使用 shell 脚本拼接 srt 字幕文件 (srtcat)
背景
前段时间迷上了做 B 站视频,主要是摩托车方面的知识分享。做的也比较粗糙,就是几张图片配上语音和字幕进行解说。尝试过自己解说,发现录制视频对节奏的要求还是比较高的,这里面水太深把握不住。好在以 "在线 免费 文字转语音" 作为关键字搜索一番,发现一个好用的网站——字幕说。好用的语音合成工具千千万,为什么我对这个情有独钟呢?原来它将文字底稿转换为语音的同时,还输出了字幕文件 (srt),这个在 B 站的云编辑器中就可以直接导入了,非常方便:
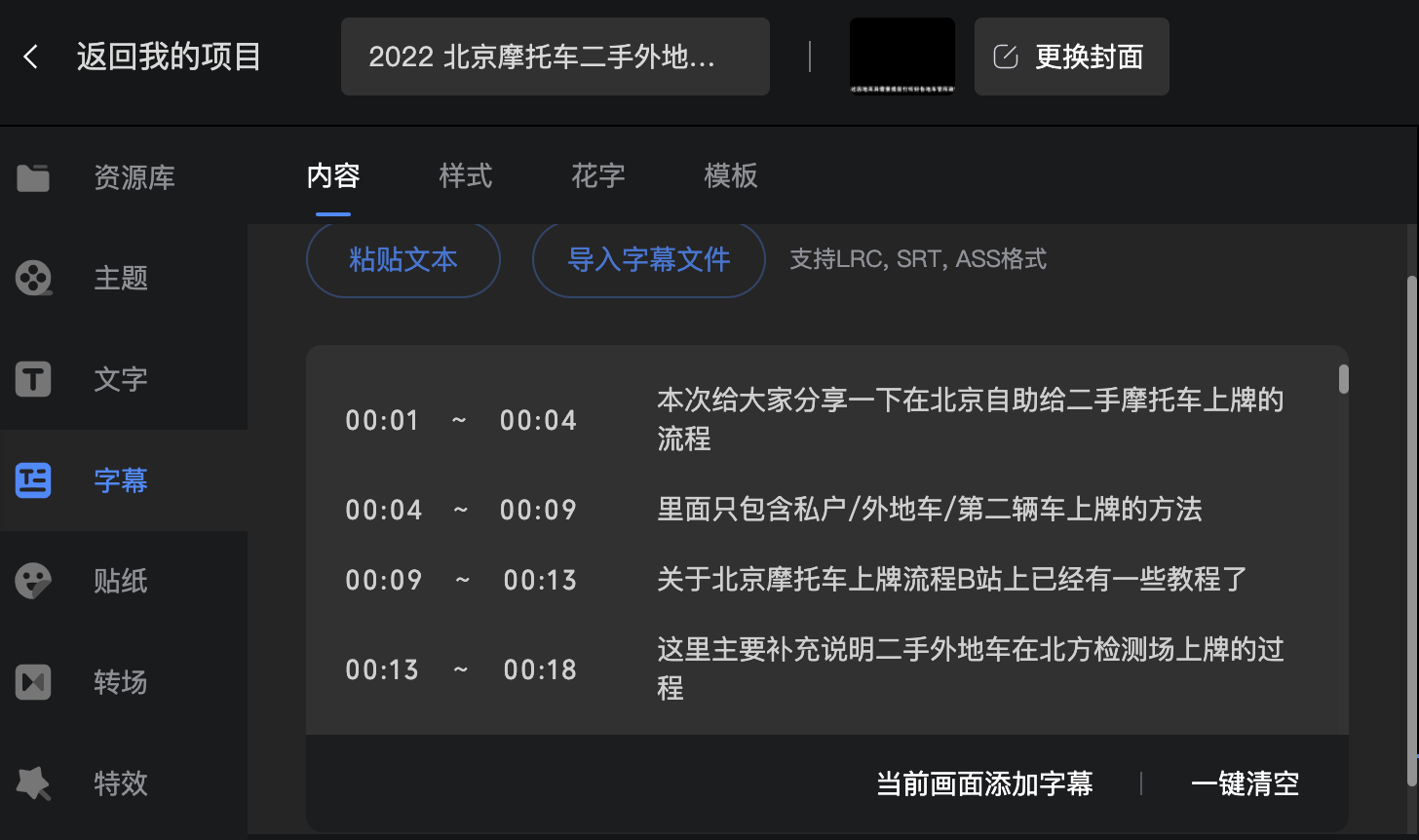
最终效果就会在视频下方与语音同步播出字幕:

感觉比自动识别的字幕准确率高的多。
白嫖字幕说
像大多数免费工具一样,免费只是揽客的招牌,毕竟天底下没有免费的午餐,字幕说限制一次转换不超过 1000 个汉字:
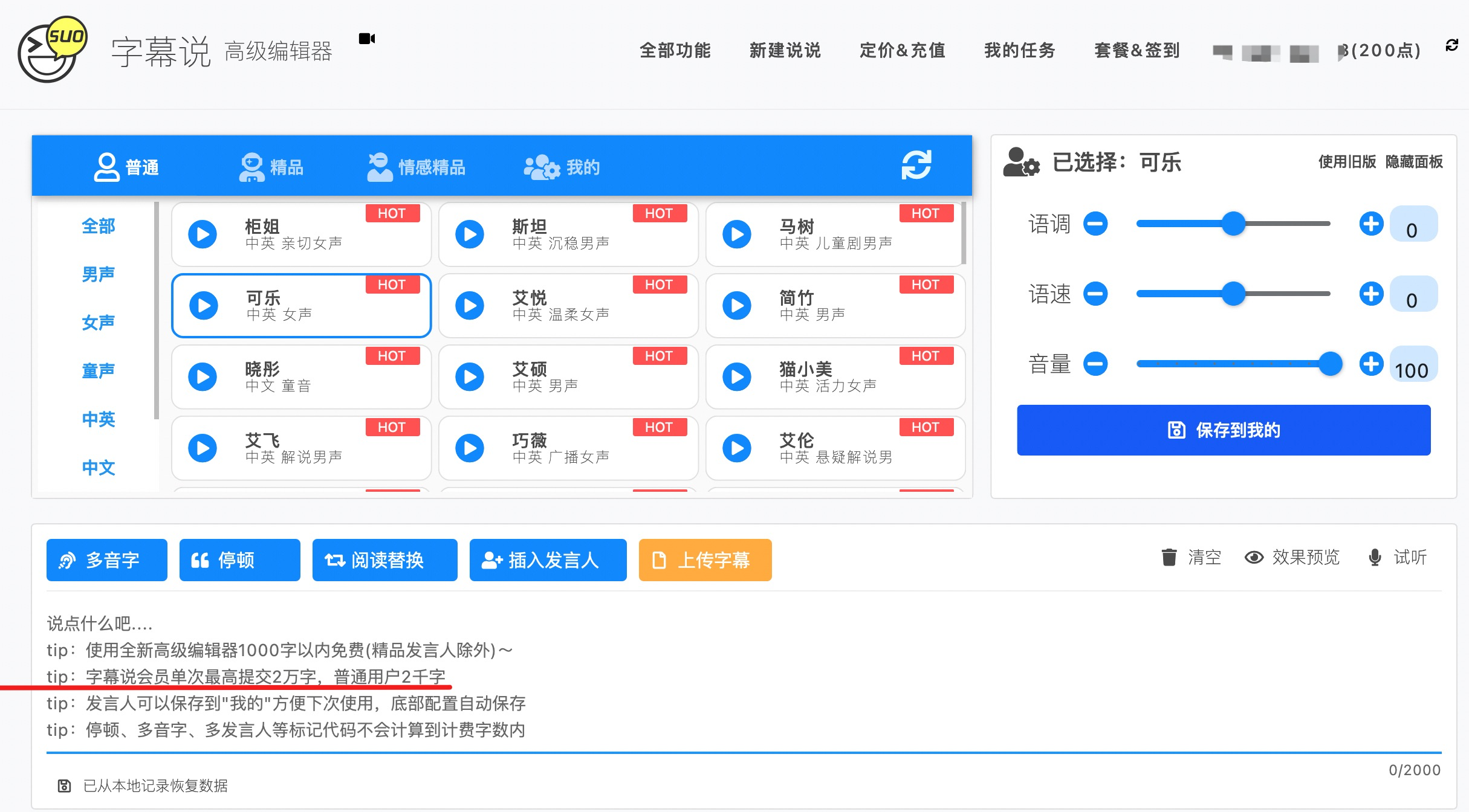
上面虽然标明 2000 字,实际上超过 1000 字已经开始要点数了:
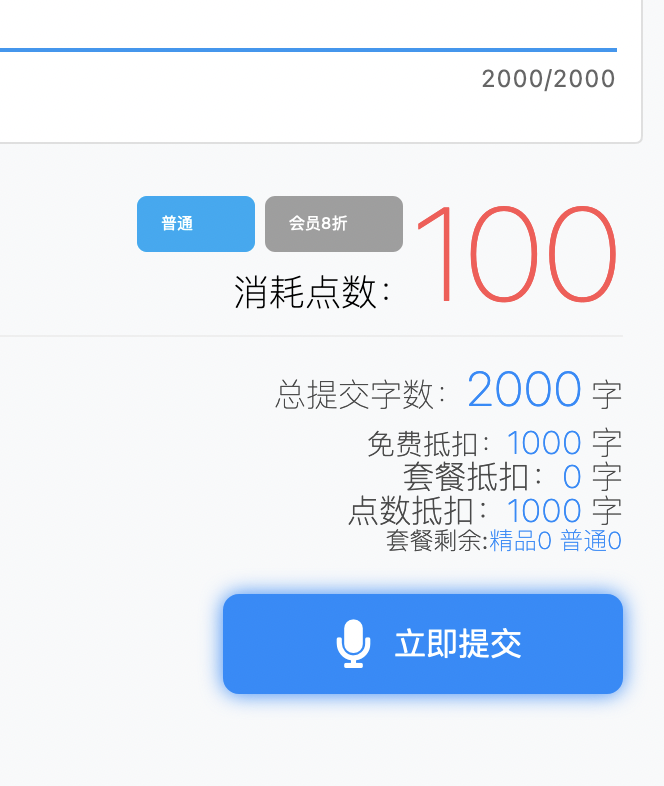
大概是 1 点 10 字的兑换方式,初始账户大概有 200 点,只能超 2000 字,而且这 2000 字也得遵守一次不超 2000 字的限制,如果文稿有 3000 字,仍得分两次生成语音和字幕。
作为白嫖用户,别说花钱买点数,就是用点数也是不乐意的,每次免费的不是限制 1000 字吗,那就按这个限制将文稿切分一下:
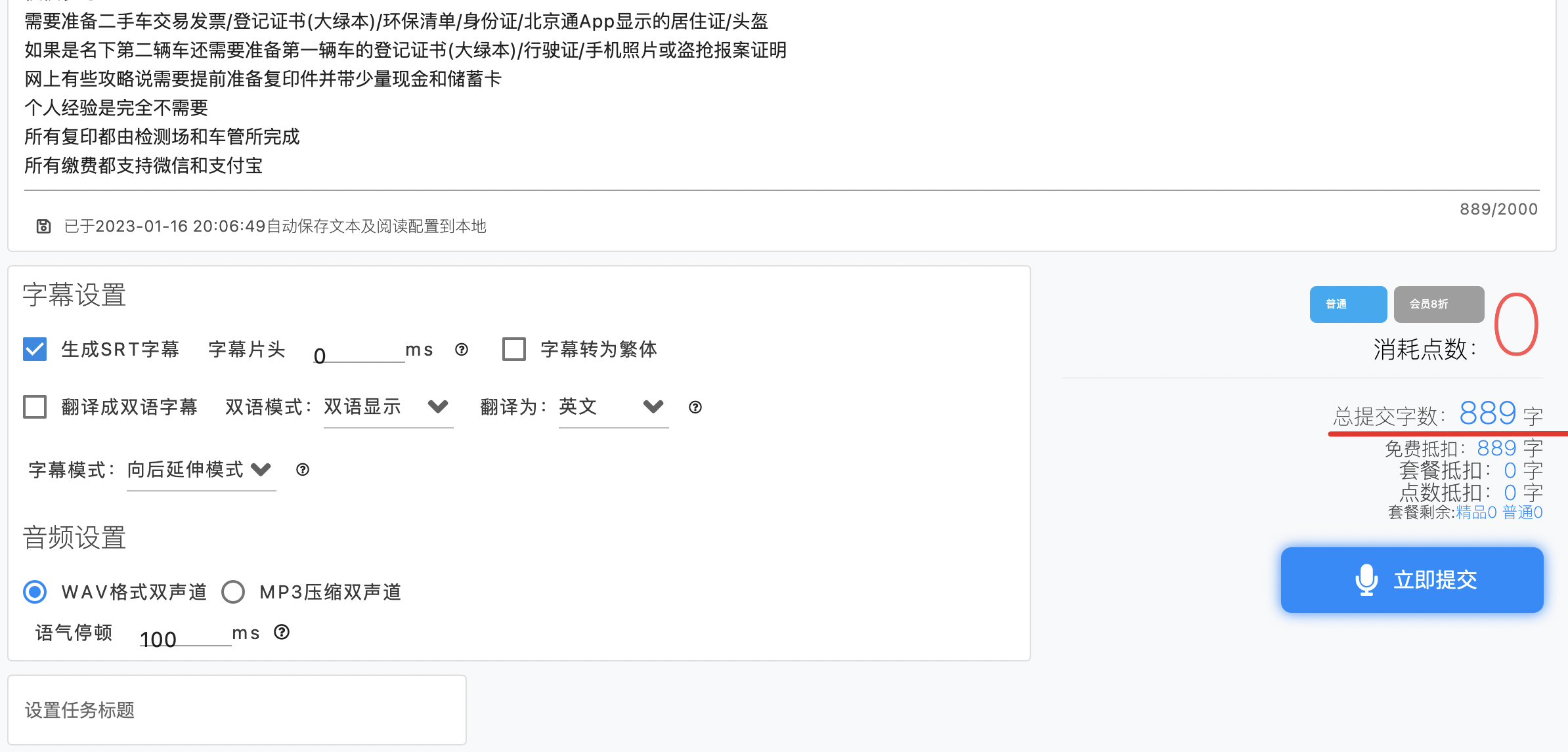
哈哈,果然白嫖成功,点立即提交后就可以跳转到任务查询界面了:

转换完成后可以选择对应的音频和字幕文件进行下载,下载后的 srt 文件长这个样子:
1
00:00:00,000 --> 00:00:04,600
本次给大家分享一下在北京自助给二手摩托车上牌的流程
2
00:00:04,600 --> 00:00:08,680
里面只包含私户/外地车/第二辆车上牌的方法
3
00:00:08,680 --> 00:00:12,560
关于北京摩托车上牌流程B站上已经有一些教程了
4
00:00:12,560 --> 00:00:17,120
这里主要补充说明二手外地车在北方检测场上牌的过程
...每段字幕之间以空行分隔,分为三行内容,分别是序号、播放时间、文字内容。对于文稿中一些比较长的行,后台会自动拆分为多个字幕段落。
