python 爬取喜马拉雅节目生成RSS Feed
记录于:2020年12月03日
用了N年的手机在经历N次掉落之后终于扛不住了,后背都张嘴了,估计再摔一次电池都能飞出来。
换了手机,由于之前有听喜马拉雅的习惯,但是手机里自带有播客软件,强迫症逼着我不能下载喜马拉雅app。
找了几天没发现喜马拉雅提供的有RSS订阅(后来想了一下,别人怎么可能提供这个功能,O(∩_∩)O哈哈~),网上也没有相关服务。
苦啊,后来还是下载了喜马拉雅app,但是实在受不了,就索性自己捣鼓一个轮子。
诉求很简单,就是想将喜马拉雅的节目搬到播客软件,用原生的app听第三方的数据,这个需求好恶心啊,还好不是产品经理提的。
好吧,开始吧。
其实写爬虫,重要的不是代码实现,而是刚开始对需要爬取的数据的分析,分析怎么爬取,怎么得到自己的数据,只要这个流程明白了。代码实现就很简单了。
分析
浏览器打开喜马拉雅,找到想听的节目,比如:郭德纲
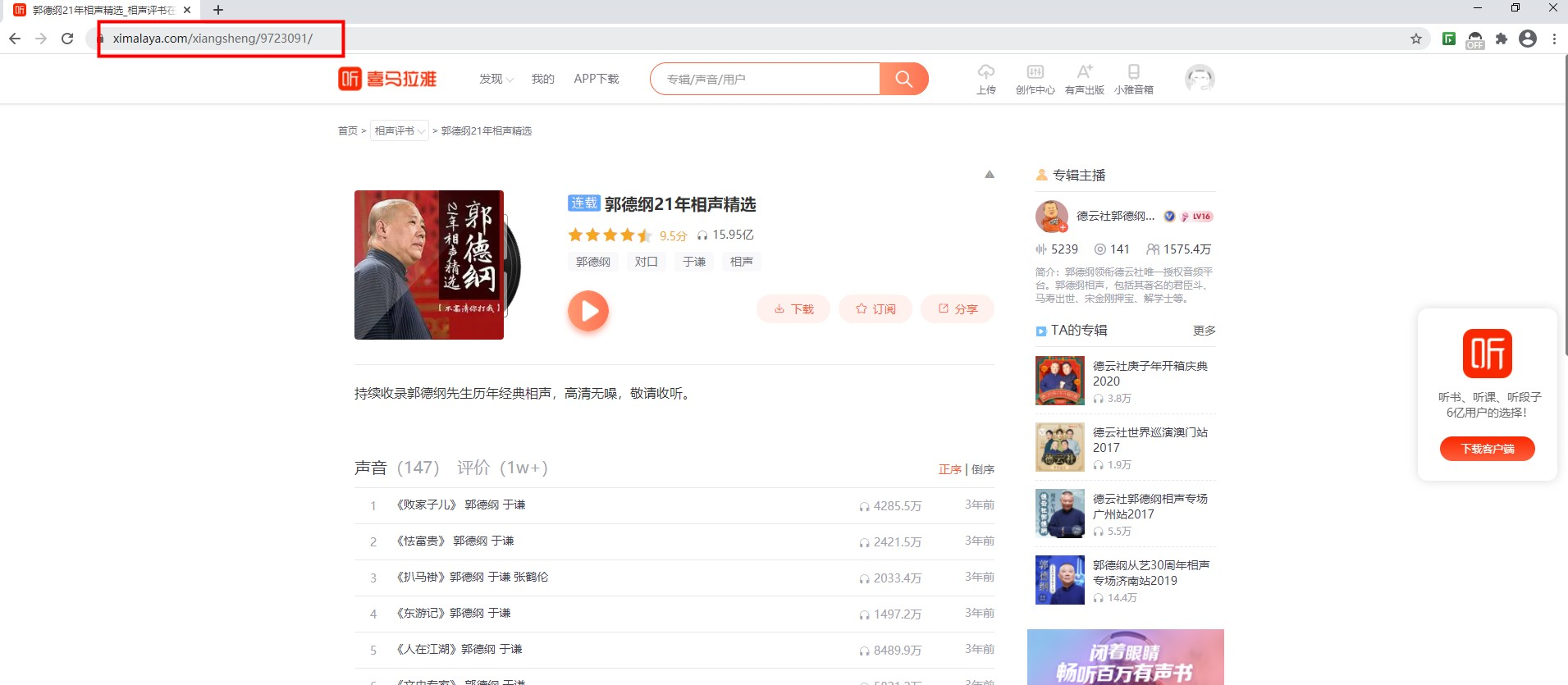
这样就有了爬取项目啦,对着这个页面开始分析,我需要标题,作者,图片三个元素,打开浏览器F12,找到这三个元素的定位,这样只需要相应的代码就能抓取信息了,这些信息就足够生成RSS中的<channel> 元素啦。
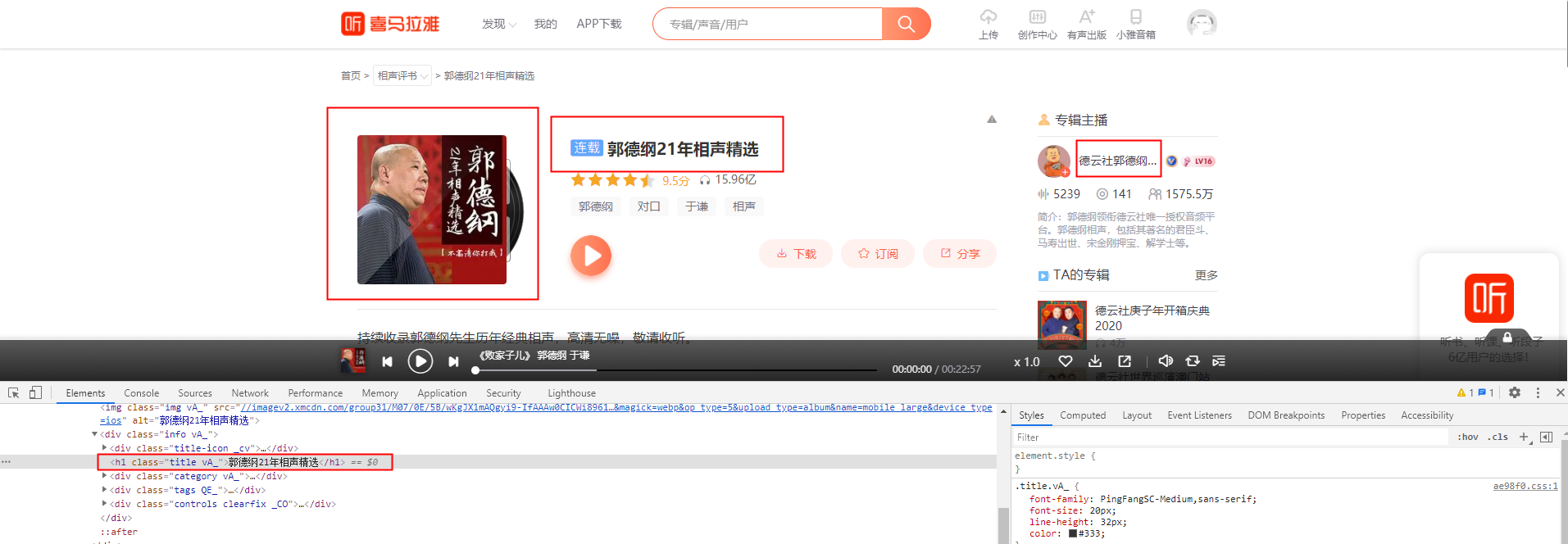
重要的是<item> 元素,播客播的就是这个元素中的信息。
其实就是要拿到页面上的 [播放列表],还是F12找到 [播放列表]的定位,有了定位,就可以抓取出这个列表,并获取这个列表中每个元素的链接,通过此链接就可以进去详情页。
