2.Ceph 基础篇 - 集群部署及故障排查
部署之前
安装方式
ceph-deploy 安装,官网已经没有这个部署页面,N之前的版本可以使用,包括N,自动化安装工具,后面的版本将不支持,这里我们选择使用ceph-deploy安装;
cephadm 安装,近期出现的安装方式,需要 Centos8 的环境,并且支持图形化安装或者命令行安装,O版本之后,未来推荐使用 cephadm 安装;
手动安装,一步步的教你如何安装,这种方法可以清晰了解部署细节,以及 Ceph 集群各组件的关联关系等;
Rook 安装,与现有 kubernetes 集群集成安装,安装到集群中;
ceph-ansiable 自动化安装;
服务器规划

架构图
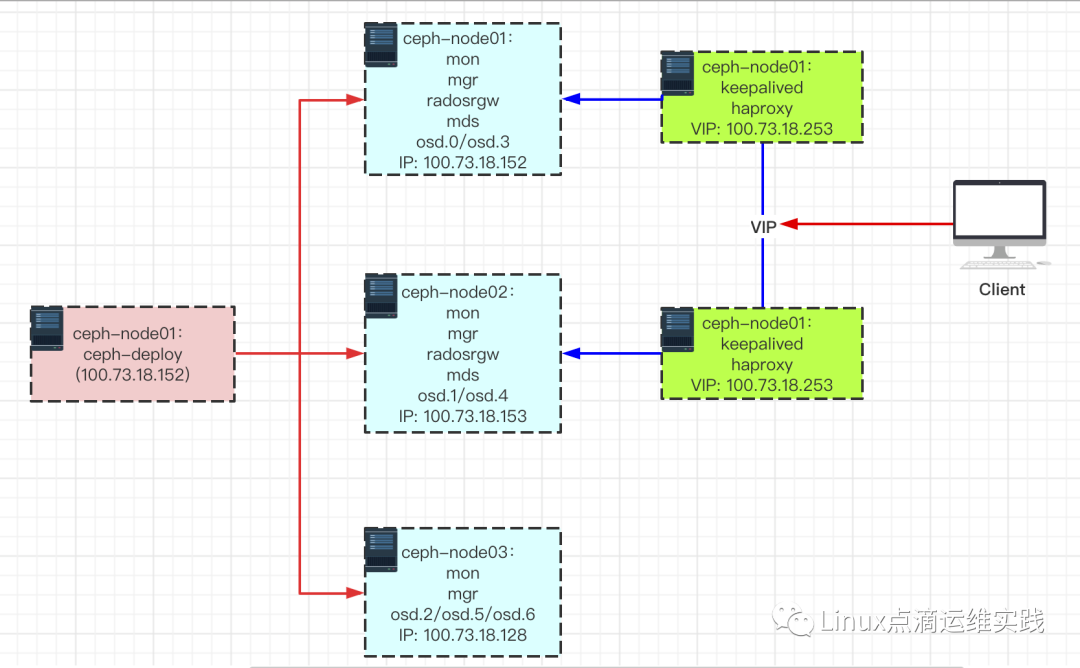
Ceph 概念介绍
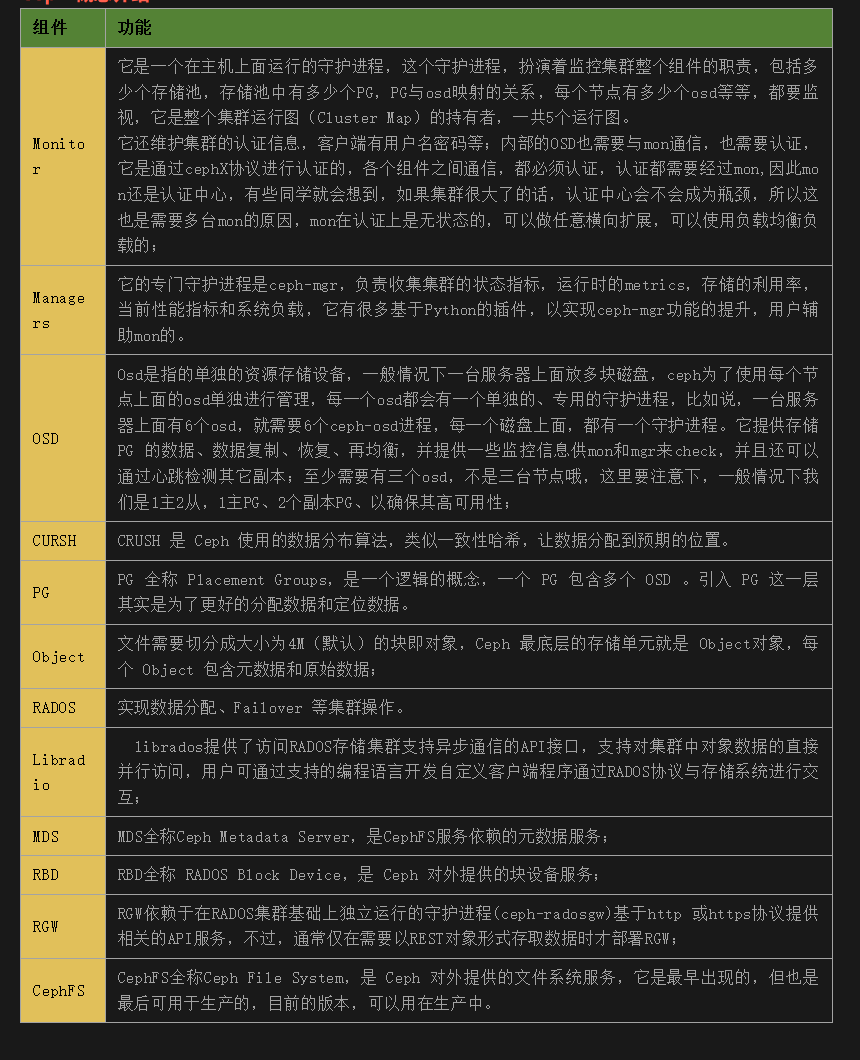
安装部署
1.修改主机名以及添加host(所有机器)
# 修改主机名(每个主机执行一个)
hostnamectl set-hostname ceph-node01
hostnamectl set-hostname ceph-node02
hostnamectl set-hostname ceph-node03
# 修改hosts
[root@ceph-node01 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
100.73.18.152 ceph-node01
100.73.18.153 ceph-node02
100.73.18.128 ceph-node03
[root@ceph-node01 ~]#
2.ceph-admin 节点与其它节点做信任
由于ceph-deploy命令不支持运行中输入密码,因此必须在管理节点(ceph-admin)上生成 ssh 密钥并将其分发到ceph 集群的各个节点上面。
# 生成密钥
ssh-keygen -t rsa -P ""
# copy 密钥
ssh-copy-id -i .ssh/id_rsa.pub <node-name>
# 实际执行命令:
ssh-copy-id -i .ssh/id_rsa.pub ceph-node01
ssh-copy-id -i .ssh/id_rsa.pub ceph-node02
ssh-copy-id -i .ssh/id_rsa.pub ceph-node03
- 配置Chrony服务进行时间同步
配置参考网址 https://www.cnblogs.com/sanduzxcvbnm/p/15347934.html
# vim /etc/chrony.conf
# 删除server开头的4行,新增如下这行
server ntp.aliyun.com minpoll 4 maxpoll 10 iburst
# systemctl start chronyd.service && systemctl enable chronyd.service
# chronyc -n sources -v
4.关闭 iptables 或 firewalld 服务 (也可以指定端口通信,不关闭)
systemctl stop firewalld.service
systemctl stop iptables.service
systemctl disable firewalld.service
systemctl disable iptables.service
5.关闭并禁用 SELinux
# 修改
sed -i 's@^\(SELINUX=\).*@\1disabled@' /etc/sysconfig/selinux
# 生效
setenforce 0
# 查看
getenforce
6.配置 yum 源(同步到所有机器)
删除原来的配置文件,从阿里源下载最新yum 文件;阿里云的镜像官网:https://developer.aliyun.com/mirror/,基本上可以在这里找到所有相关的镜像链接;
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
注意 epel-7 也要下载一下,默认的ceph版本较低,配置 ceph 源,需要自己根据阿里提供的进行自己编写,如下:
ceph:https://mirrors.aliyun.com/ceph/?spm=a2c6h.13651104.0.0.435f22d16X5Jk7
[root@ceph-node01 yum.repos.d]# cat ceph.repo
