Pytorch实战学习(七):高级CNN
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Advanced CNN
一、GoogLeNet
Inception Module:而为了减少代码的冗余,将由(卷积(Convolution),池化(Pooling)、全连接(Softmax)以及连接(Other))四个模块所组成的相同的部分,封装成一个类/函数。
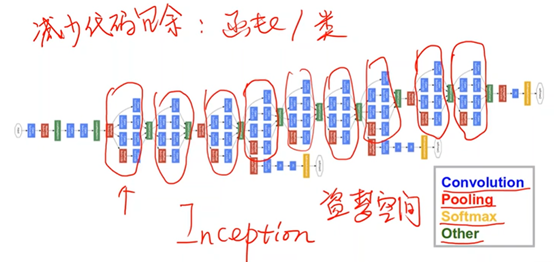
1、Inception Module
以卷积核大小(kernel_size)为例,虽然无法具体确定某问题中所应使用的卷积核的大小。但是往往可以有几种备选方案,因此在这个过程中,可以利用这样的网络结构,来将所有的备选方案进行计算,并在后续计算过程中增大最佳方案的权重,以此来达到确定超参数以及训练网络的目的。
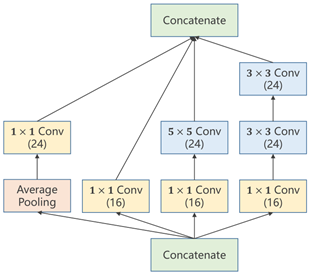
最后每个张量沿着通道拼接(Concatenate)在一起时,要保证图像宽度、高度必须相同,通道可以不同
①Average Pooling:均值池化,需要手动设定padding以及stride来保持图像大小(W&H)不变
②1×1 Conv:个数取决于输入张量的通道数,用于改变通道数量
2、1×1 Conv
在1x1卷积中,每个通道的每个像素需要与卷积中的权重进行计算,得到每个通道的对应输出,再进行求和得到一个单通道的总输出,以达到信息融合的目的。即将同一像素位置的多个通道信息整合在同位置的单通道上。
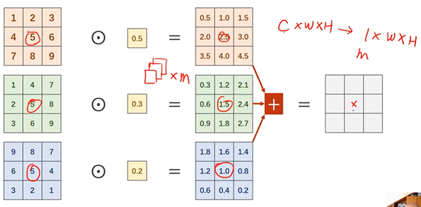
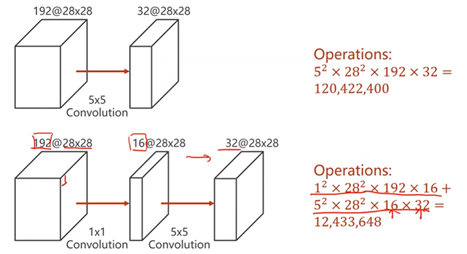
1x1卷积:减少计算量
3、Inception Module代码实现
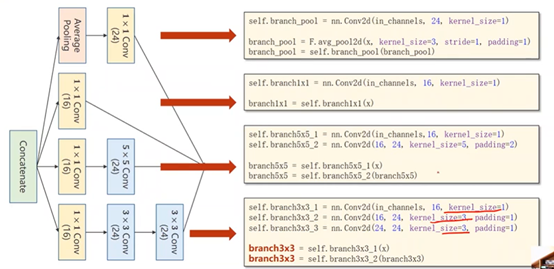
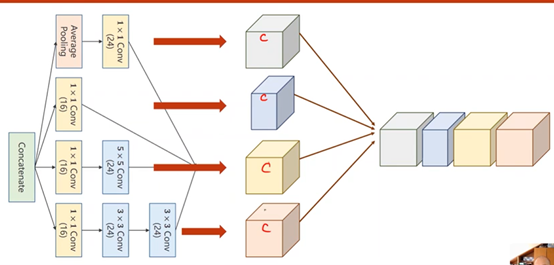
沿着通道进行拼接,dim设为1(batch-0、channel-1、weight-2、hight-3)

定义一个Inception Module

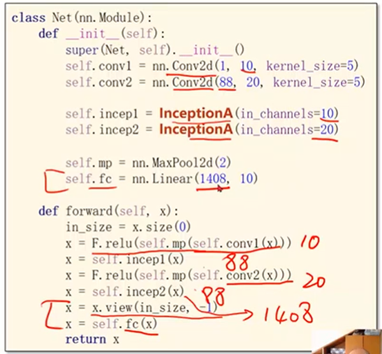
经过Inception模块输出的通道数:24*3+16=88
4、完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class InceptionA(torch.nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1) self.branch5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2) self.branch3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1) self.branch_pool = torch.nn.Conv2d(in_channels, 24, kernel_size=1) def forward(self, x):
