MapReduce计算流程
MapReduce的计算流程
1.1 原始数据File
The books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger, all of whom are students at Hogwarts School of Witchcraft and Wizardry.
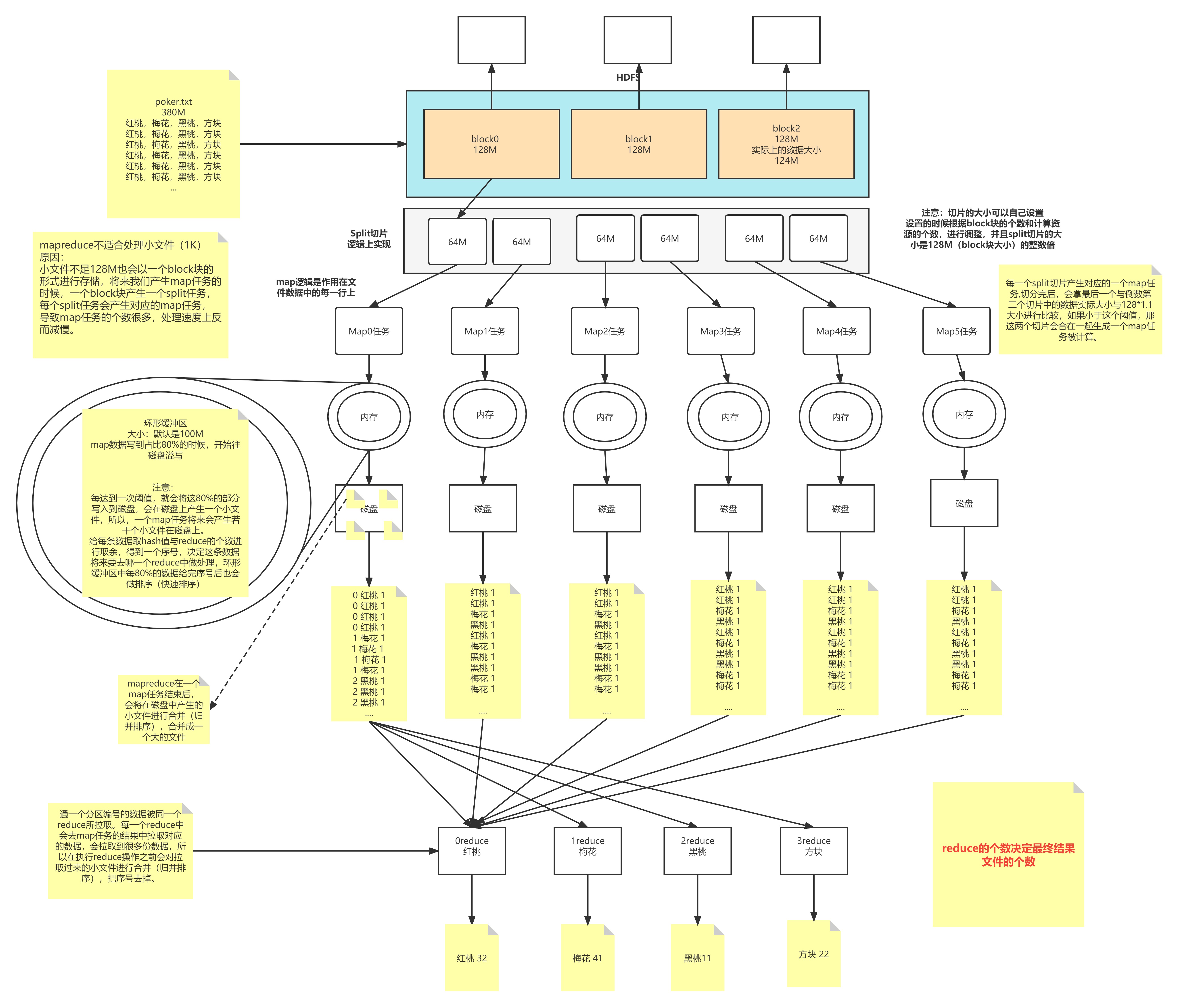
1T数据被切分成块存放在HDFS上,每一个块有128M大小
1.2 数据块Block
block块是hdfs上数据存储的一个单元,同一个文件中块的大小都是相同的
因为数据存储到HDFS上不可变,所以有可能块的数量和集群的计算能力不匹配
我们需要一个动态调整本次参与计算节点数量的一个单位
我们可以动态的改变这个单位–-->参与的节点
1.3 切片Split
目的:动态地控制计算单元的数量
切片是一个逻辑概念
在不改变现在数据存储的情况下,可以控制参与计算的节点数目
通过切片大小可以达到控制计算节点数量的目的
有多少个切片就会执行多少个Map任务
一般切片大小为Block的整数倍(2 1/2)
防止多余创建和很多的数据连接
如果Split大小 > Block大小 ,计算节点少了
如果Split大小 < Block大小 ,计算节点多了
默认情况下,Split切片的大小等于Block的大小 ,默认128M,如果读取到最后一个block块的时候,与前一个blokc块组合起来的大小小于128M*1.1的话,他们结合生一个split切片,生成一个map任务
一个切片对应一个MapTask
1.4 MapTask
map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中(map种的逻辑作用在每一行上)
我们可以根据自己书写的分词逻辑(空格,逗号等分隔),计算每个单词出现的次数(wordcount)
这时会产生(Map<String,Integer>)临时数据,存放到内存中
the books chronicle the adventures of the adolescent wizard Harry Potter and his best friends Ron Weasley and Hermione Granger, all of whom are students at Hogwarts School of Witchcraft and Wizardry
the 1
books 1
chronicle 1
the 1
adventures 1
of 1
...
