深入学习卷积神经网络(CNN)的原理知识
网上关于卷积神经网络的相关知识以及数不胜数,所以本文在学习了前人的博客和知乎,在别人博客的基础上整理的知识点,便于自己理解,以后复习也可以常看看,但是如果侵犯到哪位大神的权利,请联系小编,谢谢。好了下面言归正传:
在深度学习领域中,已经经过验证的成熟算法,目前主要有深度卷积网络(DNN)和递归网络(RNN),在图像识别,视频识别,语音识别领域取得了巨大的成功,正是由于这些成功,能促成了当前深度学习的大热。与此相对应的,在深度学习研究领域,最热门的是AutoEncoder、RBM、DBN等产生式网络架构,但是这些研究领域,虽然论文比较多,但是重量级应用还没有出现,是否能取得成功还具有不确定性。但是有一些比较初步的迹象表明,这些研究领域还是非常值得期待的。比如AutoEncoder在图像、视频搜索领域的应用,RBM对非结构化数据的处理方面,DBN网络在结合人工智能领域两大流派连接主义和符号主义,都具有巨大的前景,有理由期待产生重量级成果。我们在后续会对这些网络逐一进行介绍和实现,除了给出重构后的Theano实现代码外,还会逐步补充这些算法在实际应用的中的实例,我们会主要将这些算法应用在创业公司数据中,从几万家创业公司及投融资数据中,希望能挖掘出哪些公司更可能获得投资,特定公司更有可能获得哪家投资机构的投资。
卷积神经网络(CNN),这是深度学习算法应用最成功的领域之一,卷积神经网络包括一维卷积神经网络,二维卷积神经网络以及三维卷积神经网络。一维卷积神经网络主要用于序列类的数据处理,二维卷积神经网络常应用于图像类文本的识别,三维卷积神经网络主要应用于医学图像以及视频类数据识别。
下面我的学习分为四部分,首先利用一个形象的例子说明电脑是如何识别图像的,然后在说明什么是神经网络,什么是卷积神经网络,最后介绍常见的几种卷积神经网络。大体的结构就是这样的。
一:如何帮助神经网络识别图像?
人类大脑是一非常强大的机器,每秒内能看(捕捉)多张图,并在意识不到的情况下就完成了对这些图的处理。但机器并非如此。机器处理图像的第一步是理解,理解如何表达一张图像,进而读取图片。
简单来说,每个图像都是一系列特定排序的图点(像素)。如果你改变像素的顺序或颜色,图像也随之改变。举个例子,存储并读取一张上面写着数字 4 的图像。
基本上,机器会把图像打碎成像素矩阵,存储每个表示位置像素的颜色码。在下图的表示中,数值 1 是白色,256 是最深的绿色(为了简化,我们示例限制到了一种颜色)。
一旦你以这种格式存储完图片信息,下一步就是让神经网络理解这种排序与模式。(表征像素的数值是以特定的方式排序的)
那么如何帮助神经网络识别图像?
假设我们尝试使用全连接网络识别图像,应该如何做?
全连接网络可以通过平化它,把图像当作一个数组,并把像素值当作预测图像中数值的特征。明确地说,让网络理解理解下面图中发生了什么,非常的艰难。

即使人类也很难理解上图中表达的含义是数字 4。我们完全丢失了像素的空间排列。
我们能做什么呢?可以尝试从原图中提取特征,从而保留空间排序。
案例一
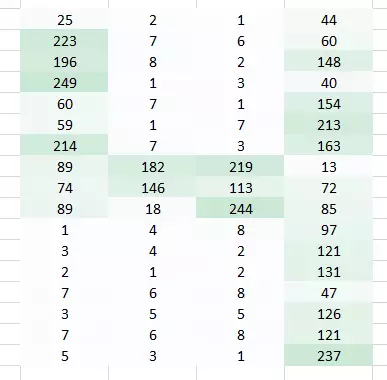
这里我们使用一个权重乘以初始像素值
现在裸眼识别出这是「4」就变得更简单了。但把它交给全连接网络之前,还需要平整化(flatten) 它,要让我们能够保留图像的空间排列。

