中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问

截止2022年,中国联通用户规模达到4.6亿,占据了全中国人口的30%,随着5G的推广普及,运营商IT系统普遍面临着海量用户、海量话单、多样化业务、组网模式等一系列变革的冲击。
当前,联通每天处理话单量超过400亿条。在这样的体量基础上,提高服务水平,为客户提供更有针对性的服务,也成为了联通品牌追求的终极目标。而中国联通在海量数据汇集、加工、脱敏、加密等技术与应用方面已崭露头角,在行业中具有一定的先发优势,未来势必成为大数据赋能数字经济发展的重要推动者。
在 Apache DolphinScheduler 4月 Meetup 上,我们邀请到了联通软件研究院的柏雪松,他为我们分享了《DolphinScheduler在联通计费环境中的应用》。
本次演讲主要包括三个部分:
DolphinScheduler在联通的总体使用情况
联通计费业务专题分享
下一步的规划

柏雪松 联通软研院 大数据工程师
毕业于中国农业大学,从事于大数据平台构建和 AI 平台构建,为 Apache DolphinScheduler 贡献 Apache SeaTunnel(Incubating) 插件,并为 Apache SeaTunnel(Incubating) 共享 alluxio 插件
01 总体使用情况
首先给大家说明一下联通在DolphinScheduler的总体使用情况:
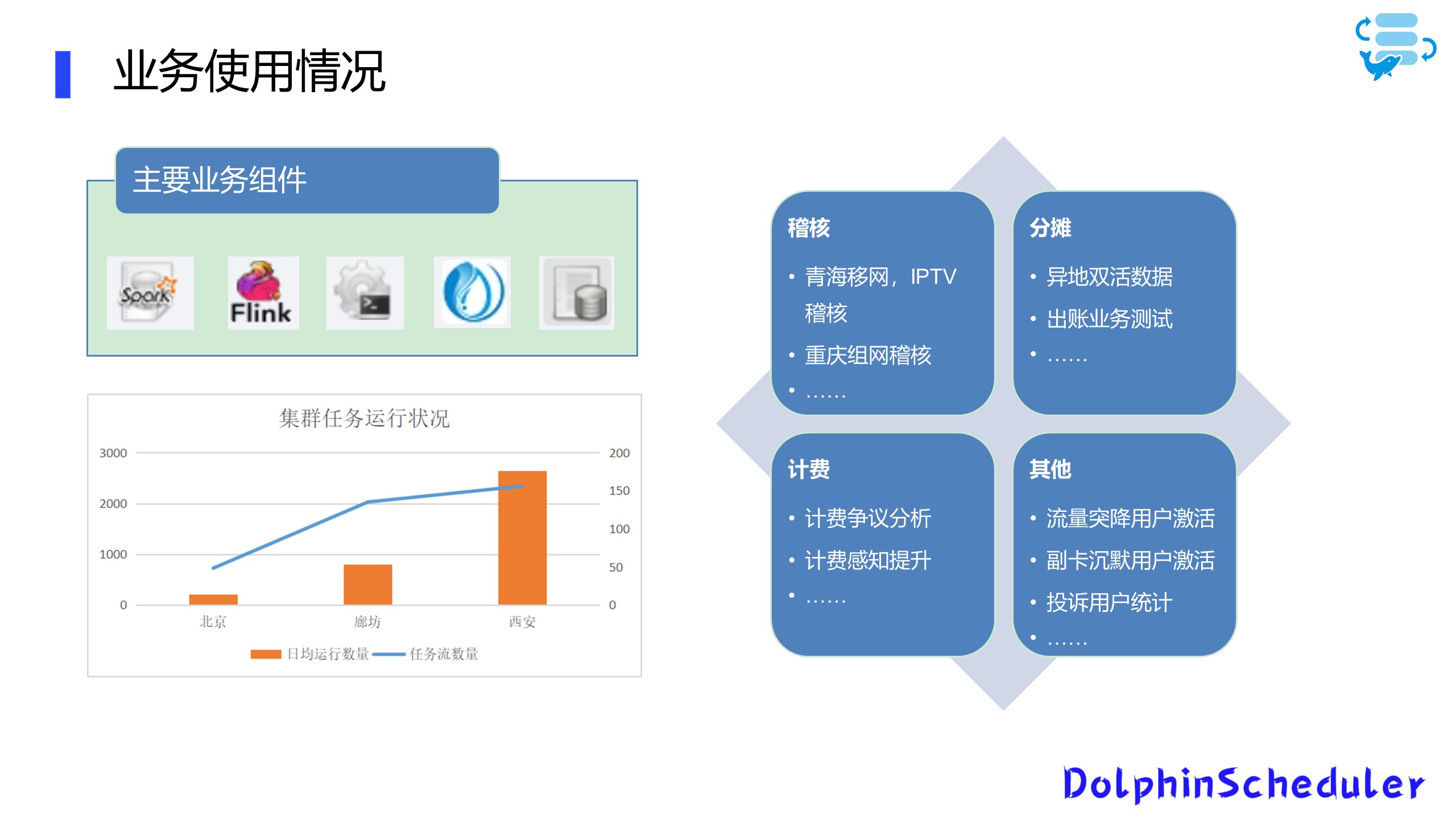
现在我们的业务主要运行在3地4集群
总体任务流数量大概在300左右
