python爬虫简单代码爬取郭德纲单口相声
搜索老郭的单口相声,打开检查模式,刷新
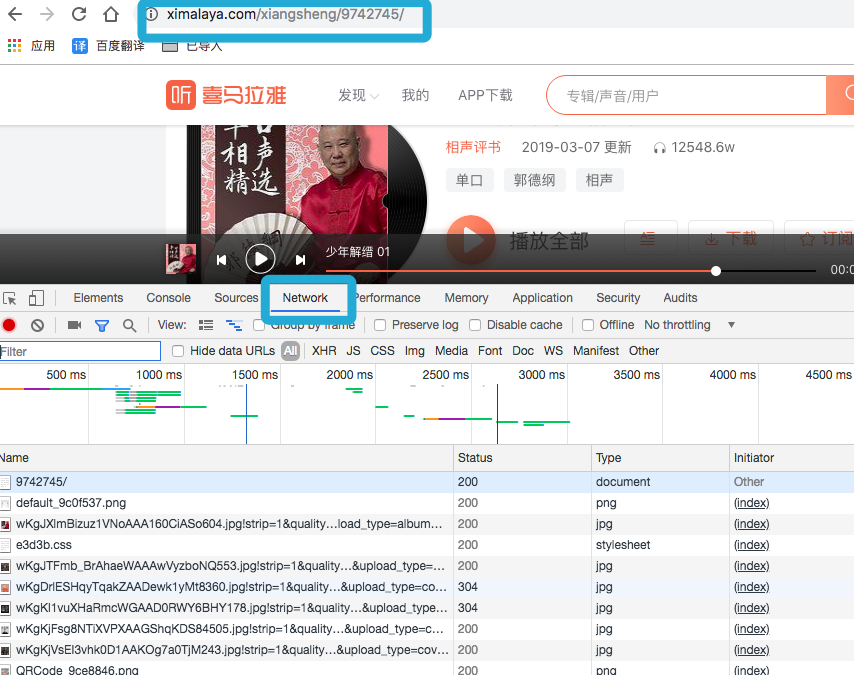
没有什么有价值的东东, 不过....清掉内容, 点击一个相声,再看看有些什么
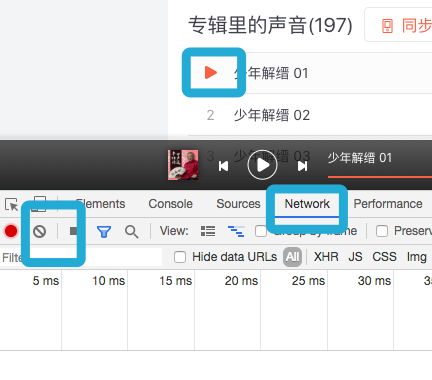
是不是发现了些什么
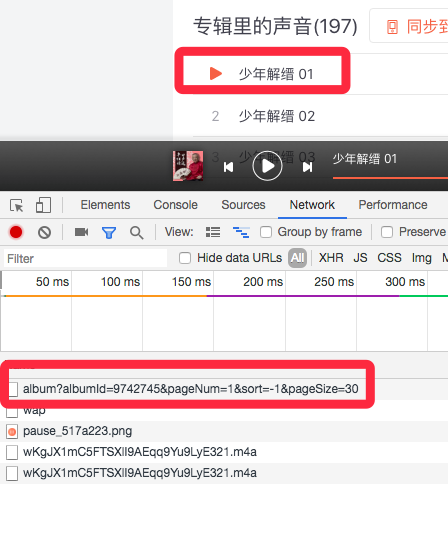
我们来点击这个看看, 首先看一下headers, 这个url是不是看起来很顺眼
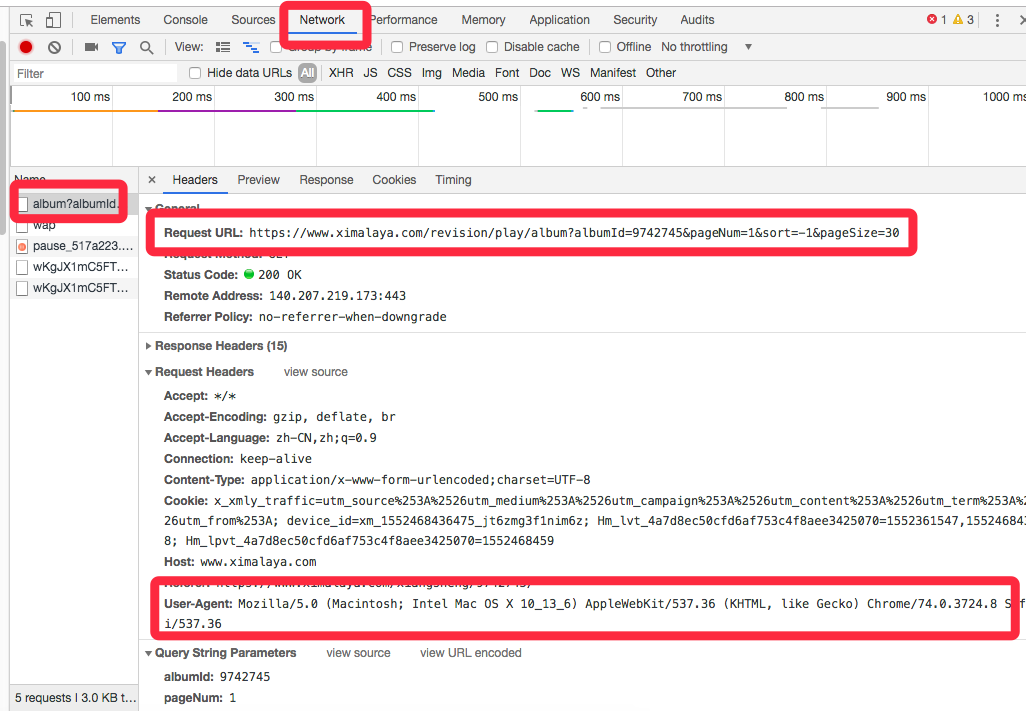
再来preview, 或者打开那个Request URL
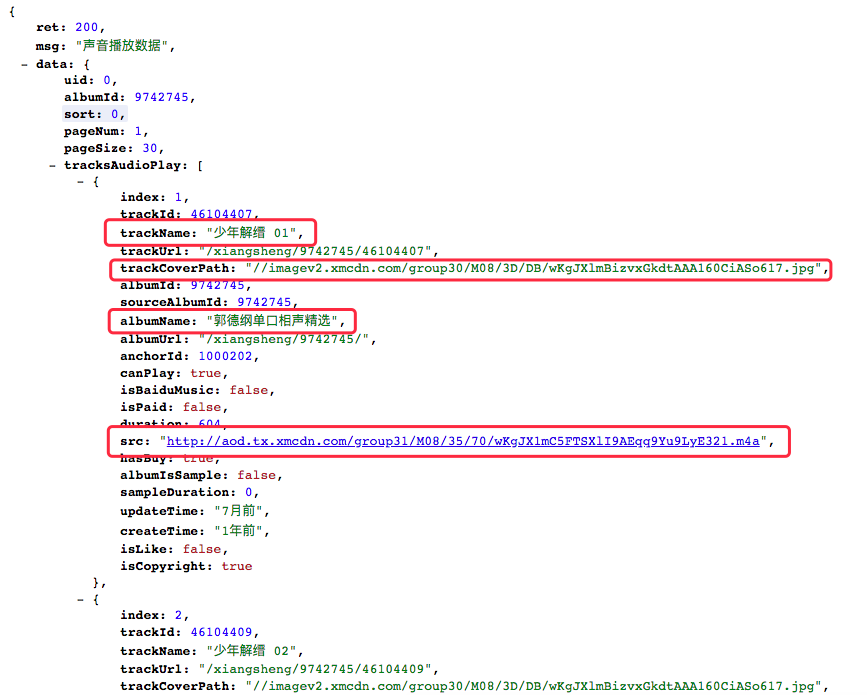
- # -*- coding:utf-8 -*-
- # Author : Niuli
- # Data : 2019-03-13 16:08
- import requests,os
- # 数据来源
- URL = 'https://www.ximalaya.com/revision/play/album?albumId=9742745&pageNum=1&sort=-1&pageSize=30'
- # 伪造请求头
- XMLY_HEADER = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3724.8 Safari/537.36'}
- res = requests.get(URL,headers=XMLY_HEADER)
- res_json = res.json()
- play_list = res_json['data']['tracksAudioPlay']
- ALL_PATH = play_list[0]['albumName']
- # 创建本地专辑文件夹
- os.system(f'mkdir -p {ALL_PATH}/MUSIC')
- os.system(f'mkdir -p {ALL_PATH}/COVER')
- MUSIC_PATH = ALL_PATH + '/MUSIC'
- COVER_PATH = ALL_PATH + '/COVER'
