Rainbow: Combining Improvements in Deep Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

arXiv:1710.02298v1 [cs.AI] 6 Oct 2017 (AAAI 2018)
Abstract
深度强化学习社区对DQN算法进行了一些独立的改进。但是,尚不清楚这些扩展中的哪些是互补的,是否可以有效地组合。本文研究了DQN算法的六个扩展,并通过经验研究了它们的组合。我们的实验表明,该组合在数据效率和最终性能方面均提供了Atari 2600基准测试的最新性能。我们还提供了详细的消融研究结果,显示了每个组件对整体性能的贡献。
Introduction
深度Q网络算法(DQN;Mnih et al. 2013,2015)启动了将强化学习(RL)扩展到复杂的顺序决策问题的许多最新成功。它将Q学习与CNN和经验重播相结合,使其能够从原始像素中学习如何以人类水平的性能玩许多Atari游戏。从那时起,许多扩展方案被提出以增强其速度或稳定性。
双重DQN (DDQN;van Hasselt, Guez, and Silver 2016) 通过去耦选择和bootstrap动作的评估,解决了Q学习的高估偏差(van Hasselt 2010)。优先经验重播(Prioritized Experience Replay, Schaul et al. 2015)通过重播更多的转换内容,从中学习更多来提高数据效率。对偶网络结构(Wang et al. 2016)通过分别表示状态价值和动作优势来帮助推广各种动作。从A3C(Mnih et al.2016)中使用的多步bootstrap目标学习(Sutton 1988;Sutton and Barto 1998),可以改变偏差-方差权衡并有助于将新观察到的奖励更快地传播到较早访问的状态。分布Q学习(Bellemare, Dabney, Munos 2017)学习折扣回报的分类分布,而不是估计均值。带噪DQN(Fortunato et al. 2017)使用随机网络层进行探索。当然,这个列表并不详尽。
这些算法中的每一种都可以在单独情况下显著提高性能。由于它们基于共享框架来解决根本不同的问题,因此可以合理地将它们组合在一起。在某些情况下,已经有这么做的:优先DDQN和对偶DDQN都使用双重Q学习,并且对偶DDQN也与优先经验重播结合在一起。在本文中,我们提出研究一种结合了所有上述成分的智能体。我们展示了如何将这些不同的想法整合在一起,并且它们确实在很大程度上是互补的。实际上,它们的结合在Arcade学习环境(Bellemare et al. 2013)的57套Atari 2600游戏的基准套件中带来了最新的技术成果,无论是数据效率还是最终性能。最后,我们显示了消融研究的结果,以帮助了解不同成分的贡献。
Background
强化学习解决了智能体学习如何在环境中动作以最大化标量奖励信号的问题。没有直接监督会被提供给智能体,例如,永远不会直接告诉智能体采取最优动作。
Agents and environments. 在每个离散时间步骤t = 0, 1, 2 …,环境向智能体提供观察值St,智能体通过选择动作At进行响应,然后环境提供下一个奖励Rt+1,折扣γt+1和状态St+1。这种交互被形式化为马尔可夫决策过程(Markov Decision Process,MDP),即元组(S, A, T, r, γ),其中S是状态的有限集合,A是动作的有限集合,T(s, a, s') = P[St+1 = s' | St = s, At = a]是(随机)转换函数,r(s, a) = E[Rt+1 | St = s, At = a]是奖励函数,而γ ∈ [0, 1]是折扣因子。在我们的实验中,MDP将是episodic的,其中常数γt = γ,除非episode终止(γt = 0),但算法以一般形式表示。
在智能体方面,动作选择由策略π给出,该策略定义了每个状态的动作概率分布。根据在时间 t 遇到的状态St,我们将折扣回报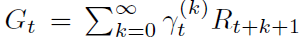 定义为智能体收集的未来奖励的折扣总和,其中未来k步奖励的折扣由该时间之前折扣的乘积给出,
