python基础-模块
一、模块介绍
Python Module(模块),就是一个保存了Python代码的文件。模块能定义函数,类和变量。模块里也能包含可执行的代码。
文件名就是模块名加上后缀.py,在模块内部,模块名存储在全局变量__name__中,是一个string,可以直接在module中通过__name__引用到module name。
模块分为三种:
自定义模块
内置标准模块(又称标准库)
开源模块
导入模块:
import: 使客户端(导入者)以一个整体获取一个模块。
from:容许客户端从一个模块文件中获取特定的变量名。
reload:在不中止Python程序的情况下,提供了一个重新载入模块文件代码的方法。
导入模块方法:
- 语法:
- import module
- from module.xx.xx import xx
- from module.xx.xx import xx as rename
- from module.xx.xx import * #一般不推荐使用
- 示例:
- 推荐方法一:
- import cal #当前目录直接调用模块
- from my_module import cal #二层目录调用模块
- from web1,web2,web3 import cal #多层目录调用模块
- 推荐方法二:
- from web1,web2,web3.cal import add
- 注意:不支持的调用方式
- from web1.web2 import web3 #执行__init__文件,唯一不支持的调用方式
- print(web3.cal.add(2,6))
模块路径:
- #获取路径
- import sys
- for i in sys.path:
- print(i)
- #输出结果:
- S:\Myproject
- S:\Python 3.5.1\python35.zip
- S:\Python 3.5.1\DLLs
- S:\Python 3.5.1\lib #存放标准库
- S:\Python 3.5.1
- S:\Python 3.5.1\lib\site-packages #存放第三方库,扩充库
- #添加路径
- 15 import os
- 16 pre_path = os.path.abspath('../') #当前路径
- import sys
- sys.path.append(pre_path) #添加环境变量,临时生效
- 19 环境变量:永久生效方法:我的电脑--->系统属性--->环境变量--->Path路径中添加,以";" 分割。
开源模块:
- #先安装 gcc 编译和 python 开发环境
- yum install gcc
- yum install python-devel
- 或
- apt-get python-dev
- #安装方式(安装成功后,模块会自动安装到 sys.path 中的某个目录中)
- yum
- pip
- apt-get
- ...
- #进入python环境,导入模块检查是否安装成功
二、包(package)的概念
我们先设想一下,如果不同的人编写的模块名相同怎么办?为了避免冲突,Python又引进了按目录
来组织模块的方法,称为包(package)。
假设,如下图,我的两个time_file.py模块名字重名了,但是这两个模块的功能都不相同,如果这两个模块都在同一级目录中,那么我在其他地方要调用这个time_file.py模块,那么这个时候就会发生冲突,在这里我们就可以通过包来组织模块,避免冲突,
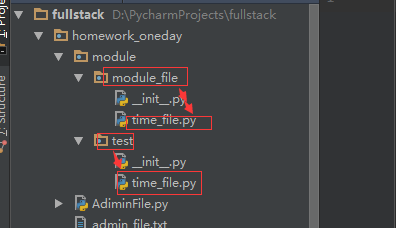
方法是:选择一个顶层包名,引入包以后,只要顶层的包名不与别人冲突,那这个包里面的模块都不会与别人冲突了。
请注意:每个包目录下来都会有一个__init__.py的文件,这个文件必须是存在的,否则,Python就不把这个目录当成普通目录,而不是一个包,__init__.py可以是空文件,也可以有python代码,__init__.py本身就是一个文件,它的模块命就是对应的包名,它一般由于做接口文件。
三、time模块
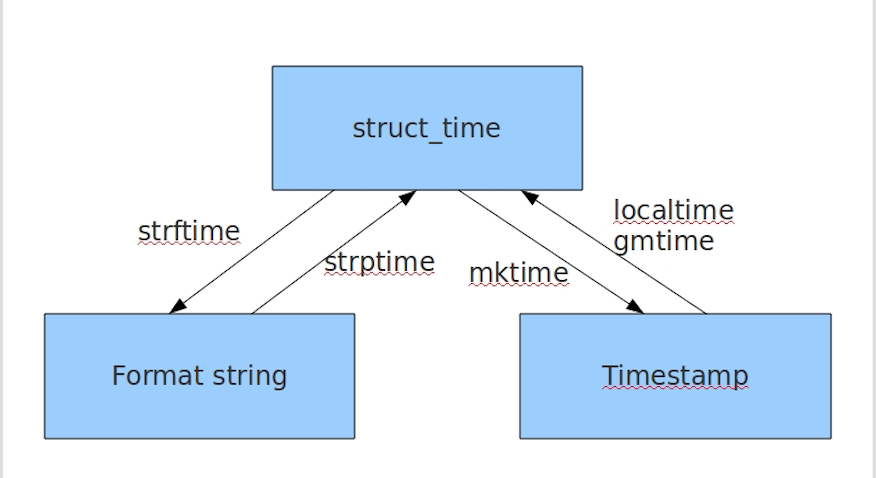
- 时间相关的操作,时间有三种表示方式:
- 时间戳 1970年1月1日之后的秒,即:time.time()
- 格式化的字符串 2016-12-12 10:10, 即:time.strftime('%Y-%m-%d')
- 结构化时间 元组 即:time.struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时) 即:time.localtime()
- import time
- # 1 time() :返回当前时间的时间戳
- time.time() #1473525444.037215
- #----------------------------------------------------------
- # 2 localtime([secs])
- # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
- time.localtime() #time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0,
- # tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0)
- time.localtime(1473525444.037215)
- #----------------------------------------------------------
- # 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
- #----------------------------------------------------------
- # 4 mktime(t) : 将一个struct_time转化为时间戳。
- print(time.mktime(time.localtime()))#1473525749.0
- #----------------------------------------------------------
- # 5 asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
- # 如果没有参数,将会将time.localtime()作为参数传入。
- print(time.asctime())#Sun Sep 11 00:43:43 2016
- #----------------------------------------------------------
- # 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
- # None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
- print(time.ctime()) # Sun Sep 11 00:46:38 2016
- print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
- # 7 strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和
- # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
- # 元素越界,ValueError的错误将会被抛出。
- print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56
- # 8 time.strptime(string[, format])
- # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
- print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
- #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
- # tm_wday=3, tm_yday=125, tm_isdst=-1)
- #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
- # 9 sleep(secs)
- # 线程推迟指定的时间运行,单位为秒。
- # 10 clock()
- # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。
- # 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行
- # 时间,即两次时间差。

示例:
- import time
- print(time.time()) #1481556467.5820887 返回当前系统时间戳(1970年1月1日0时0分0秒开始)
- print(time.localtime()) #将时间戳转换为struct_time格式,返回本地时间
- #time.struct_time(tm_year=2016, tm_mon=12, tm_mday=12, tm_hour=23, tm_min=27, tm_sec=47, tm_wday=0, tm_yday=347, tm_isdst=0)
- print(time.gmtime()) #将时间戳转换为struct_time格式
- #time.struct_time(tm_year=2016, tm_mon=12, tm_mday=12, tm_hour=15, tm_min=27, tm_sec=47, tm_wday=0, tm_yday=347, tm_isdst=0)
- print(time.mktime(time.localtime())) #1481556446.0 与time.localtime()功能相反,将struct_time格式转回成时间戳格式
- print(time.asctime()) #Mon Dec 12 23:26:24 2016
- print(time.ctime()) #Mon Dec 12 23:26:24 2016
- print(time.ctime(time.time())) #Mon Dec 12 23:26:24 2016
- print(time.strftime("%Y-%m-%d %X",time.localtime())) #2016-12-12 23:26:24
- print(time.strptime('2016-12-12 18:25:30','%Y-%m-%d %X')) #将字符串格式转换成struct_time格式
