终于弄明白了 RocketMQ 的存储模型
RocketMQ 优异的性能表现,必然绕不开其优秀的存储模型 。
这篇文章,笔者按照自己的理解 , 尝试分析 RocketMQ 的存储模型,希望对大家有所启发。
1 整体概览
首先温习下 RocketMQ 架构。
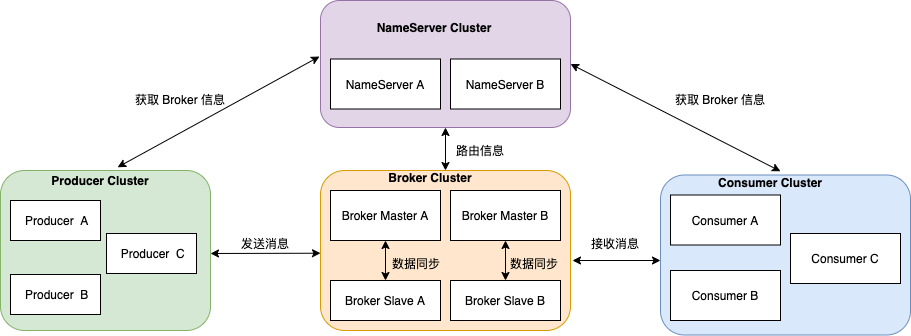
整体架构中包含四种角色 :
Producer :消息发布的角色,Producer 通过 MQ 的负载均衡模块选择相应的 Broker 集群队列进行消息投递,投递的过程支持快速失败并且低延迟。
Consumer :消息消费的角色,支持以 push 推,pull 拉两种模式对消息进行消费。
NameServer :名字服务是一个非常简单的 Topic 路由注册中心,其角色类似 Dubbo 中的 zookeeper ,支持 Broker 的动态注册与发现。
BrokerServer :Broker 主要负责消息的存储、投递和查询以及服务高可用保证 。
本文的重点在于分析 BrokerServer 的消息存储模型。我们先进入 broker 的文件存储目录 。

消息存储和下面三个文件关系非常紧密:
数据文件 commitlog
消息主体以及元数据的存储主体 ;
消费文件 consumequeue
消息消费队列,引入的目的主要是提高消息消费的性能 ;
索引文件 index
索引文件,提供了一种可以通过 key 或时间区间来查询消息。
RocketMQ 采用的是混合型的存储结构,Broker 单个实例下所有的队列共用一个数据文件(commitlog)来存储。
生产者发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 commitlog 文件中。只要消息被刷盘持久化至磁盘文件 commitlog 中,那么生产者发送的消息就不会丢失。
Broker 端的后台服务线程会不停地分发请求并异步构建 consumequeue(消费文件)和 indexFile(索引文件)。
2 数据文件
RocketMQ 的消息数据都会写入到数据文件中, 我们称之为 commitlog 。