案例二
现在我们可以看到,把图像平整化完全破坏了它的排列。我们需要想出一种方式在没有平整化的情况下把图片馈送给网络,并且还要保留空间排列特征,也就是需要馈送像素值的 2D/3D 排列。
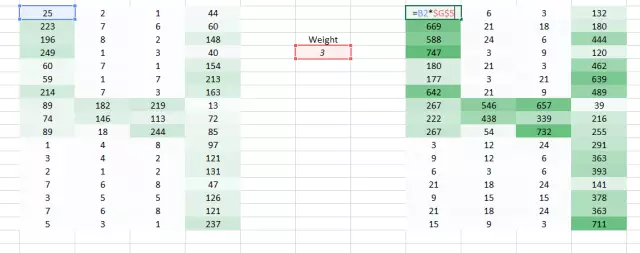
我们可以尝试一次采用图像的两个像素值,而非一个。这能给网络很好的洞见,观察邻近像素的特征。既然一次采用两个像素,那也就需要一次采用两个权重值了。
希望你能注意到图像从之前的 4 列数值变成了 3 列。因为我们现在一次移用两个像素(在每次移动中像素被共享),图像变的更小了。虽然图像变小了,我们仍能在很大程度上理解这是「4」。而且,要意识到的一个重点是,我们采用的是两个连贯的水平像素,因此只会考虑水平的排列。
这是我们从图像中提取特征的一种方式。我们可以看到左边和中间部分,但右边部分看起来不那么清楚。主要是因为两个问题:
1. 图片角落左边和右边是权重相乘一次得到的。
2. 左边仍旧保留,因为权重值高;右边因为略低的权重,有些丢失。
现在我们有两个问题,需要两个解决方案。
案例三
遇到这样的问题是图像左右两角只被权重通过一次,我们需要做的是让网络像考虑其他像素一样考虑角落。我们有一个简单的方法解决这一问题:把零放在权重运动的两边。

你可以看到通过添加零,来自角落的信息被再训练。图像也变得更大。这可被用于我们不想要缩小图像的情况下。
案例四
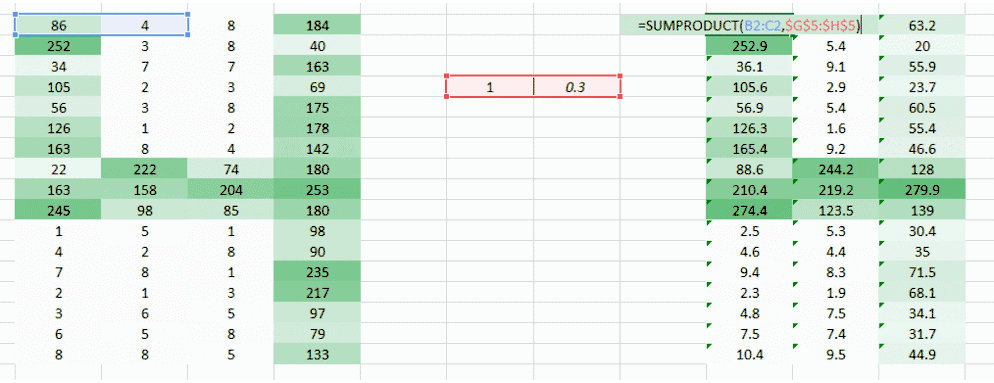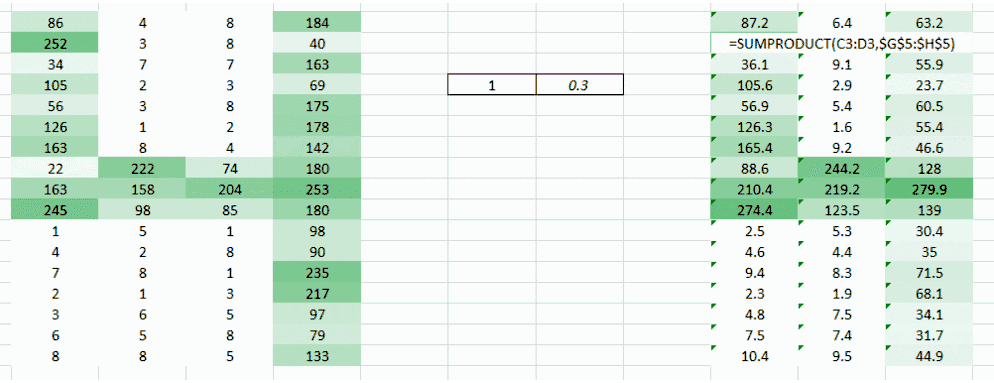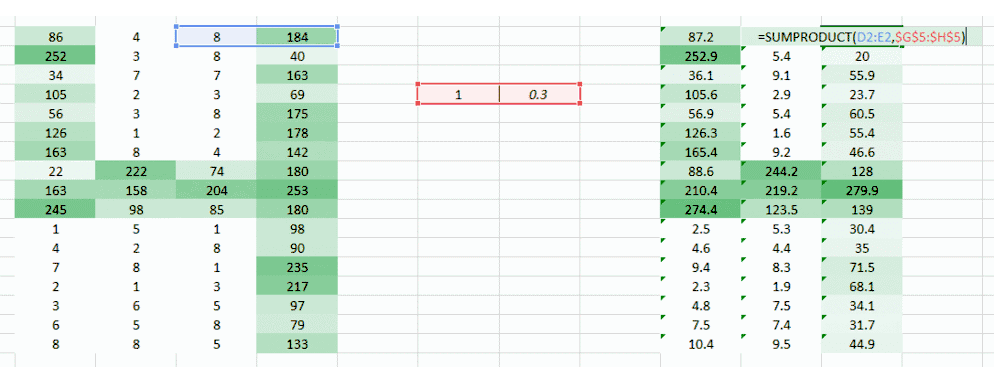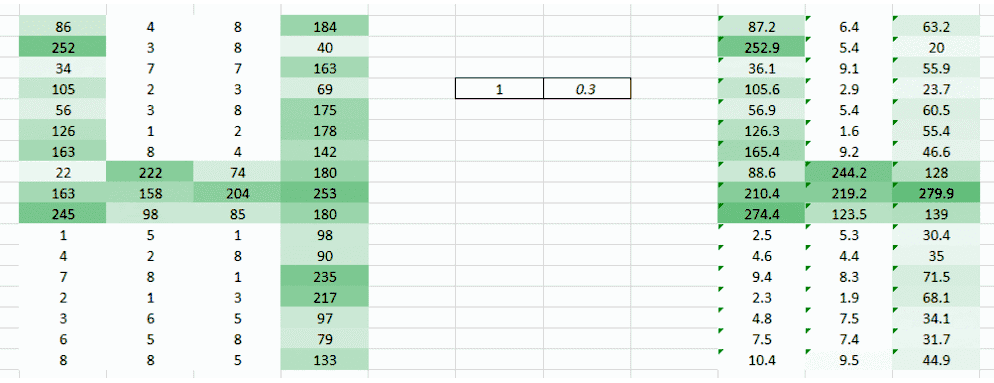
这里我们试图解决的问题是右侧角落更小的权重值正在降低像素值,因此使其难以被我们识别。我们所能做的是采取多个权重值并将其结合起来。
(1,0.3) 的权重值给了我们一个输出表格
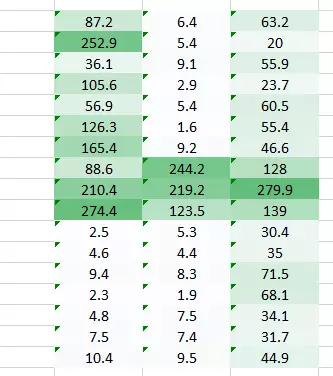
同时表格 (0.1,5) 的权重值也将给我们一个输出表格。
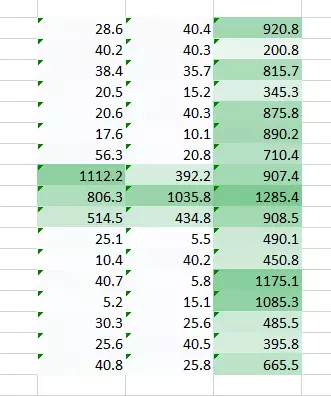
两张图像的结合版本将会给我们一个清晰的图片。因此,我们所做的是简单地使用多个权重而不是一个,从而再训练图像的更多信息。最终结果将是上述两张图像的一个结合版本。
案例五
我们到现在通过使用权重,试图把水平像素(horizontal pixel)结合起来。但是大多数情况下我们需要在水平和垂直方向上保持空间布局。我们采取 2D 矩阵权重,把像素在水平和垂直方向上结合起来。同样,记住已经有了水平和垂直方向的权重运动,输出会在水平和垂直方向上低一个像素。

所以我们做了什么?
上面我们所做的事是试图通过使用图像的空间的安排从图像中提取特征。为了理解图像,理解像素如何安排对于一个网络极其重要。上面我们所做的也恰恰是一个卷积网络所做的。我们可以采用输入图像,定义权重矩阵,并且输入被卷积以从图像中提取特殊特征而无需损失其有关空间安排的信息。
这个方法的另一个重大好处是它可以减少图像的参数数量。正如所见,卷积图像相比于原始图像有更少的像素。
2 :什么是神经网络?
