聊聊经典数据结构HashMap,逐行分析每一个关键点
本文基于JDK-8u261源码分析
本文原创首发于 奇客时间(qiketime)
1 简介
HashMap是一个使用非常频繁的键值对形式的工具类,其使用起来十分方便。但是需要注意的是,HashMap不是线程安全的,线程安全的是ConcurrentHashMap(Hashtable这种过时的工具类就不要再提了),在Spring框架中也会用到HashMap和ConcurrentHashMap来做各种缓存。从Java 8开始,HashMap的源码做了一定的修改,以此来提升其性能。首先来看一下HashMap的数据结构:
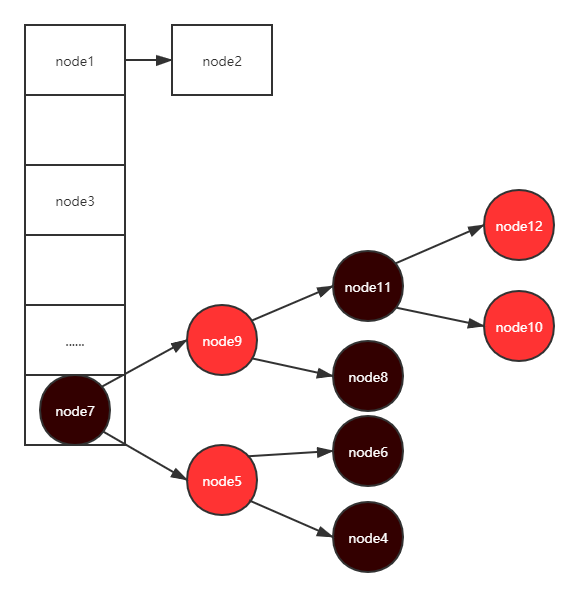
整体上可以看作是数组+链表的形式。数组是为了进行快速检索,而如果hash函数冲突了的话,就会在同一个位置处后面进行挂链表的操作。也就是说,同一个链表上的节点,它们的hash值计算出来都是一样的。但是如果hash冲突比较多的时候,生成的链表也会拉的比较长,这个时候检索起来就会退化成遍历操作,性能就比较低了。在Java 8中为了改善这种情况,引入了红黑树。
红黑树是一种高级的平衡二叉树结构,其能保证查找、插入、删除的时间复杂度最坏为O(logn)。在大数据量的场景下,相比于AVL树,红黑树的插入删除性能要更高。当链表中的节点数量大于等于8的时候,同时当前数组中的长度大于等于MIN_TREEIFY_CAPACITY时(注意这里是考点!所以以后不要再说什么当链表长度大于8的时候就会转成红黑树,这么说只会让别人觉得你没有认真看源码),链表中的所有节点会被转化成红黑树,而如果当前链表节点的数量小于等于6的时候,红黑树又会被退化成链表。其中MIN_TREEIFY_CAPACITY的值为64,也就是说当前数组中的长度(也就是桶bin的个数)必须大于等于64的时候,同时当前这个链表的长度大于等于8的时候,才能转化。如果当前数组中的长度小于64,即使当前链表的长度已经大于8了,也不会转化。这点需要特别注意。以下的treeifyBin方法是用来将链表转化成红黑树操作的:
1/**
2 * Replaces all linked nodes in bin at index for given hash unless
3 * table is too small, in which case resizes instead.
4 */
5final void treeifyBin(Node<K,V>[] tab, int hash) {
6 int n, index; Node<K,V> e;
7 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
8 resize();
9 else if ((e = tab[index = (n - 1) & hash]) != null) {
10 TreeNode<K,V> hd = null, tl = null;
11 do {
12 TreeNode<K,V> p = replacementTreeNode(e, null);
13 if (tl == null)
14 hd = p;
15 else {
16 p.prev = tl;
17 tl.next = p;
18 }
19 tl = p;
20 } while ((e = e.next) != null);
21 if ((tab[index] = hd) != null)
22 hd.treeify(tab);
23 }
24}
从上面的第7行和第8行代码处可以看出,如果当前数组的长度也就是桶的数量小于MIN_TREEIFY_CAPACITY的时候,会选择resize扩容操作,此时就不会走转成红黑树的逻辑了。这里的意思就是说如果当前的hash冲突达到8的时候,根本的原因就是因为桶分配的太少才产生那么多冲突的。那么此时我选择扩容操作,以此来降低hash冲突的产生。等到数组的长度大于等于MIN_TREEIFY_CAPACITY的时候,如果当前链表的长度还是8的话,才会去转化成红黑树。
由此可以看出加入MIN_TREEIFY_CAPACITY这个参数的意义就是在于要保证hash冲突多的原因不是因为数组容量少才导致的;还有一个意义在于,假如说当前数组的所有数据都放在了一个桶里面(或者类似于这种情况,绝大部分的节点都挂在了一个桶里(hash函数散列效果不好,一般不太可能出现)),此时如果没有MIN_TREEIFY_CAPACITY这个参数进行限制的话,那我就会去开开心心去生成红黑树去了(红黑树的生成过程以及后续的维护还是比较复杂的,所以原则上是能不生成就不生成,后面会有说明)。而有了MIN_TREEIFY_CAPACITY这个参数进行限制的话,在上面的第8行代码处就会触发扩容操作。这里的扩容更多的意义在于把这个hash冲突尽量削减。比如把链表长度为8的八个节点再平分到扩容后新的两倍数组的两处新的桶里面,每个桶由原来的八个节点到现在的四个节点(也可能是一个桶5个另一个桶3个,极端情况下也可能一个桶8个另一个桶0个。但不管怎样,从统计学上考量的话,原来桶中的节点数大概率会被削减),这样就相当于减少了链表的个数,也就是说减少了在同一个位置上的hash冲突的发生。还有一点需要提一下,源码注释中说明MIN_TREEIFY_CAPACITY的大小要至少为4倍的转成红黑树阈值的数量,这么做的原因也是更多的希望能减少hash冲突的发生。
**那么为什么不直接用红黑树来代替链表,而是采用链表和红黑树来搭配在一起使用呢?**原因就在于红黑树虽然性能更好,但是这也仅是在大数据量下才能看到差异。如果当前数据量很小,就几个节点的话,那么此时显然用链表的方式会更划算。因为要知道红黑树的插入和删除操作会涉及到大量的自旋,以此来保证树结构的平衡。如果数据量小的话,插入删除的性能高效根本抵消不了自旋操作所带来的成本。
**还有一点需要留意的是链表转为红黑树的阈值是8,而红黑树退化成链表的阈值是6。**为什么这两个值会不一样呢?可以试想一下,如果这两个值都为8的话,而当前链表的节点数量为7,此时一个新的节点进来了,计算出hash值和这七个节点的hash值相同,即发生了hash冲突。于是就会把这个节点挂在第七个节点的后面,但是此时已经达到了变成红黑树的阈值了(MIN_TREEIFY_CAPACITY条件假定也满足),于是就转成红黑树。但是此时调用了一次remove操作需要删掉这个新加的节点,删掉之后当前红黑树的节点数量就又变成了7,于是就退化成了链表。然后此时又新加了一个节点,正好又要挂在第七个节点的后面,于是就又变成红黑树,然后又要remove,又退化成链表…可以看到在这种场景下,会不断地出现链表和红黑树之间的相互转换,这个性能是很低的,因为大部分的执行时间都花费在了转换数据结构上面,而我仅仅是做了几次连续的增删操作而已。所以为了避免这种情况的发生,将两个阈值错开一些,以此来尽量避免在阈值点附近可能存在的、频繁地做转换数据结构操作而导致性能变低的情况出现。
这里之所以阈值会选择为8是通过数学统计上的结论得出的,在源码中也有相关注释:

其中中间的数字表示当前这个位置预计发生指定次数哈希冲突的概率是多少。可以看到当冲突概率为8的时候,概率已经降低到了0.000006%,几乎是不可能发生的概率。从这里也可以看出,HashMap作者选择这个数作为阈值是不希望生成红黑树的(红黑树的维护成本高昂)。而同样负载因子默认选择为0.75也是基于统计分析出来的,以下是源码中对负载因子的解释:
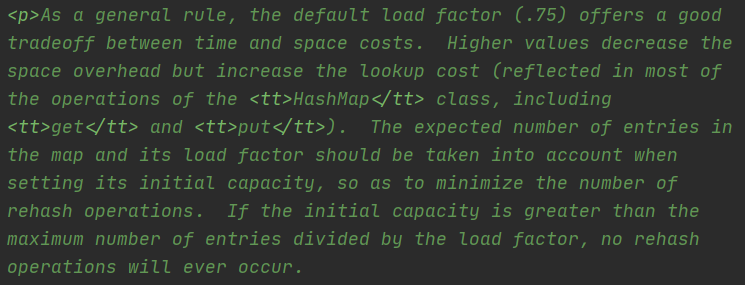
负载因子衡量的是数组在扩容前的填充程度,也就是说一个数组真正能存进去的实际容量 = 数组的长度 * 负载因子(比如当前数组的长度为16(桶的个数),负载因子为0.75,那么当数组存进了16 * 0.75 = 12个桶的时候,就会进行扩容操作,而不是等到数组空间满了的时候)。如果为0.5表示的就是数组填充一半后就进行扩容;为1就表示的是数组全部填满后再进行扩容。之所以默认值选择为0.75是在时间和空间成本上做的一个折中方案,一般不建议自己更改。这个值越高,就意味着数组中能存更多的值,减少空间开销,但是会增加hash冲突的概率,增加查找的成本;这个值越低,就会减少hash冲突的概率,但是会比较费空间。
而数组的默认容量为16也是统计上的结果。值得一说的是,如果事先知道了HashMap所要存储的数量的时候,就可以将数组容量传进构造器中,以此来避免频繁地扩容操作。比如我现在要往HashMap中大约放进200个数据,如果不设置初始值的话,默认容量就是16,当存进16 * 0.75 = 12个数据的时候就会扩容一次,扩容到两倍容量32,然后等再存进32 * 0.75 = 24个数据的时候再继续扩容…直到扩容到能存进200个数据为止。所以说,如果能提前先设置好初始容量的话,就不需要再扩容这么多次了。
2 构造器
1/**
2 * HashMap:
3 * 无参构造器
4 */
5public HashMap() {
6 //负载因子设置为默认值0.75,其他的属性值也都是走默认的
7 this.loadFactor = DEFAULT_LOAD_FACTOR;
8}
9
10/**
11 * 有参构造器
12 */
13public HashMap(int initialCapacity) {
14 //初始容量是自己指定的,而负载因子是默认的0.75
15 this(initialCapacity, DEFAULT_LOAD_FACTOR);
16}
17
18public HashMap(int initialCapacity, float loadFactor) {
19 //initialCapacity非负校验
20 if (initialCapacity < 0)
21 throw new IllegalArgumentException("Illegal initial capacity: " +
22 initialCapacity);
23 //initialCapacity如果超过了设定的最大值(2的30次方),就重置为2的30次方
24 if (initialCapacity > MAXIMUM_CAPACITY)
25 initialCapacity = MAXIMUM_CAPACITY;
26 //负载因子非负校验和非法数字校验(当被除数是0或0.0,而除数是0.0的时候,得出来的结果就是NaN)
27 if (loadFactor <= 0 || Float.isNaN(loadFactor))
28 throw new IllegalArgumentException("Illegal load factor: " +
29 loadFactor);
30 this.loadFactor = loadFactor;
31 /*
32 将threshold设置为大于等于当前设置的数组容量的最小2次幂
33 threshold会在resize扩容方法中被重新更新为新数组容量 * 负载因子,也就是下一次的扩容点
34 */
35 this.threshold = tableSizeFor(initialCapacity);
36}
37
38/**
39 * 这个方法是用来计算出大于等于cap的最小2次幂的,但是实现的方式很精巧,充分利用了二进制的特性
40 */
41static final int tableSizeFor(int cap) {
42 /*
43 这里的-1操作是为了防止cap现在就已经是2的幂的情况,后面会进行说明。为了便于理解,这里举个例子:
44 假设此时cap为34(100010),n就是33(100001)。我们其实只要关注第一个最高位是1的这个位置,即从左
45 到右第一个为1的位置。通用的解释是01xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx(x代表不确定,不用关心这个位置上是0还是1)
46 */
47 int n = cap - 1;
48 /*
49 经过一次右移操作并按位或之后,n变成了110001(100001 | 010000)
50 通用解释:此时变成了011xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
51 */
52 n |= n >>> 1;
53 /*
54 此时经过两次右移操作并按位或之后,n变成了111101(110001 | 001100)
55 通用解释:此时变成了01111xxxxxxxxxxxxxxxxxxxxxxxxxxx
56 */
57 n |= n >>> 2;
58 /*
59 此时经过四次右移操作并按位或之后,n变成了111111(111101 | 000011)
60 通用解释:此时变成了011111111xxxxxxxxxxxxxxxxxxxxxxx
61 */
62 n |= n >>> 4;
63 /*
64 此时经过八次右移操作并按位或,对于上面的示例数据来说,此时已经变成了所有位都是1的情况,
65 那么下面的两次右移操作做了和没做已经没区别了(因为右移后的结果肯定是0,和原来的数按位或之后是没有变的)
66 其实经过这么多次的右移并按位或,就是为了最后能得出一个全是1的数
67 通用解释:此时变成了01111111111111111xxxxxxxxxxxxxxx
68 */
69 n |= n >>> 8;
70 /*
71 此时经过十六次右移操作并按位或,通用解释:此时变成了01111111111111111111111111111111
72 需要说明一下的是int的位数是32位,所以只需要右移16位就可以停止了(当然也可以继续右移32位,64位...