所有的消息都会顺序写入数据文件,当文件写满了,会写入下一个文件。

如上图所示,单个文件大小默认 1G , 文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0 ,文件大小为1 G = 1073741824。
当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。
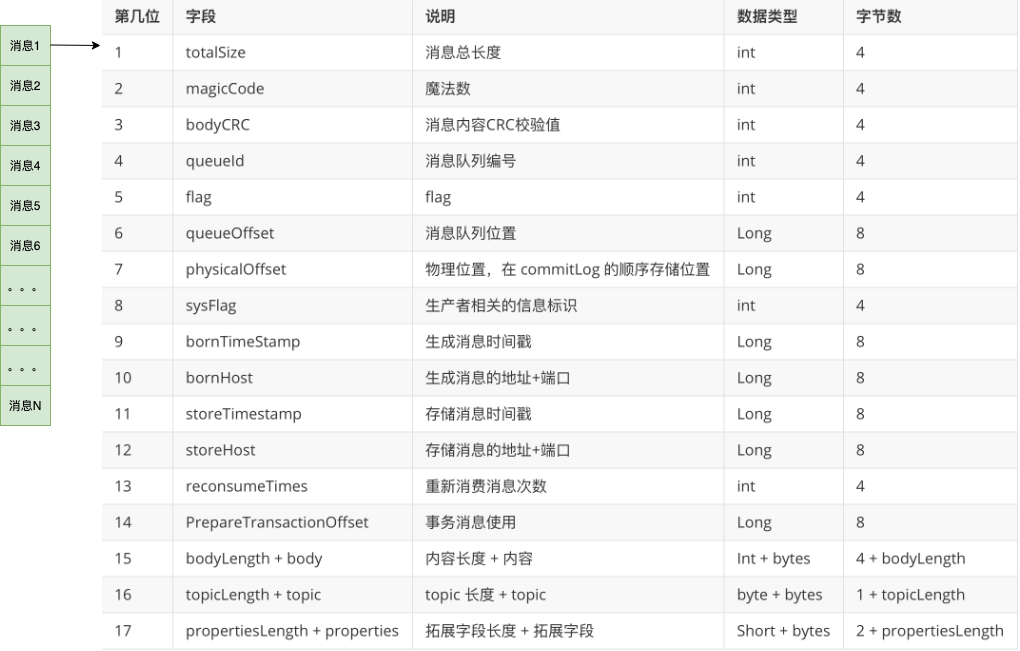
从上图中,我们可以看到消息是一条一条写入到文件,每条消息的格式是固定的。
这样设计有三点优势:
顺序写
磁盘的存取速度相对内存来讲并不快,一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO 。
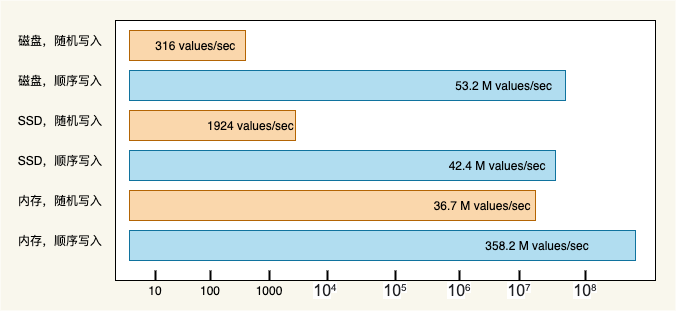
《 The Pathologies of Big Data 》这篇文章指出:内存随机读写的速度远远低于磁盘顺序读写的速度。磁盘顺序写入速度可以达到几百兆/s,而随机写入速度只有几百 KB /s,相差上千倍。
快速定位
因为消息是一条一条写入到 commitlog 文件 ,写入完成后,我们可以得到这条消息的物理偏移量。
每条消息的物理偏移量是唯一的, commitlog 文件名是递增的,可以根据消息的物理偏移量通过二分查找,定位消息位于那个文件中,并获取到消息实体数据。
通过消息 offsetMsgId 查询消息数据
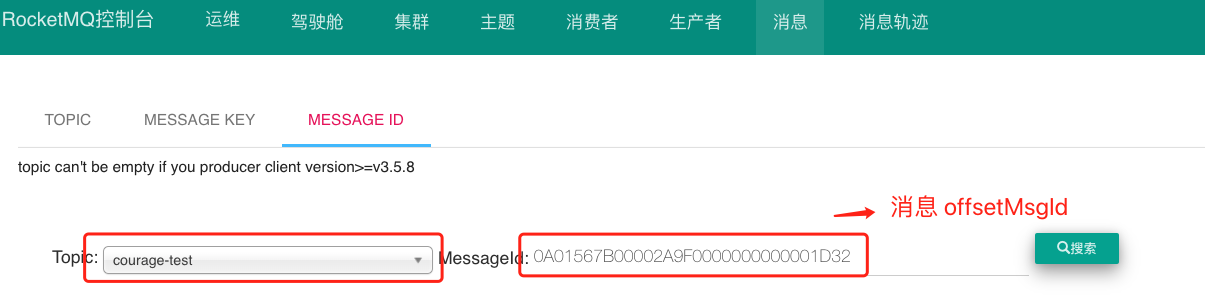
消息 offsetMsgId 是由 Broker 服务端在写入消息时生成的 ,该消息包含两个部分:
Broker 服务端 ip + port 8个字节;
commitlog 物理偏移量 8个字节 。
我们可以通过消息 offsetMsgId ,定位到 Broker 的 ip 地址 + 端口 ,传递物理偏移量参数 ,即可定位该消息实体数据。
3 消费文件
