Git、Github、Gitkraken 学习笔记
《Git、Github、Gitkraken 学习笔记》
一、写在前面
1、参考资料
本文参考 《Pro Git》 一书。
在官网有免费在线版可供阅读:https://git-scm.com/book/en/v2
未看章节:
- 服务器上的 Git
- Git 内部原理 - 引用规范
2、符号备注
- 本文出现
【重点】处,表示为知识的重点,可以着重看待。
二、起步
1、版本控制
(1)什么是版本控制
版本控制(Revision control)是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
功能:
- 记录
- 回退
- 比较
- ……
(2)版本控制系统(VCS)的发展
① 手动备份
② 本地版本控制系统
其中最流行的一种叫做修订控制系统(Revision Control System,简称 RCS)。工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
③ 集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)
特点:客户端只需取出最新的文件进行工作。
产品:CVS、Subversion(SVN)、SVN 以及 Perforce 等
好处:
- 可以协同工作
- 支持权限管理
- 好管理。管理一个 CVCS 要远比在各个客户端上维护本地 VCS 来得轻松容易
缺点:
- 单点故障整个系统就瘫痪了
- 必须联上 CVCS 的那台中央服务器才能提交
④ 分布式版本控制系统(Distributed Version Control System,简称 DVCS)
特点:客户端需要把代码仓库完整地镜像下来,包括完整的历史记录,然后进行工作。
这就是分布式的特点。
产品:Git、Mercurial、Bazaar 以及 Darcs 等
好处:
- 既有集中化的版本控制系统的优点,也可避免其缺点
所以能上 git 就别用 svn 那种了。
- 实现更复杂的工作流
- 对文件和提交的完整性保证的更好。(例如 Git 提交的内容或者元信息只要修改了,commit-id 就会变)
- 因为操作几乎都在本地执行,所以速度很快,性能更高
即使是跟远程仓库的交互(例如 fetch / push),git 也比 SVN 要快。仅在 clone 时,因为 git 正在下载整个历史记录,而不仅仅是最新版本(这也是分布式的必要),所以比 SVN 要慢。但基本上操作 Git 比SVN 快一两个数量级。
- 在 Git 中任何已提交的东西几乎都是可以恢复的。
坏处:
- 略
还是有的,不存在没有缺点的技术,但本人不敢班门弄斧,具体可以参考网上别人的总结。
(3)Git 与其他版本控制系统的三大区别
① 分布式
参考上面 分布式版本控制系统 的叙述。
② 快照流【重点】
这是 Git 和其它版本控制系统(包括 SVN 和近似工具)的最主要差别,即在于 对待数据的方法。
1、其它版本系统
- (1)存每个版本完整的文件(存在重复)
- (2)
基于差异(delta-based)的版本控制,以文件变更列表的方式存储信息。
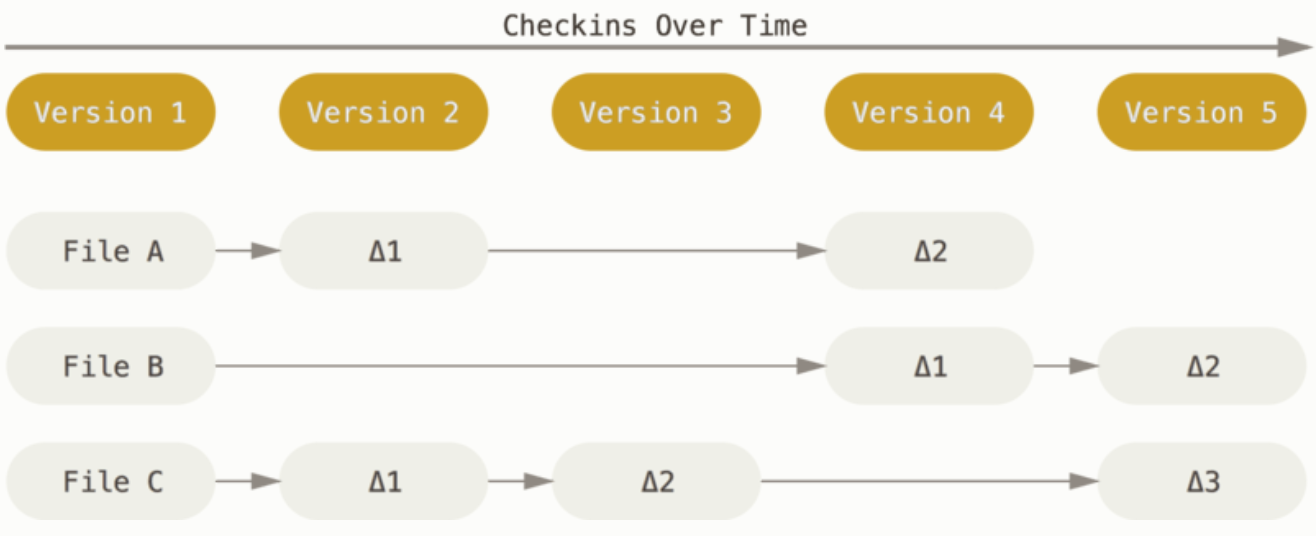
2、Git
- (1)对当时的全部文件创建一个快照并保存这个快照的索引(基于SHA-1)。 为了效率,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。
具体原理涉及 git 对象(三大对象),下面会有详细介绍。
- (2)基于
快照流。
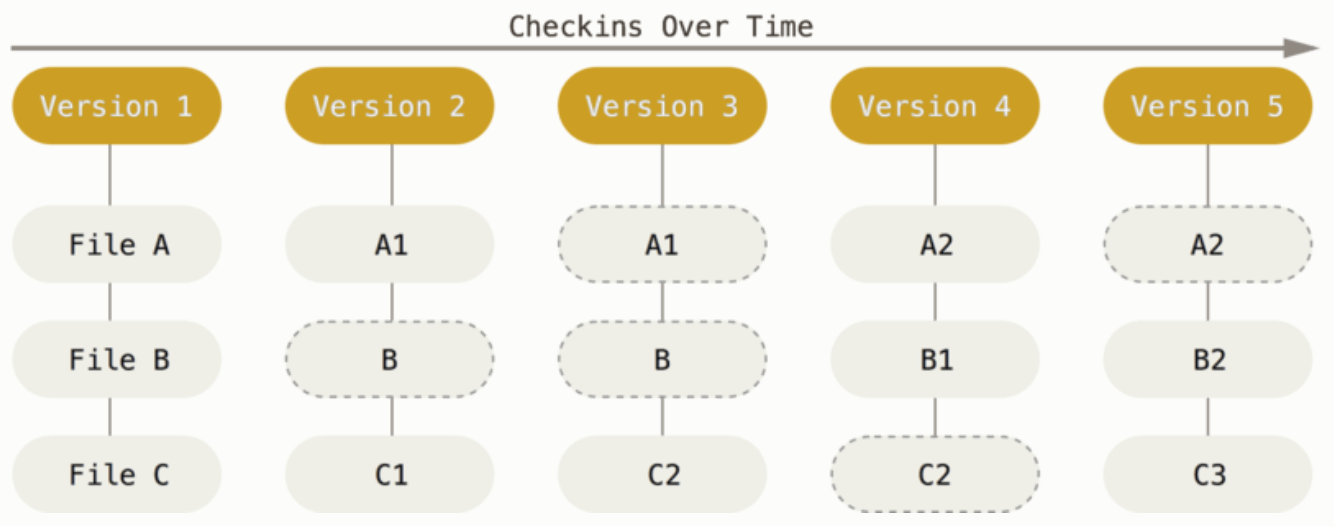
好处:
- 让 git 的仓库体量更小,性能更好。
③ 开源
可免费使用。
2、SCM - 软件配置管理
(1)什么是软件配置管理
如果你留心的话,可以发现 git 的官网地址不是 git.com 而是 git-scm.com,这个 scm 是什么意思呢?
软件配置管理(Software Configuration Management,简称:SCM),又称软件形态管理、或软件建构管理,简称软件形管。界定软件的组成项目,对每个项目变更进行管控(版本控制),并维护不同项目之间的版本关系,以使软件在开发过程中任一时间的内容都可以被追溯,包括某几个具有重要意义的数个组合,例如某一次交付给客户的软件内容。
摘自维基百科。
(2)软件配置管理(SCM)跟版本控制系统(VCS)有啥区别?
- SCM 包括了 VSC。软件配置管理是一个广义的术语,涵盖了构建,打包和部署软件所需的所有过程。
- VSC 只是软件,而 SCM 不是。
3、Git 诞生历史
Linux 内核开源项目有着为数众多的参与者。绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991-2002年间)。到 2002 年,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux 内核社区免费使用 BitKeeper 的权力。 这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统,即 Git。
据说 Linus 只花了两周时间自己用C写出了 git。
4、安装
以 CentOS 为例:
yum install git
写本文时,最新版本为
v2.27.0。
5、帮助
(1)命令行
可以随时运行 git help <command> 命令来了解。
(2)官方文档
6、配置
(1)配置文件
按优先级从低到高排列(级别高的会覆盖级别低的):
- 1、
/etc/gitconfig文件: 所有 OS 用户 + 所有仓库
git config --system
由于它是系统配置文件,因此你需要管理员或超级用户权限来修改它。
- 2、
~/.gitconfig或~/.config/git/config文件:当前 OS 用户 + 所有仓库
git config --global
- 3、当前仓库 Git 目录中的 config 文件(即
.git/config):当前 OS 用户 + 当前仓库
git config --local or git config(缺省)
(2)查看配置
# 查看所有原始配置(以及他们所在的配置文件)
git config --list --show-origin
# 查看所有配置(会存在优先级不同而覆盖的情况,下同)
git config --list
# 查看具体某个配置
git config <key>
(3)常用配置
① 用户信息(建议设置全局)
第一件事就是设置你的用户名和邮件地址。
$ git config --global user.name "xjnotxj"
$ git config --global user.email xjnotxj@example.com
② 文本编辑器
git config --global core.editor vim
这个值刚安装 git 的是空,Git 会调用你通过环境变量 $VISUAL 或 $EDITOR 设置的文本编辑器, 如果没有设置,默认则会调用 vi 来创建和编辑你的提交以及标签信息。
更多的编辑器如何设置,见:https://git-scm.com/book/zh/v2/附录-C%3A-Git-命令-设置与配置
(4)你需要知道的配置(但不用改)
① 处理不同 OS 的换行规则
注意:换行处理只针对文本文件,而非二进制文件。
通过 core.autocrlf 配置。
关于不同 OS 的换行规则 ,参考我的旧文:《关于“编码”的方方面面》
② 修复空白
通过 core.whitespace 配置来探测和修正多余空白字符问题。
默认被打开的三个选项是:
- blank-at-eol,查找行尾的空格
- blank-at-eof,盯住文件底部的空行
- space-before-tab,警惕行头 tab 前面的空格
7、在其它环境中使用 Git
(1)GUI
① 为什么要用 GUI?
只有在命令行模式下你才能执行 Git 的 所有 命令,而大多数的 GUI 软件只实现了 Git 所有功能的一个子集以降低操作难度。
② 用什么 GUI
1、内置 GUI
gitk - 在 git 仓库下执行 gitk 命令即可打开。
2、第三方 GUI
本文以 gitkraken 为例(下文如果提到 GUI,默认指的就是它)(参见下文还有会单独一章介绍 gitkraken)。
本人之前在 mac 上用的 tower,后来才换到了 gitkraken,感觉明显好用多了,推荐。
更多 第三方 GUI 列表,可见:https://git-scm.com/download/gui/mac
(2)IDE
① 支持哪些?
