Scala编程 笔记
date: 2019-08-07 11:15:00
updated: 2019-11-25 20:00:00
Scala编程 笔记
1. makeRDD 和 parallelize 生成 RDD
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
makeRDD 最底层实现还是通过 parallelize 的方式,所以两种方式没有太大的区别。numSlices 是传入的切片数。
Scala 中的 Seq 相当于 Java 的 List,Scala 的 List 相当于 Java 的LinkedList
2. yield
for 循环中的 yield 会把当前的元素记下来,保存在集合中,循环结束后将返回该集合。Scala 中 for 循环是有返回值的。如果被循环的是 Map,返回的就是 Map,被循环的是 List,返回的就是 List,以此类推。
scala> val a = Array(1, 2, 3, 4, 5)
a: Array[Int] = Array(1, 2, 3, 4, 5)
scala> for (e <- a if e > 2) yield e
res1: Array[Int] = Array(3, 4, 5)
// 可以在 for 循环中添加 if 语句,进行过滤
def scalaFiles =
for {
file <- filesHere
if file.isFile
if file.getName.endsWith(".scala")
} yield file
3.函数和方法
首先有一个比较广泛的叫法规则是:
面向对象的语言叫方法 eg:Java
面对过程的语言叫函数 eg:C
对于 Java 而言,函数和方法一般都是一样的。
对于 Python 而言,分两种情况:
- 与类和实例无绑定关系的 function 叫做函数
- 与类和实例有绑定关系的 function 叫做方法
这里的绑定,我的理解是,调用参数中包含类或实例,并在 function 中对参数进行了赋值
对于 Scala 而言,分两种情况:
方法是一个以 def 开头的带有参数列表(可以无参数列表)的一个逻辑操作块,这正如 object 或者 class 中的成员方法一样
函数是赋值给一个变量(或者常量)的匿名方法(带或者不带参数列表),并且通过 => 转换符号跟上逻辑代码块的一个表达式。=> 转换符号后面的逻辑代码块的写法与 method 的 body 部分相同
4. List 的一些方法
Scala 的 seq = Java 的 List
Scala 的 List = Java 的 LinkedList
- mkString
- drop 丢弃前 n 个元素,返回新列表
- dropRight 丢弃最后 n 个元素,返回新列表
- head 返回第一个元素
- tail 返回所有元素,除第一个
- last 返回最后一个元素
- init 返回所有元素,除最后一个
- take 返回前 n 个元素
- takeRight 返回后 n 个元素
……
5. Map 的初始化
(key1 -> val1, key2 -> val2)
6. Set 和 Map
- 可变:修改集合本身
- 不可变:创建并返回一个新的集合
7. reduceLeft 和 reduceRight
val longestLine = lines.reduceLeft(
(a, b) => if(a.length > b.length) a else b
)
reduceLeft 会把自动把第一个、第二个的比较结果保存,再和第三个进行比较,以此类推,最后返回一个值。
eg:求和 求最大值等
array.reduceLeft(_ + _)
array.reduceLeft(_ max _)
reduceRight 会从尾部开始拿两个数据进行计算
val list = List(1,2,3,4,5)
list.reduce(_ - _) // -13
list.reduceLeft(_ - _) // -13
list.reduceRight(_ - _) // 3 先计算 4-5,然后是 3-(4-5) ...
8. Scala自带的特质: Application
object test extends Application {
...
}
特质 Application 声明了带有适合的签名的 main 方法,继承 Application 之后,可以把原先放在 main 方法中的代码直接放在单例对象的大括号之间,这样代码比显式的 main 会显得要短,但也存在几个缺点:
如果运行时有参数,那就必须得带有显式的 main 方法
如果程序是多线程的话,就需要显式的 main 方法
某些 JVM 的实现没有优化被 Application 特质执行的对象的初始化代码
9. 富包装器
代码 结果
0 max 5 5
-2.7 abs 2.7
-2.7 round -3L
1.5 isInfinity false
(1.0/0) isInfinity true
4 to 6 range(4, 5, 6)
"bob" capitalize "Bob"
"robert" drop 2 "bert"
10. 先决条件:precondition
在构造器中可以定义一个先决条件:对传递给方法或构造器的参数的值进行限制。
class Rational(n: Int, d: Int){
require(d != 0)
override def toString = n + "/" + d
}
require 方法会带一个布尔型参数。如果传入的值是真,require 会正常返回,并进行下面的操作。反之,require 会通过抛出 IllegalArgumentException 来阻止对象被构造。
11. 从构造器 auxiliary constructor
有时候一个类里面需要多个构造器,比如构造分数时,分子为1时就不需要传递分子这个参数
class Rational(n: Int, d: Int){
require(d != 0)
override def toString = n + "/" + d
def this(n: Int) = this(n, 1)
}
从构造器从 def this(...) 开始,几乎完全调用主构造器,直接传递主构造器的参数。
主构造器是类的唯一入口点。
12. 最大公约数 greatest common divisor
private def gcd(a: Int, b: Int): Int = if(b == 0) a else gcd(b, a % b)
13. 闭包
闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。
var factor = 3
val multiplier = (i:Int) => i * factor
14. for 循环
14.1 简单的循环
for(i <- 1 to 4) 1, 2, 3, 4
for(i <- 1 until 4) 1, 2, 3
14.2 在 for 循环中添加过滤器
for(
file <- files
if file.isFile;
if file.getName.endsWith(".scala")
) println(file)
如果添加超过一个过滤器,if字句必须用分号分隔。
14.3 嵌套枚举
