复制状态
mysql > SHOW slave STATUS \G
*************************** 1. ROW ***************************
Slave_IO_State: Waiting FOR master TO send event
.......
.......
Retrieved_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:9-11
Executed_Gtid_Set: 0c005b76-d3c7-11e2-a27d-274c063b18c4:1-11
Auto_Position: 1
1 ROW IN SET (0.00 sec) mysql > SELECT * FROM t;
+----+-------+
| id | title |
+----+-------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+-------+
4 ROWS IN SET (0.00 sec) 成功跳过 truncate table, 当然此时主从的数据已经不一致了。
注意:通过GTID的复制都是没有指定MASTER_LOG_FILE和MASTER_LOG_POS的,所以通过GTID复制都是从最先开始的事务开始,除非在自己的binlog里面有执行过之前的记录,才会继续后面的执行。
② 要是事务日志被purge,再进行change
mysql> show master logs;
+----------------------+-----------+
| Log_name | File_size |
+----------------------+-----------+
| mysql-bin3306.000001 | 38260944 |
+----------------------+-----------+
1 row in set (0.00 sec) mysql> flush logs;
Query OK, 0 rows affected (0.03 sec) mysql> show tables;
+---------------+
| Tables_in_mmm |
+---------------+
| patent_family |
| t1 |
| t2 |
+---------------+
3 rows in set (0.01 sec) mysql> create table t3(id int)engine = tokudb;
Query OK, 0 rows affected (0.02 sec) mysql> insert into t3 values(3),(4);
Query OK, 2 rows affected (0.05 sec)
Records: 2 Duplicates: 0 Warnings: 0 mysql> flush logs;
Query OK, 0 rows affected (0.02 sec) mysql> create table ttt(id int)engine = tokudb;
Query OK, 0 rows affected (0.02 sec) mysql> insert into ttt values(1),(2),(3),(4),(5);
Query OK, 5 rows affected (0.03 sec)
Records: 5 Duplicates: 0 Warnings: 0 mysql> show master logs;
+----------------------+-----------+
| Log_name | File_size |
+----------------------+-----------+
| mysql-bin3306.000001 | 38260995 |
| mysql-bin3306.000002 | 656 |
| mysql-bin3306.000003 | 619 |
+----------------------+-----------+
3 rows in set (0.00 sec) mysql> purge binary logs to 'mysql-bin3306.000003'; #日志被purge
Query OK, 0 rows affected (0.02 sec) mysql> show master logs; #日志被purge之后等下的binlog
+----------------------+-----------+
| Log_name | File_size |
+----------------------+-----------+
| mysql-bin3306.000003 | 619 |
+----------------------+-------- 3308登陆之后执行: mysql> change master to master_host='127.0.0.1',master_user='rep',master_password='rep',master_port=3306,master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.04 sec) mysql> start slave;
Query OK, 0 rows affected (0.02 sec) mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State:
Master_Host: 127.0.0.1
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: mysqld-relay-bin3308.000001
Relay_Log_Pos: 4
Relay_Master_Log_File:
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 0
Relay_Log_Space: 151
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4e659069-3cd8-11e5-9a49-001c4270714e
Master_Info_File: /var/lib/mysql3/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 150811 00:02:50
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 1
报错:
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
这里需要解决的是:Slave如何跳过purge的部分,而不是在最先开始的事务执行。
在主上执行,查看被purge的GTID:
mysql> show global variables like 'gtid_purged';
+---------------+-------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------+
| gtid_purged | 4e659069-3cd8-11e5-9a49-001c4270714e:1-50 |
+---------------+-------------------------------------------+
1 row in set (0.00 sec) 在从上执行,跳过这个GTID:
mysql> stop slave;
Query OK, 0 rows affected (0.00 sec) mysql> set global gtid_purged = '4e659069-3cd8-11e5-9a49-001c4270714e:1-50';
Query OK, 0 rows affected (0.02 sec) mysql> reset master;
Query OK, 0 rows affected (0.04 sec) mysql> start slave;
Query OK, 0 rows affected (0.01 sec) 要是出现:
ERROR 1840 (HY000): @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
则需要执行:
mysql> reset master;
到这从的同步就正常了。
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin3306.000003
Read_Master_Log_Pos: 619
Relay_Log_File: mysqld-relay-bin3308.000002
Relay_Log_Pos: 797
Relay_Master_Log_File: mysql-bin3306.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 619
Relay_Log_Space: 1006
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4e659069-3cd8-11e5-9a49-001c4270714e
Master_Info_File: /var/lib/mysql3/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:51-52
Executed_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:1-52
Auto_Position: 1
1 row in set (0.00 sec) mysql> use mmm
Database changed
mysql> show tables;
+---------------+
| Tables_in_mmm |
+---------------+
| ttt |
+---------------+
1 row in set (0.00 sec)
③ 通过另一个从库恢复从库数据
比如一台从库误操作,数据丢失了,可以通过另一个从库来进行恢复:
slave2(3308):
mysql> use mmm
Database changed
mysql> show tables;
+---------------+
| Tables_in_mmm |
+---------------+
| patent_family |
| t |
| tt |
+---------------+
3 rows in set (0.00 sec) mysql> truncate table tt; #误操作,把记录删除了
Query OK, 0 rows affected (0.02 sec) mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 127.0.0.1
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin3306.000001
Read_Master_Log_Pos: 38260553
Relay_Log_File: mysqld-relay-bin3308.000002
Relay_Log_Pos: 38260771
Relay_Master_Log_File: mysql-bin3306.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 38260553
Relay_Log_Space: 38260980
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 4e659069-3cd8-11e5-9a49-001c4270714e
Master_Info_File: /var/lib/mysql3/master.info
SQL_Delay: 0 #延迟同步
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 4e659069-3cd8-11e5-9a49-001c4270714e:1-46
Executed_Gtid_Set: 081ccacf-3ce4-11e5-9a95-001c4270714e:1, #多出了一个GTID(本身实例执行的事务)
4e659069-3cd8-11e5-9a49-001c4270714e:1-46
Auto_Position: 1 数据被误删除之后,最好停止复制:stop slave; 恢复数据从slave1(3307)上备份数据,并还原到slave2(3308)中。
备份:
mysqldump -uzjy -p123456 -h127.0.0.1 -P3307 --default-character-set=utf8 --set-gtid-purged=ON -B mmm > mmm1.sql 在还原到slave2的时候需要在slave2上执行:reset master; 不然会报错:
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty. 还原:
root@zjy:~# mysql -uzjy -p123456 -h127.0.0.1 -P3308 --default-character-set=utf8 < mmm.sql 开启同步:
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.03 sec) 这时候你会发现误删除的数据已经被还原,并且复制也正常。因为根据GTID的原理,通过slave1的备份直接可以和Master进行同步。
这里备份注意的一点是:在备份开启GTID的实例里,需要指定 --set-gtid-purged参数,否则会报warning:
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events
备份文件里面会出现:
SET @@GLOBAL.GTID_PURGED='4e659069-3cd8-11e5-9a49-001c4270714e:1-483';
还原的时候会要求先在实例上reset master,不然会报错:
Warning: Using a password on the command line interface can be insecure.