Visual Studio Code / Visual Studio / Eclipse / IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine 中的 Git
② Visual Studio Code
Visual Studio Code 的官方教程:https://code.visualstudio.com/Docs/editor/versioncontrol
③ 其它
略
(3)编辑器
Sublime Text
略
(4)命令行
① 环境变量
Git 总是在一个 shell 中运行,并借助一些 shell 环境变量来决定它的运行方式。
略。
② 在 Bash 中
1、效果:
2、如何实现
略。
③ 在 Zsh 中(我本人用的就是这个)
1、效果:
可使用 "oh-my-zsh" (推荐)

2、如何实现
略,详细可见:https://git-scm.com/book/zh/v2/附录-A%3A-在其它环境中使用-Git-Zsh-中的-Git
④ 在 PowerShell 中
略
8、在你的应用中嵌入 Git
(1)方法一
直接嵌入 shell,执行 git 命令。
略
(2)方法二
使用第三方库:
- for c
- for java
- for go
- ……
略
三、Git 基础知识
1、获取 Git 仓库
(1)方法一 - git init
git init 将尚未进行版本控制的本地目录转换为 Git 仓库。
该命令将创建一个名为
.git的子目录。
(2)方法二 - git clone
① 介绍
git clone 从其它远程地址克隆一个已存在的 Git 仓库。
② 协议
支持:
https://协议git://协议
适用场景:
- 对于 Github 来说,通常对于公开项目可以优先分享基于 HTTPS 的 URL,因为用户克隆项目不需要有一个 GitHub 帐号。
HTTPS URL 与你贴到浏览器里查看项目用的地址是一样的。
- 如果你分享 SSH URL,用户必须有一个帐号并且上传 SSH 密钥才能访问你的项目。
③ 操作
1、指定分支
# git clone 不指定分支 (默认为 master)
git clone http://10.1.1.11/service/tmall-service.git
# git clone 指定分支
git clone -b dev http://10.1.1.11/service/tmall-service.git
注:不管指不指定分支,git clone 都是整个仓库拉下来,只是拉下来后默认创建的跟踪分支不同。
跟踪分支的概念下面会说。
GitKraken clone 后会把所有远程分支都建立一个本地分支。
2、重命名
# clone 下来重命名项目
git clone https://github.com/libgit2/libgit2 mylibgit
④ 结果
把远程仓库整个给 clone 下来。
包含:
- 分支
- 标签
- log
不包含:
- 暂存区
- stash
- reflog
(3)[拓展] 协议 与 凭证存储
如果你使用的是 SSH 方式连接远端,并且设置了一个没有口令的密钥,这样就可以在不输入用户名和密码的情况下安全地传输数据。
然而,这对 HTTP 协议来说是不可能的 —— 每一个连接都是需要用户名和密码的。 这在使用双重认证的情况下会更麻烦,因为你需要输入一个随机生成并且毫无规律的 token 作为密码。
幸运的是,Git 拥有一个凭证系统来处理这个事情。
略。
(4)[拓展] 协议的底层
Git 可以通过两种主要的方式在版本库之间传输数据:“哑(dumb)”协议和“智能(smart)”协议。
知道常用的默认的是智能协议就好。
略。
2、基本操作
(1)常用操作
① 文件的四种状态
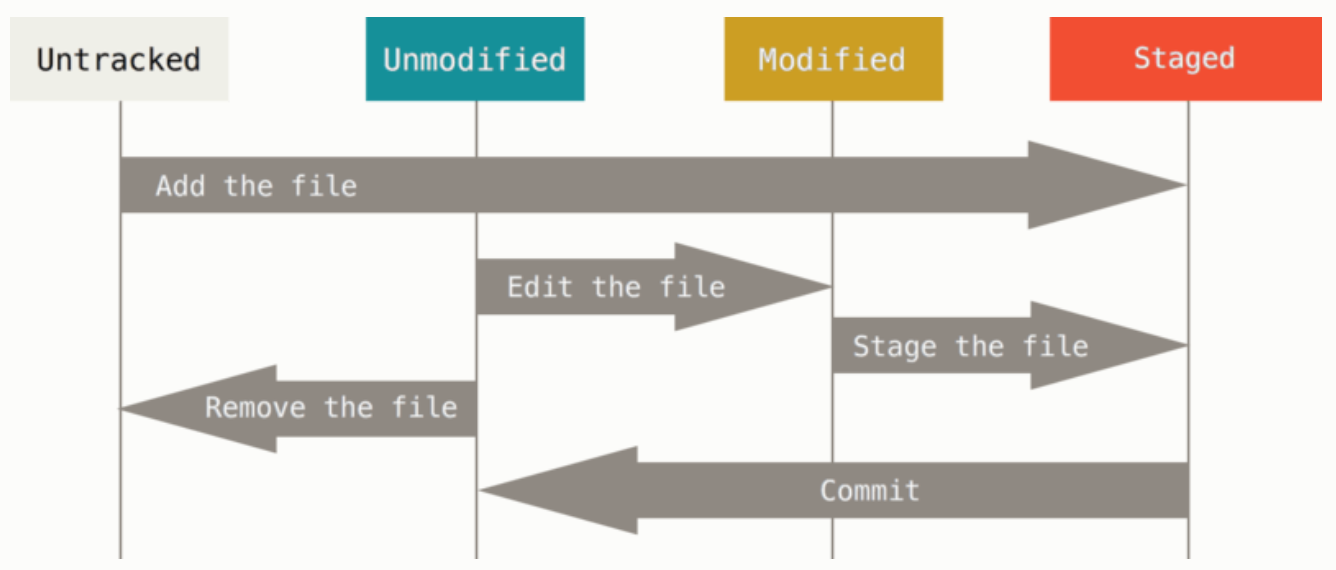
② 三类区域(三个阶段)
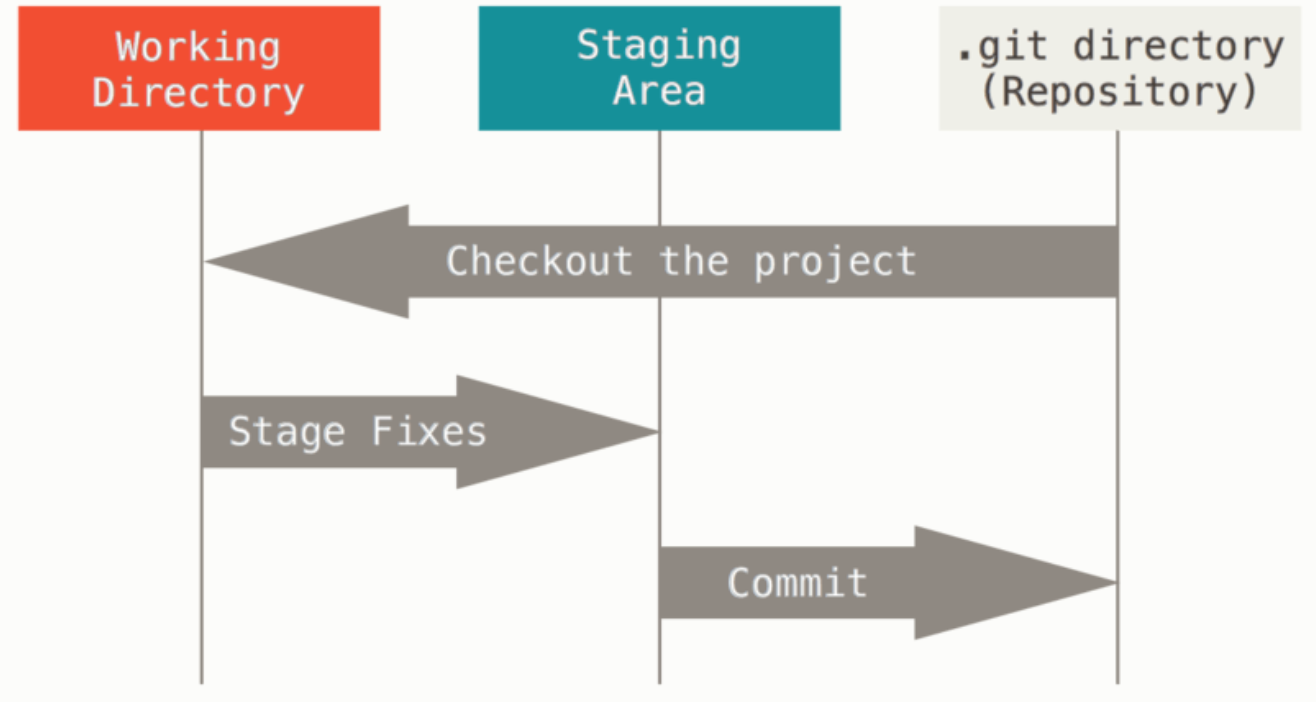
工作区暂存区
SVN 就没有暂存区的概念。
Git 目录
基本的 Git 工作流程如下:
- 在工作区中修改文件。
- 将你想要下次提交的更改选择性地暂存,这样只会将更改的部分添加到暂存区。
- 提交更新,找到暂存区的文件,将快照永久性存储到 Git 目录。
问:为什么要有暂存区?
- 分批递交。(比如我工作区先提交 A、B 文件,再提交 C、D 文件)
- 分阶段提交。(比如我工作区先修改了某文件的 A 处,再修改这个文件的 B 处,当两次提交)
- 保留一份快照,必要时可回退到 stage 时的状态。(git checkout -- file.txt)
③ 我的总结

注:
- 此图只涵盖一些日常操作,方便仅我自己快速查阅,具体细节不赘述了。
- 关于 clone、fetch、pull、push 这些,其实不光是远程仓库跟 git 目录的交互,这里简略的写的。
(2)git add
① 基本操作
git add 是一个多功能命令:
- 把未跟踪(新文件)变成已跟踪,即放到暂存区
- 把已修改文件(已跟踪)放到暂存区
- 合并时把有冲突的文件标记为已解决状态
- 等…
可以将这个命令理解为“精确地将内容添加到下一次提交中”而不是“将一个文件添加到项目中”要更加合适。
注:
- git add 也可以写成 git stage(后者含义更准确,前者是历史遗留)
- 如果同一个文件多次被 add(即可能新增、修改、删除了多次),在暂存区中会合并成一次(最终态)。
② 交互式暂存
应用场景:一个文件你修改了两处地方,但是你只想 add 一处。
> 注:这里不多介绍交互式暂存了,因为在命令行里操作我个人觉得不方便,推荐在 GUI 里操作。
③ 常见问题
1、为什么工作区的空文件夹不能被 add ?
原因:git 会忽略空文件夹
解决办法:在此空文件夹中新建一个空文件,名为 .gitkeep(此名只是约定俗成)
(3)快速 git add 的方法
① git rm - 删除文件的快速 add
git rm README.md
# 相当于
rm README.md
git add README.md
② git mv - 重命名文件的快速 add
git mv README.md README
相当于
mv README.md README
git rm README.md
git add README
适用条件:上面的命令只适用于已跟踪文件。
问:为什么要用这些命令?
- 快捷。会自动帮你 git add
- 安全。如果文件是已修改 or 已放入暂存区,则会被拒并提示你使用 -f
(4)git commit
① 基本操作
方法一:调用编辑器输入提交信息
git commit
注:
- 编辑器中 # 开头的行都是注释行,确认提交后会被丢弃。
- 默认的提交消息中,开头有一个空行,供你输入;接着下面包含了最后一次运行 git status 的输出(但为注释状态)。
- 可以用
commit.template来设置 commit 的提交信息的模板。
方法二:直接命令行里快速输入提交信息
git commit -m 'initial project version'
注:
- 保持一个好习惯:每次 commit 前 status 一下,看看有没有需要 add 的。
② commit message
1、规范
示例:
Redirect user to the requested page after login
http://gitlab.xxx.com/production-team/xxx/issues/171
Users were being redirected to the home page after login, which is less
useful than redirecting to the page they had originally requested before
being redirected to the login form.
