爬虫(14) - Scrapy-Redis分布式爬虫(1) | 详解
1.什么是Scrapy-Redis
- Scrapy-Redis是scrapy框架基于redis的分布式组件,是scrapy的扩展;分布式爬虫将多台主机组合起来,共同完成一个爬取任务,快速高效地提高爬取效率。
- 原先scrapy的请求是放在内存中,从内存中获取。scrapy-redisr将请求统一放在redis里面,各个主机查看请求是否爬取过,没有爬取过,排队入队列,主机取出来爬取。爬过了就看下一条请求。
- 各主机的spiders将最后解析的数据通过管道统一写入到redis中
- 优点:加快项目的运行速度;单个节点的不稳定性不影响整个系统的稳定性;支持端点爬取
- 缺点:需要投入大量的硬件资源,硬件、网络带宽等
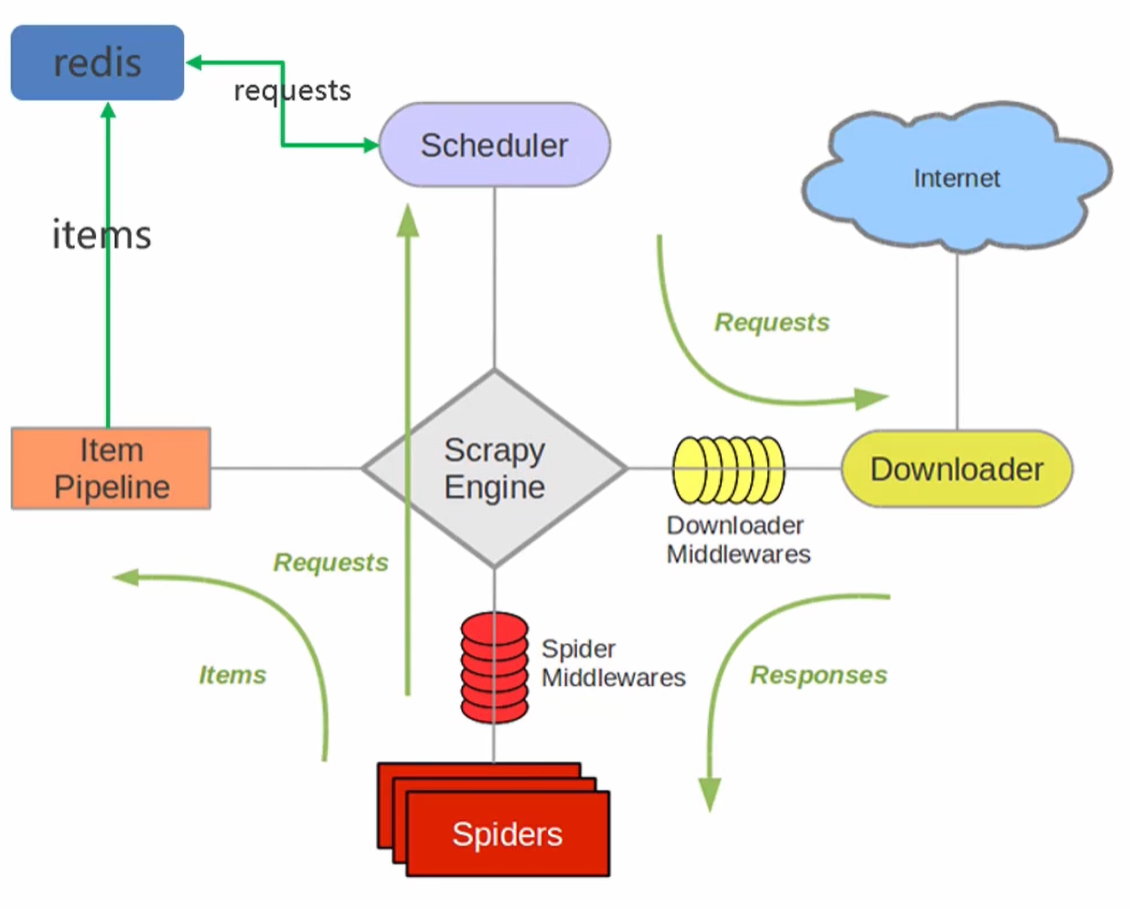
- 在scrapy框架流程的基础上,把存储request对象放到了redis的有序集合中,利用该有序集合实现了请求队列
- 并对request对象生成指纹对象,也存储到同一redis的集合中,利用request指纹避免发送重复的请求
2.Scrapy-Redis分布式策略
假设有三台电脑:Windows 10、Ubuntu 16.04、Windows 10,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
- Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储。
- Slaver端(爬虫程序执行端) :使用 Ubuntu 16.04、Windows 10,负责执行爬虫程序,运行过程中提交新的Request给Master。
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
3.Scrapy-Redis的安装和项目创建
3.1.安装scrapy-redis
- pip install scrapy-redis
3.2.项目创建前置准备
- win 10
- Redis安装:redis相关配置参照这个https://www.cnblogs.com/gltou/p/16226721.html;如果跟着笔记学到这的,前面链接那个redis版本3.0太老了,需要重新安装新版本,新版本下载链接:https://pan.baidu.com/s/1UwhJA1QxDDIi2wZFFIZwow?pwd=thak,提取码:thak;
- Another Redis Desktop Manager:这个软件是用于查看redis中存储的数据,安装也很简单,一直下一步即可;下载链接:https://pan.baidu.com/s/18CC2N6XtPn_2NEl7gCgViA?pwd=ju81 提取码:ju81