branch1x1 = self.branch1x1(x) branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5) branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1 class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16 self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应
self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应 self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10) def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x) return x model = Net()
## Device—选择是用GPU还是用CPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad() outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

二、ResNet (残差网络)
1、解决梯度消失问题
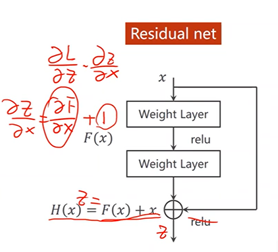
梯度消失:由于在梯度计算的过程中是用的反向传播,所以需要利用链式法则来进行梯度计算,是一个累乘的过程。若每一个地方梯度都是小于1的,累乘之后的总结果应趋近于0,ω不会再进行进一步的更新
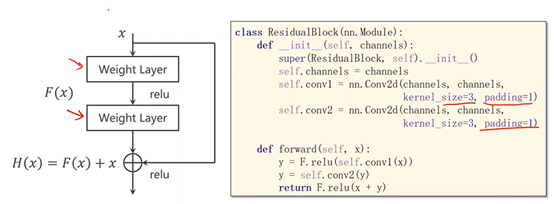
2、跳连接,H(x) = F(x) + x,张量维度必须一样,加完后再激活。不要做pooling,张量的维度会发生变化。
若存在梯度消失现象,即存在某一层网络中的对x求偏导趋近于0
通过加入一个x会使得在方向传播过程中,传播的梯度会保持在1左右,即对x求偏导趋近于1如此,离输入较近的层也可以得到充分的训练。
3、Residual Block
实现 Residual Block,要确保输入和输出维度大小完全一样(等宽等高等通道数)
先是1个卷积层(conv,maxpooling,relu),然后Residual Block模块,接下来又是一个卷积层(conv,mp,relu),然后Residual Block模块模块,最后一个全连接层(fc)。
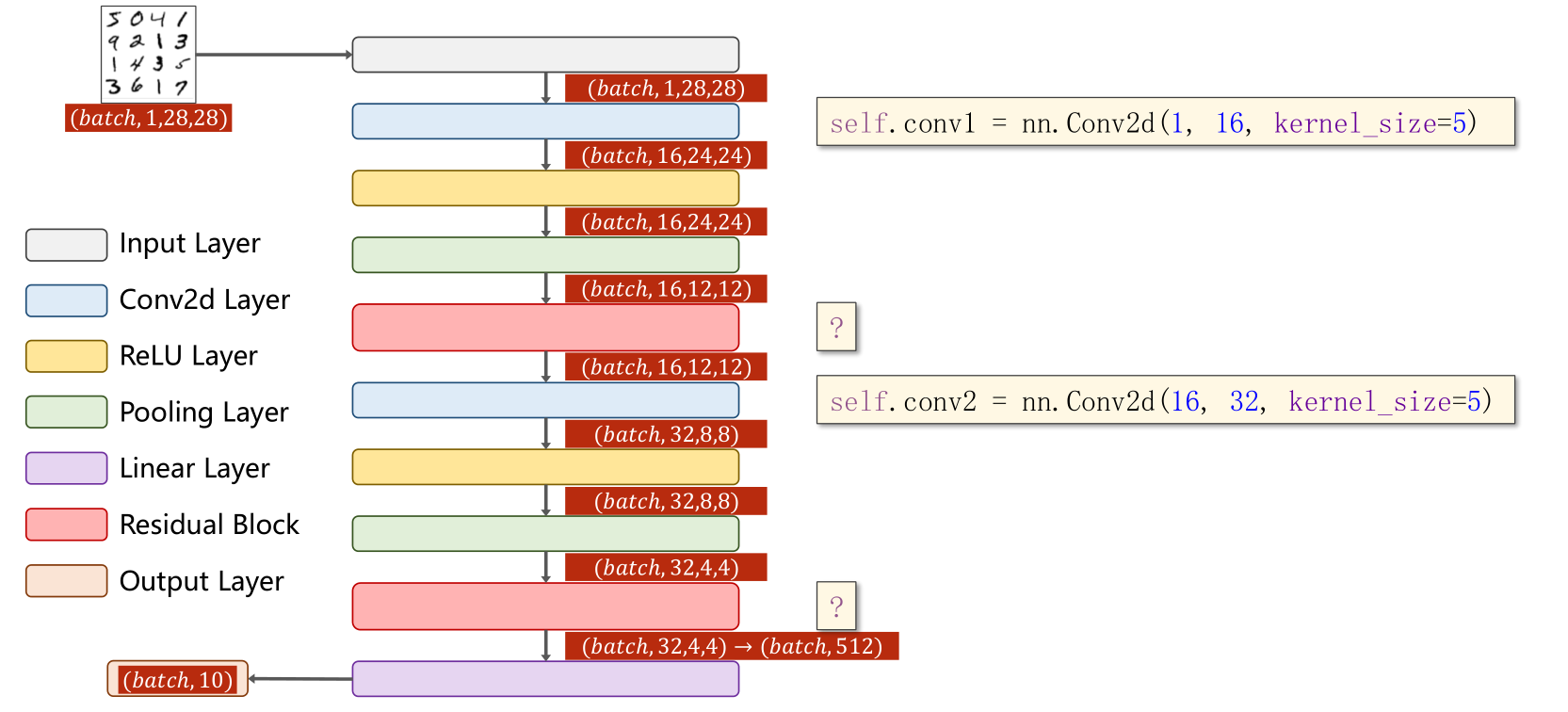
4、完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim # prepare dataset batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
#为了保证 输入和输出 维度相同
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1) def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