* Store requested path in a session variable
* Redirect to the stored location after successfully logging in the user
格式:
- 1、第一行的描述不超过50字
- 2、第二行提供解决了什么 issue
如果是 github / gitlab ,直接 # + issues id 即可。
- 3、第三行详细解析问题
注:
- 使用 line break 分离段落
- 可以使用 emoji,emoji 代表的意思可以参考这个规范:https://gitmoji.carloscuesta.me/
2、Gitkraken 中的 summary + description
有的 GUI 中会把提交信息拆分为 summary + description:
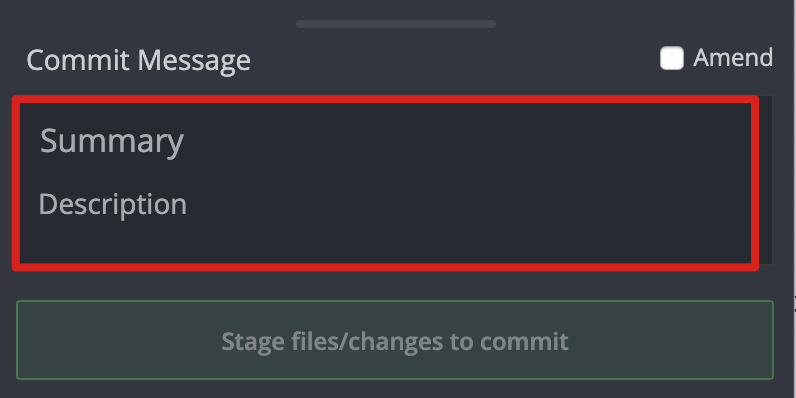
其实划分的规则很简单:summary 为提交信息的首行,description 为提交信息的剩下行。
③ 高级操作
1.0、git commit --amend
作用:这一次提交将代替上一次提交的结果。
适用场景:
- 有新的变动需要提交,但想要合并到上一个提交里。
- 没有新的变动需要提交,只是想修改上一次提交的提交信息。
1.1、git commit --amend --no-edit:
适用场景:
- 有新的变动需要提交,但想要合并到上一个提交里(但提交信息沿用上一个)。
适合只是改改上一个提交的错别字什么的。
注:--amend 生成的提交本质上是新提交,所有 commit id 是会变的。
2、git commit -a
把所有已跟踪文件跳过暂存(无需 add),直接 commit。
这个命令图快,但是使用需谨慎。
(5)git checkout
见上图。(详细介绍看下面的 重置揭秘)
(6)git reset
见上图。(详细介绍看下面的 重置揭秘)
(7)git status
① git status
功能:
- 显示文件状态
- 提供 add commit checkout reset 等命令的建议
- 显示分支信息
- 等…
② git status -s(git status --short)
git status -s 跟 git status 的不同:
- 仅显示文件状态
- git status 的展示逻辑是先划分 工作区暂存区,再展示文件状态(即同一个文件可能出现多次);而 git status -s 展示逻辑是先划分 文件,再展示文件状态(即同一个文件仅会出现一次)
git status -s 的输出结果示例:
$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txt
git status -s 的输出结果中,每个文件的可能出现情况:
| 针对单个文件 | 工作区 | 暂存区 | 暂存区是 add 状态后再在工作区操作 | 暂存区是 修改 状态后再在工作区操作 | 暂存区是 删除 状态后再在工作区操作 |
|---|---|---|---|---|---|
| 添加文件 | ?? | A 空 | N/A | N/A | 会拆分两个同名文件显示(一个是 D空,一个是 ??) |
| 修改文件 | 空 M | M 空 | AM | MM | N/A |
| 删除文件 | 空 D | D 空 | AD | MD | N/A |
注:
- 1、上面的
空代表空格 - 2、如
MM,左边为暂存区文件情况,右边为工作区文件情况 - 3、如果一个文件重命名或者移动了路径,视为删除
(8)git log - 查看提交历史
① 基础用法
1、基础:
git log,结果按时间先后排序,每个 commit 包括:
- commit id
- 作者的名字和电子邮件地址
- 提交时间
- 提交说明
注:作者的名字和电子邮件地址 和 提交时间 都是可以随意改的,所以并不可信。
2、简略:
git log --pretty=oneline,结果只有一行,每个 commit 包括:
- commit id
- 提交说明(如果太长会截取显示)
3、更简略:
git shortlog,结果只有提交说明。(适合输出修改日志(changelog)类文档)
默认会按作者分好组。
4、详细:
git log --stat,结果会比 git log 多出:
- 列出所有被添加/删除/修改过的文件名
- 这些文件,如果是文本文件,显示增删行数;如果是二进制文件,显示增删字节大小。(注意文件的添加删除,也会视为行数/字节的变化)
5、更详细:
git log --patch or git log -p,结果会比 git log 和 git log --stat 多出更多信息:比如每次提交所引入的差异(按 补丁 的格式输出),等。
注:这种展示在命令行很乱,推荐用 GUI 来看吧。
6、定制化:
git log --format定制提交记录的显示格式。
| 选项 | 说明 |
|---|---|
%H |
提交的完整哈希值 |
%h |
提交的简写哈希值 |
%T |
树的完整哈希值 |
%t |
树的简写哈希值 |
%P |
父提交的完整哈希值 |
%p |
父提交的简写哈希值 |
%an |
作者名字 |
%ae |
作者的电子邮件地址 |
%ad |
作者修订日期(可以用 --date=选项 来定制格式) |
%ar |
作者修订日期,按多久以前的方式显示 |
%cn |
提交者的名字 |
%ce |
提交者的电子邮件地址 |
%cd |
提交日期 |
%cr |
提交日期(距今多长时间) |
%s |
提交说明 |
[拓展] 作者(author)和提交者(committer)的区别是:
作者是最初写补丁(patch)的人,而提交者是最后应用补丁的人。
大多数情况两者是一样的,也有不一样:
- 譬如你在 github 的 web 端修改文件并 commit,那作者是你,而提交者是 github
- 如果另一个人用 git cherry-pick, git rebase, git commit --amend, git filter-branch, git format-patch && git am 之类的 git 命令重写了这个 commit,其实都是新生成了一个commit,那么新生成的那个 commit 的 author 还是原来的,但 committer 会变成执行这个操作的用户。可以简单地理解成 author 是第一作者,committer 是生成 commit 的人。
② 筛选用法
| 选项 | 说明 |
|---|---|
<commit id> |
仅显示这条提交及更早的提交。 |
-<n> |
仅显示最近的 n 条提交。 |
--since, --after |
仅显示指定时间之后的提交。 |
--until, --before |
仅显示指定时间之前的提交。 |
--author |
仅显示作者匹配指定字符串的提交。 |
--committer |
仅显示提交者匹配指定字符串的提交。 |
--grep |
仅显示提交说明中包含指定字符串的提交。 |
-S |
仅显示添加或删除内容匹配指定字符串的提交。 |
-- |
仅显示涉及该文件的提交。 |
示例:
# 选项可以搭配使用
git log 42d8fc -2
# 可以是时间 or 时段
git log --since=2.weeks
git log --before="2008-11-01"
# value 有空格等特殊字符,记得加双引号
git log --grep="fix bug"
# -- 可以指定多个文件
git log -- foo.py bar.py
③ 针对单个文件
git log <file>
④ 针对文件中的某行
git log -L:可以展示代码中一行或者一个函数的历史。
写法:
git log -L <start>,<end>:<file>
or
git log -L :<funcname>:<file>,
示例:
假设我们想查看 zlib.c 文件中 git_deflate_bound 函数的每一次变更,我们可以执行 git log -L :git_deflate_bound:zlib.c
注:至于函数的历史,git 默认只支持 C 语言,其他语言需要单独配置,这里不赘述了。
(9)git diff(tool)
① 基本用法
git diff 可以用来分析文件差异。显示的格式正是 Unix 通用的 diff 格式。
git diff 不同比较的参数:
| git diff | 工作区 | 暂存区 | 指定 commit | 最新 commit |
|---|---|---|---|---|
| 工作区 | N/A | - | - | - |
| 暂存区 | 缺省 | N/A | - | - |
| 指定 commit | <commit-id> |
--cached <commit-id> |
<commit-id><commit-id> |
- |
| 最新 commit | HEAD |
--cached HEAD |
<commit-id> |
N/A |
注:
- 默认是比较所有文件,加上
-- <path>是比较具体文件 --cached别名--staged(后者的表意更加正确,前者是历史遗留)
② 高级用法
1、检查差错
--check 可以用来检查多余的 冲突标记 或 空白。
到底什么算空白,是根据
core.whitespace参数来指定的(上面有介绍)。
③ 插件
命令行这么看还是不太直观,git 支持使用插件(譬如第三方 diff 工具甚至图形化工具)来比较差异。
1、查看插件
git difftool --tool-help 可以查看你的系统支持哪些 Git Diff 插件,我的结果如下:
'git difftool --tool=<tool>' may be set to one of the following:
araxis
bc
bc3
emerge
opendiff
vimdiff
vimdiff2
vimdiff3
The following tools are valid, but not currently available:
codecompare
deltawalker
diffmerge
diffuse
ecmerge
examdiff
gvimdiff
gvimdiff2
gvimdiff3
kdiff3
kompare
meld
p4merge
tkdiff
winmerge
xxdiff
Some of the tools listed above only work in a windowed
environment. If run in a terminal-only session, they will fail.
这里我自己会使用我熟悉且好用的 bc/bc3 (即 Beyond Compare)。
2、进行差异比较
用法跟 git diff 一样,即把 diff 替换成 difftool 即可。
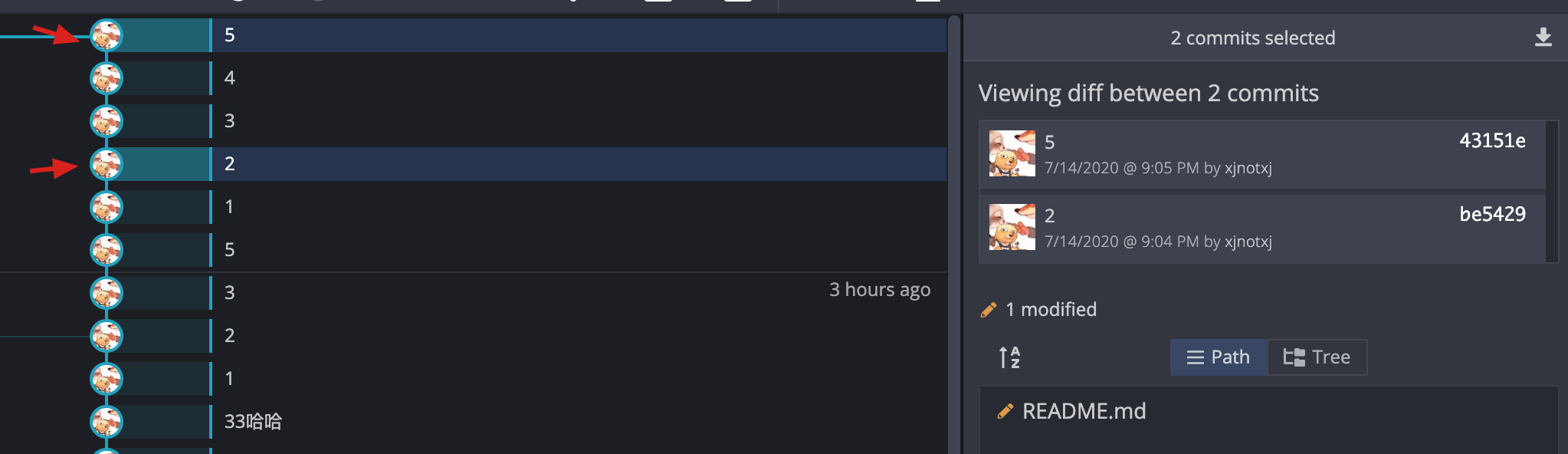
④ GUI - Gitkraken(推荐)
使用 GUI 更方便。
1、选中仅两个提交 - diff between
结果:两个文件之间的差异。
2、选中两个以上提交 - merged diff
结果:这些文件的修改累计在一起。
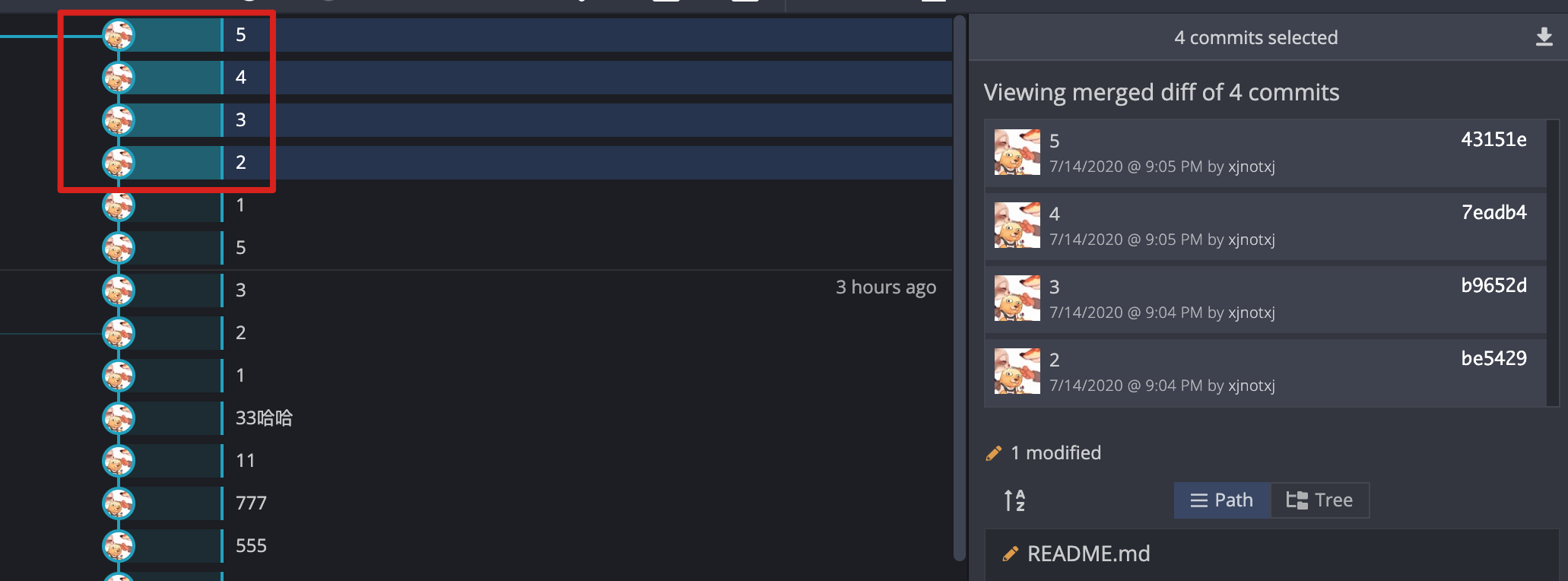
注意:diff between 和 merged diff 结果并不同。
3、其他操作
(1)拒绝 add - 忽略文件
① 基本操作
.gitignore
作用:
当 .gitignore 中包含文件(夹)的路径时, git add . 并不会 add 它,并且如果你单独 git add <filename> 的话,也会默认拒绝,并提示你用 -f 才行。
规则:
.gitignore 使用标准的 glob 模式匹配。
在最简单的情况下,一个仓库可能只根目录下有一个 .gitignore 文件,它递归地应用到整个仓库中。 然而,子目录下也可以有额外的 .gitignore 文件。子目录中的 .gitignore 文件中的规则只作用于它所在的目录中。 (Linux 内核的源码库拥有 206 个 .gitignore 文件。)
注:也可在 git 的配置文件里设置想要忽略的文件,但是不推荐,这样别人 clone 你的项目,并不会沿用你忽略的设置。
示例:
github 针对一些主流的语言、框架、平台推出了常用的 .gitignore:https://github.com/github/gitignore, 例如 Node.js 的 https://github.com/github/gitignore/blob/master/Node.gitignore
没有看到 react。
② 高级操作
1、调试忽略规则
适用场景:某个不想忽略的文件被忽略了,但不知道是哪个 .gitignore 文件的哪一行起的作用。
git check-ignore -v App.class
结果:
.gitignore:3:*.class App.class
Git会告诉我们,.gitignore 文件的第3行规则忽略了该文件,于是我们就可以知道应该修订哪个规则。
③ 常见问题
1、已经 add 的文件如何忽略?
还来得及,因为文件还没被跟踪。保证 .gitignore 有此文件的路径,并用 git reset 把文件从暂存区拿下,即可。
2、已经 commit 的文件如何忽略?
