kafka 消费组功能验证以及消费者数据重复数据丢失问题说明 3
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
背景
上一篇文章记录了kafka的副本机制和容错功能的说明,本篇则主要在上一篇文章的基础上,验证多分区Topic的消费者的功能验证;
目录:
消费组功能验证
新建1副本,2分区的Topic做测试验证
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic arnold_consumer_test
查看对应的Topic分区情况
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_consumer_test
Topic:arnold_consumer_test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: arnold_consumer_test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: arnold_consumer_test Partition: 1 Leader: 2 Replicas: 2 Isr: 2
创建Topic每个分区只设置了一个副本及主副本,所以如上可看到,各分区所在的broker节点的情况。
配置消费者组group.id信息为:test-consumer-group-arnold-1
修改 kafka下 config目录下的consumer.properties,修改内容为:
bootstrap.servers=10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092
group.id=test-consumer-group-arnold-1
分别在两台kafka服务器上的 kafka 主目录下启动两个消费者,并指定对应的消费者配置为 consumer.properties文件,消费的Topic 为arnold_consumer_test topic
10.0.6.39启动消费者
[gangtise@yinhua-ca000003 kafka_2.11-2.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
10.0.3.17 启动消费者
[root@dev kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
两个消费者都是使用的相同的consumer.properties文件,即都是在一个消费组里面(为什么要在两台服务器上启动两个消费者?不能在一个服务器上启动两个消费者吗?答:都可以,我之所以用两个不同的服务器启动消费者是因为我当前39服务器启动消费者后,当前的shell进程就已经被占用了,处于等待状态,除非我再开一个39服务器的会话,重新开一个消费者。)
OK,消费者启动以后,观察下消费者和Topic分区的对应情况
查看当前所有的消费组的列表信息
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --list
test-consumer-group-arnold-1
test-consumer-group-arnold
test-consumer-group
如上,可以知道当前kafka服务器上已有的消费组分别是有三个,而我们现在已经启动了的消费者组是test-consumer-group-arnold-1,所以,详细查看下消费组test-consumer-group-arnold-1的详细信息
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --describe --group test-consumer-group-arnold-1
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
arnold_consumer_test 0 19 19 0 consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae /10.0.6.39 consumer-1
arnold_consumer_test 1 19 19 0 consumer-1-917ecb37-3027-45de-b293-fe5125867432 /10.0.3.17 consumer-1
CURRENT-OFFSET: 当前消费组消费到的偏移量
LOG-END-OFFSET: 日志最后的偏移量
CURRENT-OFFSET = LOG-END-OFFSET 说明当前消费组已经全部消费了;
LAG:表示落后未消费的数据量
可以看到当前topic arnold_consumer_test 的Partition 0分区对应的消费者id是
consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae,该消费者对应的host是
10.0.6.39;通过上述内容就可以很清晰的知道,当前所启动的消费组下的两个消费者分别对应消费的是topic的那个分区,OK进行下测试
启动生产者生产数据
[root@dev bin]# ./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_consumer_test
>message1
>message2
按照kafka的消息路由策略,此时插入message1和message2两条消息,将会采用轮训的策略分别插入到两个分区中;(不清楚的话可以看下上篇的内容,这块都有做过说明)
此时partition0分区中将会接收到 message1的消息,partition2分区中将会接受到message2的消息,然后又分别由partition0分区所对应的 10.0.6.39的消费者消费到对应的数据,partition1同理
此时查看消费者的状况如下:
10.0.6.39
