MapReduce 过程详解
Hadoop 越来越火, 围绕Hadoop的子项目更是增长迅速, 光Apache官网上列出来的就十几个, 但是万变不离其宗, 大部分项目都是基于Hadoop common
MapReduce 更是核心中的核心。那么到底什么是MapReduce, 它具体是怎么工作的呢?
关于它的原理, 说简单也简单, 随便画个图喷一下Map 和 Reduce两个阶段似乎就完了。 但其实这里面还包含了Sort, Partition, Shuffle, Combine, Merge等子阶段,尤其是Shuffle, 很多资料里都把它称为MapReduce的“心脏”, 和所谓“奇迹发生的地方”。真正能说清楚其中关系的人就没那么多了。可是了解这些流程对我们理解和掌握MapReduce 并对其进行调优是非常有用的。
本文名为详解, 其实笔者水平有限, 也就是结合自己的一些理解争取能够深入浅出地描述一下整个过程, 如有错误, 敬请指出。
首先我们看一副图, 包含了从头到尾的整个过程, 后面对所有步骤的解释都以此图作为参考 (此图100%原创)
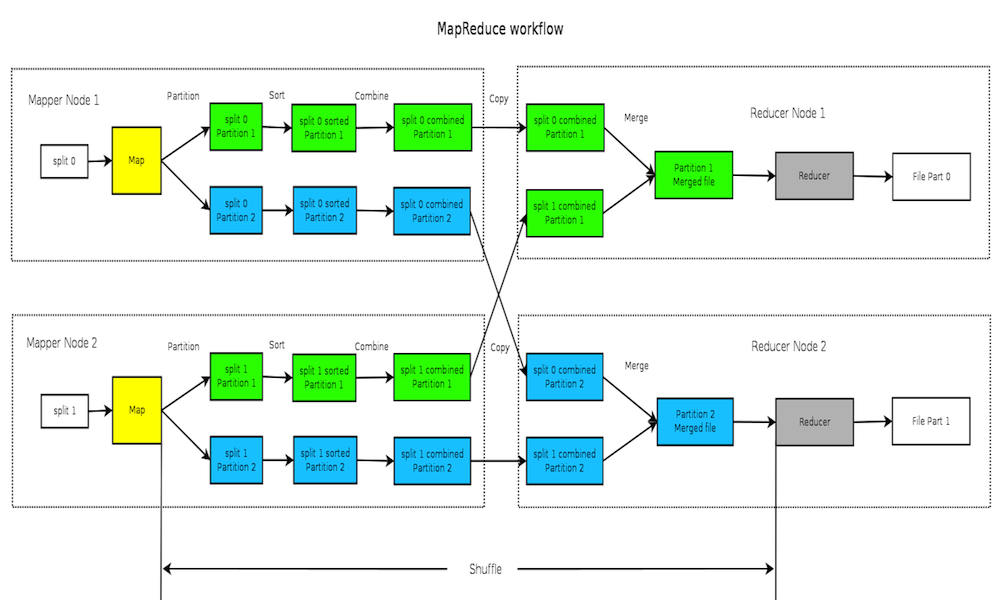
这张图简单来说, 就是说在我们常见的Map 和 Reduce 之间还有一系列的过程, 其中包括Partition, Sort, Combine, Copy, Merge等. 而这些过程往往被统称为"Shuffle" 也就是 “混洗”. 而Shuffle 的目的就是对数据进行梳理,排序,以更科学的方式分发给每个Reducer,以便能够更高效地进行计算和处理。 (难怪人家说这是奇迹发生的地方, 原来这里面有这么多花花, 能没奇迹么?)
如果您是Hadoop的大牛, 看了这幅图可能马上要跳出来了, 不对! 还有一个spill 过程云云...
且慢, 关于spill, 我认为只是一个实现细节, 其实就是MapReduce利用内存缓冲的方式提高效率, 整个的过程和原理并没有受影响, 所以在此处忽略掉spill 过程, 以便更好理解。
光看原理图还是有点费解是吧? 没错! 雷子一直认为, 没有例子的文章就是耍流氓 :) 所以我们就用大家都耳熟能详的WordCount 作为例子, 开始我们的讨论。
先创建两个文本文件, 作为我们例子的输入:
File 1 内容:
My name is Tony
My company is pivotal File 2 内容:
My name is Lisa
My company is EMC
1. 第一步, Map
顾名思义, Map 就是拆解.
首先我们的输入就是两个文件, 默认情况下就是两个split, 对应前面图中的split 0, split 1
两个split 默认会分给两个Mapper来处理, WordCount例子相当地暴力, 这一步里面就是直接把文件内容分解为单词和 1 (注意, 不是具体数量, 就是数字1)其中的单词就是我们的主健,也称为Key, 后面的数字就是对应的值,也称为value.