[norch]
name=norch
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/
enabled=1
gpgcheck=0
[x86_64]
name=x86_64
baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/
enabled=1
gpgcheck=0
[root@ceph-node01 yum.repos.d]#
然后同步repo到所有机器上面(这一步在每个主机上都操作一下,或者使用copy命令复制这些文件到其他主机对应目录下)
# 查看当前 yum 源
yum repolist && yum repolist all
就是把服务器的包信息下载到本地电脑缓存起来,makecache建立一个缓存,以后用yum install时就在缓存中搜索,提高了速度,配合yum -C search xxx使用。
yum clean all && yum makecache
yum -C search xxx
7.管理节点安装 ceph-deploy
Ceph 存储集群部署过程中可通过管理节点使用ceph-deploy全程进行,这里首先在管理节点安装ceph-deploy及其依赖的程序包,这里要注意安装 python-setuptools 工具包;
yum install ceph-deploy python-setuptools python2-subprocess32
8.部署RADOS存储集群
创建一个专属目录;
mkdir ceph-deploy && cd ceph-deploy
初始化第一个MON节点,准备创建集群
ceph-deploy new --cluster-network 100.73.18.0/24 --public-network 100.73.18.0/24 <node-name>
# 实际操作命令:ceph-deploy new --cluster-network 192.168.20.0/24 --public-network 192.168.20.0/24 ceph-node01
--cluster-network内部数据同步使用;--public-network对外提供服务使用的;
生成三个配置文件,ceph.conf(配置文件)、ceph-deploy-ceph.log(日志文件)、 ceph.mon.keyring(认证文件)。
9.安装 ceph 集群
ceph-deploy install {ceph-node} {....}
这里使用这种方式安装的话,会自动化的把软件安装包安装上去,这种安装方式不太好,因为它会重新配置yum源,包括我们的 epel yum源,还有 ceph 的 yum 源,都会指向他内置的yum源,这样会导致你访问到国外,下载很慢,建议手动安装,下面每台机器都手动安装即可,如下:
[root@ceph-node01 ceph-deploy]# yum -y install ceph ceph-mds ceph-mgr ceph-osd ceph-radosgw ceph-mon
10.配置文件和admin密钥copy到ceph集群各节点
[root@ceph-node01 ceph-deploy]# ceph -s
[errno 2] error connecting to the cluster
[root@ceph-node01 ceph-deploy]#
# 原因,没有admin 文件,下面通过 admin 命令进行 copy
[root@ceph-node01 ceph-deploy]# ceph-deploy mon create-initial # 这一步先不执行,若有下面的报错信息再执行
[root@ceph-node01 ceph-deploy]# ceph-deploy admin ceph-node01 ceph-node02 ceph-node03
原文执行的是# ceph-deploy admin ceph-node01 ceph-node02 ceph-node03,但是报错:[ceph_deploy][ERROR ] RuntimeError: ceph.client.admin.keyring not found
因此先执行 ceph-deploy mon create-initial,再执行 ceph-deploy admin ceph-node01 ceph-node02 ceph-node03
再次查看集群状态如下:
