[大数据从入门到放弃系列教程]第一个spark分析程序
原文链接:http://www.cnblogs.com/blog5277/p/8580007.html
原文作者:博客园--曲高终和寡
*********************分割线**********************
由于新入职了一家公司,准备把我放进大数据的组里面
我此前对大数据,仅仅停留在听说过这个名词上,那么这次很快就要进入项目,一边我自己在学习,一边也把教程分享出来,避免后来之人踩我所踩过的坑
*********************分割线**********************
前面两篇文章讲了如何配置Hadoop,Scala,spark,那么这一篇就开始写第一个基于spark的数据分析小项目了(我也是照搬教程的,可能跟很多人的相同)
一.待分析数据来源
你们可以自己准备,也可以跟教程一样直接用spark目录下的README.md
我的文件的绝对路径就是 :
/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md
二.在IDE里面新建一个maven项目,引入这个包:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
三.开始两个练手小程序
1.统计类型的:统计包含X的行数
每一句的意义我都标了详细的注释,看注释就OK了
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function; /**
* @Author Created by ShadowSaint on 2018/3/16
*/
public class SimpleApp {
public static void main(String[] args) {
//指定待读取文件的路径
String filePath = "/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md";
//配置一个Spark配置,注意,本次测试的时候这里不能少setMaster,这里可选的master好像有4种,分别对应了Spark是本地测试的,还是集群的等运行方式
SparkConf conf=new SparkConf()
.setMaster("local[*]")
.setAppName("Simple Application");
//新建一个JavaSpark的运行环境
JavaSparkContext context=new JavaSparkContext(conf);
//初始化一个RDD,RDD全称弹性分布式数据集Resilient Distributed Dataset,是Spark最主要的一个抽象出来的概念,就是分布式的数据集合
