02: OpenStack
1.1 OpenStack各组件
1、Horizon(控制台),又名Dashboard
就是web展示界面操作平台,方便用户交互的
2、Nova(计算)
负责创建,调度,销毁云主机
3、Neutron(网络)
负责实现SDN
4、Swift(对象存储)
目录结构存储数据
5、Cinder(块存储)
提供持久化块存储,即为云主机提供附加云盘
6、Glance(镜像)
提供镜像服务,装机使用
7、Keystone(认证)
为访问openstack各组件提供认证和授权功能,认证通过后,提供一个服务列表(存放你有权访问的服务),可以通过该列表访问各个组件
8、Ceilometer(计费)
很明显自用的根本不需要这功能,而且所谓的监控其实根本也算不上什么监控,监控性能,计费
9、Heat(编排)
这个太高大上了,就目前阶段正常企业还搞不定
自动化部署应用,自动化管理应用的整个生命周期.主要用于Paas
1.2 每一个组件为创建一台vm都提供了什么
注:这里需要注意的就是每一步都需要去keystone去进行验证,下图有详细的流程(每一步完成后去验证的过程省略了)
1、整体流程图
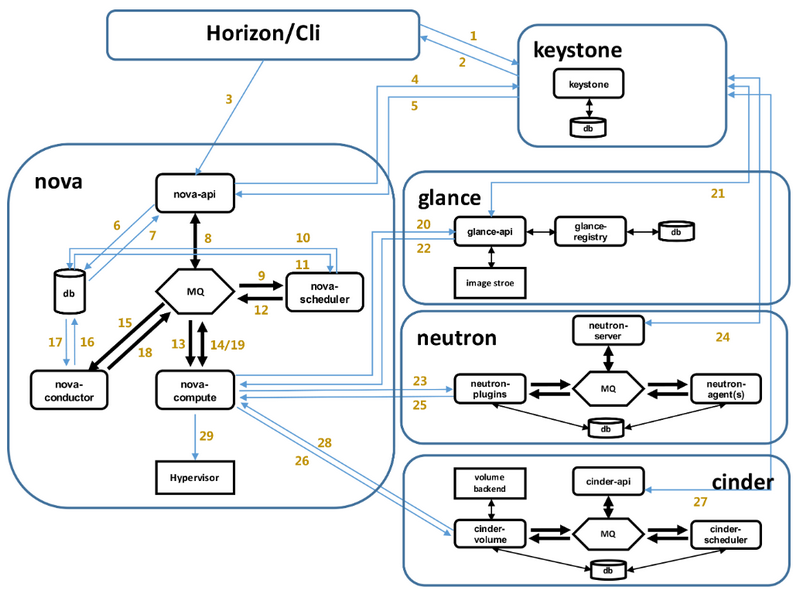
# 1、登录界面或命令行通过RESTful API向keystone获取认证信息。 # 2、keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。 # 3、界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。 # 4、nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。 # 5、keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。 # 6、通过认证后nova-api和数据库通讯。 # 7、初始化新建虚拟机的数据库记录。 # 8、nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。 # 9、nova-scheduler进程侦听消息队列,获取nova-api的请求。 # 10、nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
#
# 11、对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。 # 12、ova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。 # 13、nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。 # 14、nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor) # 15、nova-conductor从消息队队列中拿到nova-compute请求消息。 # 16、nova-conductor根据消息查询虚拟机对应的信息。 # 17、nova-conductor从数据库中获得虚拟机对应信息。 # 18、nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。 # 19、nova-compute从对应的消息队列中获取虚拟机信息消息。 # 20、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。 # 21、glance-api向keystone认证token是否有效,并返回验证结果。 # 22、token验证通过,nova-compute获得虚拟机镜像信息(URL)。 # 23、nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。 # 24、neutron-server向keystone认证token是否有效,并返回验证结果。 # 25、token验证通过,nova-compute获得虚拟机网络信息。 # 26、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。 # 27、cinder-api向keystone认证token是否有效,并返回验证结果。 # 28、token验证通过,nova-compute获得虚拟机持久化存储信息。 # 29、nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。 # 注:这里面可以看出组件之间的通讯都是通过restapi实现的
创建一台vm各组件都做了哪些事情
11111111111111111111
02: OpenStack的更多相关文章
- OpenStack(二)——使用Kolla部署OpenStack-allinone云平台
(1).Kolla概述 Kolla是OpenStack下用于自动化部署的一个项目,它基于docker和ansible来实现,其中docker主要负责镜像制作和容器管理,ansible主要负责环境的部署 ...
