学习笔记(三): Generalization/Overfitting/Validation
目录
Generalization: Peril of Overfitting
Low loss, but still a bad model?
How Do We Know If Our Model Is Good?
What If We Only Have One Data Set?
Generalization: Peril of Overfitting
- Develop intuition about overfitting.
- Determine whether a model is good or not.
- Divide a data set into a training set and a test set.
Low loss, but still a bad model?

The model overfits the peculiarities of the data it trained on.
An overfit model gets a low loss during training but does a poor job predicting new data.
Overfitting is caused by making a model more complex than necessary.
The fundamental tension of machine learning is between fitting our data well, but also fitting the data as simply as possible.
How Do We Know If Our Model Is Good?
- Theoretically:
- Interesting field: generalization theory
- Based on ideas of measuring model simplicity / complexity
- Intuition: formalization of Occam's Razor principle
- The less complex a model is, the more likely that a good empirical result is not just due to the peculiarities of our sample
- Empirically:
- Asking: will our model do well on a new sample of data?
- Evaluate: get a new sample of data-call it the test set
- Good performance on the test set is a useful indicator of good performance on the new data in general:
- If the test set is large enough
- If we don't cheat by using the test set over and over
The ML Fine Print
Three basic assumptions
- We draw examples independently and identically (i.i.d.独立同分布) at random from the distribution
- The distribution is stationary: It doesn't change over time
- We always pull from the same distribution: Including training, validation, and test sets
In practice, we sometimes violate these assumptions. For example:
- Consider a model that chooses ads to display. The i.i.d. assumption would be violated if the model bases its choice of ads, in part, on what ads the user has previously seen.
- Consider a data set that contains retail sales information for a year. User's purchases change seasonally, which would violate stationarity.
When we know that any of the preceding three basic assumptions are violated, we must pay careful attention to metrics.
Summary
Overfitting occurs when a model tries to fit the training data so closely that it does not generalize well to new data.
- If the key assumptions of supervised ML are not met, then we lose important theoretical guarantees on our ability to predict on new data.
Glossay
generalization:refers to your model's ability to adapt properly to new, previously unseen data, drawn from the same distribution as the one used to create the model.
overfitting:occurs when a model tries to fit the training data so closely that it does not generalize well to new data.
stationarity:A property of data in a data set, in which the data distribution stays constant across one or more dimensions. Most commonly, that dimension is time, meaning that data exhibiting stationarity doesn't change over time. For example, data that exhibits stationarity doesn't change from September to December.
- training set:The subset of the data set used to train a model.
- validation set:A subset of the data set—disjunct from the training set—that you use to adjust hyperparameters.
- test set:The subset of the data set that you use to test your model after the model has gone through initial vetting by the validation set.
Training and Test Sets
- Examine the benefits of dividing a data set into a training set and a test set.
What If We Only Have One Data Set?
- Divide into two sets:
- training set
- test set
- Classic gotcha: do not train on test data
- Getting surprisingly low loss?
- Before celebrating, check if you're accidentally training on test data
Splitting Data
Make sure that your test set meets the following two conditions:
- Is large enough to yield statistically meaningful results.
- Is representative of the data set as a whole. In other words, don't pick a test set with different characteristics than the training set.
Assuming that your test set meets the preceding two conditions, your goal is to create a model that generalizes well to new data. Our test set serves as a proxy for new data.
For example, consider the following figure. Notice that the model learned for the training data is very simple. This model doesn't do a perfect job—a few predictions are wrong. However, this model does about as well on the test data as it does on the training data. In other words, this simple model does not overfit the training data.