定义为智能体收集的未来奖励的折扣总和,其中未来k步奖励的折扣由该时间之前折扣的乘积给出,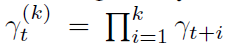 。智能体的目标是通过找到好的策略来最大化期望折扣回报。
。智能体的目标是通过找到好的策略来最大化期望折扣回报。
该策略可以直接学习,也可以根据其他一些学习量来构建。在基于价值的强化学习中,当从给定状态vπ(s) = Eπ[Gt | St = s](或状态-动作对,qπ(s, a) = Eπ[Gt | St = s, At = a])开始执行策略π时,智能体将学习期望折扣回报或价值的估计。从状态-动作价值函数派生新策略的一种常见方法是相对于动作价值ε-贪婪地采取动作。这对应于以概率(1 - ε)采取最高价值的动作(贪婪动作),否则以概率ε随机均匀地采取动作。此类策略用于引入一种探索形式:通过根据其当前估计值随机选择局部最优的动作,智能体可以在适当的时候发现并纠正其估计值。主要的局限性在于,很难发现可以延伸到未来的替代动作方案。这激发了更直接的探索形式的研究。
Deep reinforcement learning and DQN. 较大的状态与/或动作空间使得难以分别学习每个状态和动作对的Q值估计。在深度强化学习中,我们使用深度(即多层)神经网络表示智能体的各种组成部分,例如策略π(s, a)或价值q(s, a)。这些网络的参数通过梯度下降进行训练,以最小化一些合适的损失函数。
在DQN中(Mnih et al. 2015),深度神经网络和RL通过使用CNN成功地组合在一起,以近似估计给定状态St的动作价值(以原始像素帧栈的形式输入到网络中)。在每个步骤中,智能体基于当前状态,相对于动作价值ε-贪婪地选择一个动作,并将状态(St, At, Rt+1, γt+1, St+1)添加到重播内存缓冲区(Lin 1992),其中包含最近的一百万个转换。通过使用随机梯度下降来优化神经网络的参数,以最小化损失:
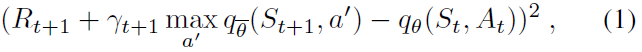
其中 t 是从重播内存中随机选取的时间步骤。损失的梯度仅反向传播到在线网络的参数θ中(这也用于选择动作);该项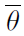 表示目标网络的参数;未直接优化的在线网络的定期复制。优化是使用RMSprop(Tieleman and Hinton 2012)(一种随机梯度下降的变体)对从经验重播中均匀采样的小批处理进行的。这意味着在上述损失中,时间索引 t 将是最近的一百万次转换以来的随机时间索引,而不是当前时间。使用经验重播和目标网络可以相对稳定地学习Q值,并在数款Atari游戏中带来超出人类的性能。
表示目标网络的参数;未直接优化的在线网络的定期复制。优化是使用RMSprop(Tieleman and Hinton 2012)(一种随机梯度下降的变体)对从经验重播中均匀采样的小批处理进行的。这意味着在上述损失中,时间索引 t 将是最近的一百万次转换以来的随机时间索引,而不是当前时间。使用经验重播和目标网络可以相对稳定地学习Q值,并在数款Atari游戏中带来超出人类的性能。
Extensions to DQN
DQN是一个重要的里程碑,但是现在知道该算法的一些局限性,并且已经提出了许多扩展。我们提出选择六个扩展,每个扩展都解决了局限性并提高了整体性能。为了使选择的规模易于管理,我们选择了一组扩展程序来解决不同的问题(例如,只是众多探索中的一个)。
Double Q-learning. 由于等式1中的最大化步骤,传统的Q学习受到高估偏差的影响,这可能会损害学习。双重Q学习(van Hasselt 2010)通过在引导目标执行的最大化中解耦来解决此高估的问题,即从其评估中选择动作。使用下面的损失,可以将其与DQN有效结合 (van Hasselt, Guez, and Silver 2016):
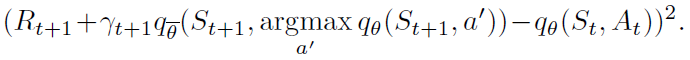
事实证明,此更改可以减少DQN所存在的有害高估,从而提高性能。
