scrapy 爬取酷狗热门歌手音乐
声明
文章仅供学习交流使用,切勿他用。如有侵权,请联系本人处理。
scrapy之前了解过,但是过一段时间又忘记,于是打算爬一个网站,顺便记录下,以便后续能够快速回忆。以下是自己的一些理解,如果有不对的地方,还请各位看官指教。本来想爬取echo音乐的(喜欢而已),但是好像echo音乐挂了有一段时间了。无奈,找个酷狗啪啪啪,爬爬爬...
先上成果图
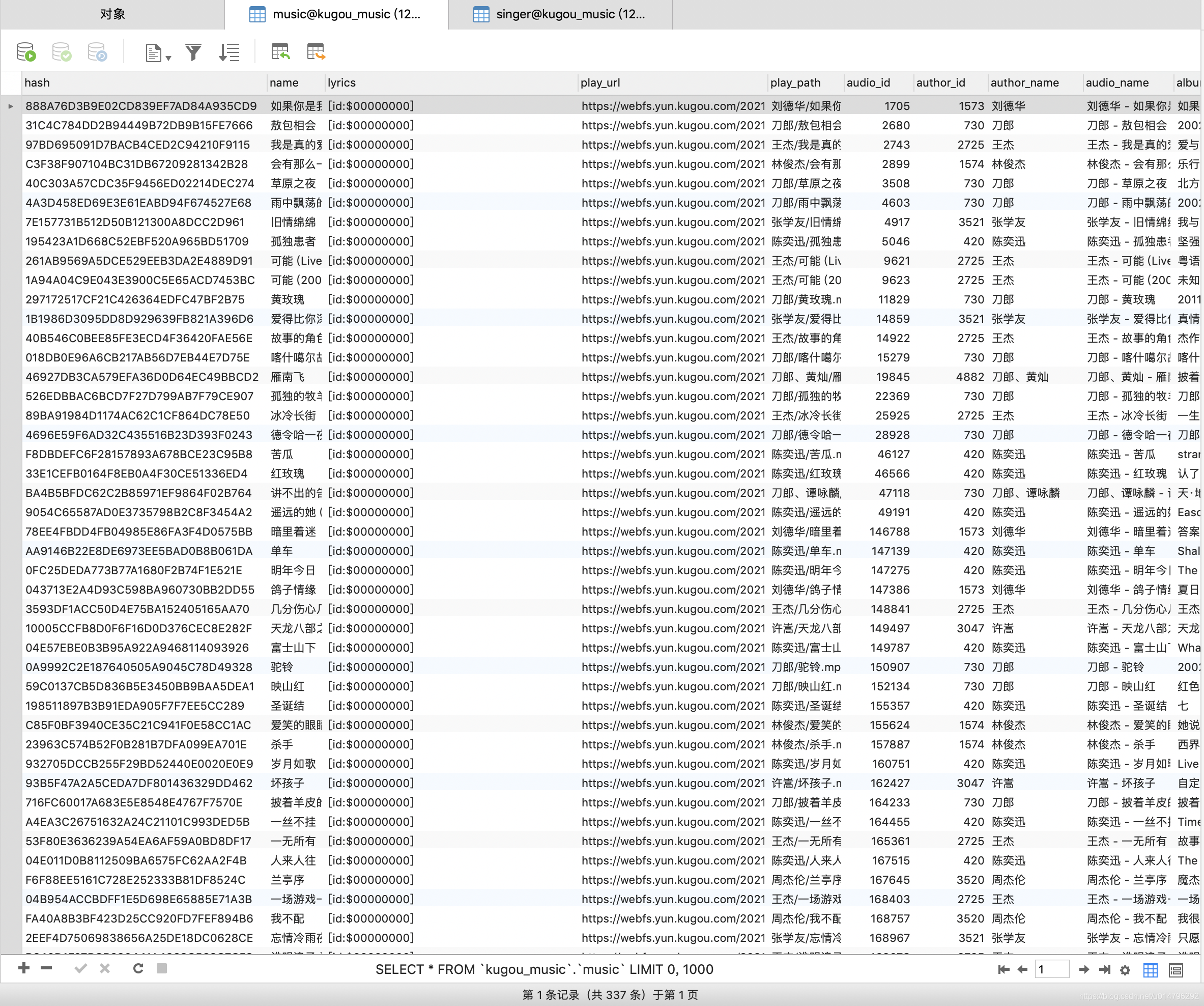
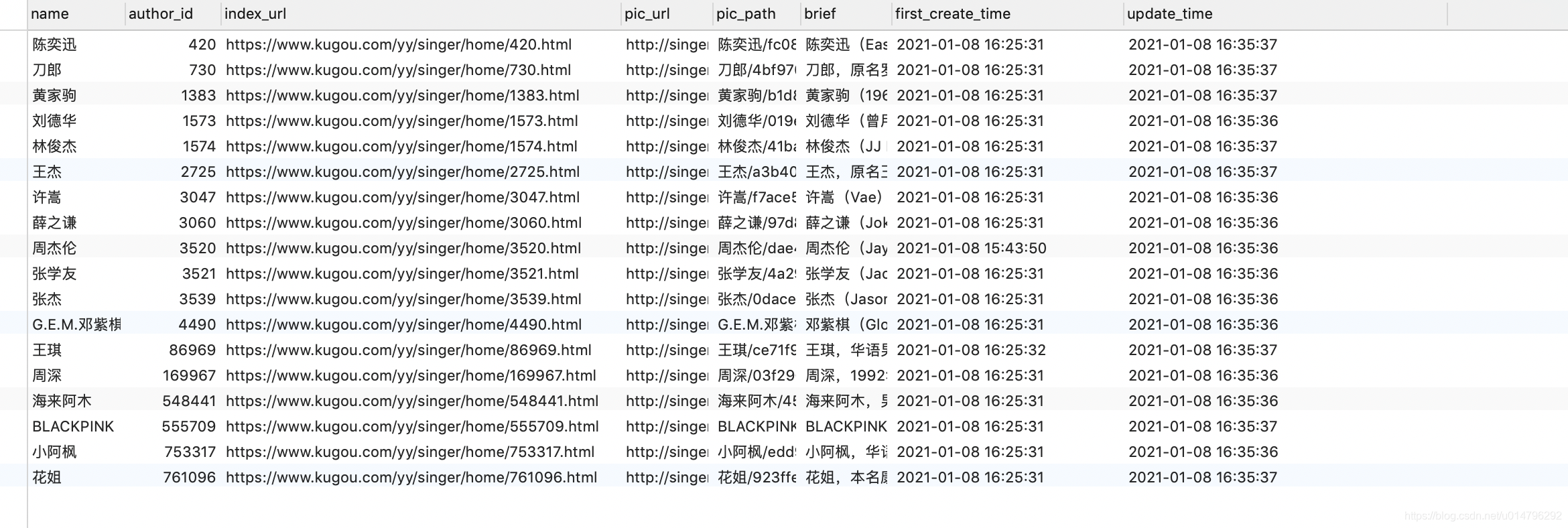
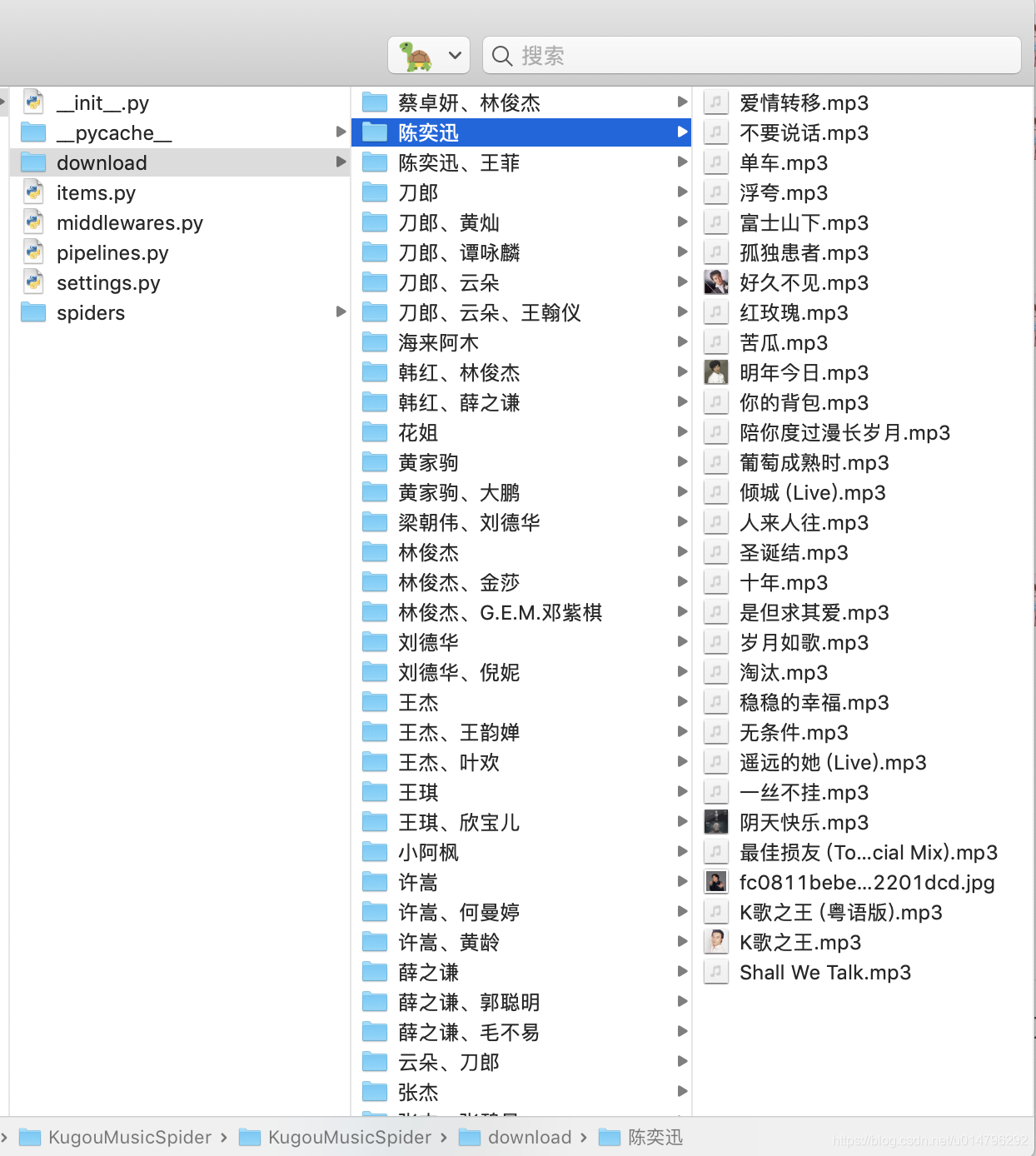
Hello,酷狗!