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
指定--set-gtid-purged=ON参数,出现GTID_PURGED,直接还原的时候执行,从库不需要其他操作就可以直接change到主。
顺便总结一下:GTID跳过复制错误的方法
1)对于跳过一个错误,找到无法执行事务的编号,比如是2a09ee6e-645d-11e7-a96c-000c2953a1cb:1-10
mysql> stop slave;
mysql> set gtid_next='2a09ee6e-645d-11e7-a96c-000c2953a1cb:1-10';
mysql> begin;
mysql> commit;
mysql> set gtid_next='AUTOMATIC';
mysql> start slave; 2)上面方法只能跳过一个事务,那么对于一批如何跳过?
在主库执行"show master status",看主库执行到了哪里,比如:2a09ee6e-645d-11e7-a96c-000c2953a1cb:1-33,那么操作如下:
mysql> stop slave;
mysql> reset master;
mysql> set global gtid_purged='2a09ee6e-645d-11e7-a96c-000c2953a1cb:1-33';
mysql> start slave;
五、运维场景中GTID的运用
====== 使用GTID搭建Replication ======
- 从0开始搭建
step 1: 让所有server处于同一个点
mysql> SET @@global.read_only = ON; step 2: 关闭所有MySQL
# mysqladmin -uusername -p shutdown step 3: 重启所有MySQL,并开启GTID
# mysqld --gtid-mode=ON --log-bin --enforce-gtid-consistency & 当然,在my.cnf文件中配置好最佳! step 4: 在从数据库上通过change master语句进行复制
mysql> change master to master_host=host,master_port=port,master_user=user,master_password=password,master_auto_position=1;
mysql> start slave; step 5: 让master可读可写
mysql> SET @@global.read_only = OFF;
- 从备份中恢复&搭建
step 1: 备份
mysqldump xx; #获取并且记录gtid_purged值
or
冷备份; #获取并且记录gtid_executed值,这个就相当于mysqldump中得到的gtid_purged step 2: 在新服务器上reset master,导入备份
mysql> reset master; #清空gtid信息
导入备份; #如果是逻辑导入,请设置sql_log_bin=off
mysql> set global gtid_purged=xx; step 3: 在从数据库上通过change master语句进行复制
mysql> change master to master_host=host,master_port=port,master_user=user,master_password=password,master_auto_position=1;
mysql> start slave;
====== 如何从classic replication 升级成 GTID replication ======
- offline 方式升级 (线下升级)
offline 的方式升级最简单:
- 全部关闭mysql
- 在my.cnf文件中配置好GTID
- 重启mysql
- 登录mysql,执行"change master to MASTER_AUTO_POSITION=1;"
- online 方式升级 (线上升级)
先介绍几个重要GTID_MODE的参数:
GTID_MODE = OFF
不产生Normal_GTID,只接受来自master的ANONYMOUS_GTID GTID_MODE = OFF_PERMISSIVE
不产生Normal_GTID,可以接受来自master的ANONYMOUS_GTID & Normal_GTID GTID_MODE = ON_PERMISSIVE
产生Normal_GTID,可以接受来自master的ANONYMOUS_GTID & Normal_GTID GTID_MODE = ON
产生Normal_GTID,只接受来自master的Normal_GTID 归纳总结:
1)当master产生Normal_GTID的时候,如果slave的gtid_mode(OFF)不能接受Normal_GTID,那么就会报错
2)当master产生ANONYMOUS_GTID的时候,如果slave的gtid_mode(ON)不能接受ANONYMOUS_GTID,那么就会报错
3)设置auto_position的条件: 当master的gtid_mode=ON时,slave可以为OFF_PERMISSIVE,ON_PERMISSIVE,ON。
除此之外,都不能设置auto_position = on ============================================
下面开始说下如何online 升级为GTID模式? step 1: 每台server执行
检查错误日志,直到没有错误出现,才能进行下一步
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN; step 2: 每台server执行
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON; step 3: 每台server执行
不用关心一组复制集群的server的执行顺序,只需要保证每个Server都执行了,才能进行下一步
mysql> SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE; step 4: 每台server执行
不用关心一组复制集群的server的执行顺序,只需要保证每个Server都执行了,才能进行下一步
mysql> SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE; step 5: 在每台server上执行,如果ONGOING_ANONYMOUS_TRANSACTION_COUNT=0就可以
不需要一直为0,只要出现过0一次,就ok
mysql> SHOW STATUS LIKE 'ONGOING_ANONYMOUS_TRANSACTION_COUNT'; step 6: 确保所有anonymous事务传递到slave上了
#master上执行
mysql> SHOW MASTER STATUS; #每个slave上执行
mysql> SELECT MASTER_POS_WAIT(file, position); 或者,等一段时间,只要不是大的延迟,一般都没问题 step 7: 每台Server上执行
mysql> SET @@GLOBAL.GTID_MODE = ON; step 8: 在每台server上将my.cnf中添加好gtid配置
gtid_mode=on
enforce-gtid-consistency=1
log_bin=mysql-bin
log-slave-updates=1 step 9: 在从机上通过change master语句进行复制
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;
====== GTID failover (故障转移) ======
- MySQL crash (Mysql 崩溃)
配置好loss-less semi-sync replication,可以更可靠的保证数据零丢失!下面说的都是mysql crash 后,起不来的情况:
binlog 在master还有日志没有传递到slave (解决措施如下)
1. 选取最新的slave,change master to maseter_auto_position同步好
2. mysqlbinlog 将没传递过来的binlog在新master上replay
3. 打开新master的surper_read_only=off;
binlog 已经传递到slave (解决措施如下)
1. 选取最新的slave,change master to maseter_auto_position同步好
2. 打开新master的surper_read_only=off;
- OS crash (操作系统崩溃)
1. 选取最新的slave,change master to maseter_auto_position同步好
2. 打开新master的surper_read_only=off;
以上操作,在传统模式复制下,需要通过MHA来实现,但MHA还是比较复杂。现在有了GTID模式的情况下,实现起来就非常简单,非常方便了。
====== GTID 运维和错误处理 ======
使用GTID后,对原来传统的运维有不同之处了,需要调整过来;使用Row模式且复制配置正确的情况下,基本上很少发现有复制出错的情况;slave 设置 "super_read_only=on"
- 错误场景: Errant transaction
出现这种问题基本有两种情况
- 复制参数没有配置正确,当slave crash后,会出现重复键问题;
- DBA操作不正确,不小心在slave上执行了事务; 对于第一个重复键问题的解决措施:
1) 传统模式 (需要skip transation)
SQL> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
SQL> START SLAVE; 2) GTID模式
SQL> SET GTID_NEXT='b9b4712a-df64-11e3-b391-60672090eb04:7'; --设置需要跳过的gtid event
SQL> BEGIN;COMMIT;
SQL> SET GTID_NEXT='AUTOMATIC';
SQL> START SLAVE; 对于第二种不小心多执行了事务
这种情况就比较难了,这样已经导致了数据不一致,大多数情况,建议slave重做
如何避免? 则需要在slave上设置 "super_read_only=on"
- 特别注意: 当发生inject empty transction后,有可能会丢失事务
这里说下inject empty transction的隐患:
- 当slave上inject empty transction,说明有一个master的事务被忽略了(这里假设是 $uuid:100)
- 事务丢失一:如果此时此刻master挂了,这个slave被选举为新master,那么其他的slave如果还没有执行到$uuid:100,就会丢失掉$uuid:100这个事务。
- 事务丢失二:如果从备份中重新搭建一个slave,需要重新执行之前的所有事务,而此时,master挂了, 又回到了事务丢失一的场景。
- 如何重置gtid_executed,gtid_purged
设置gtid_executed
mysql> reset master #目前只能这么操作 设置gtid_purged
- 当gtid_executed 非空的时候,不能设置gtid_purged
- 当gtid_executed 为空的时候(即刚搭建好mysql), 可以直接SET @@GLOBAL.GTID_PURGED='0ad6eae9-2d66-11e6-864f-ecf4bbf1f42c:1-3';
- 如果auto.cnf 被删掉了,对于GTID的复制会有什么影响?