- #time.struct_time(tm_year=2016, tm_mon=12, tm_mday=12, tm_hour=18, tm_min=25, tm_sec=30, tm_wday=0, tm_yday=347, tm_isdst=-1)
- #time.sleep(3) #sleep停顿3分钟
查看帮助示例:
- import time
- help(time)
- Help on built-in module time:
- NAME
- time - This module provides various functions to manipulate time values.
- Commonly used format codes:
- %Y Year with century as a decimal number.
- %m Month as a decimal number [01,12].
- %d Day of the month as a decimal number [01,31].
- %H Hour (24-hour clock) as a decimal number [00,23].
- %M Minute as a decimal number [00,59].
- %S Second as a decimal number [00,61].
- %z Time zone offset from UTC.
- %a Locale's abbreviated weekday name.
- %A Locale's full weekday name.
- %b Locale's abbreviated month name.
- %B Locale's full month name.
- %c Locale's appropriate date and time representation.
- %I Hour (12-hour clock) as a decimal number [01,12].
- %p Locale's equivalent of either AM or PM.
- import time
- help(time.asctime)
- Help on built-in function asctime in module time:
- asctime(...)
- asctime([tuple]) -> string
- Convert a time tuple to a string, e.g. 'Sat Jun 06 16:26:11 1998'.
- When the time tuple is not present, current time as returned by localtime()
- is used.
四、random 模块
随机数:
- import random
- print(random.random()) #用于生成一个0到1的随机符点数: 0 <= n < 1.0
- print(random.randint(1,2)) #用于生成一个指定范围内的整数
- print(random.randrange(1,10)) #从指定范围内,按指定基数递增的集合中获取一个随机数
- print(random.uniform(1,10)) #用于生成一个指定范围内的随机符点数
- print(random.choice('nick')) #从序列中获取一个随机元素
- li = ['nick','jenny','car',]
- random.shuffle(li) #用于将一个列表中的元素打乱
- print(li)
- li_new = random.sample(li,2) #从指定序列中随机获取指定长度的片断(从li中随机获取2个元素,作为一个片断返回)
- print(li_new)
验证码:
- #!/usr/bin/env python
- # -*- coding:utf-8 -*-
- #Author: nulige
- import random
- def v_code():
- code = ''
- for i in range(6): #生成随机6位长度验证码,通过这里控制
- num=random.randint(0,9)
- alf=chr(random.randint(65,90))
- add=random.choice([num,alf])
- code += str(add)
- return code
- print(v_code())
执行结果:
- GAHTAR #随机生成验证码(每次运行都不一样)
五、os模块
os模块是与操作系统交互的一个接口
- os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
- os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
- os.curdir 返回当前目录: ('.')
- os.pardir 获取当前目录的父目录字符串名:('..')
- os.makedirs('dirname1/dirname2') 可生成多层递归目录
- os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
- os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
- os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
- os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
- os.remove() 删除一个文件
- os.rename("oldname","newname") 重命名文件/目录
- os.stat('path/filename') 获取文件/目录信息
- os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
- os.linesep 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
- os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
- os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
- os.system("bash command") 运行shell命令,直接显示
- os.environ 获取系统环境变量
- os.path.abspath(path) 返回path规范化的绝对路径
- os.path.split(path) 将path分割成目录和文件名二元组返回
- os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
- os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
- os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
- os.path.isabs(path) 如果path是绝对路径,返回True
- os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
- os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
- os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
- os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
- os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
示例:
ps1: getcwd 获取当前工作目录 ,chdir("..") 改变当前脚本工作目录
- import os
- print(os.getcwd()) #获取当前工作目录
- os.chdir("..") #改变当前脚本工作目录,相当于shell下cd
- print(os.getcwd())
执行结果:
- D:\python\day13
- D:\python
ps2: makedirs 递归创建空目录
- import os
- os.makedirs('dirname1/dirname2') #创建两层空目录
ps3: removedirs 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
- import os
- os.removedirs("dirname1/dirname2")
ps4: listdir 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
- import os
- print(os.listdir()) #显示当前目录下所有内容
ps5: stat 获取文件/目录信息
stat 结构:
- st_mode: inode 保护模式
- st_ino: inode节点号。
- st_dev: inode驻留的设备。
- st_nlink: inode 的链接数。
- st_uid: 所有者的用户ID。
- st_gid: 所有者的组ID。
- st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
- st_atime: 上次访问的时间。
- st_mtime: 最后一次修改的时间。
- st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
- import os
- print(os.stat("json_s1.py"))
执行结果:
- os.stat_result(st_mode=33206, st_ino=8162774324611606, st_dev=1753083748, st_nlink=1, st_uid=0, st_gid=0, st_size=464, st_atime=1481615313, st_mtime=1481615313, st_ctime=1481610945)
ps6: os.system(("dir")) 显示目录和文件
- import os
- print(os.system("dir")) #显示目录和文件
执行结果:
- Volume in drive D is SSD
- Volume Serial Number is 687D-EF64
- Directory of D:\python\test
- 2016/12/27 15:39 <DIR> .