这里的神经网络,也指人工神经网络(Artificial Neural Networks,简称ANNs),是一种模仿生物神经网络行为特征的算法数学模型,由神经元、节点与节点之间的连接(突触)所构成,如下图:
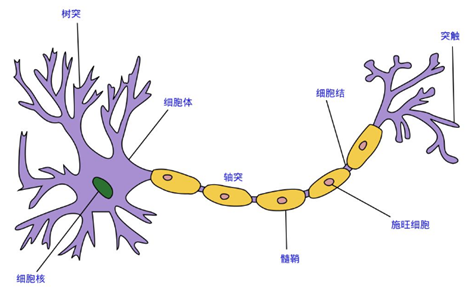
每个神经网络单元抽象出来的数学模型如下,也叫感知器,它接收多个输入(x1,x2,x3...),产生一个输出,这就好比是神经末梢感受各种外部环境的变化(外部刺激),然后产生电信号,以便于转导到神经细胞(又叫神经元)。

单个的感知器就构成了一个简单的模型,但在现实世界中,实际的决策模型则要复杂得多,往往是由多个感知器组成的多层网络,如下图所示,这也是经典的神经网络模型,由输入层、隐含层、输出层构成。

人工神经网络可以映射任意复杂的非线性关系,具有很强的鲁棒性、记忆能力、自学习等能力,在分类、预测、模式识别等方面有着广泛的应用。
3 :什么是卷积神经网络?
卷积神经网络是近年发展起来的,并引起广泛重视的一种高效识别方法,20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。 K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。
这听起来像是一个奇怪的生物学和数学的结合,但是这些网络已经成为计算机视觉领域最具影响力的创新之一。2012年是神经网络成长的第一年,Alex Krizhevsky用它们赢得了当年的ImageNet竞赛(基本上是计算机视觉年度奥运会),把分类错误记录从26%降到了15%,这个惊人的提高从那以后,许多公司一直在以服务为核心进行深度学习。Facebook使用自动标记算法的神经网络,谷歌的照片搜索,亚马逊的产品推荐,Pinterest的家庭饲料个性化和Instagram的搜索基础设施。
一般的,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形,该部分功能主要由池化层实现。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
说了这么多,接下来将以图像识别为例子,来介绍卷积神经网络的原理。
3.1 案例
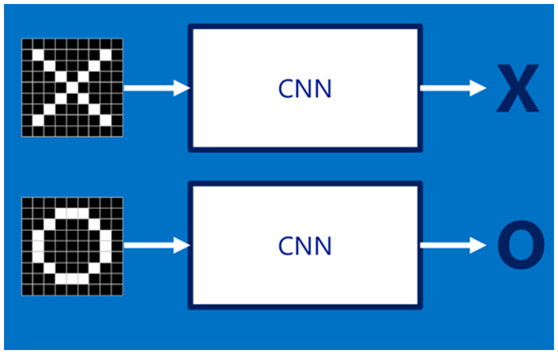
假设给定一张图(可能是字母X或者字母O),通过CNN即可识别出是X还是O,如下图所示,那怎么做到的呢
3.2 图像输入
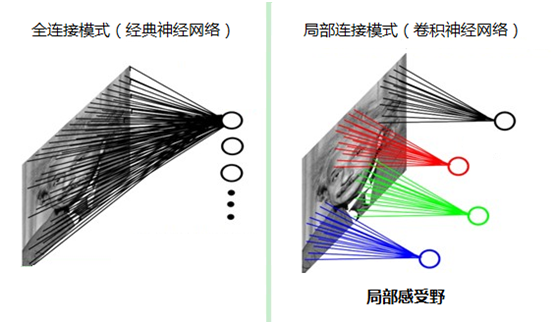
如果采用经典的神经网络模型,则需要读取整幅图像作为神经网络模型的输入(即全连接的方式),当图像的尺寸越大时,其连接的参数将变得很多,从而导致计算量非常大。
而我们人类对外界的认知一般是从局部到全局,先对局部有感知的认识,再逐步对全体有认知,这是人类的认识模式。在图像中的空间联系也是类似,局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。这种模式就是卷积神经网络中降低参数数目的重要神器:局部感受野。
3.3 提取特征
如果字母X、字母O是固定不变的,那么最简单的方式就是图像之间的像素一一比对就行,但在现实生活中,字体都有着各个形态上的变化(例如手写文字识别),例如平移、缩放、旋转、微变形等等,如下图所示:
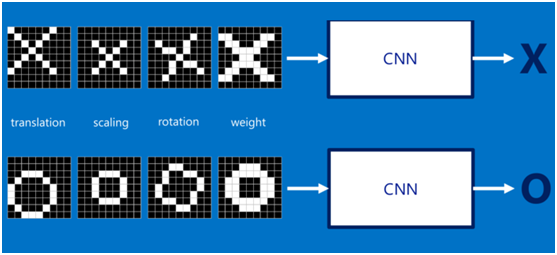
我们的目标是对于各种形态变化的X和O,都能通过CNN准确地识别出来,这就涉及到应该如何有效地提取特征,作为识别的关键因子。
回想前面讲到的“局部感受野”模式,对于CNN来说,它是一小块一小块地来进行比对,在两幅图像中大致相同的位置找到一些粗糙的特征(小块图像)进行匹配,相比起传统的整幅图逐一比对的方式,CNN的这种小块匹配方式能够更好的比较两幅图像之间的相似性。如下图:
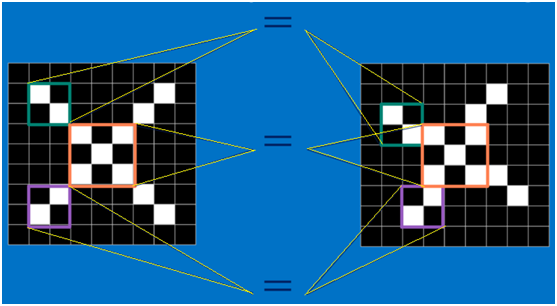
以字母X为例,可以提取出三个重要特征(两个交叉线、一个对角线),如下图所示:
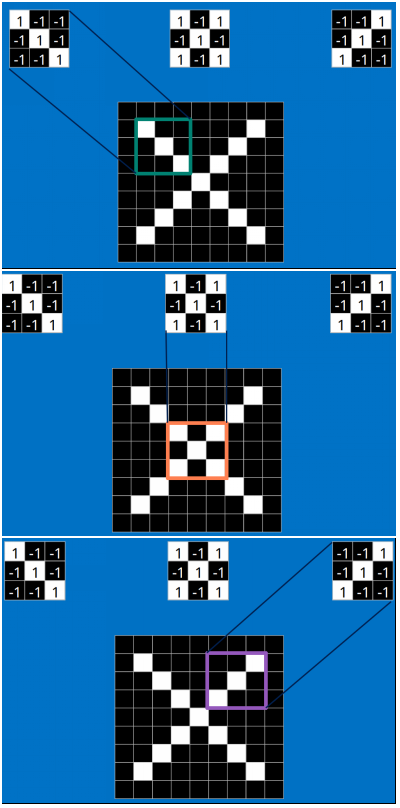
假如以像素值"1"代表白色,像素值"-1"代表黑色,则字母X的三个重要特征如下:

那么这些特征又是怎么进行匹配计算呢?
