Google论文BigTable拜读
这周少打点dota2,争取把这篇论文读懂并呈现出来,和大家一起分享。
先把论文搞懂,然后再看下和论文搭界的知识,比如hbase,Chubby和Paxos算法。
Bigtable: A Distributed Storage System for Structured Data
大表:用于结构化数据的分布式存储系统
怎么样,"大表"这个翻译是不是很屌。
Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach
Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber
ffay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruberg@google.com
Google, Inc.
摘要
Bigtable是一个用于管理结构化数据的分布式存储系统,它被设计为可以扩展到非常大的规模:可在数千台商用机上存储PB级的数据。Google中的很多应用都采用Bigtable来存储数据,包括网页的索引,Google地球以及Google金融。这些应用对Bigtable提出了很多不同的需求,不论是数据的大小(从URLs到网页再到卫星图像)还是延迟需求(从后端批处理到实时数据服务)。即使外部有这么多不同的需求,Bigtable依然成功地为所有的这些Google产品提供了灵活的,高性能的解决方案。在本文中,我们描述Bigtable提供的简单数据模型,这种模型赋予了客户端对数据布局以及格式化上的动态控制,然后我们对Bigtable的设计以及实现进行了描述。
注意这里设计一个数据模型
1 引言
在过去的两年半中,我们设计,实现并部署了被称之为Bigtable的分布式存储系统来管理Google的结构化数据。Bigtable被设计为能够扩展至PB级的数据和数千台机器上。Bigtable已经实现了如下的几个目标:普适性,可扩展性,高性能以及高可用。Bigtable在Google中已经被用于超过60个产品以及项目,包括Google Analytics,Google Finance,Orkut,Personalized Search,Writely以及Google Earth。这些产品使用Bigtable来满足不同需求的工作负载,从面向吞吐量的批处理任务到提供给终端用户的对延迟敏感的数据服务。这些产品使用的Bigtable集群的配置各有不同,从少数到几千台服务器,并且存储了多达数百TB的数据。
Bigtable在很多方面都表现得像一个数据库:它和数据库有很多相同的实现策略。并行数据库和主存数据库实现了可扩展性和高性能,但是Bigtable相比于这些系统提供了不同的接口。Bigtable并不支持所有的关系型数据模型;而是为客户端提供了一种简单的数据模型来支持对数据布局以及格式上的动态控制,并且允许客户端探究在底层存储的数据的局部属性。数据通过行来建立索引并且列的名字可以是任意的字符串。Bigtable也将数据当做未解释的字符串,虽然客户端经常会将各种不同形式的结构化和半结构化的数据序列化为字符串。客户端可以通过在模式上的仔细选择来控制它们数据的局部属性。最终,Bigtable的模式参数让客户端动态控制是从内存还是从磁盘提供数据。
第2部分更加详细地描述了数据模型,第3部分则提供了对客户端API的概览。第4部分简要地描述了Bigtable所依赖的底层的Google基础架构。第5部分描述了Bigtable实现的基本原理,第6部分则描述了一些对于提高Bigtable性能所做的优化。第7部分提供了对于Bigtable性能的度量。我们在第8部分描述了几个例子用于说明Bigtable在Google中是如何使用的,并且在第9部分讨论了一些我们在设计以及支持Bigtable时所学习到的经验。最后在第10部分描述了一些相关的工作,在第11部分对本文进行了总结。
2 数据模型
Bigtable是一个稀疏的,分布式的,永久存储的多维排序的映射。这个映射是通过行键,列键以及一个时间戳来索引的;在这个映射中的每个值都是未解释的字节数组。
(row:string,column:string,time:int64)→string