73 只不过那样的话就没有什么意义了,因为右移后的结果都是0,按位或的结果是不会发生变动的)
74 而int的最大值MAX_VALUE是2的31次方-1,换算成二进制就是有31个1
75 在之前的第25行代码处已经将该值改为了2的30次方,1后面有30个0,即010000...000
76 所以传进来该方法的最大值cap只能是这个数,经过-1再几次右移操作后就变成了00111...111,即30个1
77 最后在第90行代码处+1后又会重新修正为2的30次方,即MAXIMUM_CAPACITY
78 */
79 n |= n >>> 16;
80 /*
81 n如果小于0对应的是传进来的cap本身就是0的情况。经过右移后,n变成了-1(其实右不右移根本不会改变结果,
82 因为-1的二进制数就是32个1,和任何数按位或都不会发生变动),这个时候就返回结果1(2的0次方)就行了
83
84 由此可以看到,最后的效果就是得出了一个原始数据从第一个最高位为1的这个位置开始,后面的所有位不管是0还是1都改成1
85 最后在第90行代码处再加一后就变成了最高位是1而剩下位都是0的一个数,但是位数比原数据多一位,也就是原数据的最小2次幂了
86
87 现在可以考虑一下之前说过的如果传进来的cap本身就是2的幂的情况。假如说没有第47行代码操作的话,那么经过不断右移操作后,
88 得出来的是一个全是1的二进制数,也就是这个数*2-1的结果,最后再加1后就变成了原数据的2倍,这显然是不对的
89 */
90 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
91}
3 put方法
1/**
2 * HashMap:
3 */
4public V put(K key, V value) {
5 return putVal(hash(key), key, value, false, true);
6}
7
8/**
9 * 计算key的hash值
10 * 注意这里是直接调用key的hashCode方法,并且会将其高16位和低16位进行异或来作为最终的hash(Java中的int值是32位)
11 * 那么为什么会这样做呢?因为在后续的判断插入桶bin的位置使用的方法是(table.length - 1) & hash
12 * 这里数组的长度必须为2的幂(如果不是则会转换成大于该值的最小2次幂,详见tableSizeFor方法),那么数组的长度减去1后的值
13 * 用二进制来表示就是11111...低位全都是1的一个数。这样再去和本方法计算出来的hash值进行按位与的话,结果就是一个
14 * 保留了hash值所有这些低位上的数,说白了就是和hash % table.length这种是一样的结果,就是对数组长度取余而已
15 * 但是直接用%做取余的话效率不高,而且这种按位与的方式只能适用于数组长度是2的幂的情况,不是这种情况的话是不能做等价交换的
16 *
17 * 从上面可以看到,按位与的方式只会用到hash值低位的信息,高位的信息不管是什么都无所谓,反正不会记录到最后的hash计算中
18 * 这样的话就觉得有些可惜、有些浪费。如果将高位信息也进行记录的话那就更好了。所以在下面第26行代码处,
19 * 将其高16位和低16位进行异或,就是为了将高16位的特征信息也融合进hash值中,尽量使哈希变得散列,减少hash冲突的发生
20 * 同时使用一个异或操作的话也很简单高效,不会像有些hash函数一样会进行很多的计算后才会生成一个hash值(比如说这块
21 * 在Java 7中的实现就是会有很多次的右移操作)
22 * <<<在底层源码中,在能完成需求的前提下,能实现得越简单越高效,就是王道>>>
23 */
24static final int hash(Object key) {
25 int h;
26 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
27}
28
29/**
30 * 第5行代码处:
31 */
32final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
33 boolean evict) {
34 Node<K, V>[] tab;
35 Node<K, V> p;
36 int n, i;
37 if ((tab = table) == null || (n = tab.length) == 0)
38 //如果当前数组还没有初始化的话,就进行初始化的工作。由此可以看到,HashMap的初始化工作被延迟到了put方法中
39 n = (tab = resize()).length;
40 if ((p = tab[i = (n - 1) & hash]) == null)
41 /*
42 通过(n - 1) & hash的方式来找到这个数据插入的桶位置(至于为什么用这种方式详见hash方法的注释)
43 如果这个桶上还没有数据存在的话,就直接创建一个新的Node节点插入进这个桶就可以了,也就是快速判断
44 */
45 tab[i] = newNode(hash, key, value, null);
46 else {
47 /*
48 否则如果这个桶上有数据的话,就执行下面的逻辑
49
50 e是用来判断新插入的这个节点是否能插入进去,如果不为null就意味着找到了这个新节点要插入的位置
51 */
52 Node<K, V> e;
53 K k;
54 if (p.hash == hash &&
55 ((k = p.key) == key || (key != null && key.equals(k))))
56 /*
57 如果桶上第一个节点的hash值和要插入的hash值相同,并且key也是相同的话,
58 就记录一下这个位置e,后续会做值的覆盖(快速判断模式)
59 */
60 e = p;
61 //走到这里说明要插入的节点和当前桶中的第一个节点不是同一个节点,但是他们计算出来的hash值是一样的
62 else if (p instanceof TreeNode)
63 //如果节点是红黑树的话,就执行红黑树的插入节点逻辑(红黑树的分析本文不做展开)
64 e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
65 else {
66 //走到这里说明链表上有多个节点,遍历链表上的节点(第一个节点不需要判断了,因为在第54行代码处已经判断过了)
67 for (int binCount = 0; ; ++binCount) {
68 if ((e = p.next) == null) {
69 /*
70 如果当前链表的下一个位置为null,意味着已经循环到最后一个节点还没有找到一样的,
71 此时将要插入的新节点插到最后
72 */
73 p.next = newNode(hash, key, value, null);
74 //如果循环到此时,链表的数量已经达到了转成红黑树的阈值的时候,就进行转换
75 if (binCount >= TREEIFY_THRESHOLD - 1)
76 /*
77 之前分析过,是否真正会转成红黑树,需要看当前数组的桶的个数
78 是否大于等于MIN_TREEIFY_CAPACITY,小于就只是扩容
79 */
80 treeifyBin(tab, hash);
81 break;
82 }
83 if (e.hash == hash &&