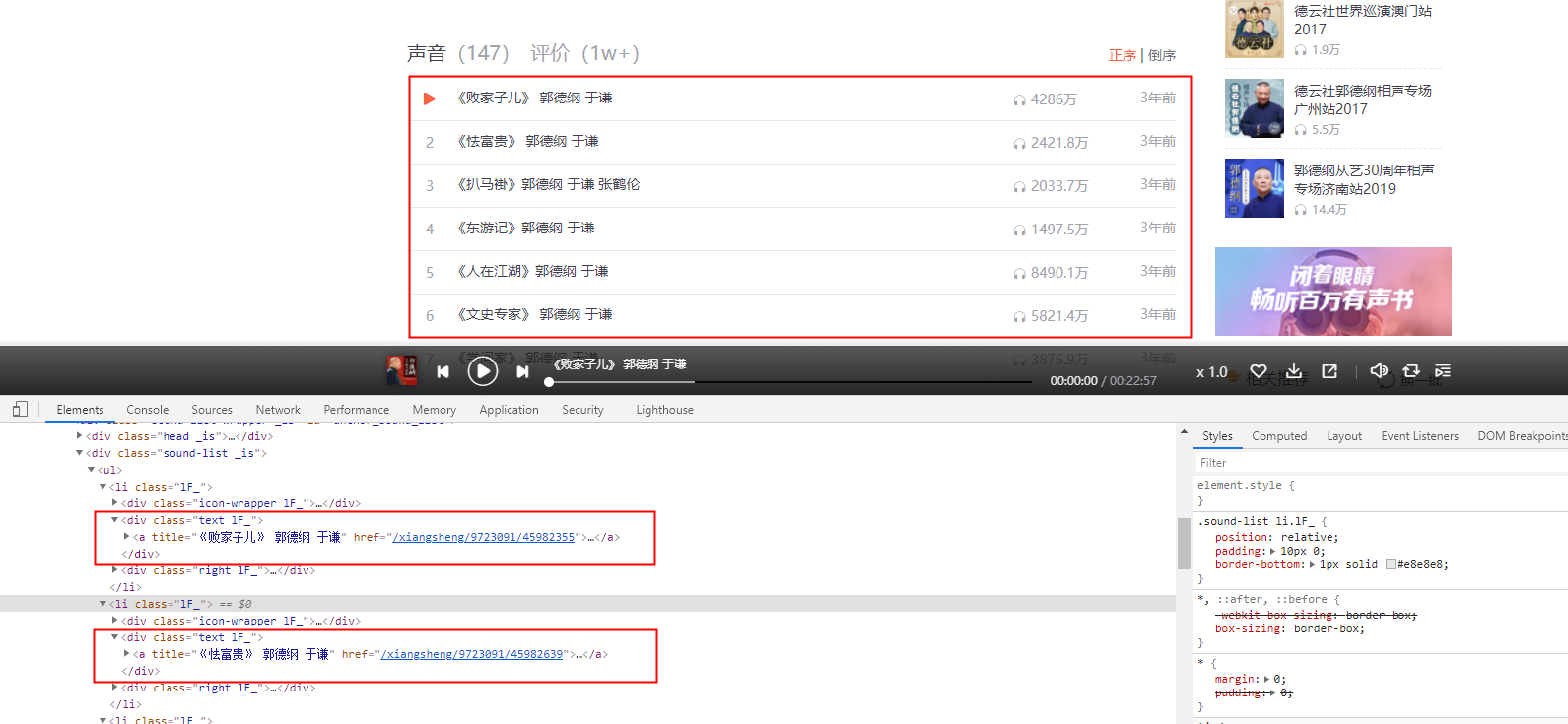
点开详情页,离实现越来越近了。
我需要标题,描述,及播放源这三个元素来构成<item> 元素。
标题和描述很好获取,还是老套路F12定位就可以了,播放源就需要观察了,打开F12,观察详情页有哪些请求,看是否有某些请求得到声音源数据,
通过发现:https://www.ximalaya.com/revision/play/v1/audio 这个请求,会响应数据播放数据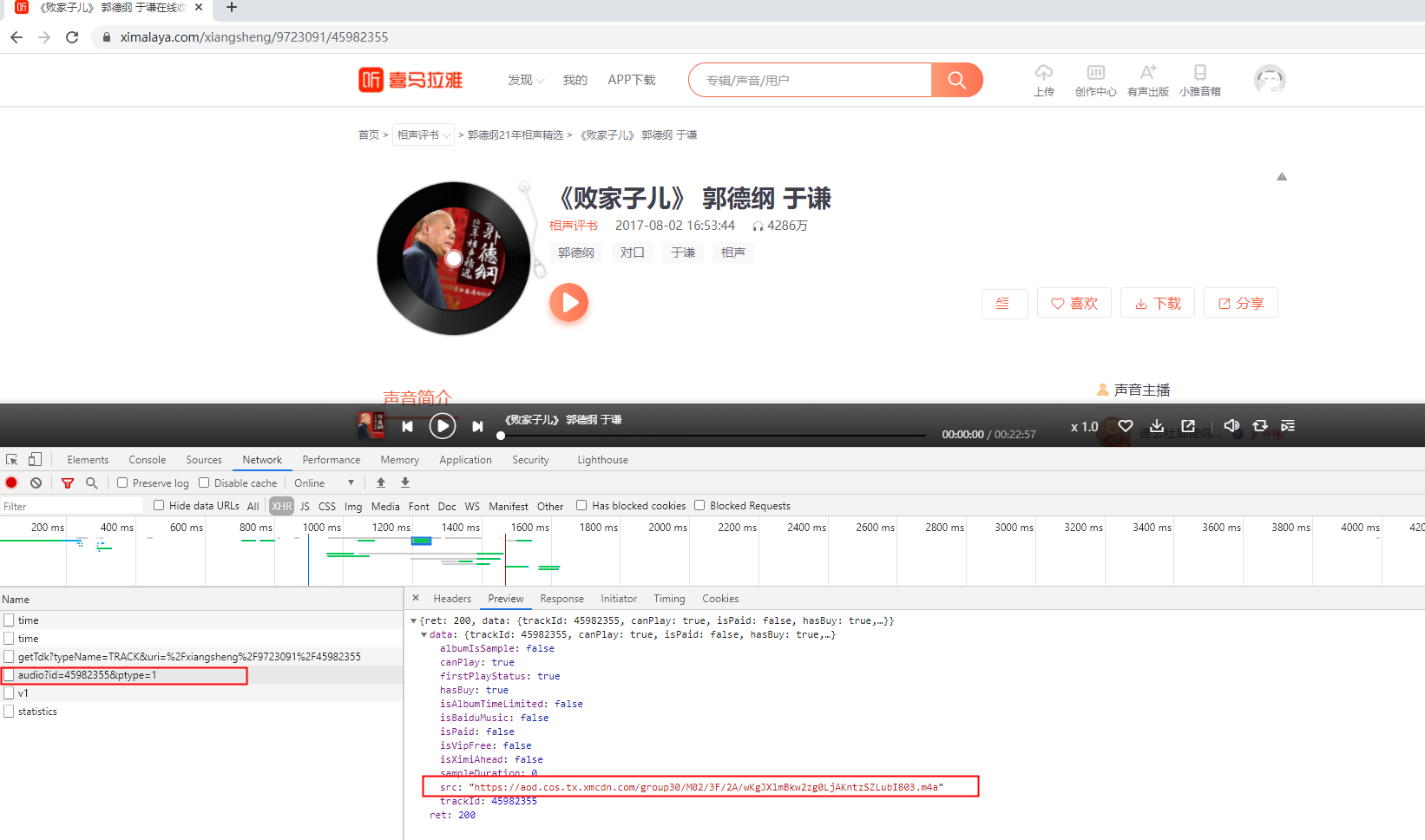
这就能拿到播放数据啦。这样一来,第一页的所有播放数据都能拿到了。
由于当前是列表页,所以少不了分页,我们只需要找出当前页面是否存在下一页,且找到下一页的链接,发起请求然后重复步骤,这样就能拿到整个列表页。
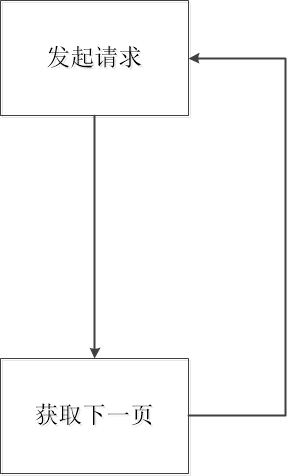
有了上面的一通分析,就知道了如何去编写代码实现这个功能啦。
编码
按照上面的流程,进行编码
1.构建Channel对象
2.构建Item对象
3.生成RSS(在同级目录下会生成一个xml文件)
import requests
from bs4 import BeautifulSoup
import datetime ##################################
##### 公用对象,存储/生成 ######
################################## # rss channel