日均任务运行差不多5000左右
我们使用到的DolphinScheduler组件包括Spark、Flink、SeaTunnel(原Waterdrop),以及存储过程中的Presto和一些Shell脚本,涵盖的业务则包含稽核,收入分摊,计费业务,还有其他一些需要自动化的业务等。
02 业务专题分享
01 跨集群双活业务调用
上文说过,我们的业务运行在3地4集群上,这样就免不了集群之间的互相的数据交换和业务调用。如何统一管理和调度这些跨集群的数据传输任务是一个重要的问题,我们数据在生产集群,对于集群网络带宽十分敏感,必须有组织地对数据传输进行管理。
另一方面,我们有一些业务需要跨集群去调用,例如A集群数据到位后B集群要启动统计任务等,我们选择 Apache DolphinScheduler作为调度和控制,来解决这两个问题。
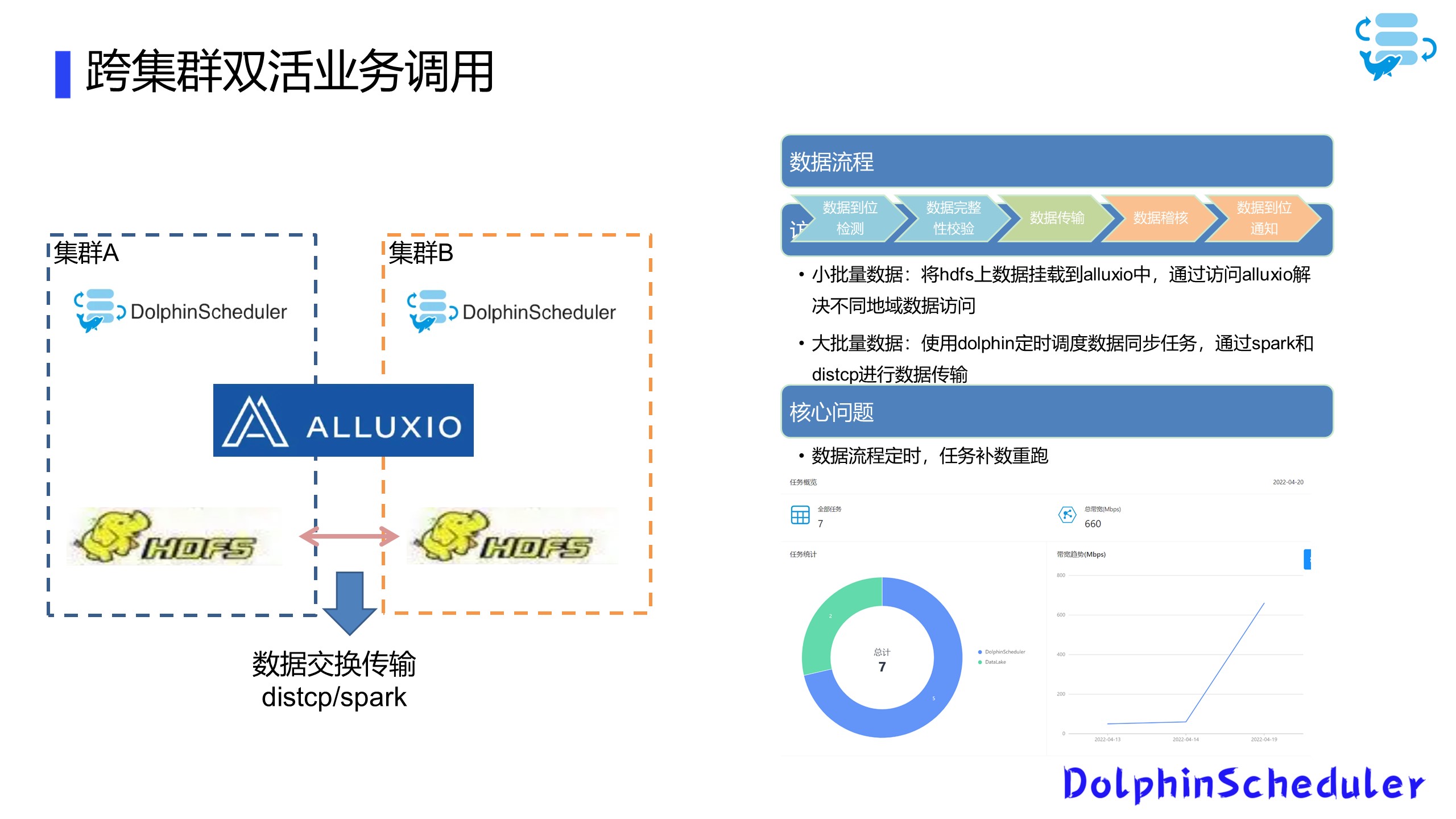
首先说明下我们跨集群数据传输的流程在AB两个集群上进行,我们均使用HDFS进行底层的数据存储,在跨集群的HDFS数据交换上,根据数据量大小和用途,我们将使用的数据分为小批量和大批量数据,向结构表,配置表等。
对于小批量数据,我们直接将其挂载到同一个Alluxio上进行数据共享,这样不会发生数据同步不及时导致的版本问题。
像明细表和其他大文件,我们使用Distcp和Spark混合进行处理;
对于结构表数据,使用SeaTunnel on Spark的方式;
通过Yarn队列的方式进行限速设置;
非结构数据使用Distcp传输,通过自带的参数Bandwidth进行速度限制;