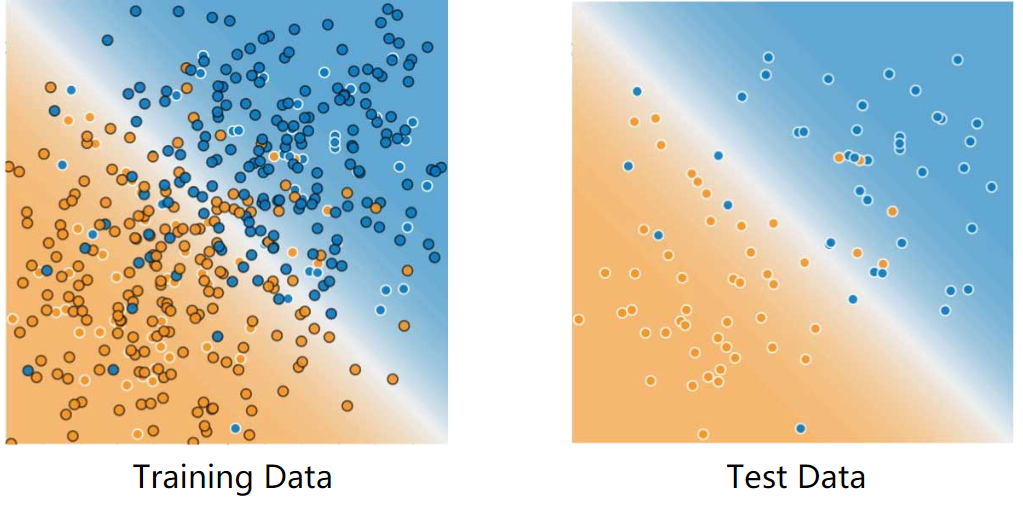
Never train on test data. If you are seeing surprisingly good results on your evaluation metrics, it might be a sign that you are accidentally training on the test set. For example, high accuracy might indicate that test data has leaked into the training set.
For example, consider a model that predicts whether an email is spam, using the subject line, email body, and sender's email address as features. We apportion the data into training and test sets, with an 80-20 split. After training, the model achieves 99% precision on both the training set and the test set. We'd expect a lower precision on the test set, so we take another look at the data and discover that many of the examples in the test set are duplicates of examples in the training set (we neglected to scrub duplicate entries for the same spam email from our input database before splitting the data). We've inadvertently trained on some of our test data, and as a result, we're no longer accurately measuring how well our model generalizes to new data.
Validation
Check Your Intuition
We looked at a process of using a test set and a training set to drive iterations of model development. On each iteration, we'd train on the training data and evaluate on the test data, using the evaluation results on test data to guide choices of and changes to various model hyperparameters like learning rate and features. Is there anything wrong with this approach? (Pick only one answer.)
- (F)This is computationally inefficient. We should just pick a default set of hyperparameters and live with them to save resources.
Although these sorts of iterations are expensive, they are a critical part of model development. Hyperparameter settings can make an enormous difference in model quality, and we should always budget some amount of time and computational resources to ensure we're getting the best quality we can.
- (T)Doing many rounds of this procedure might cause us to implicitly fit to the peculiarities of our specific test set.
Yes indeed! The more often we evaluate on a given test set, the more we are at risk for implicitly overfitting to that one test set. We'll look at a better protocol next.
- (F)Totally fine, we're training on training data and evaluating on separate, held-out test data.
Actually, there's a subtle issue here. Think about what might happen if we did many, many iterations of this form.
Validation
- Understand the importance of a validation set in a partitioning scheme.
Partitioning a data set into a training set and test set lets you judge whether a given model will generalize well to new data. However, using only two partitions may be insufficient when doing many rounds of hyperparameter tuning.
Another Partition
The previous module introduced partitioning a data set into a training set and a test set. This partitioning enabled you to train on one set of examples and then to test the model against a different set of examples.
With two partitions, the workflow could look as follows:
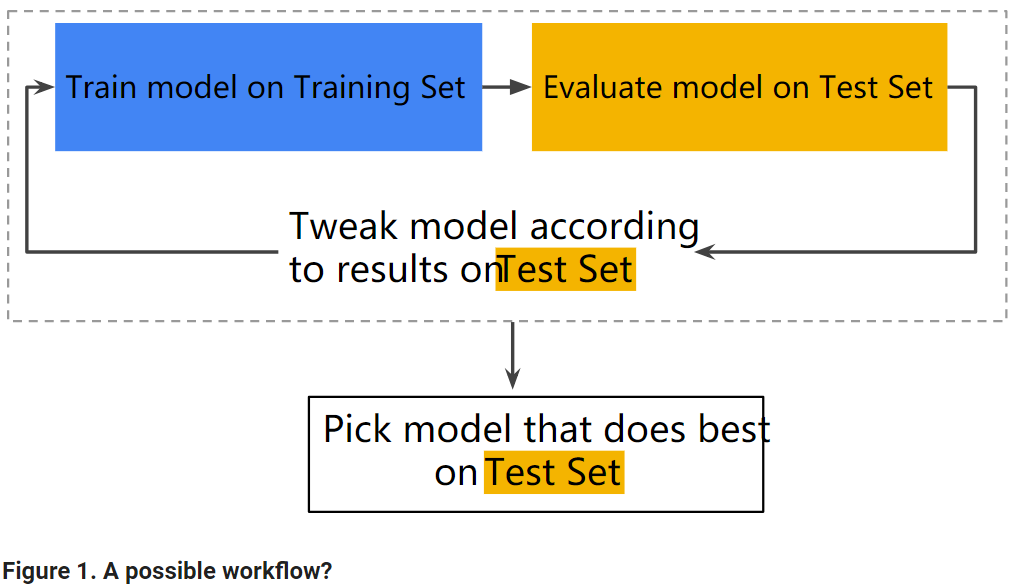
In the figure, "Tweak model" means adjusting anything about the model you can dream up—from changing the learning rate, to adding or removing features, to designing a completely new model from scratch. At the end of this workflow, you pick the model that does best on the test set.