- 2016/12/27 15:39 <DIR> ..
- 2016/12/01 20:50 563 for.py
- 2016/12/09 08:20 21,892 haproxy01.py
- 2016/12/09 08:27 8,112 haproxy02.py
- 2016/12/24 23:10 16 hello
- 2016/12/27 15:39 258 os_module.py
- 2016/12/23 09:53 381 s1.py
- 2016/12/06 15:01 969 s2.py
- 2016/12/22 10:08 149 s4.py
- 2016/12/24 23:16 699 s5.py
- 2016/12/27 14:59 348 s6.py
- 2016/12/27 15:33 308 sys_module.py
- 2016/12/09 13:14 2,631 test.txt
- 12 File(s) 36,326 bytes
- 2 Dir(s) 639,014,264,832 bytes free
ps7: os.path.split 将文件分割成目录和文件名
- import os
- print(os.path.split(r"C:\Users\Administrator\脱产三期\day22\sss.py")) #将path分割成目录和文件名
执行结果:
- ('C:\\Users\\Administrator\\脱产三期\\day22', 'sss.py')
ps8: os.path.dirname 返回path的目录,加了r转义
- import os
- print(os.path.dirname(r"C:\Users\Administrator\脱产三期\day22\sss.py")) #返回path的目录。其实就是os.path.split(path)的第一个元素
执行结果:
- C:\Users\Administrator\脱产三期\day22
ps9: 文件路径的综合应用
- print(__file__) #获取当前文件路径的文件名
- 结果:D:/python/test/os_module.py
- print(os.path.dirname(__file__)) #返回上一层目录
- 结果:D:/python/test
- print(os.path.abspath(__file__)) #返回他的绝对路径
- 结果:D:\python\test\os_module.py
- print(os.path.split(os.path.abspath(__file__))) #将path分割成目录和文件名
- 结果:('D:\\python\\test', 'os_module.py')
- print(os.path.dirname(os.path.abspath(__file__))) #返回当前文件的上一层目录
- 结果:D:\python\test
- print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) #返回上二层的目录
- 结果:D:\python
ps10: ps.path.hasename 返回path最后的文件名
- import os
- print(os.path.basename(r"C:\Users\Administrator\脱产三期\day22\sss.py")) #返回path最后的文件名。
执行结果:
- sss.py
ps11: os.path.join 路径拼接
ps1:
- import os
- a="D:\python\day13"
- b="pickle_s1.py"
- os.path.join(a,b)# 路径拼接
执行结果:
- C:\Python3.5\python.exe D:/python/day13/os_test.py
ps2: os.path.join 路径和文件名拼接
- print(os.path.join("d:\\"))
- print(os.path.join("d:\\","www","baidu","test.py"))
执行结果:
- d:\www\baidu\test.py
ps3: \test\bb\123.txt os.path.join拼接出这个路径
- print(os.path.join(os.path.dirname(os.path.abspath(__file__)),"bb","123.txt"))
执行结果:
- D:\python\test\bb\123.txt #拼接出来的结果
六、sys模块
- sys.argv 命令行参数List,第一个元素是程序本身路径
- sys.exit(n) 退出程序,正常退出时exit(0)
- sys.version 获取Python解释程序的版本信息
- sys.maxint 最大的Int值
- sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- sys.platform 返回操作系统平台名称
1、sys.argv
- import sys,os
- li = sys.argv
- if li[1] == "post":
- print("post")
- elif li[1] == "down":
- print("")
需在终端执行,才能返回结果:
- #用cd进入到python目录
- D:\python\test>python sys_module.py post
- post #返回的结果
- D:\python\test>python sys_module.py down
- 11111 #返回的结果
2、sys.path
- import sys print(sys.path)
- ps2:
- for i in sys.path:
- print(i)
执行结果:
- ['D:\\python\\test', 'D:\\python', 'C:\\Python3.5\\python35.zip', 'C:\\Python3.5\\DLLs', 'C:\\Python3.5\\lib', 'C:\\Python3.5', 'C:\\Python3.5\\lib\\site-packages']
- D:\python\test
- D:\python
- C:\Python3.5\python35.zip
- C:\Python3.5\DLLs
- C:\Python3.5\lib
- C:\Python3.5
- C:\Python3.5\lib\site-packages
3、sys.version
- print(sys.version)
执行结果:
- 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:01:18) [MSC v.1900 32 bit (Intel)]
4、进度条
- import sys,time
- for i in range(10):
- sys.stdout.write('#')
- time.sleep(1)
- sys.stdout.flush()
七、json & pickle(* * * *)
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存 到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到它们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
示例:
ps1: 把一个字典,写入到文件中
- dic = '{"name": "alex"}'
- f = open("hello", "w")
- f.write(dic)
执行结果:
会生成一个hello文件
- {"name": "alex"}
ps2: 读取文件方法,把字典转成字符串
- f_read=open("hello","r") #读取文件
- data=f_read.read()
- print(type(data))
- data=eval(data) #字典转成字符串(eval的使用方法)
- print(data["name"])
执行结果:
- <class 'str'>
- alex
json模块方法:
ps1: 把字典转换成json形式的字符串写入文件中 (两种方法效果一样,只是写法不同而已)
方法一:推荐用这种方法
- #1、把字典转换成json形式的字符串写入文件中
- import json
- dic = {'name': 'alex'}
- dic = json.dumps(dic)
- f = open("hello", "w")
- f.write(dic)
方法二:
- import json
- dic = {'name': 'alex'}
- f = open("hello", "w")
- dic = json.dump(dic, f)
执行结果:
会生成一个hello的文件,并写入内容:
- {"name": "alex"}
#----------------json------------------序列化(重点,必须掌握)
ps2: 把文件中json类型的字符串读取出来转换成字典
方法一:推荐用这种方法
- #把文件中json类型的字符串读取出来转换成字典
- import json
- f = open('hello','r')
- f = json.loads(f.read())
- print(f)
- print(type(f))
方法二:
- import json
- f = open('hello','r')
- f = json.load(f) #不常用这种方法
- print(f)
- print(type(f))
执行结果:
- {'name': 'alex'}
- <class 'dict'> #查看类型
注意知识点:
示例一:
- import json
- #dct="{'1':111}"#json 不认单引号
- #dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
- dct='{"1":"111"}'
- print(json.loads(dct))
- #conclusion:
- # 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
示例二:
先创建一个json_test文件,写入内容
- {"name":"alvin"} #只要符合json规范就可以把值取出来。 另一种示例:{'name':"alvin"} #如果是'name' 的值是单引号就会报错。
再去取值
- import json
- with open("Json_test","r") as f: #双引号可以直接把值取出来
- data=f.read()
- data=json.loads(data)
- print(data["name"])
执行结果:
- alvin
json的dumps,loads,dump,load功能总结:
json.dumps(x) 把python的(x)原对象转换成json字符串的对象,主要用来写入文件。
json.loads(f) 把json字符串(f)对象转换成python原对象,主要用来读取文件和json字符串
json.dump(x,f) 把python的(x)原对象,f是文件对象,写入到f文件里面,主要用来写入文件的
json.load(file) 把json字符串的文件对象,转换成python的原对象,只是读文件
pickle模块:(不常用这个模块)
#---------------pickle---------------序列化
ps1: pickle转换后的结果是bytes(字节)
- import pickle
- dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
- print(type(dic)) # <class 'dict'>
- j = pickle.dumps(dic)
- print(type(j)) # <class 'bytes'>
执行结果:
- <class 'dict'> #字典类型
- <class 'bytes'> #bytes类型
ps2:
- import pickle
- dic = {'name': 'alvin', 'age': 23, 'sex': 'male'}
- j = pickle.dumps(dic)
- f = open('序列化对象_pickle', 'wb') #注意是w是写入str,wb是写入bytes,j是'bytes'
- f.write(j) #等价于pickle.dump(dic,f)
- f.close()
执行结果:
生成一个序列化对象_pickle文件,文件内容如下:
- �}q (X ageqKX sexqX maleqX nameqX alvinqu. #生成一个不可读的文件,但计算机可以解析出来
ps3: 反序列化
- import pickle
- f = open('序列化对象_pickle', 'rb')
- data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
- print(data['age'])
执行结果:
- 23 #读出里面的结果
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
八、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
ps1:
- #添加键值对到文件中,会生成三个文件,并写入字典内容
- import shelve
- f = shelve.open(r'shelve1') # 目的:将一个字典放入文本 f={}
- f['stu1_info']={'name':'alex','age':''}
- f['stu2_info']={'name':'alvin','age':''}
- f['school_info']={'website':'oldboyedu.com','city':'beijing'}
- f.close()
执行结果:
会生成三个文件:shelvel.dat,shelve1.dir,shelve1.bak,其中shelvel.bak中内容如下:
- 'stu1_info', (0, 49) #生成只有计算机能识别的语言
- 'stu2_info', (512, 50)
- 'school_info', (1024, 67)
ps2:取出age的值
- import shelve
- f = shelve.open(r'shelve1')
- print(f.get('stu1_info')['age']) #取出age的值
- print(f.get('stu2_info')['age'])
执行结果:
- 18
- 20
九、xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
- <?xml version="1.0"?>
- <data> #根
- <country name="Liechtenstein"> #节点
- <rank updated="yes">2</rank>
- <year>2008</year>
- <gdppc>141100</gdppc>
- <neighbor name="Austria" direction="E"/>
- <neighbor name="Switzerland" direction="W"/>
- </country>
- <country name="Singapore"> #节点
- <rank updated="yes">5</rank>
- <year>2011</year>
- <gdppc>59900</gdppc>
- <neighbor name="Malaysia" direction="N"/>
- </country>
- <country name="Panama"> #节点
- <rank updated="yes">69</rank>
- <year>2011</year>
- <gdppc>13600</gdppc>
- <neighbor name="Costa Rica" direction="W"/>
- <neighbor name="Colombia" direction="E"/>
- </country>
- </data>
- xml数据
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
- import xml.etree.ElementTree as ET
- tree = ET.parse("xmltest.xml")
- root = tree.getroot()
- print(root.tag)
- #遍历xml文档
- for child in root:
- print(child.tag, child.attrib)
- for i in child:
- print(i.tag,i.text)
- #只遍历year 节点
- for node in root.iter('year'):
- print(node.tag,node.text)
- #执行结果:
year 2008
year 2011
year 2011- #---------------------------------------
- import xml.etree.ElementTree as ET
- tree = ET.parse("xmltest.xml")
- root = tree.getroot()
- #修改
- for node in root.iter('year'):
- new_year = int(node.text) + 1 #2008+1=2009
- node.text = str(new_year)
- node.set("updated","yes") #修改通过set,加个属性yes
- tree.write("xmltest.xml")
- 31 #执行结果:
会生成一个新的xmltest.xml文件,内容中会添加
<year updated="yes">2009</year> #年份+1,加个yes属性- #删除node
- for country in root.findall('country'): #通过对country进行遍历
- rank = int(country.find('rank').text) #再用find找到rank
- if rank > 50: #再判断>50的值
- root.remove(country) #再用remove删除
- tree.write('output.xml') #写到一个新文件中
- #执行结果:
自己创建xml文档:
- import xml.etree.ElementTree as ET #as后面的ET是前面的类的别名,名称随便取
- new_xml = ET.Element("namelist")
- name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
- age = ET.SubElement(name,"age",attrib={"checked":"no"})
- sex = ET.SubElement(name,"sex")
- sex.text = ''
- name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
- age = ET.SubElement(name2,"age")
- age.text = ''
- et = ET.ElementTree(new_xml) #生成文档对象 (记住重点)
- et.write("test.xml", encoding="utf-8",xml_declaration=True) (记住重点)
- ET.dump(new_xml) #打印生成的格式
- 创建xml文档
执行结果:
会生成一个test.xml的文件,文件内容如下:
- <?xml version='1.0' encoding='utf-8'?>
- <namelist>
- <name enrolled="yes">
- <age checked="no" />
- <sex>33</sex>
- </name>
- <name enrolled="no">
- <age>19</age>
- </name>
- </namelist>