Prioritized replay. DQN从重播缓冲区均匀采样。理想情况下,我们希望更频繁地对那些需要学习的转换进行采样。作为学习潜能的智能体,优先经验重播(Schaul et al. 2015)以相对于最后遇到的绝对TD误差的概率pt对转换进行采样:
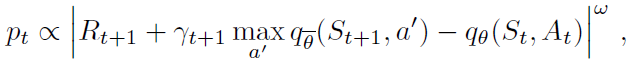
其中w是决定分布形状的超参数。新的转换将以最高优先级插入到重播缓冲区中,从而偏向于最近的转换。请注意,即使几乎没有什么可以了解的,随机转换也可能会受到青睐。
Dueling networks. 对偶网络是为基于价值的RL设计的神经网络架构。它具有两个计算流,即价值流和优势流,共享一个卷积编码器,并由一个特殊的聚合器合并(Wang et al. 2016)。这对应于以下动作价值分解:
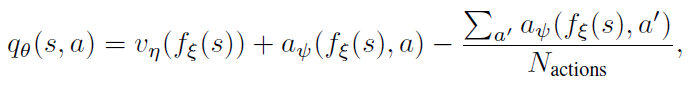
其中ξ,η和Ψ分别是共享编码器fξ,价值流vη和优势流aΨ的参数;并且θ = {ξ, η, Ψ}是它们的串联。
Multi-step learning. Q学习累积单个奖励,然后在下一步中使用贪婪动作进行bootstrap。或者,可以使用前视多步目标(Sutton 1988)。我们定义从给定状态St截断的n步回报为:
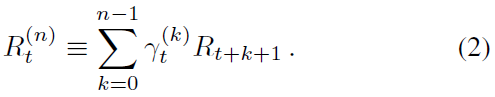
然后通过最小化替代损失来定义DQN的多步变体:
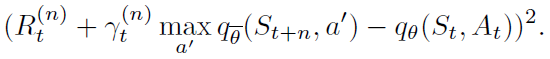
适当调整n的多步目标通常会导致学习速度更快(Sutton and Barto 1998)。
Distributional RL. 我们可以学习估计回报的分布,而不是期望回报。最近,Bellemare, Dabney, and Munos (2017)提出以概率密度放置在离散支持z上来建模此类分布,其中z是具有Natoms ∈ N+个原子的向量,对于i ∈ {1, ... , Natoms},定义为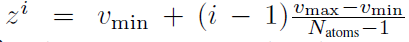 。在此支持上定义时间 t 处的近似分布dt,每个原子 i 上的概率密度为
。在此支持上定义时间 t 处的近似分布dt,每个原子 i 上的概率密度为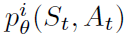 ,使得
,使得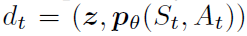 。目标是更新θ,以使该分布与回报的实际分布紧密匹配。
。目标是更新θ,以使该分布与回报的实际分布紧密匹配。
要学习概率密度,关键的见解是回报分布满足Bellman方程的一个变体。对于给定的状态St和动作At,最优策略π*下的回报分配应与通过获取下一个状态St+1和动作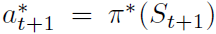 的分布,根据折扣将其收缩为零,并根据奖励(或随机情况下的奖励分布)进行调整。然后,通过首先为目标分布构造新的支持,然后最小化分布dt和目标分布
的分布,根据折扣将其收缩为零,并根据奖励(或随机情况下的奖励分布)进行调整。然后,通过首先为目标分布构造新的支持,然后最小化分布dt和目标分布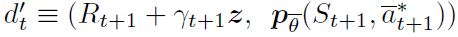 之间的Kullbeck-Leibler散度来推导Q学习的分布变体:
之间的Kullbeck-Leibler散度来推导Q学习的分布变体:

其中Φz是目标分布到固定支持z上的L2投影,并且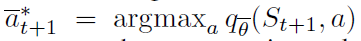 是相对于状态St+1中平均动作价值
是相对于状态St+1中平均动作价值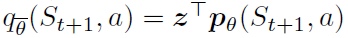 的贪婪动作。
的贪婪动作。
与非分布情况一样,我们可以使用参数的冻结复制来构建目标分布。与DQN中一样,参数化分布可以由神经网络表示,但具有Natoms x Nactions个输出。对输出的每个动作维度独立应用softmax,以确保每个动作的分布都适当地归一化。
Noisy Nets. 在“蒙特祖玛的复仇”这类游戏中,使用ε-贪婪策略进行探索的局限性显而易见,在游戏中必须执行许多动作才能获得第一笔奖励。带噪网络(Fortunato et al. 2017)提出了一种将确定性和噪声流相结合的带噪线性层:
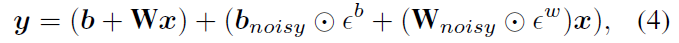
其中εb和εw是随机变量, 表示按元素乘积。然后可以使用此变换来代替标准线性y = b + Wx。随着时间的流逝,网络可以学会忽略噪声流,但是会在状态空间的不同部分以不同的rate忽略噪声流,从而允许采用自退火形式的状态条件探索。
表示按元素乘积。然后可以使用此变换来代替标准线性y = b + Wx。随着时间的流逝,网络可以学会忽略噪声流,但是会在状态空间的不同部分以不同的rate忽略噪声流,从而允许采用自退火形式的状态条件探索。
The Integrated Agent
在本文中,我们将所有上述组件整合到单个集成智能体中,我们将其称为Rainbow。
首先,我们将一步分布损失(3)替换为多步变量。我们通过根据累计折扣收缩价值分布,并用截断的n步折扣回报对其进行移位,构造目标分布。这对应于将目标分布定义为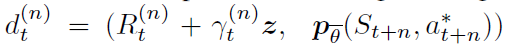 。产生的损失为:
。产生的损失为:
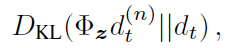
其中,Φz是在z上的投影。
通过将根据在线网络选择的St+n中的贪婪动作作为bootstrap动作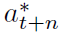 ,并使用目标网络评估这种动作,我们将多步分布损失与双重Q学习结合起来。
,并使用目标网络评估这种动作,我们将多步分布损失与双重Q学习结合起来。
在标准成比例优先重播中(Schaul et al. 2015),使用绝对TD误差确定转换的优先级。这可以使用平均动作价值在分布设置中进行计算。但是,在我们的实验中,所有分布Rainbow变体均按KL损失作为转换的优先级,因为这是该算法最小化的方法:
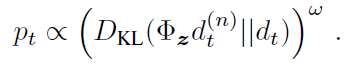
用KL损失作为优先级对于带噪的随机环境可能更为稳健,因为即使回报不确定,损失也会继续减少。
该网络结构是适用于回报分布的对偶网络结构。网络具有共享表示fξ(s),然后将其送入具有Natoms个输出的价值流vη和具有Natoms x Nactions个输出的优势流aξ,其中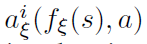 将表示对应于原子 i 和动作a的输出。对于每个原子zi,将价值和优势流汇聚在一起,就像在对偶DQN中一样,然后通过softmax层以获得用于估计回报分布的归一化参数分布:
将表示对应于原子 i 和动作a的输出。对于每个原子zi,将价值和优势流汇聚在一起,就像在对偶DQN中一样,然后通过softmax层以获得用于估计回报分布的归一化参数分布:
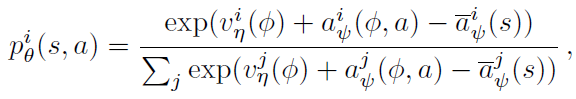
其中,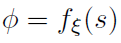 且
且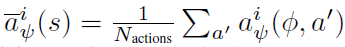 。
。
然后我们用等式(4)中描述的等效噪声替换所有线性层。在这些带噪线性层中,我们使用分解高斯噪声(Fortunato et al. 2017)来减少独立噪声变量的数量。
Experimental Methods
现在,我们描述用于配置和评估学习智能体的方法和设置。
Evaluation Methodology. 我们从Arcade学习环境中评估了57种Atari 2600游戏上的所有智能体(Bellemare et al. 2013)。我们遵循Mnih et al. (2015)和van Hasselt et al. (2016)的训练和评估程序。在训练过程中,通过暂停学习并评估500K帧的最新智能体,在环境中每1M个步骤评估智能体的平均得分。如van Hasselt et al. (2016)所述,episode以108K帧(或30分钟的模拟播放)被截断。