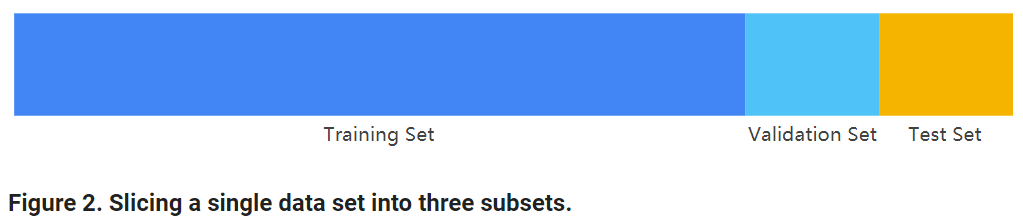
Dividing the data set into two sets is a good idea, but not a panacea. You can greatly reduce your chances of overfitting by partitioning the data set into the three subsets shown in the following figure:
Use the validation set to evaluate results from the training set. Then, use the test set to double-check your evaluation after the model has "passed" the validation set. The following figure shows this new workflow:
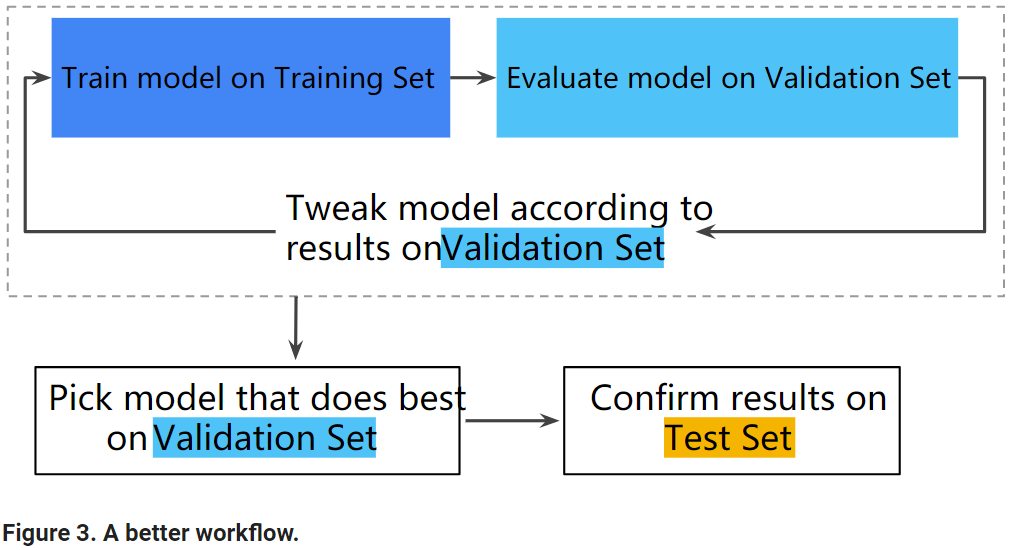
In this improved workflow:
- Pick the model that does best on the validation set.
- Double-check that model against the test set.
This is a better workflow because it creates fewer exposures to the test set.
Tip
- Test sets and validation sets "wear out" with repeated use. That is, the more you use the same data to make decisions about hyperparameter settings or other model improvements, the less confidence you'll have that these results actually generalize to new, unseen data. Note that validation sets typically wear out more slowly than test sets.
- If possible, it's a good idea to collect more data to "refresh" the test set and validation set. Starting anew is a great reset.
Programming Exercise
Learning Objectives:
- Use multiple features, instead of a single feature, to further improve the effectiveness of a model
- Debug issues in model input data
- Use a test data set to check if a model is overfitting the validation data
学习笔记(三): Generalization/Overfitting/Validation的更多相关文章
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- [Firefly引擎][学习笔记三][已完结]所需模块封装
原地址:http://www.9miao.com/question-15-54671.html 学习笔记一传送门学习笔记二传送门 学习笔记三导读: 笔记三主要就是各个模块的封装了,这里贴 ...
