Hadoop(二)Hdfs基本操作
HDFS
HDFS由大量服务器组成存储集群,将数据进行分片与副本,实现高容错。
而分片最小的单位就是块。默认块的大小是64M。
HDFS Cli操作
官网https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html
启动命令
sbin/start-dfs.sh
停止命令
sbin/stop-dfs.sh
创建目录
hadoop fs -mkdir /chesterdata
查看是否创建成功
hadoop fs -ls /
上传文件
hadoop fs -put test.txt /chesterdata
查看文件
hadoop fs -ls /chesterdata
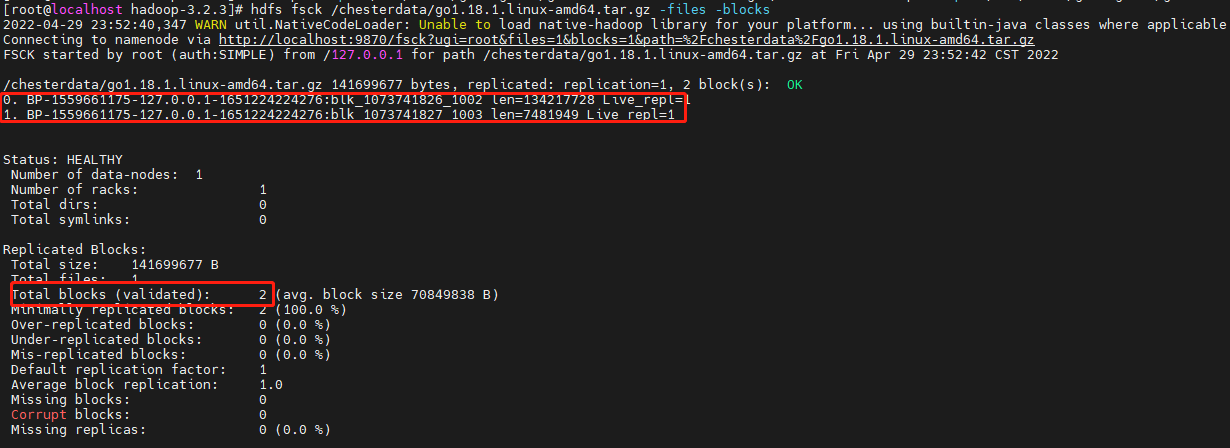
验证块是不是64M,上传一个130M的文件
hadoop fs -put /usr/local/golang1181/go1.18.1.linux-amd64.tar.gz /chesterdata
查看此文件的块信息,hdfs的命令https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
hdfs fsck /chesterdata/go1.18.1.linux-amd64.tar.gz -files -blocks
编程语言操作HDFS
在Github上搜hdfs可以看到哪些语言支持hdfs的操作
我们选择golang来演示操作
引入github.com/colinmarc/hdfs,官网https://pkg.go.dev/github.com/colinmarc/hdfs#section-readme
package main import "github.com/colinmarc/hdfs"
通过go mod tidy安装
[root@localhost hdfsdemo]# go mod tidy
go: finding module for package github.com/colinmarc/hdfs
go: downloading github.com/colinmarc/hdfs v1.1.3
go: found github.com/colinmarc/hdfs in github.com/colinmarc/hdfs v1.1.3
go: finding module for package github.com/golang/protobuf/proto
创建hdfsclient,并尝试删除hdfs中的/chesterdata/go1.18.1.linux-amd64.tar.gz
package main import (
"fmt" "github.com/colinmarc/hdfs"
) func main() {
client, _ := hdfs.New("localhost:9000") err := client.Remove("/chesterdata/go1.18.1.linux-amd64.tar.gz")
fmt.Println(err)
}
通过go run .运行
[root@localhost hdfsdemo]# go run .
<nil>
通过cli检查是否真正删除
[root@localhost hadoop-3.2.3]# hadoop fs -ls /chesterdata
根据ui来查看文件

Hadoop(二)Hdfs基本操作的更多相关文章
- hadoop(二):hdfs HA原理及安装
早期的hadoop版本,NN是HDFS集群的单点故障点,每一个集群只有一个NN,如果这个机器或进程不可用,整个集群就无法使用.为了解决这个问题,出现了一堆针对HDFS HA的解决方案(如:Linux ...