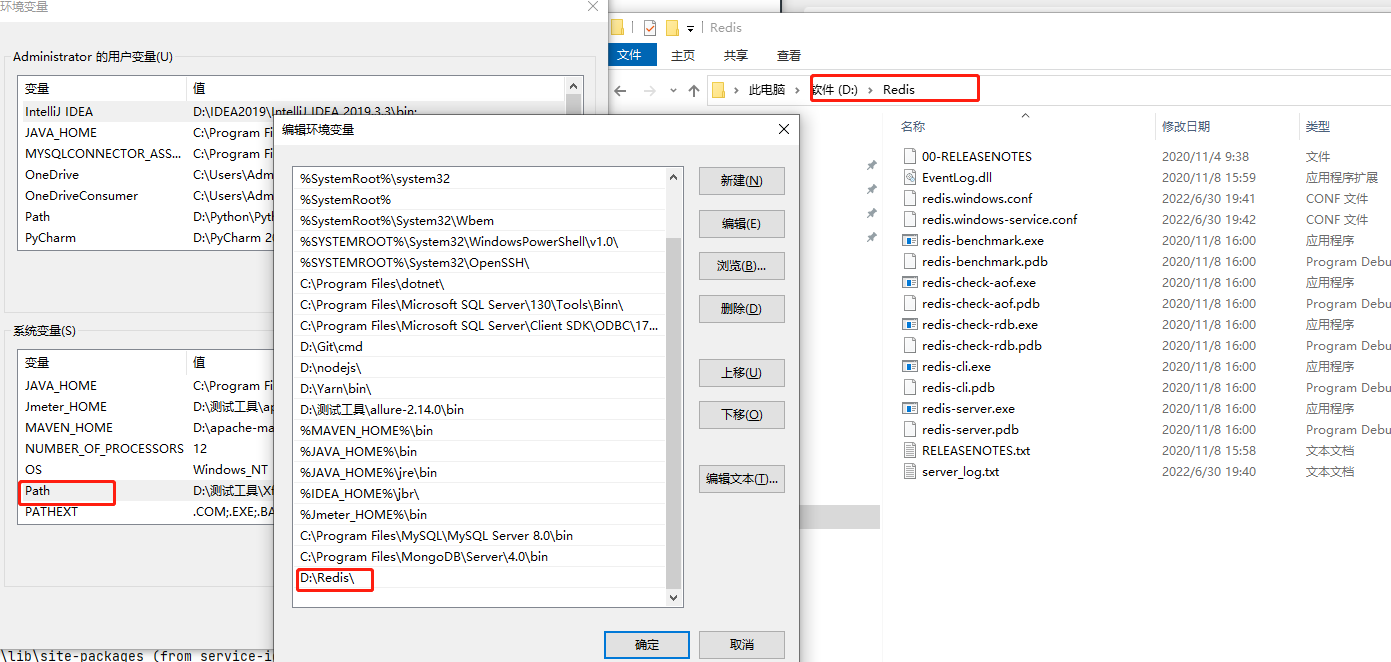
Redia安装简单讲解:安装包下载下来后,点击下一步一直安装就行,把安装路径记录好;注意安装好后需要将redis的安装目录添加到环境变量中;每当你修改了配置文件,需要重启redis时,要记得将服务重启下
Another Redis Desktop Manager简单讲解:点击【New Connection】添加redis连接,连接内容如下(地址、端口等),密码Auth和昵称Name不是必填。

可以看到redis安装的环境、当前redis的版本、内存、连接数等信息。后面我们的笔记会讲解通过该软件查看待抓取的URL以及URL的指纹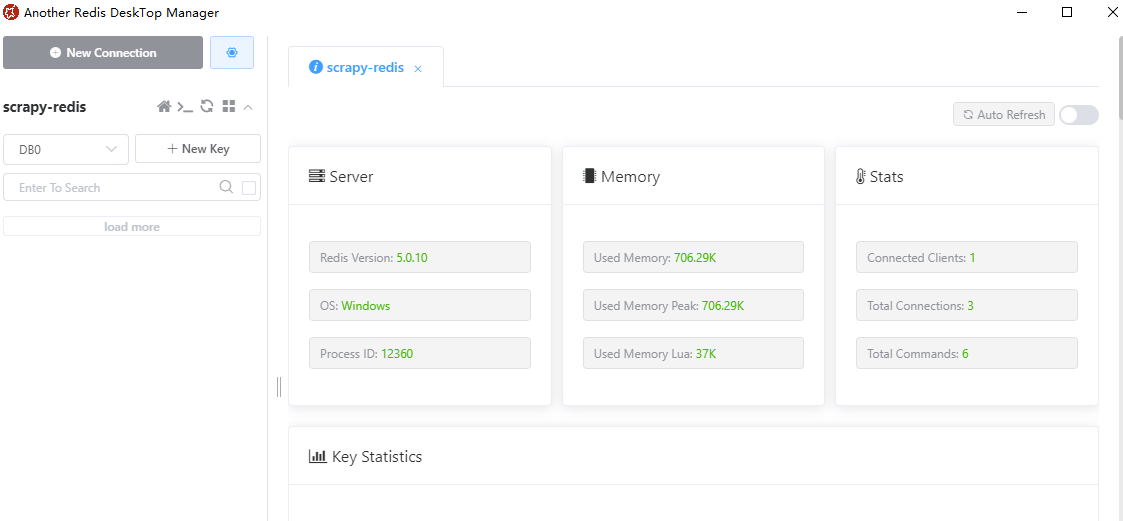
3.3.项目创建
创建普通scrapy爬虫项目,在普通的项目上改造成scrapy-redis项目;普通爬虫分为四个阶段:创建项目、明确目标、创建爬虫、保存内容;
scrapy爬虫项目创建好后,进行改造,具体改造点如下:
- 导入scrapy-redis中的分布式爬虫类
- 继承类
- 注释start_url & allowed_domains
- 设置redis_key获取start_urls
- 编辑settings文件
3.3.1.创建scrapy爬虫
step-1:创建项目
创建scrapy_redis_demo目录,在该目录下输入命令 scrapy startproject movie_test ,生成scrapy项目cd到movie_test项目下 cd .\movie_test\ 输入命令 scrapy genspider get_movie 54php.cn 生成spiders模板文件;这个过程不清楚的,转到https://www.cnblogs.com/gltou/p/16400449.html学习下
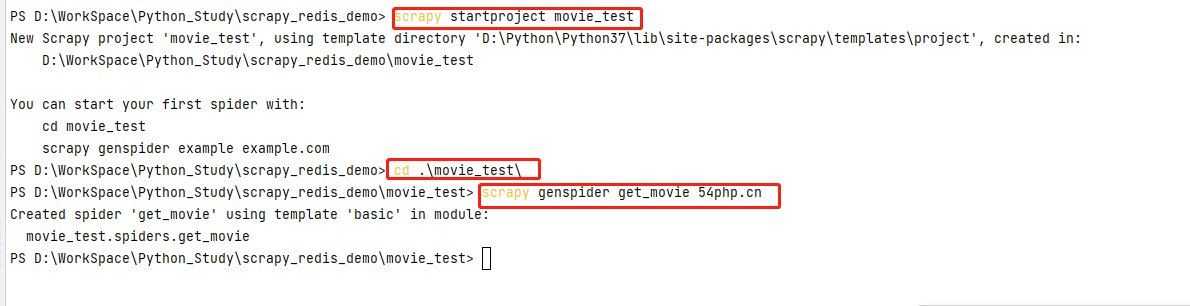
step-2:明确目标
在items.py文件中,明确我们此次需要爬取目标网站哪些数据。
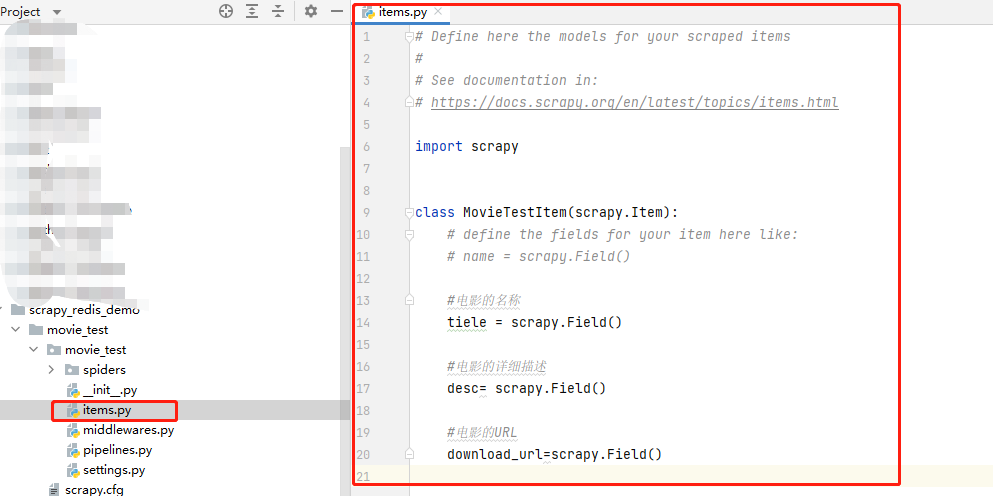
- 1 # Define here the models for your scraped items
- 2 #
- 3 # See documentation in:
- 4 # https://docs.scrapy.org/en/latest/topics/items.html
- 5
- 6 import scrapy
- 7
- 8
- 9 class MovieTestItem(scrapy.Item):
- 10 # define the fields for your item here like:
- 11 # name = scrapy.Field()
- 12
- 13 #电影的名称
- 14 tiele = scrapy.Field()
- 15
- 16 #电影的详细描述
- 17 desc= scrapy.Field()
- 18
- 19 #电影的URL
- 20 download_url=scrapy.Field()
step-3:创建爬虫
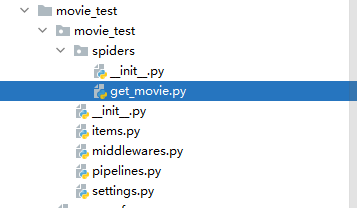
导入items.py的类,在get_movie.py文件中编写我们的爬虫文件,下面为get_movie.py的code代码
- import scrapy
- from ..items import MovieTestItem
- class GetMovieSpider(scrapy.Spider):
- name = 'get_movie'
- allowed_domains = ['54php.cn']
- start_urls = ['http://movie.54php.cn/movie/']
- def parse(self, response):
- movie_item=response.xpath("//div[2][@class='row']/div")
- for i in movie_item:
- #详情页url
- detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first()
- yield scrapy.Request(url=detail_url,callback=self.parse_detail)
- next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first()
- if next_page:
- next_page_url='http://movie.54php.cn{}'.format(next_page)
- yield scrapy.Request(url=next_page_url,callback=self.parse)
- def parse_detail(self,response):
- """解析详情页"""
- movie_info=MovieTestItem()
- movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first()
- movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first()
- movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first()