class channel(object): def __init__(self, title, author, image):
self.title = title
self.author = author
self.image = image # rss item
class item(object): def __init__(self, title, pubDate, description,enclosure):
self.title = title
self.pubDate = pubDate
self.description = description
self.enclosure = enclosure ##################################
##### 爬取数据,存储 ######
################################## headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
} # 开始页 - 郭德纲21年相声精选
mainUrl = "https://www.ximalaya.com/xiangsheng/9723091/"
# 播放地址
playV1 = "/revision/play/v1/audio?id={}&ptype=1"
# gmt时间格式化
GMT_FORMAT = '%a, %d %b %Y %H:%M:%S GMT'
# 网址
ximalaya = mainUrl[:mainUrl.index('/',8)]
# 所有播放项
items = [] # 构建Channel对象
def getChannel():
r = requests.get(mainUrl, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
title = soup.find('h1', attrs={'class': 'title vA_'}).text
author = soup.find('a',attrs={'class':'nick-name gK_'}).text
image = "http:" + soup.find('img', attrs={'class': 'img vA_'})['src'].split('!')[0]
return channel(title, author, image) # 构建Item对象
def getItem(listPageUrl): print('======> 正在爬取列表页',listPageUrl)
r = requests.get(listPageUrl, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser') # 获取所有播放列表项详情
soundList = soup.find_all('div', attrs={'class': 'text lF_'})
for sound in soundList:
getDetails(ximalaya + sound.a['href']) # 进入下一页
pageNext = soup.find('li', attrs={'class': 'page-next page-item WJ_'})
if pageNext:
getItem(ximalaya + pageNext.a['href']) # 进入详情页
def getDetails(detailPageUrl): print("======> 正在爬取详情页",detailPageUrl) r = requests.get(detailPageUrl, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser') # 标题
title = soup.find('h1', attrs={'class': 'title-wrapper _uv'}).text
# 发布时间
pubDate = soup.find('span', attrs={'class': 'time _uv'}).text
# 声音简介
description = ""
if soup.find('article'):
description = soup.find('article').text # 播放源
playUrl = ximalaya + playV1.format(detailPageUrl.split('/')[-1]);
r = requests.get(playUrl, headers=headers)
enclosure = r.json()['data']['src'] items.append( item(title,datetime.datetime.strptime(pubDate, '%Y-%m-%d %H:%M:%S').strftime(GMT_FORMAT),description,enclosure) ) ##################################
##### 生成RSS ######
################################## def createRSS(channel): rss_text = r'<rss ' \
r' xmlns:atom="http://www.w3.org/2005/Atom" ' \
r' xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd" ' \
r' version="2.0" ' \
r' encoding="UTF-8"> ' \
r' <channel>' \
r' <title>{}</title>' \
r' <itunes:author>{}</itunes:author>' \
r' <itunes:image href="{}"/>' \
.format(channel.title, channel.author, channel.image) for item in items:
rss_text += r' <item>' \
r' <title>{}</title>' \
