入门Python数据分析最好的实战项目(一)分析篇
数据初探
首先导入要使用的科学计算包numpy,pandas,可视化matplotlib,seaborn,以及机器学习包sklearn。
python学习交流群:660193417###
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
from IPython.display import display
plt.style.use("fivethirtyeight")
sns.set_style({'font.sans-serif':['simhei','Arial']})
%matplotlib inline
# 检查Python版本
from sys import version_info
if version_info.major != 3:
raise Exception('请使用Python 3 来完成此项目')
然后导入数据,并进行初步的观察,这些观察包括了解数据特征的缺失值,异常值,以及大概的描述性统计。
python学习交流群:660193417###
# 导入链家二手房数据
lianjia_df = pd.read_csv('lianjia.csv')
display(lianjia_df.head(n=2))

初步观察到一共有11个特征变量,Price 在这里是我们的目标变量,然后我们继续深入观察一下。
# 检查缺失值情况
lianjia_df.info()

发现了数据集一共有23677条数据,其中Elevator特征有明显的缺失值。
lianjia_df.describe()
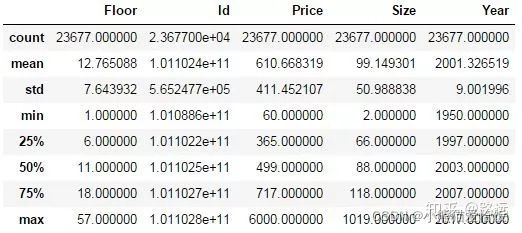
上面结果给出了特征值是数值的一些统计值,包括平均数,标准差,中位数,最小值,最大值,25%分位数,75%分位数。这些统计结果简单直接,对于初始了解一个特征好坏非常有用,比如我们观察到 Size 特征 的最大值为1019平米,最小值为2平米,那么我们就要思考这个在实际中是不是存在的,如果不存在没有意义,那么这个数据就是一个异常值,会严重影响模型的性能。
当然,这只是初步观察,后续我们会用数据可视化来清晰的展示,并证实我们的猜测。
# 添加新特征房屋均价
df = lianjia_df.copy()
df['PerPrice'] = lianjia_df['Price']/lianjia_df['Size']
# 重新摆放列位置
columns = ['Region', 'District', 'Garden', 'Layout', 'Floor', 'Year', 'Size', 'Elevator', 'Direction', 'Renovation', 'PerPrice', 'Price']
df = pd.DataFrame(df, columns = columns)
# 重新审视数据集
display(df.head(n=2))
我们发现 Id 特征其实没有什么实际意义,所以将其移除。由于房屋单价分析起来比较方便,简单的使用总价/面积就可得到,所以增加一个新的特征 PerPrice(只用于分析,不是预测特征)。另外,特征的顺序也被调整了一下,看起来比较舒服。
数据可视化分析
Region特征分析
对于区域特征,我们可以分析不同区域房价和数量的对比。