话不多说,首先看看酷狗首页长啥样。
分类很多,我们没必要全站爬取,hold不住,简单爬一爬。就从热门歌手下手吧。
撸起袖子加油干,奥利给~
创建一个Scrapy项目
#创建一个scrapy项目
scrapy startproject KugouMusicSpider
#创建一个爬虫,我用酷狗首页作为入口,也可以直接从目标网址入手
scrapy genspider kugou_music_spider www.kugou.com
spider模块
spider模块主要有两个作用:
- yield组装Item实体,engine会将item交由pipeline处理
- yield新的Request请求,engine会将request交由scheduler处理
由源码可以看出,我们的spider会从start_requests方法中通过start_urls开始爬取,并会将结果交由parse方法处理,当然默认去重dont_filter是为True的。
所以我们可以复写start_requests方法自行处理,也可直接从默认的parse方法中等待start_url的结果response进行处理。
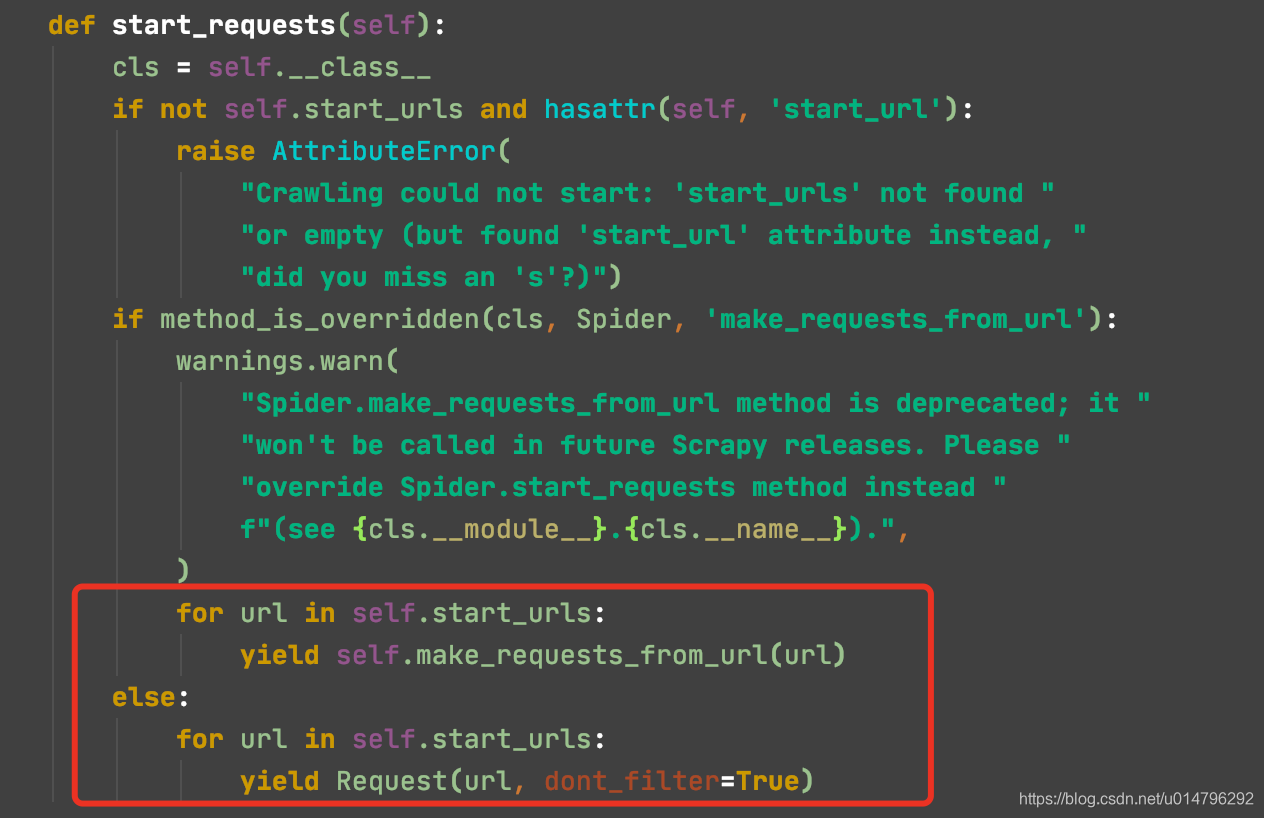
弄清楚spider的作用后,我们鬼刀一开,就可以操作了。
def start_requests(self):
for url in self.start_urls:
yield Request(url, dont_filter=True, callback=self.parse_index)
def parse_index(self, response):
"""
根据酷狗首页获取'更多'歌手连接(即歌手首页)
:param response:
:return:
"""
singer_index_url = response.xpath('//div[@id="tabMenu"]//a[@class="more"]/@href').extract_first()
singer_index_url = parse.urljoin(response.url, singer_index_url)
yield Request(
url=singer_index_url,
callback=self.parse_singer_index,
dont_filter=True
)
拿到歌手首页后,我们获取前面18为歌手,主要是html刚好在一个标签内,其他的不想搞了,否则太多了。
def parse_singer_index(self, response):
"""
解析歌手首页,只爬取前18位歌手数据
:param response:
:return:
"""
head_singers = response.xpath('//ul[@id="list_head"]/li')
for singer_info in head_singers:
singer_url = singer_info.xpath('./a/@href').extract_first()
match_re = re.match(".*?(\d+).*", singer_url)
if match_re:
author_id = match_re.group(1)
name = singer_info.xpath('./a/@title').extract_first()
pic_url = singer_info.xpath('./a/img/@_src').extract_first()
singer_item = SingerItem()
singer_item.update({
"name": name,
"author_id": author_id,
"index_url": singer_url,
"pic_url": pic_url
})
yield Request(
url=singer_url,
callback=self.parse_singer_detail,
meta={"singer_item": singer_item},
dont_filter=True
)
接着我们请求每一个歌手的详情界面,获取音乐列表
def parse_singer_detail(self, response):
"""
解析歌手详情页面,提取歌曲
:param response:
:return:
"""
singer_item = response.meta.get('singer_item')