如果被删掉,重启后,server-uuid 会变
- 手动设置"set @@gtid_purged = xx:yy", mysql会去主动修改binlog的头么?
不会去主动修改!
- GTID和复制过滤规则之间如何协同工作?MySQL,test还能愉快的过滤掉吗?
GTID和复制过滤规则之间如何协同工作?MySQL,test还能愉快的过滤掉吗?
六、基于GTID模式的主从复制环境部署记录 (Mysql 5.6 +GTID复制)
mysql主数据库: 172.16.60.205 (master)
mysql从数据库: 172.16.60.206 (slave)
mysql5.6.39 安装部署,参考:https://www.cnblogs.com/kevingrace/p/6109679.html mysql5.7+GTID复制的配置和5.6的配置基本一致~ ============================================
主数据库172.16.60.205的操作 my.cnf文件里GTID复制的配置内容如下:
[root@mysql-master ~]# vim /usr/local/mysql/my.cnf
.........
#GTID:
server_id = 205
gtid_mode = on
enforce_gtid_consistency = on #强制gtid一直性,用于保证启动gitd后事务的安全; #binlog
log_bin = master-bin
log-slave-updates = 1 #在从服务器进入主服务器传入过来的修改日志所使用,在Mysql5.7之前主从架构上使用gtid模式的话,必须使用此选项,在Mysql5.7取消了,会增加系统负载。
binlog_format = row #推荐采用此模式
sync-master-info = 1 #同步master_info,任何事物提交以后都必须要把事务提交以后的二进制日志事件的位置对应的文件名称,记录到master_info中,下次启动自动读取,保证数据无丢失
sync_binlog = 1 #最好加上这一行。表示binlog进行FSYNC刷盘,同时dump线程会在sync阶段后进行binlog传输 #relay log
skip_slave_start = 1 配置完成之后,别忘了重启Mysql
[root@mysql-master ~]# /etc/init.d/mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL.. [ OK ] 查看一下master状态, 发现多了一项"Executed_Gtid_Set "
mysql> show master status;
+-------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------+
| master-bin.000006 | 151 | | | |
+-------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec) mysql> show global variables like '%uuid%';
+---------------+--------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------+
| server_uuid | b3df746a-1487-11e9-a8ba-0050568843f8 |
+---------------+--------------------------------------+
1 row in set (0.00 sec) mysql> show global variables like '%gtid%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| binlog_gtid_simple_recovery | OFF |
| enforce_gtid_consistency | ON |
| gtid_executed | |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
| simplified_binlog_gtid_recovery | OFF |
+---------------------------------+-------+
7 rows in set (0.00 sec) 主库执行从库复制授权
mysql> grant replication slave,replication client on *.* to slave@'172.16.60.206' identified by "slave@123";
Query OK, 0 rows affected (0.01 sec) mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec) mysql> show grants for slave@'172.16.60.206';
+--------------------------------------------------------------------------------------------------------------------------------------------------+
| Grants for slave@172.16.60.206 |
+--------------------------------------------------------------------------------------------------------------------------------------------------+
| GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'172.16.60.206' IDENTIFIED BY PASSWORD '*4F0FF134CC4C1A2872D972373A6AA86CA0A81872' |
+--------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec) 这里需要注意一下:
启动配置之前,同样需要对从服务器进行初始化。对从服务器初始化的方法基本和基于日志点是相同的,只不过在启动了GTID模式后,在备份中所记录的就不是备份时的二进制日志文件名和偏移量了,
而是记录的是备份时最后的GTID值。 需要先在主数据库机器上把目标库备份一下,假设这里目标库是kevin(为了测试效果,下面手动创建)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec) mysql> CREATE DATABASE kevin CHARACTER SET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.01 sec) mysql> use kevin;
Database changed
mysql> create table if not exists haha (id int(10) PRIMARY KEY AUTO_INCREMENT,name varchar(50) NOT NULL);
Query OK, 0 rows affected (0.27 sec) mysql> insert into kevin.haha values(1,"congcong"),(2,"huihui"),(3,"grace");
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from kevin.haha;
+----+----------+
| id | name |
+----+----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
+----+----------+
3 rows in set (0.00 sec) 把kevin库备份出来
[root@mysql-master ~]# mysqldump --single-transaction --master-data=2 --triggers --routines --database kevin -uroot -p123456 > /root/kevin.sql 备份完成之后,查看一下sql文件内容。
[root@mysql-master ~]# cat /root/kevin.sql
-- MySQL dump 10.13 Distrib 5.6.39, for Linux (x86_64)
--
-- Host: localhost Database: kevin
-- ------------------------------------------------------
-- Server version 5.6.39-log
...............
...............
--
-- GTID state at the beginning of the backup
-- SET @@GLOBAL.GTID_PURGED='b3df746a-1487-11e9-a8ba-0050568843f8:1-5'; --
...............
............... 然后把备份的/root/kevin.sql文件拷贝到从数据库服务器上
[root@mysql-master ~]# rsync -e "ssh -p22" -avpgolr /root/kevin.sql root@172.16.60.206:/root/ ============================================
从数据库172.16.60.206的操作 my.cnf文件里GTID复制的配置内容如下:
与主服务器配置大概一致,除了server_id不一致外,从服务器还可以在配置文件里面添加:"read_only=on" ,
使从服务器只能进行读取操作,此参数对超级用户无效,并且不会影响从服务器的复制;
[root@mysql-slave ~]# vim /usr/local/mysql/my.cnf
..........
