redis底层数据结构之跳表(skiplist)
跳表(跳跃表, skiplist)
跳跃表(skiplist)是用于有序元素序列快速搜索查找的数据结构,跳表是一个随机化的数据结构,实质是一种可以进行二分查找的、具有层次结构的有序链表
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找,平均期望的查找、插入、删除时间复杂度都是O(logn),同时支持范围查询
具有如下性质:
1) 每个节点由多层组成,排列顺序为由高层到底层
2) 每一层都是一个有序链表
3) 最底层的链表包含了所有的元素
4) 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现
5) 每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点
6) 分数(score)允许重复,即key是允许重复的
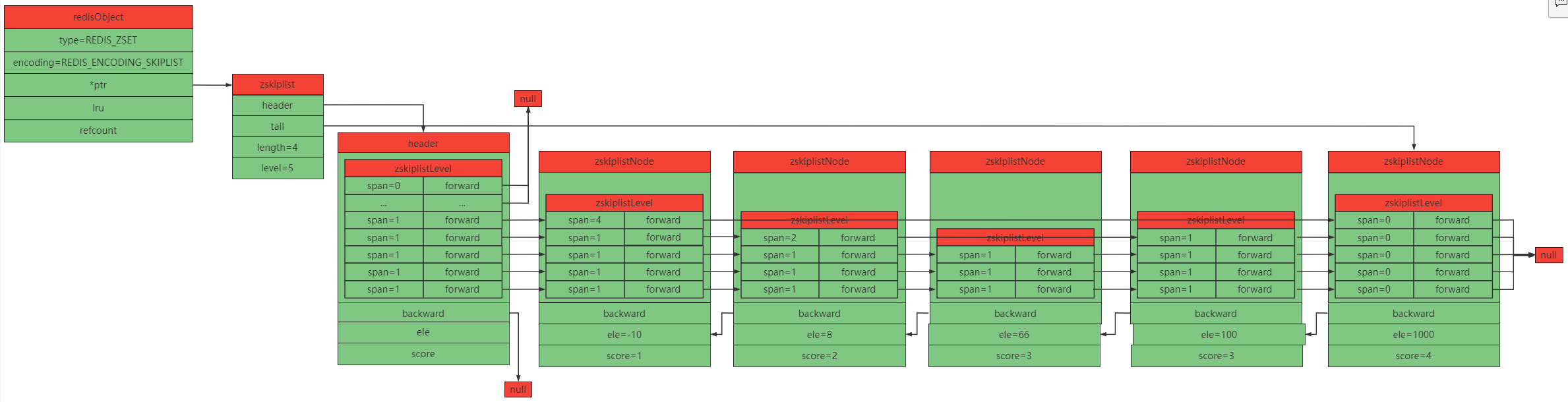
1 zskiplist结构
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
其中:
header: 表头节点,没有存储实际的数据,而是一个空的,初始化层级数为ZSKIPLIST_MAXLEVEL值(默认32)的节点
tail: 表尾节点
length: 节点数量
level: 最大层级,表头节点层数不计
2 zskiplistNode结构
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
其中:
ele:节点对象,即节点数据
score:当前节点值对应的分值,用于排序,按分值从小到大来排序,各个节点对象必须是唯一的, 但是多个节点保存的分值却可以是相同的, 分值相同的节点按照成员对象值从小到大排序
backward:当前节点的上一个节点
level:表示层数
forward:同一层的下一个节点
span:跨度,当前节点到forward指向的节点跨越了多少个节点
3 skiplist示意图
4 skiplist插入节点
步骤如下:
1) 找到每一层新节点要插入的位置(update):从高层到低层遍历skiplist,找到每一层小于新节点score的最大的节点,如果节点score相等,则比较ele
2) 随机分配一个层数(level),如果层数比skiplist的层数大,增加skiplist的层数并修改新加层数的span
3) 插入新节点(x):新节点每一层(x->level[i]) 的forward修改为每一层插入位置(update[i]->level[i]) 的forward,每一层插入插入位置的forward修改为新节点(顺序不能反),更新新节点(x),插入位置节点(update[i]->level[i]) 的每一层的span
4) 修改更高的level的span
5) 修改新节点的backward(x->backward)
6) 修改新节点最低层后一个节点(x->level[0].forward)的backward:如果新节点的forward不为null,则新节点后一个节点的backward为新节点;否则新节点是skiplist的尾结点
7) 修改skiplist的节点数量
src/t_zset.c文件对应的源码如下:
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned long rank[ZSKIPLIST_MAXLEVEL];
int i, level; serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
} /* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
} x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
5 skiplist删除节点
步骤如下:
1) 找到每一层要删除节点(x) 的前一个节点(update):从高层到低层遍历skiplist,每一层都找到小于新节点score的最大的节点,如果节点score相等,则比较ele
2) 删除节点,更新每一层要删除节点前一个节点(udpate[i]) 的span和forward
3) 修改要删除节点后一个节点最低层([x->level[0].forward->backward]) 的backward:如果删除节点最低层的forward不为null,则要删除节点后一个节点最低层的backward为要删除节点的backward,否则要删除节点后一个节点是skiplist的尾结点
4) 修改skiplist的层数level
5) 修改skiplist的节点个数
src/t_zset.c文件对应的源码如下:
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
redis底层数据结构之跳表(skiplist)的更多相关文章
- 存储系统的基本数据结构之一: 跳表 (SkipList)
在接下来的系列文章中,我们将介绍一系列应用于存储以及IO子系统的数据结构.这些数据结构相互关联又有着巨大的区别,希望我们能够不辱使命的将他们分门别类的介绍清楚.本文为第一节,介绍一个简单而又有用的数据 ...