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-node01 (age 2m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-node01 ceph-deploy]#
发现 services 只有一个 mon,没有 mgr、也没有 osd;
11.安装 mgr
[root@ceph-node01 ceph-deploy]# ceph-deploy mgr create ceph-node01
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-node01 (age 4m)
mgr: ceph-node01(active, since 84s)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-node01 ceph-deploy]#
12.向 RADOS 集群添加 OSD
[root@ceph-node01 ceph-deploy]# ceph-deploy osd list ceph-node01
# 执行这个会有如下报错信息:(此时报错正常)
[ceph-node01][DEBUG ] find the location of an executable
[ceph-node01][INFO ] Running command: /usr/sbin/ceph-volume lvm list
[ceph-node01][WARNIN] No valid Ceph lvm devices found
[ceph-node01][ERROR ] RuntimeError: command returned non-zero exit status: 1
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: /usr/sbin/ceph-volume lvm list
ceph-deploy disk 命令可以检查并列出 OSD 节点上所有可用的磁盘的相关信息;
在这一步执行之前,需要有新的裸磁盘
[root@ceph-node01 ceph-deploy]# ceph-deploy disk zap ceph-node01 /dev/vdb # 原有磁盘有数据的话需要执行这一步,清除磁盘数据,若是新的裸磁盘就不用执行这个命令了
在管理节点上使用 ceph-deploy 命令擦除计划专用于 OSD 磁盘上的所有分区表和数据以便用于 OSD,命令格式 为 ceph-deploy disk zap {osd-server-name} {disk-name},需要注意的是此步会清除目标设备上的所有数据。
# 查看磁盘情况
[root@ceph-node01 ceph-deploy]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 50G 0 disk
├─vda1 252:1 0 500M 0 part /boot
└─vda2 252:2 0 49.5G 0 part
├─centos-root 253:0 0 44.5G 0 lvm /
└─centos-swap 253:1 0 5G 0 lvm [SWAP]
vdb 252:16 0 100G 0 disk
vdc 252:32 0 100G 0 disk
[root@ceph-node01 ceph-deploy]#
# 添加 osd
[root@ceph-node01 ceph-deploy]# ceph-deploy osd create ceph-node01 --data /dev/vdb
。。。
[root@ceph-node01 ceph-deploy]# ceph-deploy osd create ceph-node02 --data /dev/vdb
。。。
[root@ceph-node01 ceph-deploy]# ceph-deploy osd create ceph-node03 --data /dev/vdb
。。。
[root@ceph-node01 ceph-deploy]# ceph-deploy osd list ceph-node01
ceph-deploy osd list 命令列出指定节点上的 OSD 信息;
13.查看 OSD
查看 OSD 的相关信息;
[root@ceph-node01 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.39067 root default