那么对应两个Mapper的输出就是:
split 0
My 1
name 1
is 1
Tony 1
My 1
company 1
is 1
Pivotal 1
split 1
My 1
name 1
is 1
Lisa 1
My 1
company 1
is 1
EMC 1
2. Partition
Partition 是什么? Partition 就是分区。
为什么要分区? 因为有时候会有多个Reducer, Partition就是提前对输入进行处理, 根据将来的Reducer进行分区. 到时候Reducer处理的时候, 只需要处理分给自己的数据就可以了。
如何分区? 主要的分区方法就是按照Key 的不同,把数据分开,其中很重要的一点就是要保证Key的唯一性, 因为将来做Reduce的时候有可能是在不同的节点上做的, 如果一个Key同时存在于两个节点上, Reduce的结果就会出问题, 所以很常见的Partition方法就是哈希。
结合我们的例子, 我们这里假设有两个Reducer, 前面两个split 做完Partition的结果就会如下:
split 0
Partition 1:
company 1
is 1
is 1
Partition 2:
My 1
My 1
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
is 1
is 1
EMC 1
Partition 2:
My 1
My 1
name 1
Lisa 1
其中Partition 1 将来是准备给Reducer 1 处理的, Partition 2 是给Reducer 2 的
这里我们可以看到, Partition 只是把所有的条目按照Key 分了一下区, 没有其他任何处理, 每个区里面的Key 都不会出现在另外一个区里面。
3. Sort
Sort 就是排序喽, 其实这个过程在我来看并不是必须的, 完全可以交给客户自己的程序来处理。 那为什么还要排序呢? 可能是写MapReduce的大牛们想,“大部分reduce 程序应该都希望输入的是已经按Key排序好的数据, 如果是这样, 那我们就干脆顺手帮你做掉啦, 请叫我雷锋!” ......好吧, 你是雷锋.
那么我们假设对前面的数据再进行排序, 结果如下:
split 0
Partition 1:
company 1
is 1
is 1
Partition 2:
My 1
My 1
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
EMC 1
is 1
is 1 Partition 2:
Lisa 1
My 1
My 1
name 1
这里可以看到, 每个partition里面的条目都按照Key的顺序做了排序
4. Combine
什么是Combine呢? Combine 其实可以理解为一个mini Reduce 过程, 它发生在前面Map的输出结果之后, 目的就是在结果送到Reducer之前先对其进行一次计算, 以减少文件的大小, 方便后面的传输。 但这步也不是必须的。
按照前面的输出, 执行Combine:
split 0
Partition 1:
company 1
is 2 Partition 2:
My 2
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
EMC 1
is 2 Partition 2:
Lisa 1
My 2
name 1
我们可以看到, 针对前面的输出结果, 我们已经局部地统计了is 和My的出现频率, 减少了输出文件的大小。
5. Copy
下面就要准备把输出结果传送给Reducer了。 这个阶段被称为Copy, 但事实上雷子认为叫他Download更为合适, 因为实现的时候, 是通过http的方式, 由Reducer节点向各个mapper节点下载属于自己分区的数据。
那么根据前面的Partition, 下载完的结果如下:
Reducer 节点 1 共包含两个文件:
Partition 1:
company 1
is 2
Partition 1:
company 1
EMC 1
is 2
Reducer 节点 2 也是两个文件:
My 2
name 1
Pivotal 1
Tony 1
Partition 2:
Lisa 1
My 2
name 1
这里可以看到, 通过Copy, 相同Partition 的数据落到了同一个节点上。
6. Merge
如上一步所示, 此时Reducer得到的文件是从不同Mapper那里下载到的, 需要对他们进行合并为一个文件, 所以下面这一步就是Merge, 结果如下:
Reducer 节点 1
company 1
company 1
EMC 1
is 2
is 2
Reducer 节点 2
Lisa 1
My 2
My 2
name 1
name 1
Pivotal 1
Tony 1
7. Reduce
终于可以进行最后的Reduce 啦...这步相当简单喽, 根据每个文件中的内容最后做一次统计, 结果如下:
Reducer 节点 1
company 2
EMC 1
is 4
Reducer 节点 2
Lisa 1
My 4
name 2
Pivotal 1
Tony 1
至此大功告成! 我们成功统计出两个文件里面每个单词的数目, 同时把它们存入到两个输出文件中, 这两个输出文件也就是传说中的 part-r-00000 和 part-r-00001, 看看两个文件的内容, 再回头想想最开始的Partition, 应该是清楚了其中的奥秘吧。
如果你在你自己的环境中运行的WordCount只有part-r-00000一个文件的话, 那应该是因为你使用的是默认设置, 默认一个job只有一个reducer
如果你想设两个, 你可以:
1. 在源代码中加入 job.setNumReduceTasks(2), 设置这个job的Reducer为两个
或者
2. 在 mapred-site.xml 中设置下面参数并重启服务
<property>
<name>mapred.reduce.tasks</name>
<value>2</value>
</property>
这样, 整个集群都会默认使用两个Reducer
结束语:
本文大致描述了一下MapReduce的整个过程以及每个阶段所作的事情, 并没有涉及具体的job,resource的管理和控制, 因为那个是第一代MapReduce框架和Yarn框架的主要区别。 而两代框架中上述MapReduce 的原理是差不多的,希望对大家有所帮助。
版权声明:
本文由 雷子-晓飞爸 所有,发布于http://www.cnblogs.com/npumenglei/ 如果转载,请注明出处,在未经作者同意下将本文用于商业用途,将追究其法律责任。
MapReduce 过程详解的更多相关文章
- MapReduce过程详解(基于hadoop2.x架构)
本文基于hadoop2.x架构详细描述了mapreduce的执行过程,包括partition,combiner,shuffle等组件以及yarn平台与mapreduce编程模型的关系. mapredu ...
