Java多线程下载分析
为什么要多线程下载
俗话说要以终为始,那么我们首先要明确多线程下载的目标是什么,不外乎是为了更快的下载文件。那么问题来了,多线程下载文件相比于单线程是不是更快?
对于这个问题可以看下图。
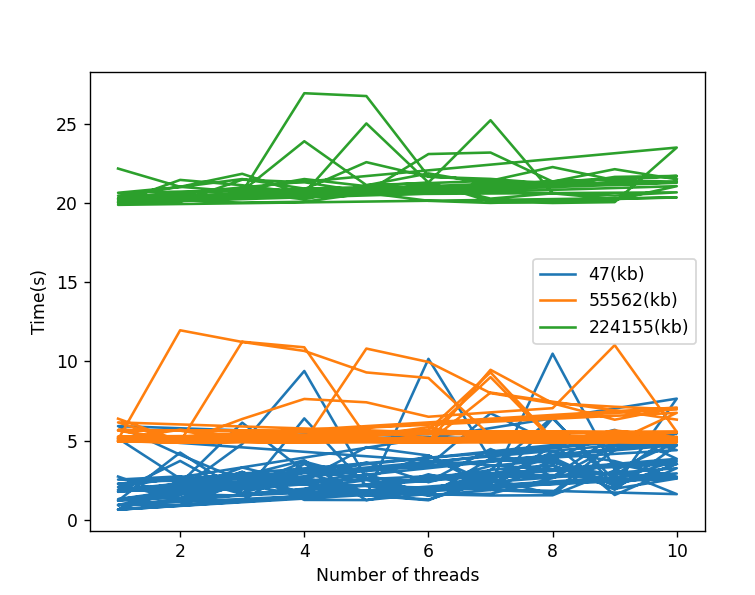
横坐标是线程数,纵坐标是使用对应线程数下载对应文件时花费的时间,蓝橙绿代表下载文件的大小,每个线程下载对应文件20次,根据对应数据绘制了上图。
可以看出在忽略个别网络波动出现的突出点后,整体的趋势是线程数量的提升对下载速度没有多大影响。根据上述图片可以得出的结论是,单线程下载就够了,还需要多线程下载干嘛?既没有提升还增加麻烦。
根据目前测试结果来看这个结论是没有问题的。那我们试着在分析下问题,想一想此时为什么多线程下载没有作用?可以看下橙色线条下载文件为55M左右,下载时间平均在5s左右,平均下载速度大概为11M左右,还有绿色线条文件大概224M,下载速度平均为20s,平均下载速度大概在11M左右。而我本地网络是100M宽带,实际下行速率的上限是12.5M,可以看出下载速度已经逼近下行峰值。此时无论是单个线程还是多个线程都可以将下载带宽跑满,那么即使是开多个线程也不能把本地带宽提高,你也不能把本地100M带宽变成300M,所以这里使用多线程进行下载速度基本不可能提升了,除非我换宽带加到300M或更大。这里可以看出是本地带宽限制了下载速度。
由此我们可以得出结论,下载速度由本地带宽决定,本地带宽已经跑满的情况下,下载速度无法进行提升,这个也比较符合我们的正常逻辑,网速不够怎么办,换更大的带宽,速度自然提升,当然也意味着交更多的钱....。
那么问题真的是如此吗,比如我们知道的某网盘,管你本地带宽多大,我都只有几十或几百k的下载速度。你强任你强,你能跑满带宽算我输!!!当然开VIP还是可以享受加速服务的,加速二字划重点。
此时可以看出是服务器端限制了下载速度,即使我本地有很大带宽但依然跑不满。那么这个时候我上多线程会有提升吗?可以看下图。
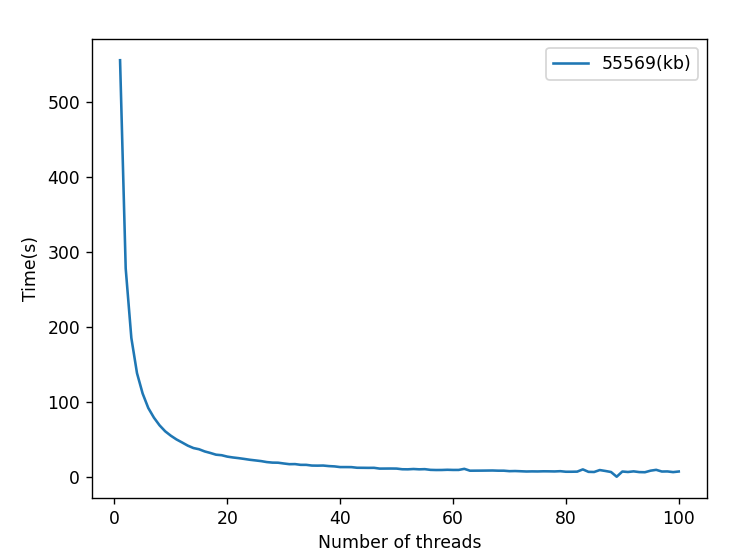