- Redis 底层数据结构之跳跃表
文章参考 <Redis 设计与实现>黄建宏 Redis(2) 跳跃表 跳跃表 跳跃表 skiplist 是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
- Redis 的底层数据结构(跳跃表)
字典相对于数组,链表来说,是一种较高层次的数据结构,像我们的汉语字典一样,可以通过拼音或偏旁唯一确定一个汉字,在程序里我们管每一个映射关系叫做一个键值对,很多个键值对放在一起就构成了我们的字典结构. ...
- redis的zset数据结构:跳表
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 广州这边封闭式管理好久了,今天终于周末可以出去溜溜了 什么是zset z ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- Redis底层数据结构详解
上一篇说了Redis有五种数据类型,今天就来聊一下Redis底层的数据结构是什么样的.是这一周看了<redis设计与实现>一书,现来总结一下.(看书总是非常烦躁的!) Redis是由C语言 ...
- 跳表(SkipList)原理篇
1.什么是跳表? 维基百科:跳表是一种数据结构.它使得包含n个元素的有序序列的查找和插入操作的平均时间复杂度都是 O(logn),优于数组的 O(n)复杂度.快速的查询效果是通过维护一个多层次的链表实 ...
- 跳表SkipList
原文:http://www.cnblogs.com/xuqiang/archive/2011/05/22/2053516.html 跳表SkipList 1.聊一聊跳表作者的其人其事 2. 言归正 ...
- 跳表 SkipList
跳表是平衡树的一种替代的数据结构,和红黑树不同,跳表对树的平衡的实现是基于一种随机化的算法,这样就使得跳表的插入和删除的工作比较简单. 跳表是一种复杂的链表,在简单链表的节点信息之上又增加了额 ...
随机推荐
- 一文详解 Linux Crontab 调度任务
最近接到这样一个任务: 定期(每天.每月)向"特定服务器"传输"软件服务"的运营数据,因此这里涉及到一个定时任务,计划使用Python语言添加Crontab依赖 ...
- 《线段树学习笔记》 AC代码索引
P3372 [模板]线段树 1 | LibreOJ#132. 树状数组 3 :区间修改,区间查询 #include <bits/stdc++.h> #define int long lon ...
- Flutter帧率监控 | 由浅入深,详解获取帧率的那些事
前言 做线上帧率监控上报时,少不了需要弄明白如何通过代码获取实时帧率的需求,这篇文章通过图解配合Flutter性能调试工具的方式一步步通俗易懂地让你明白获取帧率的基础知识,以后再也不愁看不懂调试工具上 ...
- 本地python环境安装kylin项目依赖时报认证错误信息
问题描述:项目需要连接kylin数据库查询数据,本地安装kylin项目的依赖环境后报认证错误 python版本3.7 32位 pycharm版本 2022版 成功方法: 更换解释器选择无解释器,创建虚 ...
- 谈谈Selenium中的三种切换之alert
谈谈Selenium中的三种切换之alert 一.如何识别 识别方法:alert中的确定.取消.输入框无法用inspector定位到,当然还有一些特例. alert分为三种 alert confirm ...
- 一个比 Redis 性能更强的数据库
给大家推荐一个比Redis性能更强的数据:KeyDB KeyDB是Redis的高性能分支,侧重于多线程.内存效率和高吞吐量.除了性能改进外,KeyDB还提供主动复制.闪存和子密钥过期等功能.KeyDB ...
- [清华集训2016] Alice 和 Bob 又在玩游戏
\(\text{Solution}\) 第一道有向图 \(SG\) 函数的博弈论 有根树,设 \(f[x]\) 表示以 \(x\) 为根子树的 \(SG\) 值 对于分裂的图的 \(SG\) 值为每个 ...
- 单词检索(search)
单词检索(search) \(Description\) 小可可是学校图书馆的管理员,现在他接手了一个十分棘手的任务. 由于学校需要一些材料,校长需要在文章中检索一些信息.校长一共给了小可可N篇文章, ...
- 【雅礼联考DAY01】数列
#include<cstdio> #include<map> using namespace std; typedef long long LL; const int N = ...
- MySQL索引的基本理解
之前一致以为索引就是简单的在原表的数据上加了一些编号,让查询更加快捷.后来发现里面还有更深的知识. 索引用于快速查找具有特定列值的行.如果没有索引,MySQL 必须从第一行开始,然后通读整个表以找到相 ...