[root@dev kafka_2.11-2.1.0]# bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
message1
10.0.3.17
[gangtise@yinhua-ca000003 kafka_2.11-2.1.0]$ bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
message2
验证完毕,内容很简单,但是想要表达记录下来还真的是着实有些麻烦;所以,后续其他的一些规则,此处就直接放总结了,不再列出来实验过程;
消费者与分区的对应关系总结
- topic 3个分区的情况,启动一个消费者组且只有一个消费者,则该消费者会消费topic的3个分区;
- topic 3个分区的情况,启动一个消费者组且只有两个消费者c1,c2,则将会有一个消费者负责消费两个分区,另外一个消费者负责消费一个分区;
- topic 3个分区的情况,启动一个消费者组且有三个消费者c1,c2,c3,则正常对应分区消费,一个消费者对应一个partition分区;
- topic 3个分区的情况,启动一个消费者组且有四个消费者c1,c2,c3,c4,则一般情况下没有人这样做。。。太愚蠢了。。。所以我也就没做这个测试,但是按照kafka的规则来看,会有第四个消费者消费不到对应的分区,也就是不会消费到任何数据。。
上述的内容,则也是都可以通过使用kafka-consumer-groups.sh命令,查看消费组下的消费者所对应的分区的情况即可得知对应的结果;
此时如果一个消费组已经在消费的情况下,此时又来了新的消费组进行消费,那就按照新的消费组规则来消费即可, 不会影响到其他消费组;举例,此时一个消费组三个消费者,在进行数据的消费;此时新来了一个消费组,只有一个消费者,那么此时这个消费者会消费所有的消费分区,不会和其他的消费组有任何的重叠,原理是,kafka的消费组其实在kafka中也是一个消费者topic分区的概念,分区中记录各个消费组的消费的offset位移信息,以此保证所有的消费者所消费的内容的offset位移互不影响,关于这个概念后续会详细说明一下,其实挺重要的。
另外,上述只做了部分的测试验证,便直接给出了最终的总结内容,对于部分测试内容并没有再在本篇列出来(因为很多步骤其实都是重复的);但是,无意中发现了一个老哥的博客,已经对这方面也做了详细的测试,详情还需要看剩下的测试方式的,可以点击这个链接查看;
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
消费者数据重复问题说明
本来这篇文章在上述的消费者和Partition的关系介绍完以后也就结束了,但是在写完以后,翻了下博客园的首页发现有一个推荐的kafka的帖子就顺手点进去想get点技能,然后结果有点伤心,文章中对于一些kafka数据重复的问题一笔带过。。甚至没有说明为什么kakfa会出现数据重复的问题,只是说这是kafka的一种自我保护的机制产生的。。。这,就很伤心,于是本篇内容再对kafka数据重复的问题做一下说明,这些问题早晚也都要记录的。
对于kafka的使用上,其实Java代码的实现是相对简单的,网上的内容也有很多,但是如果对于kafka的一些基本概念就不熟悉的话,在使用过程中便会出现很多懵逼的事情,所以这篇文章包括前两篇的文章,则都是重点在说kafka的一些机制的问题,当然后续对于kafka java的一些配置和实现,也会做一些记录说明。
回到问题本身,为什么kafka有时候会出现消费者的数据重复问题?首先,消费者的数据本身是来自于生产者生产的数据,所以了解生产者所生产数据的可靠性机制,便和当前的问题有这直接的关联了。
生产者的可靠性保证
生产者的数据可靠性,在配置上是根据kafka 生产者的 Request.required.acks 来配置生产者消息可靠性;
Request.required.acks=-1 (ISR全量同步确认,强可靠性保证)
Request.required.acks = 1(leader 确认收到,无需保证其它副本也确认收到, 默认)
Request.required.acks = 0 (不确认,但是吞吐量大)
在分布式的系统中,有一个对应的ACP理论,分别是:
可用性(Availability):在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
一致性(Consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
分区容忍性(Partition tolerance):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性;所以kafka也不例外;
Kafka 生产者CP系统
如果想实现 kafka 配置为 CP(Consistency & Partition tolerance) 系统, 配置需要如下:
request.required.acks=-1
min.insync.replicas = ${N/2 + 1}
unclean.leader.election.enable = false
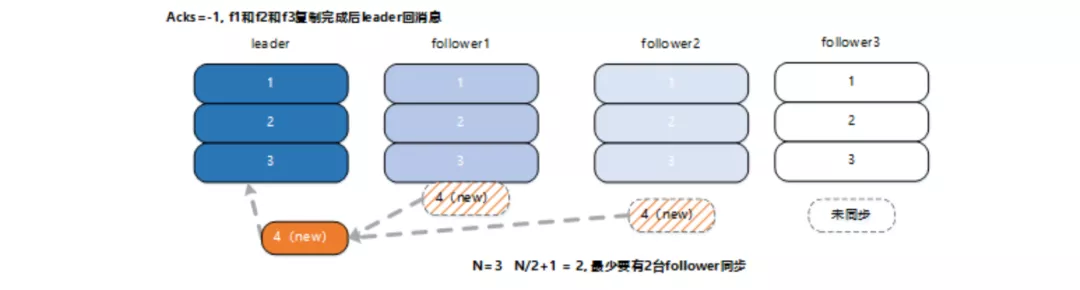
如图所示,在 acks=-1 的情况下,新消息只有被 ISR 中的所有 follower(f1 和 f2, f3) 都从 leader 复制过去才会回 ack, ack 后,无论那种机器故障情况(全部或部分), 写入的 msg4,都不会丢失, 消息状态满足一致性 C 要求。
正常情况下,所有 follower 复制完成后,leader 回 producer ack。
异常情况下,如果当数据发送到 leader 后部分副本(f1 和 f2 同步), leader 挂了?此时任何 follower 都有可能变成新的 leader, producer 端会得到返回异常,此时producer端会重新发送数据,此时数据重复
