大数据学习之路又之从csv文件到sql文件的操作过程
根据前几天的测试,简单的做个总结
csv文件的字段说明:

1.将csv文件上传到虚拟机中
在SecureCRT中点击 ,创建目录,直接把文件从本地拖拽进去
,创建目录,直接把文件从本地拖拽进去

我放在了/linmob/data的路径下,所以文件的位置是/linmob/data/sales_sample_20170310.csv
2.在hive命令行中建表,表名要与csv文件中的一一对应,人生建议字段类型都选择varchar
hive
create table sales_sample_20170310(day_id varchar(30),sale_nbr varchar(30),buy_nbr varchar(30),cnt varchar(30),round varchar(30)) row format delimited fields terminated by ',' ;

3.导入数据 其中的路径 '/linmob/data/sales_sample_20170310.csv'和表名 sales_sample_20170310要修改成自己的
load data local inpath '/linmob/data/sales_sample_20170310.csv' overwrite into table sales_sample_20170310;

4.select验证数据是否导入,因为数据量大,一定要limit
select * from sales_sample_20170310 limit 10;
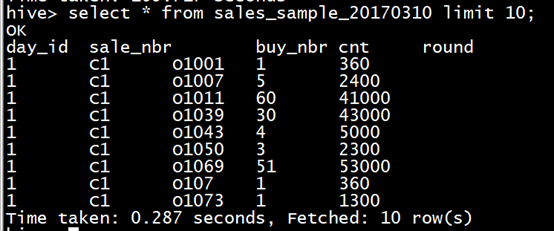
5.退出hive命令行,进入mysql,建表
exit;
mysql -uroot -proot
create table sales_sample_20170310(day_id varchar(30), sale_nbr varchar(30),buy_nbr varchar(30),cnt varchar(30),round varchar(30))charset utf8 collate utf8_general_ci;

6.退出mqsql,进入sqoop的bin目录下,到出数据到mysql数据库中,其中ip地址192.168.111.100、mysql数据库名tab、mysql用户名和密码root、mysql表名 sales_sample_20170310、hive路径名 /user/hive/warehouse/sales_sample_20170310都要换成自己的
hive路径名不清楚?到9870可以找到
./sqoop export --connect "jdbc:mysql://192.168.111.100:3306/tab?characterEncoding=UTF-8" --username root --password root --table sales_sample_20170310 --export-dir /user/hive/warehouse/sales_sample_20170310 --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "," --input-lines-terminated-by "\\n" -m 1
7.数据导出
大数据学习之路又之从csv文件到sql文件的操作过程的更多相关文章
- 大数据学习之路又之从小白到用sqoop导出数据
写这篇文章的目的是总结自己学习大数据的经验,以为自己走了很多弯路,从迷茫到清晰,真的花费了很多时间,希望这篇文章能帮助到后面学习的人. 一.配置思路 安装linux虚拟机--->创建三台虚拟机- ...
- 大数据学习之路------借助HDP SANDBOX开始学习
一开始... 一开始知道大数据这个概念的时候,只是感觉很高大上,引起了我的兴趣.当时也不知道,这个东西是做什么的,有什么用,当然现在看来也是很模糊的样子,但是的确比一开始强了不少. 所以学习的过程可能 ...
- 大数据学习之路(1)Hadoop生态体系结构
Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YARN. Hadoop1.x的生态系统: Hadoop2.x引入YARN: HDFS(Hadoop分布式文件系统)源自于Go ...
- 大数据学习之路之HBASE
Hadoop之HBASE 一.HBASE简介 HBase是一个开源的.分布式的,多版本的,面向列的,半结构化的NoSql数据库,提供高性能的随机读写结构化数据的能力.它可以直接使用本地文件系统,也可以 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习之路-phoenix
1.phoenix安装 ------------------ 1.安装phoenix a)下载apache-phoenix-4.10.0-HBase-1.2-bin.tar.gz 下载网址:htt ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之路-hdfs
1.什么是hadoop hadoop中有3个核心组件: 分布式文件系统:HDFS —— 实现将文件分布式存储在很多的服务器上 分布式运算编程框架:MAPREDUCE —— 实现在很多机器上分布式并行运 ...
- 大数据学习之路——MySQL基础(一)——MySQL的基础知识与常见操作
一.存储引擎 1.含义 存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建.查询.更新和删除数据.不同的存储引擎提供不同的存储机制.索引技巧.锁定水平等功能,使用不同的存储引 ...
随机推荐
- 流程控制、if、elif、else,whilie、break、continue的使用
今日内容 流程控制理论 if判断 while循环 流程控制概念 流程控制就是控制事物的执行流程 执行流程的分类 顺序结构 从上往下依次执行,代码运行流程图如下 分支结构 根据某些条件判断做出不同的运行 ...
- jmeter 24个常用函数
Jmeter_24个常用函数 JMeter提供了很多函数,如果能够熟练使用,可以为脚本带来很多方便. JMeter函数是一种特殊值,可用于除测试计划外的任何组件. 函数调用的格式如下所示:${__ ...
- Linux网卡ifcfg-eth0配置详解
DEVICE="eth1" 网卡名称 NM_CONTROLLED="yes" n ...
- jmeter(二十八)利用beanshell进行多重断言
在接口测试中,我们对返回结果的正确性判断一般是基于响应报文的返回内容进行断言.但有些时候,按照正常的业务逻辑来说,一个请求返回的内容是多种不同的. 比如:用户注册功能,注册成功是正常的返回messag ...
- 『现学现忘』Docker基础 — 22、使用Docker安装Nginx
目录 步骤1:搜索镜像 步骤2:下载Nginx镜像 步骤3:运行Nginx镜像 步骤4:进行本机测试 步骤5:进入容器内操作 步骤6:测试外网访问容器 步骤1:搜索镜像 使用docker search ...
- 基于Zookeeper的分布式锁(干干干货)
原文地址: https://juejin.im/post/5df883d96fb9a0163514d97f 介绍 为什么使用锁 锁的出现是为了解决资源争用问题,在单进程环境下的资源争夺可以使用 JDK ...
- Applied Social Network Analysis in Python 相关笔记
- 25 面向对象编程 继承概念 代码 快捷键 super注意点
继承概念 继承的本质是对某一批的抽象,从而实现对现实世界更美好的建模. extends的意思的"扩展".子类是父类的扩展. JAVA中类只有单继承,没有多继承!理解:一个儿子只能有 ...
- LGP6667题解
既然看到了这道"板子",那还是来写一下题解吧... 如果有机会希望能推一下 载谈binominial sum 的做法. \[\sum_{k=0}^nf(k)\binom n kx^ ...
- 抖音网页版高清视频抓取教程selenium
废话不多说,直接上代码 from selenium import webdriver from selenium.webdriver import ChromeOptions import time ...