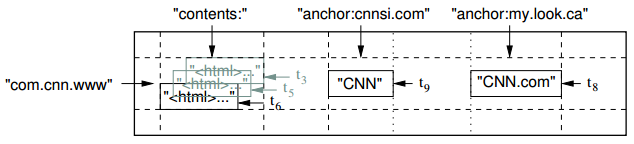
图1:一个用于存储网页的示例表的片段。行的名字是一个翻转的URL。内容列族包含了页的内容,anchor列族包含了任何引用这个页面的anchors。CNN的主页同时被Sports Illustrated和MY-look主页所引用,因此行包含了名为anchor:cnnsi.com以及anchor:my.look.ca的列。每个anchor单元格都有一个版本;内容列在时间戳t3,t5和t6的三个版本。
我们是在考虑了很多潜在的类似于Bigtable的这种系统之后敲定了这种数据模型的。作为驱动我们某些设计决策的具体例子,假设我们想要对很多的网页和可以被很多不同系统所使用的相关信息进行一个拷贝;我们首先称这种特殊的表叫做Webtable。在这个Webtable中,我们会使用URLs作为行的键,网页的很多不同部分作为列名,并且在content中存储网页的内容:就像图1所示的那样,我们是按照时间戳来取出网页的内容的。
行
在一个表中的行键是任意的字符串(目前为止最大可以有64KB,对于我们的用户来说通常的大小是10-100字节)。每次对于单个行的键进行读写都是原子性的(不论一个行中的多数个列被读和写),这个设计决策可以使得客户端能够在并发对同一行进行修改地时候探究系统的性能。
Bigtable通过行键以字典序来存储数据。在表中行的范围是可以动态分区的。每个行的范围都被称为tablet,这个也是分布式和负载均衡的单位。结果,短的行范围数据的读取效率都很高,通常只需要和少量的机器进行通讯。客户端可以通过选择它们的行键来利用这种属性,从而可以对它们数据的访问可以获得更好的局部性。例如,在Webtable中,通过将URLs中的主机名进行反转可以将相同域名中的网页分组成相邻的行。例如,我们会在com.google.maps/index.html的键下面存储map.google.com/index.html的数据。将网页存储到每个都邻近的相同的域可以使得某些主机和域的分析更加高效。
列族
列键都被分组到了一个被称为列族的集合中,形成了权限控制的基本单位。在列族中存储的数据通常类型都是相同的(我们会对相同列族中的数据进行压缩)。一个列族必须在在列族中任何列键可以存储之前创建;一个列族被创建之后,列族中的任何列键都可以被使用。我们的目的是让一个表中的列族个数少一点(最多有数百个),并且列族在操作的时候很少回去改变。相反,一个表可能会有无数多个列。
列的命名形式是采用如下的语法:family:qualifier。列族的名字必须是可打印的,而标识符则可以是任意的字符串。对于Webtable的一个实例的列族名字可以使language,这个列中存储的是这个网页所使用的语言。我们仅仅使用language族中的一个列键,而这一列存储的是网页的language ID。另一个对这个表有用的列族是anchor;在这个组中的每个列键都表示单一的anchor,就像图1中描绘的那样。标识符是引用的站点的名字;而单元格中的内容时链接的文本。
权限控制和磁盘以及内存审计都是在列族水平。在我们的Webtable的例子中,这种控制允许我们管理不同类型的应用:有些是增加新的基础数据,有些是读取并且创建派生的列族,而有些则只允许查看已经存在的数据(而且由于隐私原因甚至可能不会允许其查看所有的已经存在的列)。
时间戳
在Bigtable中的每个单元格都会包含有相同数据的多个版本;这些版本都是通过时间戳来进行索引的。Bigtable的时间戳是64位的整数。它们可以被Bigtable赋值,它们代表以毫秒为单位的真实时间或者通过客户端应用来明确地赋值。需要避免冲突的应用必须由它们自己生成唯一的时间戳。一个单元格中不同版本的数据是以时间戳降序排列的,因此最近的版本会最先读到。
为了减少带版本数据的管理繁重任务,我们支持了两个每个列族的设定,告诉Bigtable自动回收单元格的版本。客户端可以指定两个中的其中一个只持有最近n个版本的数据,或者只是足够新的版本数据保存下来(例如,只保留在最近七天的值)。
在我们的Webtable例子中,我们给保存在content的中的原始页设定时间戳:这些页实际被爬取的时间。上面所描述的垃圾回收机制会让我们保留每个页面最近三个版本的数据。