在介绍 consumequeue 文件之前, 我们先温习下消息队列的传输模型-发布订阅模型 , 这也是 RocketMQ 当前的传输模型。
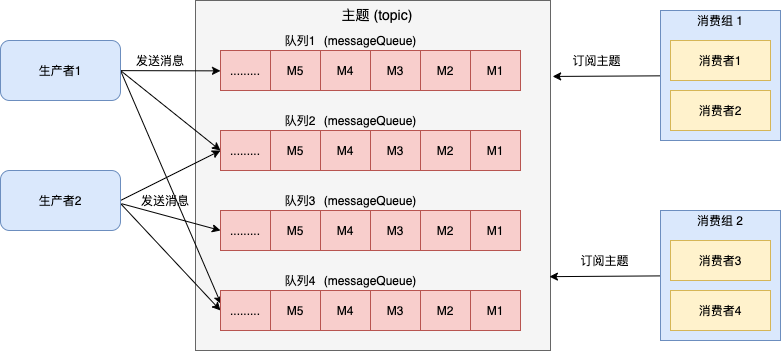
发布订阅模型具有如下特点:
- 消费独立:相比队列模型的匿名消费方式,发布订阅模型中消费方都会具备的身份,一般叫做订阅组(订阅关系),不同订阅组之间相互独立不会相互影响。
- 一对多通信:基于独立身份的设计,同一个主题内的消息可以被多个订阅组处理,每个订阅组都可以拿到全量消息。因此发布订阅模型可以实现一对多通信。
因此,rocketmq 的文件设计必须满足发布订阅模型的需求。
那么仅仅 commitlog 文件是否可以满足需求吗 ?
假如有一个 consumerGroup 消费者,订阅主题 my-mac-topic ,因为 commitlog 包含所有的消息数据,查询该主题下的消息数据,需要遍历数据文件 commitlog , 这样的效率是极其低下的。
进入 rocketmq 存储目录,显示见下图:
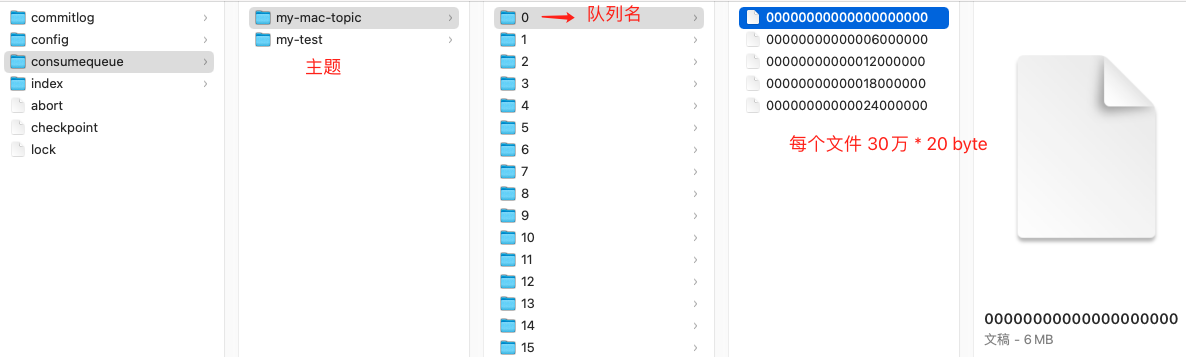
- 消费文件按照主题存储,每个主题下有不同的队列,图中 my-mac-topic 有 16 个队列 ;
- 每个队列目录下 ,存储 consumequeue 文件,每个 consumequeue 文件也是顺序写入,数据格式见下图。

每个 consumequeue 包含 30 万个条目,每个条目大小是 20 个字节,每个文件的大小是 30 万 * 20 = 60万字节,每个文件大小约5.72M 。和 commitlog 文件类似,consumequeue 文件的名称也是以偏移量来命名的,可以通过消息的逻辑偏移量定位消息位于哪一个文件里。
消费文件按照主题-队列来保存 ,这种方式特别适配发布订阅模型。
消费者从 broker 获取订阅消息数据时,不用遍历整个 commitlog 文件,只需要根据逻辑偏移量从 consumequeue 文件查询消息偏移量 , 最后通过定位到 commitlog 文件, 获取真正的消息数据。