//后面加 .cache 就是spark的优点所在了,数据可以缓存在内存内计算,速度会快很多,内存不够用了再存在硬盘,不像Hadoop那样都存在硬盘
JavaRDD<String> logData = context.textFile(filePath).cache(); //然后就对RDD进行操作,filter,顾名思义,过滤器,里面的入口参数是 Function ,count,算数
//spark还有个特点就是,只有到要计算的那一步了,才开始读取文件,借用忘了在哪看到的一句话就是"老师不来检查作业,我就不做"
long numAs=logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("a");
}
}).count(); long numBs=logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) throws Exception {
return s.contains("b");
}
}).count();
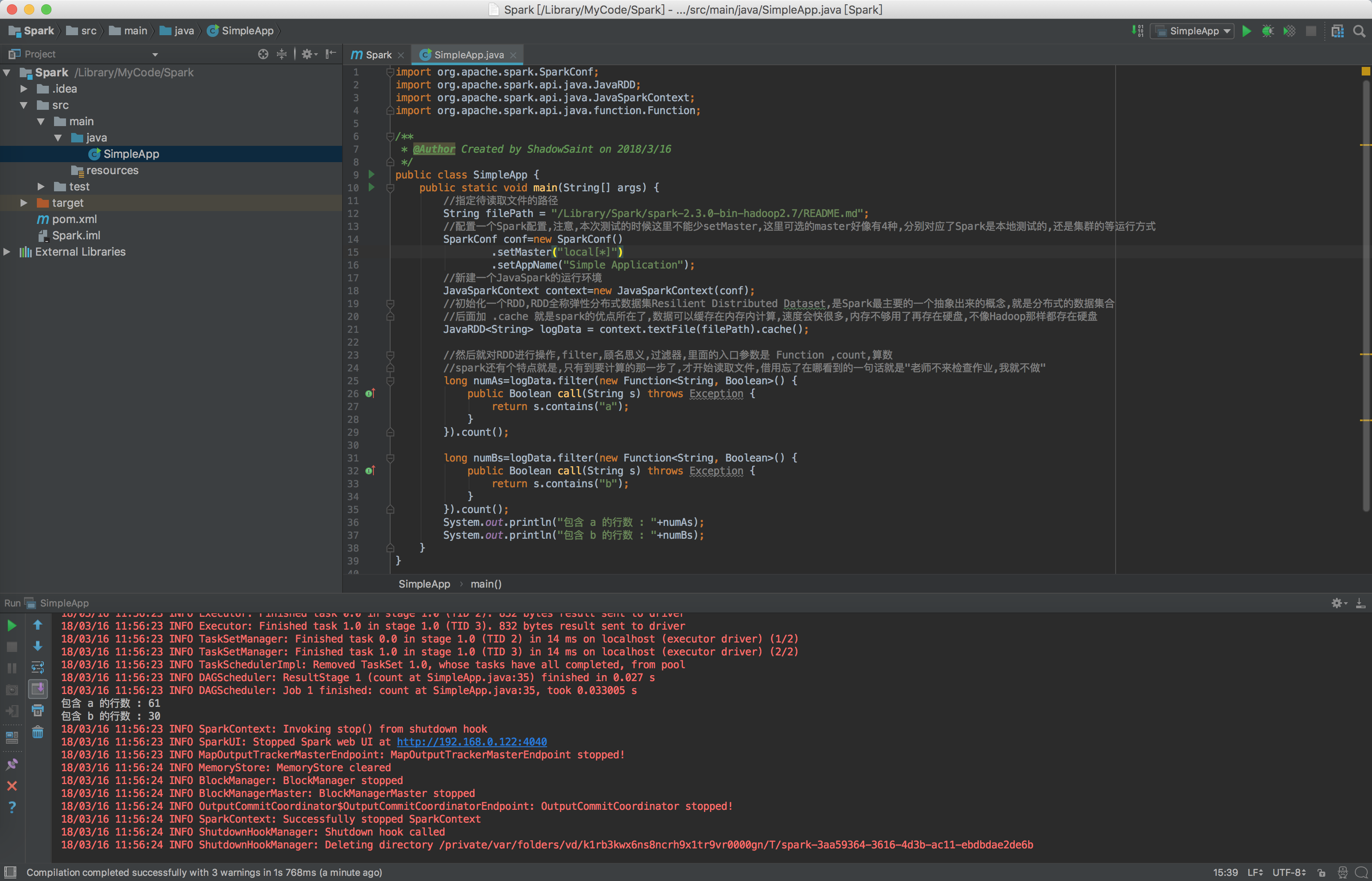
System.out.println("包含 a 的行数 : "+numAs);
System.out.println("包含 b 的行数 : "+numBs);
}
}
注意,本次测试,在你还没弄清楚spark到底干嘛的时候,一定要在SparkConf那里配置 setMaster,否则的话会报如下错误:
org.apache.spark.SparkException: A master URL must be set in your configuration
好了,照我上面那样整完,项目就可以正常运行了,输出了一大堆东西,如下:
2.分类的:将一个文本拆分,看总共出现了多少单词,每个单词出现了多少次
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays;
import java.util.Iterator;
import java.util.Map; /**
* @Author Created by ShadowSaint on 2018/3/16
*/
public class CountWords {
public static void main(String[] args) {
//指定待读取文件的路径
String filePath = "/Library/Spark/spark-2.3.0-bin-hadoop2.7/README.md";
//配置一个Spark配置,注意,本次测试的时候这里不能少setMaster,这里可选的master好像有4种,分别对应了Spark是本地测试的,还是集群的等运行方式