3.4 卷积(convolution)
这时就要请出今天的重要嘉宾:卷积。那什么是卷积呢,不急,下面慢慢道来。
当给定一张新图时,CNN并不能准确地知道这些特征到底要匹配原图的哪些部分,所以它会在原图中把每一个可能的位置都进行尝试,相当于把这个feature(特征)变成了一个过滤器。这个用来匹配的过程就被称为卷积操作,这也是卷积神经网络名字的由来。
卷积的操作如下图所示:
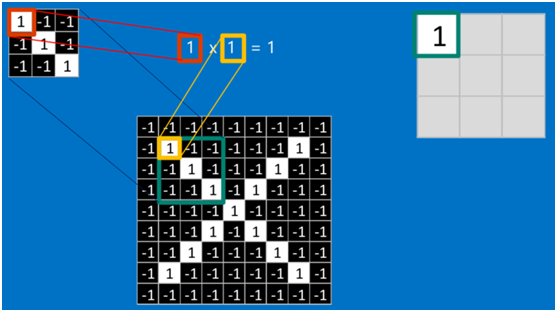
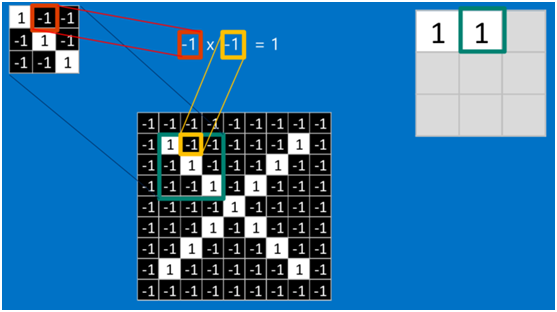
是不是很像把毛巾沿着对角卷起来,下图形象地说明了为什么叫「卷」积

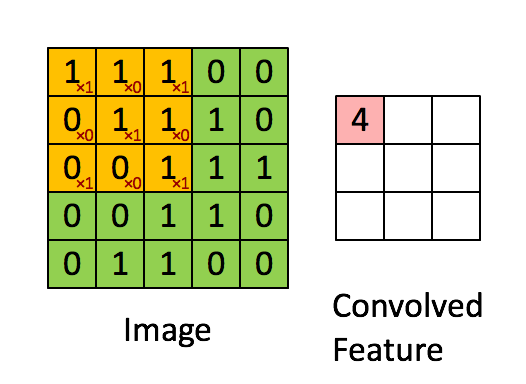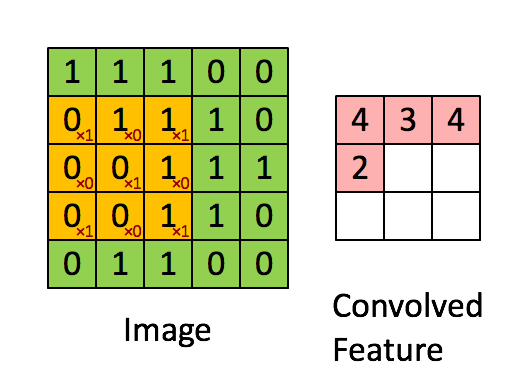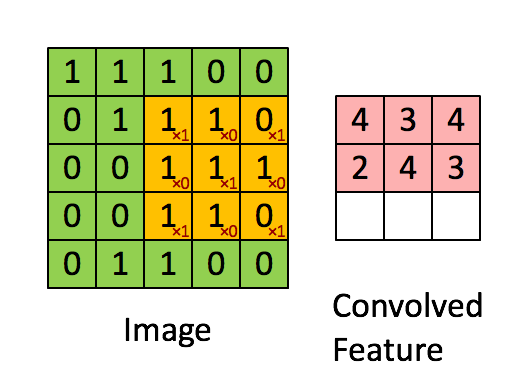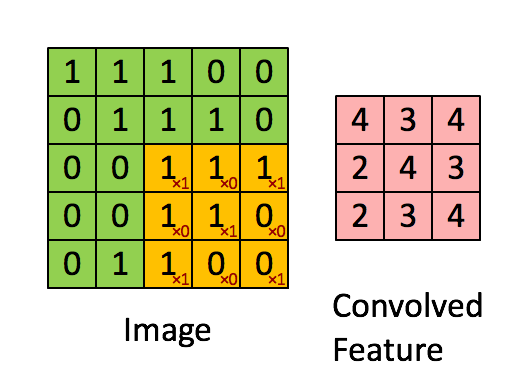
在本案例中,要计算一个feature(特征)和其在原图上对应的某一小块的结果,只需将两个小块内对应位置的像素值进行乘法运算,然后将整个小块内乘法运算的结果累加起来,最后再除以小块内像素点总个数即可(注:也可不除以总个数的)。
如果两个像素点都是白色(值均为1),那么1*1 = 1,如果均为黑色,那么(-1)*(-1) = 1,也就是说,每一对能够匹配上的像素,其相乘结果为1。类似地,任何不匹配的像素相乘结果为-1。具体过程如下(第一个、第二个……、最后一个像素的匹配结果):

根据卷积的计算方式,第一块特征匹配后的卷积计算如下,结果为1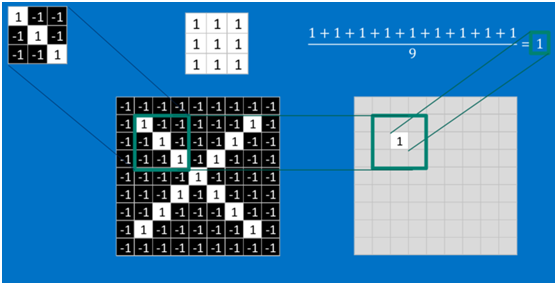
对于其它位置的匹配,也是类似(例如中间部分的匹配)
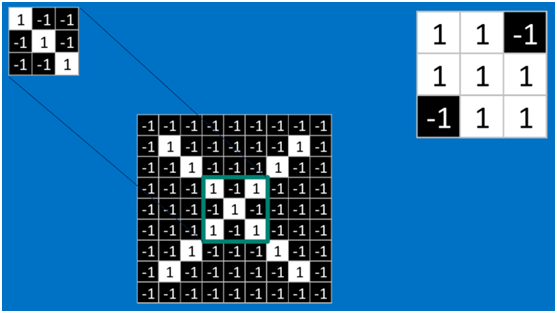
计算之后的卷积如下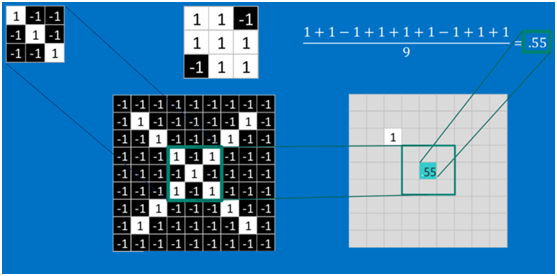
以此类推,对三个特征图像不断地重复着上述过程,通过每一个feature(特征)的卷积操作,会得到一个新的二维数组,称之为feature map。其中的值,越接近1表示对应位置和feature的匹配越完整,越是接近-1,表示对应位置和feature的反面匹配越完整,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。如下图所示:
可以看出,当图像尺寸增大时,其内部的加法、乘法和除法操作的次数会增加得很快,每一个filter的大小和filter的数目呈线性增长。由于有这么多因素的影响,很容易使得计算量变得相当庞大。
3.5 池化(Pooling)
为了有效地减少计算量,CNN使用的另一个有效的工具被称为“池化(Pooling)”。池化就是将输入图像进行缩小,减少像素信息,只保留重要信息。
池化的操作也很简单,通常情况下,池化区域是2*2大小,然后按一定规则转换成相应的值,例如取这个池化区域内的最大值(max-pooling)、平均值(mean-pooling)等,以这个值作为结果的像素值。
下图显示了左上角2*2池化区域的max-pooling结果,取该区域的最大值max(0.77,-0.11,-0.11,1.00),作为池化后的结果,如下图: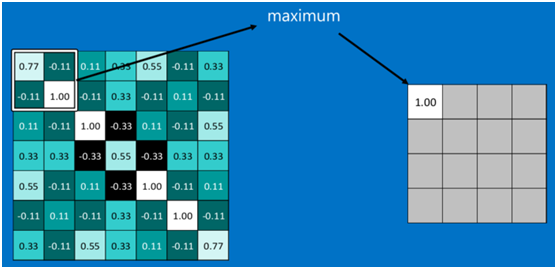
池化区域往左,第二小块取大值max(0.11,0.33,-0.11,0.33),作为池化后的结果,如下图: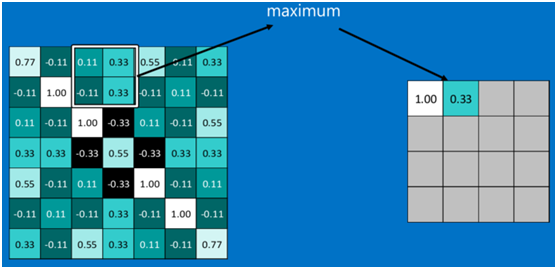
其它区域也是类似,取区域内的最大值作为池化后的结果,最后经过池化后,结果如下: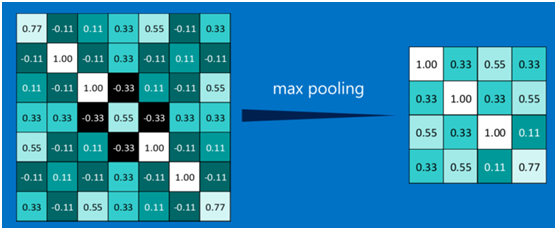
对所有的feature map执行同样的操作,结果如下:
最大池化(max-pooling)保留了每一小块内的最大值,也就是相当于保留了这一块最佳的匹配结果(因为值越接近1表示匹配越好)。也就是说,它不会具体关注窗口内到底是哪一个地方匹配了,而只关注是不是有某个地方匹配上了。