十、configparser 模块
configparser 模块作用: 用来读写配置文件。
一、常见文档格式如下:
1、先新建一个名字为confile文件,写入下面内容:
- [DEFAULT]
- ServerAliveInterval = 45
- Compression = yes
- CompressionLevel = 9
- ForwardX11 = yes
- [bitbucket.org]
- User = hg
- [topsecret.server.com]
- Port = 50022
- ForwardX11 = no
示例1: 写入一个文件
- import configparser
- config = configparser.ConfigParser() #config={}
- config["DEFAULT"] = {'ServerAliveInterval': '',
- 'Compression': 'yes',
- 'CompressionLevel': ''}
- with open('example1.ini', 'w') as f:
- config.write(f)
执行结果:
- #会生成example1.ini文件,内容如下:
- [DEFAULT]
- compressionlevel = 9
- compression = yes
- serveraliveinterval = 45
示例2: 生成多个键值对
- import configparser
- config = configparser.ConfigParser() #config={}
- config["DEFAULT"] = {'ServerAliveInterval': '',
- 'Compression': 'yes',
- 'CompressionLevel': ''}
- config['bitbucket.org'] = {}
- config['bitbucket.org']['User'] = 'hg'
- config['topsecret.server.com'] = {}
- topsecret = config['topsecret.server.com']
- topsecret['Host Port'] = '' # mutates the parser
- topsecret['ForwardX11'] = 'no' # same here
- with open('example1.ini', 'w') as f:
- config.write(f)
执行结果:
- #会生成example1.ini文件,内容如下:
- [DEFAULT]
- compression = yes
- compressionlevel = 9
- serveraliveinterval = 45
- [bitbucket.org]
- user = hg
- [topsecret.server.com]
- host port = 50022
- forwardx11 = no
#-----------------------------------查询功能-------------------------------#
示例3: 实现查询功能
#查出键中user对应的值
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini') #先把文件读进来
- print(config['bitbucket.org']['User']) #取出user的值
- print(config['DEFAULT']['Compression']) #Compression的值
- print(config['topsecret.server.com']['ForwardX11']) #ForwardX11的值
执行结果:
- hg
- yes
- no
示例4:取的是bitbucket.org键的值,他会把DEFAULT的一起打印出来
DEFAULT的特殊功能:因为只要带DEFAULT键值对的,他就会把DEFAULT的键打印出来
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini')
- for key in config['bitbucket.org']: #取的是bitbucket.org的值,他会把DEFAULT的一起打印出来
- print(key)
执行结果:
- user
- compression
- compressionlevel
- serveraliveinterval
示例5:
取的是bitbucket.org键的值,以列表的方式打印出来
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini')
- print(config.options('bitbucket.org'))
执行结果:
- ['user', 'compression', 'compressionlevel', 'serveraliveinterval']
示例6:
取的是bitbucket.org键和值,以元组的方式打印出来
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini')
- print(config.items('bitbucket.org'))
执行结果:
- [('compression', 'yes'), ('compressionlevel', ''), ('serveraliveinterval', ''), ('user', 'hg')]
示例7:
连续取值,取出compression的值
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini')
- print(config.get('bitbucket.org','compression')) #取出compression的值
执行结果:
- yes #=====>取出的compression的值 yes
#-------------------------------------增加功能----------------------------------#
实现:在example1.txt文件中读取原来块的内容,增加一个新的块
1、首先必须有一个example1.txt文件,里面内容为:
- [DEFAULT]
- serveraliveinterval = 45
- compression = yes
- compressionlevel = 9
- [bitbucket.org]
- user = hg
- [topsecret.server.com]
- host port = 50022
- forwardx11 = no
2、增加一个块和键值对
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini') #从这里面拿到三个对象
- config.add_section('yuan') #再新增加一个块
- config.set('yuan','k1','') #给键添加键值对
- config.write(open('1.cfg', "w")) #创建一个新文件
执行结果:
- [DEFAULT]
- serveraliveinterval = 45
- compression = yes
- compressionlevel = 9
- [bitbucket.org]
- user = hg
- [topsecret.server.com]
- host port = 50022
- forwardx11 = no
- [yuan] #这就是新增加的块
- k1 = 11111
#-------------------------------------删除功能----------------------------------#
示例1:
1、首先必须有一个example1.txt文件,里面内容为:
- [DEFAULT]
- serveraliveinterval = 45
- compression = yes
- compressionlevel = 9
- [bitbucket.org]
- user = hg
- [topsecret.server.com]
- host port = 50022
- forwardx11 = no
- [yuan] #这就是新增加的块
- k1 = 11111
2、删除块和键值对的值
- import configparser
- config = configparser.ConfigParser()
- config.read('example1.ini') #从这里面拿到三个对象
- config.remove_section('topsecret.server.com') #删除块和键值对的值
- config.remove_option('bitbucket.org','user')
- config.write(open('1.cfg', "w")) #创建一个新文件
执行结果:
- [DEFAULT]
- serveraliveinterval = 45
- compression = yes
- compressionlevel = 9
- [bitbucket.org]
十一、logging模块
一、logging模块
示例1:
- import logging
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
执行结果: (默认是WARNING级别,所以只显示三条信息)
- WARNING:root:warning message
- ERROR:root:error message
- CRITICAL:root:critical message
日志级别:一般info就够用
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING
日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET(从高到低),默认的日志格式为日志级别:Logger名称:用户输出消息。
示例2: 设置参数,调日志级别。调整为DEBUG级别,显示5条信息