每个游戏的智能体得分均经过归一化处理,因此0%对应随机智能体,而100%则相当于人类专家的平均得分。可以在所有Atari水平上汇聚归一化分数,以比较不同智能体的性能。跟踪所有游戏中人类归一化性能的中位数很常见。我们还考虑了智能体性能高于人类性能几分的游戏数量,以理清中位数改进的来源。平均人类归一化性能可能没有那么丰富的信息,因为它受到一些游戏(例如,Atlantis)的支配,在这些游戏中,智能体取得的得分比人类高几个数量级。
除了根据环境步骤跟踪中位数性能外,在训练结束时,我们还使用两种不同的测试方案重新评估最优智能体快照。在无操作启动机制中,我们在每个episode的开头插入无操作动作的一个随机数(最多30个)(就像我们在训练中一样)。在人类启动机制中,episode是利用从人类专家轨迹的初始部分随机采样的点进行初始化的(Nair et al. 2015);两种机制之间的差异表明了智能体过拟合其自身轨迹的程度。
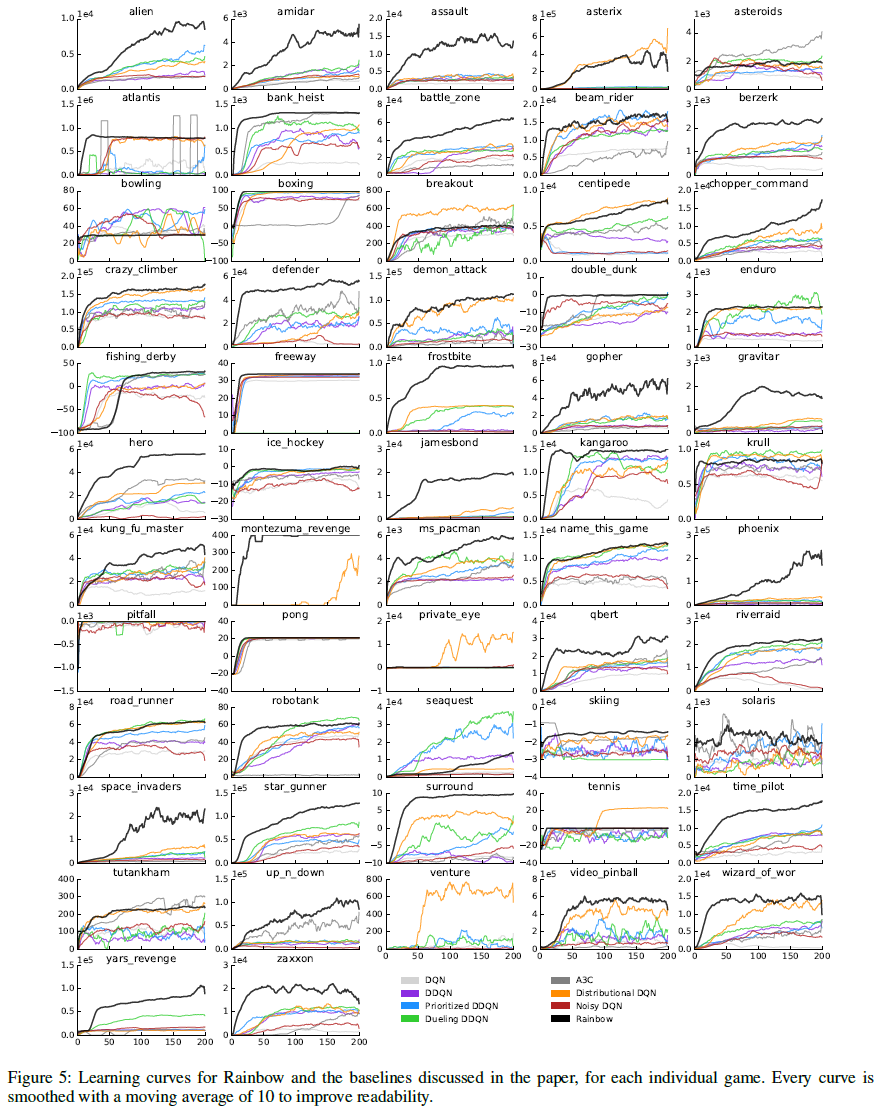
由于篇幅所限,我们专注于跨游戏的聚合结果。但是,在附录中,我们提供了在无操作和人类启动测试机制中所有游戏和所有智能体的完整学习曲线,以及原始分数和归一化分数的详细比较表。
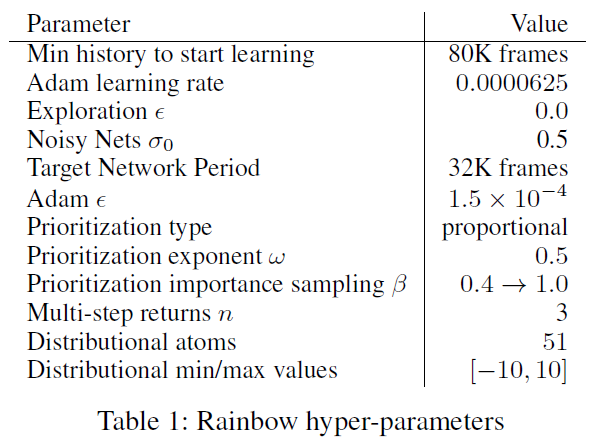
Hyper-parameter tuning. Rainbow的所有组件都有许多超参数。超参数的组合空间太大,无法进行详尽的搜索,因此我们进行了有限的调整。对于每个组件,我们从介绍该组件的论文中使用的值开始,然后通过手动坐标下降来调整超参数中最敏感的值。
DQN及其变体在前200K帧期间不执行学习更新,以确保足够不相关的更新。我们发现,通过优先播放,可以在仅80K帧之后更快地开始学习。
DQN从1的探索ε开始,对应于随机均匀地动作;它将前4M帧的探索量退火,最终值为0.1(在以后的变体中降低到0.01)。无论何时使用带噪网络,我们都会完全贪婪地动作(ε = 0),用于超参数σ0的0.5值用于初始化带噪流中的权重1。对于没有带噪网络的智能体,我们使用ε-贪婪,但探索速度的降低速度比以前使用的快,在前250K帧中将ε退火到0.01。
我们使用了Adam优化器(Kingma and Ba 2014),发现它对学习率的选择不如RMSProp敏感。DQN使用的学习率α = 0.00025。在所有Rainbow的变体中,我们使用的学习率为α/4,选自{α/2, α/4, α/6},Adam的超参数ε值为1.5 x 10-4。
对于重播优先级,我们使用了建议的成比例变量,优先级指数ω为0.5,并且在训练过程中将重要性采样指数β从0.4线性增加到1。比较{0.4, 0.5, 0.7}的值,优先级指数ω被调整。使用分布DQN的KL损失作为优先级,我们已经观察到性能对于ω的选择是非常鲁棒的。
多步学习中的n值是Rainbow的敏感超参数。我们比较了n = 1, 3, 5的值。我们观察到n = 3, 5最初都表现良好,但总体n = 3到最后表现最优。
在所有57款游戏中,超参数(请参阅表1)均相同,即Rainbow智能体实际上是在所有游戏中均表现良好的单个智能体设置。
1噪声是在GPU上产生的。Tensorflow噪声生成在GPU上可能不可靠。如果在CPU上产生噪音,将σ0降低到0.1可能会有所帮助。
Analysis
在本节中,我们分析了主要的实验结果。首先,我们证明Rainbow与多家已发布的智能体相比具有优势。然后,我们进行消融研究,比较智能体的几种变体,每种变体对应于从Rainbow去除单个成分。
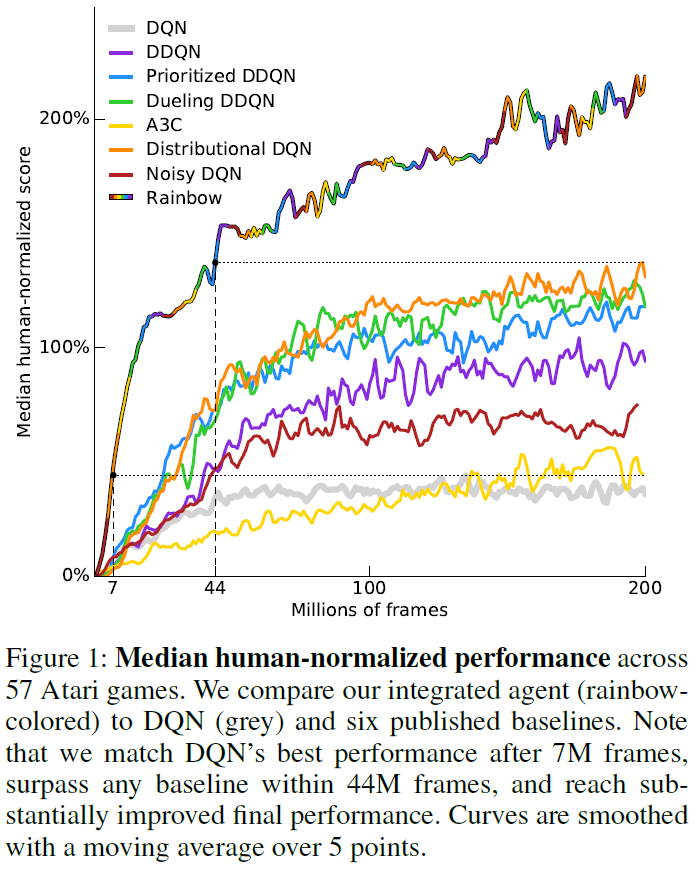
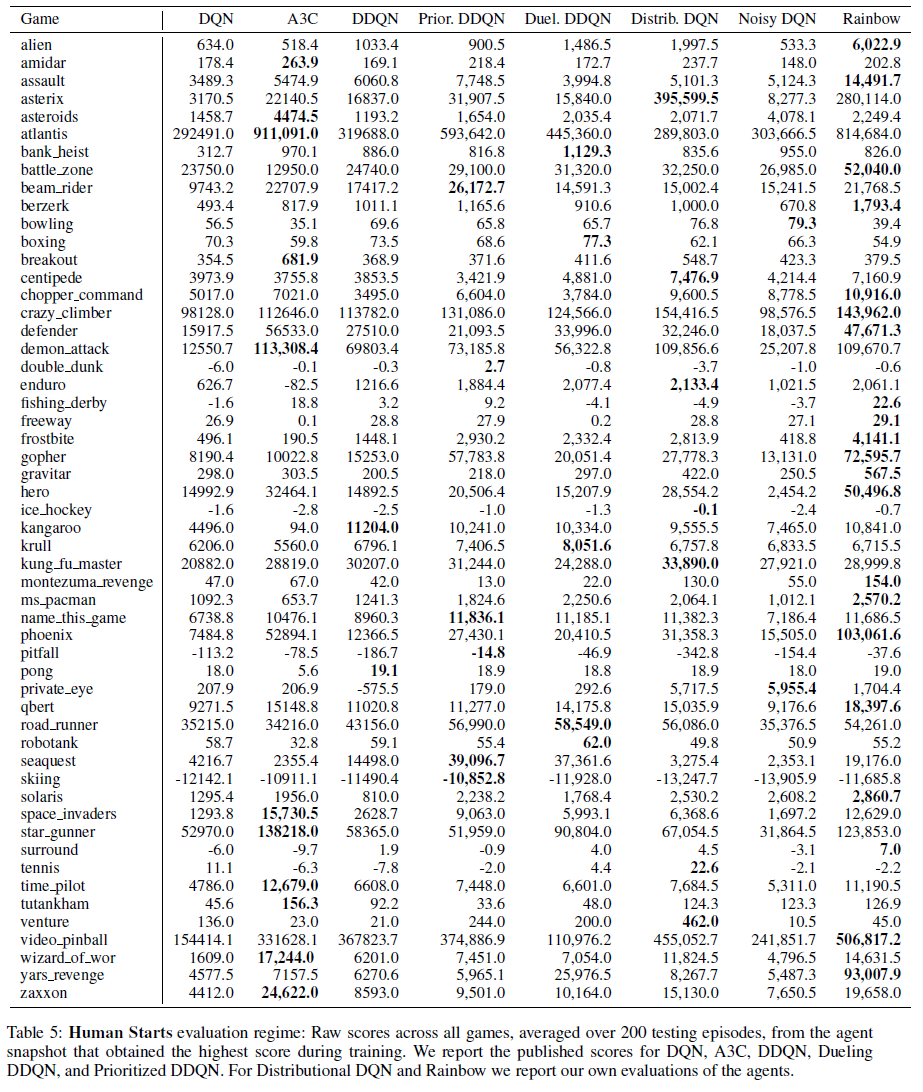
Comparison to published baselines. 在图1中,我们将Rainbow的性能(以游戏中的人类归一化得分的中位数衡量)与A3C,DQN,DDQN,优先DDQN,对偶DDQN,分布DQN和带噪DQN的相应曲线进行了比较。我们感谢对偶和优先智能体的作者提供了这些学习曲线,并报告了我们自己针对DQN,A3C,DDQN,分布DQN和带噪DQN的重新运行。在数据效率和最终性能方面,Rainbow的性能均明显优于任何基准。请注意,我们匹配了7M帧后DQN的最终性能,超过了这些基准在4400万帧中的最优最终性能,并达到了大幅提高的最终性能。