# 对二手房区域分组对比二手房数量和每平米房价
df_house_count = df.groupby('Region')['Price'].count().sort_values(ascending=False).to_frame().reset_index()
df_house_mean = df.groupby('Region')['PerPrice'].mean().sort_values(ascending=False).to_frame().reset_index()
f, [ax1,ax2,ax3] = plt.subplots(3,1,figsize=(20,15))
sns.barplot(x='Region', y='PerPrice', palette="Blues_d", data=df_house_mean, ax=ax1)
ax1.set_title('北京各大区二手房每平米单价对比',fontsize=15)
ax1.set_xlabel('区域')
ax1.set_ylabel('每平米单价')
sns.barplot(x='Region', y='Price', palette="Greens_d", data=df_house_count, ax=ax2)
ax2.set_title('北京各大区二手房数量对比',fontsize=15)
ax2.set_xlabel('区域')
ax2.set_ylabel('数量')
sns.boxplot(x='Region', y='Price', data=df, ax=ax3)
ax3.set_title('北京各大区二手房房屋总价',fontsize=15)
ax3.set_xlabel('区域')
ax3.set_ylabel('房屋总价')
plt.show()
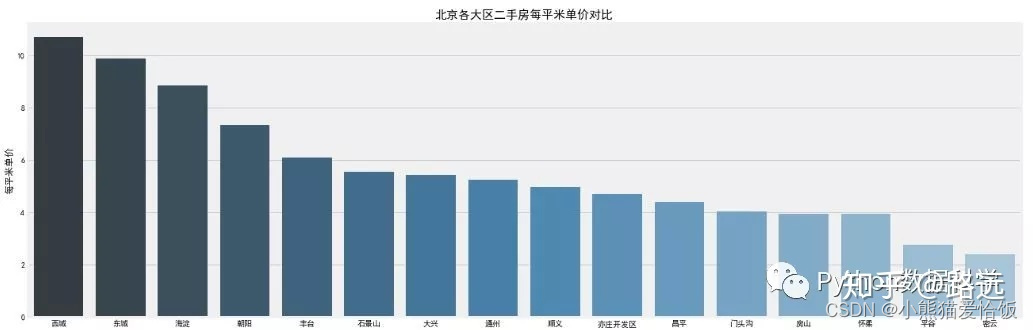


使用了pandas的网络透视功能groupby 分组排序。区域特征可视化直接采用 seaborn完成,颜色使用调色板palette 参数,颜色渐变,越浅说明越少,反之越多。可以观察到:
二手房均价:西城区的房价最贵均价大约11万/平,因为西城在二环以里,且是热门学区房的聚集地。其次是东城大约10万/平,然后是海淀大约8.5万/平,其它均低于8万/平。
二手房房数量:从数量统计上来看,目前二手房市场上比较火热的区域。海淀区和朝阳区二手房数量最多,差不多都接近3000套,毕竟大区,需求量也大。然后是丰台区,近几年正在改造建设,有赶超之势。
二手房总价:通过箱型图看到,各大区域房屋总价中位数都都在1000万以下,且房屋总价离散值较高,西城最高达到了6000万,说明房屋价格特征不是理想的正太分布。
Size特征分析
f, [ax1,ax2] = plt.subplots(1, 2, figsize=(15, 5))
# 建房时间的分布情况
sns.distplot(df['Size'], bins=20, ax=ax1, color='r')
sns.kdeplot(df['Size'], shade=True, ax=ax1)
# 建房时间和出售价格的关系
sns.regplot(x='Size', y='Price', data=df, ax=ax2)
plt.show()