84 ((k = e.key) == key || (key != null && key.equals(k))))
85 //如果这个节点之前就在链表中存在,就可以退出循环了(e在第68行代码处已经被赋值了)
86 break;
87 p = e;
88 }
89 }
90 if (e != null) {
91 /*
92 如果找到了要插入的位置的话,就做值的覆盖
93
94 记录旧值,并最终返回出去
95 */
96 V oldValue = e.value;
97 //如果onlyIfAbsent为false,或者本身旧值就为null,就新值覆盖旧值
98 if (!onlyIfAbsent || oldValue == null)
99 e.value = value;
100 //钩子方法,空实现
101 afterNodeAccess(e);
102 return oldValue;
103 }
104 }
105 /*
106 走到这里说明之前是走到了第45行代码处,添加了一个新的节点。
107
108 修改次数+1,modCount是用来做快速失败的。如果迭代器中做修改,modCount != expectedModCount,
109 表明此时HashMap被其他线程修改了,会抛出ConcurrentModificationException异常(我在分析ArrayList
110 的源码文章中详细解释了这一过程,在HashMap中也是类似的)
111 */
112 ++modCount;
113 /*
114 既然是添加了一个新的节点,那么就需要判断一下此时是否需要扩容
115 如果当前数组容量已经超过了设定好的threshold阈值的时候,就执行扩容操作
116 */
117 if (++size > threshold)
118 resize();
119 //钩子方法,空实现
120 afterNodeInsertion(evict);
121 return null;
122}
4 resize方法
在上面putVal方法中的第39行和118行代码处,都是调用了resize方法来进行初始化或扩容的。而resize方法也是HashMap源码中比较精髓、比较有亮点的一个方法。其具体实现大致可以分为两部分:设置扩容标志位和具体的数据迁移过程。下面就首先来看一下resize方法的前半部分源码:
1/**
2 * HashMap:
3 * 扩容操作(当前数组为空的话就变成了对数组初始化的操作)
4 */
5final Node<K, V>[] resize() {
6 Node<K, V>[] oldTab = table;
7 //记录旧数组(当前数组)的容量,如果为null就是0
8 int oldCap = (oldTab == null) ? 0 : oldTab.length;
9 /*
10 1.在调用有参构造器的时候threshold存放的是大于等于当前数组容量的最小2次幂,将其赋值给oldThr
11 2.调用无参构造器的时候threshold=0
12 3.之前数组已经不为空,现在在做扩容的时候,threshold存放的是旧数组容量 * 负载因子
13 */
14 int oldThr = threshold;
15 //newCap指的是数组扩容后的数量,newThr指的是newCap * 负载因子后的结果(如果计算出来有小数就取整数部分)
16 int newCap, newThr = 0;
17 //下面就是对各种情况进行分析,然后将newCap和newThr标记位进行赋值的过程
18 if (oldCap > 0) {
19 if (oldCap >= MAXIMUM_CAPACITY) {
20 /*
21 如果当前数组容量已经超过了设定的最大值,就将threshold设置为int的最大值,然后返回当前数组容量
22 也就意味着在这种情况下不进行扩容操作
23 */
24 threshold = Integer.MAX_VALUE;
25 return oldTab;
26 } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
27 oldCap >= DEFAULT_INITIAL_CAPACITY)
28 /*
29 如果当前数组容量*2后没有超过设定的最大值,并且当前数组容量是大于等于初始容量16的话,
30 就将newCap设置为oldCap * 2,newThr设置为oldThr * 2
31 oldCap >= DEFAULT_INITIAL_CAPACITY这个条件出现的意义在后面会说明
32 */
33 newThr = oldThr << 1;
34 } else if (oldThr > 0)
35 /*
36 走到这里说明oldCap=0,也就是当前是初始化数组的时候。我们刚才看到如果是默认的无参构造器的话,
37 threshold是不会被赋值的,也就是为0。但是如果调用的是有参的构造器,threshold就会在构造器初始阶段被赋值了,
38 而这个if条件就是对应于这种情况。这里设置为oldThr是因为在上面的第14行代码处可以看到oldThr指向的是threshold,
39 也就是说oldThr的值是大于等于“当前数组容量”的最小2次幂(注意,“当前数组容量”我在这里是加上引号的,
40 也就是说并不是现在真正物理存在的数组容量(当前的物理容量是0),而是通过构造器传进来设定的容量),
41 肯定是个大于0的数。既然这个oldThr现在就代表着我想要设定的新容量,那么直接就将newCap也赋值成这个数就可以了
42 */
43 newCap = oldThr;
44 else {
45 /*
46 如上所说,这里对应的是调用无参构造器,threshold=0的时候
47 将newCap赋值为16,newThr赋值为16 * 0.75 = 12,都是取默认的值
48 */
49 newCap = DEFAULT_INITIAL_CAPACITY;
50 newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
51 }
52 if (newThr == 0) {
53 /*
54 有两种情况程序能走到这里:
55 第一种:在第43行代码处的if条件中没有对newThr进行赋值,此时计算出ft = 新数组容量 * 负载因子,
56 如果数组容量和ft都没有超过设定的最大值的话,就将newThr赋值为ft,否则赋值给int的最大值
57
58 第二种:注意到上面第27行代码处的条件,如果oldCap比16要小的话,newThr也是没有赋值的。
59 出现这种情况的根源不在于这一次resize方法的调用,而是在于上一次初始化时候的调用。举个例子就明白了:
60 一开始我是调用new HashMap<>(2)这个构造器,经过计算后threshold=2。接着调用put方法触发初始化会跳进该方法里
61 此时oldCap=0,oldThr=2。接着会走进第34行代码处的if条件中,newCap=2,然后会走进第52行代码处,
62 也就是本if条件中:newThr=1,然后修改threshold=1。之后resize方法就会走具体的扩容操作了
63 但是之前这些设置的标志位都不会被更改,扩容后就退出该方法了。这是第一次调用过程。
64 然后我此时成功插入了这个节点后,又再次调用了put方法。此时还是会把该节点插入成功进去,