#GTID:
server_id = 206
gtid_mode = on
enforce_gtid_consistency = on #binlog
log_bin = master-bin
log-slave-updates = 1
binlog_format = row
sync-master-info = 1
sync_binlog = 1 #relay log
skip_slave_start = 1
read_only = on 配置完成之后,别忘了重启Mysql
[root@mysql-slave ~]# /etc/init.d/mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL.. [ OK ] 接着将主数据库目标库的备份数据kevin.sql导入到从数据库里
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec) mysql> source /root/kevin.sql; mysql> select * from kevin.haha;
+----+----------+
| id | name |
+----+----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
+----+----------+
3 rows in set (0.00 sec) 在从数据库里,使用change master 配置主从复制
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> change master to master_host='172.16.60.205',master_user='slave',master_password='slave@123',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.50 sec) mysql> start slave;
Query OK, 0 rows affected (0.05 sec) mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.60.205
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000006
Read_Master_Log_Pos: 1270
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 411
Relay_Master_Log_File: master-bin.000006
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
..............
..............
Retrieved_Gtid_Set:
Executed_Gtid_Set: b3df746a-1487-11e9-a8ba-0050568843f8:1-5 #这是master主数据库的GTID
Auto_Position: 1 然后回到主数据库中查看master状态
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 205 | b6589756-1487-11e9-a8bb-005056ac509b |
+-----------+------+------+-----------+--------------------------------------+
1 row in set (0.00 sec) 通过上面一系列配置,则mysql基于GTID的主从复制环境就部署好了。 下面开始验证:
在172.16.60.205的主数据库里插入新数据
mysql> insert into kevin.haha values(10,"heifei"),(11,"huoqiu"),(12,"chengxihu");
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0 mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
+----+-----------+
6 rows in set (0.00 sec) 到172.16.60.206的从数据库里查看,发现已经同步过来了
mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
+----+-----------+
6 rows in set (0.00 sec)
如果上面slave再使用"change master to..."进行同步复制操作时报错:Error 'Can't create database 'kevin'; database exists' on query. Default database: 'kevin'. Query: 'CREATE DATABASE kevin CHARACTER SET utf8 COLLATE utf8_general_ci', 则解决办法就是把slave从库里导入的kevin库删除,然后再接着执行同步复制操作:stop slave; change master to ...; start slave 即可!
重做GTID主从复制关系 (迁移到新的slave从库或变更slave从库)
由于master主数据库上当前GTID_EXECUTED参数已经有值,而从master主库直接备份出来的dump文件中包含了SET @@GLOBAL.GTID_PURGED的操作,所以在新的slave从数据库导入dump备份文件时,会报错: ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty. (这个报错在迁移数据库的时候很有可能会碰过)
有两种方法解决上面的问题(可以使用其中任意一个方法,也可以两种方法一起使用):
方法一: 执行命令"reset master",这个操作可以将当前slave库的GTID_EXECUTED值置空;
方法二: 在dump导出master数据时,添加--set-gtid-purged=off参数,避免将master上的gtid信息导出,然后再导入到slave库;
在添加--set-gtid-purged=off参数前的dump导出文件信息如下(包含了SET @@GLOBAL.GTID_PURGED的操作):

在添加--set-gtid-purged=off参数后的dump导出文件信息如下:

如上是在172.16.60.205 master主库和 172.16.60.206 slave从库之间做的GTID复制关系, 假设现在172.16.60.206 slave节点有问题,需要将数据迁移到另一个slave节点(比如172.16.60.207)上, 则迁移后需要重新配置GTID主从复制关系 !操作记录如下:
1)在172.16.60.205主数据库上的操作
mysql > reset master;
mysql> grant replication slave,replication client on *.* to slave@'172.16.60.207' identified by "slave@123";
mysql> flush privileges; [root@mysql-master ~]# mysqldump -uroot -p'123456' -B -A -F --set-gtid-purged=OFF --master-data=2 --single-transaction --events |gzip >/root/205_$(date +%F).sql.gz /root/205_2019-01-10.sql.gz
[root@mysql-master ~]# ll /root/205_*
-rw-r--r-- 1 root root 181334 Jan 10 14:26 /root/205_2019-01-10.sql.gz [root@mysql-master ~]# rsync -e "ssh -p22" -avpgolr /root/205_2019-01-10.sql.gz root@172.16.60.207:/root/ 2) 在新的slave节点172.16.60.207从数据库上的操作
[root@mysql-slave2 ~]# vim /usr/local/mysql/my.cnf
..........
#GTID:
server_id = 207
gtid_mode = on
enforce_gtid_consistency = on #binlog
log_bin = master-bin
log-slave-updates = 1
binlog_format = row
sync-master-info = 1
sync_binlog = 1 #relay log
skip_slave_start = 1
read_only = on 配置完成之后,别忘了重启Mysql
[root@mysql-slave2 ~]# /etc/init.d/mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL.. [ OK ] 接着将主数据库拷贝过来的备份数据导入到从数据库中
[root@mysql-slave2 ~]# gzip -d 205_2019-01-10.sql.gz
[root@mysql-slave2 ~]# ls 205_2019-01-10.sql
205_2019-01-10.sql mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec) mysql> source /root/205_2019-01-10.sql; mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
+----+-----------+
6 rows in set (0.00 sec) 在从数据库里,使用change master 配置主从复制
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> change master to master_host='172.16.60.205',master_user='slave',master_password='slave@123',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.50 sec) mysql> start slave;
Query OK, 0 rows affected (0.05 sec) mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.60.205
Master_User: slave
Master_Port: 3306
..............
..............
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
..............
..............
Retrieved_Gtid_Set: 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-2
Executed_Gtid_Set: 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-2,
d743d65c-14b8-11e9-a9fb-005056ac05b5:1-126
Auto_Position: 1
1 row in set (0.00 sec) 通过上面可知,新添加的slave节点172.16.60.207已经和主数据库172.16.60.205配置好了GTID主从复制关系了。 接着回到master数据库查看
mysql> show master status;
+-------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+------------------------------------------+
| master-bin.000003 | 745 | | | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-4 |
+-------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec) mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 205 | 26ca2900-14f0-11e9-ab63-005056ac509b |
| 207 | | 3306 | 205 | 1e14b008-14f0-11e9-ab63-005056ac05b5 |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec) 由上面结果可知,新节点172.16.60.207已经成为了172.16.60.205主库的slave,即有了主从同步关系! 在master主数据库插入新数据
mysql> insert into kevin.haha values(20,"lanzhou"),(21,"zhongguo");
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0 然后到新的slave从库172.16.60.207上查看
mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
| 20 | lanzhou |
| 21 | zhongguo |
+----+-----------+
8 rows in set (0.00 sec) 但是到之前的slave从库172.16.60.206上查看,发现没有成功同步到master主库在上面插入的数据库
mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
+----+-----------+
6 rows in set (0.00 sec) 查看172.16.60.206机器上查看slave同步状态
mysql> show slave status \G;
..........