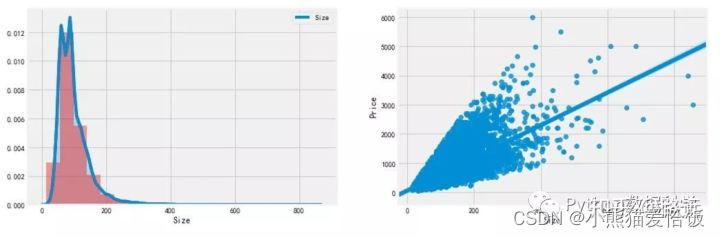
Size 分布:
通过 distplot 和 kdeplot 绘制柱状图观察 Size 特征的分布情况,属于长尾类型的分布,这说明了有很多面积很大且超出正常范围的二手房。
Size 与 Price 的关系:
通过 regplot 绘制了 Size 和 Price 之间的散点图,发现 Size 特征基本与Price呈现线性关系,符合基本常识,面积越大,价格越高。但是有两组明显的异常点:1. 面积不到10平米,但是价格超出10000万;2. 一个点面积超过了1000平米,价格很低,需要查看是什么情况。
df.loc[df['Size']< 10]

经过查看发现这组数据是别墅,出现异常的原因是由于别墅结构比较特殊(无朝向无电梯),字段定义与二手商品房不太一样导致爬虫爬取数据错位。也因别墅类型二手房不在我们的考虑范围之内,故将其移除再次观察Size分布和Price关系。
df.loc[df['Size']>1000]
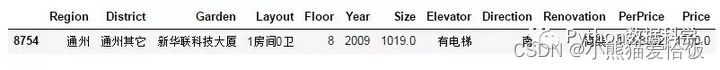
经观察这个异常点不是普通的民用二手房,很可能是商用房,所以才有1房间0厅确有如此大超过1000平米的面积,这里选择移除。
df = df[(df['Layout']!='叠拼别墅')&(df['Size']<1000)]
重新进行可视化发现就没有明显的异常点了。
Layout特征分析
f, ax1= plt.subplots(figsize=(20,20))
sns.countplot(y='Layout', data=df, ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax1.set_ylabel('户型')
plt.show()
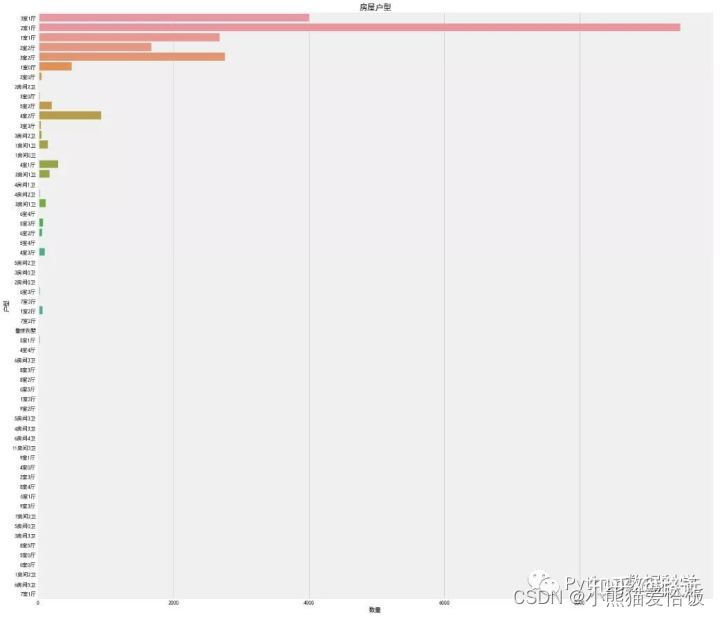
这个特征真是不看不知道,各种厅室组合搭配,竟然还有9室3厅,4室0厅等奇怪的结构。其中,2室一厅占绝大部分,其次是3室一厅,2室2厅,3室两厅。但是仔细观察特征分类下有很多不规则的命名,比如2室一厅与2房间1卫,还有别墅,没有统一的叫法。这样的特征肯定是不能作为机器学习模型的数据输入的,需要使用特征工程进行相应的处理。
Renovation 特征分析
df['Renovation'].value_counts()
精装 11345
简装 8497
其他 3239
毛坯 576
南北 20
Name: Renovation, dtype: int64
发现Renovation装修特征中竟然有南北,它属于朝向的类型,可能是因为爬虫过程中一些信息位置为空,导致“Direction”朝向特征出现在这里,所以需要清除或替换掉。
# 去掉错误数据“南北”,因为爬虫过程中一些信息位置为空,导致“Direction”的特征出现在这里,需要清除或替换
df['Renovation'] = df.loc[(df['Renovation'] != '南北'), 'Renovation']
# 画幅设置
f, [ax1,ax2,ax3] = plt.subplots(1, 3, figsize=(20, 5))
sns.countplot(df['Renovation'], ax=ax1)