r' <description><![CDATA[{}]]></description>' \
r' <enclosure url="{}" type="audio/mpeg"/>' \
r' </item>'\
.format(item.title, item.description, item.enclosure) rss_text += r' </channel></rss>' print('======> 生成RSS')
print(rss_text) #写入文件
with open(mainUrl.split('/')[-2]+'.xml', 'w' ,encoding='utf-8') as f:
f.write(rss_text) if __name__=="__main__": channel = getChannel()
getItem(mainUrl)
createRSS(channel)
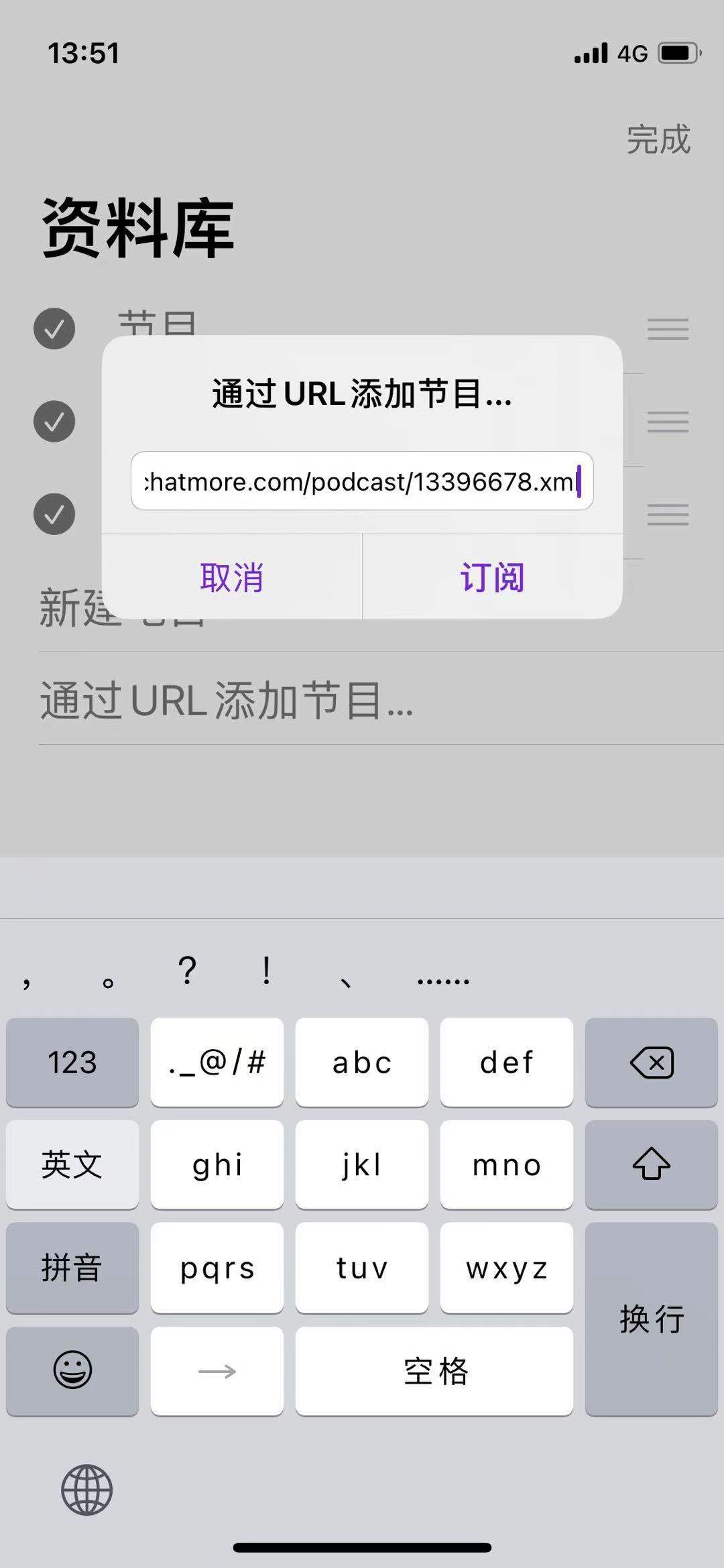
将生成后的xml放到服务器,就可以尽情享用了。
成果

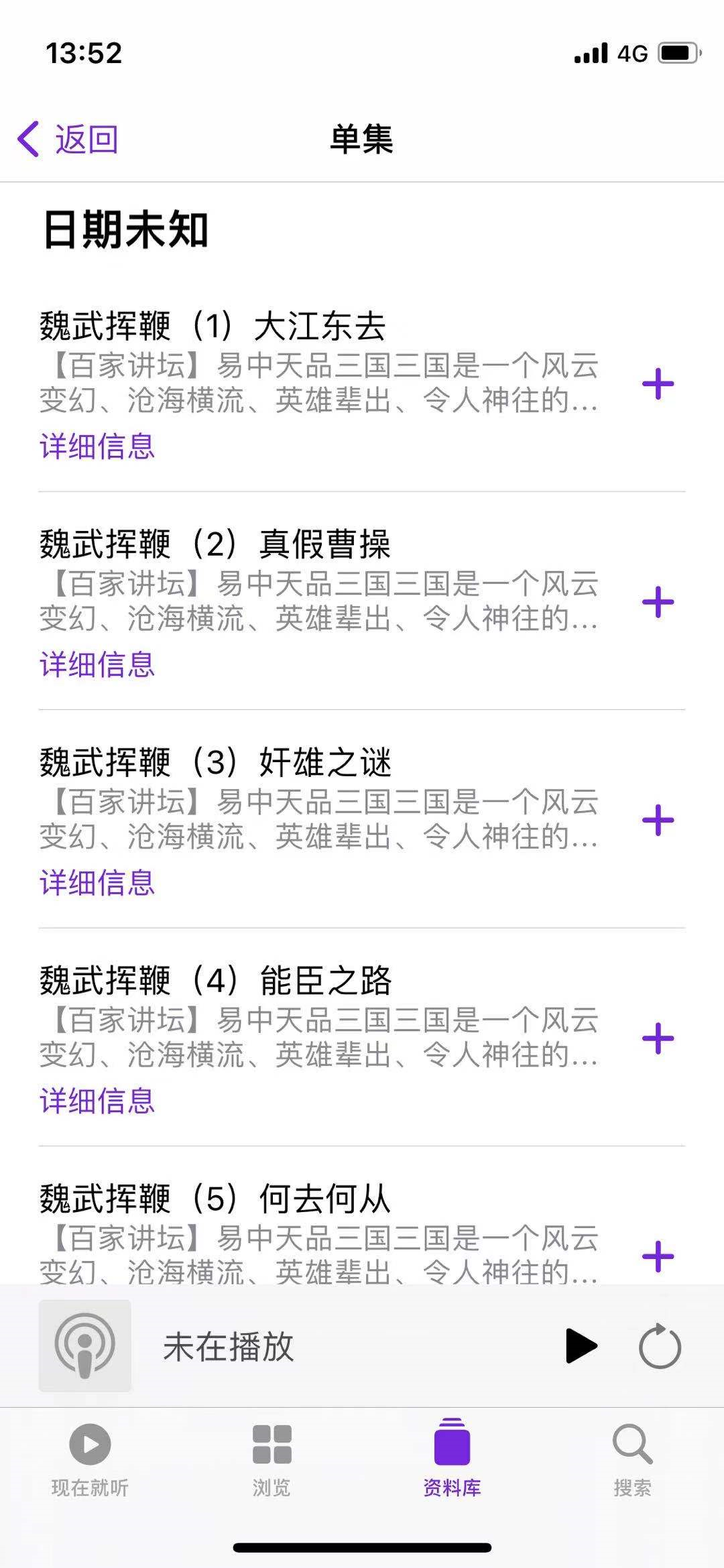
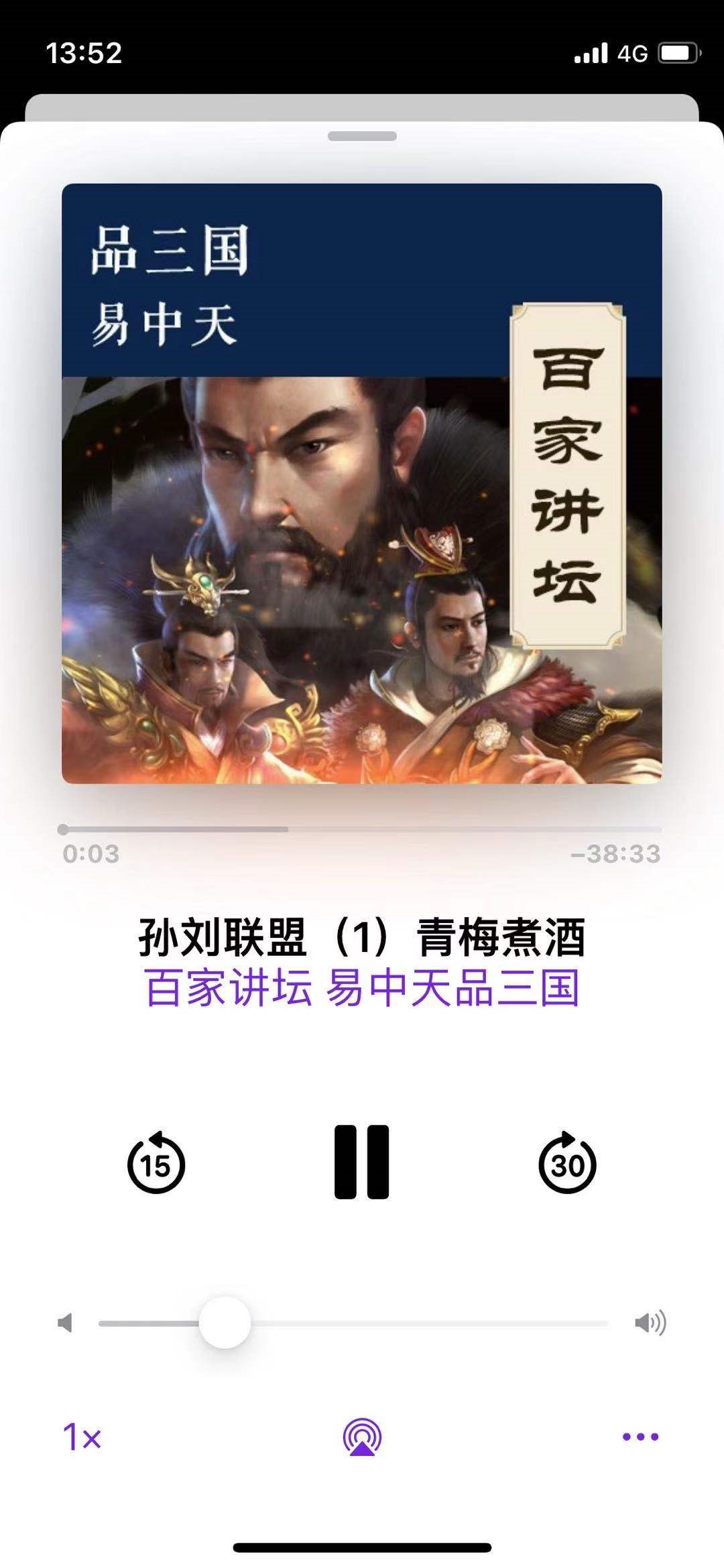
易中天老师讲的真的好
后续
本文编写于2020年12月3日,后续官方可能会对页面进行更改,请求进行更改等,会导致以上爬虫失效,所以需要知道如何进行分析,才能知道如何爬取。
以上代码只作为学习探讨,请问恶意使用!