..........
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
..........
Retrieved_Gtid_Set: 59a1b34c-14f0-11e9-ab65-0050568843f8:6
Executed_Gtid_Set: 59a1b34c-14f0-11e9-ab65-0050568843f8:1-6
Auto_Position: 1 发现172.16.60.206 从库的slave同步状态是正常的! 因为IO和SQL都是YES!
那么为什么会同步不到master插入的新数据呢?
原因是:因为此时172.16.60.206从库的gtid和master主库的gtid不一样了! mysql> show global variables like 'gtid_%';
+---------------+------------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------------+
| gtid_executed | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-6 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-5 |
+---------------+------------------------------------------+
4 rows in set (0.00 sec) 而在172.16.60.205主库和新从库172.16.60.207上查看的gtid,发现这两个节点的gtid是一样的,所以它们两个数据能保持一致性!
但是172.16.60.206的gtid和它们两个的gtid不一样,所以172.16.60.206数据不能和master保持一致! 在172.16.60.205主库节点上查看gtid
mysql> show global variables like 'gtid_%';
+---------------+------------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------------+
| gtid_executed | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+------------------------------------------+
4 rows in set (0.00 sec) 在172.16.60.207从库节点上查看gtid mysql> show global variables like 'gtid_%';
+---------------+--------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+--------------------------------------------------------------------------------------+
| gtid_executed | 1e14b008-14f0-11e9-ab63-005056ac05b5:1-123,
59a1b34c-14f0-11e9-ab65-0050568843f8:1-3 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+--------------------------------------------------------------------------------------+
4 rows in set (0.00 sec) ===============================================================================================================
总结:
a) 通过以上操作方式后,新节点会成为master主库的slave从库,但是可能会导致之前的slave节点的gtid跟master不一样而破坏数据一致性。
b) 上面操作后,通过"show slave hosts;"查看,可能只有172.16.60.207这一个slave,之前的172.16.60.206节点的slave同步直接出现问题而导致主从复制失效。
c) 后面发现在后续添加172.16.60.208节点后(注意下面master主库的操作),172.16.60.206的gtid又自动恢复到和master的gtid一样了,即恢复了数据一致性的主从复制关系。
通过上面操作结果可知,采用"reset master" 以及添加"--set-gtid-purged=off"参数进行mysqldump备份,并添加新的slave节点的方式后,可能会导致之前的slave节点的主从同步失效(通过"show global variables like 'gtid_%';"命令查看之前的206从库的gtid和master的gtid不一样!)。比较推荐采用下面的方法添加新的slave,添加成功后,之前的slave的主从关系仍然保留有效,可实现"一主多从"的GTID主从复制。
一主多从的GTID主从复制
上面说到的是mysql基于GTID的一主一从模式的复制,现在需要再加一个slave从节点做成一主两从的模式。比如追加一个新的slave从节点172.16.60.208,也作为master主节点172.16.60.205的slave从节点,即由之前的一主一从调整为一主两从!
1)在master节点172.16.60.205上的操作
备份master主节点数据
mysql> grant replication slave,replication client on *.* to slave@'172.16.60.208' identified by "slave@123";
Query OK, 0 rows affected (0.06 sec) mysql> flush privileges;
Query OK, 0 rows affected (0.04 sec) mysql> FLUSH TABLE WITH READ LOCK;
Query OK, 0 rows affected (0.06 sec) 备份master
[root@mysql-master ~]# mysqldump -u root -p'123456' --lock-all-tables --master-data=2 --flush-logs --all-databases --triggers --routines --events > 205_slave.sql
[root@mysql-master ~]# ls 205_slave.sql
205_slave.sql 将master的备份文件拷贝给新的slave节点172.16.60.208
[root@mysql-master ~]# rsync -e "ssh -p22" -avpgolr 205_slave.sql root@172.16.60.208:/root/ 记录当前的gtid
mysql> show global variables like 'gtid_%';
+---------------+------------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-7 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+------------------------------------------+
4 rows in set (0.00 sec) 2) 在新添加的slave节点172.16.60.208上的操作
[root@mysql-slave3 ~]# vim /usr/local/mysql/my.cnf
..........
#GTID:
server_id = 208
gtid_mode = on
enforce_gtid_consistency = on #binlog
log_bin = master-bin
log-slave-updates = 1
binlog_format = row
sync-master-info = 1
sync_binlog = 1 #relay log
skip_slave_start = 1
read_only = on 配置完成之后,别忘了重启Mysql
[root@mysql-slave3 ~]# /etc/init.d/mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL... [ OK ] 恢复全备
[root@mysql-slave3 ~]# ls 205_slave.sql
205_slave.sql mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+--------------------+
4 rows in set (0.00 sec) mysql> source /root/205_slave.sql; mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| kevin |
| mysql |
| performance_schema |
| test |
+--------------------+
5 rows in set (0.00 sec) mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
| 20 | lanzhou |
| 21 | zhongguo |
+----+-----------+
8 rows in set (0.00 sec) 先检查一下新的slave节点上当前的gtid:
mysql> show global variables like 'gtid_%';
+---------------+------------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-7 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-7 |
+---------------+------------------------------------------+
4 rows in set (0.00 sec) 由于新的slave库是从master主库恢复过来的,gtid_purged现在自动就有了值1-11,并不需要手动的执行"reset master; set global gtid_purged = 'xxxxx';",
(只有在@@global.gtid_executed为空的情况下,才可以动态设置@@global.gtid_purged, 可以通过RESET MASTER的方式来清空@@global.gtid_executed) 在新的slave节点上直接开启复制就行了
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> change master to master_host='172.16.60.205',master_user='slave',master_password='slave@123',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.36 sec) mysql> start slave;
Query OK, 0 rows affected (0.03 sec) mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.60.205
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000007
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 363
Relay_Master_Log_File: master-bin.000007
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...........
...........