- import logging
- logging.basicConfig(
- level=logging.DEBUG
- )
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
执行结果: 显示5条信息
- DEBUG:root:debug message
- INFO:root:info message
- WARNING:root:warning message
- ERROR:root:error message
- CRITICAL:root:critical message
示例3: 设置filename把日志写入到文件中,并参过加w参数,控制他每次只写5条,不重复的记录
- import logging
- logging.basicConfig(
- level=logging.DEBUG, #默认信息显示在屏幕上面
- filename="logger.log", #通过加filename参数,以追加的方式,把日志信息写入到文件中,每次重复运行都会往里面写5条记录
- filemode="w", #通过加w参数,就可以控制他,每次只写5条记录。不会重复往里写相同记录
- )
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
执行结果:
- 会创建一个logger.log日志,并写入五条记录
- DEBUG:root:debug message
- INFO:root:info message
- WARNING:root:warning message
- ERROR:root:error message
- CRITICAL:root:critical message
示例4: 给logging加上参数,显示时间,行号等信息。
- import logging
- logging.basicConfig(
- level=logging.DEBUG, #默认信息显示在屏幕上面
- filename="logger.log", #通过加filename参数,以追加的方式,把日志信息写入到文件中,每次重复运行都会往里面写5条记录
- filemode="w", #通过加w参数,就可以控制他,每次只写5条记录。不会重复往里写相同记录
- # format="%(asctime)s", #加上时间
- format="%(asctime)s %(filename)s[%(lineno)d] %(message)s" #asctime 时间,lineno 行号,message 信息,还可以加其它信息参数
- )
- logging.debug('debug message')
- logging.info('info message')
- logging.warning('warning message')
- logging.error('error message')
- logging.critical('critical message')
执行结果:
- 会创建一个logger.log日志,并写入五条记录
- 2016-12-15 14:10:33,615 logging_s1.py[15] debug message
- 2016-12-15 14:10:33,616 logging_s1.py[16] info message
- 2016-12-15 14:10:33,616 logging_s1.py[17] warning message
- 2016-12-15 14:10:33,616 logging_s1.py[18] error message
- 2016-12-15 14:10:33,617 logging_s1.py[19] critical message
可见在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
二、logger对象(自定义日志格式,经常用的一种方法) 重点掌握
上述几个例子中我们了解到了logging.debug()、logging.info()、logging.warning()、logging.error()、logging.critical()(分别用以记录不同级别的日志信息),logging.basicConfig()(用默认日志格式
(Formatter)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到root logger(根Logger)中)这几个logging模块级别的函数,另外还有一个模块级别的函数
是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)
原理图:

示例1:
- import logging
- logger=logging.getLogger() #创建一个大对象
- fh=logging.FileHandler("test_log") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- fm=logging.Formatter("%(asctime)s %(message)s") #这个也是一个对象,作用是:定义日志格式
- fh.setFormatter(fm) #往文件里写内容
- ch.setFormatter(fm) #往屏幕上输出内容
- logger.addHandler(fh) #对象,类似于吸别人内力,把fh吃掉
- logger.addHandler(ch) #对象,类似于吸别人内力,把ch吃掉
- logger.debug("debug") #输出日志的级别
- logger.info("info")
- logger.warning("warning")
- logger.error("error")
- logger.critical("critical")
执行结果:
- 会生成一个test_log的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- 2016-12-15 14:38:27,657 warning
- 2016-12-15 14:38:27,658 error
- 2016-12-15 14:38:27,658 critical
- 屏幕输出信息如下:
- 2016-12-15 14:38:27,657 warning
- 2016-12-15 14:38:27,658 error
- 2016-12-15 14:38:27,658 critical
示例2: logger.setLevel("DEBUG") 调整日志级别,控制日志显示信息,DEBUG显示5条记录
- import logging
- logger=logging.getLogger() #创建一个大对象
- fh=logging.FileHandler("test_log") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- fm=logging.Formatter("%(asctime)s %(message)s") #这个也是一个对象,作用是:定义日志格式
- fh.setFormatter(fm) #往文件里写内容
- ch.setFormatter(fm) #往屏幕上输出内容
- logger.addHandler(fh) #对象,类似于吸别人内力,把fh吃掉
- logger.addHandler(ch) #对象,类似于吸别人内力,把ch吃掉
- logger.setLevel("DEBUG") #设置日志级别,控制日志输入多少条信息
- #-------------从这里开始都是在操作log----------------
- logger.debug("debug") #输出日志的级别
- logger.info("info")
- logger.warning("warning")
- logger.error("error")
- logger.critical("critical")
执行结果:
- 会生成一个test_log的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- 2016-12-15 14:54:37,036 debug
- 2016-12-15 14:54:37,037 info
- 2016-12-15 14:54:37,038 warning
- 2016-12-15 14:54:37,038 error
- 2016-12-15 14:54:37,039 critical
- 屏幕输出信息如下:
- 2016-12-15 14:54:37,036 debug
- 2016-12-15 14:54:37,037 info
- 2016-12-15 14:54:37,038 warning
- 2016-12-15 14:54:37,038 error
- 2016-12-15 14:54:37,039 critical
示例3: 写成函数的形式,并有返回值
- import logging
- def logger():
- logger=logging.getLogger() #创建一个大对象
- fh=logging.FileHandler("test_log") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- fm=logging.Formatter("%(asctime)s %(message)s") #这个也是一个对象,作用是:定义日志格式
- fh.setFormatter(fm) #往文件里写内容
- ch.setFormatter(fm) #往屏幕上输出内容
- logger.addHandler(fh) #对象,类似于吸别人内力,把fh吃掉
- logger.addHandler(ch) #对象,类似于吸别人内力,把ch吃掉
- logger.setLevel("DEBUG") #设置日志级别,控制日志输入多少条信息
- return logger
- #-------------从这里开始都是在操作log----------------
- logger=logger() #这个日志就做成了一个接口,想在其它地方使用,直接调用他就可以啦!