这是一个下载文件限速的网址,使用不同线程数进行下载,根据线程数和下载花费时间绘制的图片。可以看到随着线程数的增加,下载速度显著提升,一个线程情况下55M文件下载了550s左右,平均速度为100k每秒,100个线程下载大概需要6秒,平均速度大概为9M每秒,加上线程创建请求等开销基本逼近本地带宽上限。
由上述可知,在服务器不限速或者说服务器的传输速度大于等于本地带宽的情况下,单线程下载足矣。在服务器对单个连接下载限速时,使用多线程可以提升下载速度。但服务器本身的带宽也是有限的,例如服务器带宽为300M,下载速度可达37.5M/s.这时有多个用户在进行下载,此时可能开了多线程也不会有太大收益,服务器本身带宽已经很紧张了,你也不能无中生有,突破带宽本身的上限。就有点像抢票软件,资源没那么紧张的使用抢票软件有一定提升可以方便抢到,等到春运时即使用抢票软件抢,也很难抢到票。
前置条件
上述说明了在什么时候可以快的问题。可以看出在特定情况下还是有收益的,既然有收益,那么就值得我们去做。既然要做那么就面临第一个问题,能不能做?怎么做是第二步,第一步首先要考虑能不能做的问题,违法的事情当然不能做,受客观条件限制目前做不了的事也不能做。
那么首先可以想一想多线程下载的大概思路,一个线程下载一部分,然后将所有下载好的内容组装再一次。比如一个文件有2kb(2048byte),一共两个线程下载,第一个线程下载第一个1kb,第二个线程下载第二个1kb,然后将第一个下载好的1kb写入文件,接着将下载好的第二个1kb写入文件,下载完成。
实现上述流程,向服务器请求时,服务器必须能返回下载文件指定范围的数据。也就是说服务器需要支持http请求中的关键字Range.Range的常规格式为Range : bytes=start-end其中start表示起始字节,end表示结束字节,start和end位都包含在内,既左右都是闭区间 [start,end],如bytes=0-1表示第0个字节和第1个字节,一共2个字节。如一个文件大小为10byte,分三个线程线程下载那么三个请求的Range分别为bytes=0-2,bytes=3-5,bytes=6-9.分别下载3byte,3byte,4byte.