def fileLines(file: java.io.File) = scala.io.Source.fromFile(file).getLines.tolist
def grep(pattern: String) = {
for{
file <- files
if file.getName.endsWith(".scala")
line <- fileLines(file)
if line.trim.mathces(pattern)
} println(file + ": " + line.trim)
}
grep(".*gcd.*")
14.4 创建新集合
for {字句} yield {循环体}
for 表达式在每次执行的时候都会产生一个值,在 for 表达式完成之后,返回的结果将是一个包含了所有产生的值的集合。结果集合的类型取决于枚举子句处理的结合类型。
15. 模式匹配
15.1 match 表达式
val firstArg = if (args.length > 0 ) args(0) else ""
firstArg match {
case "salt" => println("pepper")
case "chips" => println("salsa")
case "eggs" => println("bacon")
case _ => println("¿")
}
缺省情况用下划线说明,这是常用在 Scala 里作为占位符表示完全不清楚的值的通配符。
这段代码和 Java 的 switch 相比有几点不同:
- 任何类型的常量都可以用在 case 语句中,而不仅仅是 int 或是枚举类型。
- 每个 case 语句无需使用 break,Scala不支持 “fall through”。
- Scala 的缺省匹配为'_',其作用类似 Java 中的 default。
而最关键的一点是 Scala 的 match 表达式有返回值,上面的代码使用的是 println 打印,而实际上你可以使用表达式,比如修改上面的代码如下:
val firstArg = if (args.length > 0 ) args(0) else ""
val friend = firstArg match {
case "salt" => "pepper"
case "chips" => "salsa"
case "eggs" => "bacon"
case _ => "¿"
}
15.2 更多详情见32
16. 重复参数
Scala 允许指明函数的最后一个参数可以是重复的。这可以允许用户向函数传入可变长度参数列表。想要标注一个重复参数,在参数的类型之后放一个星号。
def echo(args: String*) =
for (arg <- args) println(arg)
echo()
echo("one")
echo("one", "two")
echo 函数里被声明为类型 String 的 args,传入到函数中的其实是 Array[String]。但是我们并不能直接传递给 echo 函数一个数组(数组中的每一个元素都是 String)。但是可以换成下面的写法:
var arr = Array("one", "two")
echo(arr: _*)
这个标注告诉编译器把 arr 的每个元素当作参数,而不是当作单一的参数传给 echo。
17. 尾递归
使用递归函数来消除需要使用 var 变量的 while 循环。下面为一个使用逼近方法求解的一个递归函数表达:
def approximate(guess: Double) : Double =
if (isGoodEnough(guess)) guess
else approximate(improve(guess))
通过实现合适的 isGoodEnough 和 improve 函数,说明这段代码在搜索问题中经常使用。 如果你打算 approximate 运行的快些,你很可能使用下面循环来实现什么的算法:
def approximateLoop(initialGuess: Double) : Double = {
var guess = initialGuess
while(!isGoodEnough(guess))
guess=improve(guess)
guess
}
从简洁度和避免使用 var 变量上看,使用函数化编程递归比较好。但是有 while 循环是否运行效率更高些?实际上,如果我们通过测试,两种方法所需时间几乎相同,这听起来有些不可思议,因为回调函数看起来比使用循环要耗时得多。
其实,对于 approximate 的递归实现,Scala 编译器会做些优化,我们可以看到 approximate 的实现,最后一行还是调用 approximate 本身,我们把这种递归叫做尾递归。Scala 编译器可以检测到尾递归而使用循环来代替。因此,你应该习惯使用递归函数来解决问题,如果是尾递归,那么在效率时不会有什么损失。
在函数最后一行调用自身时,不能再有任何其他操作,如果有其他的类似于 ±1 的操作的话就不算是尾递归。
Scala优化尾递归的方案:所有的调用将在一个框架内执行。
但也有其局限的地方:因为 JVM 指令集使实现更加先进的尾递归形式变得很难。Scala 仅优化了直接实现尾递归的函数。如果递归是间接的,如下面代码所示,那就没有优化的可能性了。
def isEven(x:Int): Boolean =
if(x==0) true else isOdd(x-1)
def isOdd(x:Int): Boolean=
if(x==0) false else isEven(x-1)
// 快速排序的例子
def quicksort(ls: List[Int]): List[Int] = {
if (ls.isEmpty)
ls
else
quicksort(ls.filter(_ < ls.head)) ::: ls.head :: quicksort(ls.filter(_ > ls.head))
}
18. exists
Scala 标准库中的一个高阶函数,可以用来替换一定的循环结构。
def containsOdd(nums: List[Int]): Boolean = {
var exists = false
for (num <- nums)
if(num % 2 == 1)
exists = true
exists
}
可以替换为:
def containsOdd(nums: List[Int]) = nums.exists(_ % 2 == 1)
19. Curry 柯里化
Curry化指的是:把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数。
def oldSum(x: Int, y: Int) = x + y
oldSum(1, 2)
经过 Curry 化后
def curriedSum(x: Int)(y: Int) = x + y
curriedSum(1)(2)
Curry 化的过程类似于以下过程:
def first(x: Int) = (y: Int) => x + y
val second = first(1)
second(2)
20. 大括号和小括号
Scala的任何方法在调用时,如果只传入一个参数,就能可选地使用大括号来代替小括号包围参数。
println("Hello, world!")
println{"Hello, world!"}
但是如果有2个及以上参数时,是不可以使用大括号的:
val g = "Hello, world!"