sns.barplot(x='Renovation', y='Price', data=df, ax=ax2)
sns.boxplot(x='Renovation', y='Price', data=df, ax=ax3)
plt.show()

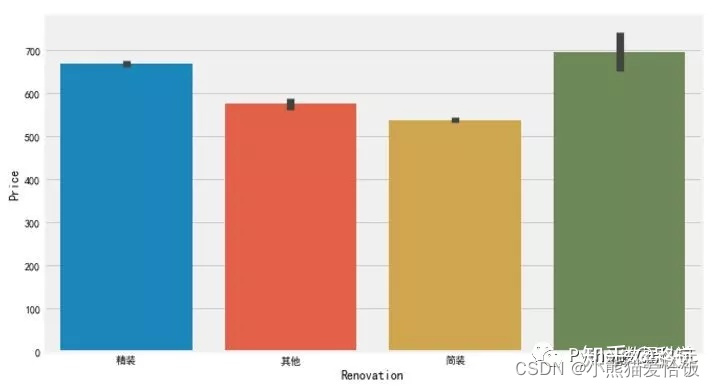

观察到,精装修的二手房数量最多,简装其次,也是我们平日常见的。而对于价格来说,毛坯类型却是最高,其次是精装修。
Elevator 特征分析
初探数据的时候,我们发现 Elevator 特征是有大量缺失值的,这对于我们是十分不利的,首先我们先看看有多少缺失值:
misn = len(df.loc[(df['Elevator'].isnull()), 'Elevator'])
print('Elevator缺失值数量为:'+ str(misn))
Elevator 缺失值数量为:8237
这么多的缺失值怎么办呢?这个需要根据实际情况考虑,常用的方法有平均值/中位数填补法,直接移除,或者根据其他特征建模预测等。
这里我们考虑填补法,但是有无电梯不是数值,不存在平均值和中位数,怎么填补呢?这里给大家提供一种思路:就是根据楼层 Floor 来判断有无电梯,一般的楼层大于6的都有电梯,而小于等于6层的一般都没有电梯。有了这个标准,那么剩下的就简单了。
# 由于存在个别类型错误,如简装和精装,特征值错位,故需要移除
df['Elevator'] = df.loc[(df['Elevator'] == '有电梯')|(df['Elevator'] == '无电梯'), 'Elevator']
# 填补Elevator缺失值
df.loc[(df['Floor']>6)&(df['Elevator'].isnull()), 'Elevator'] = '有电梯'
df.loc[(df['Floor']<=6)&(df['Elevator'].isnull()), 'Elevator'] = '无电梯'
f, [ax1,ax2] = plt.subplots(1, 2, figsize=(20, 10))
sns.countplot(df['Elevator'], ax=ax1)
ax1.set_title('有无电梯数量对比',fontsize=15)
ax1.set_xlabel('是否有电梯')
ax1.set_ylabel('数量')
sns.barplot(x='Elevator', y='Price', data=df, ax=ax2)
ax2.set_title('有无电梯房价对比',fontsize=15)
ax2.set_xlabel('是否有电梯')
ax2.set_ylabel('总价')
plt.show()
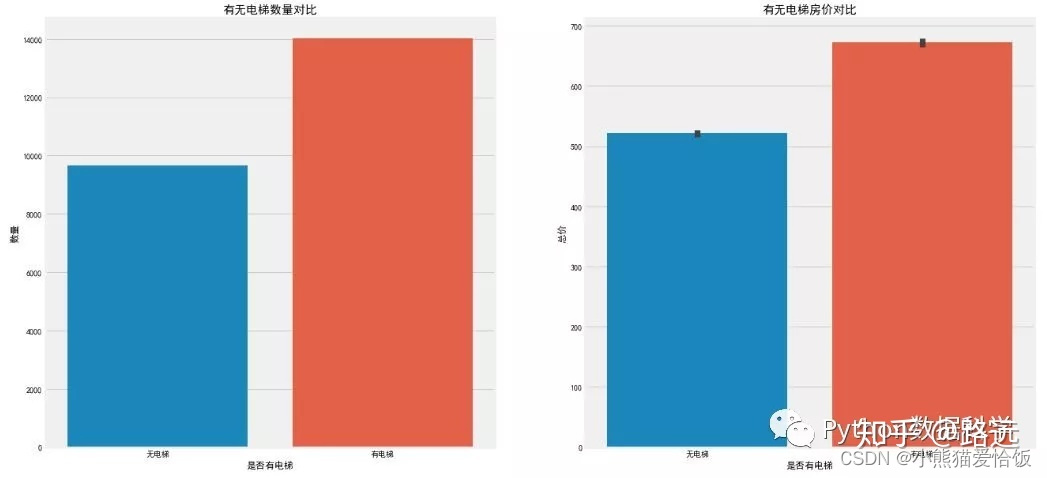
结果观察到,有电梯的二手房数量居多一些,毕竟高层土地利用率比较高,适合北京庞大的人群需要,而高层就需要电梯。相应的,有电梯二手房房价较高,因为电梯前期装修费和后期维护费包含内了(但这个价格比较只是一个平均的概念,比如无电梯的6层豪华小区当然价格更高了)。
Year 特征分析
grid = sns.FacetGrid(df, row='Elevator', col='Renovation', palette='seismic',size=4)