brief = response.xpath('//div[@class="intro"]/p/text()').extract_first()
singer_item.update({
"brief": brief
})
yield singer_item
musics = response.xpath('//ul[@id="song_container"]/li')
for music in musics:
music_hash = music.xpath('./a/input/@value').extract_first()
match_re = re.match(".*\|(.*)\|.*", music_hash)
if match_re:
music_hash = match_re.group(1)
if music_hash:
url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}'.format(music_hash)
yield Request(
url=url,
headers=self.headers,
cookies=self.cookies,
callback=self.parse_music_info,
dont_filter=True
)
到此,歌手信息我们要这些差不多够了。那如何爬取下载音乐的问题呢?其实,上面代码中可以看到我除了yield出去一个singer_item,还yield出去一个请求,实不相瞒,这个请求就是获取歌曲信息的,我们由前端页面来分析下为何会有如此的骚操作。
分析前端界面
可以看出,当我们在歌手详情界面的时候,比如周董这个界面。
打开F12,我们点击歌曲,它会进行打开一个新标签进行播放。
我们接着在播放页面打开F12,清除缓存刷新(command+R)
不难可以看到这样一个url请求
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery191016332021391396312_1610098389715&hash=0A62227CAAB66F54D43EC084B4BDD81F&dfid=339APl2z0YhL137NsD3cEyfR&mid=ce2e5886bdbb858e1d6dced7a863772f&platid=4&album_id=960399&_=1610098389716
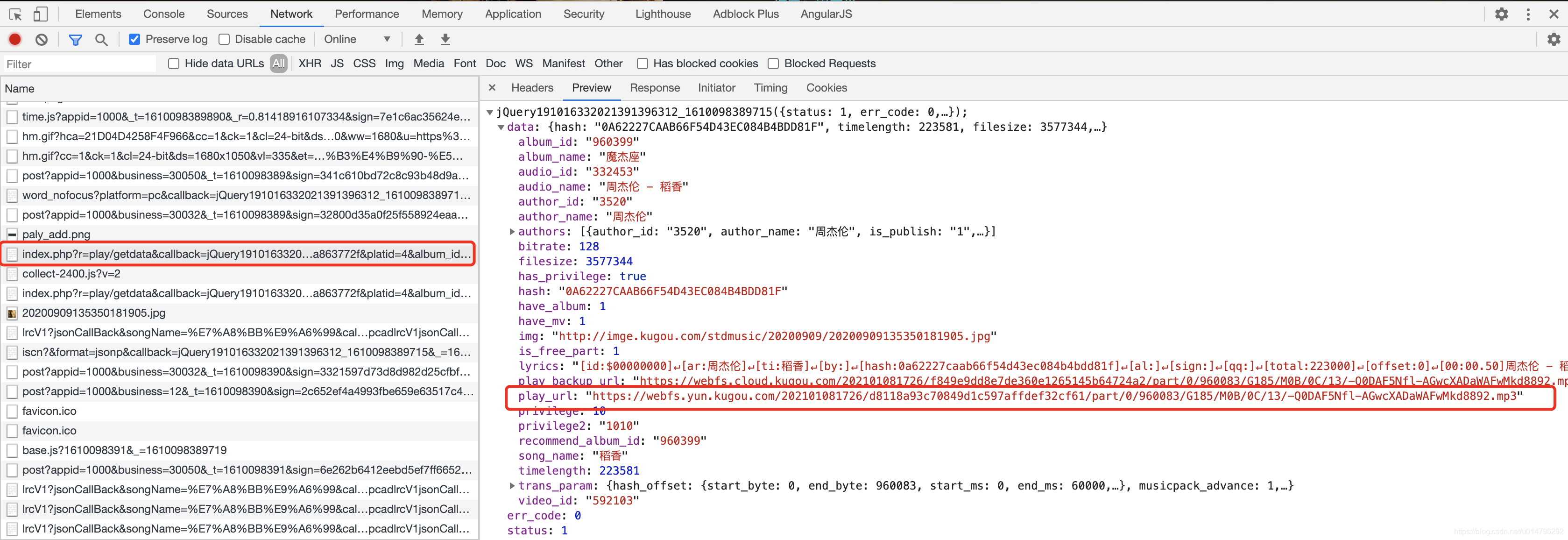 她的返回是如此的优美,漂亮,落落大方。(哈哈哈哈,皮一下就很开心。)
她的返回是如此的优美,漂亮,落落大方。(哈哈哈哈,皮一下就很开心。)
这不正是我们想找的东西吗?play_url,她是MP3格式的。我们试着打开这个play_url链接
https://webfs.yun.kugou.com/202101081726/d8118a93c70849d1c597affdef32cf61/part/0/960083/G185/M0B/0C/13/-Q0DAF5Nfl-AGwcXADaWAFwMkd8892.mp3
完美的音频文件。
但是,有个问题,不论是上述的url请求还是play_url,都有我们看不懂的参数,目测是加密用的。并且mp3格式的链接应该是有时效性的
一筹莫展之际,抱着试试看的态度,将上述url留下我们能认识的参数
hash,这个我们认识,在歌手详情界面每首歌的标签里我们见过

试着请求
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=0A62227CAAB66F54D43EC084B4BDD81F
可以获取到歌曲的部分信息,其中包含album_id

刚刚我们url链接里也看到过这个参数,再加上,试试
https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=0A62227CAAB66F54D43EC084B4BDD81F&album_id=960399
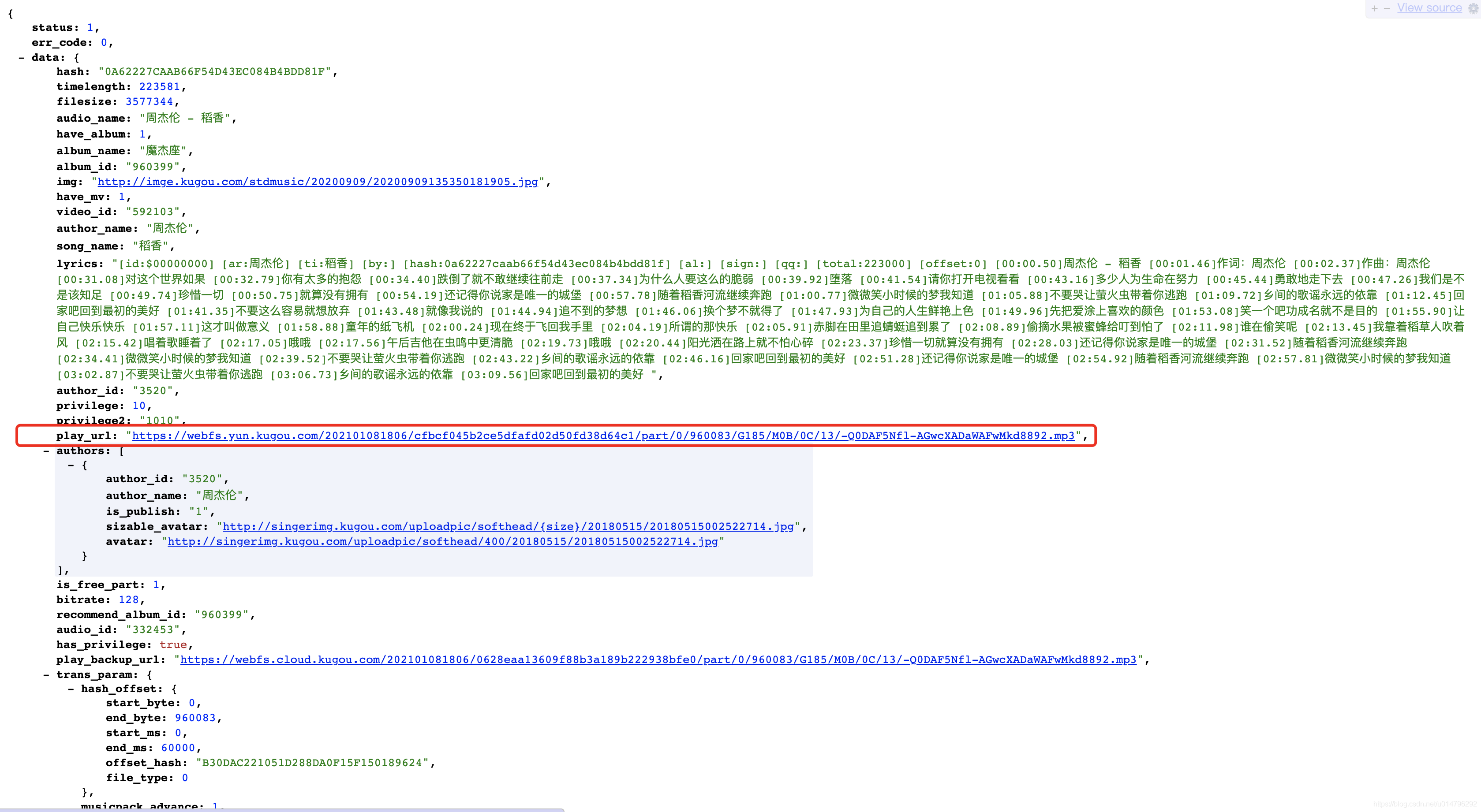
大哥,搞定~
此时,音乐的信息我们也基本差不多了。
def parse_music_info(self, response):
"""
获取歌曲album_id
:param response:
:return:
"""
res = json.loads(response.text)