Wizardry 1
但是内存的大小是有限的,如果每个任务随机的去占用内存,会导致内存不可控。多个任务同时执行有可能内存溢出(OOM)
如果把数据都直接放到硬盘,效率太低
所以想个方案,内存和硬盘结合,我们要做的就是在OOM和效率低之间提供一个有效方案,可以先往内存中写入一部分数据,然后写出到硬盘
1.5 环形缓冲区(KV-Buffer)
可以循环利用这块内存区域,减少数据溢写时map的停止时间
每一个Map可以独享的一个内存区域
在内存中构建一个环形数据缓冲区(kvBuffer),默认大小为100M
设置缓冲区的阈值为80%(设置阈值的目的是为了同时写入和写出),当缓冲区的数据达到80M开始向外溢写到硬盘
溢写的时候还有20M的空间可以被使用效率并不会被减缓
而且将数据循环写到硬盘,不用担心OOM问题
说完这个先说溢写,合并,拉取(分析出问题得到结论),再说中间的分区排序
1.6 分区Partition(环形缓冲区做的)
根据Key直接计算出对应的Reduce
分区的数量和Reduce的数量是相等的
hash(key) % partation(reduce的数量) = num
默认分区的算法是Hash然后取余
Object的hashCode()—equals()
如果两个对象equals,那么两个对象的hashcode一定相等
如果两个对象的hashcode相等,但是对象不一定equlas
1.7 排序Sort(环形缓冲区做的,快速排序,对前面分区后的编号进行排序,使得相同编号的在一起)
对要溢写的数据进行排序(QuickSort)
按照先Partation后Key的顺序排序–>相同分区在一起,相同Key的在一起
我们将来溢写出的小文件也都是有序的
1.8 溢写Spill
将内存中的数据循环写到硬盘,不用担心OOM问题
每次会产生一个80M的文件
如果本次Map产生的数据较多,可能会溢写多个文件
1.9 合并Merge
因为溢写会产生很多有序(分区 key)的小文件,而且小文件的数目不确定
后面向reduce传递数据带来很大的问题
所以将小文件合并成一个大文件,将来拉取的数据直接从大文件拉取即可
合并小文件的时候同样进行排序(归并 排序),最终产生一个有序的大文件
1.10 组合器Combiner(目的是减少reduce拉取数据量,加快mapreduce的执行效率)
a. 集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间的数据传输,hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数(如同map函数和reduce函数一般),其逻辑一般和reduce函数一样,combiner的输入是map的输出,combiner的输出作为reduce的输入,很多情况下可以i直接将reduce函数作为conbiner函数来试用(job.setCombinerClass(FlowCountReducer.class))。
b. combiner属于优化方案,所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner,但是要保证不管调用多少次,combiner函数都不影响最终的结果,所以不是所有处理逻辑都可以i使用combiner组件,有些逻辑如果试用了conbiner函数会改变最后reduce的输出结果(如求几个数的平均值,就不能先用conbiner求一次各个map输出结果的平均值,再求这些平均值的平均值,那样会导致结果的错误)。
c. combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量:
原先传给reduce的数据时a1 a1 a1 a1 a1
第一次combiner组合后变成a(1,1,1,1,1)
第二次combiner后传给reduce的数据变为a(5,5,6,7,23,...)