# H(x) = F(x) + x,加完以后再Relu
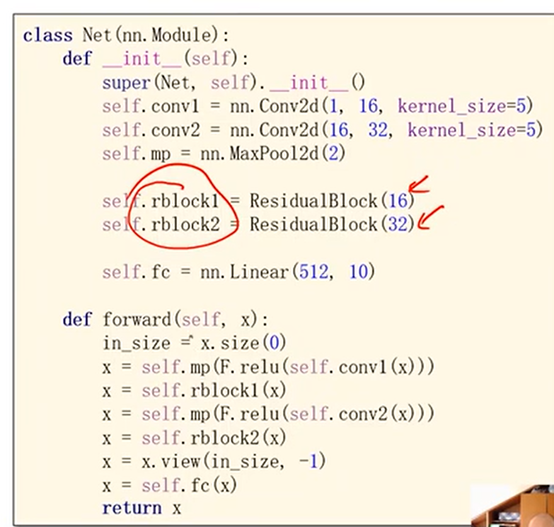
return F.relu(x + y) class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5) # 88 = 24x3 + 16 self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32) self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(512, 10) # 暂时不知道1408咋能自动出来的 def forward(self, x):
in_size = x.size(0) x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x) x = x.view(in_size, -1)
x = self.fc(x)
return x model = Net()
## Device—选择是用GPU还是用CPU训练
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device) # construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad() outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step() running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0 def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()

Pytorch实战学习(七):高级CNN的更多相关文章
- nginx学习七 高级数据结构之动态数组ngx_array_t
1 ngx_array_t结构 ngx_array_t是nginx内部使用的数组结构.nginx的数组结构在存储上与大家认知的C语言内置的数组有相似性.比方实际上存储数据的区域也是一大块连续的内存. ...
- 深度学习之PyTorch实战(3)——实战手写数字识别
上一节,我们已经学会了基于PyTorch深度学习框架高效,快捷的搭建一个神经网络,并对模型进行训练和对参数进行优化的方法,接下来让我们牛刀小试,基于PyTorch框架使用神经网络来解决一个关于手写数字 ...
- 深度学习之PyTorch实战(1)——基础学习及搭建环境
最近在学习PyTorch框架,买了一本<深度学习之PyTorch实战计算机视觉>,从学习开始,小编会整理学习笔记,并博客记录,希望自己好好学完这本书,最后能熟练应用此框架. PyTorch ...
- Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程
Shell高级编程视频教程-跟着老男孩一步步学习Shell高级编程实战视频教程 教程简介: 本教程共71节,主要介绍了shell的相关知识教程,如shell编程需要的基础知识储备.shell脚本概念介 ...