srt 文件拼接
下面将拆分后的音频和字幕导入 B 站云剪辑中。音频比较简单,上传文件后一段段拖到合成的视频中就可以了;字幕就麻烦了,云剪辑只支持一次导入一个字幕文件,导入新的字幕会自动清空之前的内容,因此需要将切分后的字幕文件拼接成一整个文件导入。
一开始用了 cat,生成的文件确实包含了所有内容,但是导入后发现只有最后一部分字幕生效了,末尾还保留了一部分前面的字幕,全乱套了:
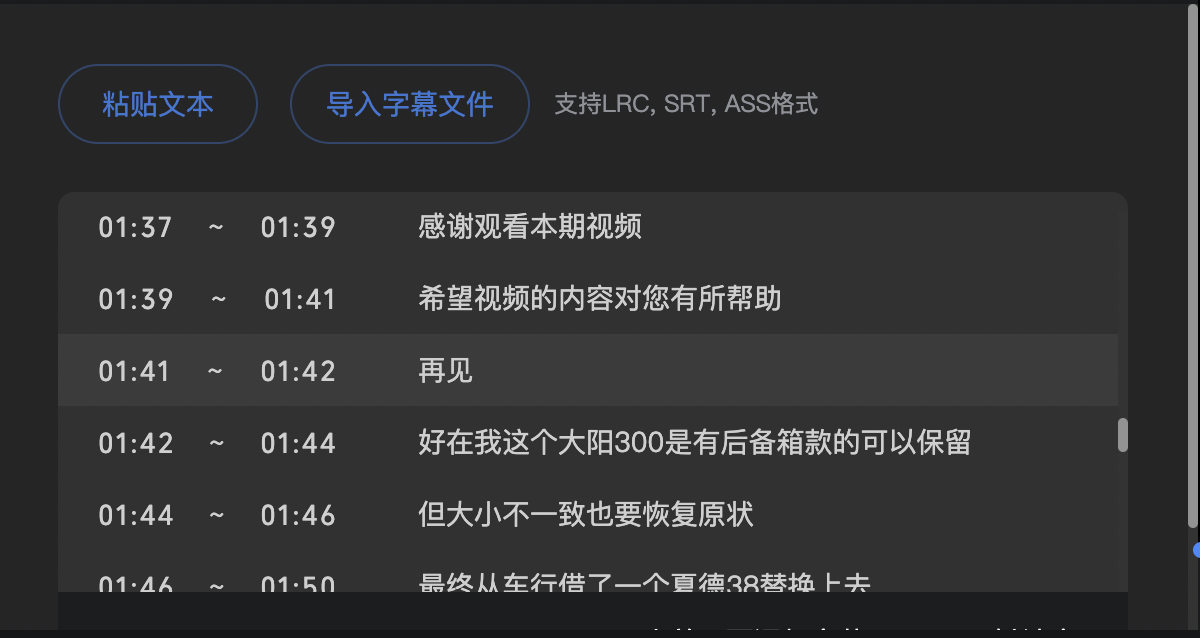
原来,不调整字幕中的序号和播放时间,会导致前面的被后面同序号的字幕所覆盖。看起来需要找一个字幕文件拼接工具了,经过一番百度,主要找到下面几个工具
SrtEdit
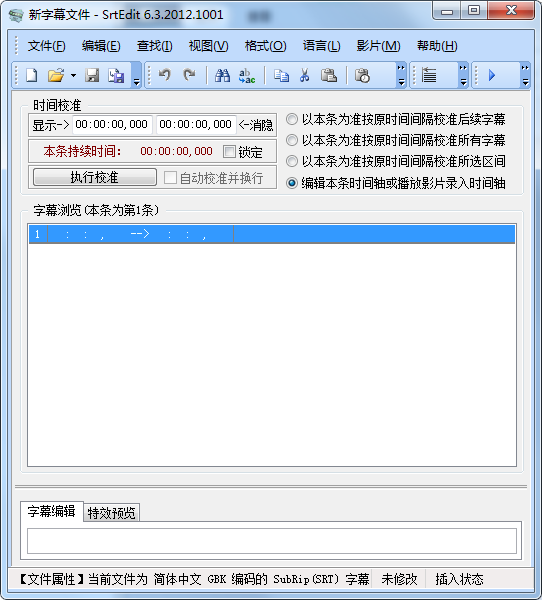
这个是一个专门对字幕文件做各种处理的工具,打开字幕文件后,直接追加即可实现文件的拼接:
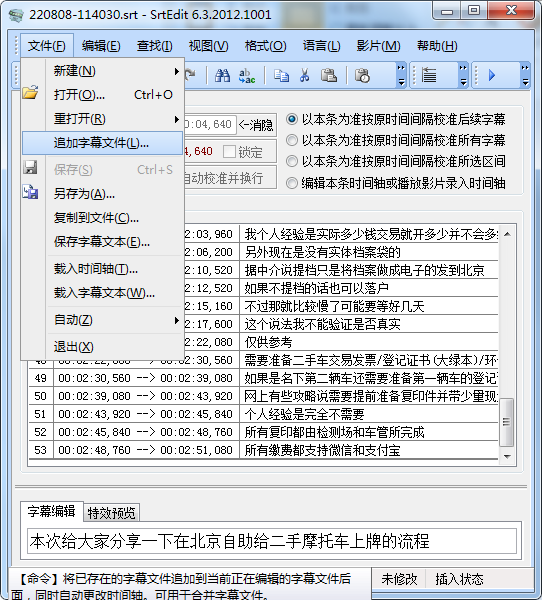
追加时还可以选择新文件的起始时间:
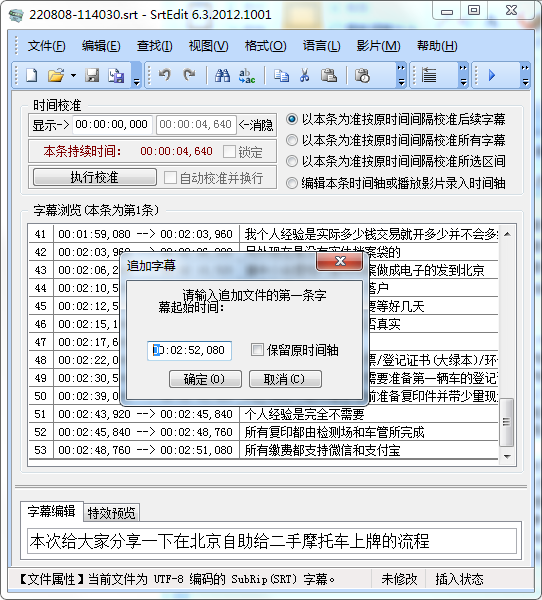
默认是上一个文件结尾时间加 1 秒。追加后就可以直接另存为拼接后的文件。
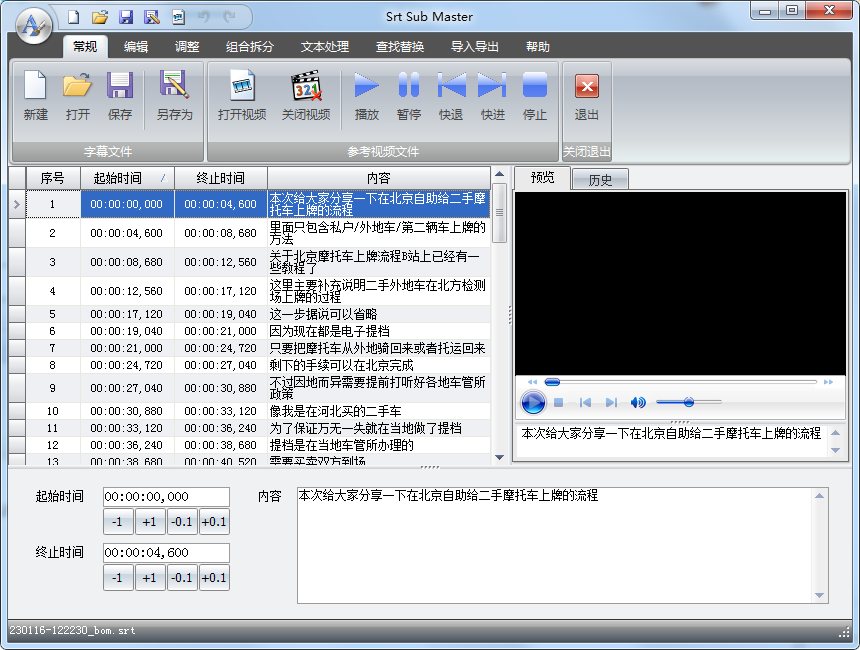
Srt Sub Master
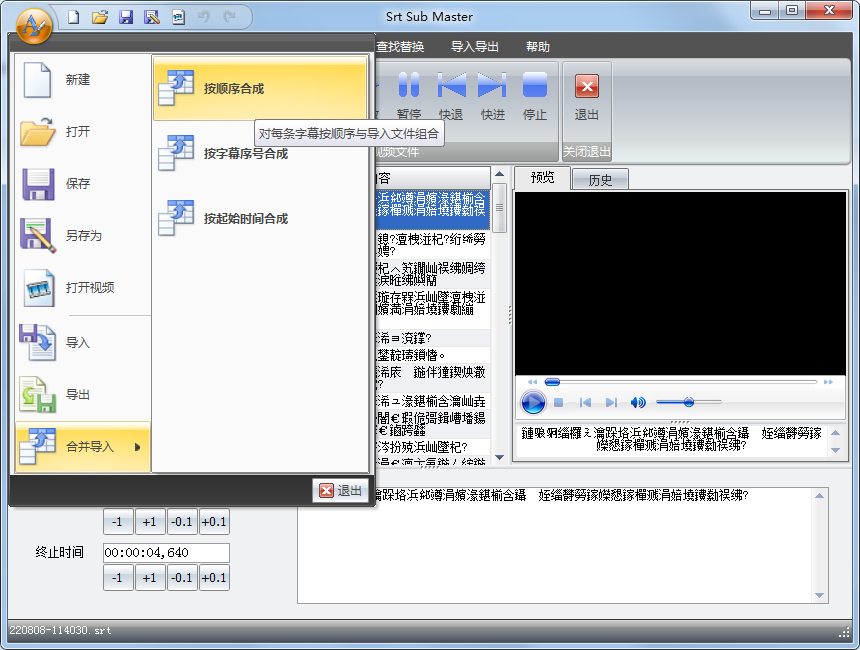
打开第一个文件后选择:文件->合并导入->按顺序合成,在弹出的选项框中进行设置:
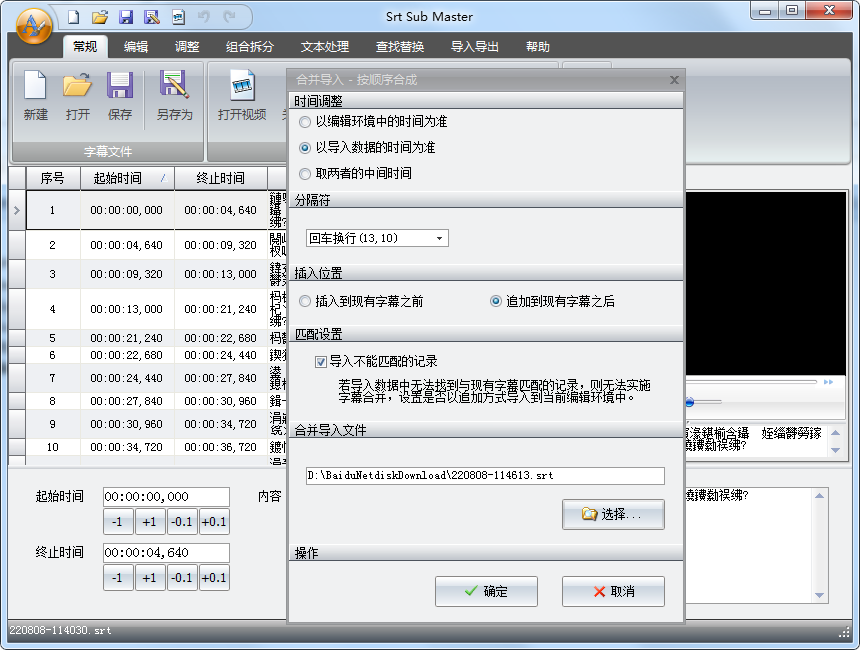
选择要合并的文件后就可以了:
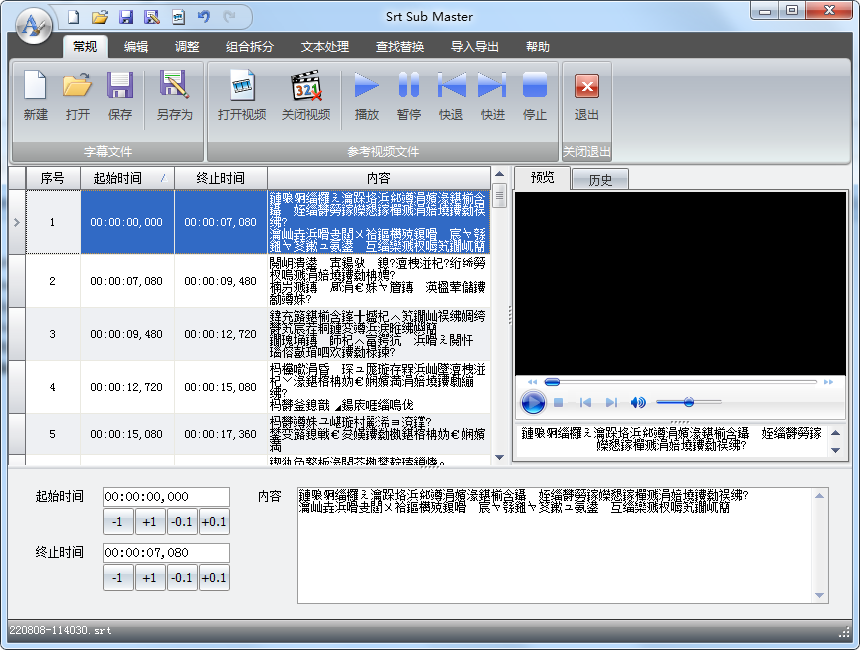
不过最终效果好像是将多条字幕合并到一个时间段上了,貌似是用来整合中英文字幕的。翻了一下应用提供的其它功能菜单,没发现直接拼接两个字幕文件的功能,pass
Subtitle Workshop
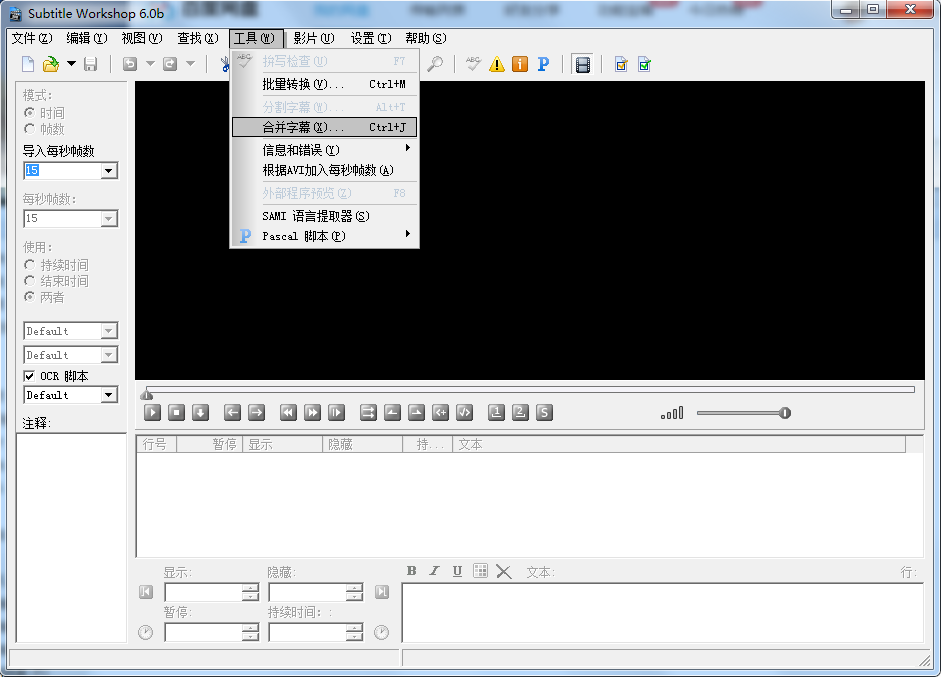
打开软件后直接选择:工具->合并字幕
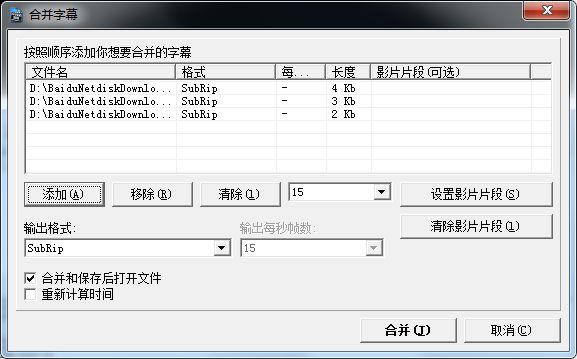
在弹出的选择框中选择文件后合并:
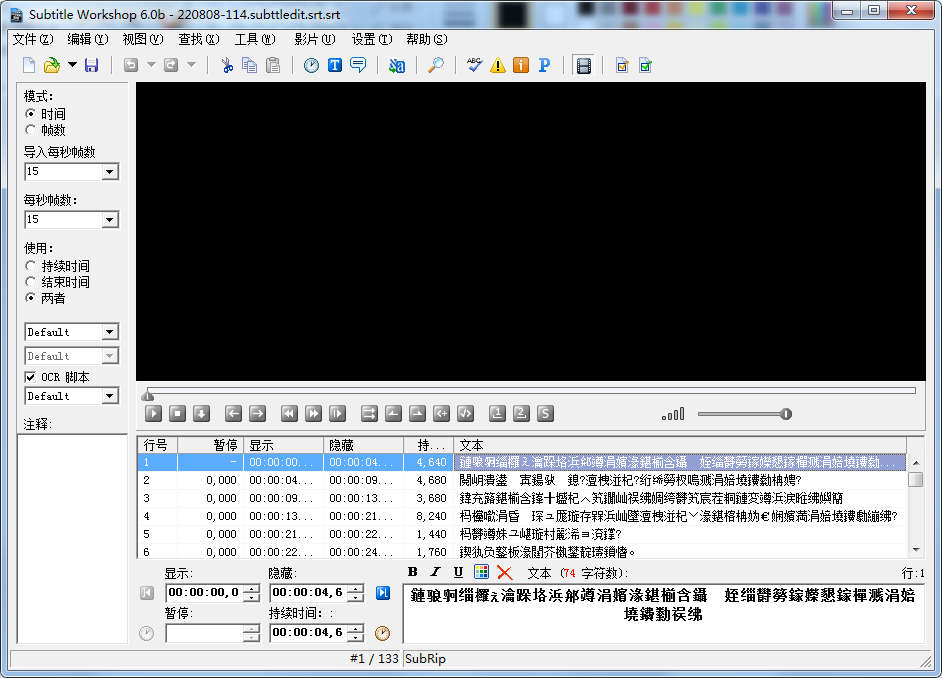
最后保存合并后的文件。
这里字幕中的汉字显示为乱码,一开始以为是从字幕说导出 srt 文件时没有选择带 BOM 的 utf-8 格式所致:
切换到带 bom 格式后仍不行:
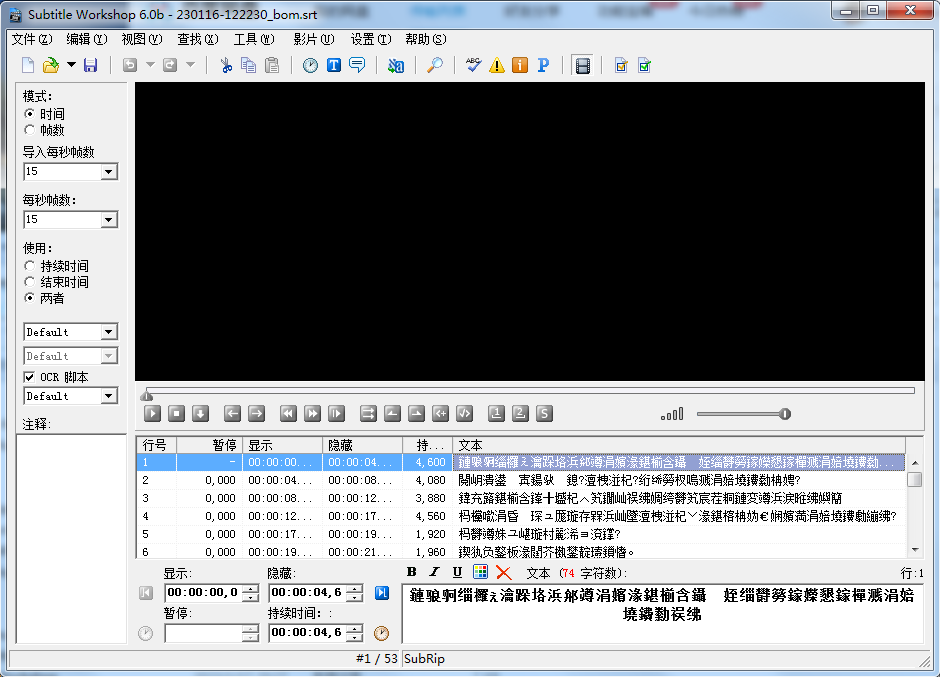
但同样的乱码问题,对于 Srt Sub Master 却可以用上面的办法解决:
一时半会儿没弄明白 Subtitle Workshop 是个什么情况,pass
横评
经过一番对比,Sub Srt Master 没有找到对应的功能,Subtitle Workshop 在汉字编码上存在一些问题,最后选择了 SrtEdit。因为当时比较急,就用选定的这个工具生成的字幕文件导入到 B 站云剪辑去生成视频了。
srtcat
GUI 工具固然好用,然而有两个问题:
- 依赖某些平台,例如 windows,这对 mac 用户非常不友好
- IDE 形式的图形工具一般是包罗万象的,而我的场景非常单一,安装了许多不必要的功能。
第二点对 SrtEdit 还不明显,看看其它两个,有些还和视频文件耦合在一起,字幕只是其功能中的一小部分。其实 unix 的哲学就是提供 tool 的集合,而非做一个包罗万象的平台,工具的生命周期远远大于平台,因为你永远无法预测将来的用户会怎么使用。提供单一功能的工具供用户去选择来集成在他们的场景中是最好的方式。
基于这个想法,再加上拼接 srt 文件的功能并不复杂,主要是序号和时间上的处理,所以决定使用 shell 脚本手搓一个,名字就叫 srtcat 吧:
> sh srtcat.sh
Usage: srtcat [-t timespan] file1 file2 ...在使用上非常简单,参数列表为要拼接的 srt 文件,内容都从序号 1 开始,第一个文件的起始时间需要从 00:00:00,000 开始;-t 选项指定文件间的时间间隔,默认 1000 毫秒。拼接结果将打印到 stdout,可以重定向到新文件。错误和警告将打印到 stderr 防止污染 stdout 内容。
项目地址:https://github.com/goodpaperman/srtcat
这个工具只包含一个 shell 脚本 srtcat.sh,230 多行,比较好读,这里不逐行解说了,只说明一下重点功能的方案选型。
拼接过程中时间的处理是个重点,按处理的时序又分为拆分、去零,下面分别说明。
拆分
形如 hh:mm:ss,xxx 格式的时间,首先需要从字符串提取时、分、秒、毫秒四个部分,这部分主要想说一下拆分时间字符串的三种方案。
cut
最直观的方式就是使用 cut 命令挨个截取:
hour=$(echo "${line}" | cut -b 1-2)
min=$(echo "${line}" | cut -b 4-5)
sec=$(echo "${line}" | cut -b 7-8)
msec=$(echo "${line}" | cut -b 10-12)调用 cut 的命令来处理字符串的缺点是效率比较低,一个时间处理就要启动 4 个子进程,大量的这种字符串操作,绝对会拖慢脚本效率,替代的方案是 shell 自己的字符串截取:
hour=${line:0:2}
min=${line:3:2}
sec=${line:6:2}
msec=${line:9:3}这样虽然可以避免上面的性能问题,但也是基于固定长度来截取,这是基于时分秒占用 2 位、毫秒占用 3 位的假设,如果 hour 占用超过 2 位的话 (hour > 99),就全对不上了,考虑到拓展性,方案 1 这种固定长度的方式就 pass 了。
awk
不使用固定长度,那就按关键字符分割。首先想到的是 awk 命令,可以通过 -F 选项指定多个分隔符:
line="00:01:02,003 --> 04:05:06,007"
echo "${line}" | awk -F':|,| ' '{ for (i=1; i<=NF; i++) { print $i }}'注意多个字符间通过 | 分隔,效果如下:
> sh awk.sh
00
01
02
003
-->
04
05
06
007那如何将分割的字符串赋值给 shell 变量呢?有很多方法,这里用到了 eval:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1";min1="$2";sec1="$3";msec1="$4";hour2="$6";min2="$7";sec2="$8";msec2="$9";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"运行效果如下:
> sh awk.sh
hour1=00;min1=01;sec1=02;msec1=003;hour2=04;min2=05;sec2=06;msec2=007;
00:01:02,003
04:05:06,007eval 后就可以使用 shell 变量hour1/min1/sec1/msec1引用第一个时间、使用hour2/min2/sec2/msec2引用第二个时间,这里变量名可以任意设置。
IFS