-3 0.09769 host ceph-node01
0 hdd 0.09769 osd.0 up 1.00000 1.00000
-5 0.09769 host ceph-node02
1 hdd 0.09769 osd.1 up 1.00000 1.00000
-7 0.19530 host ceph-node03
2 hdd 0.19530 osd.2 up 1.00000 1.00000
[root@ceph-node01 ceph-deploy]#
[root@ceph-node01 ceph-deploy]# ceph osd stat
3 osds: 3 up (since 2d), 3 in (since 2d); epoch: e26
[root@ceph-node01 ceph-deploy]# ceph osd ls
0
1
2
[root@ceph-node01 ceph-deploy]# ceph osd dump
epoch 26
fsid cc10b0cb-476f-420c-b1d6-e48c1dc929af
created 2020-09-29 09:14:30.781641
modified 2020-09-29 10:14:06.100849
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 7
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client jewel
min_compat_client jewel
require_osd_release nautilus
pool 1 'ceph-demo' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode warn last_change 25 lfor 0/0/20 flags hashpspool,selfmanaged_snaps stripe_width 0
removed_snaps [1~3]
max_osd 3
osd.0 up in weight 1 up_from 5 up_thru 22 down_at 0 last_clean_interval [0,0) [v2:100.73.18.152:6802/11943,v1:100.73.18.152:6803/11943] [v2:100.73.18.152:6804/11943,v1:100.73.18.152:6805/11943] exists,up 136f6cf7-05a0-4325-aa92-ad316560edff
osd.1 up in weight 1 up_from 9 up_thru 22 down_at 0 last_clean_interval [0,0) [v2:100.73.18.153:6800/10633,v1:100.73.18.153:6801/10633] [v2:100.73.18.153:6802/10633,v1:100.73.18.153:6803/10633] exists,up 79804c00-2662-47a1-9987-95579afa10b6
osd.2 up in weight 1 up_from 13 up_thru 22 down_at 0 last_clean_interval [0,0) [v2:100.73.18.128:6800/10558,v1:100.73.18.128:6801/10558] [v2:100.73.18.128:6802/10558,v1:100.73.18.128:6803/10558] exists,up f15cacec-fdcd-4d3c-8bb8-ab3565cb4d0b
[root@ceph-node01 ceph-deploy]#
14.扩展 mon
[root@ceph-node01 ceph-deploy]# ceph-deploy mon add ceph-node02
[root@ceph-node01 ceph-deploy]# ceph-deploy mon add ceph-node03
由于 mon 需要使用 paxos 算法进行选举一个 leader,可以查看选举状态;
[root@ceph-node01 ceph-deploy]# ceph quorum_status
查看 mon 状态
[root@ceph-node01 ceph-deploy]# ceph mon stat