- 深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
上一篇博客先搭建了基础环境,并熟悉了基础知识,本节基于此,再进行深一步的学习. 接下来看看如何基于PyTorch深度学习框架用简单快捷的方式搭建出复杂的神经网络模型,同时让模型参数的优化方法趋于高效. ...
- (转)跟着老男孩一步步学习Shell高级编程实战
原文:http://oldboy.blog.51cto.com/2561410/1264627/ 跟着老男孩一步步学习Shell高级编程实战 原创作品,允许转载,转载时请务必以超链接形式标明文章 原 ...
- 对比学习:《深度学习之Pytorch》《PyTorch深度学习实战》+代码
PyTorch是一个基于Python的深度学习平台,该平台简单易用上手快,从计算机视觉.自然语言处理再到强化学习,PyTorch的功能强大,支持PyTorch的工具包有用于自然语言处理的Allen N ...
- 参考《深度学习之PyTorch实战计算机视觉》PDF
计算机视觉.自然语言处理和语音识别是目前深度学习领域很热门的三大应用方向. 计算机视觉学习,推荐阅读<深度学习之PyTorch实战计算机视觉>.学到人工智能的基础概念及Python 编程技 ...
- 【新生学习】深度学习与 PyTorch 实战课程大纲
各位20级新同学好,我安排的课程没有教材,只有一些视频.论文和代码.大家可以看看大纲,感兴趣的同学参加即可.因为是第一次开课,大纲和进度会随时调整,同学们可以随时关注.初步计划每周两章,一个半月完成课 ...
- Maven实战(七,八)——经常使用Maven插件介绍
我们都知道Maven本质上是一个插件框架,它的核心并不运行不论什么详细的构建任务,全部这些任务都交给插件来完毕,比如编译源代码是由maven-compiler-plugin完毕的.进一步说,每一个任务 ...
随机推荐
- exgcd & 线性同余方程
前置芝士 裴蜀定理 同余的性质 exgcd exgcd即扩展欧几里得定理,常用来求解\(ax + by = gcd(a,b)\)的可行解问题 推导过程: 考虑我们有: \(ax + by = gc ...
- Nginx03 虚拟主机
1 虚拟主机 虚拟主机使用特殊的软硬件技术,把一台运行在因特网上的服务器主机分成一台台"虚拟"的主机,每一台虚拟主机都具有独立的域名,具有完整的Internet服务器(WWW.FT ...
- STM32F4寄存器初始化系列:三重ADC——DMA
static void ADC_Init(void) { /********************DMA配置**************************/ DMA2_Stream0-> ...
- Mybatis的缓存与动态SQL
Mybatis的缓存 缓存也是为了减少java应用与数据库的交互次数,提升程序的效率 一级缓存 自带一级缓存,并且无法关闭,一直存在,存储在SqlSession中 使用同一个sqlsession进行查 ...
- JavaScript 如何验证 URL
前言 当开发者需要为不同目的以不同形式处理URL时,比如说浏览器历史导航,锚点目标,查询参数等等,我们经常会借助于JavaScript.然而,它的频繁使用促使攻击者利用其漏洞.这种被利用的风险是我们必 ...
- 在wifi的5G频率下无法加载图片解决方法
开始是这样的:因为我家wifi支持300兆的网速,所以换了一个荣耀的路由器,换了一根网线,但是发现5G频率有的应用加载不了图片,所以查了很多资料想了很多办法,终于解决了, 解决方法如下: 1.这是DH ...
- 跳板攻击之:MSF portfwd 端口转发与端口映射
跳板攻击之:MSF portfwd 端口转发与端口映射 郑重声明: 本笔记编写目的只用于安全知识提升,并与更多人共享安全知识,切勿使用笔记中的技术进行违法活动,利用笔记中的技术造成的后果与作者本人无关 ...
- LeetCode-442 数组中重复的数据
来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/find-all-duplicates-in-an-array 题目描述 给你一个长度为 n 的整 ...
- Vitis-AI之docker指南
由于网络原因,有时候进入docker官网时候很卡,故摘录一部分安装要点,供自己查阅参考 docker安装原文链接:https://docs.docker.com/engine/install/ubun ...
- 自我生啃 AMBA AXI 总线笔记
视频1:https://www.youtube.com/watch?v=1zw1HBsjDH8&list=PLkqJVNOiuuHtNrVaNK4O1BSgczja4obeW (What is ...