大数据学习——Storm+Kafka+Redis整合
1 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId>
<artifactId>TestStorm</artifactId>
<version>1.0-SNAPSHOT</version> <repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories> <dependencies> <dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<!--<scope>provided</scope>-->
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>0.9.5</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.8.2</artifactId>
<version>0.8.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency> </dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>com.cyf.StormTopologyDriver</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
2 MyLocalFileSpout.java
package kfk; import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import org.apache.commons.lang.StringUtils; import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map; /**
* Created by Administrator on 2019/2/19.
*/
public class MyLocalFileSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private BufferedReader bufferedReader; //初始化方法
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
try {
this.bufferedReader = new BufferedReader(new FileReader("/root/1.log"));
// this.bufferedReader = new BufferedReader(new FileReader("D:\\1.log"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} } //循环调用的方法
//Storm实时计算的特性就是对数据一条一条的处理 public void nextTuple() {
//每调用一次就会发送一条数据出去
try {
String line = bufferedReader.readLine(); if (StringUtils.isNotBlank(line)) {
List<Object> arrayList = new ArrayList<Object>();
arrayList.add(line);
collector.emit(arrayList);
}
} catch (IOException e) {
e.printStackTrace();
} } public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("juzi"));
}
}
3 MySplitBolt.java
package kfk; import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values; /**
* Created by Administrator on 2019/2/19.
*/
public class MySplitBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { //1.数据如何获取
byte[] juzi = (byte[]) tuple.getValueByField("bytes");
//2.进行切割
String[] strings = new String(juzi).split(" ");
//3.发送数据
for (String word : strings) {
basicOutputCollector.emit(new Values(word, 1));
}
} public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word", "num"));
}
}
4 MyWordCountAndPrintBolt.java
package kfk; import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
import redis.clients.jedis.Jedis; import java.util.HashMap;
import java.util.Map; /**
* Created by Administrator on 2019/2/19.
*/
public class MyWordCountAndPrintBolt extends BaseBasicBolt { private Map<String, String> wordCountMap = new HashMap<String, String>();
private Jedis jedis; @Override
public void prepare(Map stormConf, TopologyContext context) {
//连接redis——代表可以连接任何事物
jedis=new Jedis("127.0.0.1",6379);
super.prepare(stormConf, context);
} public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String word = (String) tuple.getValueByField("word");
Integer num = (Integer) tuple.getValueByField("num"); //1查看单词对应的value是否存在
Integer integer = wordCountMap.get(word)==null?0:Integer.parseInt(wordCountMap.get(word)) ;
if (integer == null || integer.intValue() == 0) {
wordCountMap.put(word, num+"");
} else {
wordCountMap.put(word, (integer.intValue() + num)+"");
}
//2.打印数据
// System.out.println(wordCountMap);
//保存数据到redis
//redis key wordcount:Map
jedis.hmset("wordcount",wordCountMap);
} public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { }
}
5 StormTopologyDriver.java
package kfk; import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
import backtype.storm.topology.TopologyBuilder;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.ZkHosts; /**
* Created by Administrator on 2019/2/21.
*/
public class StormTopologyDriver {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
//1准备任务信息
TopologyBuilder topologyBuilder = new TopologyBuilder(); topologyBuilder.setSpout("KafkaSpout", new KafkaSpout(new SpoutConfig(new ZkHosts("mini1:2181"),"wordCount","/wc","wc")));
topologyBuilder.setBolt("bolt1", new MySplitBolt()).shuffleGrouping("KafkaSpout");
topologyBuilder.setBolt("bolt2", new MyWordCountAndPrintBolt()).shuffleGrouping("bolt1"); //2任务提交
//提交给谁,提交什么内容
Config config=new Config();
StormTopology stormTopology=topologyBuilder.createTopology(); //本地模式
LocalCluster localCluster=new LocalCluster();
localCluster.submitTopology("wordcount",config,stormTopology); //集群模式
// StormSubmitter.submitTopology("wordcount",config,stormTopology);
}
}
6 TestRedis.java
package kfk; import redis.clients.jedis.Jedis; import java.util.Map; /**
* Created by Administrator on 2019/2/25.