3 API
Bigtable的API提供了创建和删除表以及列族的功能。同时它也提供了改变诸如访问控制权限等集群,表和列族等元数据的功能。
客户端应用可以写或者删除Bigtable中的值,从单独的行中查找值,或者遍历表中的某个子集。图2展示了使用RowMutation抽象方法来进行一系列更新的C++代码。(删除了不相关的代码使例子看起来更短一些。)对于Apply的调用对Webtable执行了一个原子性变更:它向www.cnn.com增加了一个新的anchor并且删除了一个不同的anchor。

图3演示了使用抽象方法Scanner来遍历某个行中的所有anchors。客户可以遍历多个列族,并且有一些机制可以用来限定某些行,列以及浏览产生的时间戳。例如,我们可以将浏览限定在正则表达式anchor:*.cnn.com所匹配到的anchor的列,或者找到时间戳在当前时间10天以内的时间戳。

Bigtable支持几种其他允许用户以更复杂的方式来操作数据的特性。第一,Bigtable支持单行的事务,可以用来执行在单个行键上的数据的读-修改-写序列。Bigtable并不支持在多个行上的一般的事务,虽然对客户端提供了在多个行上写数据的接口。第二,Bigtable允许单元格用作整数的计数器。最后,Bigtable支持在服务器的地址空间执行客户端提供的脚本。这些脚本可以使用Google为数据处理而开发的Sawzall语言来编写。同时,我们的Sawzall API并不允许客户端的脚本写回Bigtable,但是它允许不同形式的数据变换,根据根据任意的表达式过滤和通过一系列操作符进行概括。
Bigtable可以和Google的大规模并发计算框架MapReduce结合使用。我们编写了一条封装器允许Bigtable用作MapReduce的输入或者输出目标。
4 构建块
Bigtable是构建在几个其他的Google基础设施之上的。Bigtable使用分布式的Google File System来存储日志以及数据文件。一个Bigtable集群通常会对运行着很多其他分布式应用的机器进行操作,Bigtable进程经常和其他的应用共享相同的机器。Bigtable依赖于一个集群管理系统来调度任务,管理共享机器上的资源,处理机器失效情况以及监控机器的状态。
在内部我们使用Google SSTable文件格式来存储Bigtable数据。SSTable提供从keys到values的持久的有序不可变的映射,其中键和值都是任意字节的字符串。提供了用于查找和一个特定的键相关的值的操作,以及遍历指定键范围内的键值对。在内部,SSTable会包含一个块序列(一般来说每个块都是64KB大小,但是这个值是可以配置的)。块索引(存储在SSTable的末端)被用来定位块;当SSTable被打开的时候,块索引就会被导入到内存中。在单次的磁盘搜索可以执行一次查找:我们可以首先通过二分搜索在内存索引中找到合适的块,让后从磁盘中读入合适的块。或者,一个SSTable可以完全映射到内存中,这样我们不用接触磁盘便可以完成查找了。
Bigtable依赖于Chubby所提供的高可用的以及持久分布的锁服务。Chubby服务包含了5个活跃的备份,其中一个被选举为主节点并活跃地响应外部请求。当大部分的备份都在运行并且相互之间可以通信的时候服务时可用的。Chubby使用Paxos算法来处理失效时备份的一致性。Chubby提供了包含目录和少量文件的命名空间。每个目录或者文件都可以当做一个锁来用,并且读写一个文件都是原子性的。Chubby客户端库提供了Chubby文件的一致性的缓存。每个Chubby客户端维护了一个Chubby服务的回话。如果一个客户端不能再租赁的过期时间内续租续租会话租赁的话,那么客户端的租赁就会过期了。当一个客户端会话过期,它会丢失所有的锁以及打开的句柄。Chubby客户端同样可以对Chubby的文件和目录注册回调事件用于变更的通知和会话的过期。
