Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算
Pandas 继承了Numpy的功能,也实现了一些高效技巧。
- 对于1元运算,(函数,三角函数)保留索引和列标签
- 对于2元运算,(加法,乘法),Pandas 会自动对齐索引进行计算。
通用函数:保留索引
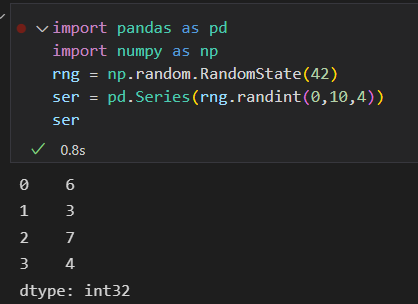
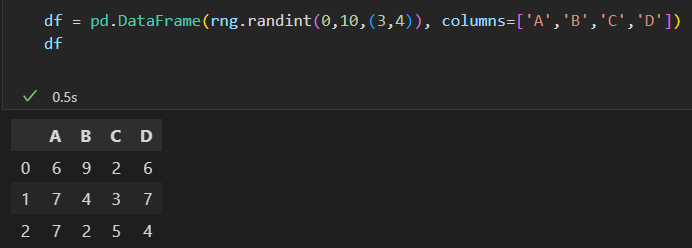
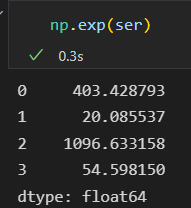
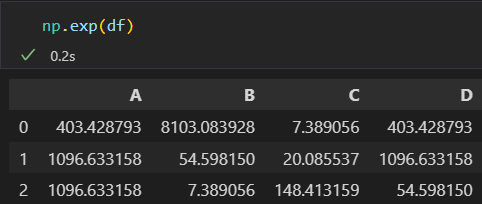
对ser对象或 df对象使用Numpy通用函数,生成的结果是另一个保留索引的Pandas对象。
通用函数: 索引对齐
当Series 或 DataFram对象进行二元计算,会对齐俩个对象的索引
当处理不完整的额数据时,这一点非常方便
Series索引对齐
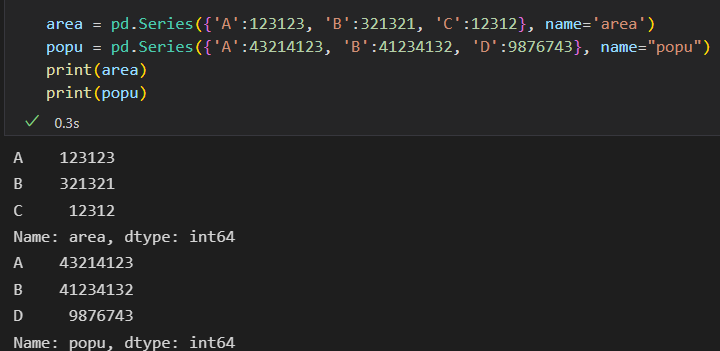
俩个相除
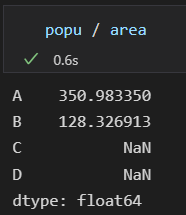
结果数组索引是:俩个输入数组索引的并集,
对于确实位置的数据,Pandas会用NaN填充,表示此处无数。
DataFrame索引对齐
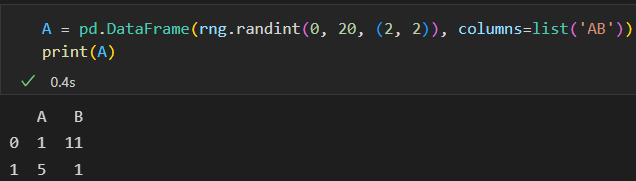
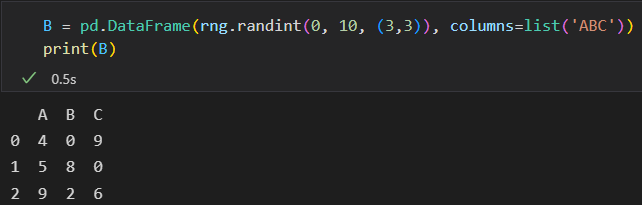
A + B
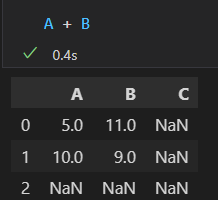
行列索引的顺序可以不同。结果的索引会自动按顺序排列。
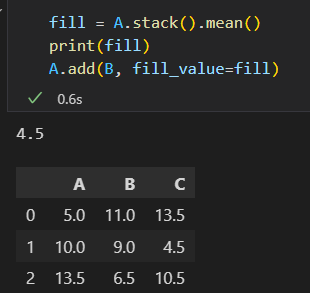
可以通过fill_value 参数自定义缺失值,注意:fill_value填充在A上,然后与B相加,不是运算之后再填fill_value.