awk 虽然直观,但是仍要调起一个子进程,有没有更高效的方法呢?网上搜到一篇文章,说可以用 shell 自带的 IFS 分隔符设置来处理日期拆分,感觉还蛮符合我这个场景的,拿来试验一下:
#! /bin/sh
line="00:01:02,003 --> 04:05:06,007"
OLD_IFS="${IFS}"
IFS=":, "
arr=(${line})
IFS="${OLD_IFS}"
for var in "${arr[@]}"
do
echo "${var}"
doneIFS 字符串的每个字符就是一个分割符。运行上面这段脚本,得到:
> sh ifs.sh
00
01
02
003
-->
04
05
06
007使用 ${arr[0]}:${arr[1]}:${arr[2]},${arr[3]} 引用第一个时间,${arr[5]}:${arr[6]}:${arr[7]},${arr[8]} 引用第二个时间。
横评
从性能上讲,IFS 方式是最优解,shell 字符截取次之,awk+eval 次之,cut 最末;从可拓展性角度讲 (hour > 99),IFS、awk 方式优于 shell 字符截取和 cut;从直观性上讲,awk+eval 最优、shell 字符截取和 cut 次之,IFS (使用 arr[N] 引用) 最末。考虑到脚本以后使用场景,面对比较大的 srt 文件,性能将成为一个瓶颈,因此选择 IFS 来尽量提升脚本性能,虽然牺牲了直观性,不过保留了可拓展性。
去零
拆分后的时间变量是字符串,有前导零时,直接参与加法运算时,偶尔会出现下面的错误:
srtcat.sh: line 8: 080: value too great for base (error token is "080")原因是将毫秒 080 识别为八进制 (前缀 0 为八进制,前缀 0x 为十六进制) ,而八进制中最大的数字是 7,遇到超过 7 的数字就会报错。
下面介绍几种解决方案:
${var##0*}
一开始是想用 shell 字符串截取,通过 ## 实现从左向右最长匹配,通过0*匹配全零串,但是发现这个方案不行:
> var=080
> echo ${var##0*}
> echo ${var#0*}
80
> var=007
> echo ${var##0*}
> echo ${var#0*}
07主要是 shell 将##0*理解为了匹配所有数字,直到遇到符号或字母时才会停止匹配,导致匹配非零数字。pass
sed