g.substring{7, 9} 错误
g.substring(7, 9) 正确
在传入一个参数时可以用大括号替代小括号的机制的目的是让客户程序员能写出包围在大括号内的函数文本。这可以让方法调用感觉更像控制抽象。
21. 编写新的控制结构
如何编写新的控制结构?创建带函数做参数的方法。
函数是可以被当做参数传递的。
def withPrintWriter(file: File, op: PrintWriter => Unit) {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
withPrintWriter(
new File("date.txt"),
writer => writer.println(new java.util.Date)
)
使用这个方法的好处是,由 withPrintWriter 而不是用户的代码,确认文件在结尾被关闭。因此忘记关闭文件是不可能的。这个技巧被称为贷出模式:loan pattern,因为控制抽象函数,如 withPrintWriter,打开了资源并"贷出"给函数。例如,前面例子里的 withPrintWriter 把 PrintWriter 借给函数op。当函数完成的时候,它发出信号说明它不再需要"借"的资源。于是资源被关闭在finally块中,以确信其确实被关闭,而忽略函数是正常结束返回还是抛出了异常。
结合第 20 条笔记,把 withPrintWriter 方法的参数 curry 化,这样可以使得方法在调用时,可以用大括号来编写方法体。
def withPrintWriter(file: File)(op: PrintWriter => Unit) {
val writer = new PrintWriter(file)
try {
op(writer)
} finally {
writer.close()
}
}
方法调用时使用大括号:
val file = new File("date.txt")
withPrintWriter(file){
writer => writer.println(new java.util.Date)
}
22. 叫名参数 by-name parameter
23. Scala的类层级
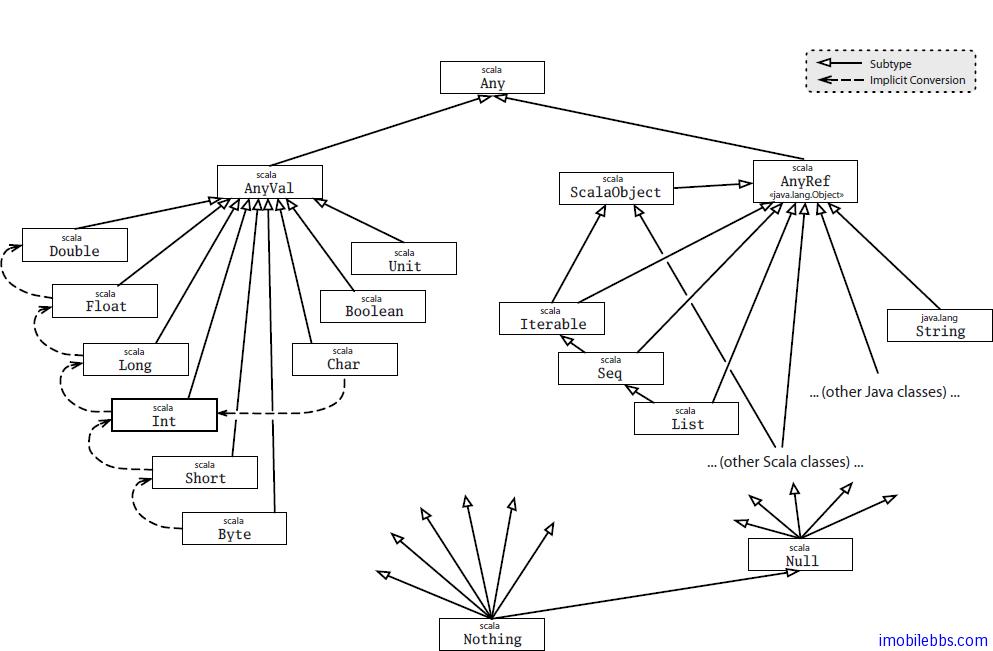
Any 是所有其他类的超类,Nothing 是所有其他类的子类。
Unit 类相当于 Java 的 void 类型,被用作不返回任何结果的方法的结果类型。
值类的空间是扁平的:所有的值类都是 scala.AnyVal 的子类型,但是它们不是互相的子类。代之以它们不同的值类类型之间可以隐式地互相转换。例如,需要的时候,类 scala.Int 的实例可以自动放宽(通过隐式转换)到类 scala.Long 的实例。
42 max 43
42 min 43
1 until 5 => scala.collection.immutable.Range = Range(1, 2, 3, 4)
1 to 5 => scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5)
...
像 max、min、until、to、abs 等方法都定义在类 scala.runtime.RichInt 里,当你在 Int 上调用没有定义在 Int 上但定义在 RichInt 上的方法时,会自动进行从类 Int 到 RichInt 的隐式转换。
AnyRef 是所有引用类的基类,是 Java 中 java.lang.Object 的别名。
关于相等
// Java代码
boolean isEqual(int x,int y) {
return x == y;
}
System.out.println(isEqual(421,421)); 结果是true
// Java代码
boolean isEqual(Integer x, Integer y) {
return x == y;
}
System.out.println(isEqual(421,421)); 结果是false
原因是在第一个 isEqual 中,x 和 y 会被自动装箱,从 Int 到 Integer,但是第二个里面的参数被装箱两次,导致是两个不一样的对象,判断是false。
而在 Scala 中,x 和 y 的类型是 Int 或者 Any 都不会影响 x = y 的判断结果。同理,Java 中字符串判等需要用 equals。
但是,有些情况你需要使用引用相等代替用户定义的相等。例如,某些时候效率是首要因素,你想要把某些类哈希合并: hash cons 然后通过引用相等比较它们的实例,为这种情况,类 AnyRef 定义了附加的 eq 方法,它不能被重载并且实现为引用相等(也就是说,它表现得就像 Java 里对于引用类型的 == 那样)。同样也有一个 eq 的反义词,被称为 ne。
val x = new String("abc")
val y = new String("abc")
scala> x == y
res0: Boolean = true
scala> x eq y // 这里相当于两个 String 对象
res1: Boolean = false
scala> x ne y
res2: Boolean = true
如果说是两个字符串比较
val a = "abc"
val b = "abc"
a == b 和 a eq b 的结果都是 true
- Nothing 类是所有其他类的子类,然而这个类型没有任何实例(也就是没有任何值对应 Nothing 类型)。它的一个用法是示意应用程序非正常终止。
def error(message:String) : Nothing =
throw new RuntimeException(message)
def divide(x:Int,y:Int):Int=
if(y!=0) x/y
else error("Cannot divide by Zero")
error 的返回类型就是 Nothing,告诉调用者该方法没有正常退出(抛出异常)。在调用 error 方法时,因为返回类型是 Nothing,而 Nothing 又是 Int 的子类,而 divide 方法的返回值类型恰恰是 Int。
24. 特质:trait
特质:trait 是 Scala 里复用代码的基础单元。特质封装了方法和字段的定义,其他类可以通过 extends 类继承,并且可以混入任意个特质。最常用到的两种方式:拓宽瘦接口为宽接口和定义可堆叠的改变。
和接口不同,特质的方法可以有实现,像是抽象类。
定义一个 Trait 的方法和定义一个类的方法非常类似,除了它使用 trait 而非 class 关键字来定义一个 trait。
特质和类在大多数方面都是一样的,语法也是一样的。除了以下两点。
- 特质不能有任何“类”参数,即传递给类的主构造器的参数。
class point(x: Int, y: Int) 可以
trait point(x: Int, y: Int) 不可以
- 不论在类的哪个角落,super 的调用都是静态绑定的。在特质中,它们是动态绑定的,即特质中的 super 调用的方法只有当特质混入到具体类的时候才被决定。(可以想象特质只是这么写,它可以被不同的类继承,或者说它可以混入到不同的类中,调用的方法会因为混入到的类不同而不同)。
trait Equal {
def isEqual(x: Any): Boolean
def isNotEqual(x: Any): Boolean = !isEqual(x)
}
class Point(xc: Int, yc: Int) extends Equal {
var x: Int = xc
var y: Int = yc
def isEqual(obj: Any) = obj.isInstanceOf[Point] && obj.asInstanceOf[Point].x == y
}
object Demo {
def main(args: Array[String]) {
val p1 = new Point(2, 3)
val p2 = new Point(2, 4)
val p3 = new Point(3, 3)
println(p1.isNotEqual(p2))
println(p1.isNotEqual(p3))
println(p1.isNotEqual(2))
}
}
25. Ordered 特质
class test extends Ordered[test]{
...