这些传输任务都是运行在DolphinScheduler平台上面,我们整体的数据流程主要是A集群的数据到位检测,A集群的数据完整性校验,AB集群之间的数据传输,B集群的数据稽核和到位通知。
强调一点:其中我们重点用到了DolphinScheduler自带的补数重跑,对失败的任务或者不完整的数据进行修复。
在完成了跨集群的数据同步和访问,我们还会使用DolphinScheduler进行跨地域和集群的任务调用。
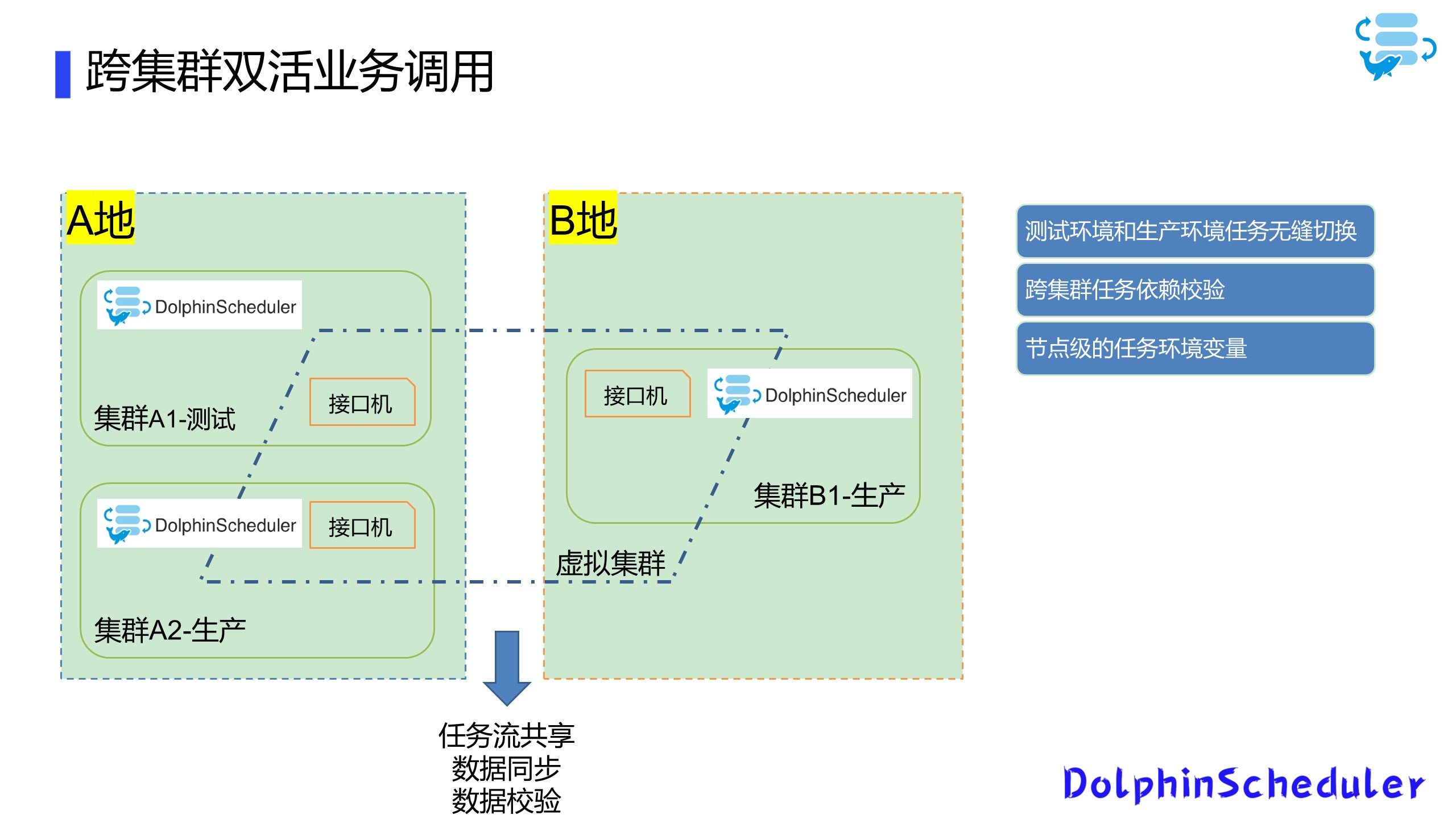
我们在A地有两个集群,分别是测试A1和生产A2,在B地有生产B1集群,我们会在每个集群上拿出两台具有内网IP的机器作为接口机,通过在6台接口机上搭建DolphinScheduler建立一个虚拟集群,从而可以在统一页面上操作三个集群的内容;
Q:如何实现由测试到生产上线?
A:在A1测试上进行任务开发,并且通过测试之后,直接将worker节点改动到A2生产上;
Q:遇到A2生产出了问题,数据未到位等情况怎么办?
A:我们可以直接切换到B1生产上,实现手动的双活容灾切换;
最后我们还有些任务比较大,为满足任务时效性,需要利用两个集群同时计算,我们会将数据拆分两份分别放到A2和B1上面,之后同时运行任务,最后将运行结果传回同一集群进行合并,这些任务流程基本都是通过DolphinScheduler来进行调用的。
请大家注意,在这个过程中,我们使用DolphinScheduler解决了几个问题:
项目跨集群的任务依赖校验;
控制节点级别的任务环境变量;
02 AI开发同步任务运行
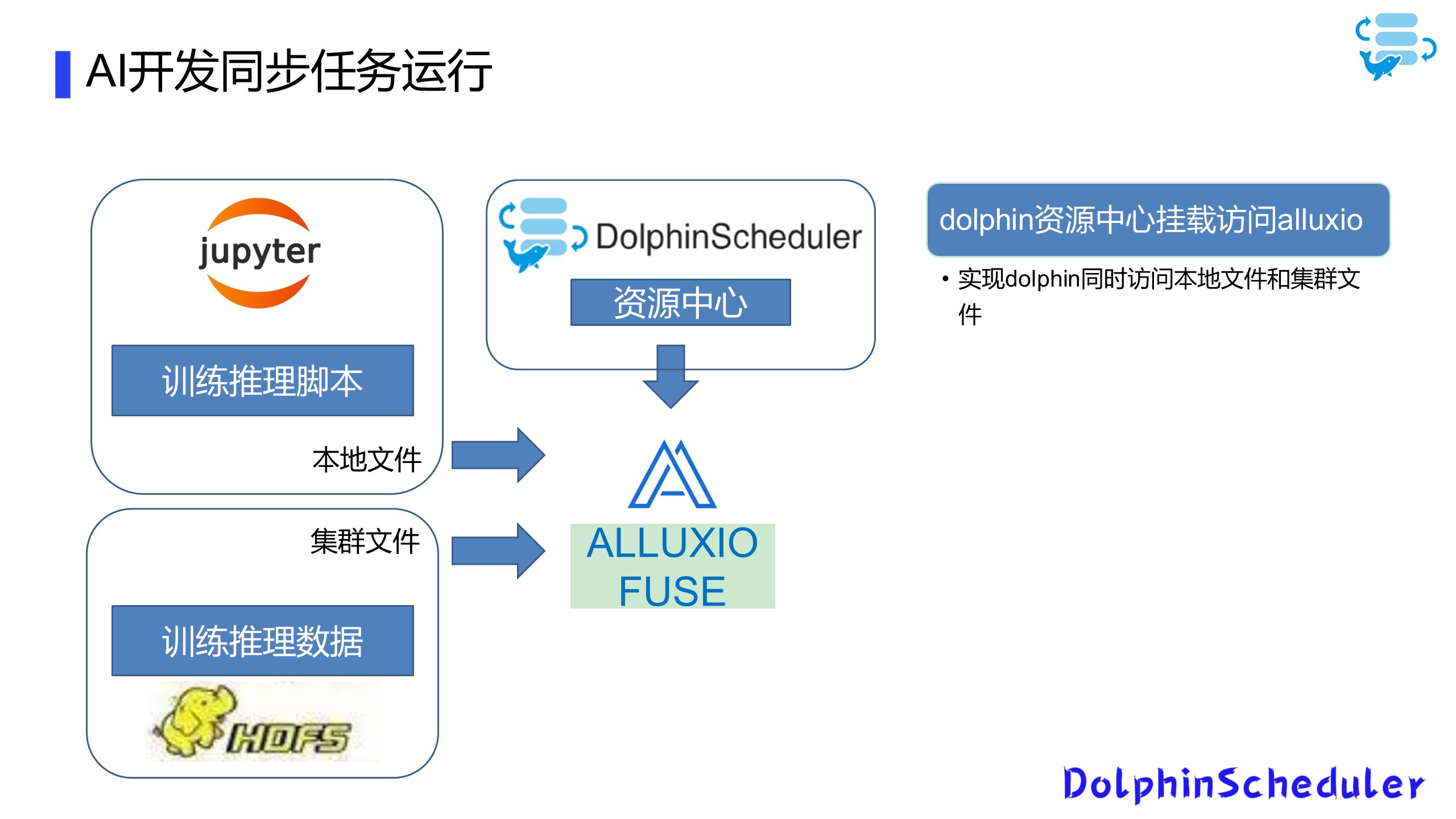
1、统一数据访问方式