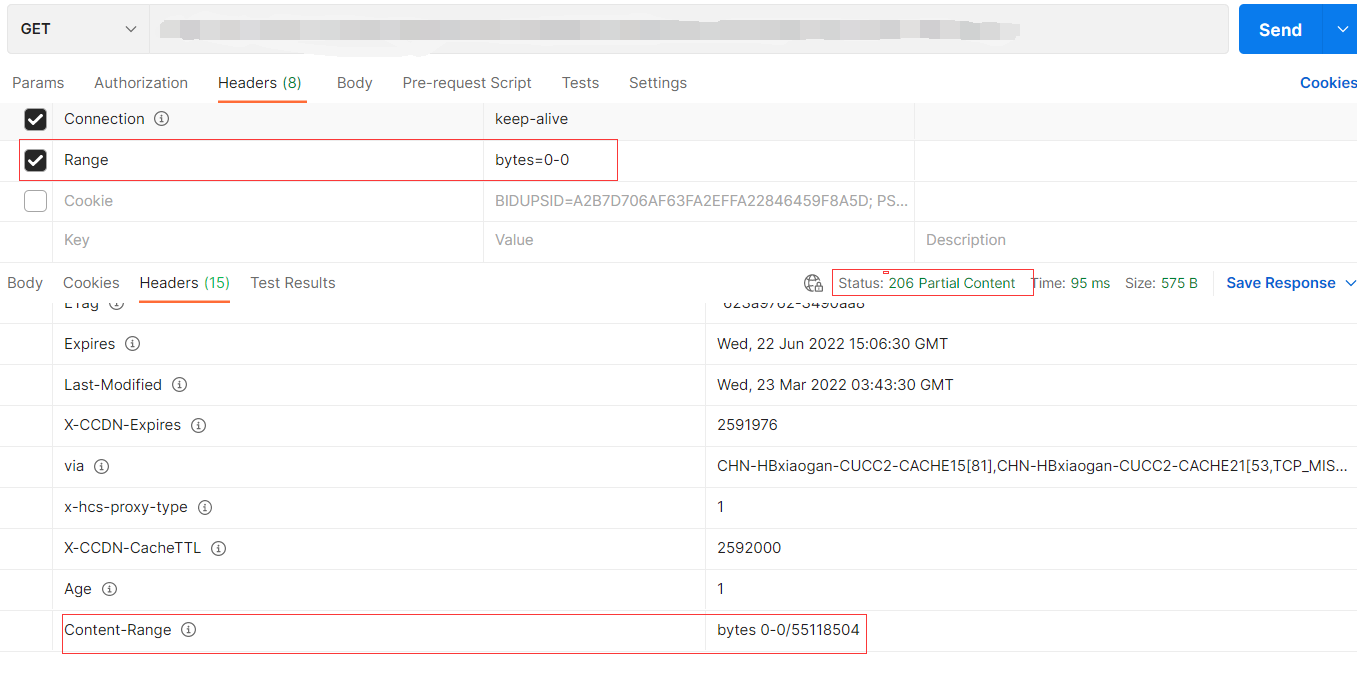
那么如何确定服务器是否支持Range呢,你可以对下载文件发送一个带Range的请求,可以将请求头中Ragne设置为bytes=0-0.看返回的状态码是否为206.如果时206表示支持Ragne,并且返回的响应头中也会有Content-Range字段标识当前请求的字节范围,文件总大小。例如文件大小为55118504byte,请求bytes=0-0,会返回一个Content-Range : bytes 0-0/55118504.