Bigtable使用Chubby来完成一系列的任务:来保证最多只有一个活跃的主节点;来存储Bigtable数据的启动位置(见5.1节);来发现tablet服务以及终结tablet服务(见5.2节);来存储Bigtable的模式信息(每个表的列族信息);以及存储访问控制列表。如果Chubby在某个时间段内变得不可用了,Bigtable也会不可用。我们最近在用11个Chubby实例的14个Bigtable集群测试了这种影响。由于Chubby的不可用(由于Chubby停电或者网络问题)导致了Bigtable上存储的数据的不可用的百分比为0.0047%。单个集群因Chubby不可用受到的最大影响的百分比为0.0326%。
5 实现
Bigtable的实现有三个主要的部分:连接到每个客户端的库,一个主节点服务器和很多的tablet服务器。tablet服务器可以被动态地添加或者从集群中删除来调整网络的负载。
master负责将tablet分配到tablet服务器上,检测tablet服务器的增加和过期,平衡tablet服务器的负载以及对GFS上的文件进行垃圾回收。除此之外,它还会处理例如表和列族创建之类的模式改变。
每个tablet服务器会管理一套tablets(一般来说每个tablet上会有数十个到数千个tablets)。tablet服务器会处理对它所负载的tablets的读和写请求,同样也会分割增长得太大的tablets。
和很多的单个主节点分布式存储系统一样,客户端的数据并不会通过主节点进行传输:客户端会直接和tablet服务器进行通信来读写。因为Bigtable客户端并不依赖于master来获取tablet的定位信息,大部分的客户端都从来不和主节点通信。结果,使得master实际上的负载很轻。
Bigtable集群会存储很多的表。每个表都会包含一套tablets,并且每个tablet包含了和了某个行中的所有数据。最开始,每个表仅包含一个tablet。随着表的增长,它会自动地划分成多个tablets,每个的大小默认是100-200MB。
5.1 Tablet的位置
我们使用类似于B+树的三层结构来存储tablet的位置信息(图4)。
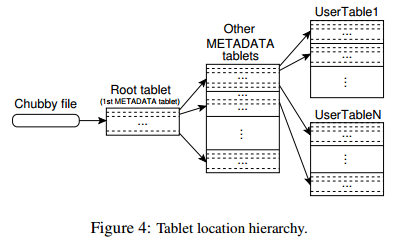
第一层是存储在Chubby中包含了root tablet的位置的文件。root tablet包含了在特殊元数据表中所有的tablets。每个元数据tablet包含了一套用户tablets。root tablet只是元数据表中的第一个tablet,但是它处理的方式比较特别——它从来都不会被分割——来确保tablet的位置结构不会超过三层。
元数据表存储了一个编码到tablet的表标识符到结束行的tablet的位置。每个METADATA行在内存中存储了大概1KB的数据。METADATA tablet的限制为128MB的时候,我们的三层结构的位置模式足够寻址2^34个tablets(或者在128MB中的2^61个字节)。
客户端的库会缓存tablet的位置。如果客户端不知道tablet的位置,或者如果它发现了缓存位置的信息不正确,那么它会递归地移向tablet位置结构的顶端。如果客户端的缓存为空,那么位置算法需要三次网络往返,包括一次从Chubby中的读。如果客户端的缓存成就了,寻址算法会花费6次往返,因为过时的缓存条目仅仅是在缺失的时候才会被发现(假设METADATA tablets并不会移动得很频繁)。虽然tablet的位置是存放在内存中,因此不需要GFS的访问,我们会通过让客户端库来预读取tablet的位置来减少这种公共的开销:不管什么时候它需要读取METADATA表,它都会从超过一个tablet中读取metadata。
我们同样也会在METADATA table中存储辅助信息,包括涉及到每个tablet的所有事件的日志(例如一个服务器开始提供服务的时候)。这些信息对于调试和性能分析十分有用。
5.2 Tablet的分配
每个tablet会在某个时间分配到一个tablet服务器上。主节点会跟踪存活的tablet服务器的集合以及当前的tablets服务器上分配的tablets,还有那些未分配的tablets。
