pgm14
这部分讨论在有数据缺失情况下的 learning 问题,这里仍然假定了图结构是已知的。
首先需要讨论的是为什么会缺失,很多情况下缺失并不是“随机”的:有的缺失是人为的,那么某些情况下缺失的可以直接补上,而某些情况下我们需要使用额外的随机变量对缺失进行 modeling;有的缺失是随机的,有的是因为的确存在“解释”或者人为赋予了随机性(如 Bayesian 里面对参数假定了分布),这些时候我们会引入所谓的隐变量。这种情况下,我们 learning 的目标是最大化观测到的的数据的 likelihood,而将 missing 的通过 marginalization 去掉。某些不影响的情况下我们甚至可以扔掉 missing value。
这里引入两个概念:MCAR(missing at complete random),指 model 蕴含着 independency assertion,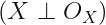

,即给定观测后,隐变量与控制是否缺失的隐变量独立。可以证明,MAR 情况下的 likelihood 可以 decompose 称为两部分,一部分是关于观测数据的,另一部分是关于
下面很自然的问题是既然是 MLE,与 fully observed 情况的区别是什么?很自然的一个 solver 就是我们写出 likelihood function,然后对参数求导进行优化,但实际情况并非我们想象的那么简单,去掉了 missing value 后,我们的 margin 往往是一个非常复杂的东西(多峰),特别对 BN 来说一个很好的 learning 性质(在 full observation 可以转换到每个 local likelihood 分开进行优化)已经没有了。说的更加形式化一点,我们会丧失 identifiability,参数模型的 identifiability 指对给定的参数集合,其任意参数均 indentifiable,即不存在其他的参数值导致似然函数值与其相同。往往在 exponential family 上的 MLE 都是 identifiable,而如果存在 missing value,我们往往只能得到 locally identifiable。那么像计算 gradient 的过程往往需要 inference 的结果,比如可以证明 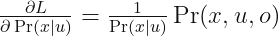

另外一种非常重要的思路就是 EM(expectation maximization)。直观的说 EM 的想法就是我们将 missing value 填上(data imputation),这样就可以在 fully observed 情况下进行 MLE,这是我们所熟悉的问题。这就有个 chick and egg 的问题:如果我们希望填上数据,那我们就得知道 model 的参数,可是我们现在正在估计参数呢!因此 EM 使用的是一种 bootstrap 的策略,假象我们有一个参数之后在后验分布下更新参数,如此不断迭代下去。具体来说,
- E-step,利用给定的参数计算 missing value 的后验分布
- 将补全后的数据的对数似然函数在后验分布下的平均进行学习,获得新的模型参数
注意这里如果是 BN 补全数据后对数似然函数就可以分解了,故而这里的计算可以直接使用前面的结论。因此 EM 需要不断的进行 inference 和做全观测下的 learning。可以证明 EM 算法会收敛,这是因为每步选择的参数以及
且