65 但是在上面putVal方法中的第117行代码处判断发现,我当前的size=2已经大于了threshold=1。于是又会调用resize该方法来进行扩容
66 而此时oldCap=2,oldThr=1。会走到第26行代码处的if条件中,newCap=4,而此时的oldCap=2要小于16,
67 于是就跳出了该if条件,然后会走进第52行代码处,也就是本if条件中:newThr=3,然后修改threshold=3
68 这是正确的情况,因为newThr本身就是newCap * 负载因子后的结果,即 4 * 0.75 = 3
69 那么假如说源码里没有第27行代码处的判断条件的话,就会跳进到第33行代码处,此时的oldThr=1,所以newThr=2
70 可以看到此时newCap=4而newThr=2,发生了错误,4 * 0.75不等于2。所以说在第27行代码处的
71 oldCap >= DEFAULT_INITIAL_CAPACITY这个条件的出现,将原本在第33行代码处进行更新newThr的操作
72 改为了在第97行代码处,以解决newThr更新不准确的问题
73
74 当然这里只是演示了可能出错的一种情况,并没有说到本质。其实我通过对比其他的一些数据来演示这个结果后发现:
75 如果桶的个数超过了16也会存在这种差异点。其实上述的出错可以一般化:一个是原容量 * 负载因子后取整,然后*2,
76 另一个是原容量 * 2 * 负载因子后再取整。差异点就在于取整的时机。而出现差别也就是
77 原容量 * 负载因子后是一个带小数的数(如果为整数是不会有差别的,而且也并不是所有带小数的数都会有差异),
78 这个带小数的数取整后再*2,差异点被放大了,从而导致最终的不同。还有一处线索是第27行代码处的
79 oldCap >= DEFAULT_INITIAL_CAPACITY,注意这里是大于等于,而不是小于等于,也就是说
80 只有大于等于16的话才会走进这个if条件(快速计算threshold结果),小于16的话会走进本if条件
81 (精确计算threshold结果)。所以说如果桶的个数大于16,阈值多一个少一个的话可能就没那么重要了,
82 比如说1024个桶,我是在819个桶满了的时候去扩容还是在818个,似乎差别也不太大,在这种情况下
83 就因为我把阈值threshold多减去了1个,从而会导致哈希冲突变高?还是空间更浪费了?其实不见得
84 毕竟数据量在这里摆着,而且负载因子一般都是小于1的数,所以这个差别最多也就是1个。这个差异点也会随着
85 数据的越来越大而显得越来越不重要。但是如果像前面举的例子,4个桶我是在2个桶满了还是3个桶满的时候去扩容,
86 这个差别就很大了,这两种情况下hash冲突发生概率的对比肯定是比较大的。可能一个是20%,另一个是40%,
87 而桶的个数比较大的时候这个差异对比可能就是1.2%和1.3%(这个数是我随便举的)。这样的话在数据量大
88 而且扩容方法频繁调用的时候(比如我要存进一个特别大的容量但是没有指定初始容量),我牺牲了计算阈值的准确性
89 (如果负载因子设置合理,这个差异就只有1个的区别),但换来了执行速度的高效(注意在第33行代码处是左移操作,
90 而在第96行代码处是乘法,乘法后又接着一个三目运算符,然后又取整);但是数据量小的时候,明显是计算准确更重要,
91 而且数据量小的情况下也谈不上什么性能差异,毕竟这里设定的阈值是16。所以在上面第14行代码处的注释中,
92 threshold有第四种取值:旧数组容量 * 负载因子 - 1(具体减去几要看负载因子设置的值以及数组容量),
93 但是这种完全可以算作是第三种的特殊情况。所以总结来说:第27行代码处添加的意义就是为了在桶数量比较大、
94 扩容方法频繁调用的时候,稍微牺牲一些准确性,但是能让threshold阈值计算得更快一些,是一种优化手段
95 */
96 float ft = (float) newCap * loadFactor;
97 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?
98 (int) ft : Integer.MAX_VALUE);
99 }
100 //做完上述操作后,将threshold的值也更新一下
101 threshold = newThr;
102
103 //...
104}
上面在把newCap、newThr和threshold标记位都设置好了后,下面就是具体的数据迁移的过程,也就是resize方法后半部分的实现:
1/**
2 * HashMap:
3 */
4final Node<K, V>[] resize() {
5 //...
6
7 //此时newCap和newThr标记位都已经设置好了,将根据newCap新的容量来创建一个新的Node数组,以此来替代旧数组
8 @SuppressWarnings({"rawtypes", "unchecked"})
9 Node<K, V>[] newTab = (Node<K, V>[]) new Node[newCap];
10 table = newTab;
11 //如果旧数组为null,也就是说现在是对数组做初始化的操作。那么直接就返回创建的新数组newTab就行了
12 if (oldTab != null) {
13 //遍历旧数组上的每一个桶
14 for (int j = 0; j < oldCap; ++j) {
15 Node<K, V> e;
16 //如果旧数组的这个桶上没有数据的话,就跳过它,不进行扩容
17 if ((e = oldTab[j]) != null) {
18 //旧数组上的这个节点赋值为null,便于快速GC
19 oldTab[j] = null;
20 if (e.next == null)
21 /*
22 第一个节点后面没有后续节点,也就意味着这个桶上只有一个节点,
23 那么只需要通过计算找出新位置放进去就行了,这里也就是在做快速迁移
24 */
25 newTab[e.hash & (newCap - 1)] = e;
26 else if (e instanceof TreeNode)
27 //如果是红黑树,就执行红黑树的迁移逻辑(红黑树的分析本文不做展开)
28 ((TreeNode<K, V>) e).split(this, newTab, j, oldCap);
29 else {
30 /*
31 走到这里说明当前这个桶里面有不止一个的节点,此时就会做链表上多个节点的迁移工作
32 首先来说一下大前提:现在旧数组上桶的位置是j,而准备放进新数组的桶位置有两个:一个是j,
33 也就是说新数组上也会放在j这个位置上;另一个是j+旧数组的容量。比方说当前桶的位置15,
34 而旧数组的容量是16,那么新数组上第二个将要插入的桶的位置就是15 + 16 = 31
35
36 说完了大前提,再来看下面的代码。以下定义了四个指针位置,
37 分别就对应了上面说的两个新插入桶位置的头尾指针
38 */
39 Node<K, V> loHead = null, loTail = null;
40 Node<K, V> hiHead = null, hiTail = null;
41 Node<K, V> next;
42 do {
43 //next指向当前节点的下一个节点
44 next = e.next;
45 /*
46 那么现在的问题就是通过什么办法来判断到底是插入到j位置还是j+旧数组容量的位置呢?