Bigtable使用Chubby来跟踪tablet服务器。当一个tablet启动的时候,它会从一个指定的Chubby目录中的唯一命名的文件中获取一个排他锁。主节点会监测这个目录(服务器目录)来发现tablet服务器。一个tablet服务器会在它丢失它的排他锁的时候停止服务:比如,由于网络分区造成的服务器丢失了它的Chubby会话。(Chubby提供了一个高效地机制来允许tablet服务器在不引起网络拥塞的情况下来检查它是否持有它的锁。)一个tablet服务器将试图重新获取在它的文件上的排他锁只要它的文件仍旧存在。如果文件不再存在,那么tablet服务器将再也不能提供服务了,然后它会自杀。只要一个tablet服务器终结了(例如,因为集群管理系统将tablet服务器从集群中移走了),它就会试图释放它的锁使主节点将会更快地重新分配它的tablet。
主节点负责检测是否tablet服务器不再对外提供tablets以及尽可能快地重新分配tablets。为了检测tablet服务器不再对外提供tablets了,主节点会周期性地询问每个tablet服务器的锁状态。如果一个tablet服务器报告它已经丢失了它的锁,或者如果主节点不能在最近的几次尝试中连到服务器,主节点就会试图获取在服务器文件上的一个排他锁。如果主节点能够获得那个锁,那么Chubby就是存货的,那么tablet服务器要么是已经挂掉了要么是连接Chubby的时候有问题,因此主节点就会通过删除它的服务器文件来确保它不会再提供服务了。一旦服务器文件被删除了,主节点会移走所有的之前分配的tablets,服务器上的tablets也变成未分配的状态。为了确保Bigtable集群不容易受到主节点和Chubby之间网络问题的影响,主节点会在Chubby会话过期的时候杀死自己。然而,就像之前描述的那样,主节点的失效并不会改变tablet服务器中tablets的分配。
当主节点被集群管理系统启动之后,它需要在改变tablet分配之前先发现它们。主节点会在启动的时候执行如下的步骤。
(1)主节点会抓取Chubby上唯一的主节点锁,这个唯一锁可以防止并发的主节点实例。
(2)主节点会浏览Chubby的服务器目录来寻找存活的服务器。
(3)主节点和每个存货的tablet服务器通信来发现每个服务器上已经分配了哪些tablets。
(4)主节点会浏览METADATA表来了解tablets集合。不管在什么时候只要发现了一个还未被分配的tablet,master会将这个tablet加入到未分配的集合中,使其在tablet分配的时候是合格的。
有一个复杂的地方是知道METADATA tablets被分配之后才能够扫描METADATA表。因此在开始扫描之前(步骤4),主节点如果在步骤3中没有发现root tablet的分配的话就要将root tablet加入到未分配的节点中。这个添加可以确保root tablet会被分配。因此root tablet含有所有的METADATA tablets的名字,主节点知道在扫描了root tablet之后就全都知道了。
只有在table创建或者删除的时候已经存在的tablets集合才会改变,两个已经存在的tablets会合并成一个更大的tablet,或者一个已经存在的tablet会分割成两个较小的tablet。主节点能够跟踪所有的这些改变因为它会初始化除了最后一个的其他部分。tablet的分隔比较特殊因为它是由tablet服务器初始化的。tablet服务器通过为METADATA表中的新的tablet记录数据来完成tablet的分割。当分割完成后,它会通知主节点。一旦分割的通知丢失了(tablet服务器死掉了或者主节点死掉了),主节点会让tablet服务器加载分割出来的tablet从而检测到新的tablet。tablet服务器将会通知master分割,因为因为它在METADATA表中发现的tablet条目只是指定了master让它加载的一部分。
5.3 Tablet Serving
tablet的永久状态就像图5那样,是存储在GFS中的。更新操作写入到存储重做记录的日志中。在这些更新中,最近提交的会以被称作memtable的形式有序buffer存储到内存中;早期的更新都是存放在SSTable的序列中。为了恢复一个tablet,tablet服务器会从METADATA表中读取它的元数据。
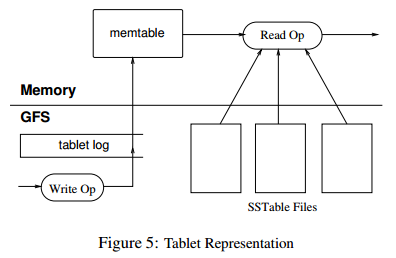
这个metadata包含构成tablet以及一系列重做点的SSTables列表,都是指向任何包含了tablet数据的提交日志的指针。服务器会把SSTables的分片读到内存中然后通过应用重做点之后的提交的更新来重新构建memtable。