来不及了,因为文件已经被跟踪。
- 方法一:还是要保留文件,只是要取消追踪
# 相当于手动删除 README.md,并 add,接着重新创建跟之前一样的新文件 README.md
git rm --cached README.md
修改 .gitignore 添加 README.md 路径
git commit
- 方法二:既要取消追踪,更要工作区删除文件
直接手动删除 README.md,然后 add
修改 .gitignore 添加 README.md 路径
git commit
方法一 跟 方法二 的区别仅在:add 后有没有重新创建跟之前一样的新文件 README.md。
3、在上面 问题2 基础上,如果我想把之前所有涉及这个文件的 commit 里的那个文件都删除呢?(比如之前的某次 commit 不小心包含了一个很大的文件,虽然按 问题2 的方法移除了,但它还是在 git 仓库中的,譬如别人 clone 还是会占很大地方)
参考下面 重置历史 介绍的 filter-branch 命令。
(2)工作目录 + 暂存区的贮藏 - git stash
① 基础用法
1、贮藏
# 1.0、只贮藏已跟踪文件(工作区+暂存区)
git stash
=
git stash push
# 1.1、贮藏所有文件,包括未跟踪(工作区+暂存区)
git stash
# 2、添加说明信息
git stash save "message…"
贮藏哪类文件的参数:
| git stash | 未跟踪 | 已跟踪(未修改) | 已跟踪(已修改) | 已跟踪(已放入暂存区) | 忽略的文件 |
|---|---|---|---|---|---|
| 缺省 | × | N/A | √ | √ | × |
--include-untrackedor -u |
√ | N/A | √ | √ | × |
--allor -a |
√ | N/A | √ | √ | √ |
原理:把保存到一个栈上。
应用场景:
- 当你在做一个新功能时,突然要紧急修复一个 bug,那你需要先把手头的工作先贮藏,之后再恢复。
2、查看
(1)查看列表
git stash list
结果:
stash@{0}: On master: test -
stash@{1}: On master: 123
stash@{2}: WIP on master: 3bd050d 111
(2)查看具体
git stash show stash@{0}
3、恢复
# 不保留在 list 中
git stash pop
git stash pop stash@{2}
# 还保留在 list 中
git stash apply
git stash apply stash@{2}
注:
- 恢复时,之前在暂存区的,会被移到工作区。如果不想这样(即想原封不动的恢复),可以加上
--index。 - 恢复不需要在当初贮藏的分支
- 恢复不需要保持工作区和暂存区是 clear 状态
适用场景:
- 可以在新分支快速恢复贮藏,并继续工作:
git stash branch testchanges
4、最佳实践
如果想最好的保留和恢复现场,最佳实践是:git stash -u / git stash -a 搭配 git stash pop --index / git stash apply --index。
5、删除
(1)具体
git stash drop
git stash drop stash@{2}。
(2)所有
git stash clear
6、交互式操作
--patch
这个还是用 GUI 把,不然太繁琐。
② 其他用法
1、备份
git stash 还可以用来作备份。
适用场景:工作完成准备提交前,先把暂存区的文件备份下(譬如可以用在另一分支上),可以用 git stash --keep-index,他的效果等于 git stash ,但同时暂存区不会动(但它确实存储了)。
(3)工作目录的清理 - git clean
① 使用
对于工作目录中一些工作或文件,你想做的也许不是贮藏而是移除。 git clean 命令就是用来干这个的。
注:这个不可恢复,一个更安全的选项是运行 git stash --all 来移除每一样东西并存放在栈中。
清理哪类文件的参数:
| git clean | 未跟踪 | 忽略的文件 |
|---|---|---|
| 缺省 | √ | × |
-x |
√ | √ |
其他参数:
-d:清除子目录-i或--interactive:交互式
注意:
git clean 不可恢复,最好
- 1、使用前先用
--dry-run或-n,模拟清理,它会告诉你将要移除什么。 - 2、可以先用 git stash 备份下。
4、签署工作
前面提到 commit 的元信息,是可以随便输入的(比如你可以把 author 随便改成别人的名字),那岂不是 git 不安全的吗?
git 可以使用 GPG 来签署自己的工作,例如:
- 签署提交
- 签署标签
- ………
本人暂时没用到,这里不赘述了,感兴趣的看:https://git-scm.com/book/zh/v2/Git-工具-签署工作
5、检索
(1)git grep
git grep 查找一个字符串或者正则表达式,支持:
- 工作区(默认)
- 暂存区
- 提交历史
- 等等
问:针对工作区,我们可以使用 grep 或者 IDE 的搜索;针对提交历史,我们可以使用 git log,为什么还要使用 git grep 呢?
答:
- 速度非常快
- 检索的范围更广
(2)其他检索方式
1、git log 检索提交历史。
参考上面的 git log 的介绍。
四、分支
1、分支简介
git 的分支功能是必杀技特性,使得 Git 从众多版本控制系统中脱颖而出。
优点:
- 轻量
- 快速
- 简单
2、分支原理
① 分支
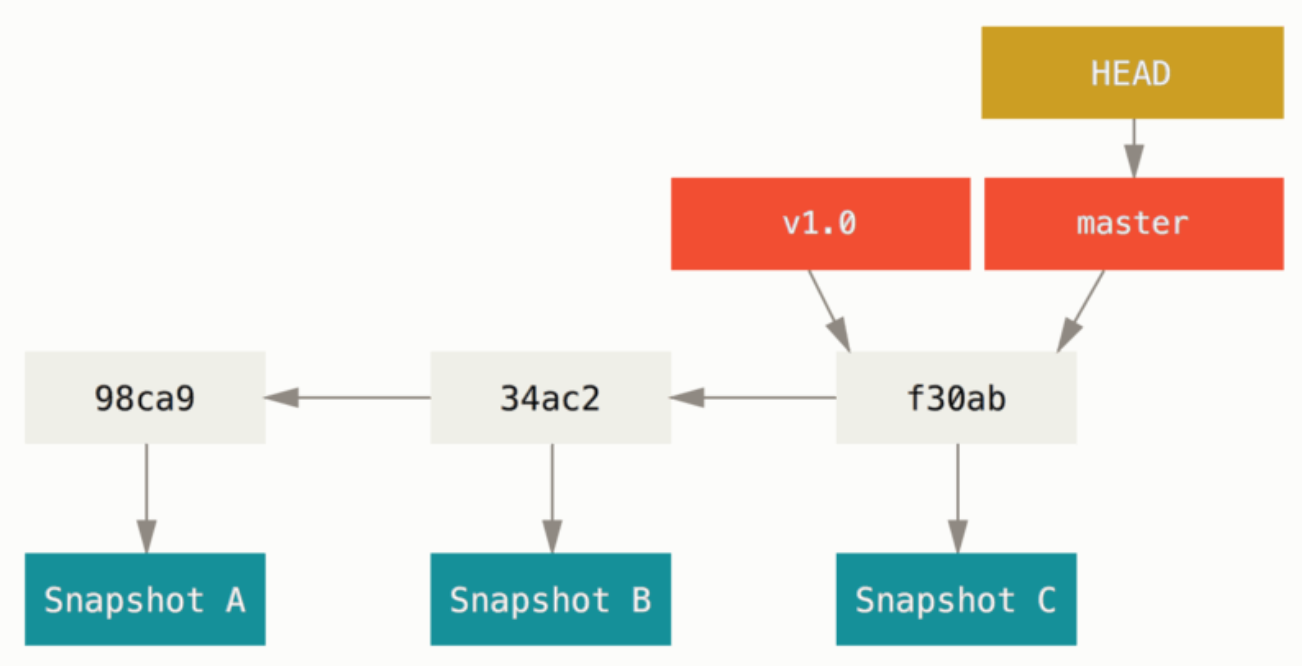
Git 的分支的本质上仅仅是指向提交对象的可变指针。
② 当前分支(通过 HEAD)
那如何知道当前分支是哪一个呢?有一个名为 HEAD 的特殊指针。