然后想到的就是 sed 的正则匹配及数字提取:
> var=007
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
7
> var=080
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
80
> var=123
> echo $var | sed -n 's/0*\([0-9]*\)/\1/p'
123通过0*匹配前导零、[0-9]*匹配剩下的数字。这个方案缺陷很明显,时间的每个分量需要启动一个单独的 sed 子进程,和之前的 cut 一样,性能肯定好不了。
$(())
参考网上的一篇文章,使用了一个 shell 运算符的奇技淫巧:
> var=080
> echo $((1${var}-1000))
80
> var=007
> echo $((1${var}-1000))
7
> var=123
> echo $((1${var}-1000))
123就是在明确字符串数字位数后,加一个前导 1 使其成为 1xxxx 的形式,此时转换为数字不会报错,再减去因为加前缀 1 导致的数字增长值 (例如对于 3 位数字是 1000),就还原成了原本的数字,且前导零也去除了。这个方法的缺陷也很明显,需要事先知道数字字符串位数,拓展性 (hour>99) 不好。
awk
之前在对比拆分方案时曾经介绍过 awk,如果使用 awk+eval 方案,则将前导零删除就是顺手的事儿:
line="00:01:02,003 --> 04:05:06,007"
val=$(echo "${line}" | awk -F':|,| ' '{print "hour1="$1/1";min1="$2/1";sec1="$3/1";msec1="$4/1";hour2="$6/1";min2="$7/1";sec2="$8/1";msec2="$9/1";"}')
echo "${val}"
eval "${val}"
echo "${hour1}:${min1}:${sec1},${msec1}"
echo "${hour2}:${min2}:${sec2},${msec2}"和之前对比,仅仅在 awk 命令内部构造赋值表达式时为每个字段增加了一个除 1 操作 (/1),awk 就自动将字符串转换为数字了:
> sh awk.sh
hour1=0;min1=1;sec1=2;msec1=3;hour2=4;min2=5;sec2=6;msec2=7;