def compare(that: test) = this.number - that.number
}
Ordered 特质通过 compare 方法实现了 <, >, <= , >= 的比较。但是对于 equals 并没有实现。因为 equals 需要检查传入对象的类型,然而因为类型擦除,Ordered 特质本身无法做这种测试。
26. 可改动堆叠
一个类混入多个特质时,越靠近右侧的特质越先起作用。
每个特质 extends 某个抽象类,并可以覆写其中的某些方法以实现功能1、2、3,之后我们去写一个类的时候可以按照自己的需要混入实现了特定功能的特质。
27. 特质的用和不用
在实现一个可重用的行为集合时,是用特质还是用抽象类,没有固定的规则,以下给出了几个可供参考的规律:
如果行为不会被重用
那么就把它做成具体类。具体类没有可重用的行为。如果要在多个不相关的类中重用
做成特质。只有特质可以混入到不同的类层级中。如果希望从 Java 代码中继承它
使用抽象类。如果效率非常重要
倾向于类。大多数 Java 运行时都能让类成员的虚方法调用快于接口方法调用。特质会编译成接口,会付出微小的性能代价。然而,仅当你知道存疑的特质构成了性能瓶颈,并且有证据说明使用类代替能确实解决问题,才做这样的选择。如果以上情况之外,还是不知道
尝试特质。毕竟可以随时改变。
28. 访问包中对象
package launch{
class Booster3
}
package bobsrockets{
package navigtion{
package launch{
class Booster1
}
class MissionControl{
val booster1 = new launch.Booster1
val booster2 = new bobsrockets.launch.Booster2
val booster3 = new _root_.launch.Booster3
}
}
package launch{
class Booster2
}
}
因为 lunch 包定义在最近的包含作用域中,所以,launch.Booster1 即可指到第一个 booster 类。
第二个通过写全引用路径来指代引用的类。
Scala在所有用户可创建的包之外提供了名为 root 的包,任何写出来的顶层包都被当做是 root 包的成员。因此,root.launch 可以访问到顶层的 launch 包。
29. 隐式引用
Scala 在每个程序隐式添加了一些引用。
import java.lang._
import scala._
import Predef._
出现在靠后位置的引用将覆盖靠前的引用。比如 StringBuilder 会被看作是 scala.StringBuilder 而不是 java.lang.StringBuilder
30. 访问修饰符
30.1 私有成员
private 的成员仅在包含了成员定义的类或对象内部可见。
class Outer{
class Inner{
private def f(){
println("f")
}
class InnerMost{
f() //OK
}
}
(new Inner).f();// error: f is not accessible
}
f 在 Inner 中被声明为 private,而访问不在类 Inner 之内。相反,在类 InnerMost 里访问 f 没有问题,因为这个访问包含在 Inner 类之内。Java 允许这两种访问,因为它允许外部类访问其内部类的私有成员。
30.2 保护成员
保护成员只在定义了成员的类的子类中可以被访问。Java 中还允许在同一个包的其他类中进行这种访问。
class p{
class Super{
protected def f() {
println("f")
}
}
class Sub extends Super{
f()
}
class Other{
(new Super).f() //error: f is not accessible
}
}
30.3 保护的作用域
private[x] 或 protected[x]
其中 x 代表某个包,类或者对象,表示可以访问这个 Private 或的 protected 的范围直到 X。
31. 几种单元测试的失败报告
assert(width === 2)
如果失败,会得到 “3 did not equal 2” 这样的信息。三等号操作符不能区分实际结果和期望结果
expert(2){
width
}
如果失败,会得到 “Expected 2, but got 3”
32. 样本类与模式匹配
32.1 样本类
样本类常常用于描述不可变的值对象(Value Object)。
abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class UnOp(operator: String, arg: Expr) extends Expr
case class BinOp(operator: String, left: Expr, Right: Expr) extends Expr
ps: Var 等类没有结构体,所以可以省略花括号
Scala 编译器会对样本类自动添加一些方法。
- 自动添加与类名一样的工厂方法,即可用
Var("x")来代替new Var("x") - 样本类参数列表中的所有参数隐式获得 val 前缀
- 自动地生成equals, canEqual, hashCode, toString, copy, showArray, showObject等方法
32.2 模式匹配的种类
Scala:选择器 match { 备选项 }
Java:switch { 选择器 } { 备选项 }
32.2.1 通配模式
_ 匹配任一对象。还可以用来忽略对象中不关心的部分。
expr match {
case BinOp(op, left, right) => println(expr + "is a binary operation")
case _ =>
}
一般来说,都需要在最后加一个
case _ =>,除非之前的 case 已经将所有的可能性都考虑到了,要不然会报 MatchError 错误。
32.2.2 常量模式
常量模式仅匹配自身。任何字面量都可以用作常量。另外,任何的 val 或单例对象也可以被用作常量。例如,单例对象 Nil 是只匹配空列表的模式。
def describe(x: Any) = x match {
case 5 => "five"
case true => "true"
case "hello" => "hi"
case Nil => "empty list"
case _ => "something else"
}
32.2.3 变量模式
Scala 用小写字母开始的简单名会被当做是模式变量;所有其他的引用会被认为是常量。
import Math.{ E, Pi}
E match {
case Pi => "strange match"
case -> "ok"
}
只会输出 ok,因为 E 不能匹配 Pi
val pi = Math.Pi
E match {
case pi => "strange match"
}
由于 pi 是变量模式,它可以匹配任意输入,因此之后的情况都访问不到,甚至如果写上 `case _ => "ok"` 还会报错。
有两种方式来给模式常量使用小写字母名。
常量是某个对象的字段,可以在其之上用限定符前缀。例如,pi 是变量模式,但是