3、使用
(1)默认分支
Git 的默认分支名字是 master。
在 git init 的时候就会默认创建它。
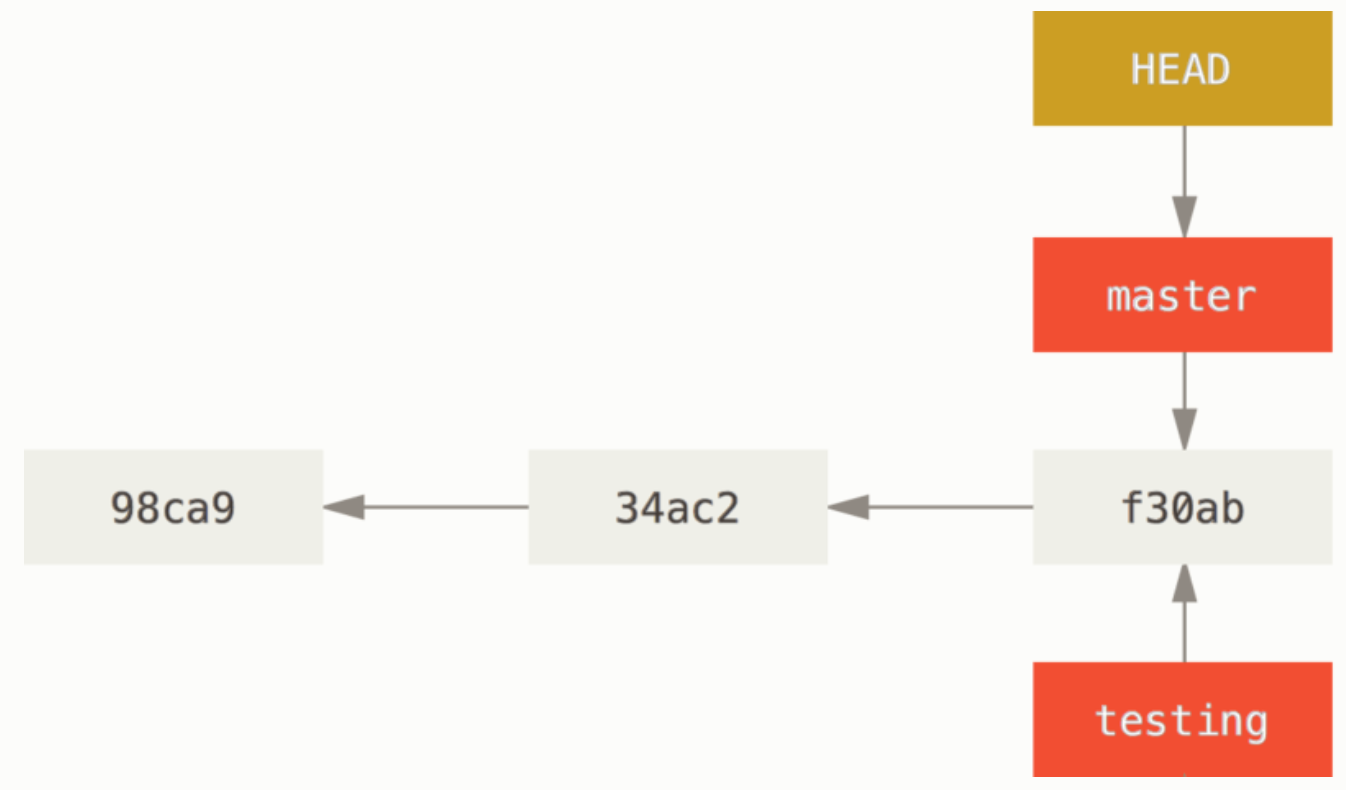
(2)分支创建
① 原理
在当前所在的提交对象上创建一个指针。
② 操作
方法一:只创建分支不切换。
# 默认指向HEAD
git branch testing
# 指向具体某个引用
git branch testing master
关于引用是什么,下面会专门介绍。
方法二:创建分支并切换。
# 默认指向HEAD
git checkout -b testing
# 指向具体某个引用
`git checkout -b testing master`
上面的 git checkout -b testing 等同于:
git branch testing
git checkout testing
(3)查看(当前)分支
① 简略
git branch
输出结果:
* master
production
staging
uat
② 详细
git branch -v
输出结果:
* master 0936571 [ahead 24] 11
master2 699c90b 123
master3 81a05db 11
staging ba8dee8 快合并
比 git branch 多包含了:
- 分支上的最新一次提交(commit id + 提交信息)
(4)分支切换
原理:HEAD 指针的移动。
git checkout testing
注:工作区和暂存区的内容都会保持跟随。
(5)删除分支
原理:删除指针(所以很快)
git branch -d hotfix
4、git log 涉及分支的用法
- git log 默认是显示当前分支下的提交历史
git log --all可以显示所有分支下的提交历史git log --oneline --graph --all可以显示所有分支下的提交历史,并且有图形化的分支合并展现。(推荐还是 GUI 看吧)--no-merges,不显示合并提交。--merge,显示合并提交。
5、分支类型
(1)按稳定性分
① 长期分支
- 为不同开发环境创建不同分支( 譬如 staging、uat、production )
- 为不同稳定性创建的不同分支(譬如 LTS、Current )
② 主题分支(短期分支)
主题分支是一种短期分支,它被用来实现单一特性或其相关工作。
- 不同人在不同分支上独立工作
- 创建新分支来 fix bug( 通常这样的分支起名为
hotfix)
6、合并分支
(1)为什么要合并分支
当你创建新的分支后,随着后续各分支的提交,会形成分支分叉。那么我们可能需要合并分支。
(2)合并操作
git merge <branch>
示例:
git checkout -b hotfix
# 修改问题
# commit
git checkout master
git merge hotfix
(3)合并结果
上面的合并分支的结果:
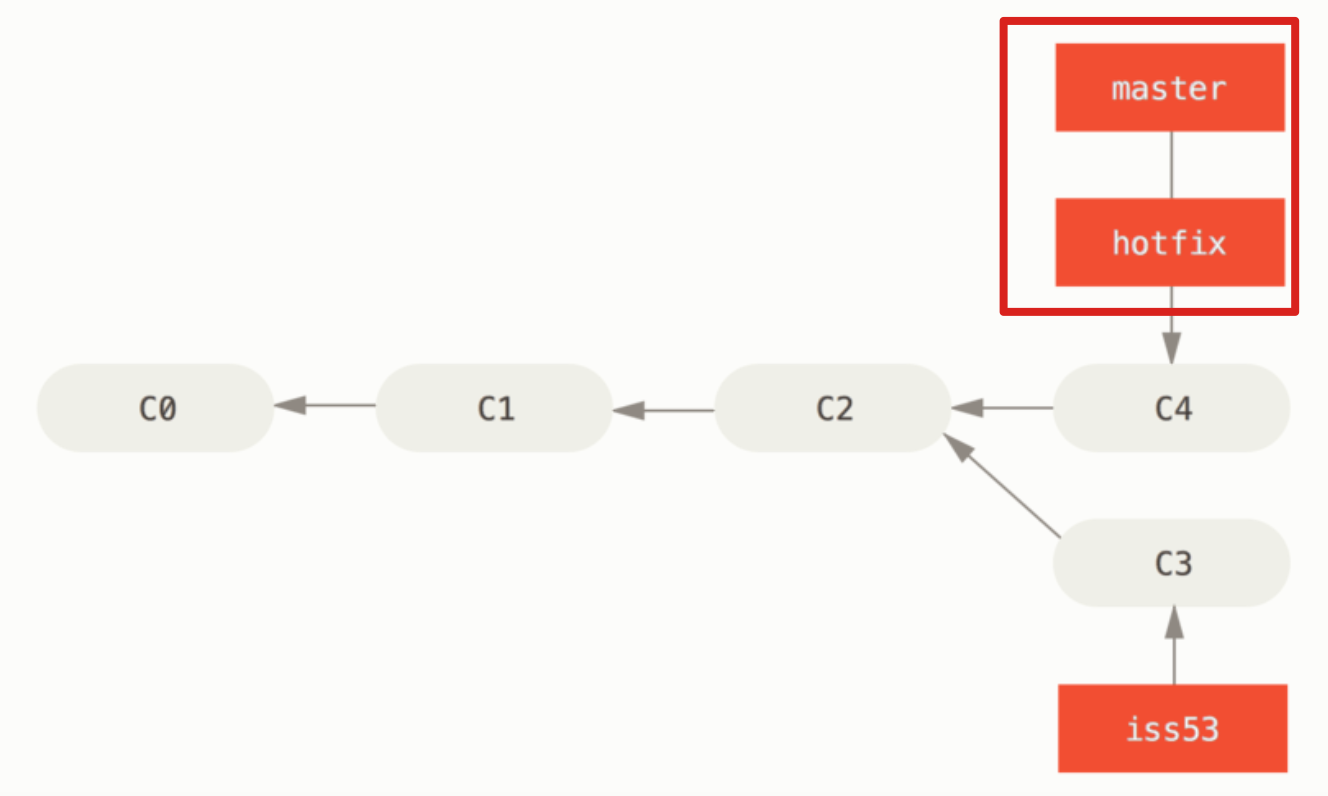
① Fast-forward 快进合并
情形:如果顺着一个分支走下去能够到达另一个分支,那么 git 只会简单的将指针向前推移。
合并前:
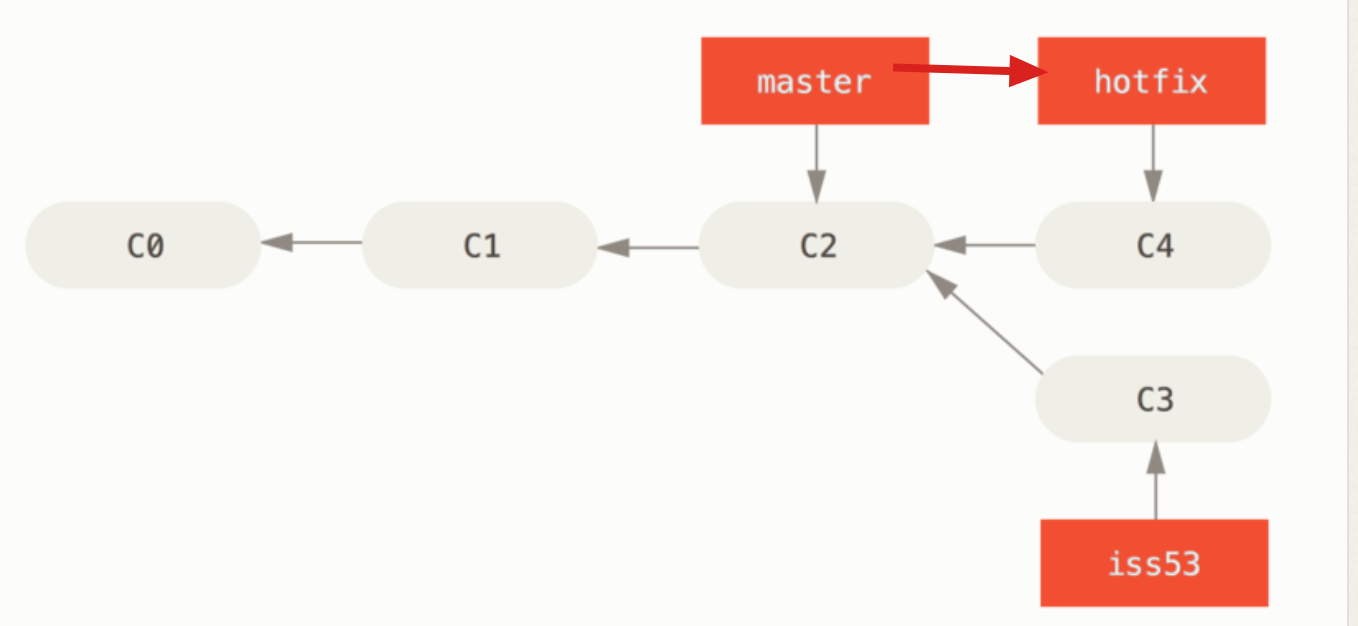
合并后:
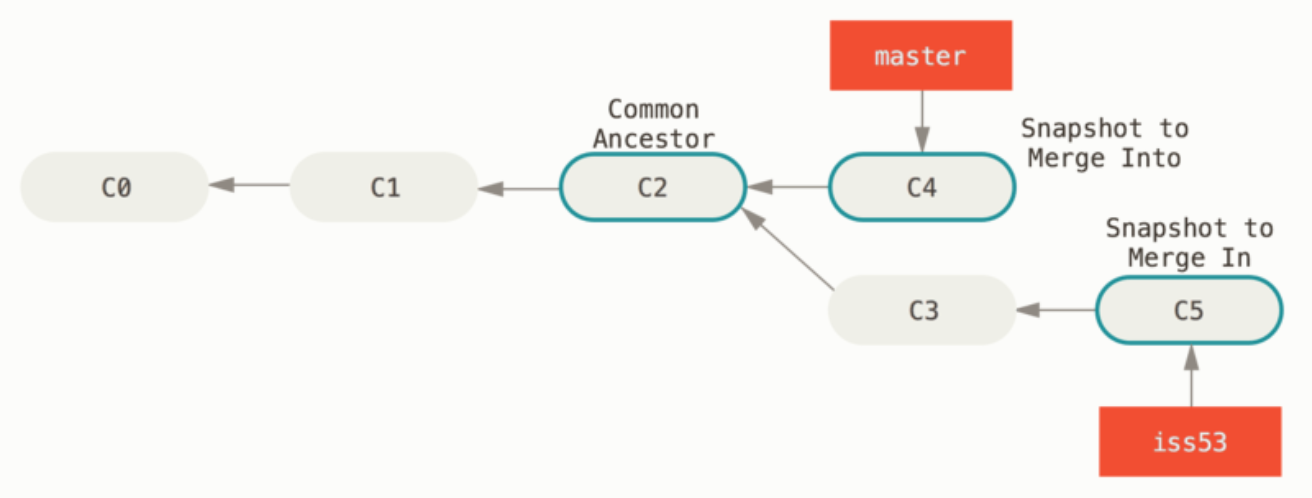
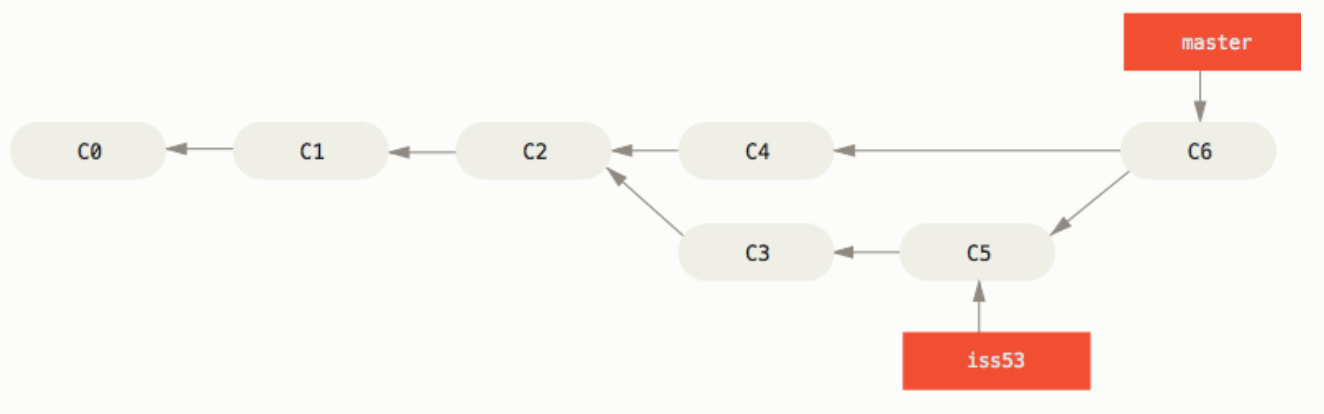
② 三方合并
情形:(如下图),Git 会使用两个分支的末端所指的快照(C4 和 C5)以及这两个分支的公共祖先(C2),做一个简单的三方合并(生成 C6)。
合并后如果不需要原分支就可以删除它了(毕竟已经指向了同一个位置)。
合并前:
合并后:
③ 快进合并和三方合并的区别【重点】
- 1、快进合比三方合并快速
- 2、快进合并不会生成新的提交对象,而三方合并会生成新的提交对象(即合并提交)
- 3、快进合并并不会产生冲突,而三方合并有可能会产生冲突
④ 问:为什么有时候要用 --no-ff 禁用快进合并?【重点】
git merge --no-ff hotfix
一般建议在主要、重要的分支上,习惯性的带上--no-ff。只要发生合并,就要有一个单独的合并节点。 (尤其是修复 bug 的分支)
它的好处有:
- 1、保持commit信息的清晰直观。
- 2、不利于以后的回滚,见下图。
示例:
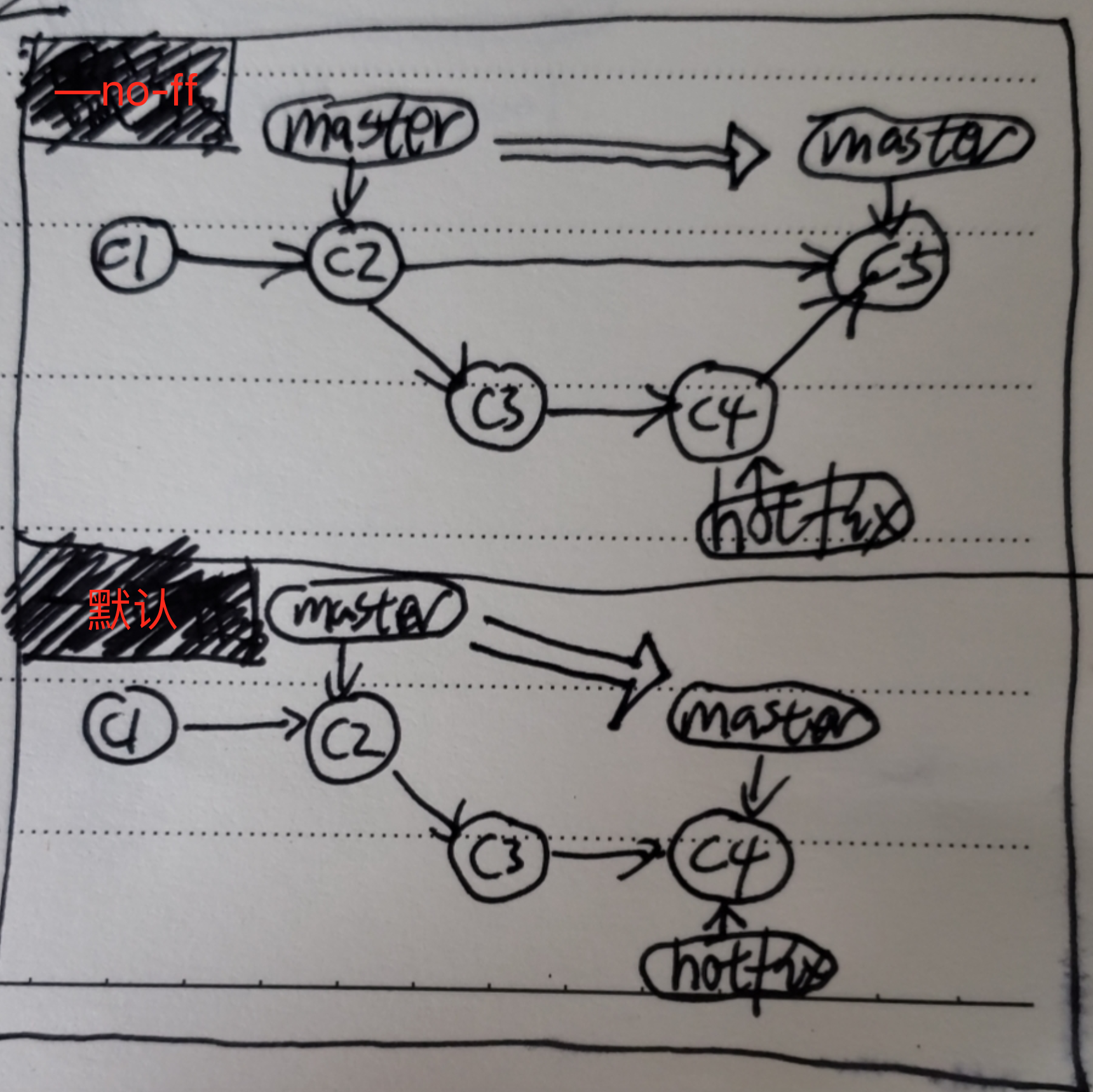
- 如果不加 --no-ff(图下方),默认是快进合并,那在 C5 处想要回滚到 HEAD^ ,则回到 C3 ( 这不是我们想要的 )。
- 而如果加了 --no-ff(图上方),那在 C5 处想要回滚到 HEAD^ ,则回到 C4 ( 是我们想要的 )。
(4)解决冲突
① 手动解决冲突
解决步骤:
1、合并结果会告诉你存在冲突,并让你去解决。(冲突的文件位于工作区)
2、git status 会在 Unmerged paths 中列出冲突的文件名
3、打开冲突的文件,会用 会用 <<<<<<< , ======= , 和 >>>>>>> 来标识冲突之处,如下所示:
<<<<<<< HEAD
2222
=======
1111111111
>>>>>>> staging
- 上面显示当前所在分支
- 下面显示合并进来的分支
4、手动编辑
5、git add 去 mark resolution, git commit 去提交 resolution,才算最终完成冲突的解决。
② 插件解决冲突
这里使用到 git mergetool 命令,跟另一个命令 git difftool 有些类似,可以借鉴使用。
1、git mergetool --tool-help 可以查看你的系统支持哪些 Git merge 插件(我是 mac,默认为 vimdiff,但我这里用 Beyond Compare)。