grid.map(plt.scatter, 'Year', 'Price')
grid.add_legend()

在Renovation和Elevator的分类条件下,使用 FaceGrid 分析 Year 特征,观察结果如下:
整个二手房房价趋势是随着时间增长而增长的;
2000年以后建造的二手房房价相较于2000年以前有很明显的价格上涨;
1980年之前几乎不存在有电梯二手房数据,说明1980年之前还没有大面积安装电梯;
1980年之前无电梯二手房中,简装二手房占绝大多数,精装反而很少;
Floor 特征分析
f, ax1= plt.subplots(figsize=(20,5))
sns.countplot(x='Floor', data=df, ax=ax1)
ax1.set_title('房屋户型',fontsize=15)
ax1.set_xlabel('数量')
ax1.set_ylabel('户型')
plt.show()
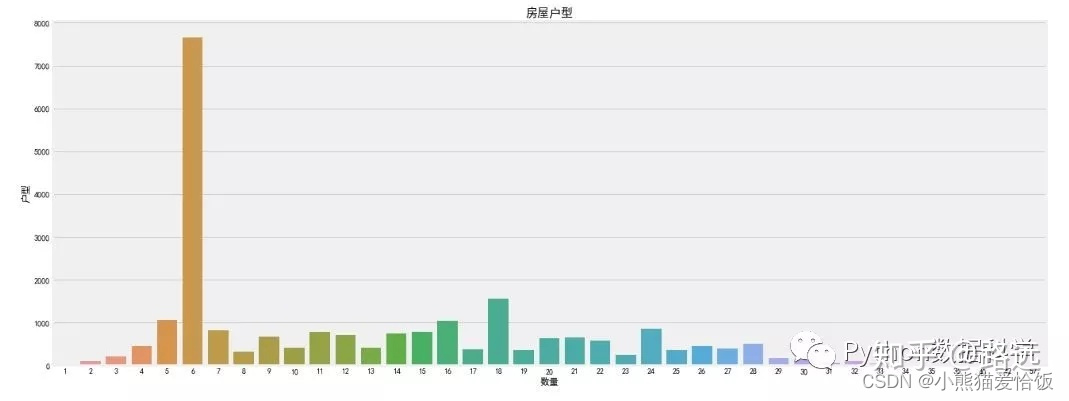
可以看到,6层二手房数量最多,但是单独的楼层特征没有什么意义,因为每个小区住房的总楼层数都不一样,我们需要知道楼层的相对意义。另外,楼层与文化也有很重要联系,比如中国文化七上八下,七层可能受欢迎,房价也贵,而一般也不会有4层或18层。当然,正常情况下中间楼层是比较受欢迎的,价格也高,底层和顶层受欢迎度较低,价格也相对较低。所以楼层是一个非常复杂的特征,对房价影响也比较大。
总结
本次分享旨在让大家了解如何用Python做一个简单的数据分析,对于刚刚接触数据分析的朋友无疑是一个很好的练习。不过,这个分析还存在很多问题需要解决,比如:
- 解决爬虫获取的数据源准确度问题;
- 需要爬取或者寻找更多好的售房特征;
- 需要做更多地特征工程工作,比如数据清洗,特征选择和筛选;
- 使用统计模型建立回归模型进行价格预测
入门Python数据分析最好的实战项目(一)分析篇的更多相关文章
- 快速入门 Python 数据分析实用指南
Python 现如今已成为数据分析和数据科学使用上的标准语言和标准平台之一.那么作为一个新手小白,该如何快速入门 Python 数据分析呢? 下面根据数据分析的一般工作流程,梳理了相关知识技能以及学习 ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- 学习参考《Python数据分析与挖掘实战(张良均等)》中文PDF+源代码
学习Python的主要语法后,想利用python进行数据分析,感觉<Python数据分析与挖掘实战>可以用来学习参考,理论联系实际,能够操作数据进行验证,基础理论的内容对于新手而言还是挺有 ...
- python数据分析与挖掘实战第二版pdf-------详细代码与实现
[书名]:PYTHON数据分析与挖掘实战 第2版[作者]:张良均,谭立云,刘名军,江建明著[出版社]:北京:机械工业出版社[时间]:2020[页数]:340[isbn]:9787111640028 学 ...
- python数据分析与挖掘实战
<python数据分析与挖掘实战>PDF&源代码&张良均 下载:链接:https://pan.baidu.com/s/1TYb3WZOU0R5VbSbH6JfQXw提取码: ...