e3: 3 mons at {ceph-node01=[v2:100.73.18.152:3300/0,v1:100.73.18.152:6789/0],ceph-node02=[v2:100.73.18.153:3300/0,v1:100.73.18.153:6789/0],ceph-node03=[v2:100.73.18.128:3300/0,v1:100.73.18.128:6789/0]}, election epoch 12, leader 0 ceph-node01, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03
[root@ceph-node01 ceph-deploy]#
查看 mon 详情
[root@ceph-node01 ceph-deploy]# ceph mon dump
dumped monmap epoch 3
epoch 3
fsid cc10b0cb-476f-420c-b1d6-e48c1dc929af
last_changed 2020-09-29 09:28:35.692432
created 2020-09-29 09:14:30.493476
min_mon_release 14 (nautilus)
0: [v2:100.73.18.152:3300/0,v1:100.73.18.152:6789/0] mon.ceph-node01
1: [v2:100.73.18.153:3300/0,v1:100.73.18.153:6789/0] mon.ceph-node02
2: [v2:100.73.18.128:3300/0,v1:100.73.18.128:6789/0] mon.ceph-node03
[root@ceph-node01 ceph-deploy]#
15.扩展 mgr
[root@ceph-node01 ceph-deploy]# ceph-deploy mgr create ceph-node02 ceph-node03
16.查看集群状态
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 9m)
mgr: ceph-node01(active, since 20m), standbys: ceph-node02, ceph-node03
osd: 3 osds: 3 up (since 13m), 3 in (since 13m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 397 GiB / 400 GiB avail
pgs:
[root@ceph-node01 ceph-deploy]#
3个mon、3个mgr、3个osd的RADOS集群创建成功;
实际操作后查看集群状态:
# ceph -s
cluster:
id: 196671fc-7230-4fc2-8c80-865463dec08c
health: HEALTH_WARN
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 44s)
mgr: ceph-node01(active, since 18m), standbys: ceph-node02, ceph-node03
osd: 3 osds: 3 up (since 8m), 3 in (since 8m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
有个提示:mons are allowing insecure global_id reclaim
解决办法:禁用掉不安全的模式,使用如下命令:ceph config set mon auth_allow_insecure_global_id_reclaim false, 重新在使用ceph -s查看警告信息就没了
17.移出故障 OSD
Ceph集群中的一个OSD通常对应于一个设备,且运行于专用的守护进程。在某OSD设备出现故障,或管理员出于管理之需确实要移除特定的OSD设备时,需要先停止相关的守护进程,而后再进行移除操作。
停用设备:ceph osd out {osd-num}
停止进程:sudo systemctl stop ceph-osd@{osd-num}
移除设备:ceph osd purge {id} --yes-i-really-mean-it
[root@ceph-node01 ceph-deploy]# ceph osd out 0
marked out osd.0.