0:1:2,3
4:5:6,7实测乘 1 (*1) 也可,这也太方便了。
横评
将拆分和去零结合起来,有以下几种搭配:
- $((var:0:2)) + sed
- $((var:0:2)) + $((1$var-100))
- awk+eval
- IFS + sed
- IFS + $((1$var-100))
由于 cut 方案明显不如 shell 字符串截取性能好,这里统一使用 $((var:0:2)) 代替 cut,它形成了前两种方案,明显第二种更优;awk+eval 本身就能删除前导零,就没有再和 sed 或 $((1$var-100)) 去做组合;IFS 方案也有两种组合,明显第二种更优。这样一精简,就只剩三个最终备选方案了:
- $((var:0:2)) + $((1$var-100))
- awk+eval
- IFS + $((1$var-100))
方案 1 和方案 3 差别不大,优势都是性能高、缺陷都是拓展性差;方案 2 的优势是拓展性好、可读性高,缺陷是性能差。
再缩小我的应用场景,一般字幕文件再大,也很少有 hour > 99 的情况,而文件内容多的时候,成千上万行却是轻轻松松,对性能要求比较高,对拓展性要求比较小。综合考虑,决定牺牲拓展性,追求性能,方案 2 pass。方案 1 和方案 3 均可,目前工具使用的是方案 3。
结语
当时因为制作视频急用,没有用到这个工具,直接使用了 SrtEdit 的输出。这个工具能 run 以后,特地找之前的文件做验证,发现拼接后的文件与 SrtEdit 生成的完全一样,下次再做类似视频,应该可以不用离开 mac 平台了,哈哈。
目前 srtcat 工具支持 mac、linux、windows 三种平台 (windows 需要 git bash),总之能运行 shell 的系统都支持。
之前在做方案选择时一直强调性能取向,那 srtcat 目前采用的方案真的有更强的性能吗?下面做个试验,选择三个测试文件,总计 500 多行:
> wc -l 220808*
211 220808-114030.srt
183 220808-114613.srt
135 220808-114838.srt
532 220808.txt
1061 total选取两种方案,一种是 awk+eval,另一种是 IFS+$((1$var-100)),先看第一种方案的性能:
> time sh srtcat.awk.sh 220808-114*.srt > 220808.txt
...