DataFrame 与 Series的运算
需要对一个DataFrame和一个Series运算,行列对齐方式与之前类似, 与Numpy 二维数组与一维数组的运算规则是一样的。
广播。
numpy 二维数组和一维数组计算
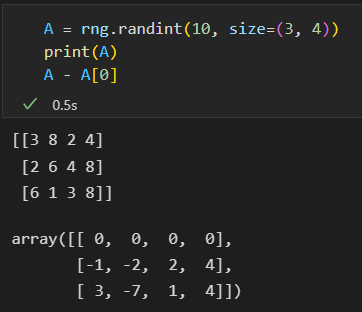
默认按行运算。
Pandas也是默认按行运算
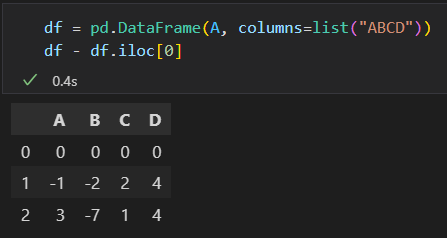
按列计算,使用axis参数。
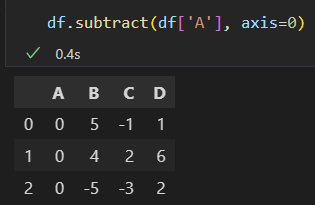
处理缺失值
缺失值三种形式:null NaN NA
识别缺失值的方法:
1)覆盖全局的掩码
2)用一个标签值
Pandas的缺失值
综合考量:Pandas最终选择标签方法表示缺失值。 浮点数据类型的NaN值,以及None对象。
- None: Python对象类型的缺失值
由于None是一个Python对象,所以不能作为任何Numpy/Pandas数组类型的缺失值。
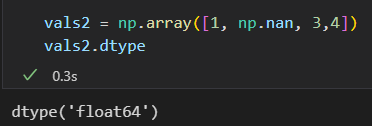
Python中没有定义None和整数之间的加法运算 - NaN:数值类型的缺失值
NaN: not a number. 任何系统中都兼容的特殊浮点数
NaN是一个数据类病毒,会同化和它接触的数据, 进行何种操作,结果都是NaN
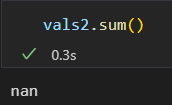
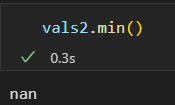
Numpy也提供了特殊的累计函数,可以忽略缺失值的影响
np.nansum() nanmin() nanmax()
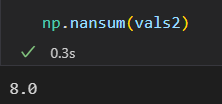
处理缺失值
- 发现缺失值 isnull() notnull()
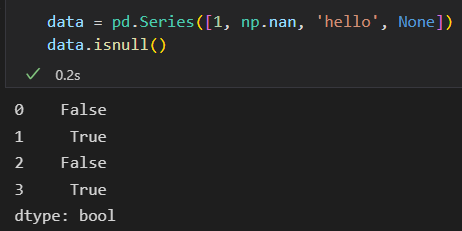
isnull() 创建一个布尔类型的掩码标签 缺失值
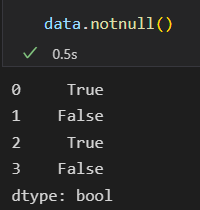
notnull() 与 isnull()相反
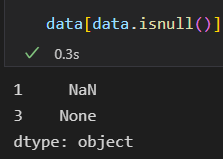
布尔类型掩码数组可以直接作为Series或DataFrame的索引使用
剔除缺失值 dropna()
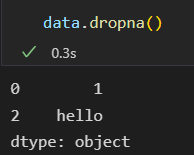
DataFrame 不太一样哦。
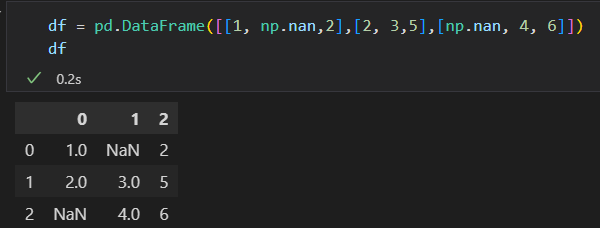
我们没法从datafram单独剔除一个值。要么是整行,要么是整列。
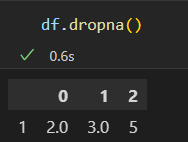
dropna()会剔除任何包含缺失值的整行数据
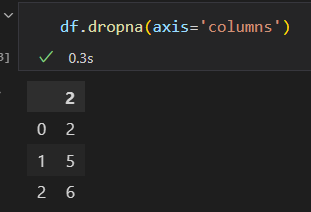
剔除列,axis=1 or axis = 'columns'
行或列全部是缺失值 剔除使用how=any,
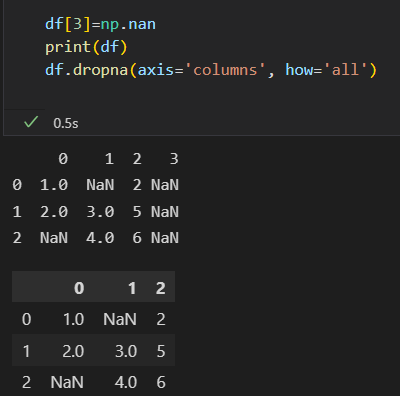
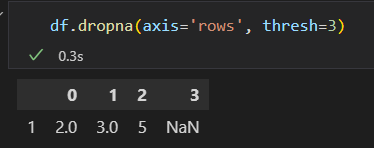
根据缺失值的数量 使用thresh 参数, 行或列中非缺失值的最小数量
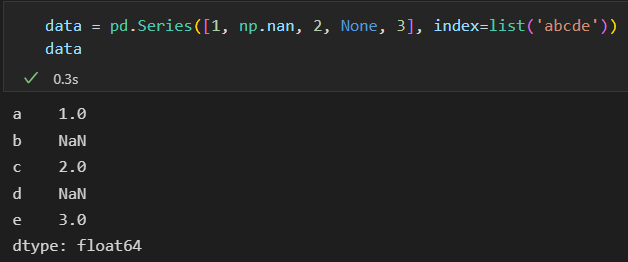
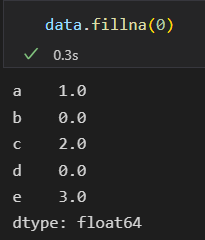
填充缺失值 fillna()
使用0来填充缺失值
从前往后填充
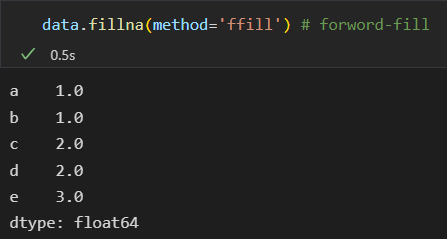
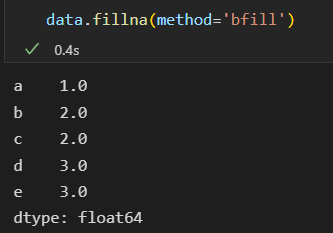
从后往前填充