[root@ceph-node01 ceph-deploy]# systemctl stop ceph-osd@0
[root@ceph-node01 ceph-deploy]# ceph osd purge 0 --yes-i-really-mean-it
purged osd.0
[root@ceph-node01 ceph-deploy]#
移出后查看状态
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_WARN
2 daemons have recently crashed
OSD count 2 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 15h)
mgr: ceph-node01(active, since 15h)
osd: 2 osds: 2 up (since 37h), 2 in (since 37h)
data:
pools: 1 pools, 128 pgs
objects: 54 objects, 137 MiB
usage: 2.3 GiB used, 298 GiB / 300 GiB avail
pgs: 128 active+clean
[root@ceph-node01 ceph-deploy]#
磁盘擦除数据时报错
[root@ceph-node01 ceph-deploy]# ceph-deploy disk zap ceph-node01 /dev/vdb
。。。
[ceph_deploy][ERROR ] RuntimeError: Failed to execute command: /usr/sbin/ceph-volume lvm zap /dev/vdb
根据擦除数据时出现报错后,可以使用dd清空数据,然后再重启
[root@ceph-node01 ceph-deploy]# dd if=/dev/zero of=/dev/vdb bs=512K count=1
[root@ceph-node01 ceph-deploy]# reboot
磁盘修复好后,再加入集群
[root@ceph-node01 ceph-deploy]# ceph-deploy osd create ceph-node01 --data /dev/vdb
。。。
[ceph-node01][WARNIN] Running command: /usr/bin/systemctl enable --runtime ceph-osd@0
[ceph-node01][WARNIN] stderr: Created symlink from /run/systemd/system/ceph-osd.target.wants/ceph-osd@0.service to /usr/lib/systemd/system/ceph-osd@.service.
[ceph-node01][WARNIN] Running command: /usr/bin/systemctl start ceph-osd@0
[ceph-node01][WARNIN] --> ceph-volume lvm activate successful for osd ID: 0
[ceph-node01][WARNIN] --> ceph-volume lvm create successful for: /dev/vdb
[ceph-node01][INFO ] checking OSD status...
[ceph-node01][DEBUG ] find the location of an executable
[ceph-node01][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host ceph-node01 is now ready for osd use.
[root@ceph-node01 ceph-deploy]#
查看集群状态,发现正在迁移数据
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_WARN
Degraded data redundancy: 9/88 objects degraded (10.227%), 7 pgs degraded
2 daemons have recently crashed
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 15h)
mgr: ceph-node01(active, since 15h)
osd: 3 osds: 3 up (since 6s), 3 in (since 6s)
data:
pools: 1 pools, 128 pgs
objects: 44 objects, 105 MiB
usage: 3.3 GiB used, 397 GiB / 400 GiB avail
pgs: 24.219% pgs not active
9/88 objects degraded (10.227%)
1/88 objects misplaced (1.136%)
90 active+clean
31 peering
6 active+recovery_wait+degraded
1 active+recovering+degraded
io:
recovery: 1.3 MiB/s, 1 keys/s, 1 objects/s
[root@ceph-node01 ceph-deploy]#
等待一段时间后,发现数据迁移完成,但有两个进程crashed了
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_WARN
2 daemons have recently crashed
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 15h)
mgr: ceph-node01(active, since 15h), standbys: ceph-node02, ceph-node03
osd: 3 osds: 3 up (since 30m), 3 in (since 30m)
data:
pools: 1 pools, 128 pgs
objects: 54 objects, 137 MiB
usage: 3.3 GiB used, 397 GiB / 400 GiB avail
pgs: 128 active+clean
[root@ceph-node01 ceph-deploy]#
通过 ceph health detail 查看集群问题
[root@ceph-node01 ceph-deploy]# ceph health
HEALTH_WARN 2 daemons have recently crashed
[root@ceph-node01 ceph-deploy]# ceph health detail
HEALTH_WARN 2 daemons have recently crashed