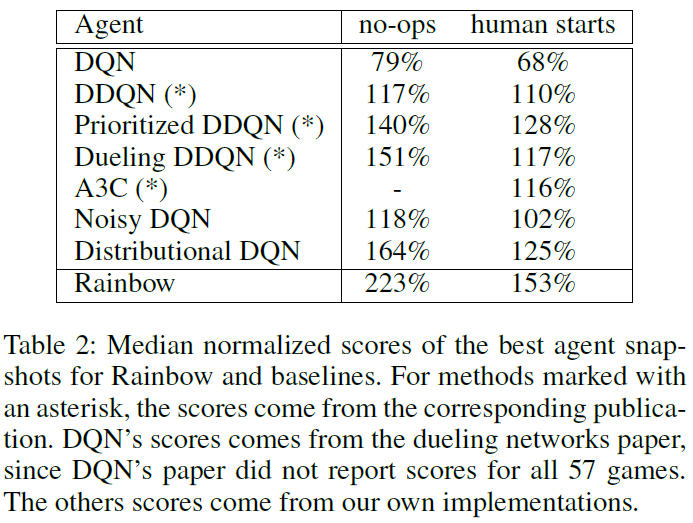
在对智能体的最终评估中,训练结束后,Rainbow在无人值守状态下的中位数得分为223%。在人类启动机制,我们测得的中位数得分为153%。在表2中,我们将这些分数与已发布的各个基准的中位数进行了比较。
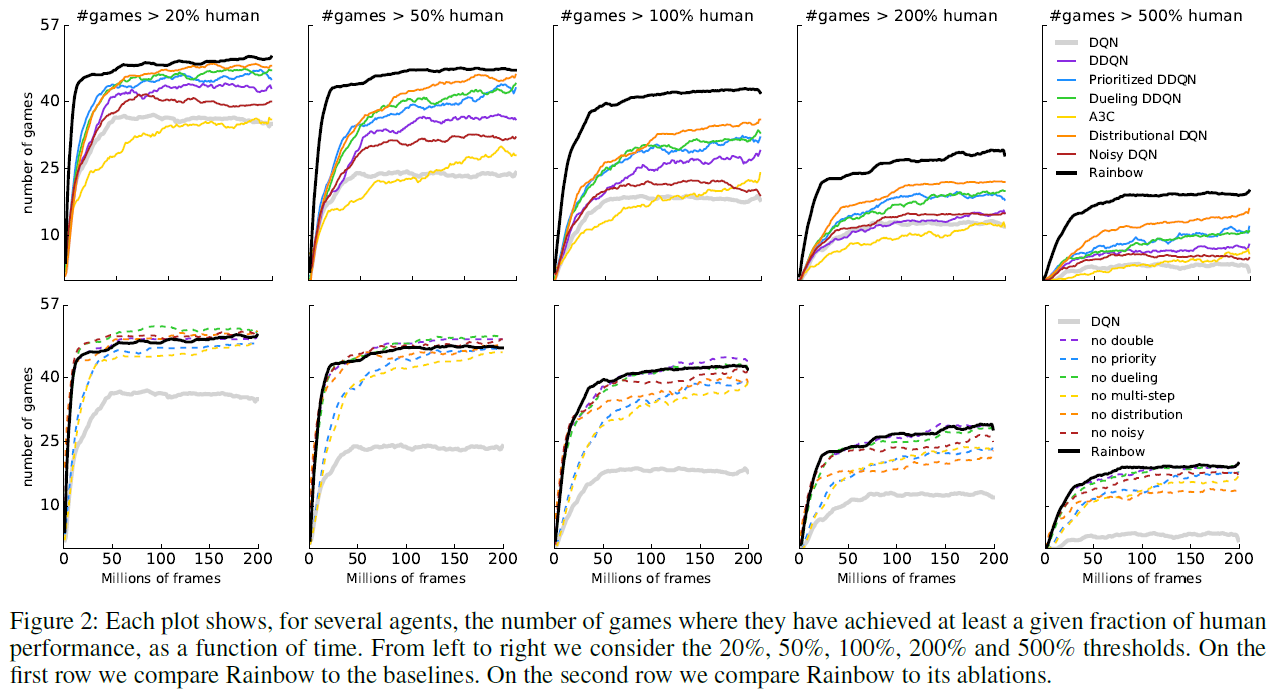
在图2(最上一行)中,我们绘制了智能体达到某种特定水平的人类归一化性能的游戏数量。从左至右,子图显示了不同智能体在多少个游戏中实现了20%,50%,100%,200%和500%的人类归一化性能。这使我们能够确定整体性能改进来自何处。请注意,Rainbow和其他智能体之间的性能差距在所有性能水平上都很明显:Rainbow智能体正在改进基准智能体已经不错的游戏得分,以及改进基准智能体仍远没有人类表现的游戏。
Learning speed. 与原始DQN设置一样,我们在单个GPU上运行每个智能体。与DQN的最终性能匹配所需的7M帧对应不到10个小时的挂钟时间。200M帧的完整运行时间大约相当于10天,而所有讨论的变体之间的差异不到20%。文献中包含许多替代训练设置,它们可以通过利用并行性来提高性能作为挂钟时间的函数,例如Nair et al. (2015),Salimans et al. (2017)和Mnih et al. (2016)。在如此截然不同的硬件/计算资源之间适当地关联性能并非易事,因此我们只专注于算法变体,从而可以进行横向比较。尽管我们认为它们很重要且相互补充,但我们将可伸缩性和并行性问题留给未来的工作。
Ablation studies. 由于Rainbow将多个不同的想法整合到一个智能体中,因此我们在此特定组合的背景下进行了额外的实验,以了解各个组件的作用。
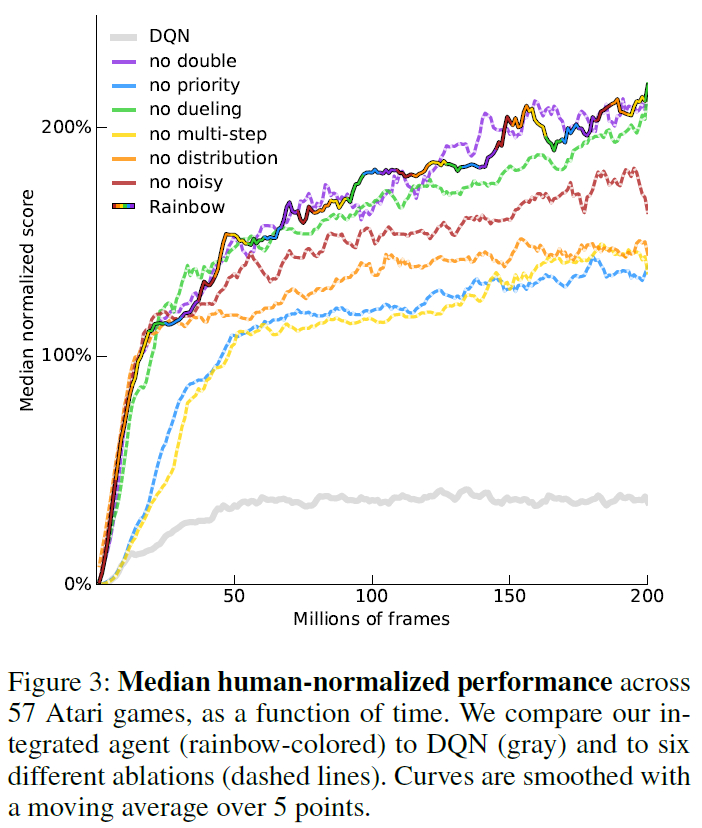
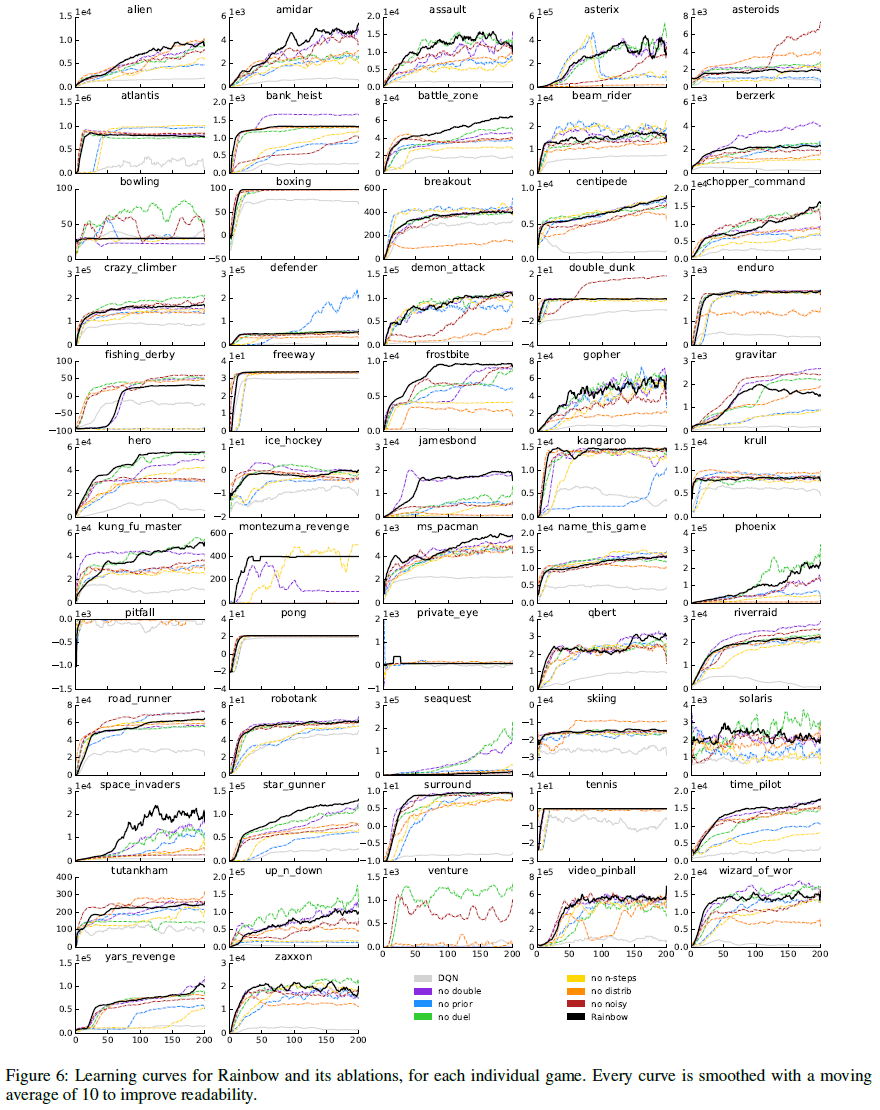
为了更好地了解每种成分对Rainbow智能体的贡献,我们进行了消融研究。在每次消融中,我们从完整的Rainbow组合中删除了一个组件。图3显示了完整Rainbow与六个消融变体的归一化得分中位数的比较。图2(底部行)显示了这些消融相对于人类归一化性能的不同阈值如何表现的更详细细分,图4显示了每个游戏从每个消融中获得的收益或损失,在整个学习过程中进行平均。
优先重播和多步学习是Rainbow的两个最关键的组成部分,因为删除这两个组成部分都会导致中位数性能大幅下降。毫不奇怪,删除其中任何一个都会损害早期性能。也许更令人惊讶的是,取消多步学习也损害了最终性能。放大各个游戏(图4),我们看到这两个组件在整个游戏中几乎都起到了一致的作用(在57个游戏中有53个游戏中,完整的Rainbow的性能要优于任一消融)。
分布Q学习在与智能体性能的相关性方面排名在前面的技术之后。值得注意的是,在早期学习中没有明显区别,如图3所示,其中对于前4000万帧,执行了分布消融以及完全智能体。但是,如果没有分布,智能体的性能便开始落后。当图2中的结果与人类性能相对分开时,我们看到分布消融似乎主要滞后在那些高于或接近人类水平的游戏。
就中位数性能而言,如果将带噪网络包括在内,该智能体的性能会更好。当删除这些并且将探索委托给传统的ε-贪婪机制时,总体性能会变差(图3中的红线)。尽管删除带噪网络会使若干游戏的性能大幅下降,但其他游戏的性能也有所提高(图4)。
总体而言,从完整的Rainbow中删除对偶网络时,我们没有观察到显著差异。但是,中位数得分掩盖了对偶的影响在游戏之间有所不同的事实,如图4所示。图2显示,对偶可能会对性能水平高于人类的游戏(#游戏 > 200%)提供一些改进,而对低于人类性能的游戏(#游戏 > 20%)则有所降低。
同样在双重Q学习的情况下,所观察到的中位数性能差异(图3)是有限的,根据游戏的不同,组件有时会造成伤害或帮助(图4)。为了进一步研究双重Q学习的作用,我们将受过训练的智能体的预测与根据限幅奖励计算出的实际折扣回报进行了比较。将Rainbow与消融了双重Q学习的智能体进行比较,我们观察到实际回报通常高于10,因此不在分布的支持范围内,从-10到+10。这导致回报的低估,而不是高估。我们假设将价值裁剪到此约束范围会抵消Q学习的高估偏差。但是请注意,如果扩展了分布的支持,则可能会增加双重Q学习的重要性。