可以使用postman发送请求判断
也可以使用java判断是否支持Range
public static boolean supportRange(String urlPath) throws IOException {
URL url = new URL(urlPath);
URLConnection urlConnection = url.openConnection();
urlConnection.setRequestProperty("Range", "bytes=0-0");
return ((HttpURLConnection) urlConnection).getResponseCode() == HttpURLConnection.HTTP_PARTIAL;//206
}
如果服务器不支持Range,那就没办法呢,老老实实用单线程下载,毕竟巧妇难为无米之炊。
主要步骤
首先肯定是判断服务器支不支持Range,在支持的基础上首先获取文件长度,然后将文件长度根据线程数计算每个线程的请求范围。然后所有线程去发送请求,请求结束后将返回结果组装,大功告成。
这里需要注意下载后数据组装顺序的问题,多线程发送请求下载指定范围的数据,可能最后一部分数据最先返回,这时需要注意数据应写入下载后文件对应位置。不能把最后10个字节写入开始位置,同样开始10个字节也不能写到文件其他位置上。
具体代码
在编写代码前,需要最好找一个对下载限速的网站,测试开启多线程后的提升。本来想试下某盘的,结果折腾半天还是没有拿到真实下载地址,后来经过很长(查找不易,欢迎点赞)时间的查找,发现 这个网站的历史软件版本下载是限速的,进入具体软件下载页面后,不要点页面开始位置的本地纯净下载(这个是不限速的),拉到页面下方点击历史版本下载中的本地下载,然后在chrome浏览器的下载管理中复制的下载链接进行测试的,希望大家文明测试下载。
package org.hcf.utils;
import lombok.extern.slf4j.Slf4j;
import java.io.*;
import java.math.BigDecimal;
import java.net.*;
import java.util.*;
import java.util.concurrent.*;
@Slf4j
public class FileUtils {
/**
* 多线程下载指定文件,写入outputStream中
* @param fileUrl 文件路径
* @param executor 线程池,根据线程池核心线程数量创建下载请求,如线程池核心线程数为3,创建3个下载请求。
* @param outputStream 下载文件输出流
* @throws IOException
* @throws URISyntaxException
* @throws InterruptedException
*/
public static void fileMultithreadingDownload(String fileUrl, ThreadPoolExecutor executor, OutputStream outputStream) throws IOException, URISyntaxException, InterruptedException {
if (!supportRange(fileUrl)) {
throw new UnsupportedOperationException("unsupported operation exception");
}
long startTime = System.currentTimeMillis();
// 获取下载文件大小
long contentLengthLong = getContentLengthLong(fileUrl);
// 根据核心线程数,计算请求数据大小。
int corePoolSize = executor.getCorePoolSize();
// 如contentLengthLong(文件长度)=10 下载线程数(corePollSize)=3。
//requestSize = 向上取整((10 / 3)) = 4
int requestSize = new BigDecimal(String.valueOf(Math.ceil(contentLengthLong / (corePoolSize + 0.0)))).intValue();
//根据文件每次请求数据大小和文件大小,计算请求范围。
//如requestSize = 4, contentLengthLong = 10,requestRanges=[0-3, 4-7, 8-9]
List<String> rangeList = getRangeSize(contentLengthLong, requestSize);
CountDownLatch countDownLatch = new CountDownLatch(rangeList.size());
Map<Long, byte[]> result = new ConcurrentHashMap<>();
//rangeList = [0-3, 4-7, 8-9],多线程请求对应范围数据
for (String range : rangeList) {
executor.execute(() -> {
Long start = Long.valueOf(range.split("-")[0]);
//获取文件指定range数据,并用范围起始位置作为key,用于后续排序组装。
result.put(start, getRangeDataByFile(fileUrl, range));
//下载完成一个range,计数-1
countDownLatch.countDown();
});
}
//等待所有线程下载完成后组合
countDownLatch.await();
//根据result的key升序顺序将数据写入输出流
new ArrayList<>(result.keySet()).stream()
.sorted()
.forEach(e ->
ExceptionRound.execute(() ->
outputStream.write(result.get(e)))
);
outputStream.flush();
outputStream.close();
long timer = System.currentTimeMillis() - startTime;
log.info("{},{},{}", contentLengthLong, corePoolSize, timer);
}
/**
* 获取文件指定range数据
*
* @param fileUrl 文件路径
* @param range 指定范围 如 range = 0-3 ,获取文件第开头4个字节
* @return
*/
private static byte[] getRangeDataByFile(String fileUrl, String range) {
return ExceptionRound.execute(() -> {
URL url = new URL(fileUrl);
HttpURLConnection downloadConnection = (HttpURLConnection) url.openConnection();
downloadConnection.setRequestMethod("GET");
downloadConnection.setRequestProperty("Range", String.format("bytes=%s", range));
InputStream inputStream = downloadConnection.getInputStream();
byte[] byt = new byte[4096];
int readSize;
ByteArrayOutputStream tempOutput = new ByteArrayOutputStream();
while ((readSize = inputStream.read(byt)) != -1) {