1.11 拉取Fetch
我们需要将Map的临时结果拉取到Reduce节点
第一种方式:两两合并
第二种方式:相同的进一个reduce
第三种对第二种优化,排序
第四种对第三种优化:如果一个reduce处理两种key,而key分布一个首一个尾,解决不连续的问题,给个编号,这个编号怎么算呢,`回到分区,排序`原则(用统计姓氏的例子画图理解)
相同的Key必须拉取到同一个Reduce节点
但是一个Reduce节点可以有多个Key
未排序前拉取数据的时候必须对Map产生的最终的合并文件做全序遍历
而且每一个reduce都要做一个全序遍历
如果map产生的大文件是有序的,每一个reduce只需要从文件中读取自己所需的即可
1.12 合并Merge
因为reduce拉取的时候,会从多个map拉取数据
那么每个map都会产生一个小文件,这些小文件(文件与文件之间无序,文件内部有序)
为了方便计算(没必要读取N个小文件),需要合并文件
归并算法合并成2个(qishishilia)
相同的key都在一起
1.13 归并Reduce
将文件中的数据读取到内存中
一次性将相同的key全部读取到内存中
直接将相同的key得到结果–>最终结果
1.14 写出Output
每个reduce将自己计算的最终结果都会存放到HDFS上
画图理解
MapReduce计算流程的更多相关文章
- 大数据-hadoop-MapReduce计算流程
MapReduce计算流程 1 首先是通过程序员所编写的MR程序通过命令行本地提交或者IDE远程提交 2 一个MR程序就是一个Job,Job信息会给Resourcemanger,向Resourcem ...
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- MapReduce处理流程
MapReduce是Hadoop2.x的一个计算框架,利用分治的思想,将一个计算量很大的作业分给很多个任务,每个任务完成其中的一小部分,然后再将结果合并到一起.将任务分开处理的过程为map阶段,将每个 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- MapReduce基本流程与设计思想初步
1.MapReduce是什么? MapReduce是一种编程模型,用于大规模数据集的并行运算.它借用了函数式的编程概念,是Google发明的一种数据处理模型. 主要思想为:Map(映射)和Reduce ...
- MapReduce工作流程及Shuffle原理概述
引言: 虽然MapReduce计算框架简化了分布式程序设计,将所有的并行程序均需要关注的设计细节抽象成公共模块并交由系统实现,用户只需关注自己的应用程序的逻辑实现,提高了开发效率,但是开发如果对Map ...
- 【Star CCM+实例】开发一个简单的计算流程.md
流程开发在CAE过程中处于非常重要的地位. 主要的作用可能包括: 将一些经过验证的模型隐藏在流程中,提高仿真的可靠性 将流程封装成更友好的界面,降低软件的学习周期 流程开发实际上需要做非常多的工作,尤 ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce——计算温度最大值 (基于全新2.2.0API)
MapReduce——计算温度最大值 (基于全新2.2.0API) deprecated: Job类的所有Constructors, 新的API用静态方法getInstance(conf)来去的Job ...
随机推荐
- .NET C#基础(6):命名空间 - 有名字的作用域
0. 文章目的 面向C#新学者,介绍命名空间(namespace)的概念以及C#中的命名空间的相关内容. 1. 阅读基础 理解C与C#语言的基础语法. 理解作用域概念. 2. 名称冲突与命 ...
- Docker容器Nginx负载均衡配置、check及stub模块安装
Nginx是一款高性能的HTTP和反向代理.负载均衡web服务器.本次在Docker容器中部署三个tomcat,Nginx代理三个tomcat服务(以下称节点)来模拟实现负载均衡效果,配置check模 ...
- git 删除、合并多次commit提交记录
合并多次记录 1. git log找到要合并的记录的数量. 2. git rebase -i HEAD~5 将最上面一个的记录选为pack,下面记录都改为s. ================= 删除 ...
- Properties集合中的方法store和Properties集合中的方法load
Properties集合中的方法store public class Demo01Properties { public static void main(String[] args) throws ...
- SpringMVC-02
一.SSM整合[重点] 1 SSM整合配置 问题导入 请描述"SSM整合流程"中各个配置类的作用? 1.1 SSM整合流程 创建工程 SSM整合 Spring SpringConf ...
- Linux shell脚本进阶使用
shell的循环控制语句 - continue:提前结束某次循环,重新开始下一次 - break:提前结束某层循环 范例: #求100以内的奇数和 #!/bin/bash sum=0 for i in ...
- MIT 6.824 Llab2B Raft之日志复制
书接上文Raft Part A | MIT 6.824 Lab2A Leader Election. 实验准备 实验代码:git://g.csail.mit.edu/6.824-golabs-2021 ...
- Linux环境下ProxyChains应用网络代理
1.下载源码 git clone https://github.com.cnpmjs.org/rofl0r/proxychains-ng.git 或者 https://hub.fastgit.org/ ...
- Vue生命周期和MVVM框架
生命周期 组件从开始到结束的全过程 创建阶段:beforeCreate.created 挂载阶段:beforeMount.mounted 更新阶段:beforeUpdate.updated 销毁阶段: ...
- Linux下IPC之共享内存的使用方法
基本参考 <Unix环境高级编程>第14.9节共享内存来学习. 参考blog:https://blog.csdn.net/weixin_45794138/article/details/1 ...