- yield movie_info
在settings.py文件中启用 USER_AGENT 并将网站的value放进去;将 ROBOTSTXT_OBEY 协议改为False

step-4:保存内容
此处暂时不写,先忽略,后面改成scrapy-redis写入redis时,再编写相关代码
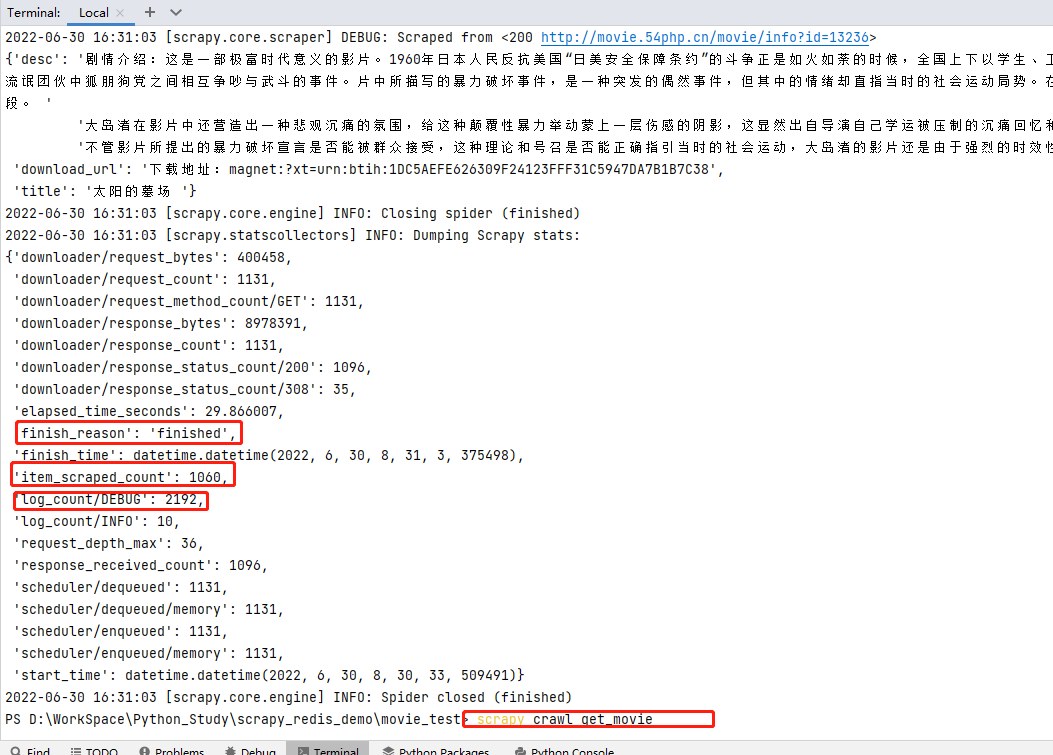
step-5:运行爬虫,查看结果
输入命令 scrapy crawl get_movie 运行爬虫,查看结果; finish_reason 为finished运行结束、 item_scraped_count 共爬取1060条数据、 log_count/DEBUG 日志文件中DEBUG记录共2192条等结果信息。
scrapy项目创建且运行成功,下面将进行scrapy-redis改造
3.3.2.改为scrapy-redis爬虫
step-1:修改爬虫文件
get_movie.py爬虫文件引入 scrapy_redis 的 RedisSpider 类,并继承他;将 allowed_domains 和 start_urls 注释掉;新增 redis_key ,值value 是一个键值对,key就是name值即爬虫名字,value就是start_urls这个变量名
- 1 import scrapy
- 2 from ..items import MovieTestItem
- 3 from scrapy_redis.spiders import RedisSpider
- 4
- 5 class GetMovieSpider(RedisSpider):
- 6 name = 'get_movie'
- 7 # allowed_domains = ['54php.cn']
- 8 # start_urls = ['http://movie.54php.cn/movie/']
- 9 redis_key = "get_movie:start_urls"
- 10
- 11 def parse(self, response):
- 12 movie_item=response.xpath("//div[2][@class='row']/div")
- 13 for i in movie_item:
- 14 #详情页url
- 15 detail_url=i.xpath(".//a[@class='thumbnail']/@href").extract_first()
- 16 yield scrapy.Request(url=detail_url,callback=self.parse_detail)
- 17
- 18 next_page=response.xpath("//a[@aria-label='Next']/@href").extract_first()