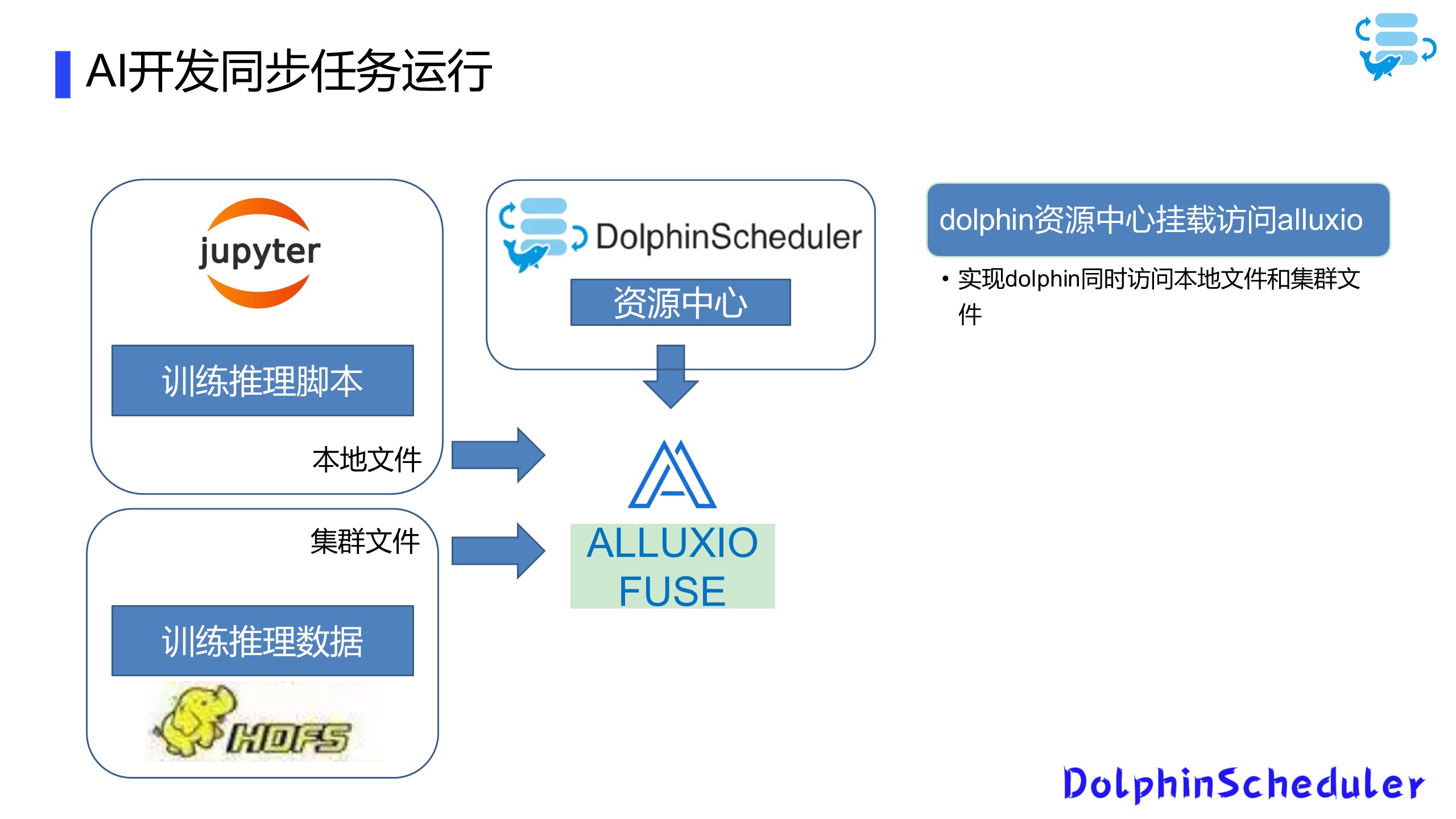
我们现在已经有一个简易的AI开发平台,主要为用户提供一些Tensorflow和Spark ML的计算环境。在业务需求下,我们需要将用户训练的本地文件模型和集群文件系统打通,并且能够提供统一的访问方式和部署方法,为解决这个问题,我们使用了Alluxio-fuse和DolphinScheduler这两个工具。
Alluxio-fuse打通本地和集群存储
DolphinScheduler共享本地和集群存储
由于我们搭建的AI平台集群和数据集群是两个数据集群,所以在数据集群上我们进行一个数据的存储,利用Spark SQL或者Hive进行一些数据的预加工处理,之后我们将处理完的数据挂载到Alluxio上,最后通过Alluxio fuse跨级群映射到本地文件,这样我们基于Conda的开发环境,就可以直接访问这些数据,这样就可以做到统一数据的访问方式,以访问本地数据的方法访问集群的数据。
2、数据脚本一站式访问
分离资源之后,通过预处理大数据内容通过数据集群,通过我们的AI集群去处理训练模型和预测模型,在这里,我们使用Alluxio-fuse对DolphinScheduler的资源中心进行了二次改动,我们将DolphinScheduler资源中心连接到Alluxio上,再通过Alluxio-fuse同时挂载本地文件和集群文件,这样在DolphinSchedule上面就可以同时访问在本地的训练推理脚本,又可以访问到存储在hdfs上的训练推理数据,实现数据脚本一站式访问。
03 业务查询逻辑持久化