python 爬取喜马拉雅节目生成RSS Feed的更多相关文章
- Python 爬取喜马拉雅音频
一.分析音频下载相关链接地址 1. 分析专辑音频列表页面 在 PC端用 Chrome 浏览器中打开 喜马拉雅 网站,打开 Chrome开发者工具,随意打开一个音频专辑页面,Chrome开发者工具中 ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- Python中使用requests和parsel爬取喜马拉雅电台音频
场景 喜马拉雅电台: https://www.ximalaya.com/ 找到一步小说音频,这里以下面为例 https://www.ximalaya.com/youshengshu/16411402/ ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- Python爬取招聘信息,并且存储到MySQL数据库中
前面一篇文章主要讲述,如何通过Python爬取招聘信息,且爬取的日期为前一天的,同时将爬取的内容保存到数据库中:这篇文章主要讲述如何将python文件压缩成exe可执行文件,供后面的操作. 这系列文章 ...
- python 爬取微信好友列表和个性签名,绘制个性签名云图
python爬取微信好友列表和个性签名,绘制个性签名云图 1. 简要介绍 本次实验主要用到下面几个库 : 1)itchat---用于微信接口,实现生成QR码,用于微信扫描登陆 2)re(正则化)--- ...
随机推荐
- 记录电子竞技游戏jesp中的传输过程公式
1.json数据转换成字典 dict1 = json.load(load_f1) dict2 = json.load(load_f2) 2.将两个字典按key排好序,然后使用zip()函数将两个字典对 ...
- JavaMail 发送邮件出现 Connection reset 问题
问题描述 使用 java mail 发送邮件的时候,申请的 163 邮箱作为发件箱,然无论如何配置,均出现 Connection reset,无法正常发送邮件. Exception in thread ...
- 怎么解决Git中出现 "LF will be replaced by CRLF" 警告
Windows中使用CRLF标识一行的结束,而在Linux/UNIX系统中只使用LF标识一行的结束.CRLF即Carriage-Return Line-Feed的缩写.通常情况下,Git库不会自动修改 ...
- 【Kata Daily 190927】Counting sheep...(数绵羊)
题目: Consider an array of sheep where some sheep may be missing from their place. We need a function ...
- 19、Haystack
Haystack 1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsear ...
- JS+CSS+HTML实现“代码雨”类似黑客帝国文字下落效果
HTML代码: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <l ...
- wpf 全局异常捕捉+简单日志记录
`namespace MyApp { /// /// App.xaml 的交互逻辑 /// public partial class App : Application { public App() ...
- 通过JS判断当前浏览器的类型
通过JS判断当前浏览器的类型,对主流浏览器Chrome.Edge.Firefox.UC浏览器.QQ浏览器.360浏览器.搜狗浏览器的userAgent属性值来判断用户使用的是什么浏览器. 不同浏览器的 ...
- MySql Binlog 说明 & Canal 集成MySql的更新异常说明 & MySql Binlog 常用命令汇总
文章来源于本人的印象笔记,如出现格式问题可访问该链接查看原文 原创声明:作者:Arnold.zhao 博客园地址:https://www.cnblogs.com/zh94 目录 背景介绍 开启MySq ...
- day05-类型转换和变量
1.类型转换概念 java是强类型语言,所以有些运算的时候,需要用到类型转换 类型转换原则:低-->高,byte,short,char-->int-->long-->float ...