- MapReduce过程详解及其性能优化
http://blog.csdn.net/aijiudu/article/details/72353510 废话不说直接来一张图如下: 从JVM的角度看Map和Reduce Map阶段包括: 第一读数 ...
- MapReduce 过程详解 (用WordCount作为例子)
本文转自 http://www.cnblogs.com/npumenglei/ .... 先创建两个文本文件, 作为我们例子的输入: File 1 内容: My name is Tony My com ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- mapreduce框架详解
hadoop 学习笔记:mapreduce框架详解 开始聊mapreduce,mapreduce是hadoop的计算框架,我学hadoop是从hive开始入手,再到hdfs,当我学习hdfs时候,就感 ...
- hadoop1.2.1+zk-3.4.5+hbase-0.94.1集群安装过程详解
hadoop1.2.1+zk-3.4.5+hbase-0.94.1集群安装过程详解 一,环境: 1,主机规划: 集群中包括3个节点:hadoop01为Master,其余为Salve,节点之间局域网连接 ...
- TortoiseGIT的安装过程详解
TortoiseGIT简介 TortoiseGIT 是Git版本控制系统的一个免费开源客户端,它是git版本控制的 Windows 扩展.可以使你避免使用枯燥而且不方便的命令行.它完全嵌入 Windo ...
随机推荐
- IO流_演示键盘录入
读取一个键盘录入的数据,打印到控制台上 键盘本身就是一个标准的输入设备,对于java而言,对于这种输入设备都有相应的对象在System类中 import java.io.IOException; im ...
- django生命周期和事件委派
这是事件委派如果不用事件委派 直接绑定的话,新添加的按钮不会有删除或者编辑的功能 上面是事件委派的代码 新添加的编辑按钮可以弹出123 django生命周期: 这是Django的生命周期 首先会通 ...
- swift 该死的派发机制--待完成
swift 该死的派发机制 final static oc类型 多态类型 静态类型 动态函数 静态函数 nsobject: 1.缺省不再使用oc的动态派发机制: 2.可以使用nsobject暴露出来 ...
- gitlab 数据同步
为了统一化管理,需要把老版本的 gitlab 仓库 同步到新的gitlab上. 1. 新建组, 新gitlab 建立的group 与 原gitlab相同.2. 新建project 3. 选择导入
- 上传文件异常 MultipartException
参考自 https://blog.csdn.net/u010429286/article/details/54381705 现象 上传文件报错 org.springframework.web.mul ...
- mysql explain(转)
explain显示了mysql如何使用索引来处理select和表连接 转自http://blog.csdn.net/zhuxineli/article/details/14455029 explain ...
- vue 路由的基本使用
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 恶意软件的bypass
导读 在网络安全的背景下,尽管存在反恶意软件控制,但逃避是执行恶意代码的做法.这种策略不会利用可修复的缺陷.相反,他们利用阻止现实世界中恶意软件检测的因素来实现其完整的理论潜力. 恶意软件这些逃避因素 ...
- 理解 boxsizing
理解boxsizing 什么是css盒模型?css盒模型包括如下属性:内容(content),填充(padding),边框(border),边界(margin). 这些东西我们可以拿日常生活中的列子来 ...
- linux安装sonar
第一步 使用上一篇博客中下载的sonar6.7.6上传到centos7 准备 安装jdk1.8 解压unzip sonarqube-6.7.6.zip 由于elasticsearch需要非root用户 ...