this.pi、obj.pi都是常量。添加反引号。
pi会再次被解释为常量。
32.2.4 构造器模式
支持深度匹配:不只检查顶层对象是否一致,还会检查对象的内容是否匹配内层的模式。
// 某个商店售卖物品,有时物品捆绑在一起打折出售
abstract class Item
case class Product(description: String, price: Double) extends Item
case class Bundle(description: String, discount: Double, items: Item*) extends Item
def price(it: Item): Double = it match {
case Product(_, p) => p
case Bundle(_, disc, its @ _*) => its.map(price _).sum * (100-disc) /100
// 这里@表示将嵌套的值绑定到变量its
// map 中的 price 指的是 def price 方法,而不是 Product 中的变量,可以写成 its.map(price(_)).sum,即把 its 中的每一个 Product 对象都传递给 price 方法。
// 还可以继续简写成 its.map(price).sum 的形式
}
// 测试
val bun1 = Bundle("Father's day special", 20.0, Product("Massager", 188.0))
val bun2 = Bundle("Appliances on sale", 10.0, Product("Haier Refrigerato, 3000.0),Product("Geli air conditionor",2000.0))
// 商品组合1 八折结果
scala> price(bun1)
res5: Double = 150.4
// 商品组合2 九折结果
scala> price(bun2)
res6: Double = 4500.0
32.2.5 序列模式
可以像匹配样本类那样匹配如 List 或 Array 这样的序列类型。并可以指定模式内任意数量的元素。
匹配 0 开头的三元素列表模式
expr match {
case List(0, _, _) => "a"
case _ => "b"
}
匹配 0 开头的任意长度的列表模式
expr match {
case List(0, _*) => "a"
case _ => "b"
}
32.2.6 元组模式
匹配元组。
32.2.7 类型模式
可以当做类型测试和类型转换的简易替代。
def generalSize(x: Any) = x match {
case s: String => s.length
case m: Map[_, _] => m.size
case _ => 1
}
参数是 any 类型,因此任何值都可以接受。这里就用了 s 来指代 string,但是不能写成 x.length,因为 Any 类型没有 length 成员。
相对复杂的版本:
类型测试: expr.isInstanceOf[String]
类型转换: expr.asInstanceOf[String]
32.2.8 类型擦除规则
def isIntIntMap(x: Any) = x match {
case m: Map[Int, Int] => true
case _ => false
}
isIntIntMap(Map(1 -> 1)) 返回 true
isIntIntMap(Map("a" -> "b")) 返回 true
原因是: 类型参数信息并没有保留到运行期。系统所能做的只是判断这个值是某种任意类型参数的 Map。
擦除规则的例外是数组。因为在 Java 和 Scala 里,数组的元素类型与数组值保存在一起,因此可以做模式匹配。
def isStringArray(x: Any) = x match {
case a: Array[String] => "yes"
case _ => "no"
}
val a = Array("a")
isStringArray(a) 返回 yes
val b = Array(1, 2, 3)
isStringArray(b) 返回 no
32.2.9 变量绑定
写法:变量名 @ 模式
意义:能像通常的那样做模式匹配,并且如果匹配成功,则把变量设置成匹配的对象,就像使用简单的变量模式那样。
expr match {
case UnOp("abs", e @ UnOp("abs", _)) => e
case _ =>
}
其中有一个用 e 作为变量,及 UnOp("abs", _) 作为模式的变量绑定模式。如果后者匹配成功,那么后者就可以用 e 来指代。
32.3 模式守卫
模式守卫接在模式之后,开始于 if。守卫可以是任意的引用模式中变量的布尔表达式。如果存在模式守卫,只有在守卫返回 true 的时候匹配才成功。
// 仅匹配正整数
case n: Int if n > 0 => ...
// 仅匹配以 a 开头的字符串
case s: String if s(0) == 'a' => ...
32.4 模式重叠与封闭类
在写 case 的时候要注意每一种 case 应该是独立的,如果有重叠的部分,那么后面的 case 可能根本不会执行到。
但是如何能保证 case 一定考虑到了可能的情况?实际上,可以让 Scala 编译器帮助检测 match 表达式中遗漏的模式组合。做法是让样本类的超类被封闭(sealed)。封闭类除了类定义所在的文件之外,不能再添加任何新的子类。
sealed abstract class Expr
case class Var(name: String) extends Expr
case class Number(num: Double) extends Expr
case class UnOp(operator: String, arg: Expr) extends Expr
case class BinOp(operator: String, left: Expr, Right: Expr) extends Expr
在使用继承自封闭类的样本类做匹配时,编译器将通过警告信息标识出缺失的模式组合。但是假如你确定缺失的模式组合不会被执行,但是编译器又确实报错了,可以添加 @unchecked 注解,随后的模式的穷举性检查会被抑制掉。
def describe(e: Expr): String = (e: @unchecked) match {
case Number(_) => "a number"
case Var(_) => "a variable"
}
32.5 Option 类型
Scala 为可选值定义了一个名为 Option 的标准类型。这种值有两种形式:一种是 Some(x),其中 x 是实际值;或者是 None 对象,代表缺失的值。
val capitals = Map("France" -> "Paris", "Japan" -> "Tokyo")
capitals get "France" 返回 Some(Paris)
capitals get "China" 返回 None
通过模式匹配可以分离可选值。
def show(x: Option[String]) = x match {
case Some(s) => s
case None => "?"