47 其实也很简单,就是通过节点的哈希值和旧数组的容量按位与的方式来判断的。旧数组容量
48 经过上面的分析后可以知道,肯定是一个2的幂,也就是1000...000,最高位为1,而剩余位都是0的形式
49 这样按位与的结果就是取出了节点hash上的那个与旧数组所对应的1的那个位置上的数。
50 比如说节点的hash值是1010110,旧数组容量是16(1000),那么按位与的结果就是
51 取出了hash值中从右往左第四位的值,即0。也就是说,存在新数组哪个位置上,取决于hash值
52 所对应旧数组容量为1的那个位置上到底是0还是1。从这里也可以看出,除了
53 (table.length - 1) & hash这种方式用来判断插入桶的位置,是必须要求数组容量是2的幂之外,
54 在扩容做迁移的时候,也必须要求了这点
55
56 按位与的结果只有两种,不是0就是1,所以如果为0的话最后就会插入到新数组的j位置,
57 为1就插入到j+旧数组容量的位置(后面会解释如果换一下的话,到底行不行)
58 */
59 if ((e.hash & oldCap) == 0) {
60 if (loTail == null)
61 //如果当前是第一个插进来的节点,就将loHead头指针指向它
62 loHead = e;
63 else
64 /*
65 不是第一个的话,就将loTail尾指针的下一个next指针指向它,也就是把链拉上
66 loTail在之前已经指向了最后一个节点处
67 */
68 loTail.next = e;
69 //更新一下loTail尾指针,重新指向此时的最后一个节点处
70 loTail = e;
71 } else {
72 //(e.hash & oldCap) == 1
73 if (hiTail == null)
74 //如果当前是第一个插进来的节点,就将hiHead头指针指向它
75 hiHead = e;
76 else
77 /*
78 不是第一个的话,就将hiTail尾指针的下一个next指针指向它,也就是把链拉上
79 hiTail在之前已经指向了最后一个节点处
80 */
81 hiTail.next = e;
82 //更新一下hiTail尾指针,重新指向此时的最后一个节点处
83 hiTail = e;
84 }
85 //如果当前遍历链表上的节点还没有到达最后一个节点处,就继续循环去判断
86 } while ((e = next) != null);
87 /*
88 走到这里说明已经将原来的旧数组上的链表拆分完毕了,现在分成了两个链表,low和high
89 接下来需要做的工作就很清楚了:将这两个链表分别插入到j位置和j+旧数组容量的位置就可以了
90 */
91 if (loTail != null) {
92 /*
93 如果low链表有节点的话(没节点说明之前的按位与的计算结果都是1),就重新更新一下low链表上
94 最后一个节点的next指针指向null。这步操作很重要,因为如果之前这个节点不是
95 旧数组桶上的最后一个节点的话,next是有值的。不改成null的话指针指向就乱了
96 */
97 loTail.next = null;
98 //将链表插入到j位置
99 newTab[j] = loHead;
100 }
101 if (hiTail != null) {
102 /*
103 如果high链表有节点的话(没节点说明之前的按位与的计算结果都是0),就重新更新一下high链表上
104 最后一个节点的next指针指向null。这步操作很重要,因为如果之前这个节点不是
105 旧数组桶上的最后一个节点的话,next是有值的。不改成null的话指针指向就乱了
106 */
107 hiTail.next = null;
108 //将链表插入到j+旧数组容量的位置
109 newTab[j + oldCap] = hiHead;
110 }
111 }
112 }
113 }
114 }
115 return newTab;
116}
在Java 7的HashMap源码中,transfer方法是用来做扩容时的迁移数据操作的。其实现就是通过遍历链表中的每一个节点,重新rehash实现的。在这其中会涉及到指针的修改,在高并发的场景下,可能会使链表上的一个节点的下一个指针指向了其前一个节点,也就是形成了死循环,死链(具体形成过程不再展开):
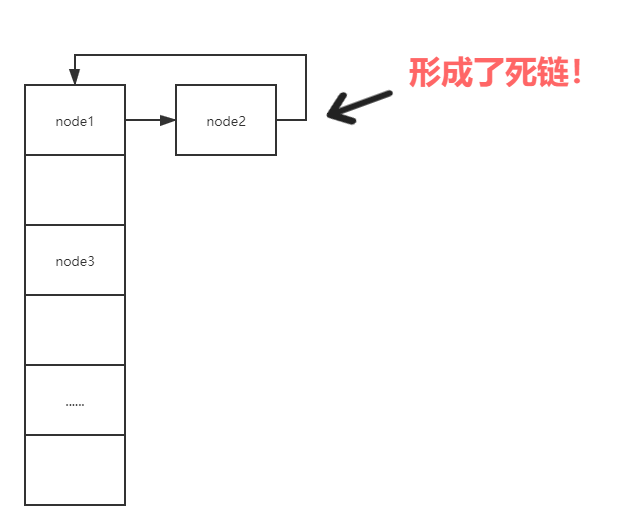
这样再去遍历链表的时候就永远不会停下来,出现了bug。而Java 8中通过形成两个链表,节点hash值在数组容量二进制数为1的那个位置处去按位与判断是0还是1,以此来选择插入的方式很好地解决了这个问题,而且不用每一个节点rehash,提高了执行速度。