Retrieved_Gtid_Set:
Executed_Gtid_Set: 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-7
Auto_Position: 1
1 row in set (0.00 sec) ERROR:
No query specified 接着回到master数据库查看
mysql> show master status;
+-------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+------------------------------------------+
| master-bin.000007 | 191 | | | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-7 |
+-------------------+----------+--------------+------------------+------------------------------------------+
1 row in set (0.00 sec) mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 205 | d743d65c-14b8-11e9-a9fb-005056ac05b5 |
| 208 | | 3306 | 205 | 9b499047-14ca-11e9-aa6e-005056ac5b56 |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec) 可以发现,master主库的从库现在已经有两个slave从节点了,新添加的172.16.60.208的slave从节点已经加进去了! 在master主数据库插入新数据
mysql> unlock tables;
Query OK, 0 rows affected (0.00 sec) mysql> insert into kevin.haha values(30,"bobo"),(31,"huahua");
Query OK, 2 rows affected (0.04 sec)
Records: 2 Duplicates: 0 Warnings: 0 查看两个slave从节点,发现master上新插入的数据已经同步到两个slave从节点数据库里了
mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
| 20 | lanzhou |
| 21 | zhongguo |
| 30 | bobo |
| 31 | huahua |
+----+-----------+
10 rows in set (0.00 sec) 到此,新slave节点已经成功加入到master中了,一主两从架构也部署完成了。
另外,再追加更多slave节点,做成一主多从架构,部署方法和上面一样。
注意上面的172.16.60.206 slave节点问题
在上面"重新GTID主从复制"的操作中, 新节点172.16.60.207作为新的slave从库后,之前的slave从库172.16.60.206的同步关系失效了!一是通过"show global variables like 'gtid_%';"命令查看gtid和master的gtid不一样导致数据不能保持同步!也有可能出现下面的报错(通过"show slave status \G;"命令查看):Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'could not find next log; the first event '' at 4, the last event read from './master-bin.000002' at 2952, the last byte read from './master-bin.000002' at 2952.'
这个时候如果想要重新将172.16.60.206节点添加为master主库的slave节点,即恢复和master节点的主从复制关系,则操作方法和上面差不多,记录如下:
1)在172.16.60.205的master主数据库上的操作
mysql> FLUSH TABLE WITH READ LOCK;
Query OK, 0 rows affected (0.00 sec) [root@mysql-master ~]# mysqldump -u root -p'123456' --lock-all-tables --master-data=2 --flush-logs --all-databases --triggers --routines --events > 206_slave.sql
[root@mysql-master ~]# ls 206_slave.sql
206_slave.sql [root@mysql-master ~]# rsync -e "ssh -p22" -avpgolr 206_slave.sql root@172.16.60.206:/root/ 查看此时master上的GTID
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-18 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+-------------------------------------------+
4 rows in set (0.00 sec) 同时可以在其他两个slave节点(172.16.60.207/208)同样执行"show global variables like 'gtid_%';"
发现这两个slave节点的GTID和master的GTID是一样的! 2)在172.16.60.206的slave数据库上的操作
[root@mysql-slave ~]# ls /root/206_slave.sql
/root/206_slave.sql 查看此时该slave节点上的GTID
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-12,
77624378-14b9-11e9-a9ff-005056ac509b:1-4 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+-------------------------------------------------------------------------------------+
4 rows in set (0.00 sec) 发现此时172.16.60.206这个slave节点的GTID和master节点以及其他两个slave节点的GTID不一样!
所以172.16.60.206不能和172.16.60.205保持主从复制关系了(即在172.16.60.206数据库上执行"show slave status \G;"会有上面的报错) 现在将从172.16.60.205 master主数据库上备份过来的数据导入到172.16.60.206 slave数据库中 mysql> source /root/206_slave.sql; 接着再次重启slave
mysql> stop slave;
Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> start slave;
Query OK, 0 rows affected (0.06 sec) 然后再次查看slave同步状态
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.60.205
Master_User: slave
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: master-bin.000009
Read_Master_Log_Pos: 191
Relay_Log_File: mysql-relay-bin.000006
Relay_Log_Pos: 403
Relay_Master_Log_File: master-bin.000009
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
.........
.........
Retrieved_Gtid_Set: 71fffa5a-14b9-11e9-a9ff-0050568843f8:13-18
Executed_Gtid_Set: 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-18,
77624378-14b9-11e9-a9ff-005056ac509b:1-4
Auto_Position: 1
1 row in set (0.00 sec) ERROR:
No query specified 发现172.16.60.206 slave节点已经和172.16.60.205 master节点恢复了主从复制关系。
即IO和SQL的状态都为YES! 再次看看172.16.60.206 slave节点的GTID,发现和master节点以及其他两个slave节点的GTID一样了。
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-18,
77624378-14b9-11e9-a9ff-005056ac509b:1-4 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+-------------------------------------------------------------------------------------+
4 rows in set (0.00 sec) 再次查看172.16.60.205 master主数据库上
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------+
| gtid_executed | 71fffa5a-14b9-11e9-a9ff-0050568843f8:1-18 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+---------------+-------------------------------------------+
4 rows in set (0.00 sec) mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 205 | d743d65c-14b8-11e9-a9fb-005056ac05b5 |
| 206 | | 3306 | 205 | 77624378-14b9-11e9-a9ff-005056ac509b |
| 208 | | 3306 | 205 | 9b499047-14ca-11e9-aa6e-005056ac5b56 |
+-----------+------+------+-----------+--------------------------------------+
3 rows in set (0.00 sec) 通过上面结果可看出,172.16.60.206已经恢复了和172.16.60.205 master节点的主从复制关系了。
即172.16.60.205 master节点有三个slave节点, 现在在172.16.60.205 master节点插入新数据
mysql> insert into kevin.haha values(40,"shanghai"),(41,"beijing");
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0 在其他三个slave节点查看,发现新数据都正常复制过去了
mysql> select * from kevin.haha;
+----+-----------+
| id | name |
+----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
| 20 | lanzhou |
| 21 | zhongguo |
| 30 | bobo |
| 31 | huahua |
| 40 | shanghai |
| 41 | beijing |
+----+-----------+
12 rows in set (0.00 sec)
温馨提示:上面这种操作也是在slave从库出现"数据同步失败"或"slave同步故障“时进行重做GTID主从复制的一种有效有段!!!
GTID主从复制 故障转移 (failover)
现在172.16.60.205为master主库,分别有三个slave从库:
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 207 | | 3306 | 205 | 1e14b008-14f0-11e9-ab63-005056ac05b5 |
| 206 | | 3306 | 205 | 26ca2900-14f0-11e9-ab63-005056ac509b |
| 208 | | 3306 | 205 | 2147a0ce-14f0-11e9-ab63-005056ac5b56 |
+-----------+------+------+-----------+--------------------------------------+
3 rows in set (0.00 sec) 如果现在172.16.60.205主库发生故障,比如mysql宕了
[root@mysql-master ~]# /etc/init.d/mysql stop
Shutting down MySQL.... [ OK ]
[root@mysql-master ~]# lsof -i:3306 然后在三个slave节点上通过"show slave status \G;"查看同步状态,会出现"Slave_IO_Running: Connecting"
即此时的主从复制关系失效了! 现在要做的就是:选取最新的slave作为master,比如选择172.16.60.208节点作为master主库。
操作如下: 172.16.60.208节点上打开读写功能,即surper_read_only=off
[root@mysql-slave3 ~]# vim /usr/local/mysql/my.cnf
........