- CentOS7安装OpenStack(Rocky版)-02.安装Keyston认证服务组件(控制节点)
本文分享openstack的认证服务组件keystone --------------- 完美的分割线 ---------------- 2.0.keystone认证服务 1)用户与认证:用户权限与用 ...
- 每天5分钟 玩转OpenStack 目录列表
最近在学习 OpenStack 的相关知识,一直苦于 OpenStack 的体系庞大以及复杂程度,学习没有进度,停滞不前.偶然机会在 51CTO 上发现了一个热点的专题关于 OpenStack 的,题 ...
- OpenStack Mitaka 版本中的 domain 和 admin
OpenStack 的 Keystone V3 中引入了 Domain 的概念.引入这个概念后,关于 admin 这个role 的定义就变得复杂了起来. 本文测试环境是社区 Mitaka 版本. 1. ...
- 关于OpenStack的学习路线及相关资源汇总
首先我们想学习openstack,那么openstack是什么?能干什么?涉及的初衷是什么?由什么来组成?刚接触openstack,说openstack不是一个软件,而是由多个组件进行组合,这是一个更 ...
- openstack api快速入门
原文:http://my.oschina.net/guol/blog/105430 openstack官方有提供api供开发者使用,可以使用api做一些外围的小工具,用来简化对openstack的管理 ...
- 理解 OpenStack 高可用(HA)(3):Neutron 分布式虚拟路由(Neutron Distributed Virtual Routing)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- centos7.1 x86_64系统安装openstack(Mitaka)一
一.Openstack各组件简单介绍 keystone:身份认证服务 glance:镜像服务 nova:计算服务 neutron:网络服务 Cinder:块存储服务 Swift:对象存储服务 heat ...
- 理解 OpenStack + Ceph (8): 基本的 Ceph 性能测试工具和方法
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
随机推荐
- ubuntu 14.04 安装python包psycopg2
http://stackoverflow.com/questions/28253681/you-need-to-install-postgresql-server-dev-x-y-for-buildi ...
- vue分页问题参考 感谢
https://www.cnblogs.com/zhoulifeng/p/9395295.html
- linux的基本操作(NFS服务配置)
服务配置 [什么是NFS] NFS会经常用到,用于在网络上共享存储.这样讲,你对NFS可能不太了解,笔者不妨举一个例子来说明一下NFS是用来做什么的.假如有三台机器A.B.C,它们需要访问同一个目录, ...
- 3 Oracle 32位客户端安装及arcgis连接
关于Oracle服务器端安装及配置的过程详见第2篇文章,链接如下:http://www.cnblogs.com/gistrd/p/8494292.html,本篇介绍客户端安装配置及连接arcgis过程 ...
- Linux中找到占用cpu最高的线程
在工作中,经常会碰到CPU占用100%的情况,那如何找到是那个线程占用了cpu呢? 1. top命令,找到cpu占用最高的进程 2. 查看该进程的线程, top -p <pid> 3. ...
- InnoDB中锁的算法(3)
Ⅰ.隐式锁vs显示锁 session1: (root@localhost) [test]> show variables like 'tx_isolation'; +-------------- ...
- python摸爬滚打之day022----模块(序列化操作)
1.pickle 可以将我们python中的任意数据类型转化成bytes并写入到文件中. 同样也可以把文件中写好的bytes转换回我们python的数据. pickle可以直接序列化对象. clas ...
- 16.0-uC/OS-III同步
同步 uC/OS-III中用于同步的两种机制:信号量和事件标志组 . 1.信号量 信号量最初用于控制共享资源的访问.信号量可用于ISR与任务间.任务与任务间的同步. “ N”表示信号量可以被累计.初始 ...
- Pandas的可视化操作(利用pandas得到图表)
基本折线图 Series和DataFrame上的这个功能只是使用matplotlib库的plot()方法的简单包装实现. 举个例子 import pandas as pd import numpy a ...
- python中的装包与拆包
python中的装包与拆包 *args和 **kwargs是在python的代码中经常用到的两个参数,初学者对这两个参数的理解可能仅仅限于*args是用于接收多余的未命名参数,**kwargs用于接收 ...