- python 数据分析与挖掘实战01
python 数据分析与挖掘实战 day 01 08/02 这种从数据中"淘金",从大量数据包括文本中挖掘出隐含的.未知的.对决策有潜在价值关系.模式或者趋势,并用这些知识和规则建 ...
- 3个月零基础入门Python+数据分析,详细时间表+计划表分享
大家好,我是白云. 今天想给大家分享的是三个月零基础入门数据分析学习计划.有小伙伴可能会说,英语好像有点不太好,要怎么办?所以今天我给大家分享的资源呢就是对国内的小伙伴很友好,还附赠大家一份三个月学 ...
- 《Python数据分析与挖掘实战》读书笔记
大致扫了一遍,具体的代码基本都没看了,毕竟我还不懂python,并且在手机端的排版,这些代码没法看. 有收获,至少了解到以下几点: 一. Python的语法挺有意思的 有一些类似于JavaSc ...
- 教程 | 一文入门Python数据分析库Pandas
首先要给那些不熟悉 Pandas 的人简单介绍一下,Pandas 是 Python 生态系统中最流行的数据分析库.它能够完成许多任务,包括: 读/写不同格式的数据 选择数据的子集 跨行/列计算 寻找并 ...
随机推荐
- 计算机系统5-> 计组与体系结构2 | MIPS指令集(上)| 指令系统
系列的上一篇计算机系统4-> 计组与体系结构1 | 基础概念与系统评估,学习了一些计算机的基础概念,将一些基本的计算机组成部分的功能和相互联系了解了一下,其中很重要的一个抽象思想就是软硬件的接口 ...
- python基础练习题(题目 输入一行字符,分别统计出其中英文字母、空格、数字和其它字符的个数)
day10 --------------------------------------------------------------- 实例017:字符串构成 题目 输入一行字符,分别统计出其中英 ...
- prometheus监控预警之AlertManager邮箱报警
Alertmanager 主要用于接收 Prometheus 发送的告警信息,它支持丰富的告警通知渠道,例如邮件.微信.钉钉.Slack 等常用沟通工具,而且很容易做到告警信息进行去重,降噪,分组等, ...
- 一次不规范HTTP请求引发的nginx响应400问题分析与解决
背景 最近分析数据偶然发现nginx log中有一批用户所有的HTTP POST log上报请求均返回400,没有任何200成功记录,由于只占整体请求的不到0.5%,所以之前也一直没有触发监控报警,而 ...
- py文件加密打包成exe文件
python的py.pyc.pyo.pyd文件区别 py是源文件: pyc是源文件编译后的文件: pyo是源文件优化编译后的文件: pyd是其他语言写的python库: 为什么选用Cpython .p ...
- asyncio 异步编程
首先了解一下协程,协程的本质就是一条线程,多个任务在一条线程上来回切换,协程的所有切换都是基于用户,只有在用户级别才能感知到的 IO 才会用协程模块来规避,在 python 中主要使用的协程模块是 a ...
- 使用 Swoole 加速你的 CMS 系统,并实现热更新 (基于 Laravel 框架)
主题:使用 Swoole 加速你的 CMS 系统,并实现热更新 关于 Swoole 的简介不再在此赘述,各位可以自行查看官网的文档进行详细的了解. 本文以 MyCms 为例,简要说明 Swoole 结 ...
- 【Docker入门】Docker的常用命令
了解和安装完docker之后,我们学习一下docker的常用命令就和当初学linux命令一样,放心命令其实大致相同只不过细节不同. 一.Docker启动类命令 1.启动docker:syste ...
- 超越OpenCV速度的MorphologyEx函数实现(特别是对于二值图,速度是CV的4倍左右)。
最近研究了一下opencv的 MorphologyEx这个函数的替代功能, 他主要的特点是支持任意形状的腐蚀膨胀,对于灰度图,速度基本和CV的一致,但是 CV没有针对二值图做特殊处理,因此,这个函数对 ...
- c++ web框架实现之静态反射实现
0 前言 最近在写web框架,框架写好后,需要根据网络发来的请求,选择用户定义的servlet来处理请求.一个问题就是,我们框架写好后,是不知道用户定义了哪些处理请求的类的,怎么办? 在java里有一 ...