这样就可以简化消费查询逻辑,同时因为同一主题下,消费者可以订阅不同的队列或者 tag ,同时提高了系统的可扩展性。
4 索引文件
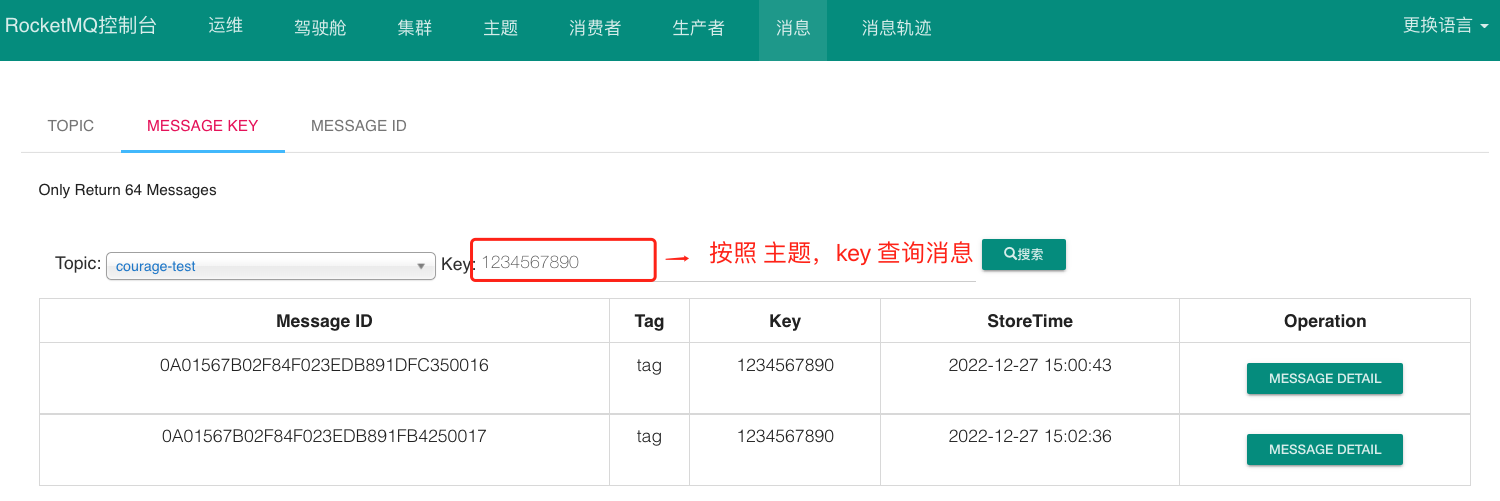
每个消息在业务层面的唯一标识码要设置到 keys 字段,方便将来定位消息丢失问题。服务器会为每个消息创建索引(哈希索引),应用可以通过 topic、key 来查询这条消息内容,以及消息被谁消费。
由于是哈希索引,请务必保证key尽可能唯一,这样可以避免潜在的哈希冲突。
//订单Id
String orderId = "1234567890";
message.setKeys(orderId);
从开源的控制台中根据主题和 key 查询消息列表:
进入索引文件目录 ,如下图所以:
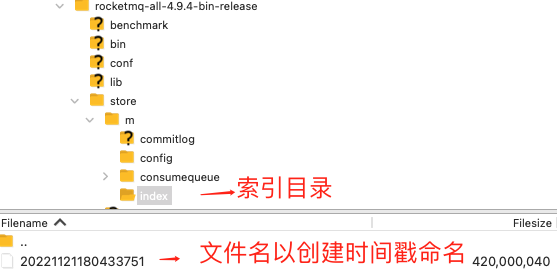
索引文件名 fileName 是以创建时的时间戳命名的,固定的单个 IndexFile 文件大小约为 400 M 。
IndexFile 的文件逻辑结构类似于 JDK 的 HashMap 的数组加链表结构。
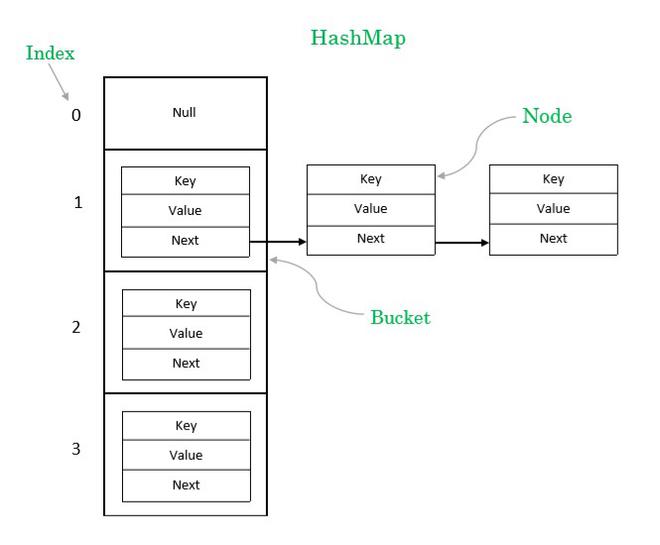
索引文件主要由 Header、Slot Table (默认 500 万个条目)、Index Linked List(默认最多包含 2000万个条目)三部分组成 。
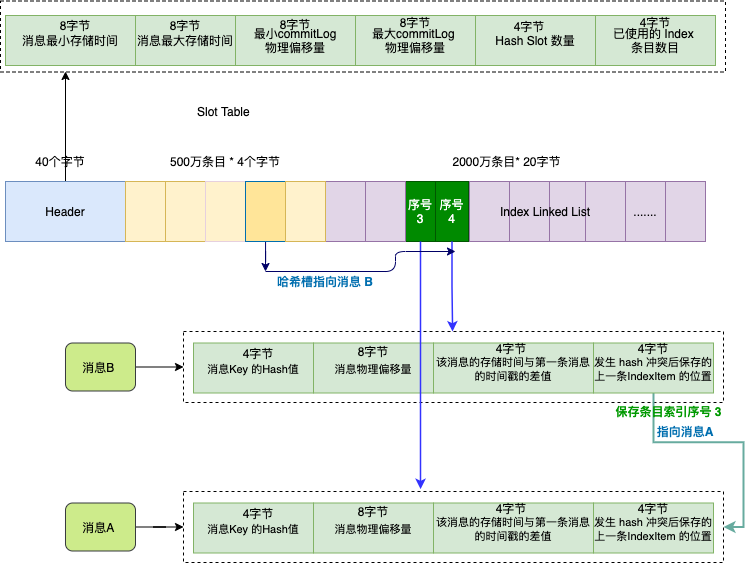
假如订单系统发送两条消息 A 和 B , 他们的 key 都是 "1234567890" ,我们依次存储消息 A , 消息 B 。
因为这两个消息的 key 的 hash 值相同,它们对应的哈希槽(深黄色)也会相同,哈希槽会保存的最新的消息 B 的索引条目序号 , 序号值是 4 ,也就是第二个深绿色条目。
而消息 B 的索引条目信息的最后 4 个字节会保存上一条消息对应的索引条目序号,索引序号值是 3 , 也就是消息 A 。
5 写到最后