#read_only = on [root@mysql-slave3 ~]# /etc/init.d/mysql restart
Shutting down MySQL.. [ OK ]
Starting MySQL.. [ OK ] mysql> show variables like '%read_only%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_read_only | OFF |
| read_only | OFF |
| tx_read_only | OFF |
+------------------+-------+
3 rows in set (0.00 sec) mysql> grant replication slave,replication client on *.* to slave@'172.16.60.206' identified by "slave@123";
Query OK, 0 rows affected (0.15 sec) mysql> grant replication slave,replication client on *.* to slave@'172.16.60.207' identified by "slave@123";
Query OK, 0 rows affected (0.04 sec) mysql> flush privileges;
Query OK, 0 rows affected (0.04 sec) 查看gtid
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------+
| gtid_executed | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-12 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-9 |
+---------------+-------------------------------------------+
4 rows in set (0.00 sec) 然后在172.16.60.206/207两个slave节点上执行下面命令,即以172.16.60.208为master的同步复制关系:
mysql> stop slave;
Query OK, 0 rows affected (0.17 sec) mysql> change master to master_host='172.16.60.208',master_user='slave',master_password='slave@123',master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.18 sec) mysql> start slave;
Query OK, 0 rows affected (0.05 sec) mysql> show slave status \G;
...............
...............
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...............
...............
Retrieved_Gtid_Set: 2147a0ce-14f0-11e9-ab63-005056ac5b56:1-3
Executed_Gtid_Set: 2147a0ce-14f0-11e9-ab63-005056ac5b56:1-3,
59a1b34c-14f0-11e9-ab65-0050568843f8:1-12
Auto_Position: 1 分别查看172.16.60.206/207两个slave节点的gtid
mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------------------------------------------------+
| gtid_executed | 2147a0ce-14f0-11e9-ab63-005056ac5b56:1-3,
59a1b34c-14f0-11e9-ab65-0050568843f8:1-12 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-5 |
+---------------+-------------------------------------------------------------------------------------+
4 rows in set (0.00 sec) mysql> show global variables like 'gtid_%';
+---------------+-------------------------------------------------------------------------------------+
| Variable_name | Value |
+---------------+-------------------------------------------------------------------------------------+
| gtid_executed | 2147a0ce-14f0-11e9-ab63-005056ac5b56:1-3,
59a1b34c-14f0-11e9-ab65-0050568843f8:1-12 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | 59a1b34c-14f0-11e9-ab65-0050568843f8:1-5 |
+---------------+-------------------------------------------------------------------------------------+
4 rows in set (0.00 sec) 由上面可看出,172.16.60.206/207两个slave节点的gtid和172.16.60.208节点的gtid是一样的,因为他们的数据会保持一致性同步! 在172.16.60.208节点上查看,发现172.16.60.206/207已经成为了它的两个slave从库!
mysql> show slave hosts;
+-----------+------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+------+------+-----------+--------------------------------------+
| 206 | | 3306 | 208 | 26ca2900-14f0-11e9-ab63-005056ac509b |
| 207 | | 3306 | 208 | 1e14b008-14f0-11e9-ab63-005056ac05b5 |
+-----------+------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec) 由此可见,当之前的master主库172.16.60.205发生故障后,选取其中的一个slave从库172.16.60.208为新的master主库,
然后其余的slave从库以这个选出来的节点作为主库! 在172.16.60.208主库上插入新数据
mysql> insert into kevin.haha values(200,"haoshen"),(201,"haoren");
Query OK, 2 rows affected (0.15 sec)
Records: 2 Duplicates: 0 Warnings: 0 然后在172.16.60.206/207从库节点上查看,发现新数据已经同步过来了!
mysql> select * from kevin.haha;
+-----+-----------+
| id | name |
+-----+-----------+
| 1 | congcong |
| 2 | huihui |
| 3 | grace |
| 10 | heifei |
| 11 | huoqiu |
| 12 | chengxihu |
| 20 | lanzhou |
| 21 | zhongguo |
| 30 | bobo |
| 31 | huahua |
| 40 | shanghai |
| 41 | beijing |
| 200 | haoshen |
| 201 | haoren |
+-----+-----------+
14 rows in set (0.00 sec)
特别注意:
1) 同一组主从复制节点的GTID一定要保持一致!(通过"show global variables like 'gtid_%';"命令查看),否则slave从库的数据就不会和master主库数据保持一致!
2) Mysql基于GTID还可以做主主同步, 即双方相互授予同步复制权限给对方, 并且设置读写权限 (#read_only=on, 即注释掉只读配置, 这个只是限制非super用户, 对于具有super权限的用户来说限制不来), 然后双方相互执"stop slave", "change master to......", "start slave"同步操作即可实现主主同步.
3) 生产环境中, 可以做多主多从, 比如"两主三从", 两主通过keepalived对外提供统一的出口ip, 负责写操作; 三个从节点负责读操作, 并通过LVS进行读操作的负载均衡, (从节点跟主节点的vip做主从同步);
4) 主从可以通过脚本进行自动切换. 下面是测试中使用的一个主从自动切换的脚本:
下面脚本中:
1) 172.16.60.211是主节点, 主节点的my.cnf文件中提前配置好"# read_only=on" (先注释掉, 为了配置自动切换的脚本 );
2) 172.16.60.212是从节点; 从节点也要提前给主节点授予同步复制的权限 (因为主节点故障恢复后, 会自动变为新的从节点, 需要进行主从同步操作)
3) 主从节点各自安装和配置keepalived;
3) 172.16.60.94 是VIP地址; 脚本内容如下:
172.16.60.211的主节点操作如下
[root@mysql-master01 ~]# mkdir -p /home/mysql
[root@mysql-master01 ~]# touch /home/mysql/remove_slave.log
[root@mysql-master01 ~]# vim /home/mysql/remove_slave.sh
#!/bin/bash user=root
password=123456
log=/home/mysql/remove_slave.log /usr/bin/mysql -u$user -p$password -e "show databases" >/dev/null 2>&1
a=$?
/usr/sbin/ip addr|grep 172.16.60.94
b=$? if [ $a -eq 0 -a $b -eq 0 ];then
\cp -f /etc/my.cnf /etc/my_monit.cnf
/bin/sed -i 's/^'read_only'/'#read_only'/g' /etc/my.cnf
diff /etc/my.cnf /etc/my_monit.cnf
c=$?
if [ $c -ne 0 ]; then
echo -e "\n$(date) \n172.16.60.211 机器之前是mysql从节点,但是现在变成了mysql主节点" >> $log
systemctl restart mysqld
mysql -u$user -p$password -e "stop slave;" >/dev/null 2>&1
else
echo -e "\n$(date) \n172.16.60.211 机器现在是mysql主节点" >> $log
fi else
\cp -f /etc/my.cnf /etc/my_monit.cnf
/bin/sed -i 's/^'#read_only'/'read_only'/g' /etc/my.cnf
diff /etc/my.cnf /etc/my_monit.cnf
d=$?
if [ $d -ne 0 ]; then
echo -e "\n$(date) \n172.16.60.211 机器之前是mysql主节点,但是现在变成了mysql从节点" >> $log
systemctl restart mysqld
mysql -u$user -p$password -e "stop slave;" >/dev/null 2>&1
mysql -u$user -p$password -e " change master to master_host='172.16.60.212',master_user='slave',master_password='slave@123',master_auto_position=1;" >/dev/null 2>&1
mysql -u$user -p$password -e "start slave;" >/dev/null 2>&1
else
echo -e "\n$(date) \n172.16.60.211 机器现在是mysql从节点" >> $log
fi
fi ===================================================================
172.16.60.212的从节点操作如下:
[root@mysql-master01 ~]# mkdir -p /home/mysql
[root@mysql-master01 ~]# touch /home/mysql/remove_slave.log
[root@mysql-master01 ~]# vim /home/mysql/remove_slave.sh
#!/bin/bash user=root
password=123456
log=/home/mysql/remove_slave.log /usr/bin/mysql -u$user -p$password -e "show databases" >/dev/null 2>&1
a=$?