- for i in play_list:
- # print(i['trackName'])
- # print(i['trackCoverPath'])
- # print(i['src'])
- # 获取文件信息 (标题 音乐路径 图片路径)
- url_title = i['trackName']
- url_music_path = i['src']
- url_cover_path = 'https:' + i['trackCoverPath']
- # 下载保存音乐文件
- music_file = requests.get(url_music_path) # 下载文件
- local_music_path = os.path.join(MUSIC_PATH,f'{url_title}.mp3') # 保存路径+文件名+后缀
- # 写入音乐文件
- with open(local_music_path,'wb') as f:
- f.write(music_file.content)
- # 下载保存图片信息
- cover_file = requests.get(url_cover_path) # 下载文件
- local_cover_path = os.path.join(COVER_PATH,f'{url_title}.jpg') # 保存路径+文件名+后缀
- # 写入图片文件
- with open(local_cover_path, 'wb') as f:
- f.write(cover_file.content)
同理可以获取其他音频咯
python爬虫简单代码爬取郭德纲单口相声的更多相关文章
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- iOS调用QQ发起临时会话
iOS调用QQ发起临时会话 iOS调用qq前先判断是否安装qq, 之后通过OpenURL打开对用的qq NSURL *url = [NSURL URLWithString:@"mqq://& ...
- Android开发工程师文集-提示框,菜单,数据存储,组件篇
提示框,菜单,数据存储,组件篇 Toast Toast.makeText(context, text, 时间).show(); setDuration();//设置时间 setGravity();// ...