解决消费重复的方式有很多啊,第一个就是你的业务场景无需在意数据重复的问题,这个自然也就业务上解决了;第二个则是消费者自己做一层缓存过滤即可,因为生产数据重复毕竟是节点down机才会出现的问题,在down机的这一刹那没有被同步到follower的数据并不会很多,所以,以数据量为缓存,或者以时间为缓存都可以解决这个问题,比如加一个缓存区,只要判断数据重复了则不再重复消费即可,然后当缓存的数据超过了1M,则清除一次缓存区;或者直接缓存到redis中,使用redis api来去重,定时清理一下redis中的数据也可以;
除了生产者数据重复外,还有一种问题是,生产者数据没有重复,但是消费者消费的数据重复了,这种问题,则是由于消费者offset自动提交的问题,如,消费者offset是1s提交一次,此时0.5s消费了5条数据,但是消费者还没有到1s自动提交的时候,消费者挂掉,此时已经消费的5条数据的偏移量由于没有提交到kafka,所以kafka中是没有记录到当前已经消费到的偏移量的,此时消费者重启,则会从5条数据前重新消费,这个问题一般比较好解决,因为大多数情况下如果使用消费者手动提交的模式,一般不会出现这种问题(手动提交的情况下如果出现异常,没有执行提交代码,那么代码中做好数据消费的回滚操作即可,更加可控);
除了数据重复的情况,另外一种问题,则是kafka数据丢失的问题
首先按照上述的kafka的cp系统的配置方式,是绝对不会出现数据丢失的情况的,因为要么各节点不工作,要么各节点数据同步完成后,才会返回ack,此时消息不会丢失且消息状态一致;
Kafka 生产者AP系统
除了配置kakfa为cp系统外,还可以配置kafka为AP(Availability & Partition tolerance)系统
request.required.acks=1
min.insync.replicas = 1
unclean.leader.election.enable = false
AP系统下生产者的吞吐量相对更高,但是由于request.required.acks 配置为1,即leader主副本收到消息便直接返回ack,此时如果leader接收到生产者消息后,返回了ack的标识,但是此时副本节点还都没有进行同步,此时leader节点挂掉,重新进行leader选举,新的follower选为leader后,则此时消息丢失;
所以根据合适的业务场景,使用合适的kafka模式则是最佳的选择。
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
上述命令汇总
新建Topic
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic arnold_consumer_test
查看Topic详细信息
[root@dev bin]# ./kafka-topics.sh --describe --zookeeper 10.0.3.17:2181 --topic arnold_consumer_test
Topic:arnold_consumer_test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: arnold_consumer_test Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: arnold_consumer_test Partition: 1 Leader: 2 Replicas: 2 Isr: 2
启动消费者
bin/kafka-console-consumer.sh --bootstrap-server 10.0.3.17:9092,10.0.6.39:9092,10.0.3.18:9092 --from-beginning --topic arnold_consumer_test --consumer.config config/consumer.properties
启动生产者
./kafka-console-producer.sh --broker-list 10.0.3.17:9092 --topic arnold_consumer_test
查看当前所有的消费组的列表信息
./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --list test-consumer-group-arnold-1
查看消费者组的详细信息
[root@dev bin]# ./kafka-consumer-groups.sh --bootstrap-server 10.0.3.17:9092 --describe --group test-consumer-group-arnold-1
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
arnold_consumer_test 0 19 19 0 consumer-1-2da16674-5b57-4e6c-9660-ab45de6ed5ae /10.0.6.39 consumer-1
arnold_consumer_test 1 19 19 0 consumer-1-917ecb37-3027-45de-b293-fe5125867432 /10.0.3.17 consumer-1
文章来源于本人的印象笔记,如出现格式问题可访问该链接查看原文
原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94
kafka 消费组功能验证以及消费者数据重复数据丢失问题说明 3的更多相关文章
- kafka消费组、消费者
consumer group consumer instance 一个消费组可能有一个或者多个消费者.同一个消费组可以订阅一个或者多个主题.主题的某一个分区只能被消费组的某一个消费者消费.那么分区和消 ...
- Kafka设计解析(十三)Kafka消费组(consumer group)
转载自 huxihx,原文链接 Kafka消费组(consumer group) 一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka ...