}
show(capitals get "France") 返回 Paris
show(capitals get "China") 返回 ?
类比 Java 中代表没有值的 null,如果忘记了检查的话,会在运行时发生 NullPointerException,但是 Scala 相当于在 get 的返回值之上加了一层包装,如果你没有对它进行处理,在编译的时候就会报类型错误,因为返回值是 Option[String],而不是 String。
32.6 模式匹配的一些其他例子
- 用在变量定义中
val myTuple = (123, "abc")
val (number, str) = myTuple
- 可用于 for 循环
for((country, city) <- capitals){
println(...)
}
但有时候可能并不能保证匹配不会出错。
val results = List(Some("a"), None, Some("b"))
for(Some(x) <- results){
println(x)
}
结果只能打印出 a 、 b 两种情况。
不能被匹配出来的值,比如 None,会自动被丢弃。
33. List 列表
列表是不可变的,不能通过赋值来改变列表的元素。其次,列表具有递归结构,而数据是连续的。
所有列表都是由两个基础构造块 Nil 和 :: 构造出来的。其中,Nil 表示空列表,中缀操作符 :: 表示右侧列表加在左侧列表之后。
插入排序:
def isort(xs: List[Int]): List[Int] = {
if (xs.isEmpty) Nil
else insert(xs.head, isort(xs.tail))
}
def insert(x: Int, xs: List[Int]): List[Int] = {
if (xs.isEmpty || x <= xs.head) x :: xs
else xs.head :: insert(x, xs.tail)
}
- 使用了模式匹配的插入排序:
def isort(xs: List[Int]): List[Int] = xs match {
case List() => List()
case x :: xs1 => insert(x, isort(xs1))
}
def insert(x: Int, xs: List[Int]): List[Int] = xs match {
case List() => List()
case y :: ys =>
if(x <= y) x :: xs
else y :: insert(x, ys)
}
在这里 xs1、 ys 能代表 xs.tail, 原因是 xs 进行模式匹配的时候,如果不为空,拿出第一个元素进行匹配,满足 xs.head :: xs.tail 的形式,于是就用 x、 y 来代替 xs.head, xs1、ys 来代替 xs.tail
- 两个列表的连接操作:
def append(xs: List[Int], ys: List[Int]): List[Int] = xs match {
case List() => ys
case x :: xs1 => x :: append(xs1, ys)
}
判断列表是否为空时,应该用
List.isEmpty,不推荐用List.length,因为获取长度比较费时。head、tail 运行时间都是常量,而 init、last 需要遍历整个列表以计算结果,因此耗费的时间和列表长度成正比。因此,组织好数据,以便让所有的访问都集中在列表的头部。
splitAt 方法:在指定位置拆分列表,返回对偶(pair)列表(可以看做返回一个元组,里面一共两个元素,类型均为列表)
xs.splitAt(2) 等效于 (xs.take(n), xs.drop(n))
abcde splitAt 2
(List(a, b), List(c, d, e))
- 元素选择:apply 和 indices 方法
abcde apply 2
等于
abcde(2)
返回结果都是 c
xs apply n 等价于 (xs drop n).head
indices 方法可以返回指定列表的所有有效索引值组成的列表。
abcde.indices 返回 List(0, 1, 2, 3, 4)
- 啮合列表:zip 方法
zip 方法是 List 类的内建方法,但是 unzip 是 List 对象的方法。
可以把两个列表组成一个对偶列表。如果两个列表长度不一致,不能匹配的元素会被丢弃。
abcde.indices zip abcde
返回 List((0, a), (1, b), (2, c), (3, d), (4, e))
abcde zip List(1, 2, 3)
返回 List((a, 1), (b, 2), (c, 3))
如果用将元素和索引啮合在一起,可以使用 zipWithIndex 方法。
abcde.zipWithIndex
返回 List((a, 0), (b, 1), (c, 2), (d, 3), (e, 4))
- 显示列表:toString 和 mkString 方法
toString 返回列表的标准字符串表达形式。
xs mkString(pre, seq, post) // 前缀,分隔符,后缀
xs mkSrtring seq 等价于 xs mkString ("", seq, "")
xs mkString 等价于 xs mkString ""
mkString 方法还有名为 addString 的变体,可以把构件好的字符串添加到 StringBuilder(scala.StringBuilder) 对象中,而不是作为结果返回。因为 mkString 和 addString 方法都继承自 List 的超特质 Iterable,因此它们可以引用到各种可枚举的集合类上。
- 转换列表:toArray、copyToArray
List => Array : List.toArray
Array => List : Array.toString.toList
xs copyToArray (arr, start)
把列表 xs 的所有元素复制到数组 arr 中,填入位置开始为 start。必须确保数组 arr 有足够的空间来存放全部列表元素。
- 归并排序
def msort[T](less: (T, T) => Boolean)(xs: List[T]: List[T]) = {
def merge(xs: List[T], ys: List[T]): List[T] = (xs, ys) match {
case (Nil, _) => ys
case (_, Nil) => xs
case (x :: xs1, y :: ys1) =>
if(less(x, y)) x :: merge(xs1, ys)
else y :: merge(xs, ys1)
}
val n = xs.length / 2
if(n == 0) xs
else {
val (ys, zs) = xs splitAt n
merge(msort(less)(ys), msort(less)(zs))
}
}
msort((x: Int, y: Int) => x < y)(List(5, 7, 3, 1))
返回 List(1, 3, 5, 7)
- 列表间的映射:map、flatMap、foreach
map 返回的是包含列表的列表, flatMap 返回的是把所有元素列表连接之后的单个列表。
val words = List("the", "fox")
words.map(_.toList) 返回 List(List("t", "h", "e"), List("f", "o", "x"))