Databases are specializing – the “one size fits all” approach no longer applies ------ MongoDB设计哲学
RocketMQ 存储模型设计得非常精巧,笔者觉得每种设计都有其底层思考,这里总结了三点 :
- 完美适配消息队列发布订阅模型 ;
- 数据文件,消费文件,索引文件各司其职 ,同时以数据文件为核心,异步构建消费文件 + 索引文件这种模式非常容易扩展到主从复制的架构;
- 充分考虑业务的查询场景,支持消息 key ,消息 offsetMsgId 查询消息数据。也支持消费者通过 tag 来订阅主题下的不同消息,提升了消费者的灵活性。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!

终于弄明白了 RocketMQ 的存储模型的更多相关文章
- 关于java中是引用传递还是值传递的问题!!!经常在笔试中遇到,今天终于弄明白了!
关于JAVA中参数传递问题有两种,一种是按值传递(如果是基本类型),另一种是按引用传递(如果是對象).首先以两个例子开始:1)public class Test2 { public static vo ...
- 终于弄明白了 Singleton,Transient,Scoped 的作用域是如何实现的
一:背景 1. 讲故事 前几天有位朋友让我有时间分析一下 aspnetcore 中为什么向 ServiceCollection 中注入的 Class 可以做到 Singleton,Transient, ...
- PID算法终于弄明白原理了,原来就这么简单
看起来PID高大尚,实则我们都是被他的外表所震撼住了.先被别人唬住,后被公式唬住,由于大多数人高数一点都不会或者遗忘,所以再一看公式,简直吓死.了解了很浅的原理后,结果公式看不懂,不懂含义,所以最终没 ...
- 弄明白CMS和G1,就靠这一篇了
目录 1 CMS收集器 安全点(Safepoint) 安全区域 2 G1收集器 卡表(Card Table) 3 总结 4 参考 在开始介绍CMS和G1前,我们可以剧透几点: 根据不同分代的特点,收集 ...