第三个场景是我们用Presto和Hue为用户提供了一个前台的即时查询界面,因为有些用户通过前台写完SQL,并且测试完成之后,需要定时运行一些加工逻辑和存储过程,所以这就需要打通从前台SQL到后台定时运行任务的流程。

另一个问题是Presto原生没有租户间的资源隔离问题。我们也是对比了几个方案之后,最后结合实际情况选择了Presto on Spark方案。
因为我们是一个多租户平台,最开始给用户提供的方案是前端用Hue界面,后端直接使用原生的Presto跑在物理集群上,这导致了用户资源争抢占的问题。当有某些大查询或者大的加工逻辑存在时,会导致其他租户业务长时间处于等待状态。
为此,我们对比了Presto on Yarn和Presto on Spark,综合对比性能之后发现Presto on Spark资源使用效率会更高一些,这里大家也可以根据自己的需求选择对应的方案。
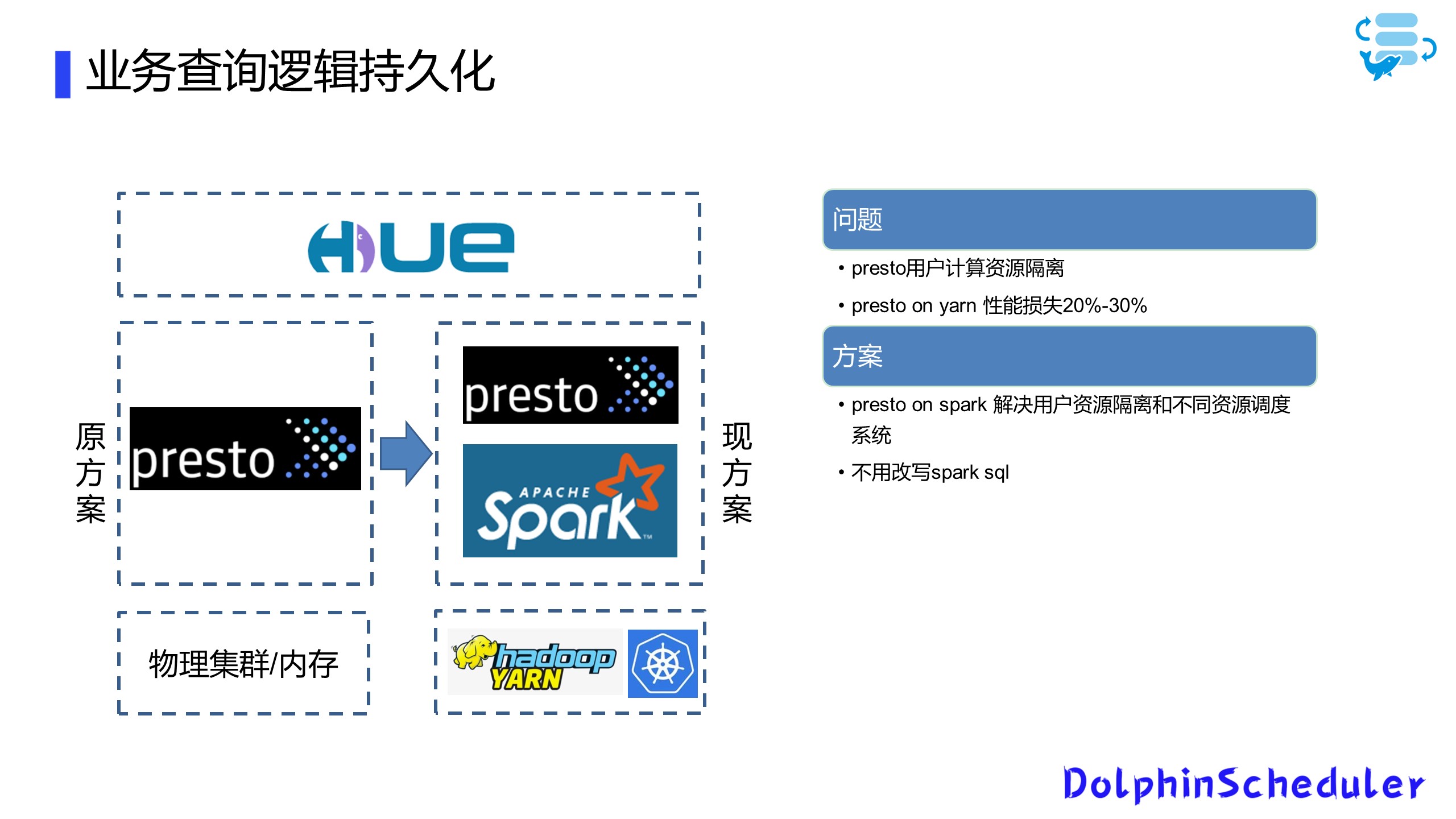
另一方面,我们使用了原生Presto和Presto on spark共存的方式,对于一些数据量较小,加工逻辑较为简单的SQL,我们直接将其在原生Presto上运行,而对于一些加工逻辑比较复杂,运行时间比较长的SQL,则在Presto on spark上运行,这样用户用一套SQL就可以切换到不同的底层引擎上。
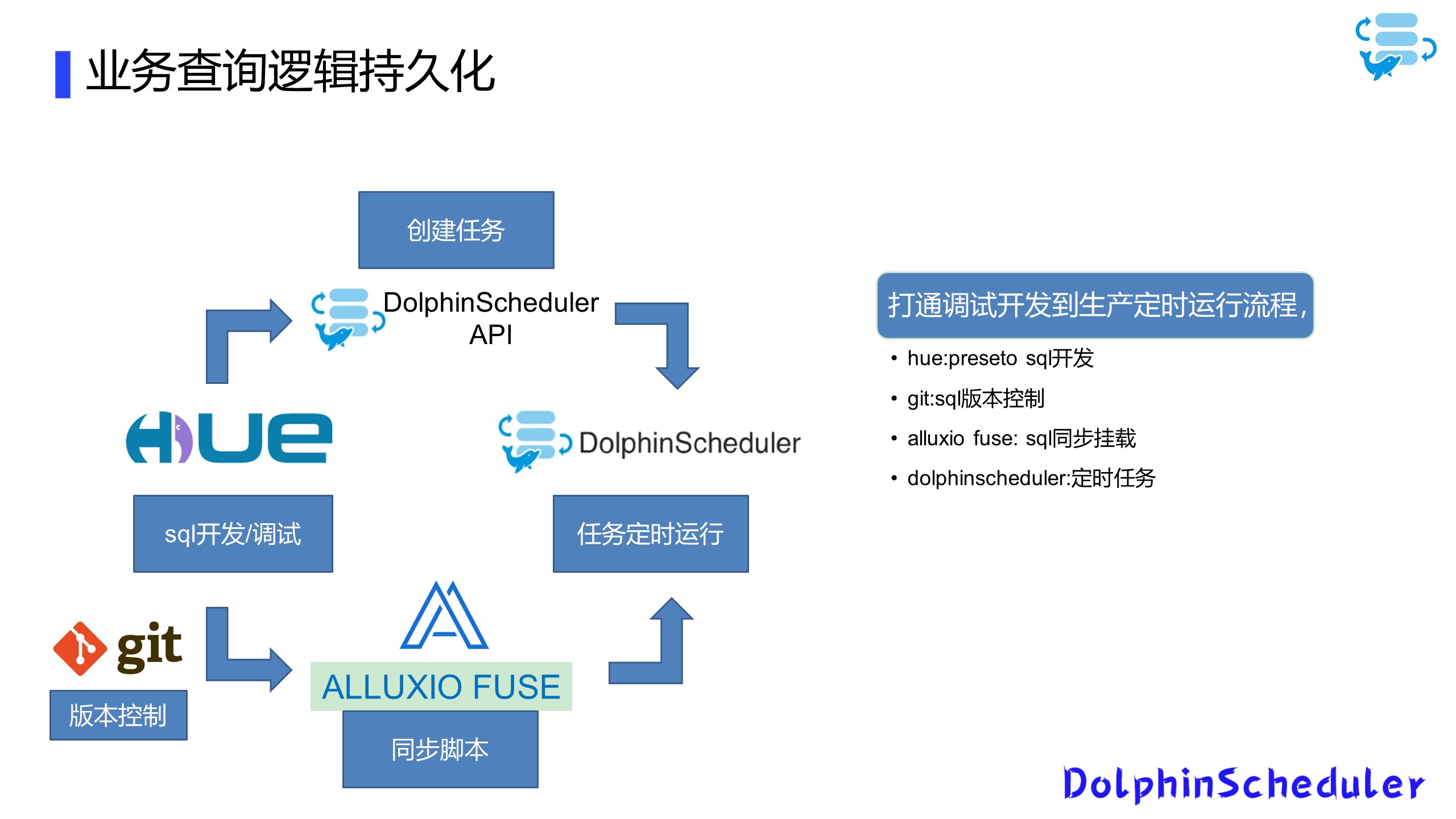
此外,我们还打通了Hue到DolphinScheduler定时任务调度流程。我们在Hue上进行SQL开发调制后,通过存储到本地Serve文件,连接到Git进行版本控制。