words.flatMap(_.toList) 返回 List("t", "h", "e", "f", "o", "x")
foreach 操作结果是 Unit,不会产生结果列表。
- 列表过滤:filter、partition、find、takeWhile、dropWhile、span
filter(p) 返回条件 p 判断为 True 的所有元素组成的列表。
partition(p) 返回的是列表对。其中一个包含所有论断 p 为 True 的元素,另一个包含所有论断 p 为 False 的元素。
xs partition p 等价于 (xs filter p, xs filter (!p(_)))
find(p) 只返回满足条件 p 为 True 的第一个元素,若无则返回 None。
takeWhile(p) 返回列表中最长的能满足条件 p 的前缀。dropWhile 则返回移除了最长的能满足条件 p 的前缀的结果。
List(1, 2, 3, -4, 5).takeWhile(_ > 0) 返回 List(1, 2, 3)
span 是把 takeWhile 和 dropWhile 组合成一个操作。
xs span p 等价于 (xs takeWhile p, xs dropWhile p)
List(1, 2, 3, -4, 5).span(_ > 0)
返回 (List(1, 2, 3), List(-4, 5))
- 列表的论断:forall、exists
forall(p) 如果列表的所有元素满足 p 则返回 true;而 exists(p) 只要有一个值满足 p 就返回 true。
def hasZeroRow(m: List[List[Int]]) = m exists (row => row forall (_ == 0))
- 折叠列表: 左折叠 /: 和 右折叠 :\
左折叠 可以用 foldLeft 代替
(z /: List(a, b, c)) (op) 等价于 op(op(op(z, a), b), c)
右折叠 可以用 foldRight 代替
(List(a, b, c) :\ z) (op) 等价于 op(a, op(b, op(c, z)))
reverse 方法反转列表的运行时间是列表长度的平方。使用左折叠方法来实现一个运行时间为线性的反转方法。
def reverseLeft[T](xs: List[T]) =
(List[T] /: xs) {(ys, y) => y :: ys}
- 列表排序:sort
List(1, -3, 4, 2, 5) sort (_ > _)
List 对象的几种方法
- List.apply(1, 2, 3)
- List.range(1, 5)
- List.make(5, 'a')
- List.unzip
- List.flatten
- List.concat
- List.map2
- List.forall2
- List.exists2
34. 集合类型
Iterable 是主要特质,它同时还是可变和不可变序列(Seq)、集(Set)以及映射(Map)的超特质。序列是有序的集合,例如数组和列表。集可以通过 == 方法确定对每个对象最多只包含一个。映射则包含了键值映射关系的集合。
34.1 序列
- 列表缓存
引入 ListBuffer 可以更高效地通过添加元素的方式构建列表。支持常量时间的添加和前缀操作。元素添加使用 += 操作符,前缀使用 +: 操作符。
可以避免栈溢出。
import scala.collection.mutable.ListBuffer 只在可变集合包中
val buf = new ListBuffer[Int]
buf += 1
buf += 2 返回 ListBuffer(1, 2)
3 +: buf 返回 Listbuffer(3, 1, 2)
- 数组缓存
ArrayBuffer 保留了 Array 的所有操作,还额外允许在序列开始和结束的地方添加和删除元素。可以避免栈溢出。
import scala.collection.mutable.ArrayBuffer 只在可变集合包中
val buf = new ArrayBuffer[Int]
buf += 1
buf += 2 返回 ArrayBuffer(1, 2)
- 队列
有可变和不可变两种。对于不可变队列来说,使用 enqueue 添加元素,dequeue 返回由队列头部元素和移除该元素之后的剩余队列组成的对偶(tuple2)。对于可变队列来说,可以使用 +=、++= 来添加元素,dequeue 方法只从队列移除头部元素并返回。
import scala.collection.immutable.Queue
val empty = new Queue[Int]
val has1 = empty.enqueue(1)
val has123 = has1.enqueue(List(2, 3))
val (element, has23) = has123.dequeue
import scala.collection.mutable.Queue
val queue = new Queue[Int]
queue += "a"
queue ++= List("b", "c")
queue.dequeue
- 栈
有可变和不可变两种。推入元素 push,弹出元素 pop,只获取栈顶元素而不移除 top。
- 字符串(经 RichString 隐式转换)
def hasUpperCase(s: String) = s.exists(_.isUpperCase)
字符串 s 调用了 exists 方法,而 String 类本身没有这个方法。因为会隐式转换为含有这个方法的 RichString 类,类型是 Seq[Char]。
34.2 集(Set)和映射(Map)
默认情况下使用的 Set 和 Map,获得的都是不可变对象。如果需要用到可变版本,需要新引用可变集合包。
List 可使用的部分方法在集和映射中也可以使用。
- 集
集的关键特性在于它可以使用对象的 == 操作检查,确保任何时候每个对象只在集中保留最多一个副本。即 元素不可重复。
val text = "see spot run. run, spot. run!"
val wordsArray = text.split("[ !,.]+") // 使用正则表达式分隔字符串
- 默认的集和映射
为了追求性能,当元素数量是1,2,3,4这四种情况的时候,对应的集的类型是 immutable.Set1, immutable.Set2, immutable.Set3, immutable.Set4,当元素数量大于等于5的时候,其类型是 immutable.HashSet。数量为0时,类型为 immutable.EmptySet(映射同理)。
- 有序的集和映射
可以引用不可变类型的 TreeSet、TreeMap(只有不可变版本),这两个类实现了 SortedSet、 SortedMap 特质,具体顺序取决于 Ordered 特质。
- 同步的集和映射
如果需要线程安全的映射,可以把 SynchronizedMap 特质混入到想要的特定类实现中。
import scala.collection.mutable.{Map, SynchronizedMap, HashMap}
object MapMaker [
def makeMap: Map[String, String] = {
new HashMap[String, String] with SynchronizedMap[String, String] {
// 覆写 default 方法,如果查询某个键的时候不存在映射,会执行 default 方法。默认会得到 NoSuchElementException
override def default (key: String) = "......"