/usr/sbin/ip addr|grep 172.16.60.94
b=$? if [ $a -eq 0 -a $b -eq 0 ];then
\cp -f /etc/my.cnf /etc/my_monit.cnf
/bin/sed -i 's/^'read_only'/'#read_only'/g' /etc/my.cnf
diff /etc/my.cnf /etc/my_monit.cnf
c=$?
if [ $c -ne 0 ]; then
echo -e "\n$(date) \n172.16.60.212 机器之前是mysql从节点,但是现在变成了mysql主节点" >> $log
systemctl restart mysqld
mysql -u$user -p$password -e "stop slave;" >/dev/null 2>&1
else
echo -e "\n$(date) \n172.16.60.212 机器现在是mysql主节点" >> $log
fi else
\cp -f /etc/my.cnf /etc/my_monit.cnf
/bin/sed -i 's/^'#read_only'/'read_only'/g' /etc/my.cnf
diff /etc/my.cnf /etc/my_monit.cnf
d=$?
if [ $d -ne 0 ]; then
echo -e "\n$(date) \n172.16.60.212 机器之前是mysql主节点,但是现在变成了mysql从节点" >> $log
systemctl restart mysqld
mysql -u$user -p$password -e "stop slave;" >/dev/null 2>&1
mysql -u$user -p$password -e " change master to master_host='172.16.60.211',master_user='slave',master_password='slave@123',master_auto_position=1;" >/dev/null 2>&1
mysql -u$user -p$password -e "start slave;" >/dev/null 2>&1
else
echo -e "\n$(date) \n172.16.60.212 机器现在是mysql从节点" >> $log
fi
fi
Mysql基于GTID复制模式-运维小结 (完整篇)的更多相关文章
- 深入MySQL复制(二):基于GTID复制
相比传统的MySQL复制,gtid复制无论是配置还是维护都要轻松的多.本文对gtid复制稍作介绍. MySQL基于GTID复制官方手册:https://dev.mysql.com/doc/refman ...
- Mysql 5.7 基于组复制(MySQL Group Replication) - 运维小结
之前介绍了Mysq主从同步的异步复制(默认模式).半同步复制.基于GTID复制.基于组提交和并行复制 (解决同步延迟),下面简单说下Mysql基于组复制(MySQL Group Replication ...
- Mysql半同步复制模式说明及配置示例 - 运维小结
MySQL主从复制包括异步模式.半同步模式.GTID模式以及多源复制模式,默认是异步模式 (如之前详细介绍的mysql主从复制).所谓异步模式指的是MySQL 主服务器上I/O thread 线程将二 ...
- MySQL5.7 GTID学习笔记,[MySQL 5.6] GTID实现、运维变化及存在的bug
GTID(global transaction identifier)是对于一个已提交事务的全局唯一编号,前一部分是server_uuid,后面一部分是执行事务的唯一标志,通常是自增的. 下表整理 ...
- [MySQL 5.6] GTID实现、运维变化及存在的bug
[MySQL 5.6] GTID实现.运维变化及存在的bug http://www.tuicool.com/articles/NjqQju 由于之前没太多深入关注gtid,这里给自己补补课,本文是我看 ...
- 企业级-Mysql双主互备高可用负载均衡架构(基于GTID主从复制模式)(原创)
前言: 原理与思想 这里选用GTID主从复制模式Mysql主从复制模式,是为了更加确保主从复制的正确性.健康性与易配性.这里做的是两服务器A,B各有Mysql实例331 ...
- MYSQL 基于GTID的复制
1.概述 从MYSQL5.6 开始,mysql开始支持GTID复制. 基于日志点复制的缺点: 从那个二进制日志的偏移量进行增量同步,如果指定错误会造成遗漏或者重复,导致数据不一致. 基于GTID复制: ...
- MySQL 5.7基于GTID复制的常见问题和修复步骤(二)
[问题二] 有一个集群(MySQL5.7.23)切换后复制slave报1236,其实是不小心在slave上执行了事务导致 Got fatal error 1236 from master when r ...
- mysql 5.6在gtid复制模式下复制错误,如何跳过??
mysql 5.6在gtid复制模式下复制错误,如何跳过?? http://www.xuchanggang.cn/archives/918.html
随机推荐
- log4Net辅助类
public class Log { private ILog logger; public Log(ILog log) { this.logger = log; } public void Debu ...
- GPU与CPU的区别
作者:虫子君 链接:https://www.zhihu.com/question/19903344/answer/96081382 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载 ...
- sklearn中各种分类器回归器都适用于什么样的数据呢?
作者:匿名用户链接:https://www.zhihu.com/question/52992079/answer/156294774来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请 ...
- .NetCore Build Terminology
.NETCore Command: 1.dotnet build 2.dotnet run 3.dotnet new classlib 4.dotnet new xunit 5.dotne ...
- Linux小技巧之:两种方法统计访问web网站的前10个IP
获得访问前10位的IP地址: 10.46.170.7 218.202.70.147 77.72.83.87 5.39.217.107 185.197.74.234 185.197.74.231 第二种 ...
- JDBC lesson 1
https://www.mkyong.com/tutorials/jdbc-tutorials/ 1.jdbc基本概念 Java Database Connectivity (JDBC)是一套提供数据 ...
- attachBaseContext
at android.content.ContextWrapper.attachBaseContext(ContextWrapper.java:66) at android.view.ContextT ...
- 莫比乌斯函数 51nod-1240(合数分解试除法)
就是输出n时,莫比乌斯函数的值.直接将n唯一分解即可. 思路:筛出105以内的素数,因为109开方,105就差不多.当一个大数还没有被1000个素数分解,那么这个数基本上可以认为是素数(为合数为小概率 ...
- nodejs stream 手册学习
nodejs stream 手册 https://github.com/jabez128/stream-handbook 在node中,流可以帮助我们将事情的重点分为几份,因为使用流可以帮助我们将实现 ...
- Java内存区域划分、内存分配原理(转)
文章引用自 http://blog.csdn.net/OyangYujun/article/details/41173747 运行时数据区域 Java虚拟机在执行Java的过程中会把管理的内存划分为若 ...