我们将本地文件挂载到Alluxio fuse上,作为SQL的同步挂载,最后我们使用Hue,通过DolphinScheduler的API创建任务和定时任务,实现从SQL开发到定时运行的流程控制。
04 数据湖数据统一治理
最后一个场景是数据湖数据统一管理,在我们自研的数据集成平台上,使用分层治理的方式对数据湖数据进行统一的管理和访问,其中使用了DolphinScheduler作为入湖调度和监控引擎。
在数据集成平台上,对于数据集成、数据入湖、数据分发这些批量的和实时的任务的,我们使用DolphinScheduler进行调度。
底层运行在Spark和Flink上,对于数据查询和数据探索这些需要即时反馈的业务需求,我们使用嵌入Hue接入Spark和Presto的方法,对数据进行探索查询;对于数据资产登记同步和数据稽核等,直接对数据源文件信息进行查询,直接同步底层数据信息。
最后一个场景是数据湖数据统一管理,在我们自研的数据集成平台上,使用分层治理的方式对数据湖数据进行统一的管理和访问,其中使用了DolphinScheduler作为入湖调度和监控引擎。
在数据集成平台上,对于数据集成、数据入湖、数据分发这些批量的和实时的任务的,我们使用DolphinScheduler进行调度。
底层运行在Spark和Flink上,对于数据查询和数据探索这些需要即时反馈的业务需求,我们使用嵌入Hue接入Spark和Presto的方法,对数据进行探索查询;对于数据资产登记同步和数据稽核等,直接对数据源文件信息进行查询,直接同步底层数据信息。
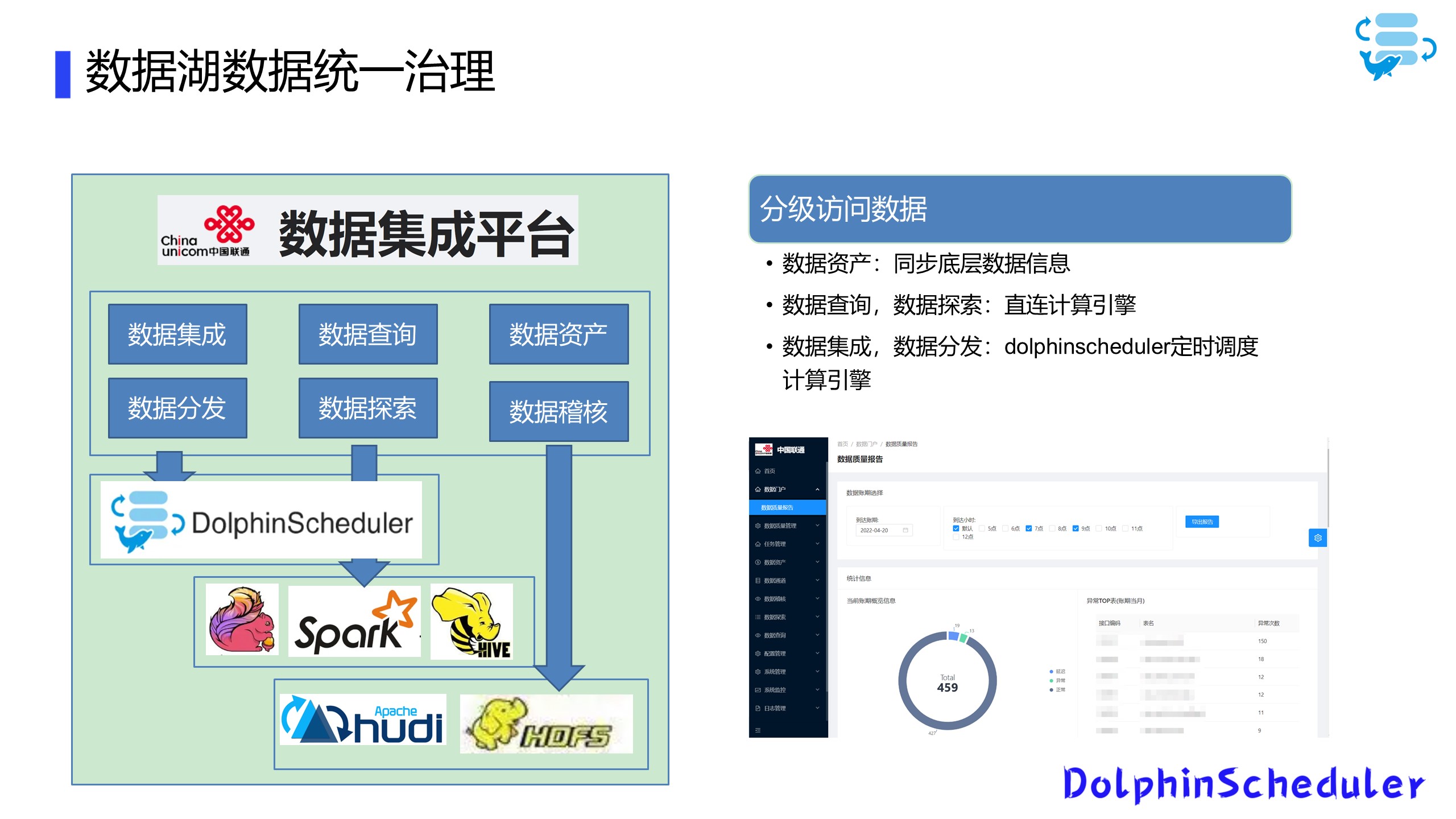
目前我们集成平台基本上管理着460张数据表的质量管理,对数据准确性和准时性提供统一的管理。