在附录中,我们为每个游戏展示了Rainbow的最终性能和学习曲线,以及它的消融和基准。

Discussion
我们已经证明,对DQN的多项改进可以成功地集成到单个学习算法中,从而实现最先进的性能。而且,我们已经表明,在集成算法中,除其中一个组件之外的所有组件都提供了明显的性能优势。我们还没有包含更多的算法组件,这些组件有望在集成智能体程序上进行进一步的实验。在众多可能的候选中,我们讨论了以下几个。
我们在这里专注于Q学习系列中基于价值的方法。我们尚未考虑纯粹基于策略的RL算法,例如信任域策略优化(Schulman et al. 2015),或执行者-评论者方法(Mnih et al. 2016;O'Donoghue et al. 2016)。
许多算法利用一系列数据来提高学习效率。最优性收紧(He et al. 2016)使用多步回报来构建额外不等式界限,而不是使用它们代替Q学习中使用的一步目标。资格迹允许对n步回报进行软组合(Sutton 1988)。但是,与Rainbow中使用的多步目标相比,顺序方法都在每个梯度上利用更多的计算量。此外,引入优先序列重播会引发有关如何存储,重播和确定序列优先级的问题。
Episodic控制(Blundell et al. 2016)也关注数据效率,并且在某些领域被证明是非常有效的。它通过使用episodic记忆作为补充学习系统来改进早期学习,能够立即重新制定成功的动作序列。
除了带噪网络之外,许多其他探索方法也可能是有用的算法要素:在这些Bootstrapped DQN(Osband et al. 2016),内在动机(Stadie, Levine, and Abbeel 2015)和基于计数的探索中(Bellemare et al. 2016)。这些替代组件的集成是有待进一步研究的硕果。
在本文中,我们专注于核心学习更新,而没有探索替代的计算架构。从环境的并行复制进行异步学习,如A3C(Mnih et al. 2016),Gorila(Nair et al. 2015)或进化策略(Salimans et al. 2017),至少在挂钟时间方面,可以有效地加快学习速度。但是请注意,它们的数据效率可能较低。
分层RL(HRL)也已成功应用于多种复杂的Atari游戏。在成功应用HRL的过程中,我们重点介绍了h-DQN(Kulkarni et al. 2016a)和封建网络(Vezhnevets et al. 2017)。
通过利用辅助任务,例如像素控制或特征控制(Jaderberg et al. 2016),监督预测(Dosovitskiy and Koltun 2016)或后续特征(Kulkarni et al. 2016b),也可以使状态表示更加高效。
为了根据基准公平地评估Rainbow,我们遵循了奖励裁剪,固定动作重复和帧堆叠的常见领域修改,但是这些可能会因其他学习算法的改进而被删除。波普艺术归一化(van Hasselt et al. 2016)允许删除奖励裁剪,同时保持相似的性能水平。细粒度的动作重复(Sharma, Lakshminarayanan, and Ravindran 2017)使我们能够学习如何重复动作。循环状态网络(Hausknecht and Stone 2015)可以学习时序状态表示,从而取代了固定的观察帧栈。总的来说,我们认为将真实游戏暴露给智能体是未来研究的有希望的方向。
Appendix
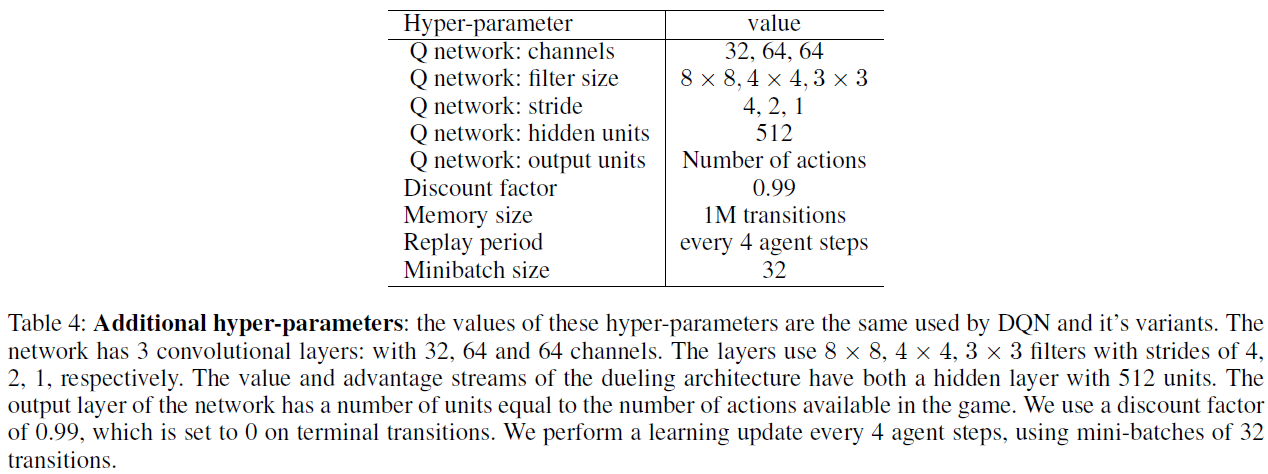
表3列出了DQN引入的环境框架,奖励和折扣的预处理。表4列出了Rainbow从DQN继承的其他超参数以及本文考虑的其他基准。而是在正文中列出Rainbow使用非标准设置的超参数。在随后的页中,我们列出了表格,显示每个游戏的Rainbow得分以及无操作机制(表6)和人类启动机制(表5)中的几个基准。在图5和6中,我们还为每个游戏绘制了Rainbow的学习曲线,几个基准以及所有消融实验。这些学习曲线在10个窗口内用移动平均进行平滑处理。


Rainbow: Combining Improvements in Deep Reinforcement Learning的更多相关文章