tempOutput.write(byt, 0, readSize);
}
inputStream.close();
return tempOutput.toByteArray();
});
}
/**
* 获取文件长度
* @param fileUrl
* @return
* @throws IOException
*/
public static long getContentLengthLong(String fileUrl) throws IOException {
URL url = new URL(fileUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
urlConnection.setRequestMethod("HEAD");
urlConnection.setRequestProperty("Accept-Encoding", "identity");
long contentLengthLong = urlConnection.getContentLengthLong();
urlConnection.disconnect();
return contentLengthLong;
}
/**
* 获取请求range列表
* 如contentLengthLong = 10,requestSize = 4,
* result[0-3, 4-7, 8-9]
* @param contentLengthLong 文件总长度
* @param requestSize 每次下载字节数
* @return
*/
private static List<String> getRangeSize(long contentLengthLong, int requestSize) {
LinkedList<String> result = new LinkedList<>();
for (long start = 0; start < contentLengthLong; ) {
long end = Math.min((start + (requestSize - 1)), contentLengthLong - 1);
result.add(String.format("%d-%d", start, end));
start = end + 1L;
}
return result;
}
/**
* 判断是否支持range请求头
* @param urlPath
* @return
* @throws IOException
*/
public static boolean supportRange(String urlPath) throws IOException {
URL url = new URL(urlPath);
URLConnection urlConnection = url.openConnection();
urlConnection.setRequestProperty("Range", "bytes=0-0");
return ((HttpURLConnection) urlConnection).getResponseCode() == HttpURLConnection.HTTP_PARTIAL;
}
}
/**
* 使用 ExceptionRound.execute包裹代码,避免try catch
*/
@Slf4j
class ExceptionRound {
public static <T> T execute(SupplierExecute<T> command) {
try {
return command.get();
} catch (Exception e) {
log.error("exception", e);
throw new UnsupportedOperationException(e);
}
}
public static void execute(Execute command) {
try {
command.execute();
} catch (Exception e) {
log.error("exception", e);
}
}
interface Execute {
void execute() throws Exception;
}
interface SupplierExecute<T> {
T get() throws Exception;
}
}
package org.hcf.utils;
import org.junit.Test;
import org.springframework.util.Assert;
import java.io.*;
import java.net.*;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.time.temporal.TemporalAccessor;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class FileUtilsTest {
@Test
public void shouldMultithreadingDownloadFile() throws InterruptedException, IOException, URISyntaxException {
int threadNumber = 40;
String downloadFileUrl = "xxxxxxx";
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
ThreadPoolExecutor executor = new ThreadPoolExecutor(threadNumber, threadNumber, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
FileUtils.fileMultithreadingDownload(downloadFileUrl, executor, outputStream);
String downloadFile = "D:\\temp\\" + dateFormat(LocalDateTime.now(), "yyyy-MM-dd_hh-mm-ss-SSS") + ".exe";
outputFile(outputStream, downloadFile);
Assert.isTrue(new File(downloadFile).length() == FileUtils.getContentLengthLong(downloadFileUrl), "file download fail");
}
private String dateFormat(TemporalAccessor dateTime, String format) {
return DateTimeFormatter.ofPattern(format).format(dateTime);
}
private void outputFile(ByteArrayOutputStream outputStream, String filePath) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream(new File(filePath));
fileOutputStream.write(outputStream.toByteArray());
fileOutputStream.flush();
fileOutputStream.close();
}
}
Java多线程下载分析的更多相关文章
- JAVA多线程下载网络文件
JAVA多线程下载网络文件,开启多个线程,同时下载网络文件. 源码如下:(点击下载 MultiThreadDownload.java) import java.io.InputStream; im ...
- java多线程下载和断点续传
java多线程下载和断点续传,示例代码只实现了多线程,断点只做了介绍.但是实际测试结果不是很理想,不知道是哪里出了问题.所以贴上来请高手修正. [Java]代码 import java.io.File ...