RECENT_CRASH 2 daemons have recently crashed
mgr.ceph-node02 crashed on host ceph-node02 at 2020-10-03 01:53:00.058389Z
mgr.ceph-node03 crashed on host ceph-node03 at 2020-10-03 03:33:30.776755Z
[root@ceph-node01 ceph-deploy]# ceph crash ls
ID ENTITY NEW
2020-10-03_01:53:00.058389Z_c26486ef-adab-4a1f-9b94-68953571e8d3 mgr.ceph-node02 *
2020-10-03_03:33:30.776755Z_88464c4c-0711-42fa-ae05-6196180cfe31 mgr.ceph-node03 *
[root@ceph-node01 ceph-deploy]#
通过 systemctl restart ceph-mgr@ceph-node02无法重启(原因后续要找下),再次重建了下;
[root@ceph-node01 ceph-deploy]# ceph-deploy mgr create ceph-node02 ceph-node03
再次查看集群状态如下,mgr已经恢复,但还提示两个进程crashed;
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_WARN
2 daemons have recently crashed
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 15h)
mgr: ceph-node01(active, since 15h), standbys: ceph-node02, ceph-node03
osd: 3 osds: 3 up (since 30m), 3 in (since 30m)
data:
pools: 1 pools, 128 pgs
objects: 54 objects, 137 MiB
usage: 3.3 GiB used, 397 GiB / 400 GiB avail
pgs: 128 active+clean
[root@ceph-node01 ceph-deploy]#
通过 ceph crash archive-all 或者 ID 的形式修复,再次查看集群状态如下:
[root@ceph-node01 ceph-deploy]# ceph crash archive-all
[root@ceph-node01 ceph-deploy]#
[root@ceph-node01 ceph-deploy]# ceph -s
cluster:
id: cc10b0cb-476f-420c-b1d6-e48c1dc929af
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-node01,ceph-node02,ceph-node03 (age 15h)
mgr: ceph-node01(active, since 15h), standbys: ceph-node02, ceph-node03
osd: 3 osds: 3 up (since 33m), 3 in (since 33m)
data:
pools: 1 pools, 128 pgs
objects: 54 objects, 137 MiB
usage: 3.3 GiB used, 397 GiB / 400 GiB avail
pgs: 128 active+clean
[root@ceph-node01 ceph-deploy]#
1. 安装前准备
服务器规划、服务器间信任、主机名解析(hosts)、NTP同步、firewalld/iptables关闭、SELinux 关闭、配置yum源等;
- Ceph 集群部署
mon 创建:ceph-deploy new --cluster-network 100.73.18.0/24 --public-network 100.73.18.0/24 (创建第一个 mon )
配置拷贝:ceph-deploy admin ceph-node01 ceph-node02 ceph-node03
mon 扩展:ceph-deploy mon add ceph-node02
mgr 创建:ceph-deploy mgr create ceph-node01
mgr 扩展:ceph-deploy mgr create ceph-node02 ceph-node03
osd 创建:ceph-deploy osd create ceph-node01 --data /dev/vdb
- 集群信息查看
列出可用 osd:ceph-deploy osd list ceph-node01(列出某节点可用osd)
查看磁盘信息:lsblk;
擦除已有盘数据使其成为osd加入集群:ceph-deploy disk zap ceph-node01 /dev/vdb;
查看 OSD 信息:ceph osd tree、ceph osd stat、ceph osd ls、ceph osd dump等
查看 mon 选举:ceph quorum_status、ceph mon stat、ceph mon dump等
- 集群故障
停止故障 OSD:ceph osd out {osd-num}
停止故障 OSD 进程:systemctl stop ceph-osd@{osd-num}
移出故障 OSD:ceph osd purge {id} --yes-i-really-mean-it
故障信息查看:ceph health、ceph health detail
查看crash进程:ceph crash ls
修复后忽略:ceph crash archive-all
2.Ceph 基础篇 - 集群部署及故障排查的更多相关文章
- 理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
- openstack(pike 版)集群部署(一)----基础环境部署
一.环境 1.系统: a.CentOS Linux release 7.4.1708 (Core) b.更新yum源和安装常用软件 # yum -y install epel-release ba ...
- Dubbo入门到精通学习笔记(二十):MyCat在MySQL主从复制的基础上实现读写分离、MyCat 集群部署(HAProxy + MyCat)、MyCat 高可用负载均衡集群Keepalived
文章目录 MyCat在MySQL主从复制的基础上实现读写分离 一.环境 二.依赖课程 三.MyCat 介绍 ( MyCat 官网:http://mycat.org.cn/ ) 四.MyCat 的安装 ...
- 这一篇 K8S(Kubernetes)集群部署 我觉得还可以!!!
