Python面试题(练习一)
1.Python的可变类型和不可变类型?
可变类型:list、dict(列表和字典)
不可变类型:数字、字符串、元组
2.求结果:
- v = dict.fromkeys(['k1','k2'],[])
- v['k1'].append(666)
- print(v) # {'k1': [666], 'k2': [666]}
- v['k1'] = 777
- print(v) # {'k1': 777, 'k2': [666]}
3.求结果: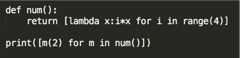
你将如何修改 multipliers 的定义来产生期望的结果
答案
以上代码的输出是 [6, 6, 6, 6] (而不是 [0, 2, 4, 6])。
这个的原因是 Python 的闭包的后期绑定导致的 late binding,这意味着在闭包中的变量是在内部函数被调用的时候被查找。所以结果是,当任何 multipliers() 返回的函数被调用,在那时,i 的值是在它被调用时的周围作用域中查找,到那时,无论哪个返回的函数被调用,for 循环都已经完成了,i 最后的值是 3,因此,每个返回的函数 multiplies 的值都是 3。因此一个等于 2 的值被传递进以上代码,它们将返回一个值 6 (比如: 3 x 2)。
(顺便说下,正如在 The Hitchhiker’s Guide to Python 中指出的,这里有一点普遍的误解,是关于 lambda 表达式的一些东西。一个 lambda 表达式创建的函数不是特殊的,和使用一个普通的 def 创建的函数展示的表现是一样的。)
这里有两种方法解决这个问题。
最普遍的解决方案是创建一个闭包,通过使用默认参数立即绑定它的参数。例如:
def multipliers():
return [lambda x, i=i : i * x for i in range(4)]
4.filter、map、reduce的作用?
- L1 = list(filter(lambda x:x%2==1,range(20)))
- print(L1)
- L2 = list(map(lambda x:x%2==1,range(20)))
- print(L2)
- L4 = list(map(lambda x:x*x,range(20)))
- print(L4)
- [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
- [False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True, False, True]
- [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361
如果用filter的话,说明匿名函数lambda给出的是个筛选条件,从1到19中筛选出奇数来,但这里如果用map的话,就好像变成了它判断对错的条件,只打印true和false。
map一般的用法如下,参数有一个函数一个序列,将右边的序列经过左边的函数变换,生成新的序列。
在python3中已将其从全局空间移除,现被放置在functools的模块里,用之前需要引入 from functools import reduce
5、一行代码实现9*9乘法表
- print ("\n".join("\t".join(["%s*%s=%s" %(x,y,x*y) for y in range(1, x+1)]) for x in range(1, 10)))
6、re的match和search区别?
match与search函数的功能一样,match匹配字符串开始的第一个位置,search是在字符串全局匹配第一个符合规则的。
- import re
- str = "this is a str"
- a = re.match('th',str)
- b = re.search("is",str)
- print(a) # <_sre.SRE_Match object; span=(0, 2), match='th'>
- print(b) # <_sre.SRE_Match object; span=(2, 4), match='is'>
7、什么是正则的贪婪匹配?
尽可能多的去匹配符合规则的字符,非贪婪模式后面加?(尽可能少的匹配)
8、求结果:
a. [ i % 2 for i in range(10) ]
b. ( i % 2 for i in range(10) )
- a = [i for i in range(10)]
- print(a) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- b = (i for i in range(10))
- print(b) # <generator object <genexpr> at 0x0212D180>
9、求结果:
a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
- print(1 or 2) # 1
- print(1 and 2) # 2
- print(1 < (2==2)) # False
- print(1<2==2) # True
10、def func(a,b=[]) 这种写法有什么坑?
- def funx(a,b=[]):
- print(a,b)
- b=[1,2]
- funx(2,b) # 2 [1, 2]
- b.append([3,4])
- funx(3,b) # 3 [1, 2, [3, 4]]
- 每次调用 funx 函数,b 并不是空
11、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
- a = ['1','2','3']
- b = []
- for i in a:
- b.append(int(i))
- print(b)
12、比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
- print(type([1,2,3][0])) # <class 'int'>
- print(type([(1),(2),(3)][0])) # <class 'int'>
- print(type([(1,),(2,),(3,)][0])) # <class 'tuple'>
13、如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
- print(list(map(lambda x: x*x ,range(1,11))))
- # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
14、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
- str = '1,2,3'
- a = []
- for num in str.split(','):
- a.append(int(num))
- print(a)
15、一行代码实现删除列表中重复的值 ?
- print(list(set([1,1,1,2,2,3,4,4,5])))
- # [1, 2, 3, 4, 5]
16、如何在函数中设置一个全局变量 ?
- def funx():
- global a
- a += 1
- print(a)
- a = 2
- funx() # 3
- funx 可以访问函数外的全局变量 a
17、请用代码简答实现stack 。
- class Stack(object):
- def __init__(self):
- self.stack = []
- def push(self,value): # 进栈
- self.stack.append(value)
- def pop(self): # 出栈
- if self.stack:
- return self.stack.pop()
- else:
- raise LookupError('stack is empty!')
- def is_empty(self): # 返回栈 是否为空
- return bool(self.stack)
- def top(self): # 返回栈中最新元素
- if self.stack:
- return self.stack[-1]
- else:
- return 'stack is empty!'