- Kafka 消费组消费者分配策略
body { margin: 0 auto; font: 13px / 1 Helvetica, Arial, sans-serif; color: rgba(68, 68, 68, 1); padd ...
- Kafka消费组(consumer group)
一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka社区邮件组已经在讨论是否应该正式使用新版本consumer替换老版本,笔者也觉得时 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费者加入消费组
消费者客户端轮询的3个步骤:发送拉取请求,客户端轮询,获取拉取结果 . 消费者在发送拉取请求之前,必须首先满足下面的两个条件.- 确保消费者已经连接协调者, 即找到服务端中管理这个消费者的协调者节点 ...
- 日志服务Python消费组实战(三):实时跨域监测多日志库数据
解决问题 使用日志服务进行数据处理与传递的过程中,你是否遇到如下监测场景不能很好的解决: 特定数据上传到日志服务中需要检查数据内的异常情况,而没有现成监控工具? 需要检索数据里面的关键字,但数据没有建 ...
- Kafka技术内幕 读书笔记之(五) 协调者——消费组状态机
协调者保存的消费组元数据中记录了消费组的状态机 , 消费组状态机的转换主要发生在“加入组请求”和“同步组请求”的处理过程中 .协调者处理“离开消费组请求”“迁移消费组请求”“心跳请求” “提交偏移量请 ...
- 日志服务Python消费组实战(二):实时分发数据
场景目标 使用日志服务的Web-tracking.logtail(文件极简).syslog等收集上来的日志经常存在各种各样的格式,我们需要针对特定的日志(例如topic)进行一定的分发到特定的logs ...
- kafka Poll轮询机制与消费者组的重平衡分区策略剖析
注意本文采用最新版本进行Kafka的内核原理剖析,新版本每一个Consumer通过独立的线程,来管理多个Socket连接,即同时与多个broker通信实现消息的并行读取.这就是新版的技术革新.类似于L ...
随机推荐
- openssl ec/ecparam/errstr/ripemd160/camellia-128-ecb/camellia-192-cbc/camellia-192-ecb3条指令及1个哈希算法3个加密算法的学习
ecparam ecparam指令通过用椭圆曲线加密方式,生成ec密钥,可以指定参数 openssl ecparam [-inform DER|PEM] [-outform DER|PEM] [-in ...
- XJOI 夏令营501-511测试11 统计方案
小B写了一个程序,随机生成了n个正整数,分别是a[1]..a[n],他取出了其中一些数,并把它们乘起来之后模p,得到了余数c.但是没过多久,小B就忘记他选了哪些数,他想把所有可能的取数方案都找出来.你 ...
- python3爬虫应用--爬取网易云音乐(两种办法)
一.需求 好久没有碰爬虫了,竟不知道从何入手.偶然看到一篇知乎的评论(https://www.zhihu.com/question/20799742/answer/99491808),一时兴起就也照葫 ...
- python语言编程算法
编程题 1 台阶问题/斐波那契 一只青蛙一次可以跳上1级台阶,也可以跳上2级.求该青蛙跳上一个n级的台阶总共有多少种跳法. fib = lambda n: n if n <= 2 else fi ...
- 强迫自己学Jquery
Jquery 适合我吗? 里面有很多用不上的功能, 我需要什么,常用的判断,常用的扩展,来自Dojo的Hitch函数,事件绑定,样式处理(添加 删除 替换),Ajax,模块加载, 足够了,真心不想用这 ...
- 使用Selenium爬取京东电商数据(以手机商品为例)
进入京东(https://www.jd.com)后,我如果搜索特定的手机产品,如oppo find x2,会先出现如下的商品列表页: 如果点击进入其中一个商品会进入到如下图所示的商品详情页,可以看到用 ...
- linux后台开发常用调试工具
一.编译阶段 nm 获取二进制文件包含的符号信息 strings 获取二进制文件包含的字符串常量 strip ...
- 极客mysql02
mysql 一条更新语句的执行过程: 1.首先客户端通过tcp/ip发送一条sql语句到server层的SQL interface 2.SQL interface接到该请求后,先对该条语句进行解析,验 ...
- linux之DHCP服务
1.DHCP介绍(动态主机配置协议) DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议, 主要用途:给内部网络或网络服务供应 ...
- osd磁盘空间足够无法写入数据的分析与解决
前言 这个问题的来源是ceph社区里面一个群友的环境出现在85%左右的时候,启动osd报错,然后在本地文件系统当中进行touch文件的时候也是报错,df -i查询inode也是没用多少,使用的也是in ...