status = res.get('status')
err_code = res.get('err_code')
if status == 1 and err_code == 0:
get_detail = response.meta.get('get_detail')
data = res.get('data', {})
if data:
if get_detail:
music_item = MusicItem()
music_item.update({
"hash": data.get('hash'),
"name": data.get('song_name'),
"lyrics": data.get('lyrics'),
"play_url": data.get('play_url'),
"audio_id": data.get('audio_id'),
"author_id": data.get('author_id'),
"author_name": data.get('author_name'),
"audio_name": data.get('audio_name'),
"album_name": data.get('album_name'),
"album_id": data.get('album_id'),
"img_url": data.get('img'),
"have_mv": data.get('have_mv'),
"video_id": data.get('video_id')
})
yield music_item
else:
album_id = data.get('album_id')
if album_id is not None:
url = '{}&album_id={}'.format(response.url, album_id)
yield Request(
url=url,
headers=self.headers,
cookies=self.cookies,
callback=self.parse_music_info,
meta={'get_detail': True},
dont_filter=True
)
将music信息yield出去交由pipeline处理。
注意
- 此处yield出去的Request需要带上headers和cookies,并且cookies不能放在headers中,否则拿不到数据
- 但是,cookies放在headers中,可以通过requests包发送请求,也可以拿到数据
- 再但是,requests是同步的方式,会阻塞,所以不建议
items模块
我们已经在spider中用过了,主要用来定义待处理的实体。此处有singer和music两个item
pipeline模块
我们定义的pipeline模块需要对item进行持久化处理,此处是下载音乐到本地以及存储信息到数据库。
- pipelines模块大都需要配置settings.py文件,勿忘记。
- 处理文件和图片可以自己继承FilesPipeline或者ImagesPipeline,自定义下载路径及名称
- 处理数据库也建议使用异步的方式插入
处理音频文件自定义下载路径
class KugouMusicPipeline(FilesPipeline):
"""
下载音频文件
"""
def get_media_requests(self, item, info):
if isinstance(item, MusicItem):
url = item['play_url']
yield Request(url)
def file_path(self, request, response=None, info=None, *, item=None):
# media_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
author_name = item['author_name']
media_guid = item['name']
media_ext = os.path.splitext(request.url)[1]
if media_ext not in mimetypes.types_map:
media_ext = ''
media_type = mimetypes.guess_type(request.url)[0]
if media_type:
media_ext = mimetypes.guess_extension(media_type)
return f'{author_name}/{media_guid}{media_ext}'
def item_completed(self, results, item, info):
if isinstance(item, MusicItem):
file_paths = [x['path'] for ok, x in results if ok]
if file_paths:
item['play_path'] = file_paths[0]
return item
自定义下载图片路径
class KugouImagePipeline(ImagesPipeline):
"""
处理文件下载路径,并将路径信息存入item
"""
def get_media_requests(self, item, info):
if isinstance(item, SingerItem):
url = item['pic_url']
yield Request(url)
def file_path(self, request, response=None, info=None, *, item=None):
if isinstance(item, SingerItem):
name = item['name']
image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
return f'{name}/{image_guid}.jpg'
def item_completed(self, results, item, info):
if isinstance(item, SingerItem):
file_paths = [x['path'] for ok, x in results if ok]
if file_paths:
item['pic_path'] = file_paths[0]
return item
两者差不多,主要是复写三个方法用于不同功能
- get_media_requests:用来指明下载的url
- file_path:用来指明下载路径
- item_completed:用来更新到item中,保存下载的文件路径,跟随item存入数据库
异步存入到数据库
class MysqlTwistedPipeline(object):
"""
异步方式插入数据库
"""
def __init__(self, db_pool):
self.db_pool = db_pool
@classmethod
def from_settings(cls, settings):
from MySQLdb.cursors import DictCursor
db_params = dict(
host=settings['MYSQL_HOST'],
db=settings['MYSQL_DBNAME'],
user=settings['MYSQL_USER'],
passwd=settings['MYSQL_PASSWORD'],
charset='utf8',
cursorclass=DictCursor,
use_unicode=True
)
db_pool = adbapi.ConnectionPool('MySQLdb', **db_params)
return cls(db_pool)
def process_item(self, item, spider):
query = self.db_pool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
def handle_error(self, failure, item, spider):
print(failure)
def do_insert(self, cursor, item):
params = list()
cur_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
if isinstance(item, SingerItem):
insert_sql = """
insert into singer
(name,author_id,index_url,pic_url,pic_path,brief,first_create_time,update_time)
values