- 19 if next_page:
- 20 next_page_url='http://movie.54php.cn{}'.format(next_page)
- 21 yield scrapy.Request(url=next_page_url,callback=self.parse)
- 22
- 23 def parse_detail(self,response):
- 24 """解析详情页"""
- 25 movie_info=MovieTestItem()
- 26 movie_info["title"]=response.xpath("//div[@class='page-header']/h1/text()").extract_first()
- 27 movie_info["desc"]=response.xpath("//div[@class='panel-body']/p[4]/text()").extract_first()
- 28 movie_info["download_url"]=response.xpath("//div[@class='panel-body']/p[5]/text()").extract_first()
- 29 yield movie_info
- 30
- 31
step-2:修改redis配置文件
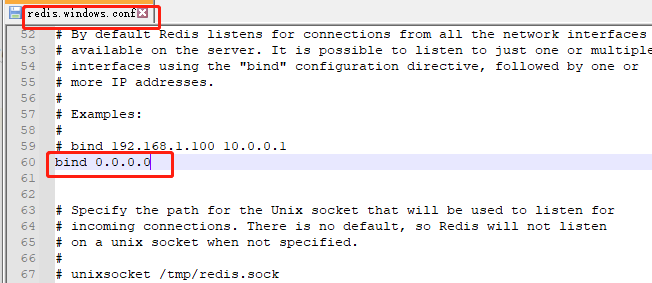
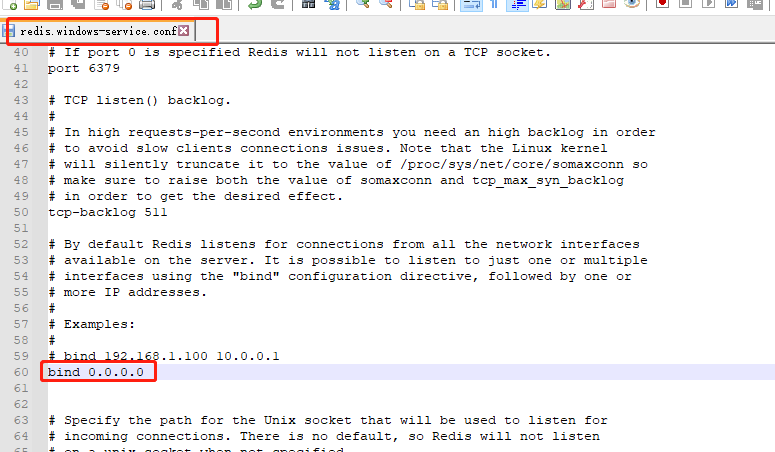
将redis.windows.conf和redis.windows-service.conf文件中 bind 设置成 0.0.0.0 ,重启redis服务
step-3:redis存入种子url
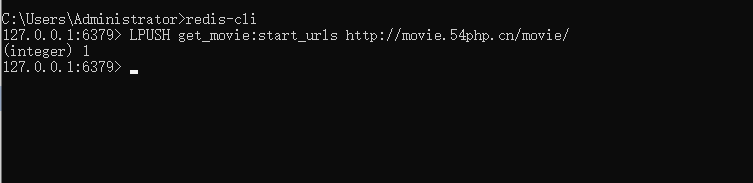
cmd输入 redis-cli 进入redis命令行,如果有密码,追加命令 auth 密码 如图

将爬虫get_movie.py文件中设置的 redis_key (是一个键值对,key就是 name 值即爬虫名字,value就是 start_urls 这个变量名),在redis中lpush一下;redis命令行输入lpush后会将命令格式带出来,不用管他,在lpush后面输入key和value值
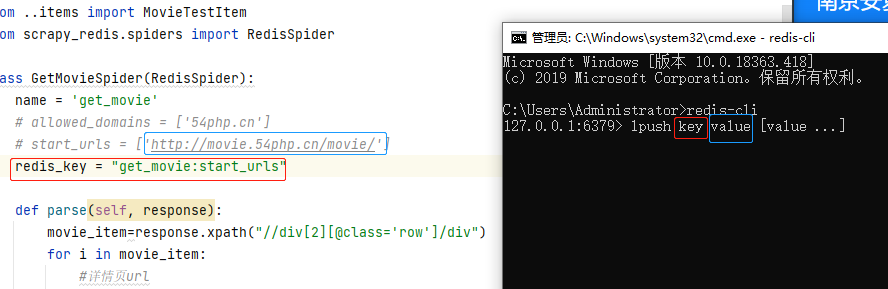
lpush的key值就是代码中的 redis_key 的值,value是 start_urls 的值,输入好后,按下Enter键

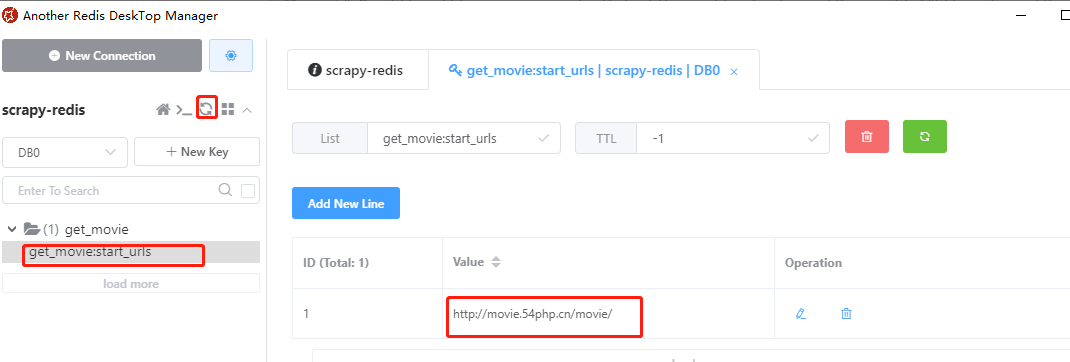