- 几张图弄明白ios布局中的尺寸问题
背景 先说说逆向那事.各种曲折..各种技术过时,老老实实在啃看雪的帖子..更新会有的. 回正题,这里讨论的是在Masnory框架下的布局问题.像我这种游击队没师傅带,什么都得自己琢磨,一直没闹明白下面 ...
- 终于搞明白Unicode,ASCII,UTF8,UCS2编码是啥了
[本文版权归微信公众号"代码艺术"(ID:onblog)所有,若是转载请务必保留本段原创声明,违者必究.若是文章有不足之处,欢迎关注微信公众号私信与我进行交流!] 前言 本文起因于 ...
- Entity Framework 6 Recipes 2nd Edition(10-5)译 -> 在存储模型中使用自定义函数
10-5. 在存储模型中使用自定义函数 问题 想在模型中使用自定义函数,而不是存储过程. 解决方案 假设我们数据库里有成员(members)和他们已经发送的信息(messages) 关系数据表,如Fi ...
- SQLite剖析之存储模型
前言 SQLite作为嵌入式数据库,通常针对的应用的数据量相对于DBMS的数据量小.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这 ...
- Bitcask 存储模型
Bitcask 存储模型 Bitcask 是一个日志型.基于hash表结构的key-value存储模型,以Bitcask为存储模型的K-V系统有 Riak和 beansdb新版本. 日志型数据存储 何 ...
- LSM存储模型
LSM存储模型 数据库有3种基本的存储引擎: 哈希表,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统.对于key-value的插入以及查询,哈希表的复杂度 ...
随机推荐
- 洛谷P4011 【网络流24题】 孤岛营救问题 (BFS+状压)
一道妙题啊......(不知道为什么这道题的标签是网络流,不需要用网络流啊) 如果没有门和钥匙,连边(边权为1)求最短路就行了. 但是有这两个因素的限制,我们采用分层建图的思想,一共2p层,每层对应持 ...
- MySQL基础、MySQL安装和MariaDB安装
MySQL基础 目录 MySQL基础 关系型数据库介绍 数据结构模型 RDBMS专业名词 关系型数据库的常见组件 SQL语句 MySQL安装与配置 MySQL安装 MariaDB安装 关系型数据库介绍 ...
- java集合框架复习----(1)
文章目录 1 .集合框架思维导图 一.什么是集合 二.collection接口 1 .集合框架思维导图 一.什么是集合 存放在java.util.*.是一个存放对象的容器. 存放的是对象的引用,不是对 ...
- 分享个好东西 - 两行前端代码搞定bilibili链接转视频
只需要在您的要解析B站视频的页面的</body>前面加上下面两行代码即可,脚本会在客户端浏览器里解析container所匹配到的容器里的B站超链接 (如果不是外围有a标签的超链接只是纯粹的 ...
- .NET性能系列文章一:.NET7的性能改进
这些方法在.NET7中变得更快 照片来自 CHUTTERSNAP 的 Unsplash 欢迎阅读.NET性能系列的第一章.这一系列的特点是对.NET世界中许多不同的主题进行研究.比较性能.正如标题所说 ...
- python查找相似图片或重复图片
1.查找重复图片 利用文件的MD5值可查找完全一样的重复图片 import os,time,hashlib def getmd5(file): if not os.path.isfile(file): ...
- Java获取/resources目录下的资源文件方法
Web项目开发中,经常会有一些静态资源,被放置在resources目录下,随项目打包在一起,代码中要使用的时候,通过文件读取的方式,加载并使用: 今天总结整理了九种方式获取resources目录下文件 ...
- 无线adb连接
使用USB数据线连接Android设备; 在dos命令行输入adb tcpip [xxxx]命令 (例如:adb tcpip 8888,xxx代表端口号); 断开USB数据线(数据线和设备断开连接 ...
- Linux环境jdk安装配置
1.jdk安装包:jdk-8u191-linux-x64.tar.gz2.拷贝 jdk-8u191-linux-x64.tar.gz 到/usr/local命令如下:cp jdk-8u191-linu ...
- 嵌入式-C语言基础:二级指针
二级指针:可以理解为指向指针的指针,存放的是指针变量的地址. 下面用一级指针来保存一个指针变量的地址: #include<stdio.h> int main() { int *p1; in ...