当一个写操作到达了tablet服务器之后,服务器会检查它是否是格式良好的,以及发送者是否有权执行变更。授权可以通过从Churry文件中读取许可的写名单列表(大多都是缓存在Chubby客户端的热点数据)。一次有效的变更通常会写到提交日志。组提交通常用于提交每次小变更的吞吐量。写操作被提交之后,它的内容会被插入到memtable中。
当一个读操作叨叨了tablet服务器之后,类似地会检查格式时候良好以及是否有合适的权限。一次有效的读操作会在合并的SSTables序列和memtable上执行。由于SSTable和memtable都是按照字典序排列的数据结构,合并的视图可以非常高效地形成。
以后的读和写操作可以在tablets被分割和合并的时候继续。
5.4 Compactions
随着写操作的执行,memtable的尺寸也会变得越来越大。当memtable的尺寸达到了一定的阈值之后,memtable就会被冻住,然后去创建一个新的memtable,被冻住的memtable就会转变为SSTable并写入到GFS。这种微小的压缩过程有两个目标:首先它可以缩小tablet服务器的内存使用,第二它可以减少在服务器挂掉而需要回复时从提交日志读取的数据量。在压缩结束之后可以进行以后的读和写操作。
每次小的压缩都会创建一个新的SSTable。如果这种行为一直是未检查的状态,读操作可能需要从任意的SSTable合并更新。而我们则是通过周期性的在后台执行合并压缩来限制这类文件的数量。合并压缩读少量的SSTable以及memtable,并且写入新的SSTable。输入的SSTable和memtable的数据可以在压缩完成之后忽视。
重写所有的SSTable到另一个SSTable的合并压缩被称为major compaction。由非major compaction产生的SSTable可以包含特别的删除条目来抑制在老的SSTable中已经删除但是仍旧存活的数据。major compaction另一个方面不会包含删除信息或者删除的数据。Bigtable遍历所有的tablets并且正常地对它们施加major compaction。这些major compaction允许Bigtable回收已删除数据占用的资源,并且允许它确保已删除的数据从系统中及时的消失,这对于存储敏感数据的服务很重要。
6 改进
(看完改进休息一下,边翻边理解好累啊)
上面部分描述的实现需要一些优化才能达到我们用户所需要的高性能,高可用以及高可靠性的目标。这部分会更加详细地描述一些为了达到这些目标所做的改进。
局部组
客户端对多个列族组成一个局部组。在每个tablet中的每个局部组都可生成一个单独的SSTable。分离的列族一般不能够一起访问,但是局部组则可以有更高的读效率。例如,在Webtable中的页元数据可以在某个局部组中,页的内容可以在一个不同的组中:那些想要读取元数据的应用并不需要通过读取所有的页的内容来读取。
除此之外,可以在局部组的基础上指定一些调优的参数。例如,局部组可以声明放在内存中。内存中的局部组SSTables可以懒加载到tablet服务器的内存中。一旦加载之后,属于哪个局部组的列族就可以不同过磁盘读取。这种特性对于需要经常访问的小碎片的数据十分有用:我们在内部使用它作为METADATA表的本地列族。
压缩
提高读性能的缓存
布隆过滤器
提交日志的实现
加速tablet的恢复
利用不可变性
7 性能评估
8 实际应用
9 经验
10 相关工作
11 结论
鸣谢
参考文献
Google论文BigTable拜读的更多相关文章
- Google论文之三----MapReduce
Google论文之三----MapReduce MapReduce:大型集群上的简单数据处理 摘要 MapReduce是一个设计模型,也是一个处理和产生海量数据的一个相关实现.用户指定一个用于处理一个 ...
- 转:Google论文之一----Bigtable学习翻译
文章来自于:http://www.cnblogs.com/geekma/archive/2013/05/30/3108391.html Bigtable研究 摘要 Bigtable是一个用于管理结构型 ...