- java 多线程下载功能
import java.io.InputStream; import java.io.RandomAccessFile; import java.net.HttpURLConnection; impo ...
- java 多线程下载文件 以及URLConnection和HttpURLConnection的区别
使用 HttpURLConnection 实现多线程下载文件 注意GET大写//http public class MultiThreadDownload { public static void m ...
- Java多线程下载文件
package com.test.download; import java.io.File; import java.io.InputStream; import java.io.RandomA ...
- Java多线程下载器FileDownloader(支持断点续传、代理等功能)
前言 在我的任务清单中,很早就有了一个文件下载器,但一直忙着没空去写.最近刚好放假,便抽了些时间完成了下文中的这个下载器. 介绍 同样的,还是先上效果图吧. Jar包地址位于 FileDownload ...
- Java多线程下载初试
一.服务端/客户端代码的实现 服务端配置config @ConfigurationProperties("storage") public class StoragePropert ...
- java 多线程下载文件并实时计算下载百分比(断点续传)
多线程下载文件 多线程同时下载文件即:在同一时间内通过多个线程对同一个请求地址发起多个请求,将需要下载的数据分割成多个部分,同时下载,每个线程只负责下载其中的一部分,最后将每一个线程下载的部分组装起来 ...
- java多线程下载网络图片
import java.io.BufferedInputStream;import java.io.BufferedOutputStream;import java.io.BufferedReader ...
随机推荐
- 微信小程序循环列表点击每一个单独添加动画
首先,咱们看一下微信小程序动画怎么实现,我首先想到的是anime.js,但是引入之后用不了,微信小程序内的css也无法做到循环的动态,我就去找官方文档看看有没有相应的方法,哎,还真有 点击这里查看 微 ...
- who 的页面制作
1. html 结构 <!-- section: Who we are --> <section id="who"> <div class=" ...
- python selenium 多个页面对象类使用同一个webdriver(即只打开一个浏览器窗口)
1 class BasePage(): 2 """selenium基类""" 3 4 def __init__(self, driver=N ...
- .NET Core企业微信网页授权登录
1.开发前准备 参数获取 corpid 每个企业都拥有唯一的corpid,获取此信息可在管理后台"我的企业"-"企业信息"下查看"企业ID" ...
- springmvc04-数据处理
数据处理 我们把它分为三种情况来分析,这样我们对于数据处理会有更好的理解 1.提交的域名称和处理方法的参数名一致 提交数据 : http://localhost:8080/hello?name=xi ...
- react 可拖拽改变位置和大小的弹窗
一 目标 最近,项目上需要一个可以弹出一个可以移动位置和改变大小的窗口,来显示一下对当前页面的一个辅助内容 二 思路 1.之前写过一个antd modal的可移动弹窗但是毕竟不如自己写的更定制化,比如 ...
- XCTF练习题---MISC---a_good_idea
XCTF练习题---MISC---a_good_idea flag:NCTF{m1sc_1s_very_funny!!!} 解题步骤: 1.观察题目,下载附件 2.到手以后发现是一张图片,尝试修改文件 ...
- HTTP.sys远程执行代码漏洞检测
1.漏洞描述:HTTP 协议栈 (HTTP.sys) 中存在一个远程执行代码漏洞,这是 HTTP.sys 不正确地分析特制 HTTP 请求时导致的.成功利用此漏洞的攻击者可以在系统帐户的上下文中执行任 ...
- Java学习笔记-基础语法Ⅷ-泛型、Map
泛型 泛型本质上是参数化类型,也就是说所操作的数据类型被指定为一个参数,即将类型由原来的具体的类型参数化,然后在使用/调用时传入具体的类型,这种参数类型可以用在类.方法和接口中,分别为泛型类.泛型方法 ...
- python入门基础知识一(基于孙兴华python自动化)
print('aaa')等价于print("aaa") 英文单引号和双引号在字符串的输出上并无区别,但如果要打印这么一段话:I'm interested in Python. 就要 ...