SparkConf conf=new SparkConf()
.setMaster("local[*]")
.setAppName("Simple Application");
//新建一个JavaSpark的运行环境
JavaSparkContext context=new JavaSparkContext(conf);
//初始化一个RDD,RDD全称弹性分布式数据集Resilient Distributed Dataset,是Spark最主要的一个抽象出来的概念,就是分布式的数据集合
//后面加 .cache 就是spark的优点所在了,数据可以缓存在内存内计算,速度会快很多,内存不够用了再存在硬盘,不像Hadoop那样都存在硬盘
JavaRDD<String> input = context.textFile(filePath).cache(); //以空格为界,划分为单词
JavaRDD<String> words=input.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
}); //转化为键值对并计数
JavaPairRDD<String,Integer> counts=words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s,1);
}
}).reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer+integer2;
}
}); //输出
Map<String,Integer> map=counts.collectAsMap();
for (String key:map.keySet()){
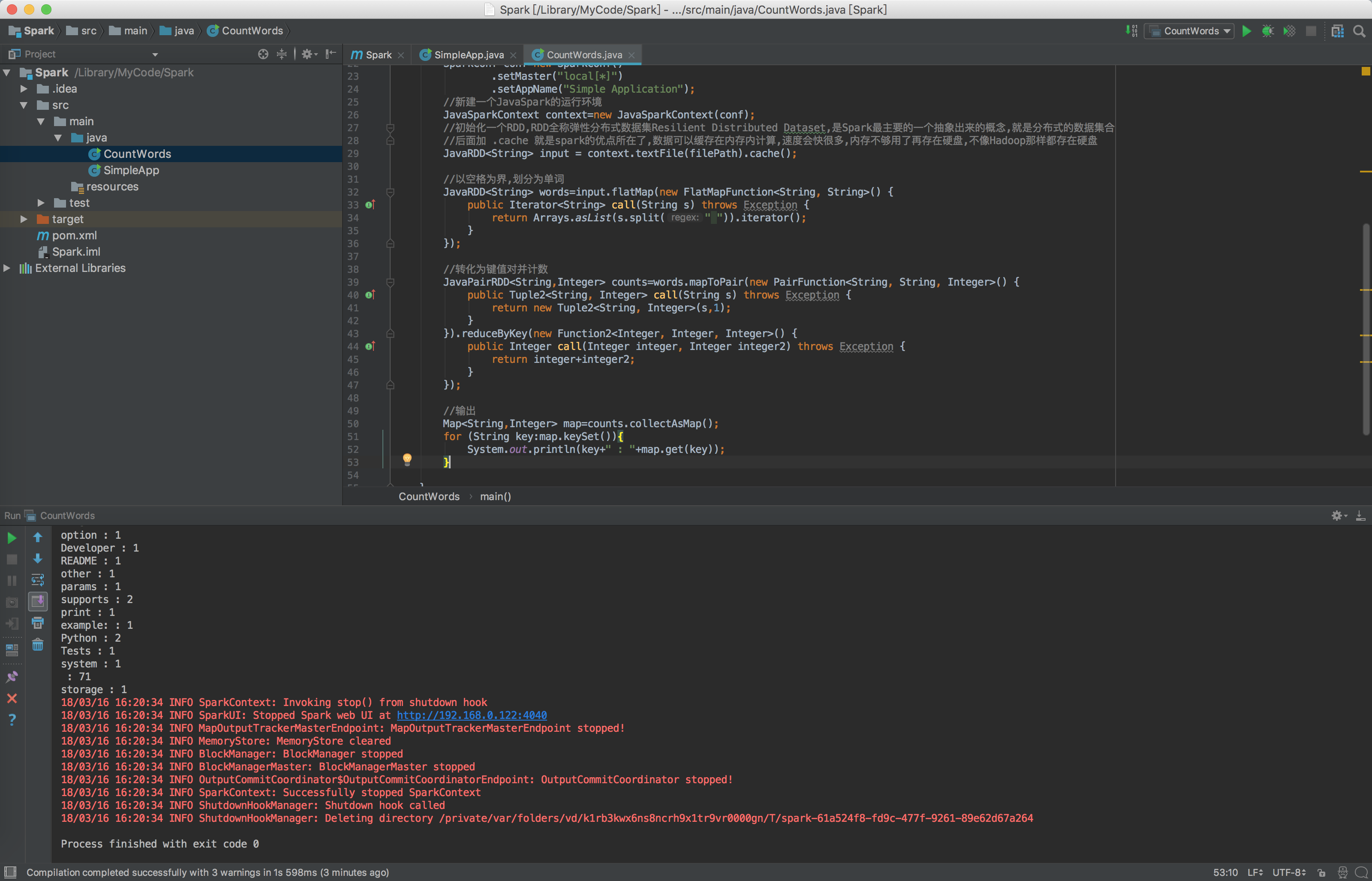
System.out.println(key+" : "+map.get(key));
} }
}
运行后,输出结果为:
然后根据出现频率,排个序,就能做出单词出现频率热力图了.
再配合已有的数据,比如说爬虫爬一下今天微博的数据(中文的话需要配合中文分词工具),就能知道,今天微博讨论最热的词是什么了(然而我就随便猜一下,频率最高的字是哈,手动滑稽)
那么,现在已经很接近传说中的大数据了,不是么?
[大数据从入门到放弃系列教程]第一个spark分析程序的更多相关文章
- [大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world
[大数据从入门到放弃系列教程]在IDEA的Java项目里,配置并加入Scala,写出并运行scala的hello world 原文链接:http://www.cnblogs.com/blog5277/ ...