2、git mergetool -t bc,git 会自动打开 Beyond Compare,然后在里面手动编辑。
3、编辑好后保存退出 Beyond Compare,命令行会向你确认:”Was the merge successful“,输入 y,则完成冲突的解决( git 会自动帮你 add ),最后再 commit。
[拓展]
用 mergetool 的话,会有一个麻烦,就是每次编辑完后,会自动生成 [冲突的文件名].orig 的备份文件在我的工作区。
解决办法:
- 在 .gitignore 中忽略它
- 直接修改 git 设置:
git config --global mergetool.keepBackup false,禁止产生备份文件
③ 手动解决冲突 和 插件解决冲突 的区别
- 1、在编辑文件时,前者只会提供冲突地点两方的文件内容;而后者会提供冲突地点三方的文件内容(即 base + local + remote )
- 2、在编辑文件后,前者需要手动 add + commit,而后者(当你在命令行里确认解决后) git 会自动帮你完成 add,但需要最后手动 commit。
④ GUI - Gitkraken 解决冲突
因为 Gitkraken 免费版不支持编辑冲突文件,所以略。
(5)高级 - 关于冲突的更多操作
① 取消解决冲突
git merge --abort or git reset --hard HEAD 可以恢复合并前的状态(工作区不可恢复,这也是为什么建议合并前保持工作区是空的状态的原因了)
② 检出(三方)冲突
1、介绍
Git 会提供一个略微不同版本的冲突标记: 不仅仅只给你 “ours” 和 “theirs” 版本,同时也会有 “base” 版本在中间来给你更多的上下文。
在上面介绍的插件解决冲突,用 Gitkraken 也是支持显示出三方源( 包括 base )。
2、操作
# 单次
git checkout --conflict=diff3 hello.rb
or
# 永久
git config --global merge.conflictstyle diff3
3、结果
def hello
<<<<<<< ours
puts 'hola world'
||||||| base
puts 'hello world'
=======
puts 'hello mundo'
>>>>>>> theirs
end
③ 快速解决文件冲突
git 提供一种无需合并的快速方式,你可以选择留下一边的修改而丢弃掉另一边修改。
git checkout --ours hello.rb
git checkout --theirs hello.rb
适用场景:
- 二进制文件冲突时这可能会特别有用,因为可以直接简单地选择一边。
④ 记住冲突 - git rerere
git rerere 是“重用已记录的冲突解决方案(reuse recorded resolution)”的意思。它允许你让 Git 记住解决一个块冲突的方法(在缓存中), 这样在下一次看到相同冲突时,Git 可以为你自动地解决它。
具体用法待写。
(6)高级 - 关于合并的更多操作
① 更多的合并方法
方法一:直接合并,不产生冲突
# 直接合并所有
git merge -Xours branch-name
git merge -Xtheirs branch-name
# 直接合并单个文件
git merge-file --ours filename.txt
git merge-file --theirs filename.txt
方法二:假合并 - “ours” 策略
欺骗 Git 认为那个分支已经合并过。实际上并没有合并。
$ git merge -s ours branch-name
Merge made by the 'ours' strategy.
适用场景:
假设你有一个分叉的 release 分支并且在上面做了一些你想要在未来某个时候合并回 master 的工作。 与此同时 master 分支上的某些 bugfix 需要向后移植回 release 分支。 你可以合并 bugfix 分支进入 release 分支同时也 merge -s ours 合并进入你的 master 分支 (即使那个修复已经在那儿了)这样当你之后再次合并 release 分支时,就不会有来自 bugfix 的冲突。
方法三:子树合并
子树合并的思想是你有两个项目,并且其中一个映射到另一个项目的一个子目录,或者反过来也行。 当你执行一个子树合并时,Git 通常可以自动计算出其中一个是另外一个的子树从而实现正确的合并。
略
② 更多的合并选项
1、忽略空白
- -Xignore-all-space:在比较行时完全忽略空白修改
- -Xignore-space-change:第二个选项将一个空白符与多个连续的空白字符视作等价的
你也可以手动处理文件后再合并,实际上,这比使用 ignore-space-change 选项要更好,因为在合并前真正地修复了空白修改而不是简单地忽略它们。(在使用 ignore-space-change 进行合并操作后,我们最终得到了有几行是 DOS 行尾的文件,反而使提交内容混乱了。)
(7)撤销合并
场景:当你不小心合并了:
① 方法一:修复引用
git reset --hard HEAD~
结果:
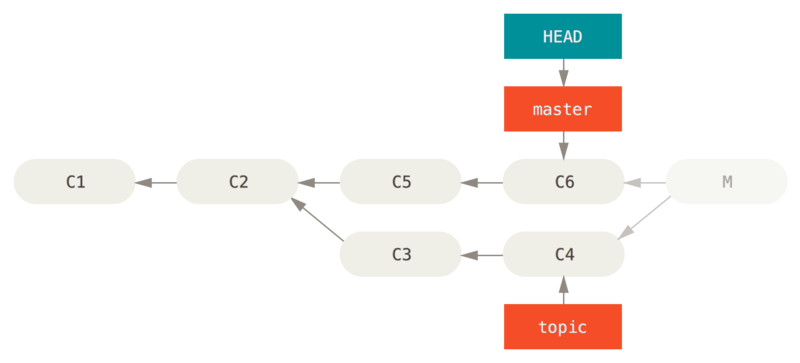
缺点:重写了历史,在一个共享的仓库中这会造成问题的。
② 方法二:还原提交
revert 命令下面会专门介绍。
git revert -m 1 HEAD
“-m 1” 标记指出 “mainline” 需要被保留下来的父结点。
结果:
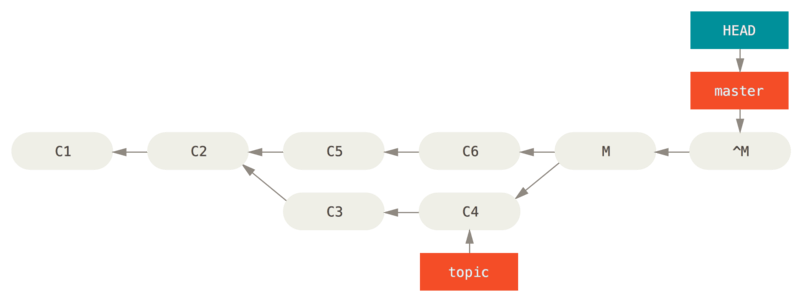
新的提交 ^M,内容等于 -C3 + -C4(他们的还原)。即 ^M 与 C6 有完全一样的内容,所以从这儿开始就像合并从未发生过。
[拓展] 问:如果在 topic 分支上又加了个 C7,然后想把 topic 分支再合并到 master 来。怎么办?