既然说到了不用rehash,那么这里想要探究一下在数组扩容时,选择新插入数组的位置是原位置和原位置+旧数组容量,为什么这里加上的是旧数组容量呢?加别的值不可以吗?其实这里加旧数组容量是有原因的。我们都知道,数组容量必须是2的幂,即100…000,而新数组的容量是原数组的2倍,也就是把原来值中的“1”往左移了一位,而我们在判断插入桶位置时用的方式是(数组容量 - 1)& hash值。把这些信息都整合一下,我们就知道在新数组中计算桶位置和在旧数组中计算桶位置的差异,其实就在于旧数组二进制为1上的这位上。如果该位是0,那就是和原来旧数组是同一个位置,如果是1,就是旧数组位置处+旧数组的容量。下面举个例子:
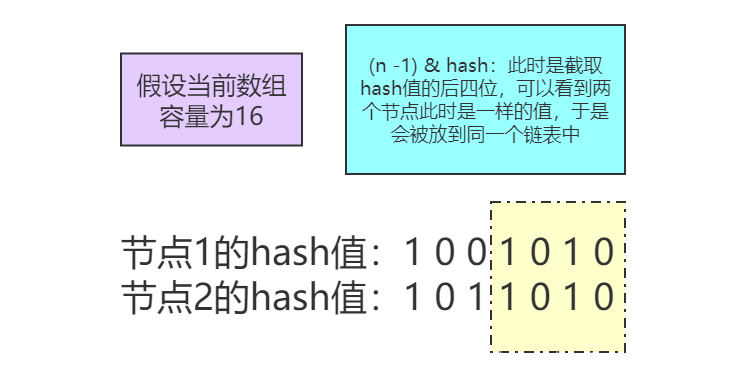
两个节点此时计算出来桶的位置都是1010,即第10个桶。它们都会被放在第10个桶中的链表中。
而现在数组扩容了,数组容量变为了32,我们再来看看结果会怎样:

这时候发现(n - 1) & hash的结果不一样了,节点1是01010,节点2是11010。也就是说,我们在get方法执行的时候(get方法也是通过(n - 1) & hash的方式来找到桶的位置),找到节点1是在第10个桶,节点2是在第26个桶,这两个节点之间相差16个桶,这不就是旧数组的容量吗?现在是不是恍然大悟了,我们当初在扩容时,将节点的hash值和旧数组容量进行按位与,其实也就是在找上图红框框中的那个位置。如果为0,就将节点1放在新数组中第10个桶中(1010),也就是原位置处;如果为1,就将节点2放在新数组中第26个桶中(1010+10000),也就是原位置+旧数组容量处。这样做的话,我在get方法执行的时候也能保证正确执行,能正确找到节点在新数组中桶的位置。同时也说明了,这个放入的策略是不能换的。也就是说,不能是如果为1的话最后就会插入到新数组的原位置,为0就插入到原位置+旧数组容量的位置。如果这么做的话,最后get方法在查找该节点的时候,就找不到了(而实际上还存在)。所以通过Java 8中的这种扩容方式,既能计算出正确的新桶位置,又能避免每一个节点的rehash,节省计算时间,实在是妙哉。
5 get方法
1/**
2 * HashMap:
3 */
4public V get(Object key) {
5 Node<K, V> e;
6 //如果获取不到值,或者本身插入的value就是null的话,就返回null,否则返回具体的value
7 return (e = getNode(hash(key), key)) == null ? null : e.value;
8}
9
10final Node<K, V> getNode(int hash, Object key) {
11 Node<K, V>[] tab;
12 Node<K, V> first, e;
13 int n;
14 K k;
15 //如果数组没有初始化,或者计算出来的桶的位置为null(说明找不到这个key),就直接返回null
16 if ((tab = table) != null && (n = tab.length) > 0 &&
17 (first = tab[(n - 1) & hash]) != null) {
18 if (first.hash == hash &&
19 ((k = first.key) == key || (key != null && key.equals(k))))
20 /*
21 如果桶上第一个节点的hash值和要查找的hash值相同,并且key也是相同的话,
22 就直接返回(快速判断模式)
23 */
24 return first;
25 /*
26 如果下一个节点为null,也就是当前桶上只有一个节点的时候,
27 并且之前那个节点不是的话,那就直接返回null,也就是找不到
28 */
29 if ((e = first.next) != null) {
30 if (first instanceof TreeNode)
31 //如果节点是红黑树的话,就执行红黑树的查找节点逻辑(红黑树的分析本文不做展开)
32 return ((TreeNode<K, V>) first).getTreeNode(hash, key);
33 /*
34 走到这里说明链表上有多个节点,遍历链表上的每一个节点进行查找(第一个节点不需要判断了,
35 因为在第18行代码处已经判断过了)
36 */
37 do {
38 if (e.hash == hash &&
39 ((k = e.key) == key || (key != null && key.equals(k))))
40 return e;
41 } while ((e = e.next) != null);
42 }
43 }
44 return null;
45}
6 remove方法
1/**
2 * HashMap:
3 */
4public V remove(Object key) {
5 Node<K, V> e;
6 //如果找不到要删除的节点,就返回null,否则返回删除的节点
7 return (e = removeNode(hash(key), key, null, false, true)) == null ?