- NHibernate从入门到精通系列(3)——第一个NHibernate应用程序
内容摘要 准备工作 开发流程 程序开发 一.准备工作 1.1开发环境 开发工具:VS2008以上,我使用的是VS2010 数据库:任意关系型数据库,我使用的是SQL Server 2005 Expre ...
- K8S从入门到放弃系列-(16)Kubernetes集群Prometheus-operator监控部署
Prometheus Operator不同于Prometheus,Prometheus Operator是 CoreOS 开源的一套用于管理在 Kubernetes 集群上的 Prometheus 控 ...
- 大数据-03-Spark入门
Spark 简介 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce).这里,主要关注的是在处理大型数据集时在查询之间的等待时间和运行程序的等 ...
- php从入门到放弃系列-01.php环境的搭建
php从入门到放弃系列-01.php环境的搭建 一.为什么要学习php 1.php语言适用于中小型网站的快速开发: 2.并且有非常成熟的开源框架,例如yii,thinkphp等: 3.几乎全部的CMS ...
- php从入门到放弃系列-04.php页面间值传递和保持
php从入门到放弃系列-04.php页面间值传递和保持 一.目录结构 二.两次页面间传递值 在两次页面之间传递少量数据,可以使用get提交,也可以使用post提交,二者的区别恕不赘述. 1.get提交 ...
- php从入门到放弃系列-03.php函数和面向对象
php从入门到放弃系列-03.php函数和面向对象 一.函数 php真正的威力源自它的函数,内置了1000个函数,可以参考PHP 参考手册. 自定义函数: function functionName( ...
- 办公软件Office PPT 2010视频教程从入门到精通系列教程(22课时)
办公软件Office PPT 2010视频教程从入门到精通系列教程(22课时) 乔布斯的成功离不开美轮美奂的幻灯片效果,一个成功的商务人士.部门经理也少不了各种各样的PPT幻灯片.绿色资源网给你提供了 ...
- php从入门到放弃系列-02.php基础语法
php从入门到放弃系列-02.php基础语法 一.学习语法,从hello world开始 PHP(全称:PHP:Hypertext Preprocessor,即"PHP:超文本预处理器&qu ...
随机推荐
- 用VsCode写Markdown
Markdown 基本语法 段落 非常自然,一行文字就是一个段落. 比如: 这是一个段落 会被解释成: <p>这是一个段落.</p> 如果你需要另起一段,请在两个段落之间隔一个 ...
- consul服务配置维护
1.命令参数 -advertise:通知展现地址用来改变我们给集群中的其他节点展现的地址,默认情况下-bind地址就是展现地址,然而也存在一些路由地址是不能受约束的,这时候会激活一个不同的地址来供应, ...
- vue computed的执行问题
1.在new Vue()的时候,vue\src\core\instance\index.js里面的_init()初始化各个功能 function Vue (options) { if (process ...
- J2EE [web] 403.500.404页面配置
如果想让系统在出错后,看到自定义的错误提示页面,而不是满屏错误原因以及代码. 1.web.xml中 <error-page> <error-code>403</error ...
- InnoDB中锁的查看
Ⅰ. show engine innodb status\G 1.1 实力分析一波 锁介绍的那篇中已经提到了这个命令,现在我们开一个参数,更细致的分析一下这个命令 (root@localhost) [ ...
- mysql in 排序 也可以按in里面的顺序来排序
SQL: select * from table where id IN (3,9,6);这样的情况取出来后,其实,id还是按3,6,9,排序的,但如果我们真要按IN里面的顺序排序怎么办?SQL能不能 ...
- FastDFS的单点部署
1 安装libfastcommon 注意:在Centos7下和在Ubuntu下安装FastDFS是不同的,在Ubuntu上安装FastDFS需要安装libevent,而外Centos上安装FastD ...
- Address already in use: AH00072: make_sock: could not bind to address 0.0.0.0:443
(1)端口被占用,找到对应的进行并结束.(2)Linux下查看,无进程占用443端口,确认/etc/httpd/conf.d下只有一个ssl.conf,无其他SSL配置.备份文件,如果有,apache ...
- Django框架获取各种form表单数据
Django中获取text,password 名字:<input type="text" name="name"><br><br& ...
- Mysql模糊查询Like传递参数的语句
set @keyWord='我的': select * from tblcontent where content like CONCAT('%',@keyWord,'%')