*/
public class TestRedis {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379); Map<String, String> wordcount = jedis.hgetAll("wordcount");
System.out.println(wordcount);
}
}
在mini1的/root/apps/kafka目录下
创建topic
bin/kafka-topics.sh --create --zookeeper mini1: --replication-factor --partitions --topic wordCount
生产数据
bin/kafka-console-producer.sh --broker-list mini1: --topic wordCount
启动 StormTopologyDriver.java
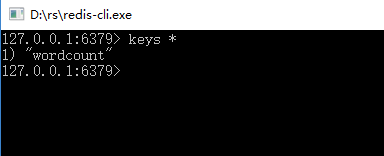
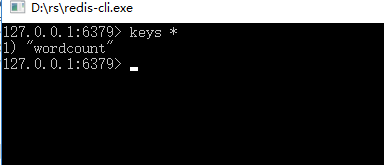
运行 redis-cli.exe
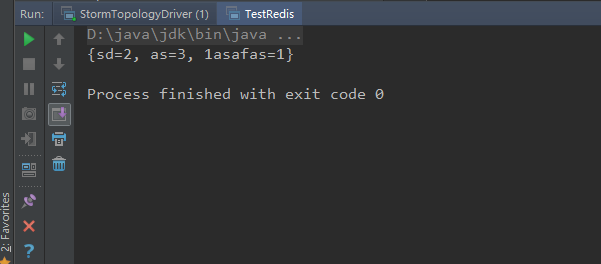
启动TestRedis.java
大数据学习——Storm+Kafka+Redis整合的更多相关文章
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习——Storm学习单词计数案例
需求:计算单词在文档中出现的次数,每出现一次就累加一次 遇到的问题 这个问题是<scope>provided</scope>作用域问题 https://www.cnblogs. ...
- 大数据学习——本地安装redis
下载安装包 https://github.com/MicrosoftArchive/redis 下载后解压 运行cmd 然后到redis路径 运行命令: redis-server redis.wind ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
随机推荐
- html 手机端click 事件延迟问题(fastclick.js使用方法)
下载地址: fastclick.js 为什么存在延迟? 从点击屏幕上的元素到触发元素的 click 事件,移动浏览器会有大约 300 毫秒的等待时间.为什么这么设计呢? 因为它想看看你是不是要进行双击 ...
- log4j2 日志框架小记
这两天开始学习日志框架了, 把常用的学习一下,记录一下.上篇日志写了log4j-----https://www.cnblogs.com/qiaoyutao/p/10995895.html今天就总结一下 ...
- Perl的Notepad++环境配置
Notepad++打开pl文件F5录入命令分别保存. Run_Perl(F9): cmd /k F:\Strawberry\perl\bin\perl.exe -w "$(FULL_CURR ...
- CF1066E Binary Numbers AND Sum
思路: 模拟.实现: #include <iostream> using namespace std; ; ], b[]; ]; int main() { int n, m; while ...
- IOS自动化测试之UIAutomation
通过Xcode工具编写运行测试脚本 1.当你有了一个应用的源代码之后,在Xcode工具中,首先选中被测应用,然后点击菜单栏中的“Product-Profile”,则会弹出Instruments工具,在 ...
- C#调用CMD程序
最近写了两个小程序都要调用Windows自带的命令行程序,一个是调用Openfiles.exe查询正在编辑的共享文档,一个是调用DiskPart.exe查询硬盘状态.两种命令行程序调用有点不同,记录一 ...
- shell批量转换iOS和Android图标
icon_ios.sh #!/bin/sh convert icon-1024.png -resize 180x180 icon-180@3x.png convert icon-1024.png -r ...
- 什么是闭包(Closure)?
http://kb.cnblogs.com/page/111780/ 这个问题是在最近一次英格兰Brighton ALT.NET Beers活动中提出来的.我发现,如果不用代码来演示,你很难单用话语把 ...
- TCP的三次握手与四次挥手详解
TCP的三次握手与四次挥手是TCP创建连接和关闭连接的核心流程,我们就从一个TCP结构图开始探究中的奥秘 序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序 ...
- 二、pandas入门
import numpy as np import pandas as pd Series: #创建Series方法1 s1=pd.Series([1,2,3,4]) s1 # 0 1 # 1 2 # ...