通过加入池化层,图像缩小了,能很大程度上减少计算量,降低机器负载。
3.6 激活函数RelU (Rectified Linear Units)
常用的激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者ReLU常见于卷积层。
回顾一下前面讲的感知机,感知机在接收到各个输入,然后进行求和,再经过激活函数后输出。激活函数的作用是用来加入非线性因素,把卷积层输出结果做非线性映射。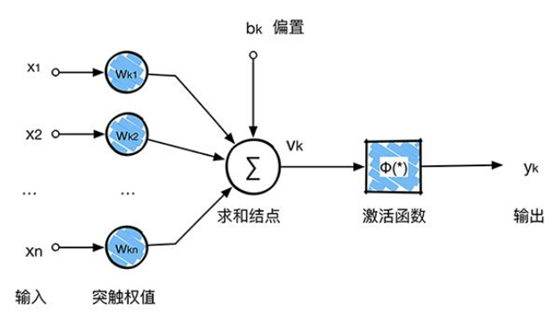
在卷积神经网络中,激活函数一般使用ReLU(The Rectified Linear Unit,修正线性单元),它的特点是收敛快,求梯度简单。计算公式也很简单,max(0,T),即对于输入的负值,输出全为0,对于正值,则原样输出。
下面看一下本案例的ReLU激活函数操作过程:
第一个值,取max(0,0.77),结果为0.77,如下图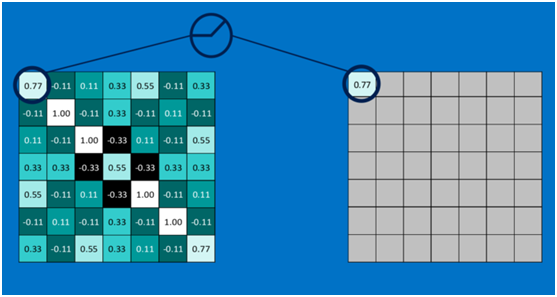
第二个值,取max(0,-0.11),结果为0,如下图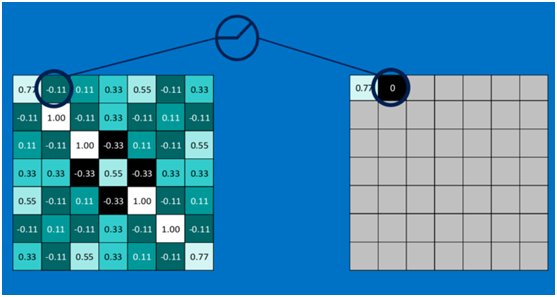
以此类推,经过ReLU激活函数后,结果如下: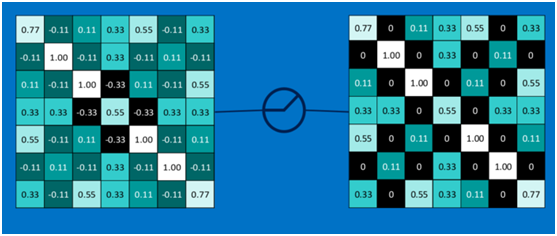
对所有的feature map执行ReLU激活函数操作,结果如下:
3.7 深度神经网络
通过将上面所提到的卷积、激活函数、池化组合在一起,就变成下图: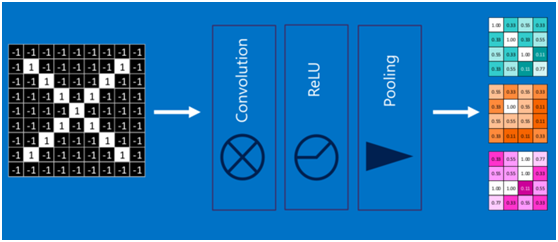
通过加大网络的深度,增加更多的层,就得到了深度神经网络,如下图: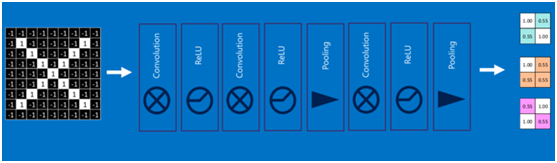
3.8 全连接层(Fully connected layers)
全连接层在整个卷积神经网络中起到“分类器”的作用,即通过卷积、激活函数、池化等深度网络后,再经过全连接层对结果进行识别分类。
首先将经过卷积、激活函数、池化的深度网络后的结果串起来,如下图所示: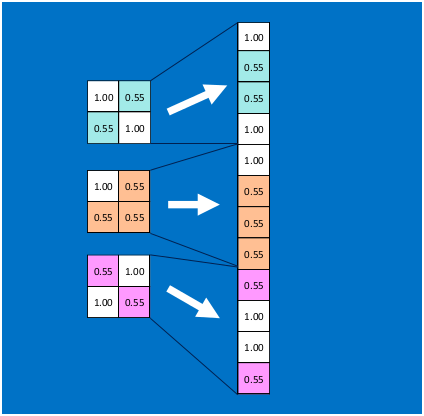
由于神经网络是属于监督学习,在模型训练时,根据训练样本对模型进行训练,从而得到全连接层的权重(如预测字母X的所有连接的权重)

在利用该模型进行结果识别时,根据刚才提到的模型训练得出来的权重,以及经过前面的卷积、激活函数、池化等深度网络计算出来的结果,进行加权求和,得到各个结果的预测值,然后取值最大的作为识别的结果(如下图,最后计算出来字母X的识别值为0.92,字母O的识别值为0.51,则结果判定为X)
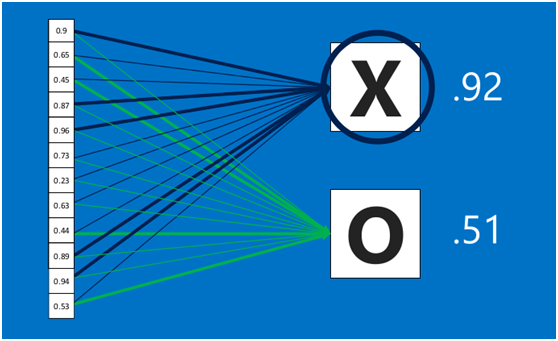
上述这个过程定义的操作为”全连接层“(Fully connected layers),全连接层也可以有多个,如下图:
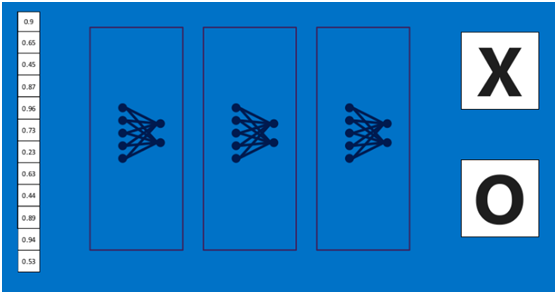
3.9 卷积神经网络(Convolutional Neural Networks)
将以上所有结果串起来后,就形成了一个“卷积神经网络”(CNN)结构,如下图所示:
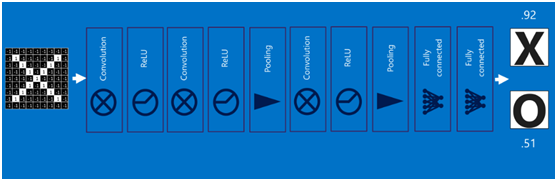
最后,再回顾总结一下,卷积神经网络主要由两部分组成,一部分是特征提取(卷积、激活函数、池化),另一部分是分类识别(全连接层),下图便是著名的手写文字识别卷积神经网络结构图: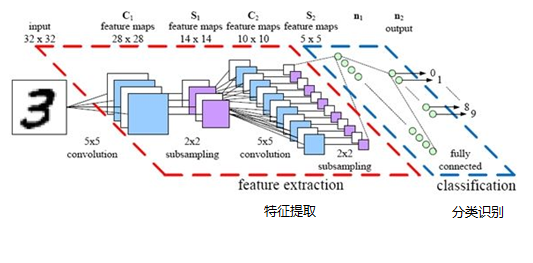
3.10 对卷积神经网络的总结
卷积网络在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。
CNN一个非常重要的特点就是头重脚轻(越往输入权值越小,越往输出权值越多),呈现出一个倒三角的形态,这就很好地避免了BP神经网络中反向传播的时候梯度损失得太快。
卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
四:常见的几种卷积神经网络介绍
目前图像分类中的ResNet, 目标检测领域占统治地位的Faster R-CNN,分割中最牛的Mask-RCNN, UNet和经典的FCN都是以下面几种常见网络为基础。
一:LeNet
1.1 网络背景
LeNet诞生于1994年,由深度学习三巨头之一的Yan LeCun提出,他也被称为卷积神经网络之父。LeNet主要用来进行手写字符的识别与分类,准确率达到了98%,并在美国的银行中投入了使用,被用于读取北美约10%的支票。LeNet奠定了现代卷积神经网络的基础。
1.2 网络结构
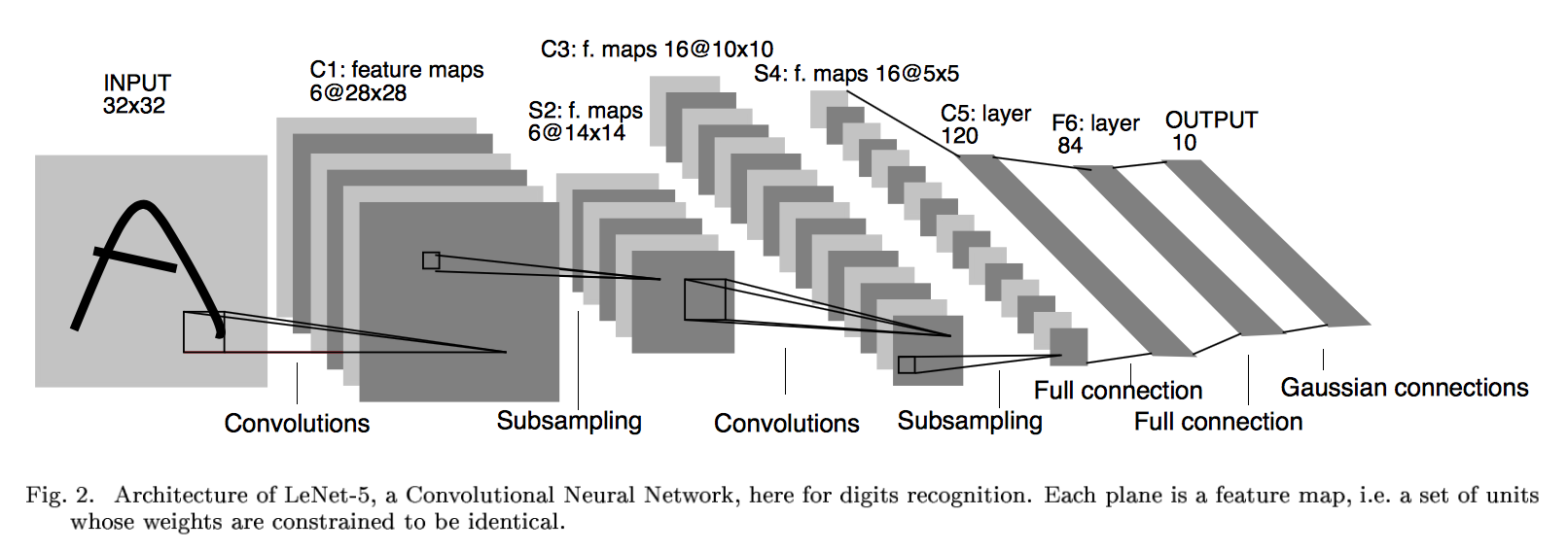
上图为LeNet结构图,是一个6层网络结构:三个卷积层,两个下采样层和一个全连接层(图中C代表卷积层,S代表下采样层,F代表全连接层)。其中,C5层也可以看成是一个全连接层,因为C5层的卷积核大小和输入图像的大小一致,都是5*5(可参考LeNet详细介绍)。
1.3 网络特点
- 每个卷积层包括三部分:卷积、池化和非线性激活函数(sigmoid激活函数)
- 使用卷积提取空间特征
- 降采样层采用平均池化
1.4 网络讲义









二:AlexNet
2.1 网络背景
AlexNet由Hinton的学生Alex Krizhevsky于2012年提出,并在当年取得了Imagenet比赛冠军。AlexNet可以算是LeNet的一种更深更宽的版本,证明了卷积神经网络在复杂模型下的有效性,算是神经网络在低谷期的第一次发声,确立了深度学习,或者说卷积神经网络在计算机视觉中的统治地位。
2.2 网络结构
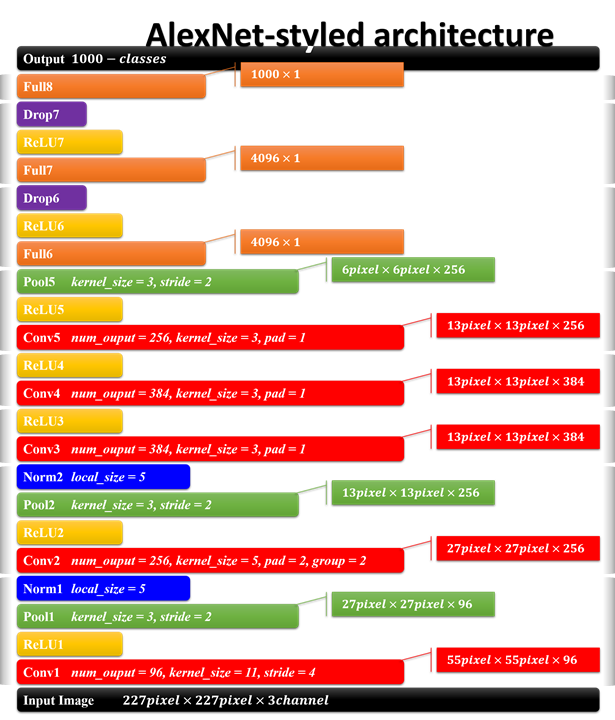
AlexNet的结构及参数如上图所示,是8层网络结构(忽略激活,池化,LRN,和dropout层),有5个卷积层和3个全连接层,第一卷积层使用大的卷积核,大小为11*11,步长为4,第二卷积层使用5*5的卷积核大小,步长为1,剩余卷积层都是3*3的大小,步长为1。激活函数使用ReLu(虽然不是他发明,但是他将其发扬光大),池化层使用重叠的最大池化,大小为3*3,步长为2。在全连接层增加了dropout,第一次将其实用化。(参考:AlexNet详细解释)
2.3 网络特点
- 使用两块GPU并行加速训练,大大降低了训练时间
- 成功使用ReLu作为激活函数,解决了网络较深时的梯度弥散问题
- 使用数据增强、dropout和LRN层来防止网络过拟合,增强模型的泛化能力
三:VGGNet
3.1 网络背景
VGGNet是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,并取得了2014年Imagenet比赛定位项目第一名和分类项目第二名。该网络主要是泛化性能很好,容易迁移到其他的图像识别项目上,可以下载VGGNet训练好的参数进行很好的初始化权重操作,很多卷积神经网络都是以该网络为基础,比如FCN,UNet,SegNet等。vgg版本很多,常用的是VGG16,VGG19网络。
3.2 网络结构

上图为VGG16的网络结构,共16层(不包括池化和softmax层),所有的卷积核都使用3*3的大小,池化都使用大小为2*2,步长为2的最大池化,卷积层深度依次为64 -> 128 -> 256 -> 512 ->512。
3.3 网络特点
网络结构和AlexNet有点儿像,不同的地方在于:
- 主要的区别,一个字:深,两个字:更深。把网络层数加到了16-19层(不包括池化和softmax层),而AlexNet是8层结构。
- 将卷积层提升到卷积块的概念。卷积块有2~3个卷积层构成,使网络有更大感受野的同时能降低网络参数,同时多次使用ReLu激活函数有更多的线性变换,学习能力更强(详细介绍参考:TensorFlow实战P110页)。
- 在训练时和预测时使用Multi-Scale做数据增强。训练时将同一张图片缩放到不同的尺寸,在随机剪裁到224*224的大小,能够增加数据量。预测时将同一张图片缩放到不同尺寸做预测,最后取平均值。