03 下一步计划与需求
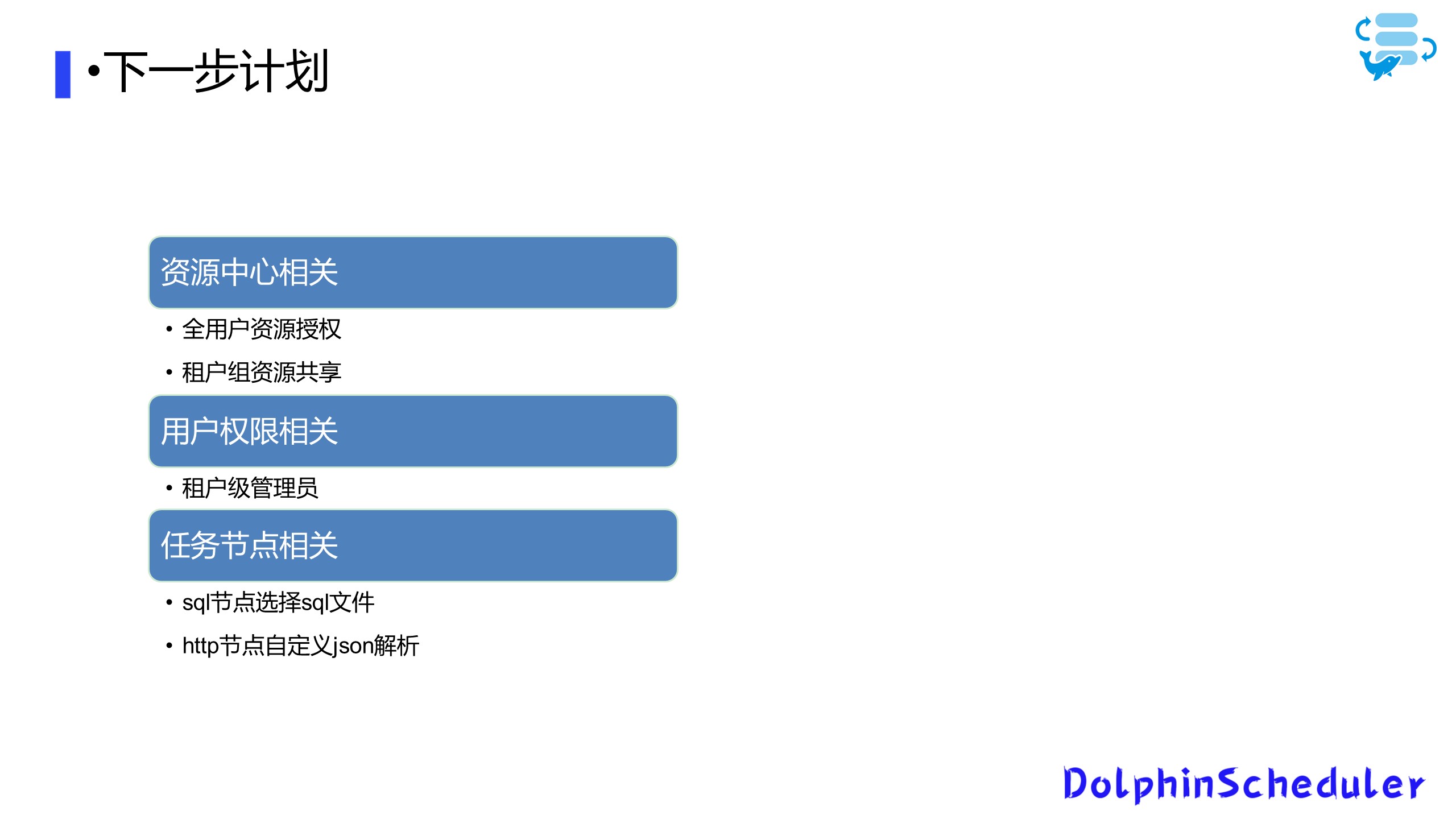
01 资源中心
在资源中心层面,为了方便用户之间的文件共享,我们计划为全用户提供资源授权,同时根据它的归属租户,分配租户级别的共享文件,使得对于一个多租户的平台更为友善。
02 用户管理
其次与用户传权限相关,我们只提供租户级别的管理员账账户,后续的用户账户由租户管理员账户创建,同时租户组内的用户管理也是由租户管理员去控制,以方便租户内部的管理。
03 任务节点
最后是我们的任务节点相关的计划,现在已在进行之中:一方面是完成SQL节点的优化,让用户能够选择一个资源中心的SQL文件,而不需要手动复制SQL;另一方面是HTTP节点对返回的json自定义解析提取字段判断,对复杂返回值进行更为友好的处理。
04 参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
05 活动推荐
当数据资源成为生产发展乃至于生存过程中必不可少的要素,企业该如何通过数据集成帮助企业数据服务全生命周期落地呢?5月14日,数据集成框架 Apache SeaTunnel(Incubating)将邀请一站式数据集成平台 Apache InLong(Incubating)的技术专家与开源贡献者们,一同来到直播间,与大家畅谈使用Apache SeaTunnel(Incubating)与Apache InLong(Incubating)后的实践经历与心得体会。
本次活动受疫情影响仍以线上直播的形式开展,活动现已开放免费报名,欢迎扫描下图二维码,或点击“阅读原文”免费报名!