- logger.debug("debug") #输出日志的级别
- logger.info("info")
- logger.warning("warning")
- logger.error("error")
- logger.critical("critical")
执行结果:
- 会生成一个test_log的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- 2016-12-15 14:54:37,036 debug
- 2016-12-15 14:54:37,037 info
- 2016-12-15 14:54:37,038 warning
- 2016-12-15 14:54:37,038 error
- 2016-12-15 14:54:37,039 critical
- 屏幕输出信息如下:
- 2016-12-15 14:54:37,036 debug
- 2016-12-15 14:54:37,037 info
- 2016-12-15 14:54:37,038 warning
- 2016-12-15 14:54:37,038 error
- 2016-12-15 14:54:37,039 critical
示例4: 只在屏幕文件中写入日志,不在屏幕上面显示
- import logging
- def logger():
- logger=logging.getLogger() #创建一个大对象
- fh=logging.FileHandler("test_log") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- #ch=logging.StreamHandler() #向屏幕上发送内容
- fm=logging.Formatter("%(asctime)s %(message)s") #这个也是一个对象,作用是:定义日志格式
- fh.setFormatter(fm) #往文件里写内容
- #ch.setFormatter(fm) #往屏幕上输出内容
- logger.addHandler(fh) #对象,类似于吸别人内力,把fh吃掉
- #logger.addHandler(ch) #对象,类似于吸别人内力,把ch吃掉
- logger.setLevel("DEBUG") #设置日志级别,控制日志输入多少条信息
- return logger
- #-------------从这里开始都是在操作log----------------
- logger=logger() #这个日志就做成了一个接口,在其它地方,直接调用他就可以啦!
- logger.debug("debug") #输出日志的级别
- logger.info("info")
- logger.warning("warning")
- logger.error("error")
- logger.critical("critical")
执行结果:
- #会生成一个test_log的文件,同时往里面写入信息,不会在屏幕上面显示信息。
- #文件内容如下:
- 2016-12-15 14:54:37,036 debug
- 2016-12-15 14:54:37,037 info
- 2016-12-15 14:54:37,038 warning
- 2016-12-15 14:54:37,038 error
- 2016-12-15 14:54:37,039 critical
示例5:没有根用户
#如果我们再创建两个logger对象
- import logging
- logger1 = logging.getLogger('mylogger') #默认是根,这里代表他是子用户(两个用户是同级)
- #logger1 = logging.getLogger('mylogger.sontree') #如果mylogger下再创建一个字对象,就用.sontree;等于他就是mylogger的下级对象。
- logger1.setLevel(logging.DEBUG) #第一次是DEBUG级别
- logger2 = logging.getLogger('mylogger') #默认是根,这里代表他是子用户(两个用户是同级)
- logger2.setLevel(logging.INFO) #第二次是INFO级别,覆盖第一次的级别,所以打印结果是INFO级别显示
- fh=logging.FileHandler("test_log-new") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- logger1.addHandler(fh)
- logger1.addHandler(ch)
- logger2.addHandler(fh)
- logger2.addHandler(ch)
执行结果:
- logger1 and logger2各打印4条信息
- 生成一个test_log-new的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- logger1 info message
- logger1 warning message
- logger1 error message
- logger1 critical message
- logger2 info message
- logger2 warning message
- logger2 error message
- logger2 critical message
- #屏幕上面显示的内容
- logger1 info message
- logger1 warning message
- logger1 error message
- logger1 critical message
- logger2 info message
- logger2 warning message
- logger2 error message
- logger2 critical message
示例6:添加根用户 (lgger和mylogger是父子关系) (注意日志输出问题)
- import logging
- logger = logging.getLogger() #根用户(根用户级别,没有定义日志级别,默认warning级别,所以是3条信息
- logger1 = logging.getLogger('mylogger') #默认是根,这里代表他是子用户(两个用户是同级)
- logger1.setLevel(logging.DEBUG) #第一次是DEBUG级别,默认是打印五条信息,但是他打印信息的时候,会先去找父,如果有父,他就会多打印一遍,所以输出是10条信息
- fh=logging.FileHandler("test_log-new") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- logger.addHandler(ch) #添加一个根用户
- logger.addHandler(fh)
- logger1.addHandler(fh) #添加一个子用户
- logger1.addHandler(ch)
- #打印信息
- logger.debug('logger debug message')
- logger.info('logger info message')
- logger.warning('logger warning message')
- logger.error('logger error message')
- logger.critical('logger critical message')
- #打印4条信息
- logger1.debug('logger1 debug message')
- logger1.info('logger1 info message')
- logger1.warning('logger1 warning message')
- logger1.error('logger1 error message')
- logger1.critical('logger1 critical message')
输出结果:
- 生成一个test_log-new的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- logger warning message
- logger error message
- logger critical message #前三条是根输出的三条信息
- logger1 debug message #后10条是子输出的10条信息,为什么会输入10条呢?