- JSP学习笔记(三):简单的Tomcat Web服务器
注意:每次对Tomcat配置文件进行修改后,必须重启Tomcat 在E盘的DATA文件夹中创建TomcatDemo文件夹,并将Tomcat安装路径下的webapps/ROOT中的WEB-INF文件夹复 ...
- java之jvm学习笔记三(Class文件检验器)
java之jvm学习笔记三(Class文件检验器) 前面的学习我们知道了class文件被类装载器所装载,但是在装载class文件之前或之后,class文件实际上还需要被校验,这就是今天的学习主题,cl ...
- VSTO学习笔记(三) 开发Office 2010 64位COM加载项
原文:VSTO学习笔记(三) 开发Office 2010 64位COM加载项 一.加载项简介 Office提供了多种用于扩展Office应用程序功能的模式,常见的有: 1.Office 自动化程序(A ...
- Java IO学习笔记三
Java IO学习笔记三 在整个IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换类. OutputStreamWriter:是Writer的子类,将输出的 ...
- NumPy学习笔记 三 股票价格
NumPy学习笔记 三 股票价格 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.&l ...
- Learning ROS for Robotics Programming Second Edition学习笔记(三) 补充 hector_slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Learning ROS for Robotics Programming Second Edition学习笔记(三) indigo rplidar rviz slam
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- Typescript 学习笔记三:函数
中文网:https://www.tslang.cn/ 官网:http://www.typescriptlang.org/ 目录: Typescript 学习笔记一:介绍.安装.编译 Typescrip ...
随机推荐
- 解决webSocke客户端连接服务端返回400错误
原因: nginx使用了转发,头信息没设置全,问题出现在nginx的配置文件 解决办法: 修改nginx.conf配置文件,在linux终端敲入vim /etc/nginx/nginx.conf,找到 ...
- 剑指Offer的学习笔记(C#篇)-- 不用加减乘除做加法
题目描述 写一个函数,求两个整数之和,要求在函数体内不得使用+.-.*./四则运算符号. 一 . 理解题目 这个题目可以让我们回归到小学,想想加法的竖式是怎么写的,哈哈,如果当时你不是那个竖式写错了, ...
- python 之 序列化与反序列化、os模块
6.6 序列化与反序列化 特殊的字符串 , 只有:int / str / list / dict 最外层必须是列表或字典,如果包含字符串,必须是双引号"". 序列化:将Python ...
- 6.Python初窥门径(小数据池,集合,深浅拷贝)
Python(小数据池,集合,深浅拷贝) 一.小数据池 什么是小数据池 小数据池就是python中一种提高效率的方式,固定数据类型,使用同一个内存地址 小数据池 is和==的区别 == 判断等号俩边的 ...
- 利用 Docker 包 Laradock 服务器部署 Laravel & ThinkSNS+ 等程序实战(多项目)
什么是ThinkSNS+ ThinkSNS(简称TS),一款全平台综合性社交系统,为国内外大中小企业和创业者提供社会化软件研发及技术解决方案,目前最新版本为ThinkSNS+.ThinkSNS V4. ...
- 概念端类型“xxx”中的成员“ID”的类型“Edm.Decimal”与对象端类型“xxx”中的成员“ID”的类型“System.Int64”不匹配
概念端类型“xxx”中的成员“ID”的类型“Edm.Decimal”与对象端类型“xxx”中的成员“ID”的类型“System.Int64”不匹配 使用EF实体模型映射之后将edmx中xml映射关系中 ...
- struts2.5+框架使用通配符与动态方法
概述:struts2.5以后加强了安全性,下面就是安全配置引发的问题 通配符: 在学习struts框架时经常会使用到通配符调用方法,如下: <package name="usercru ...
- Codeforces 1168C(二进制、dp)
要点 '&'操作暗示二进制上按位思考 对于y为1的位,要求x和y之间要至少有两个此位为1的(包含x.y),这样&起来才不是0.而这些位中只要存在一个是ok的即可 dp去求每个x的每个位 ...
- NET full stack framework
NFX UNISTACK 介绍 学习.NET Core和ASP.NET Core,偶然搜索到NFX UNISTACK,现翻译一下Readme,工程/原文:https://github.com/aumc ...
- standby checking script 3则 V1 shell 脚本
---1 #!/bin/sh export ORACLE_SID=hdbexport ORACLE_BASE=/db/hdbdg/app/product/databaseexport ORACLE_H ...