四:ResNet
4.1 网络背景
ResNet(残差神经网络)由微软研究院的何凯明等4名华人于2015年提出,成功训练了152层超级深的卷积神经网络,效果非常突出,而且容易结合到其他网络结构中。在五个主要任务轨迹中都获得了第一名的成绩:
- ImageNet分类任务:错误率3.57%
- ImageNet检测任务:超过第二名16%
- ImageNet定位任务:超过第二名27%
- COCO检测任务:超过第二名11%
- COCO分割任务:超过第二名12%
作为大神级人物,何凯明凭借Mask R-CNN论文获得ICCV2017最佳论文,也是他第三次斩获顶会最佳论文,另外,他参与的另一篇论文:Focal Loss for Dense Object Detection,也被大会评为最佳学生论文。
4.2 网络结构

上图为残差神经网络的基本模块(专业术语叫残差学习单元),输入为x,输出为F(x)+x,F(x)代表网络中数据的一系列乘、加操作,假设神经网络最优的拟合结果输出为H(x)=F(x)+x,那么神经网络最优的F(x)即为H(x)与x的残差,通过拟合残差来提升网络效果。为什么转变为拟合残差就比传统卷积网络要好呢?因为训练的时候至少可以保证残差为0,保证增加残差学习单元不会降低网络性能,假设一个浅层网络达到了饱和的准确率,后面再加上这个残差学习单元,起码误差不会增加。(参考:ResNet详细解释)
通过不断堆叠这个基本模块,就可以得到最终的ResNet模型,理论上可以无限堆叠而不改变网络的性能。下图为一个34层的ResNet网络。

4.3 网络特点
- 使得训练超级深的神经网络成为可能,避免了不断加深神经网络,准确率达到饱和的现象(后来将层数增加到1000层)
- 输入可以直接连接到输出,使得整个网络只需要学习残差,简化学习目标和难度。
- ResNet是一个推广性非常好的网络结构,容易和其他网络结合
五:几张常见的卷积神经网络论文地址:
1. LeNet论文
2. AlexNet论文
3. VGGNet论文
4. ResNet论文
参考文献:https://www.sumaarts.com/share/620.html
https://blog.csdn.net/qq_34759239/article/details/79034849
https://my.oschina.net/u/876354/blog/1620906
https://baike.baidu.com/item/%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C/17541100?fr=aladdin
LeNet-5课件学习参考:https://www.cnblogs.com/gujianhan/p/6245932.html
深入学习卷积神经网络(CNN)的原理知识的更多相关文章
- 卷积神经网络CNN的原理(一)---基本概念
什么是卷积神经网络呢?这个的确是比较难搞懂的概念,特别是一听到神经网络,大家脑海中第一个就会想到复杂的生物学,让人不寒而栗,那么复杂啊.卷积神经网络是做什么用的呢?它到底是一个什么东东呢? 卷积神经网 ...
- 卷积神经网络CNN的原理(二)---公式推导
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含多个由卷积层和池化层构成的特征抽取器.在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接.在CNN的一个卷积层中,通常包含若干个特征平面( ...
- 卷积神经网络CNN的原理(三)---代码解析
卷积神经网络在几个主流的神经网络开源架构上面都有实现,我这里不是想实现一个自己的架构,主要是通过分析一个最简单的卷积神经网络实现代码,来达到进一步的加深理解卷积神经网络的目的. 笔者在github上找 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 卷积神经网络CNN学习笔记