}
}
]
34.3 初始化集合
- 如果想在一个 Set 中添加不同类型的元素
import scala.collection.mutable.Set
val staff = Set[Any](1)
staff += "a" 返回 staff(1, a)
- 把集合初始化为指定类型,例如把列表中的元素保存在 TreeSet 中
val colors = List("blue", "yellow", "red")
import scala.collection.immutable.TreeSet
// 创建空的 TreeSet[String] 对象并使用 ++ 操作符添加列表元素
val treeset = TreeSet[String]() ++ colors
- 可变和不可变集合互转
不可变到可变:mutable.Set.empty ++ 不可变集合
可变到不可变:Set.empty ++ 可变集合
34.4 元组
由于元组可以组合不同类型的对象,因此不能继承自 Iterable。
元组常用来返回方法的多个值。
?? 使用高性能算子
使用reduceByKey/aggregateByKey替代groupByKey
使用mapPartitions替代普通map
使用foreachPartitions替代foreach
使用filter之后进行coalesce操作
使用repartitionAndSortWithinPartitions替代repartition与sort类操作
Scala编程 笔记的更多相关文章
- scala编程笔记(三)类,字段和方法
类,字段和方法 类是对象的蓝图,能够通过new来创建对象.在类的定义里能够有字段和方法.统称member val还是var都是指向对象的变量(var定义的字段可又一次赋值),def定义方法,包括可运行 ...
- Scala语言笔记 - 第一篇
目录 Scala语言笔记 - 第一篇 1 基本类型和循环的使用 2 String相关 3 模式匹配相关 4 class相关 5 函数调用相关 Scala语言笔记 - 第一篇 最近研究了下scala ...
- 基于.net的分布式系统限流组件 C# DataGridView绑定List对象时,利用BindingList来实现增删查改 .net中ThreadPool与Task的认识总结 C# 排序技术研究与对比 基于.net的通用内存缓存模型组件 Scala学习笔记:重要语法特性
基于.net的分布式系统限流组件 在互联网应用中,流量洪峰是常有的事情.在应对流量洪峰时,通用的处理模式一般有排队.限流,这样可以非常直接有效的保护系统,防止系统被打爆.另外,通过限流技术手段,可 ...
- Scala学习笔记及与Java不同之处总结-从Java开发者角度
Scala与Java具有很多相似之处,但又有很多不同.这里主要从一个Java开发者的角度,总结在使用Scala的过程中所面临的一些思维转变. 这里仅仅是总结了部分两种语言在开发过程中的不同,以后会陆续 ...
- Scala语言笔记 - 第三篇(容器方法篇)
Scala语言笔记 - 第三篇(容器方法篇) 目录 Scala语言笔记 - 第三篇(容器方法篇) map和flapMap方法: 最近研究了下scala语言,这个语言最强大的就是它强大的函数式编程( ...
- C# 高效编程笔记2
C# 高效编程笔记2 1.理解GetHashCode()的陷阱 (1)作用:作为基于散列集合定义键的散列值,如:HashSet<T>,Dictionary<K,V>容器等 (2 ...
- C# 高效编程笔记1
C# 高效编程笔记1 1.使用属性而不是可访问的数据成员 (1).NET Framework中的数据绑定类仅支持属性,而不支持共有数据成员 (2)属性相比数据成员更容易修改 2.用运行时常量(read ...
- storysnail的Linux串口编程笔记
storysnail的Linux串口编程笔记 作者 He YiJun – storysnail<at>gmail.com 团队 ls 版权 转载请保留本声明! 本文档包含的原创代码根据Ge ...
- storysnail的Windows串口编程笔记
storysnail的Windows串口编程笔记 作者 He YiJun – storysnail<at>gmail.com 团队 ls 版权 转载请保留本声明! 本文档包含的原创代码根据 ...
随机推荐
- leetcode560题解【前缀和+哈希】
leetcode560.和为K的子数组 题目链接 算法 前缀和+哈希 时间复杂度O(n). 在解决这道题前需要先清楚,一个和为k的子数组即为一对前缀和的差值. 1.我们假设有这么一个子数组[i,j]满 ...
- 中科蓝讯530X、532X模块之硬件UART
文章转载请注明来源 作者:Zeroer 一.选择IO 想要使用硬件的UART必须先确定要mapping的pin脚 注意:用作TX的脚位可以分时复用成单线双工 因为芯片默认的调试串口用的是UART0,所 ...
- Python-全局解释器锁GIL原理和多线程产生原因与原理-多线程通信机制
GIL 全局解释器锁,这个锁是个粗粒度的锁,解释器层面上的锁,为了保证线程安全,同一时刻只允许一个线程执行,但这个锁并不能保存线程安全,因为GIL会释放掉的并且切换到另外一个线程上,不会完全占用,依据 ...
- Go-常量-const
常量:只能读,不能修改,编译前就是确定的值 关键字: const 常量相关类型:int8,16,32,64 float32,64 bool string 可计算结果数学表达式 常量方法 iota pa ...
- mysql-6-groupby
#进阶5:分组查询 /* SELECT FROM WHERE GROUP BY ORDER BY 查询列表要求是分组函数和 group by 之后出现的字段 1.筛选条件分为两类: 数据源 位置 关键 ...
- CentOS openssh升级到openssh-7.2版本
查看现在的版本SSH -V 一.准备 备份ssh目录(重要) cp -rf /etc/ssh /etc/ssh.bak [ 可以现场处理的,不用设置 安装telnet,避免ssh升级出现问题,导致无法 ...
- CentOS 7安装Nginx 1.10.2
安装epel-release源并进行安装 yum install epel-release yum update(时间会有点长) yum install nginx 相关操作: systemctl s ...
- unsigned int 和 int
就如同int a:一样,int 也能被其它的修饰符修饰.除void类型外,基本数据类型之前都可以加各种类型修饰符,类型修饰符有如下四种:1.signed----有符号,可修饰char.int.Int是 ...
- RHSA-2018:0395-重要: 内核 安全和BUG修复更新(需要重启、本地提权、代码执行)
[root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.2.1511 (Core) 修复命令: 使用root账号登陆She ...
- nginx完美支持thinkphp3.2.2(需配置URL_MODE=>3 rewrite兼容模式)
来源:http://www.thinkphp.cn/topic/26637.html 环境:nginx 1.6,thinkphp3.2.2 第一步,修改server块 server { listen ...