在Another Redis Desktop Manager软件中检查是否添加成功,发现添加成功
step-4:配置文件添加组件及redis参数
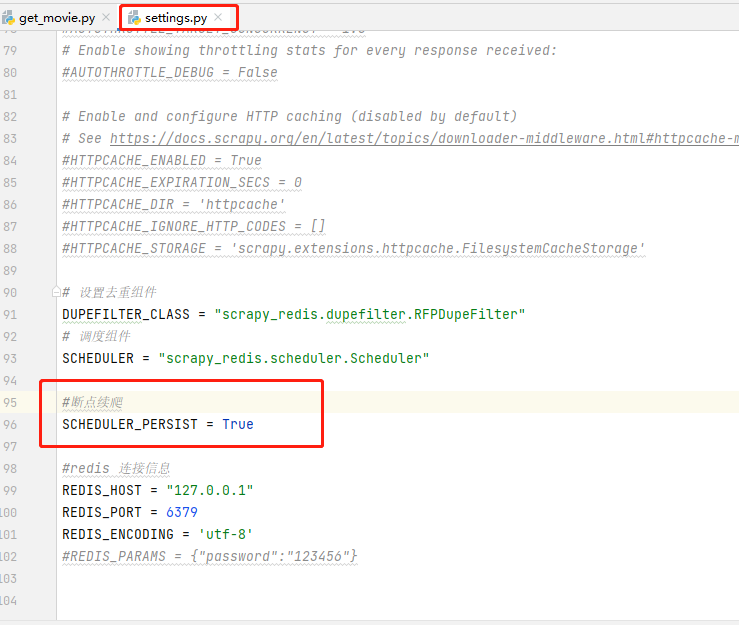
settings.py文件中添加设置去重组件和调度组件,添加redis连接信息;
- 1 # 设置去重组件
- 2 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
- 3 # 调度组件
- 4 SCHEDULER = "scrapy_redis.scheduler.Scheduler"
- 5
- 6 #redis 连接信息
- 7 REDIS_HOST = "127.0.0.1"
- 8 REDIS_PORT = 6379
- 9 REDIS_ENCODING = 'utf-8'
- 10 #REDIS_PARAMS = {"password":"123456"}
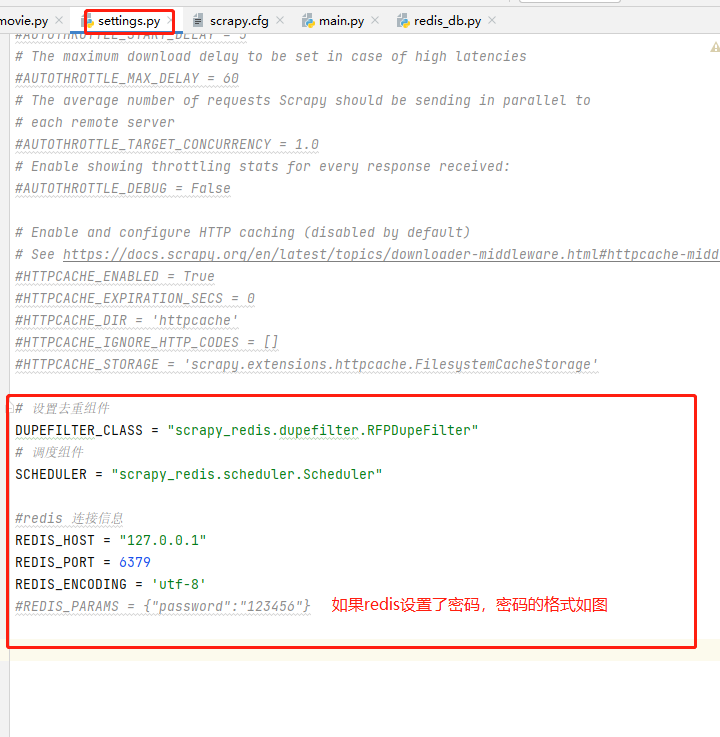
疑问:有人肯定会问,我在settings.py文件中添加了redis的信息,scrapy框架是怎么拿到的呢?
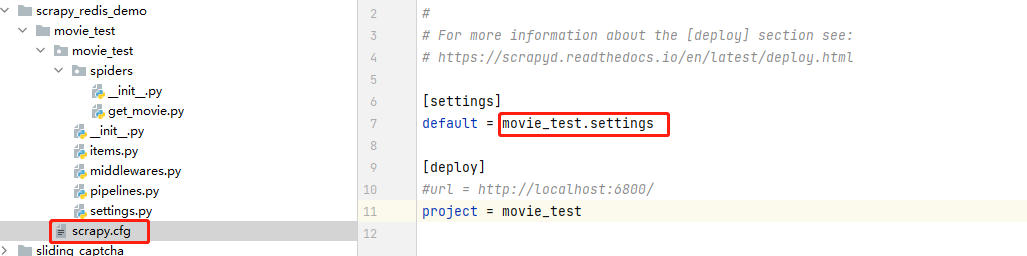
答案:其实在https://www.cnblogs.com/gltou/p/16400449.html这篇的笔记中已经讲到了,scrapy框架的scrapy.cfg文件里面会告诉框架配置文件在哪边,如图,即在movie_test目录下的settings文件中
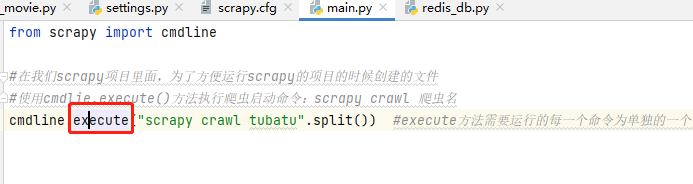
然后scrapy运行怕从文件是通过cmdline的execute方法运行的 ,这个方法其中执行的get_project_settings( )方法,就是导入全局配置文件scrapy.cfg,进而导入项目的settings .py
通过get_project_settings( )这个方法的project.py文件,我们在from部分看到导入了Settings,感兴趣的可以自己研究下源码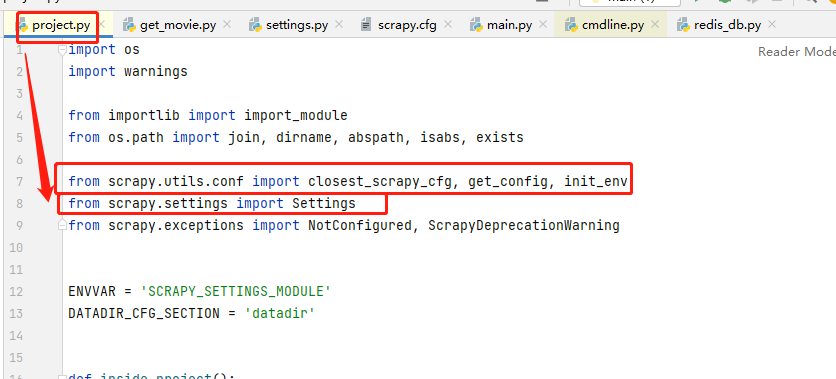
step-5:运行爬虫文件
pycharm输入命令 scrapy crawl get_movie 运行爬虫文件
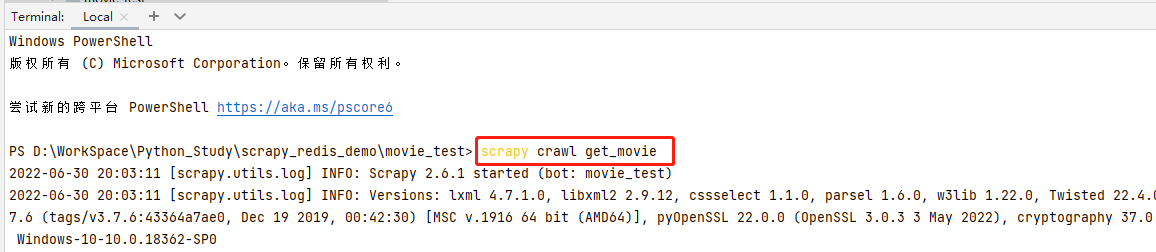
常见报错:

报错分析: 这个是因为我们安装scrapy版本问题导致的,安装Scrapy==2.5.1 版本即可
解决方案:
- pip install -U Scrapy==2.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/