(%s,%s,%s,%s,%s,%s,%s,%s)
ON DUPLICATE KEY UPDATE
author_id=VALUES(author_id),
index_url=VALUES(index_url),
pic_url=VALUES(pic_url),
brief=VALUES(brief),
update_time=VALUES(update_time);
"""
params.append(item.get('name', ''))
params.append(item.get('author_id', ''))
params.append(item.get('index_url', ''))
params.append(item.get('pic_url', ''))
params.append(item.get('pic_path', ''))
params.append(item.get('brief', ''))
params.append(cur_time)
params.append(cur_time)
cursor.execute(insert_sql, tuple(params))
elif isinstance(item, MusicItem):
pass
insert_sql = """
insert into music
(hash,name,lyrics,play_url,play_path,audio_id,author_id,author_name,audio_name,album_name,album_id,img_url,have_mv,video_id,first_create_time,update_time)
values
(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
ON DUPLICATE KEY UPDATE
hash=VALUES(hash),
play_url=VALUES(play_url),
img_url=VALUES(img_url),
update_time=VALUES(update_time);
"""
params.append(item.get('hash', ''))
params.append(item.get('name', ''))
params.append(item.get('lyrics', ''))
params.append(item.get('play_url', ''))
params.append(item.get('play_path', ''))
params.append(item.get('audio_id', ''))
params.append(item.get('author_id', ''))
params.append(item.get('author_name', ''))
params.append(item.get('audio_name', ''))
params.append(item.get('album_name', ''))
params.append(item.get('album_id', ''))
params.append(item.get('img_url', ''))
params.append(item.get('have_mv', ''))
params.append(item.get('video_id', ''))
params.append(cur_time)
params.append(cur_time)
cursor.execute(insert_sql, tuple(params))
在setting.py中配置pipelines注意先后顺序,数字越小,越先处理

settings.py
配置数据库参数和图片、文件的下载路径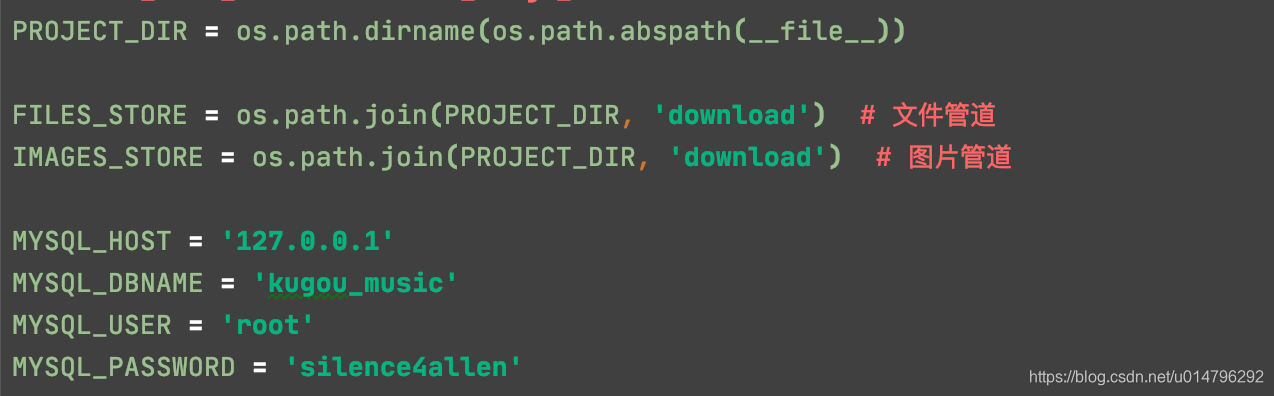
调试
- 项目下可以新建main.py文件,使用
execute(["scrapy", "crawl", "kugou_music_spider"])避免命令开启爬虫无法debug的问题 - 调试的时候先一位歌手一首歌曲的调试,避免啥你懂的
运行
奥利给~
scrapy crawl kugou_music_spider
测试了下,运行结果如下
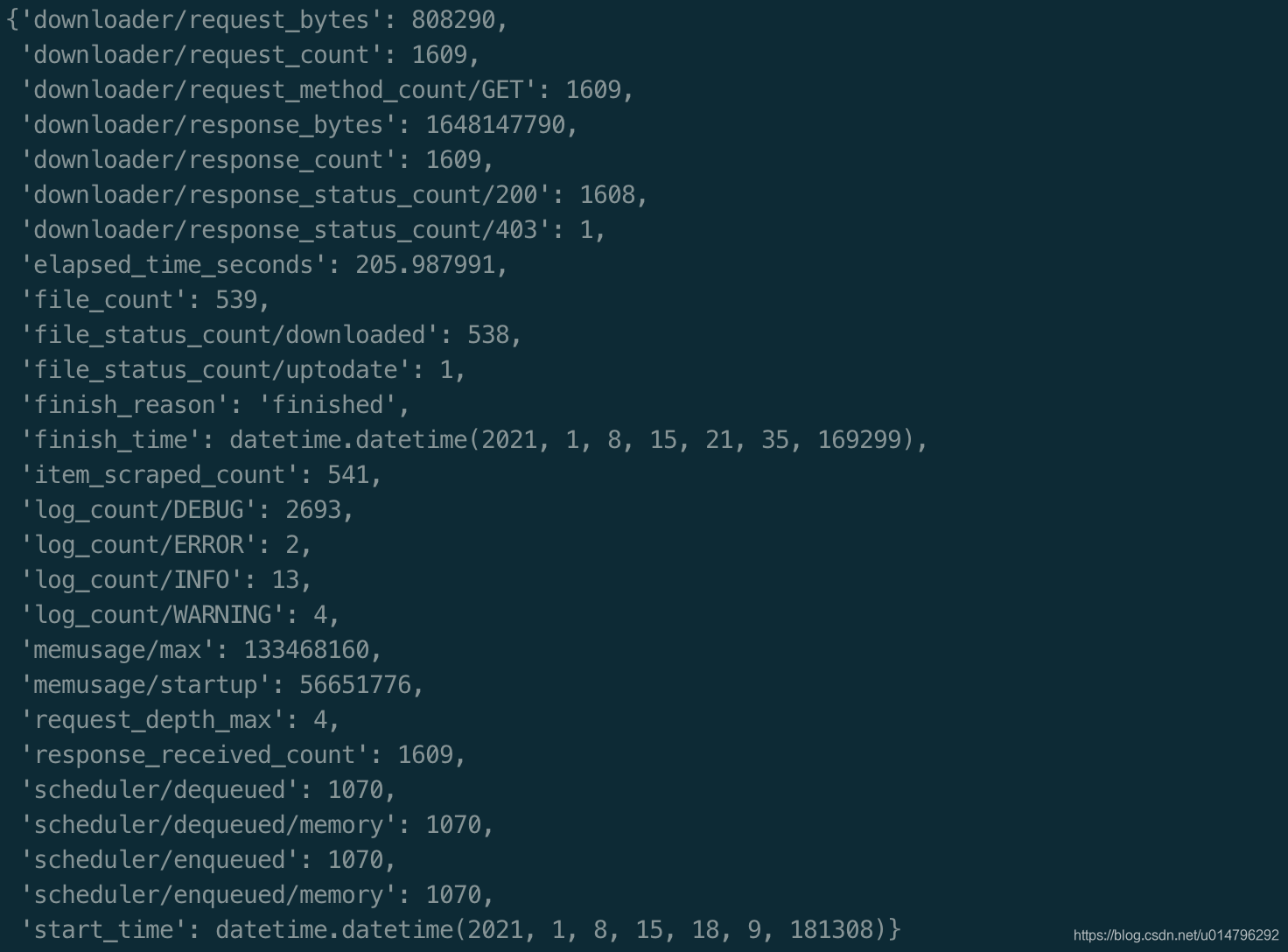
源码
代码托管于github,传送门,截止发文,有效。