DataFrame一行。只是需要设置坐标轴参数
axis=1 代表行。
axis=0 代表列。 我去。。。。
Python数据科学手册-Pandas:数值运算方法的更多相关文章
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储. 多维数据:数据索引 超过一俩个 键. Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据. ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
- python书籍推荐:Python数据科学手册
所属网站分类: 资源下载 > python电子书 作者:today 链接:http://www.pythonheidong.com/blog/article/448/ 来源:python黑洞网 ...
随机推荐
- NC202498 货物种类
NC202498 货物种类 题目 题目描述 某电商平台有 \(n\) 个仓库,编号从 \(1\) 到 \(n\) . 当购进某种货物的时候,商家会把货物分散的放在编号相邻的几个仓库中. 我们暂时不考虑 ...
- 服务器与Ajax
前端相关的技术点 HTML 主要用来实现页面的排版布局 CSS 主要用来实现页面的样式美化 JavaScript 主要用来实现前端功能特效 Ajax基础知识铺垫 客户端与服务器 通信协议( ...
- 在项目中导入lombok依赖自动生成有参,无参 空参 方法的注解
导入依赖 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok< ...
- C++ delete后的指针在不同编译器下的状态差异
今天看到小伙伴分享的一个问题,小伙伴用的MSVC2019编译器,在对delete后的指针进行取值操作时触发了访问冲突. #include<iostream> using namespace ...
- MQ系列2:消息中间件的技术选型
1 背景 在高并发.高消息吞吐的互联网场景中,我们经常会使用消息队列(Message Queue)作为基础设施,在服务端架构中担当消息中转.消息削峰.事务异步处理 等职能. 对于那些不需要实时响应的的 ...
- 串口应用:遵循uart协议发送N位数据(状态优化为3个,适用任意长度的输入数据,取寄存器中的一段(用变量作为边界))
上一节中成功实现了发送多个字节的数据.把需要发送的数据分成多段遵循uart协议的数据依次发送.上一节是使用状态机实现的,每发一次设定为一个状态,所以需要发送的数据越多,状态的个数越多,代码越长,因而冗 ...
- Object类的toString方法和equals方法
Object类 概述 java.long.Object 类是java语言中的根类,即所有类的父类.它中描述的所有方法子类都可以使用.在对象实例化的时候,最终的父类就是Object 类Object是类层 ...
- git 生成key并添加key(Windows)
简介 一般来说,在项目代码拉取或者提交前都需要添加项目权限,除此之外也需要将对应设备的public key添加至对应的git上,因此需要生成public key 步骤 1.安装git插件(Window ...
- SpringCloud gateway自定义请求的 httpClient
本文为博主原创,转载请注明出处: 引用 的 spring cloud gateway 的版本为 2.2.5 : SpringCloud gateway 在实现服务路由并请求的具体过程是在 org.sp ...
- 1000-ms-maven相关问题
一.Maven有哪些优点和缺点 优点如下: 简化了项目依赖管理: 易于上手,对于新手可能一个"mvn clean package"命令就可能满足他的工作 便于与持续集成工具(jen ...