两式相减有

很显然由于最优化前者大于零,而后者也非负。其中我们也可以看出来 M-step 实际上是在选择一个凸下界(很多时候 decouple 后的联合分布的确是个凸函数)。可以证明收敛到的结果是 marginal likelihood 的 stationary point。
EM 的一个变种是使用 MAP 填充而不是在后验分布下进行期望,这称为 hard-assignment EM。但是这个算法与 EM 优化的目标是不同的。实际上它优化的是模型参数以及导致 MAP 的隐变量赋值,从这点来看,我们使用的 k-means 等聚类算法的逻辑就不是仅仅“像 EM”,而是的确是 hard-assignment EM 了。很自然的问题是,gradient ascent 和 EM 相比各有什么特点呢?事实上 EM 算法在迭代初期能够很快的导致优化目标函数的上升,而 gradient ascent 相对较慢。而迭代的后期,如果使用数值算法,如 CG 等收敛的会更快。两个算法与初始值都有较大的关系。
值得注意的是 EM 也好 gradient ascent 也好,其中较为费事的就是在厚颜下面的期望,这个计算在如混合分布下面是非常 trivial 的,但是某些情况下仍然会变得让人无法接受。很显然使用 approximate inference 技术可能能降低这部分的计算代价,但是关键的问题是如果 E-step 换用近似后验,是否得到的还是对原先 marginal likelihood 的合理近似呢?事实上,不少情况下我们是无法 justify 这点的,一般我们只是这样做而已。一种经常使用而且有理由说明这样做合理的情况就是所谓 variational EM,这是我们在对后验分布进行 factorization 假设下获得的近似后验,这样 learning 过程中我们使用它替代 E-step 的后验会进一步简化。诸如 LDA 之类的 training 实际上都是使用的这个技巧。通常知道了近似的目标函数我们才能 track 迭代收敛的情况。在 Bayesian model 里面更多的会用到 sampling 方法(如 Gibbs sampling,比如 LDA 的另外一种 variant 的 training)。事实上在有 missing data 的时候 variational Bayesian 仍然是可以用的,一方面我们的参数是 latent,另一方面我们的 missing data 也是,这样一来我们可以将两者的联合后验写成 factorized 的形式,一样套用前面的做法即可。
一个隐变量模型的重要问题是“cardinality”,比如聚类,我们应该设定几类呢?往往我们会将这个问题当做是模型选择来处理,通过 cross validation、BIC 这些策略来做。通过隐变量我们本质上希望能捕获到其他变量的相互关系。事实上后面我们可以证明,通过 MLE 获得的对数似然函数值正好等于两部分 r.v.s 的互信息减去两部分分别的熵,可以证明 EM 迭代能够增大隐变量与其他 r.v.s 互信息减去后者熵(在当前分布下)的值,这个值高于迭代前的对数似然却不超过后者。这样一来随着迭代的进行,互信息其实在逐步变大。除了前面这些决定 cardinality 的方式以外,还有一个 non-parametric Bayesian 的方式,即 Dirichlet process,这个前面也看过不少了,但是始终觉得还没理解透彻。另外隐变量是可以弄成 hierarchical 的用来 share 某些 information(类似的工作如 hierarchical mixture of experts)。
对于 undirected graph 来说,missing data 更是给繁复的 learning 雪上加霜,比如求梯度获得的两项原先前者是不需要进行 inference,但含有隐变量后也需要进一步 marginalize 掉那部分(在当前 model 下)。那么我们是否能使用 EM 的思想呢?E-step 似乎没有什么困难,然而到了 M-step,对应似然函数并不能解耦开来变成 local likelihood,而是仍然具有 partition function 的对数项,这使得我们必须依靠数值方法才能 maximize 获得下一步的参数,这个难度与直接使用梯度法没有本质差别。因此在这个领域使用 approximate inference 比 BN 更普遍。像 Hinton 为 RBM 提出的所谓 contrastive divergence 就是一类对隐变量存在时 learning 的策略。
——————
And Abraham rose up early in the morning, and took bread, and a bottle of water, and gave it to Hagar, putting it on her shoulder, and the child, and sent her away: and she departed, and wandered in the wilderness of Beersheba.
pgm14的更多相关文章
随机推荐
- ESP NVS
简介:NVS的主要功能是:存储键值(存在flash上面): NVS利用spi_flash_{read|write|erase}这些API来操作数据在内存上的删改写,内存上data类型nvs子类型所代表 ...
- storm集成kafka的应用,从kafka读取,写入kafka
storm集成kafka的应用,从kafka读取,写入kafka by 小闪电 0前言 storm的主要作用是进行流式的实时计算,对于一直产生的数据流处理是非常迅速的,然而大部分数据并不是均匀的数据流 ...
- <转>jmeter(十七)目录结构
之前了解过jmeter的目录结构,但只知道一些常用的配置文件,看到一篇介绍的比较详细的博客,就转载过来,当然,其实是自己懒得再去搜集更多资料慢慢看了,时间不够用... 原文链接:http://www. ...
- [Synthetic-data-with-text-and-image]
0 引言 本文是之前为了解决如何将文字贴到图片上而编写的代码,默认是如发票一类的,所以并未考虑透视变换等.且采用的是pygame粘贴方式,之前也尝试过opencv的seamlessClone粘贴. 值 ...
- CF97C Winning Strategy 构造、图论
题目传送门:http://codeforces.com/problemset/problem/97/C 题意:给出$n$与一个范围在$[0,1]$内的递增序列$P_0-P_n$,试构造一个无穷序列$\ ...
- React-UI组件和容器组件
UI组件负责页面的渲染,又叫傻瓜组件. 容器组件负责逻辑,又叫聪明组件. 当一个组件只有render函数的时候,就可以用无状态组件的形式来定义这个组件.无状态组件怎么定义呢?其实就是一个函数,接受pr ...
- Data Partitioning Guidance
在很多大规模的解决方案中,数据都是分成单独的分区,可以分别进行管理和访问的.而分割数据的策略必须仔细的斟酌才能够最大限度的提高效益,同时最大限度的减少不利影响.数据的分区可以极大的提升可扩展性,降低争 ...
- Html页面雪花效果的实现
简单介绍 昨天修改了一下博客所用的模板,冬天来了,给自己的博客加点雪花,感觉更有意境. 百度找到了非常多的结果,最终还是选用了cfs.snow.js,很赞压缩之后只有1kb左右,而且不会影响页面使用, ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(63)-WebApi与Unity注入
系列目录 前言: 有时候我们系统需要开放数据给手机App端或其他移动设备,不得不说Asp.net WebApi是目前首选 本节记录Asp.net MVC WebApi怎么利用Unity注入.系列开头已 ...
- Linux下绑定网卡的操作记录
公司采购的服务器安装了双网卡,并进行bond网卡绑定设置,网卡绑定mode共有七种(0~6) bond0.bond1.bond2.bond3.bond4.bond5.bond6. 第一种模式:mod= ...