部分资料可参考
scrapy官方文档
scrapy 爬取酷狗热门歌手音乐的更多相关文章
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- 使用Xpath爬取酷狗TOP500的歌曲信息
使用xpath爬取酷狗TOP500的歌曲信息, 将排名.歌手名.歌曲名.歌曲时长,提取的结果以文件形式保存下来.参考网址:http://www.kugou.com/yy/rank/home/1-888 ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- 爬虫实例学习——爬取酷狗TOP500数据
酷狗网址:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank 环境:eclipse+pydev import requests from ...
- 【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客 import requests import time from bs4 import BeautifulSoup def get_html(url): ''' 获得 HTML ' ...
随机推荐
- [python] NetworkX实例
文章目录 NetworkX实例 1. 基础Basic 2. 绘图Drawing 3. 图标Graph NetworkX实例 代码下载地址 NetworkX 2.4版本的通用示例性示例.本教程介绍了约定 ...
- Spring Cloud Alibaba组件之Sentinel
目录 一 引入Sentinel学习 二 Sentinel入门 三 搭建Sentinel Dashboard 四 Springboot项目接入Sentinel 五 接入限流埋点 六 限流配置 七 熔断降 ...
- 为什么 java 容器推荐使用 ExitOnOutOfMemoryError 而非 HeapDumpOnOutOfMemoryError ?
前言 好久没写文章了, 今天之所以突然心血来潮, 是因为昨天出现了这样一个情况: 我们公司的某个手机APP后端的用户(customer)微服务出现内存泄露, 导致OutOfMemoryError, 但 ...
- win32com操作word 第三集:Range精讲(一)
本课程<win32com操作word API精讲&项目实战>,本公众号以文字分享为主,B站与视频号则发布视频分享,ID均为:一灯编程 本集开始,将会深入Document接口.打开或 ...
- Cert Manager 申请 SSL 证书流程及相关概念 - 一
2022.3.9 用 cert-manager 申请成功通配符证书 (*.ewhisper.cn), 2022.4.30 该证书距离过期还有 30 天,cert-manager 进行自动续期,但是却失 ...
- order by 语句怎么优化?
说明 当前演示的数据库版本5.7 一.一个简单使用示例 先创建一张订单表 CREATE TABLE `order_info` ( `id` int NOT NULL AUTO_INCREMENT CO ...
- .Net6 微服务之Polly入门看这篇就够了
前言 O(∩_∩)O 大家好!书接上文,本文将会继续建立在 .Net6 使用 Ocelot + Consul 看这篇就够了 项目的基础上进行Polly的介绍,然后这篇文章只是个人学习与分享,不喜勿喷, ...
- git拉项目出现的小问题
问题描述 在IDEA中拉代码事报错. 点击查看报错信息 error: unable to read askpass response from 'C:\Users\霍亚龙\AppData\Local\ ...
- javaWeb03-请求转发和请求重定向【包含浏览器与响应编码格式不一致的解决方法】
本文主要讲述javaWeb的请求转发和请求重定向的区别 一. 请求转发 1. 图解 2. 代码示例 Servlet1的代码示例如下 public class Servlet1 extends Http ...
- C-02\规范及随机数rand()原理
小知识点 assert()函数 assert 断言函数,用于在调试过程中捕捉程序的错误.对某种假设条件进行检测,如果条件成立就不进行任何操作,如果条件不成立就捕捉到这种错误,并打印出错误信息,终止程序 ...