CNN的基本结构包括两层: 特征提取层:每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征.一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来: 特征映射层:网络的每个计算层由多 ...
- 深度学习之卷积神经网络(CNN)详解与代码实现(一)
卷积神经网络(CNN)详解与代码实现 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10430073.html 目 ...
- 卷积神经网络CNN原理以及TensorFlow实现
在知乎上看到一段介绍卷积神经网络的文章,感觉讲的特别直观明了,我整理了一下.首先介绍原理部分. [透析] 卷积神经网络CNN究竟是怎样一步一步工作的? 通过一个图像分类问题介绍卷积神经网络是如何工作的 ...
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
随机推荐
- [SoapUI] 如何同时调用Global Script Library(放在SoapUI安装目录)和项目特有的Script Libary(放在项目代码下)
SoapUI 支持引入多个package: Global Script library : 在SoapUI工具File->Preference中设置Project Script Library: ...
- lamp环境搭建(apache安装,mysql安装,php安装)
1.卸载系统内置的LAMP环境 1)卸载httpd服务(内置Apache) ① 使用rpm指令查询安装的httpd服务 ② 卸载httpd服务 如果出现以上提示,代表系统默认不允许我们卸载软件,使用强 ...
- solr7.7.0搜索引擎使用(二)(添加搜索)
一.安装完毕之后,需要为solr添加core,每一个搜索server就是一个core,solr可以有很多core,我们需要创建一个core用于我们的搜索 添加core的方式有两种: 第一种进入solr ...
- Maven学习 五 Maven项目创建(1)jar项目
第一步:Maven项目的创建 File->new->Maven project. 点击下一步 上方的两个多选框选上,第一个是不使用archetype 原型模板,第二个是使用默认工作空间 点 ...
- python入门之两种方法修改文件内容
1.占硬盘修改 import os file_name="兼职.txt" new_file_name="%s.new".% file_name old_str= ...
- Visual Studio2013 配置opencv3.3.0 x64系统
注:小白一个,第一次写博客,可能会有一些理解上的错误,只此记录自己测试成功的坎坷之路,已备以后查看,同时给有需要之人. 我是win10 64 位,之前安装了visual studio 2013, 现在 ...
- JSP内置对象application
application对象实现了用户间数据的共享,可存放全局变量 application开始于服务器的启动,终止于服务器的关闭 在用户的前后连接或不同用户之间的连接中,可以对application对象 ...
- Java集合:LinkedList源码解析
Java集合---LinkedList源码解析 一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据re ...
- 20175316盛茂淞 2018-2019-2 《Java程序设计》第5周学习总结
20175316盛茂淞 2018-2019-2 <Java程序设计>第5周学习总结 教材学习内容总结 第六章 接口与实现. 何谓接口 接口:书上没有明确地给出接口的定义,我理解的接口就是一 ...
- leetcode记录
2019 1月31: 141交叉链表, 2月: 2/1: 160环形链表 , 思路记得,但是指针里面逻辑搞错,这里不是用快慢指针而是同时的指针.:复习了141题还是有问题,把 ...