- [转]云计算研究必备——精典Google论文
Google云计算技术奠定其在业界的领先地位,收集经典云计算技术公开文章供大家研究学习: 01)GFS-The Google File System 02) Bigtable - A Distribu ...
- google 论文
从google历年所有论文的汇总来看,TOP5的分别是人工智能和机器学习.算法理论.人机交互与视觉.自然语言处理.机器感知,大家从一个侧面看出goolge research的重点了吧. Google所 ...
- Google论文系列(2) MapReduce
思想 map函数:处理一组key/value对进而生成一组key/value对的中间结果 reduce函数:将具有相同Key的中间结果进行归并 实现 环境 普通带宽,上千台机器(失败变得正常),廉价硬 ...
- Google论文(1) GFS:Google文件系统 - 思维导图
Google文件系统是一个面向大规模分布式数据密集型应用的可扩展分布式文件系统. 这里的思维导图作为个人的读书笔记. 参考资料: <google系列论文>- GFS
- Google的Bigtable学习笔记(不保证正确性)
跪求各路大侠指正:1.首先是一个列式存储的简单数据模型的数据库,它比键值对模型/文档模型NoSQL数据库复杂点(也就更强一点).2.它的分布式存储性能依靠于GFS也就对单机房网络有硬性指标.3.它同时 ...
- 转:Google论文之三----MapReduce
文章来自于:http://www.cnblogs.com/geekma/p/3139823.html MapReduce:大型集群上的简单数据处理 摘要 MapReduce是一个设计模型,也是一个处理 ...
- 转:Google论文之二----Google文件系统(GFS)翻译学习
文章来自于:http://www.cnblogs.com/geekma/archive/2013/06/09/3128372.html 摘要 我们设计并实现了Google文件系统,它是一个可扩展的分布 ...
随机推荐
- Bzoj2829 信用卡凸包
Time Limit: 10 Sec Memory Limit: 128 MBSec Special JudgeSubmit: 333 Solved: 155 Description Input ...
- java网络编程学习笔记(一)
1.进程之间的通信 进程是指运行中的程序,进程的任务就是执行程序中的代码. 存在计算机网络上的两个进程只需要关注它们通信的具体内容,而不需关注消息在网络上传输的具体细节. 2.计算机网络的概念 Int ...
- 此时不应有 \Microsoft (转)
原文转自 http://www.tuicool.com/articles/J7RFRz 下载boost库后,在cmd中运行bootstrap.bat ,输出 "此时不应有 \Microsof ...
- python print的参数介绍
参考print的官方文档 print(...) print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False) Prints th ...
- Python学习杂记_4_分支和循环
分支 和 循环 分支和循环这俩结构在各语言中都有着很重要的地位,当然我之前都没有学好,这里总结一下在Python学习中对这俩结构的认识. 分支结构 # 单分支 if 条件判断: 执行语句… # 双分支 ...
- java模拟一次简单的sql注入
在数据库中生成 一个用户表 有用户名 username 和密码password 字段 并插入两组数据 正常的sql查询结果 非正常查询途径返回的结果 下面用一段java代码 演示一下用户登录时的sq ...
- js中click重复执行
问题背景:在写一个非常简单添加方法的时候,用onclick事件调用添加方法,点击第一次没问题,第二次会重复执行,经过多次查找资料得知这个状况的解决方案,特意总结一下: 代码如下:点击#spec_for ...
- (5)ASP.NET HTML服务器控件
工具箱 与服务端交互 <body> <form id="form1" runat="server"> <div> <% ...
- 利用Django徒手写个静态页面生成工具
每个Geek对折腾自己的博客都有着一份执念 背景介绍 曾经多次在不同的平台写博客,但全部都以失败而告终.去年七月选择微信公众号做为平台开始了又一次的技术分享,庆幸一直坚持到现在,但随着文章发表的越来越 ...
- 基于WPF系统框架设计(10)-分页控件设计
背景 最近要求项目组成员开发一个通用的分页组件,要求是这个组件简单易用,通用性,兼容现有框架MVVM模式,可是最后给我提交的成果勉强能够用,却欠少灵活性和框架兼容性. 设计的基本思想 传入数据源,总页 ...