real 0m1.826s
user 0m0.822s
sys 0m1.186s总耗时 1.826 s。再看第二种方案:
> time sh srtcat.ifs.sh 220808-114*.srt > 220808.txt
...
real 0m1.539s
user 0m0.669s
sys 0m1.037s总耗时 1.539 s,快了 0.287 s,提速约 1.2 倍。cut 和 sed 的方案没有试,因为那个肯定慢的离谱。
参考
[1]. 字幕说
[2]. sed 提取固定间隔行
[3]. [爱幕] 一个在线字幕编辑器
[4]. 【Linux】Shell命令 getopts/getopt用法详解
[5]. shell脚本报错 value too great for base
[6]. srtsubmaster用户手册字幕编辑视频字幕音频字幕(精品)
[7]. 使用Subtitle Workshop把几个srt 字幕文件合并
[8]. shell去除字符串前所有的0
[9]. shell 脚本去掉月份和天数的前导零
[10]. 详细解析Shell中的IFS变量
[11]. shell脚本实现printf数字转换N位补零
[12]. SRT字幕格式
使用 shell 脚本拼接 srt 字幕文件 (srtcat)的更多相关文章
- 如何使用shell脚本快速排序和去重文件数据
前面写过一篇通过shell脚本去重10G数据的文章,见<用几条shell命令快速去重10G数据>.然而今天又碰到另外一个业务,业务复杂度比上次的单纯去重要复杂很多.找了很久没有找到相应的办 ...
- Centos7下crontab+shell脚本定期自动删除文件
问题描述: 最近有个需求,就是rsync每次同步的数据量很多,但是需要保留的数据库bak文件 保留7天就够了,所以需要自动清理文件夹内的bak文件 解决方案: 利用shell脚本来定期删除文件夹内的任 ...
- Shell脚本使用汇总整理——文件夹及子文件备份脚本
Shell脚本使用汇总整理——文件夹及子文件备份脚本 Shell脚本使用的基本知识点汇总详情见连接: https://www.cnblogs.com/lsy-blogs/p/9223477.html ...
- shell脚本实现读取一个文件中的某一列,并进行循环处理
shell脚本实现读取一个文件中的某一列,并进行循环处理 1) for循环 #!bin/bash if [ ! -f "userlist.txt" ]; then echo &qu ...
- Shell脚本对Linux进行文件校验
Shell脚本对Linux进行文件校验 一.需求 有客户等保需求对文件一致性进行校验,想到利用md5sum工具,因此写脚本来对文件进行自定义扫描,后期可以利用其进行校验,快速校验文件发现变更的文件,一 ...
- [ Shell ] 通过 Shell 脚本导出 GDSII/OASIS 文件
https://www.cnblogs.com/yeungchie/ 常见的集成电路版图数据库文件格式有 GDSII 和 OASIS,virtuoso 提供了下面两个工具用来在 Shell 中导出版图 ...
- [linux] shell脚本编程-统计日志文件中的设备号发通知邮件
1.日志文件列表 比如:/data1/logs/2019/08/15/ 10.1.1.1.log.gz 10.1.1.2.log.gz 2.统计日志中的某关键字shell脚本 zcat *.gz|gr ...
- Shell脚本 | 抓取log文件
在安卓应用的测试过程中,遇到 Crash 或者 ANR 后,想必大家都会通过 adb logcat 命令来抓取日志定位问题.如果直接使用 logcat 命令的话,默认抓取出的 log 文件包含安卓运行 ...
- shell脚本:变量,文件判断,逻辑运算等纪要
shell脚本中的变量定义,引用各有不同的方式,除此之外,很常用的有文件属性判断,逻辑运算,数值运算等,下面记录一下它们的属性作用 变量 shell变量的定义分为两种:一种是直接赋值定义,另一种是嵌套 ...
- ubuntu 用shell脚本实现将当前文件夹下全部文件夹中的某一类文件复制到同一文件夹下
当前文件夹下有一些文件和文件夹,当中每一个文件夹里都有若干.txt文件. 如今要求在当前文件夹创建一个新文件夹all,且将那些文件夹全部.txt文件 都复制到文件夹all.在ubuntu12.04的s ...
随机推荐
- Marktext语法——Emoji表情大全
个人名片: 对人间的热爱与歌颂,可抵岁月冗长 Github:念舒_C.ying CSDN主页️:念舒_C.ying 个人博客 :念舒_C.ying People ️ ️ ️ ️ ♀️ ♀️ ♂ ...
- 模块/os/sys/json
目录 内容概要 1.os模块 2.sys模块 3.json模块/实战 内容概要 os模块 sys模块 json模块/实战 1.os模块 # os模块主要是与我们的操作系统打交道 1.创建文件夹(目录) ...
- 基于.NetCore开发博客项目 StarBlog - (20) 图片显示优化
前言 我的服务器带宽比较高,博客部署在上面访问的时候几乎没感觉有加载延迟,就没做图片这块的优化,不过最近有小伙伴说博客的图片加载比较慢,那就来把图片优化完善一下吧~ 目前有两个地方需要完善 图片瀑布流 ...
- redis集群之主从复制集群的原理和部署
最近在复盘redis的知识,所以本文开始希望介绍下redis的集群架构.原理以及部署:本文主要介绍redis的主从复制集群,包括其架构模型,原理,高可用等: 一.主从集群的介绍 redis的主从复 ...
- uni 结合vuex 编写动态全局配置变量 this.baseurl
在日常开发过程,相信大家有遇到过各种需求,而我,在这段事件便遇到了一个,需要通过用户界面配置动态接口,同时,因为是app小程序开发,所以接口中涉及到了http以及websocket两个类型的接口. 同 ...
- 基础css样式
目录 css层叠样式表 css选择器 伪类选择器 选择器生效优先级 css字体颜色背景 设置宽高 边框 display属性 div盒子模型 float漂浮 溢出overflow 定位(position ...
- Cookie添加方法
Cookie是通过response对象中的getCookie()方法进行获得的
- ArcObjects SDK 012 PageLayout和Page
1.从ArcMap角度看结构 一个Mxd文件包含一个PageLayout对象和一个多多个Map对象,每个Map会被包成MapFrame,添加到PageLayout中.我们用ArcMap打开一个mxd文 ...
- Django框架路由层-无名有名分组-无名有名分组反向解析
目录 一:路由层 1.路由匹配(错误演示) 2.路由匹配错误原因 3.路由匹配(解决方式1) 4.settings配置文件控制自动添加斜杠匹配 5.url方法第一个参数是正则表达式(正规使用url) ...
- Pytorch框架详解之一
Pytorch基础操作 numpy基础操作 定义数组(一维与多维) 寻找最大值 维度上升与维度下降 数组计算 矩阵reshape 矩阵维度转换 代码实现 import numpy as np a = ...