8 null : e.value;
9}
10
11final Node<K, V> removeNode(int hash, Object key, Object value,
12 boolean matchValue, boolean movable) {
13 Node<K, V>[] tab;
14 Node<K, V> p;
15 int n, index;
16 //如果数组没有初始化,或者计算出来的桶的位置为null(说明找不到这个key),就直接返回null
17 if ((tab = table) != null && (n = tab.length) > 0 &&
18 (p = tab[index = (n - 1) & hash]) != null) {
19 Node<K, V> node = null, e;
20 K k;
21 V v;
22 if (p.hash == hash &&
23 ((k = p.key) == key || (key != null && key.equals(k))))
24 //如果桶上第一个节点的hash值和要查找的hash值相同,并且key也是相同的话,就记录一下该位置
25 node = p;
26 else if ((e = p.next) != null) {
27 //e是桶上第一个节点的下一个节点,如果没有的话,也说明找不到要删除的节点,就返回null
28 if (p instanceof TreeNode)
29 //如果节点是红黑树的话,就执行红黑树的查找节点逻辑(红黑树的分析本文不做展开)
30 node = ((TreeNode<K, V>) p).getTreeNode(hash, key);
31 else {
32 /*
33 走到这里说明链表上有多个节点,遍历链表上的每一个节点进行查找,找到了就记录一下该位置
34 (第一个节点不需要判断了,因为在第22行代码处已经判断过了)
35 */
36 do {
37 if (e.hash == hash &&
38 ((k = e.key) == key ||
39 (key != null && key.equals(k)))) {
40 node = e;
41 break;
42 }
43 //此时p记录的是当前节点的上一个节点
44 p = e;
45 } while ((e = e.next) != null);
46 }
47 }
48 /*
49 如果找到了要删除的节点,并且如果matchValue为true(matchValue为true代表仅在value相等的情况下才能删除)
50 并且value相等的时候(如果matchValue为false,就只需要判断第一个条件node是否不为null)
51 当然,如果不相等的话,就直接返回null,也就是不会删除
52 */
53 if (node != null && (!matchValue || (v = node.value) == value ||
54 (value != null && value.equals(v)))) {
55 if (node instanceof TreeNode)
56 //如果节点是红黑树的话,就执行红黑树的删除节点逻辑(红黑树的分析本文不做展开)
57 ((TreeNode<K, V>) node).removeTreeNode(this, tab, movable);
58 else if (node == p)
59 /*
60 如果要删除的节点是桶上的第一个节点,就直接将当前桶的第一个位置处赋值为下一个节点
61 (如果next为null就是赋值为null)
62 */
63 tab[index] = node.next;
64 else
65 //不是桶上第一个节点就将前一个节点的next指向下一个节点,也就是将node节点从链表中剔除掉,等待GC
66 p.next = node.next;
67 //修改次数+1(快速失败机制)
68 ++modCount;
69 //因为是要删除节点,所以如果找到了的话,size就-1
70 --size;
71 //钩子方法,空实现
72 afterNodeRemoval(node);
73 return node;
74 }
75 }
76 return null;
77}
7 clear方法
1/**
2 * HashMap:
3 */
4public void clear() {
5 Node<K, V>[] tab;
6 //修改次数+1(快速失败机制)
7 modCount++;
8 if ((tab = table) != null && size > 0) {
9 //size记录的是当前有数据的桶的个数,因为这里要清空数据,所以将size重置为0
10 size = 0;
11 //同时将table中的每个桶都置为null就行了
12 for (int i = 0; i < tab.length; ++i)
13 tab[i] = null;
14 }
15}
原创文章,未经允许,请勿转载,更多干货请传送至奇客时间

聊聊经典数据结构HashMap,逐行分析每一个关键点的更多相关文章
- 关于Java的数据结构HashMap,ArrayList的使用总结及使用场景和原理分析
使用,必须要知道其原理,在课堂上学过散列函数的用法及其原理.但一直不知道怎么实践. 后来,在实际项目中,需要做一个流量分析预处理程序.每5分钟会接收到现网抓来的数据包并解析,每个文本文件大概200M左 ...
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- HashMap的分析(转)
一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了不同步和允许使用 null 之外,HashMap ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- 并发编程——ConcurrentHashMap#transfer() 扩容逐行分析
前言 ConcurrentHashMap 是并发中的重中之重,也是最常用的数据结果,之前的文章中,我们介绍了 putVal 方法.并发编程之 ConcurrentHashMap(JDK 1.8) pu ...
- JAVA中hashmap的分析
从http://blog.csdn.net/luanlouis/article/details/41576373?utm_source=tuicool&utm_medium=referral学 ...
- Java数据结构HashMap
java数据结构HashMap /** * <html> * <body> * <P> Copyright JasonInternational</p> ...
- Java中的数据结构-HashMap
Java数据结构-HashMap 目录 Java数据结构-HashMap 1. HashMap 1.1 HashMap介绍 1.1.1 HashMap介绍 1.1.2 HashMap继承图 1.2 H ...
- Linux运维之道(大量经典案例、问题分析,运维案头书,红帽推荐)
Linux运维之道(大量经典案例.问题分析,运维案头书,红帽推荐) 丁明一 编 ISBN 978-7-121-21877-4 2014年1月出版 定价:69.00元 448页 16开 编辑推荐 1 ...
随机推荐
- mxnet笔记
参考链接: https://mxnet.apache.org/api/faq/distributed_training https://mxnet.apache.org/api/faq/gradien ...
- css基本样式设置
div中文字居中 如何让一个div中的文字水平和垂直居中?设置如下: 给定该div的长宽(或者二者只给出其一也可) .box{ height: 100px; width: 30%; text-alig ...
- Navicat Premium 12免费版安装
前言 这几年的工作过程中使用了很多的数据库工具,比如Sqlyog,DBeaver,sqlplus等工具,但是个人觉得很好用的还是Navicat. 不如人意的就是目前Navicat都在收费,今天就来分享 ...
- iOS 报错: linker command failed with exit code 1 (use -v to see invocation) 原因
在iOS开发中,很多人会遇到这样的报错 linker command failed with exit code 1 (use -v to see invocation) 可能的原因如下: 1.引用出 ...
- 精选PDF版本书籍第一期
福利概述 精选JAVA必读书籍的PDF版本(来源于网络,侵删). Effective java 中文版(第2版) Head First 设计模式(中文版) Java并发编程的艺术 Java技术手册(第 ...
- 14_Web服务器-并发服务器
1.服务器概述 1.硬件服务器(IBM,HP): 主机 集群 2.软件服务器(HTTPserver Django flask): 网络服务器,在后端提供网络功能逻辑处理数据处理的程序或者架构等 3.服 ...
- 安装与激活PhpStrom
1.下载安装PHPstorm(https://pan.baidu.com/s/1nwK3ew5 密码dhtr) 2.运行 3.下一步选择中间,在http://idea.lanyus.com/ 上获取激 ...
- Solon详解(二)- Solon的核心
Solon详解系列文章: Solon详解(一)- 快速入门 Solon详解(二)- Solon的核心 Solon详解(三)- Solon的web开发 Solon详解(四)- Solon的事务传播机制 ...
- 使用Json-lib将对象和Json互转
工程下载地址: https://files.cnblogs.com/files/xiandedanteng/jsonSample20200308.rar Depenency: <!-- 使用js ...
- git github仓库
起因 centos 下 git到 github仓 经过 下载git yum install git -y 配置git git config --global user.name "Your ...