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- Hadoop之HDFS文件操作常有两种方式(转载)
摘要:Hadoop之HDFS文件操作常有两种方式,命令行方式和JavaAPI方式.本文介绍如何利用这两种方式对HDFS文件进行操作. 关键词:HDFS文件 命令行 Java API HD ...
- Hadoop入门--HDFS(单节点)配置和部署 (一)
一 配置SSH 下载ssh服务端和客户端 sudo apt-get install openssh-server openssh-client 验证是否安装成功 ssh username@192.16 ...
- hdfs基本操作
hdfs基本操作 1.查询命令 hadoop dfs -ls / 查询/目录下的所有文件和文件夹 hadoop dfs -ls -R 以递归的方式查询/目录下的所有文件 2.创建文件夹 hadoo ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- Hadoop基础-HDFS安全管家之Kerberos实战篇
Hadoop基础-HDFS安全管家之Kerberos实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们都知道hadoop有很多不同的发行版,比如:Apache Hadoop ...
- Hadoop基础-Hdfs各个组件的运行原理介绍
Hadoop基础-Hdfs各个组件的运行原理介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode工作原理(默认端口号:50070) 1>.什么是NameN ...
- Hadoop基础-HDFS的读取与写入过程剖析
Hadoop基础-HDFS的读取与写入过程剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客会简要介绍hadoop的写入过程,并不会设计到源码,我会用图和文字来描述hdf ...
- 深入理解Hadoop之HDFS架构
Hadoop分布式文件系统(HDFS)是一种分布式文件系统.它与现有的分布式文件系统有许多相似之处.但是,与其他分布式文件系统的差异是值得我们注意的: HDFS具有高度容错能力,旨在部署在低成本硬件上 ...
随机推荐
- Kafka 判断一个节点是否还活着有那两个条件?
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每 个节点的连接 (2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太 ...
- kafka消费组创建和删除原理
0.10.0.0版本的kafka的消费者和消费组已经不在zk上注册节点了,那么消费组是以什么形式存在的呢? 1 入口 看下kafka自带的脚本kafka-consumer-groups.sh,可见脚本 ...
- Java 中 IO 流分为几种?
按功能来分:输入流(input).输出流(output).按类型来分:字节流和字符流.字节流和字符流的区别是:字节流按 8 位传输以字节为单位输入输出数据,字符流按 16 位传输以字符为单位输入输出数 ...
- docker-compose安装和使用
安装:https://my.oschina.net/thinwonton/blog/2985886 docker-compose和Dockerfile结合使用,创建django项目和postgres数 ...
- 什么是 Spring 配置文件?
Spring 配置文件是 XML 文件.该文件主要包含类信息.它描述了这些类是如何 配置以及相互引入的.但是,XML 配置文件冗长且更加干净.如果没有正确规划 和编写,那么在大项目中管理变得非常困难.
- TIME_WAIT 优化注意事项
不同时开启tcp_timestamps和tcp_tw_recycle的场景描述 FULL NAT下 FULL NAT 在client请求VIP 时,不仅替换了package 的dst ip,还替换了 ...
- c++实现中介者模式--虚拟聊天室
内容: 在"虚拟聊天室"实例中增加一个新的具体聊天室类和一个新的具体会员类,要求如下: 1. 新的具体聊天室中发送的图片大小不得超过20M. 2. 新的具体聊天室中发送的文字长度不 ...
- tcp和udp的头部信息
源端口号以及目的端口号: 各占2个字节,端口是传输层和应用层的服务接口,用于寻找发送端和接收端的进程,通过这两个端口号和IP头部的ip发送和接收号,可以唯一的确定一个连接. 一般来讲,通过端口 ...
- URLDNS反序列化链学习
URLDNS URLDNS跟CommonsCollections比起来真是眉清目秀,该链主要用于验证漏洞,并不能执行命令,优点就是不依赖任何包. 1.利用链 * Gadget Chain: * Has ...
- LC-202
编写一个算法来判断一个数 n 是不是快乐数. 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和. 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 ...