- RSA实现JS前端加密,PHP后端解密
web前端,用户注册与登录,不能直接以明文形式提交用户密码,容易被截获,这时就引入RSA. 前端加密 需引入4个JS扩展文件,jsbn.js.prng4.js.rng.js和rsa.js. <h ...
- 实现instanceof关键字
如果用Java的伪代码来表现Java语言规范所描述的运行时语义,会是这样: // obj instanceof T boolean result; if (obj == null) { result ...
- 【微服务】.netCore eShopOnContainers 部署实践《二》
Docker 专业术语介绍 优点:轻量级.可伸缩(灵活性).可靠性.可移植 Container image A package with all of the dependencies and in ...
- 微信开发之获取openid及推送模板消息
有很多的朋友再问我怎么获取code,openid之类的问题,在这里我就给大家分享一下. 在做微信支付是需要获取openid的,推送模板消息也是需要openid包括其他一些功能分享等也都是需要的,ope ...
- postgresql-分页重复数据探索
# postgresql-分页重复数据探索 ## 问题背景 许多开发和测试人员都可能遇到过列表的数据翻下一页的时候显示了上一页的数据,也就是翻页会有重复的数据. ### 如何处理? 这个问题出现的原因 ...
- 项目- Vue全家桶实战去哪网App
最近在学习Vue,花了几天时间跟着做了这个项目,算是对学习Vue入门的一个总结,欢迎同学们star 去哪网APP
- 解决Chrome浏览器主页被hao123、360和2345篡改简单有效方法
转自:https://blog.csdn.net/qq_32635971/article/details/72793115?locationNum=10&fps=1 当你打开浏览器看到各种首页 ...
- 从零开始学 Web 之 ES6(四)ES6基础语法二
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...