18、常用字符串格式化哪几种?
- '''
- Python 中格式化有三种:
- '''
- # 需一个个的格式化
- print('Hello %s' % ('Petrolero'))
- # 不需要一个个的格式化,可以利用字典的方式,缩短时间
- print('Hello %(name)s' % {'name':'petrolero'})
- # 可读性强
- print('Hello {name}'.format(name='petrolero'))
Python面试题(练习一)的更多相关文章
- Python面试题 —— 获取列表中位数
中位数是一个可将数值集合划分为相等的上下两部分的一个数值.如果列表数据的个数是奇数,则列表中间那个数据就是列表数据的中位数:如果列表数据的个数是偶数,则列表中间那2个数据的算术平均值就是列表数据的中位 ...
- python公司面试题集锦 python面试题大全
问题一:以下的代码的输出将是什么? 说出你的答案并解释. class Parent(object): x = 1 class Child1(Parent): pass class Child2(Par ...
- 【Python】【面试必看】Python笔试题
前言 现在面试测试岗位,一般会要求熟悉一门语言(python/java),为了考验求职者的基本功,一般会出 2 个笔试题,这些题目一般不难,主要考察基本功.要是给你一台电脑,在编辑器里面边写边调试,没 ...
- Python面试题整理-更新中
几个链接: 编程零基础应当如何开始学习 Python ? - 路人甲的回答 网易云课堂上有哪些值得推荐的 Python 教程? - 路人甲的回答 怎么用最短时间高效而踏实地学习 Python? - 路 ...
- python 面试题4
Python面试题 基础篇 分类: Python2014-08-08 13:15 2071人阅读 评论(0) 收藏 举报 最近,整理了一些python常见的面试题目,语言是一种工具,但是多角度的了解工 ...
- 一道Python面试题
无意间,看到这么一道Python面试题:以下代码将输出什么? def testFun(): temp = [lambda x : i*x for i in range(4)] return ...
- 很全的 Python 面试题
很全的 Python 面试题 Python语言特性 1 Python的函数参数传递 看两个例子: Python 1 2 3 4 5 a = 1 def fun(a): ...
- SQL + Python 面试题:之二(难度:中等)
SQL + Python 面试题:之二(难度:中等)
- Python面试题之一:解密
Python面试题之一: 说明:就是Python工程师面试题 一.字典转换与正则提取值 1:key与Value交换 a = {'a':1,'b':2} print({value:key for key ...
- 震惊!几道Python 理论面试题,Python面试题No18
本面试题题库,由公号:非本科程序员 整理发布 第1题: 简述解释型和编译型编程语言? 解释型语言编写的程序不需要编译,在执行的时候,专门有一个解释器能够将VB语言翻译成机器语言,每个语句都是执行的时候 ...
随机推荐
- nmap -sS
SYN 扫描,半连接,受到syn/ack响应后意味着端口开放,收到rst包意味着端口关闭.
- SQL Server数据库log shipping 灾备(Part1 )
1.概述 Log Shipping为SQL Server提供的数据库备份过程.它可以将数据库整个复制到另一台服务器上.在这种情况下,交易日志也会定期发送到备份服务器上供恢复数据使用,这使得服务器一直处 ...
- COGS 147. [USACO Jan08] 架设电话线
★★☆ 输入文件:phoneline.in 输出文件:phoneline.out 简单对比时间限制:1 s 内存限制:16 MB Farmer John打算将电话线引到自己的农场,但电 ...
- Harvest of Apples
问题 B: Harvest of Apples 时间限制: 1 Sec 内存限制: 128 MB提交: 18 解决: 11[提交] [状态] [讨论版] [命题人:admin] 题目描述 Ther ...
- 第二单元OO总结
目录 前言 一.第一次作业分析 1. UML及复杂度分析 二.第二次作业分析 1. UML及复杂度分析 2. 性能优化 2.1 楼层类的实现 2.2 调度算法 3. bug分析 三.第三次作业分析 1 ...
- 主成分分析法(PCA)答疑
问:为什么要去均值? 1.我认为归一化的表述并不太准确,按统计的一般说法,叫标准化.数据的标准化过程是减去均值并除以标准差.而归一化仅包含除以标准差的意思或者类似做法.2.做标准化的原因是:减去均值等 ...
- 数据库连接池 dbcp与c3p0的使用区别
众所周知,无论现在是B/S或者是C/S应用中,都免不了要和数据库打交道.在与数据库交 互过程中,往往需要大量的连接.对于一个大型应用来说,往往需要应对数以千万级的用户连接请求,如果高效相应用户请求,对 ...
- C++ 内存分配操作符new和delete详解
重载new和delete 首先借用C++ Primer 5e的一个例子: string *sp = new string("a value"); ]; 这其实进行了以下三步操作: ...
- iOS快速开发框架--Bee Framework
Bee Framework是一款iOS快速开发框架,允许开发者使用Objective-C和XML/CSS来进行iPhone和iPad开发,由 Gavin Kwoe 和 QFish 开发并维护. 其早期 ...
- 【转】MFC右键显示菜单之LoadMenu()
如何在界面内单击右键弹出自己设置的菜单选项? 步骤如下: 1.在资源MENU里添加一个菜单资源,命名为IDR_POP_MENU. 2.在自己添加的菜单中添加事件,如事件1,事件2,事件3,分别添加响应 ...