注意:在pycharm中重新安装后,启动爬虫文件如果还报错。在cmd窗口再执行一下pip命令,问题就解决了
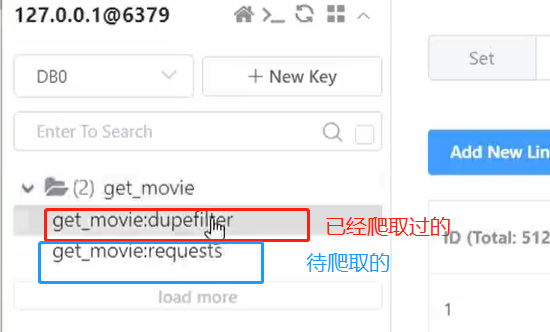
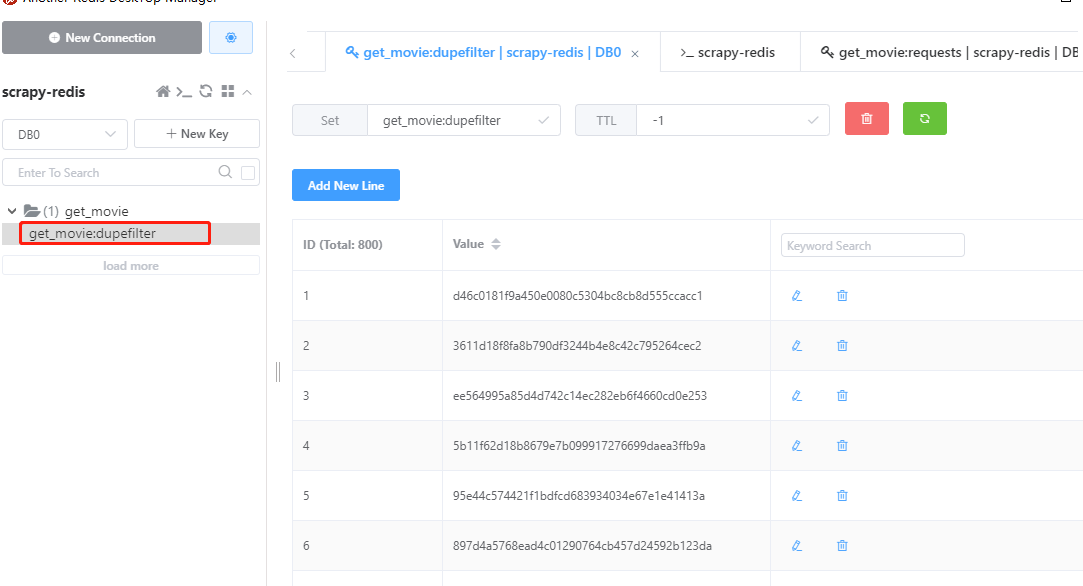
运行爬虫脚本,爬取过程中,发现redis有两张表(易于理解的描述), get_movie:dupefilter 代表已经爬取过的URL, get_movie:requests 代表待爬取的url
爬虫脚本执行成功,查看redis,发现value里面有好多数据,这些数据都是hash值,已经爬取过的url就会以hash的方式存储到value里面,这样就不会重复爬取同一个url。爬取结束后,pycharm中按ctrl+c停止脚本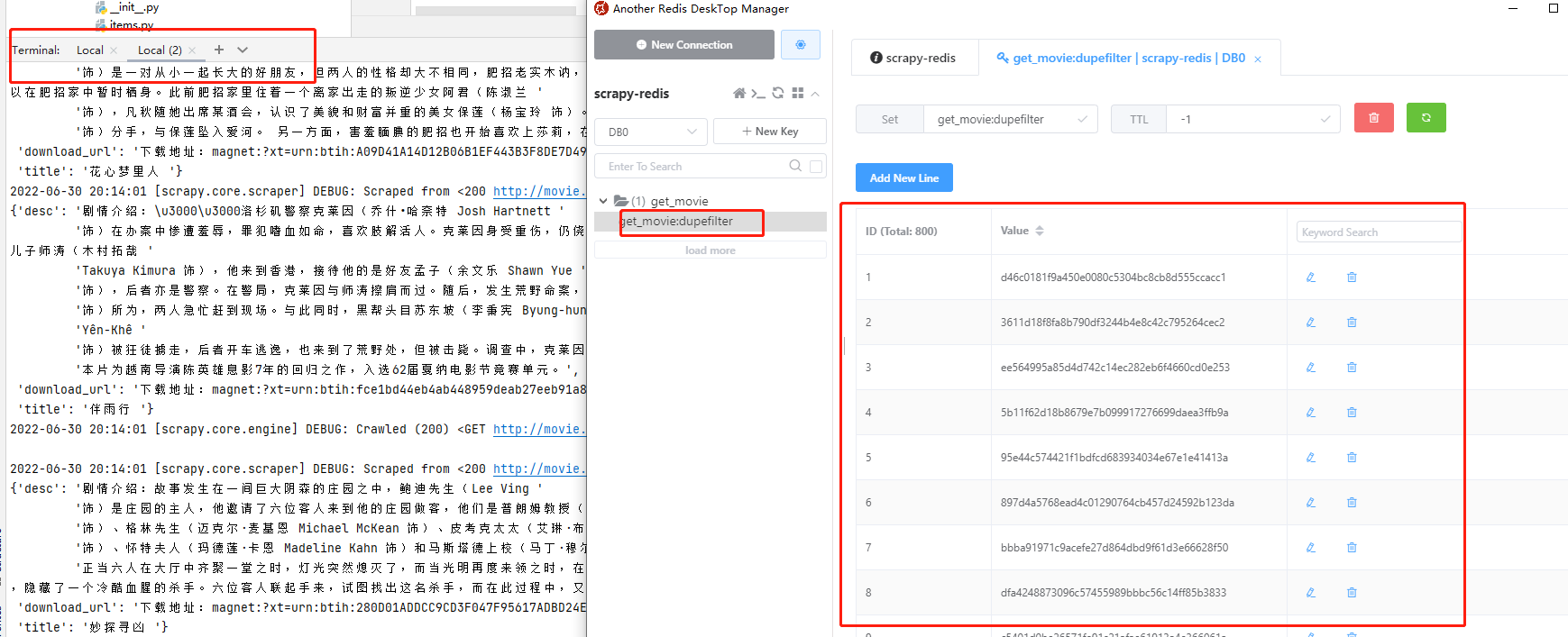
step-6:再次爬取
爬虫脚本执行结束后,redis里面种子url没有了。想要再次执行爬虫脚本,需要将种子再下发给redis,即再执行一次lpush命令,就又可以执行爬虫脚本了。

再次下发种子

执行脚本再次爬取

3.3.3.断点续爬
当爬虫爬取一半中断时,设置了断点续爬后,爬虫会接着爬取,而不会再次重新爬取数据。如何实现断点续爬,很简单,再settings.py文件中开启断点续爬即可
- 1 #断点续爬
- 2 SCHEDULER_PERSIST = True
示例
场景:爬虫到一半我们CTRL+C停止爬虫脚本再次启动爬虫脚本爬取结束后,没有种子url的情况下再次执行爬虫脚本
步骤:
step-1:redis放入种子url执行爬虫,强制停止爬虫脚本
- LPUSH get_movie:start_urls http://movie.54php.cn/movie/
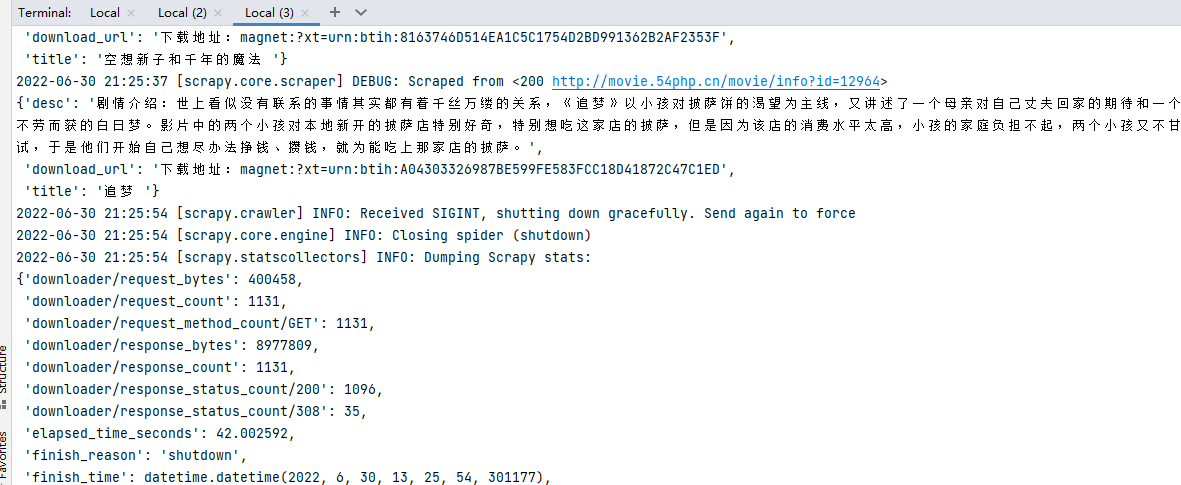

结果:爬取到一半,我们强制停止爬虫脚本,发现redis里面requests的数据还在,没有消失
step-2:再次启动爬虫文件


结果:最后脚本结束统计的爬取数量是第二次爬取的数量,而不是总的数量
step-3:当爬取结束后,我们再次启动爬虫文件
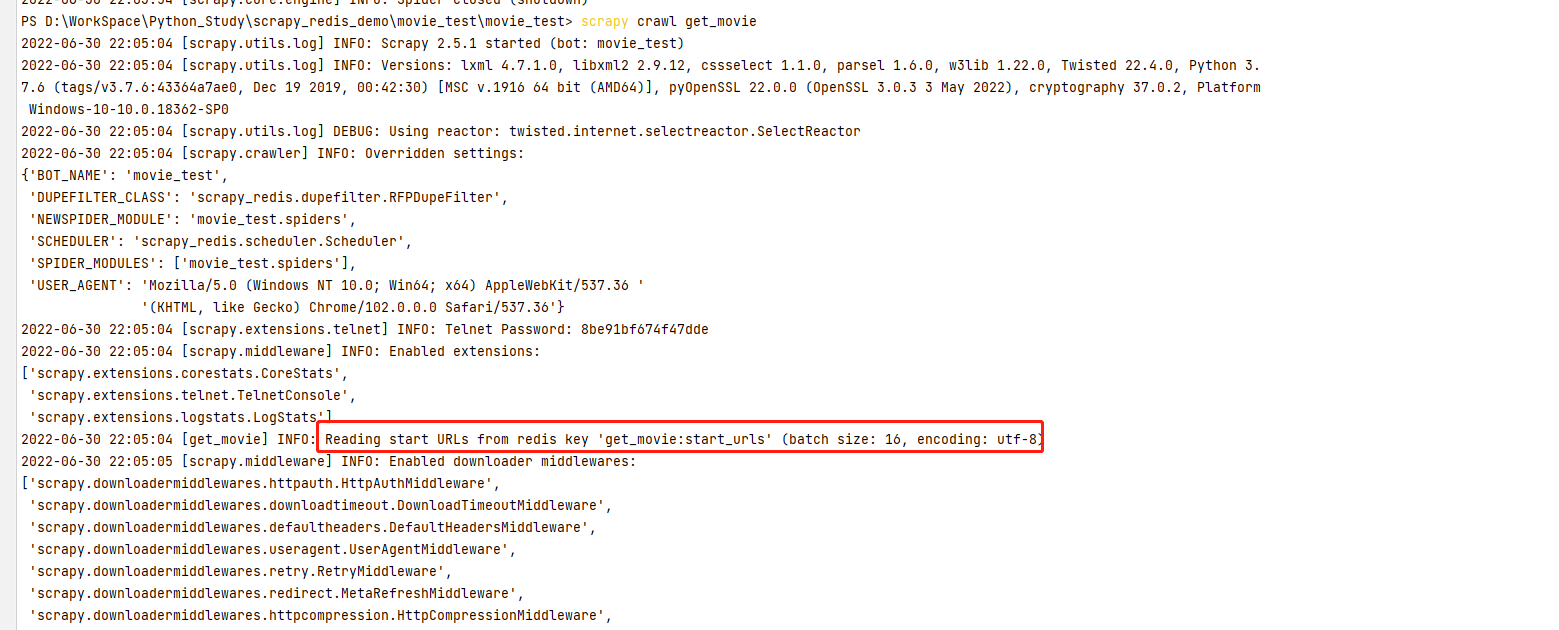
结果:控制台告诉我们 start_urls 已经抓取过了,你要抓取的url在 get_movie:dupefilter 里面都有了,不要要再爬取了
------------------------------------------------------------------------------------------------------------------------------------
思考:在不重新给种子url的情况下,我就是想多次爬取怎么办?