点赞再看,养成习惯,微信搜索[牧小农]关注我获取更多资讯,风里雨里,小农等你,很高兴能够成为你的朋友. 国内安装K8S的四种途径 Kubernetes 的安装其实并不复杂,因为Kubernetes 属 ...
- Kubernetes集群部署篇( 一)
K8S集群部署有几种方式:kubeadm.minikube和二进制包.前两者属于自动部署,简化部署操作,我们这里强烈推荐初学者使用二进制包部署,因为自动部署屏蔽了很多细节,使得对各个模块感知很少,非常 ...
- k8s1.9.0安装--基础集群部署
二.基础集群部署 - kubernetes-simple 1. 部署ETCD(主节点) 1.1 简介 kubernetes需要存储很多东西,像它本身的节点信息,组件信息,还有通过kubernetes运 ...
- 第3篇K8S集群部署
一.利用ansible部署kubernetes准备: 集群介绍 本系列文档致力于提供快速部署高可用k8s集群的工具,并且也努力成为k8s实践.使用的参考书:基于二进制方式部署和利用ansible- ...
- HBase集群部署与基础命令
HBase 集群部署 安装 hbase 之前需要先搭建好 hadoop 集群和 zookeeper 集群.hadoop 集群搭建可以参考:https://www.cnblogs.com/javammc ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
随机推荐
- 温湿度监测系统设计:基于 STM32 的温湿度变送器的设计与实现
前言:这个是2018年上半年完成的,这里只贴出硬件设计部分,软件设计部分可以看上位机说明书. 设计总说明 随着科学技术的不断发展,高集成度.高精度.高可靠性的一体化温湿度变送器开始 得到广泛的应用.同 ...
- super详解
1.super和this的区别 super调用的是父类的属性或方法,this是调用当前类的属性或者方法. (1)super和this关于属性的调用 (2)super和this关于方法的 ...
- 【Azure 应用服务】PHP应用部署在App Service for Linux环境中,上传文件大于1MB时,遇见了413 Request Entity Too Large 错误的解决方法
问题描述 在PHP项目部署在App Service后,上传文件如果大于1MB就会遇见 413 Request Entity Too Large 的问题. 问题解决 目前这个问题,首先需要分析应用所在的 ...
- linux常见命令chgrp/chown/chmod
linux文件权限有读(r-4)写(w-2)执行(x-1) linux文件的所有方式有拥有者(user),属组(group),其他人(others) 改变文件属组命令 -- chgrp 修改/data ...
- Eplan创建符号
1.打开Eplan P8 ,新建一个名为"新项目"的项目,然后选择菜单"工具"----"主数据"-----"符号库"-- ...
- 羽夏看Linux内核——启动那些事
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.如有好的建议,欢迎反馈.码字不易,如果本篇文章有帮助你的,如有闲钱,可以打赏支持我的创作.如想转载,请把我的转载信息附在文章后面,并 ...
- jQuery基础入门(二)
jQuery 效果 显示和隐藏 在 jQuery 中可以使用 hide() 和 show() 方法来隐藏和显示 HTML 元素,以及使用 toggle() 方法能够切换 hide() 和 show() ...
- LuoguP2254 [NOI2005]瑰丽华尔兹 (单调队列优化DP)(用记忆化过了。。。)
记忆化 #include <cstdio> #include <iostream> #include <cstring> #include <algorith ...
- 百亿数据百亿花, 库若恒河沙复沙,Go lang1.18入门精炼教程,由白丁入鸿儒,Go lang数据库操作实践EP12
Golang可以通过Gorm包来操作数据库,所谓ORM,即Object Relational Mapping(数据关系映射),说白了就是通过模式化的语法来操作数据库的行对象或者表对象,对比相对灵活繁复 ...
- Spring 01: Spring配置 + IOC控制反转 + Setter注入
简介 Spring框架是一个容器,是整合其他框架的框架 他的核心是IOC(控制反转)和AOP(面向切面编程),由20多个模块构成,在很多领域都提供了优秀的问题解决方案 特点 轻量级:由20多个模块构成 ...