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- Deep Reinforcement Learning
Reinforcement-Learning-Introduction-Adaptive-Computation http://incompleteideas.net/book/bookdraft20 ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- Learning Roadmap of Deep Reinforcement Learning
1. 知乎上关于DQN入门的系列文章 1.1 DQN 从入门到放弃 DQN 从入门到放弃1 DQN与增强学习 DQN 从入门到放弃2 增强学习与MDP DQN 从入门到放弃3 价值函数与Bellman ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
随机推荐
- OnePill本地保存用户的结构
sharedPreferences存储的数据 int Code code 表示当前用户的类别:医生为1,用户为2. Sting user user 存储当前user的json字符串 String do ...
- 恕我直言,我也是才知道ElasticSearch条件更新是这么玩的
背景 ElasticSearch 的使用度越来越普及了,很多公司都在使用.有做日志搜索的,有做商品搜索的,有做订单搜索的. 大部分使用场景都是通过程序定期去导入数据到 ElasticSearch 中, ...
- python绝技:运用python成为顶级黑客|中文pdf完整版[42MB|网盘地址附提取码自行提取|
Python 是一门常用的编程语言,它不仅上手容易,而且还拥有丰富的支持库.对经常需要针对自己所 处的特定场景编写专用工具的黑客.计算机犯罪调查人员.渗透测试师和安全工程师来说,Python 的这些 ...
- 【保姆级教学】新手第一次搭建vue项目和初始化
前端项目初始化步骤 安装vue脚手架 通过vue脚手架创建项目 配置vue路由 配置Element-UI组件库 配置axios库 初始化git远程仓库 将本地项目托管到github或者码云上 通过vu ...
- CF582D Number of Binominal Coefficients 库默尔定理 数位dp
LINK:Number of Binominal Coefficients 原来难题都长这样.. 水平有限只能推到一半. 设\(f(x)\)表示x中所含p的最大次数.即x质因数分解之后 p的指标. 容 ...
- 用好这几个技巧,解决Maven Jar包冲突易如反掌
前言 大家在项目中肯定有碰到过Maven的Jar包冲突问题,经常出现的场景为: 本地运行报NoSuchMethodError,ClassNotFoundException.明明在依赖里有这个Jar包啊 ...
- python程序设计PDF高清完整版免费下载|百度云盘
百度云盘:python程序设计PDF高清完整版免费下载 提取码:bvsz Python 程序设计基础难易程度适中.除Python应用开发基础知识之外,还适当介绍了Python标准库以及内置对象的工作原 ...
- 线性DP 学习笔记
前言:线性DP是DP中最基础的.趁着这次复习认真学一下,打好基础. ------------------ 一·几点建议 1.明确状态的定义 比如:$f[i]$的意义是已经处理了前$i个元素,还是处理第 ...
- SpringMVC入门和常用注解
SpringMVC的基本概念 关于 三层架构和 和 MVC 三层架构 我们的开发架构一般都是基于两种形式,一种是 C/S 架构,也就是客户端/服务器,另一种是 B/S 架构,也就 是浏览器服务器.在 ...
- 找工作的你不容错过的45个PHP面试题附答案(下篇)
找工作的你不容错过的45个PHP面试题附答案(上篇) Q28:你将如何使用PHP创建Singleton类? /** * Singleton class * */ final class UserFac ...