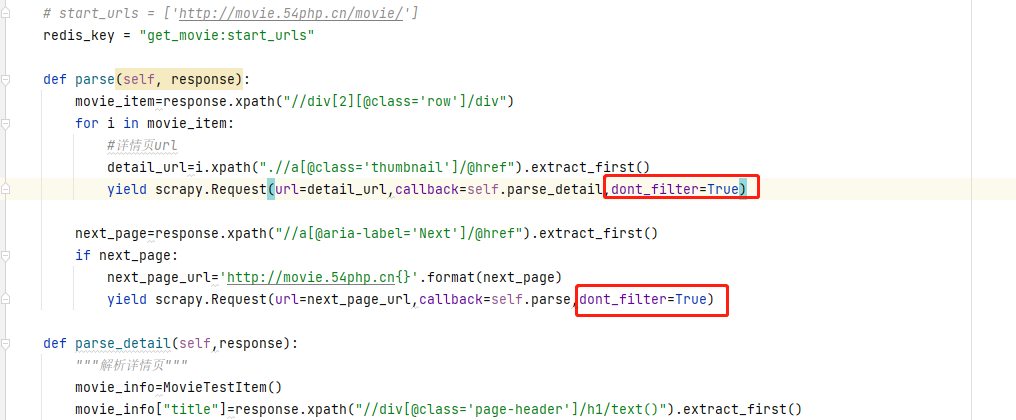
解决方案:在爬虫文件parse方法里面yield回调的时候,加上参数 dont_filter=True 即可再次爬取;dont_filter是scrapy过滤重复请求的,默认为False可以过滤dupefilter中已经抓取过去的请求,避免重复抓取,改为True后即为不过滤,可以再次请求爬取,scrapy提供了这个参数就是让自己去决定这个数据是应该过滤掉还是可以重复抓取
示例
step-1:下发种子url,执行爬虫,等待爬虫结束



step-2:爬取结束,按下CTRL+C停止脚本,按照图示点击Flush DB清空DB,再次执行爬虫脚本;没有传入种子URL的情况下,爬虫可以照常爬取

3.4.实现分布式爬虫
通过实例项目来讲解分布式爬虫的实现;
内容较多,在新的随笔里面:https://www.cnblogs.com/gltou/p/16433539.html
爬虫(14) - Scrapy-Redis分布式爬虫(1) | 详解的更多相关文章
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- scrapy进行分布式爬虫
今天,参照崔庆才老师的爬虫实战课程,实践了一下分布式爬虫,并没有之前想象的那么神秘,其实非常的简单,相信你看过这篇文章后,不出一小时,便可以动手完成一个分布式爬虫! 1.分布式爬虫原理 首先我们来看一 ...
- scrapy补充-分布式爬虫
spiders 介绍:在项目中是创建爬虫程序的py文件 #1.Spiders是由一系列类(定义了一个网址或一组网址将被爬取)组成,具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. #2.换句 ...
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- 小白进阶之Scrapy第六篇Scrapy-Redis详解(转)
Scrapy-Redis 详解 通常我们在一个站站点进行采集的时候,如果是小站的话 我们使用scrapy本身就可以满足. 但是如果在面对一些比较大型的站点的时候,单个scrapy就显得力不从心了. 要 ...
- Scrapy框架的命令行详解【转】
Scrapy框架的命令行详解 请给作者点赞 --> 原文链接 这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: loca ...
- 反射实现Model修改前后的内容对比 【API调用】腾讯云短信 Windows操作系统下Redis服务安装图文详解 Redis入门学习
反射实现Model修改前后的内容对比 在开发过程中,我们会遇到这样一个问题,编辑了一个对象之后,我们想要把这个对象修改了哪些内容保存下来,以便将来查看和追责. 首先我们要创建一个User类 1 p ...
- redis 五种数据结构详解(string,list,set,zset,hash)
redis 五种数据结构详解(string,list,set,zset,hash) Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存 ...
- NoSQL之Redis高级实用命令详解--安全和主从复制
Android IOS JavaScript HTML5 CSS jQuery Python PHP NodeJS Java Spring MySQL MongoDB Redis NOSQL Vim ...
- Redis的事务功能详解
Redis的事务功能详解 MULTI.EXEC.DISCARD和WATCH命令是Redis事务功能的基础.Redis事务允许在一次单独的步骤中执行一组命令,并且可以保证如下两个重要事项: >Re ...
随机推荐
- Android四大组件——Activity——Activity数据回传
既然可以传递数据给下一个Activity,自然也可以返回数据给上一个Activity.返回上一个Activity时只需要点击back键就好,并没有一个用于启动Activity的Intent来传递数据, ...
- 【GPLT】 集合相似度(c++)
题目如下: 这题主要用来练习stl的使用,是一道比较简单的题目 AC代码如下 #include<iostream> #include<cmath> #include<ma ...
- Photoshop图片处理在线网页使用无需下载绿色
今天给大家推荐一个ps在线版网页 实测使用效果不错,绿色简介,无需下载,不卡顿一般的电脑配置都可以带起来 因为是在线的所以是精简版的,但是一般ps软件有的工具,功能他都有,比较适合及时性使用 废话不多 ...
- redis的zset数据结构:跳表
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 广州这边封闭式管理好久了,今天终于周末可以出去溜溜了 什么是zset z ...
- Java多线程—线程同步(单信号量互斥)
JDK中Thread.State类的几种状态 线程的生命周期 线程的安全问题(同步与互斥) 方法一:同步代码块 多个线程的同步监视器(锁)必须的是同一把,任何一个类的对象都可以 syn ...
- clientWidth、offsetWidth、scrollWidth……
1.元素视图属性 clientWidth:元素内容可视区宽度(水平方向 width + 左右 padding). clientHeight:元素内容可视高度(垂直方向 height + 上下paddi ...
- Git 日志提交规范
Commit messages的基本语法 当前业界应用的比较广泛的是 Angular Git Commit Guidelines 具体格式为: <type>: <subject> ...
- JS 异步与 Promise
JS 异步与 Promise 本文写于 2020 年 6 月 8 日 1. 同步与异步与回调函数 Promise 现在是前端面试必考题呀,但是先不急着看 Promise,我们首先来看看什么是异步. - ...
- 手写vue路由
目录 一.简易demo 二.Vue-Router传参方式 三.进阶-路由导航 一.简易demo // routes注册 import Vue from "vue"; // impo ...
- 【FAQ】申请华为运动健康服务授权的4个常见问题及解决方法
华为运动健康服务(HUAWEI Health Kit)提供原子化数据开放,在获取用户对数据的授权后,应用可通过接口访问运动健康数据,对用户数据进行增.删.改.查等操作,为用户提供运动健康类数据服务.这 ...