- logger1 debug message #第一次是DEBUG级别,默认是打印五条信息,但是他打印信息的时候,会先去找父,如果有父,他就会多打印一遍,所以输出是5+5=10条信息
- logger1 info message
- logger1 info message
- logger1 warning message
- logger1 warning message
- logger1 error message
- logger1 error message
- logger1 critical message
- logger1 critical message
- 屏幕输出内容如下:
- logger warning message
- logger error message
- logger critical message
- logger1 debug message
- logger1 debug message
- logger1 info message
- logger1 info message
- logger1 warning message
- logger1 warning message
- logger1 error message
- logger1 error message
- logger1 critical message
- logger1 critical message
示例7:添加根用户 (控制根用户不输入,只输出子用户信息)
- import logging
- logger = logging.getLogger() #根用户(根用户级别,没有定义日志级别,默认warning级别,所以是3条信息
- logger1 = logging.getLogger('mylogger') #默认是根,这里代表他是子用户(两个用户是同级)
- logger1.setLevel(logging.DEBUG) #第一次是DEBUG级别,默认是打印五条信息,但是他打印信息的时候,会先去找父,如果有父,他就会多打印一遍,所以输出是10条信息
- fh=logging.FileHandler("test_log-new") #向文件里发送内容,并且给个参数,作用是:定义一个文件名,往文件里写入内容
- ch=logging.StreamHandler() #向屏幕上发送内容
- logger1.addHandler(fh) #添加一个子用户
- logger1.addHandler(ch)
- #打印4条信息
- logger1.debug('logger1 debug message')
- logger1.info('logger1 info message')
- logger1.warning('logger1 warning message')
- logger1.error('logger1 error message')
- logger1.critical('logger1 critical message')
执行结果:
- #生成一个test_log-new的文件,同时往里面写入信息,并在屏幕上面显示相同信息。
- 文件内容如下:
- logger1 debug message
- logger1 info message
- logger1 warning message
- logger1 error message
- logger1 critical message
- 屏幕输出内容如下:
- logger1 debug message
- logger1 info message
- logger1 warning message
- logger1 error message
- logger1 critical message
十二、hashlib模块 (摘要算法)
hashlib 明文变成密文,不能反解
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
md5算法 明文变成密文
示例1: md5算法
- import hashlib
- obj=hashlib.md5()
- obj.update("admin".encode("utf8"))
- print(obj.hexdigest())
执行结果:
- 21232f297a57a5a743894a0e4a801fc3 (长度32位)
示例2:
- import hashlib
- #md5加密+字符串,生成密码。就无法破解
- obj=hashlib.md5("sssdsdsb".encode("utf8")) #在md5里面加点字符串,再生成,就没法破解
- obj.update("admin".encode("utf8"))
- print(obj.hexdigest())
执行结果:
- 639cd764cf1bab2bebaa5804e37530e6
示例3:
以上加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
####### 256 位########
- import hashlib
- hash = hashlib.sha256('898oaFs09f'.encode('utf8'))
- hash.update('alvin'.encode('utf8'))
- print(hash.hexdigest())
执行结果:
- e79e68f070cdedcfe63eaf1a2e92c83b4cfb1b5c6bc452d214c1b7e77cdfd1c7
示例4:
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密:
- import hmac
- h = hmac.new('alvin'.encode('utf8'))
- h.update('hello'.encode('utf8'))
- print (h.hexdigest())
执行结果:
- 320df9832eab4c038b6c1d7ed73a5940
python基础-模块的更多相关文章
- python基础——模块
python基础——模块 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- 自学Python之路-Python基础+模块+面向对象+函数
自学Python之路-Python基础+模块+面向对象+函数 自学Python之路[第一回]:初识Python 1.1 自学Python1.1-简介 1.2 自学Python1.2-环境的 ...
- Python基础+模块、异常
date:2018414+2018415 day1+2 一.python基础 #coding=utf-8 #注释 #算数运算 +(加) -(减) *(乘) /(除) //(取整) %(取余) ...
- Python 基础 模块
python 中模块和保定 概念 如果将代码分才投入多个py 文件,好处: 同一个变量名也互不影响. python 模块导入 要使用一个模块,我们必须先导入该模块.python 使用import ...
- python基础----模块、包
一 模块 ...
- Python基础-模块与包
一.如何使用模块 上篇文章已经简单介绍了模块及模块的优点,这里着重整理一下模块的使用细节. 1. import 示例文件:spam.py,文件名spam.py,模块名spam #spam.py pri ...
- Python菜鸟之路:Python基础-模块
什么是模块? 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护.为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,分组的规则就是把实现了某个 ...
- python基础--模块&包
一.模块 1.模块是程序 任何Python程序都可以作为模块导入. 程序的保存也很重要,如果想把程序保存在C:\python (Windows)目录下,需要告诉解释器在哪里寻找模块了. >> ...
- python基础-------模块与包(四)
configparser模块与 subprcess 利用configparser模块配置一个类似于 windows.ini格式的文件可以包含一个或多个节(section),每个节可以有多个参数(键=值 ...
随机推荐
- JS特效之Tab标签切换
在我们平时浏览网站的时候,经常看到的特效有图片轮播.导航子菜单的隐藏.tab标签的切换等等.这段时间学习了JS后,开始要写出一些简单的特效.今天我也分享一个简单tab标签切换的例子.先附上代码: HT ...
- Sanboxie 5.14安装图解
Sanboxie, 即沙盘,引用官方解释:电脑就像一张纸,程序的运行与改动,就像将字写在纸上.而Sandboxie就相当于在纸上放了块玻璃,程序的运行与改动就像写在了那块玻璃上,除去玻璃,纸上还是一点 ...
- 初学HTML 常见的标签(二) 列表标签
上次介绍了一些简单的文本标签设计, 这篇介绍列表类标签, 通过列表能写出很好看的, 多元化的网络页面. ul-li 列表标签 <ul> <li>列表1</li> & ...
- 学习Maven之Maven Enforcer Plugin
1.Maven Enforcer plugin是什么鬼? 在说这个插件是什么前我们先思考这么一个问题:当我们开发人员进入项目组进行开发前,要准备开发环境,而领导总是会强调工具的统一,编译环境的统一.比 ...
- [Unity游戏开发]向量在游戏开发中的应用(二)
本文已同步发表在CSDN:http://blog.csdn.net/wenxin2011/article/details/50972976 在上一篇博客中讲了利用向量方向的性质来解决问题.这篇博客将继 ...
- ORACLE VARCHAR2最大长度问题
VARCHAR2数据类型的最大长度问题,是一个让人迷惑的问题,因为VARCHAR2既分PL/SQL Data Types中的变量类型,也分Oracle Database中的字段类型.简单的说,要看你在 ...
- Linux忘记root密码怎么办?
开篇前言:Linux系统的root账号是非常重要的一个账号,也是权限最大的一个账号,但是有时候忘了root密码怎么办?总不能重装系统吧,这个是下下策,其实Linux系统中,如果忘记了root账号密码, ...
- vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,可对操作系统的虚拟内存.进程.CPU活动进行监控.他是对系统的整体情况进行统计,不足之处是无法对某个进程进行深 ...
- sublime text3的一些插件安装方法和使用
sublime text部分插件使用方法在线安装package Control的方法: ctrl+~ 输入如下代码: import urllib2,os; pf='Package ...
- JQuery日历控件
日历控件最后一弹——JQuery实现,换汤不换药.原理一模一样,换了种实现工具.关于日历的终于写完了,接下来研究研究nodejs.嗯,近期就这点事了. 同样还是将input的id设置成calendar ...