直播链接:https://www.slidestalk.com/m/777
中国联通改造 Apache DolphinScheduler 资源中心,实现计费环境跨集群调用与数据脚本一站式访问的更多相关文章
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 使用mod_cluster进行apache httpd server和jboss eap 6.1集群配置
本文简单介绍,使用mod_cluster进行apache httpd server和jboss eap 6.1集群配置.本配置在windows上测试通过,linux下应该是一样的.可能要稍作调整.后面 ...
- Apache Spark 2.2.0 中文文档 - 集群模式概述 | ApacheCN
集群模式概述 该文档给出了 Spark 如何在集群上运行.使之更容易来理解所涉及到的组件的简短概述.通过阅读 应用提交指南 来学习关于在集群上启动应用. 组件 Spark 应用在集群上作为独立的进程组 ...
- Apache配置反向代理、负载均衡和集群(mod_proxy方式)
Apache配置负载均衡和集群使用mod_jk的方式比较多,但是mod_jk已经停止更新,并且配置相对复杂.Apache2.2以后,提供了一种原生的方式配置负载均衡和集群,比mod_jk简单很多. 1 ...
- Spring Cloud - Nacos注册中心入门单机模式及集群模式
近几年微服务很火,Spring Cloud提供了为服务领域的一整套解决方案.其中Spring Cloud Alibaba是我们SpringCloud的一个子项目,是提供微服务开发的一站式解决方案. 包 ...
- SpringCloud(四):服务注册中心Eureka Eureka高可用集群搭建 Eureka自我保护机制
第四章:服务注册中心 Eureka 4-1. Eureka 注册中心高可用集群概述在微服务架构的这种分布式系统中,我们要充分考虑各个微服务组件的高可用性 问题,不能有单点故障,由于注册中心 eurek ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 金融任务实例实时、离线跑批Apache DolphinScheduler在新网银行的三大场景与五大优化
在新网银行,每天都有大量的任务实例产生,其中实时任务占据多数.为了更好地处理任务实例,新网银行在综合考虑之后,选择使用 Apache DolphinScheduler 来完成这项挑战.如今,新网银行多 ...
- 论语音社交视频直播平台与 Apache DolphinScheduler 的适配度有多高
在 Apache DolphinScheduler& Apache ShenYu(Incubating) Meetup 上,YY 直播 软件工程师 袁丙泽 为我们分享了<YY直播基于Ap ...
随机推荐
- TypeError: this.getOptions is not a function
我在vue ui界面中安装版本依赖包后报这个错误 less-loader/sass-loader安装的版本过高 解决办法 删除原有的版本依赖包,安装更低版本的依赖包. 如 @6.0.1为选择安装的版本 ...
- 7. Docker CI、CD
在上图这个新建的docker-compose.yml文件中把刚才的代码粘贴进去. 可把上述文件保存后,然后到/etc/ssh/sshd_config文件中更改下对应的端口号即可. 然后重新启动sshd ...
- QT 基于QScrollArea的界面嵌套移动
在实际的应用场景中,经常会出现软件界面战场图大于实际窗体大小,利用QScrollArea可以为widget窗体添加滚动条,可以实现小窗体利用滚动条显示大界面需求.实现如下: QT创建一个qWidget ...
- Linux离线包管理器RPM
Linux离线包管理器RPM RPM 是RedHat Package Manager(RedHat软件包管理工具). 1.rpm常用参数介绍 查看rpm是否安装 rpm -q rpm包名 [root@ ...
- DS18B20数字温度计 (一) 电气特性, 供电和接线方式
目录 DS18B20数字温度计 (一) 电气特性, 供电和接线方式 DS18B20数字温度计 (二) 测温, ROM和CRC校验 DS18B20数字温度计 (三) 1-WIRE总线ROM搜索算法 DS ...
- 有关于weiphp2.00611上传sae的一些注意(图片上传解决方案)
一.安装中注意的事项 安装时使用的系统为weiphp2.0611 版本 1.将所有文件上传到代码库中 2.按照步骤进行安装weiphp,注意在数据库导入的时候需要手动导入. ...
- Python实现简繁体转换,真的玩得花
大家好鸭, 我是小熊猫 直接开搞!!! 1.opencc-python 首先介绍opencc中的Python实现库,它具有安装简单,翻译准确,使用方便等优点.对于我们日常的需求完全能够胜任. 1.1安 ...
- 浅议.NET遗留应用改造
浅议.NET遗留应用改造 TLDR:本文介绍了遗留应用改造中的一些常见问题,并对改造所能开展的目标.原则.策略进行了概述. 一.背景概述 1.概述 或许仅"遗留应用"这个标题就比较 ...
- 内存分析器 (MAT)
内存分析器 (MAT) 1. 内存分析器 (MAT) 1.1 MAT介绍 MAT是Memory Analyzer tool的缩写.指分析工具. 1.2 MAT作用 Eclipse Memory ...
- 深入浅出理解SVM支持向量机算法
支持向量机是Vapnik等人于1995年首先提出的,它是基于VC维理论和结构风险最小化原则的学习机器.它在解决小样本.非线性和高维模式识别问题中表现出许多特有的优势,并在一定程度上克服了" ...