希望结果: master 能包含 topic 分支的 C3 + C4 + C7 提交。
易错方法:直接 git merge topic,错误,因为之前合并过,所以导致这次合并仅有 C7 的提交
正确方法:执行 git revert ^M,M 与 ^M 抵消了(即 ^^M 等于 C3 与 C4 的修改),这时再 git merge topic 即可。结果见下图:
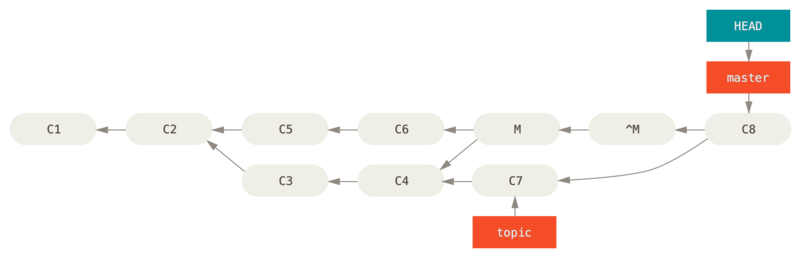
(8)查看 待合并/合并过 的分支
① 查看哪些分支已经合并到 当前分支/指定分支
git branch --merged / git branch --merged master
在输出的结果列表中,分支名字前没有 * 号的可以使用 git branch -d 删除。
② 查看哪些分支还没合并到 当前分支/指定分支
git branch --no-merged / git branch --no-merged master
在输出的结果列表中,git branch -d 是删除不了的,必须 -D 强制删除。
注意 -d 和 -D 的区别,-d 只是删除,而 -D 是强制删除。
7、远程仓库
注:远程仓库可以在远程服务器,也可以在你的本地主机上。(词语“远程”只是表示它在别处。)
(1)查看
① 列表
1、基本
git remote:它会列出每一个远程仓库的简写。
输出结果:
# 默认
origin
2、详细
git remote -v:它会列出每一个远程仓库的简写 + 对应的 URL + fetch or push。
输出结果:
origin https://github.com/xjnotxj/test.git (fetch)
origin https://github.com/xjnotxj/test.git (push)
② 具体详情
git remote show <remote>,如 git remote show origin。
输出结果:
* remote origin
Fetch URL: https://github.com/xjnotxj/test.git
Push URL: https://github.com/xjnotxj/test.git
HEAD branch: master
Remote branch:
master tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (fast-forwardable)
(2)添加
git remote add <shortname> <url>,如 git remote add pb https://github.com/paulboone/ticgit
注:如果你使用 clone 命令克隆了一个仓库,git 会自动将其添加为远程仓库并默认以 “origin” 为简写。
(3)修改
① 修改简写
git remote rename <old-shortname> <new-shortname>,git remote rename pb paul
② 修改 url
git remote set-url <shortname> <new-url>,如 git remote set-url origin git@github.com:test/thinkphp.git
注:没找到修改单独 fetch / push 的 url 的命令,不知道支不支持。待写。
(4)删除
git remote rm <shortname>,如 git remote rm origin
8、远程仓库的分支
(1)远程分支
① 介绍
远程分支(remote branch)就是在远程仓库上的分支。
② 操作
1、查看
git branch -r
还有个更底层的命令:
git ls-remote <remote>
输出结果:
origin/HEAD -> origin/master
origin/master
[拓展]
git branch -a 查看所有分支(本地+远程)。
2、删除
git push origin -d serverfix
3、创建
参考下面的 git push 介绍。
(2)远程分支的跟踪
① 概念【重点】
1、远程跟踪分支(remote-tracking branch)是记录远程分支状态的本地分支。
特点:
- 以
<remote>/<branch>的形式命名。 - 只读(用户不能随意移动,除非使用 git fetch 等指令)。
- 并不能切换过去然后编辑,它只是一个指针。(想要编辑必须创建 跟踪分支)
2、跟踪分支(tracking branch) 是一个本地分支,它通过跟远程跟踪分支产生关联,进而间接地跟远程分支产生关联。
注意:远程分支、远程跟踪分支 和 跟踪分支 的区别。
作用:可以方便的进行 pull 和 push(用简写形式)(下面会专门介绍)。
3、上游分支(upstream branch),即 跟踪分支 追踪的远程分支。
② 操作
1、创建(远程跟踪分支+跟踪分支)
方法一:git clone
- 默认只自动创建 master 的 远程跟踪分支 + 跟踪分支
- 其它的远程分支只会创建远程跟踪分支而没有跟踪分支

方法二:git checkout
1、当没有事先准备好的本地分支,就直接创建跟踪分支
(1)本地分支名跟随远程分支名(需保证没有重名的本地分支)
git checkout --track origin/serverfix
git checkout serverfix # 简写(省去了“origin/”)
(2)本地分支名自拟
git checkout -b newBranch origin/serverfix
2、当有事先准备好的本地分支,就转化为跟踪分支(也可用于修改跟踪分支的追踪)
(1)单独指定
git branch -u origin/serverfix # -u = --set-upstream-to
git branch -u origin/serverfix serverfix2
(2)在想要 push 的时候指定
git push -u origin colin1
(3)在想要 pull 的时候指定
# 并没有 git pull -u origin colin1
# 操作同(1)单独指定
2、修改
参考上面的 ”1、创建“ --> ”方法二:git checkout“ --> ”2、当有事先准备好的本地分支,就转化为跟踪分支“
3、删除
- 只能删除跟踪分支(就按普通分支删除即可)
- 不能删除远程跟踪分支
4、查看
git branch -vv:查看本地分支 or 跟踪分支(及它的远程跟踪分支)
注意:如果远程跟踪分支没有被跟踪,则不会显示。
输出结果:
* colin d145421 22
develop 17e0c45 [origin/develop] Merge pull request #3 from xjnotxj/master
master 6bd8a8d [origin/master: behind 1] Create blank.yml
输出结果:
iss53 7e424c3 [origin/iss53: ahead 2] forgot the brackets
master 1ae2a45 [origin/master] deploying index fix
* serverfix f8674d9 [teamone/server-fix-good: ahead 3, behind 1] this should do it
testing 5ea463a trying something new
注:
- 跟踪分支上还会显示与远程跟踪分支相比领先和落后的情况(例如 ahead 3, behind 1)。
这个情况需要经常的 fetch 保持更新(如何 fetch 参考下面的介绍)。
(3)git fetch - 更新 远程追踪分支
原理:将远程分支拉取到对应的远程跟踪分支。
# 1、所有 remote 的所有远程分支
git fetch --all
# 2、remote 的所有远程分支
git fetch # 默认为 origin
=
git fetch origin
# 3、remote 的指定远程分支
git fetch origin branchName
注:
- 好习惯:定期的运行 git fetch --all,不过如果用 GUI 工具,一般默认它都会自动帮你轮询频繁执行。
(4)git pull - 拉取 远程分支并合并
原理:将远程分支拉取到对应的远程跟踪分支,并与本地分支(譬如跟踪分支)合并(等于 git fetch + git merge)。
# 1、完整写法
git pull origin next:master # origin 的远程分支 next fetch 下来并和 master 合并
git pull origin next # 简写(如果远程分支和本地分支都叫 next)
# 2、简洁写法(如果配了跟踪分支)
git pull # 默认 origin + 当前分支
=
git pull origin # 默认 当前分支
(5)git push - 推送
原理:将本地分支(譬如跟踪分支)推送到远程分支。
# 1、完整写法
git push origin next:master # origin 的本地分支 next push 到远程分支 master 上
git push origin next # 简写(如果本地分支和远程分支都叫 next)
# 2、简洁写法(如果配了跟踪分支)
git push # 默认 origin + 当前分支
=
git push origin # 默认 当前分支
前提:
- 有远程仓库的写入权限
- 之前没有人推送过(最佳实践:先 pull 再 push)
适用场景:
- 可以分私人分支和公开分支,私有分支不 push。
(6)应用:使用远程仓库与别人协作
也可适用于 github 上 fork 项目后,保持更新。
① 长期合作
保存为源,并建立跟踪分支,以后方便使用。
git remote add jessica git://github.com/jessica/myproject.git
git fetch jessica
git checkout -b rubyclient jessica/ruby-client
② 短期合作
不保存,仅临时使用。
git pull https://github.com/onetimeguy/project # 当前分支
git pull https://github.com/onetimeguy/project master # 指定分支
9、变基
(1)介绍
其实,在 Git 中整合不同分支的修改主要有两种方法:
merge 合并(上面介绍过了)rebase 变基
变基(rebase)可以将提交到某一分支上的所有修改都移至另一分支上。
就好像“重新播放(replay)”一样。
这个比喻生动形象!
(2)基础用法
① 示例
1、变基前
目标:把 experiment 分支变基到 master 分支上。
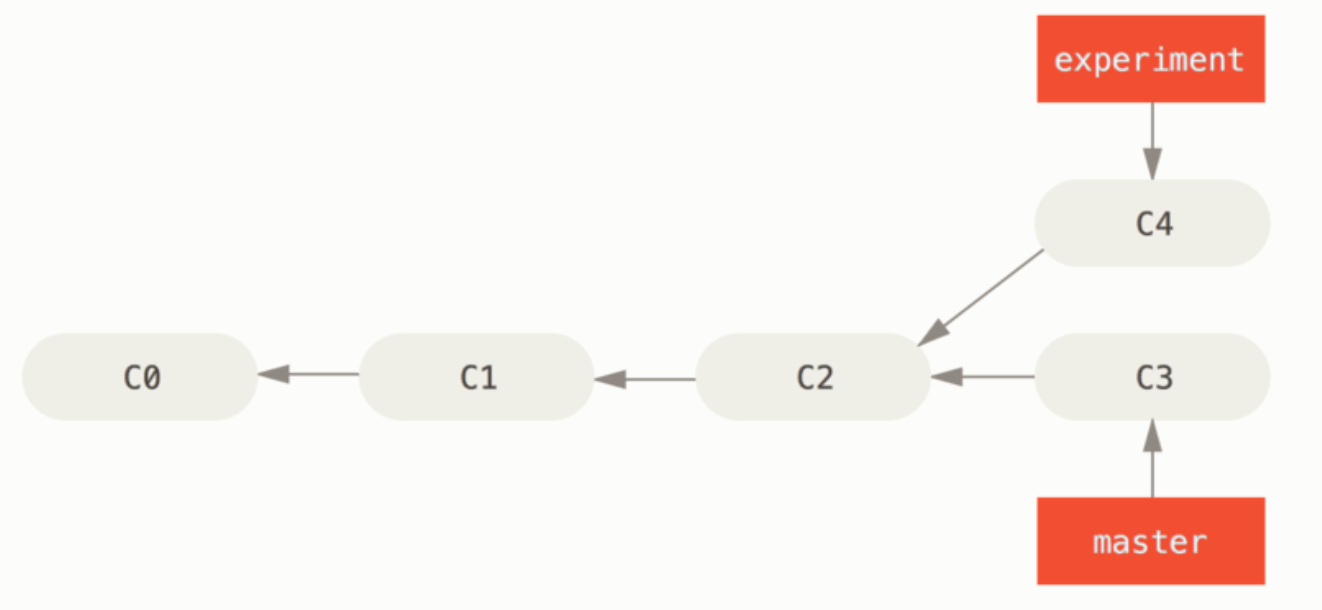
2、变基
git checkout experiment
git rebase master
结果:现在提取在 C4 中的修改,然后在 C3 的基础上应用一次。
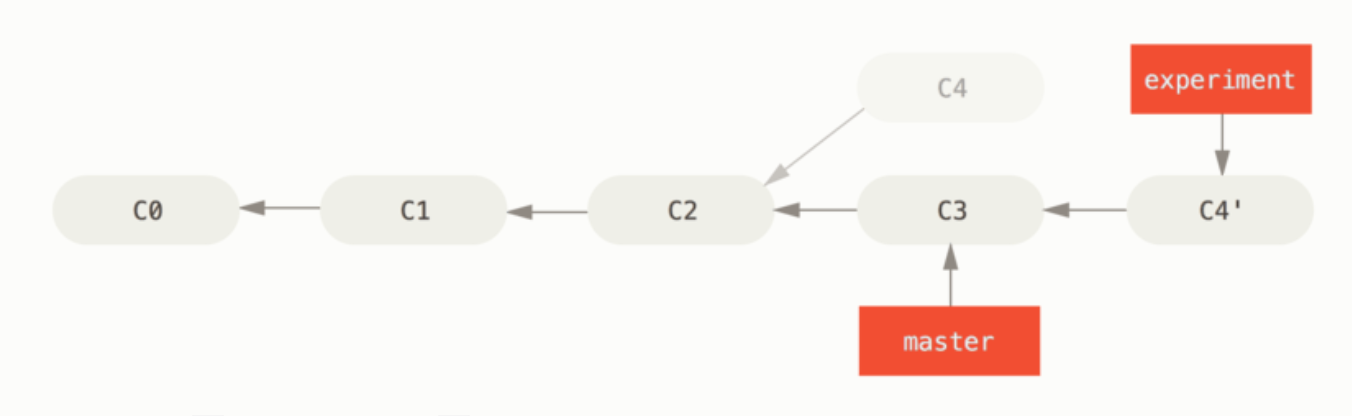
3、变基后
目标:把 master 分支往前移,到 experiment 分支的位置。
方法一:使用 merge 的快进合并
git checkout master
git merge experiment
方法二:再次用 rebase(使用 rebase 的快进合并)
git rebase master
git checkout master
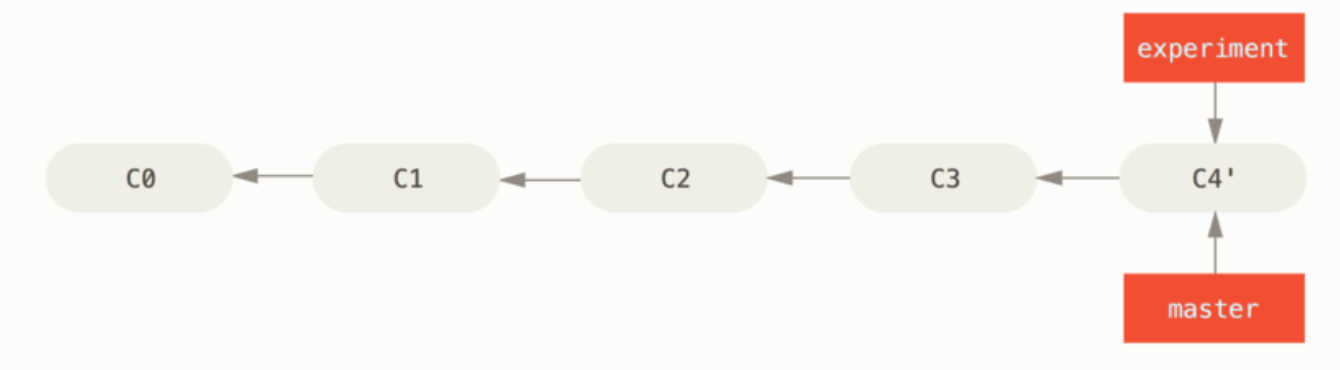
② 原理步骤
- 1、首先找到这两个分支(即当前分支 experiment、目标分支 master)的最近共同祖先 C2
- 2、然后对比当前分支相对于 C2 的历次提交,提取相应的修改并存为临时文件
- 3、然后将当前分支指向目标分支的最新提交 C3
- 4、最后将之前另存为临时文件的修改依序应用
(3)高级操作
① --onto
1、介绍
上面说到变基可以将提交到某一分支上的所有修改都移至另一分支上,注意这个“所有修改”。但有时候我们不想要全部。
目的:选中在 client 分支里但不在 server 分支里的修改(即下图的 C8 和 C9),将它们在 master 分支上重放。
结果:让 client 看起来像直接基于 master 修改一样
2、操作
(1)变基前
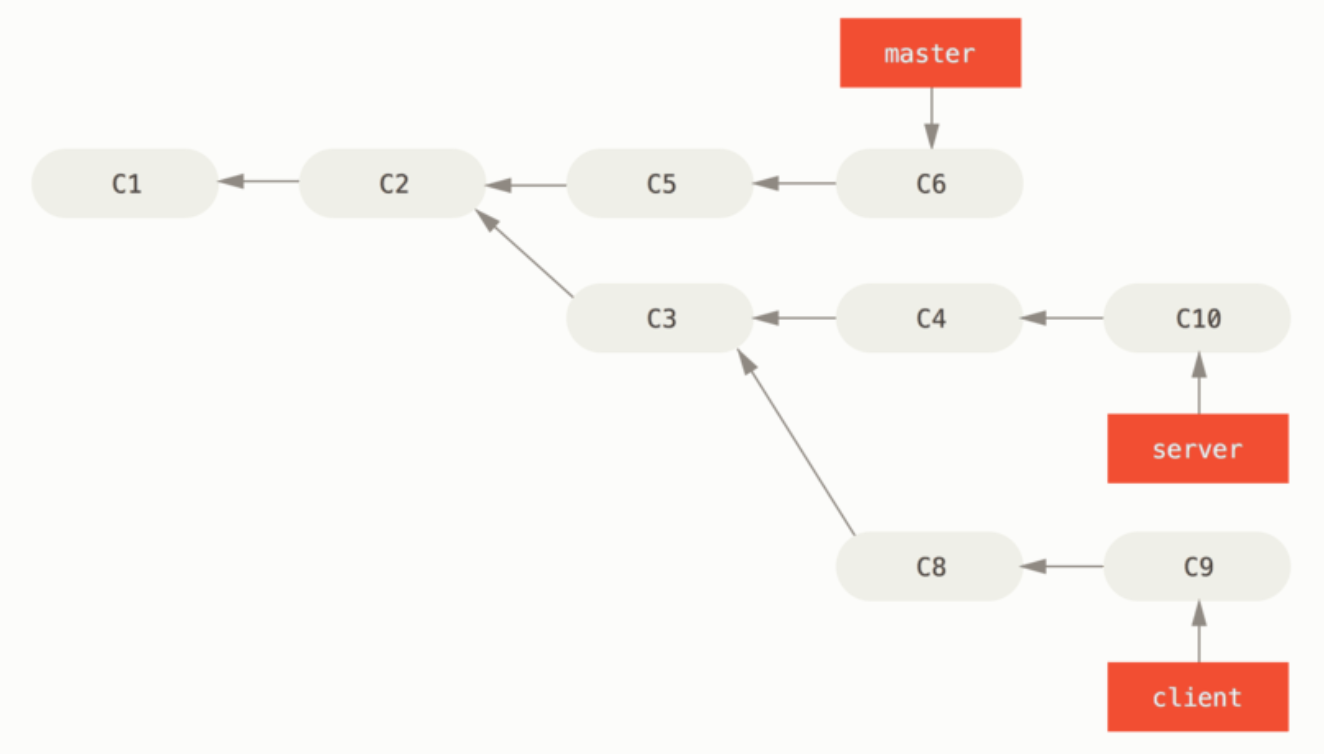
(2)变基
git rebase --onto master server client
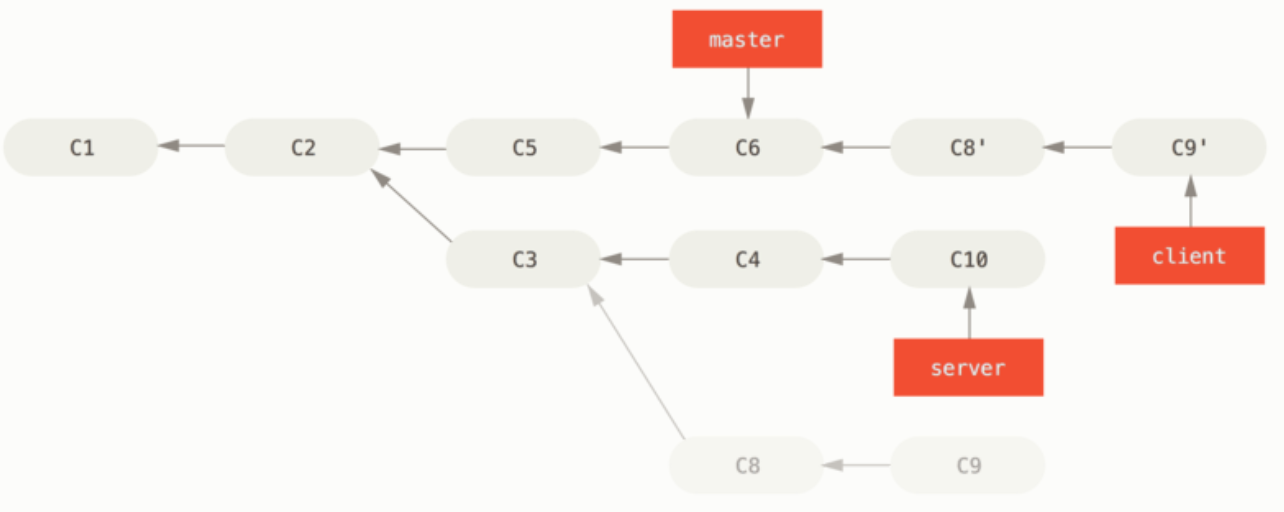
(3)变基后
git checkout master
git merge client
② 交互式【重点】
1、介绍
上面说到 rebase 的功能就像”重新播放“一样,那在重新播放的时候,我们可以做很多的变化:
- 删除提交
- 修改提交(的提交信息)
- 合并提交
- 拆分提交
- 重新排序提交
2、用法
(1)命令行
git rebase -i 支持交互式操作。
例如 git rebase -i HEAD~3 表示要修改在 HEAD~3..HEAD 范围内的提交。
(2)GUI(Gitkraken)(推荐)
跟用命令行差不多,但操作更加直观便捷。
方法一:交互式操作
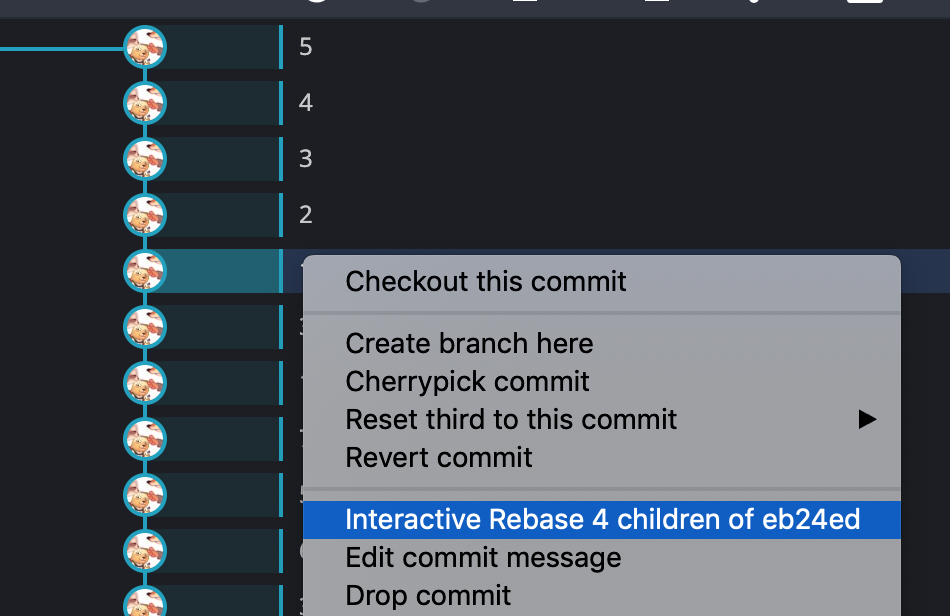

支持:
- 即保留这个提交不变 —— pick(默认)
- 合并提交 —— squash
- 修改提交信息 —— reword
- 删除提交 —— drop
- 排序提交 —— 直接鼠标拖拽排序位置
没找到拆分提交在哪。
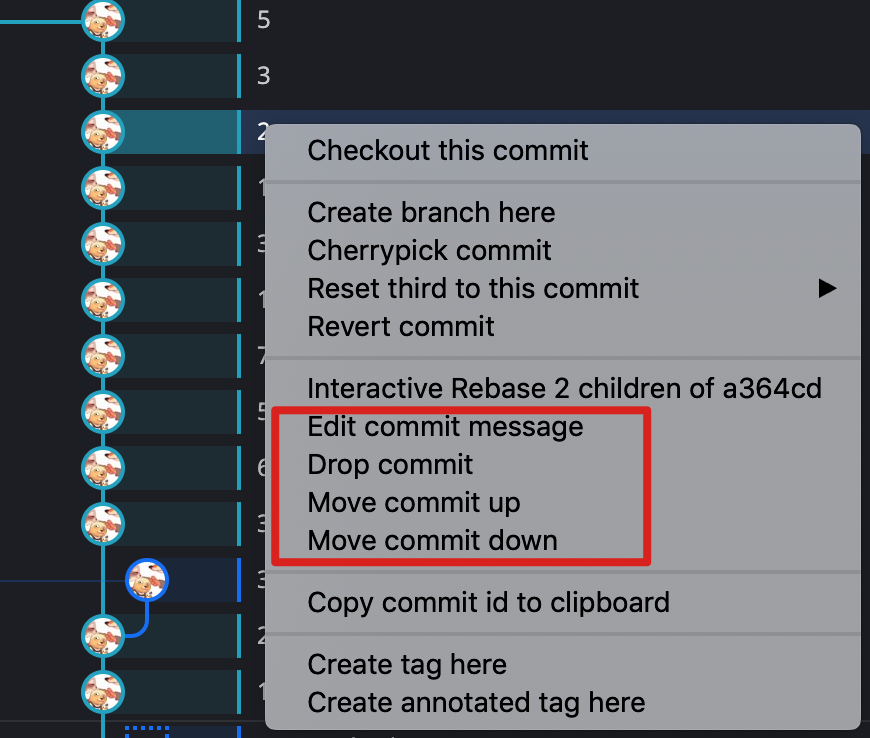
方法二:快捷操作
是基于上面交互式操作的快捷方法。
(4)冲突
① rebase 关于冲突的操作
- 如果您希望跳过冲突:git rebase --skip
- 停止 rebase:git rebase --abort
② rebase vs merge
rebase 跟 merge 一样,在涉及快进合并上不会有冲突,但是三方合并可能存在冲突。
但跟 rebase 的冲突处理操作跟 merge 相比有一些不同:
- 关于解决完成冲突:rebase 解决完后是执行
git rebase --continue,而 merge 解决完后是执行 commit
(5)merge vs rebase
关于二者冲突的相同和不同,看上面一节。这里不提了。
① 相同点
- merge 和 rebase 的最终结果没有任何区别。
② 不同点

见上图:
执行命令的所在分支不一样。merge 是在目标分支执行命令,rebase 是在原有分支执行命令(前者拉过来,后者推过去)
在三方合并上,是否生成新的提交对象(即合并提交)。merge 会产生新的提交对象,而 rebase 只会把自己原有的提交对象移过去,而不是生成新的。
在三方合并上,分支指针的变化不同。看上图。所以 merge 一般完成后不需要再移动分支指针,而 rebase 后,一般需要手动再移动下目标分支的指针(用 merge or rebase)。
产生的提交历史不同。merge 的提交历史不变,提交树保持分叉,而 rebase 会修改提交历史,提交树改造成一条直线。
注意:改造提交历史有风险。
五、标签
1、适用场景
- 发布结点( 譬如版本号:v1.0、v2.0 )
2、分类与创建
(1)轻量标签(lightweight)
① 原理
轻量标签只是一个指针,永远指向一个提交对象(不可移动)。
注意“通常”二字,实际上标签对象可以指向任何 git 对象。
② 创建
git tag v1.4-lw
(2)附注标签(annotated)
① 原理
若要创建一个附注标签,Git 会先创建一个标签对象,然后记录一个引用来指向该标签对象,而不是(像轻量标签一样)直接指向提交对象。
所以 附注标签 跟 轻量标签 的结果都是引用,但前者中间隔了一个标签对象。
② 标签对象的内容
标签对象很像提交对象,本身带有元信息,包括:
- Tagger
- Date
- 标签信息
③ 创建
git tag -a v1.4 -m "my version 1.4"
(3)轻量标签 vs 附注标签
相同:
- 创建后,都不可以轻易移动
不同:
- 创建原理不同(具体看上面附注标签的原理)
- 后者比前者多了一些关于标签的元信息
3、查看标签
(1)列表
注:
- 默认情况下,标签不是按时间顺序列出,而是按字母排序的。
① 本地
git tag
# 想要通配符匹配可以带上 -l / --list
git tag -l "v1.8.5*"
② 远程
git ls-remote --tags origin
(2)具体
git show <tagname>
4、跟远程交互(共享标签)
① 拉
git fetch、git pull、git clone 会默认拉取所有标签到本地仓库。
# 拉取所有标签
git pull origin --tags
② 推
git push 默认并不会传送标签到远程仓库。
那么如何推送标签呢:
# 单独推送一个标签
git push origin <tagname>。
# 推送所有标签(把所有不在远程仓库上的标签全部传送到那里)
git push origin --tags
5、删除标签
① 针对本地
git tag -d <tagname>
② 针对远程
git push origin -d <tagname>
6、检出标签
git checkout <tag-name>
六、Git 内部原理
1、Git 的底层命令和上层命令
“底层(plumbing)”命令:这些命令被设计成能以 UNIX 命令行的风格连接在一起,抑或藉由脚本调用,来完成工作。“上层(porcelain)”命令:对用户更友好的命令。

本文介绍的几乎大多都是上层命令。
2、.git 目录
① 介绍
.git 目录包含了几乎所有 Git 存储和操作的东西。
如若想备份或复制一个版本库,只需把这个目录拷贝至另一处即可。
② 内容
新初始化的 .git 目录的典型结构如下:
config
description
HEAD
hooks/
info/
objects/
refs/
重要的:
- HEAD 文件:指向目前被检出的分支
- index 文件(尚待创建):保存暂存区信息
- objects 目录:存储所有数据内容
- refs 目录:存储指向数据(分支、远程仓库和标签等)的提交对象的指针
次要的:
- description 文件:仅供 GitWeb 程序使用,我们无需关心。
- config 文件:包含项目特有的配置选项
- info 目录:包含一个全局性排除(global exclude)文件, 用以放置那些不希望被记录在 .gitignore 文件中的忽略模式(ignored patterns)
- hooks 目录:包含客户端或服务端的钩子脚本(hook scripts)
3、Git 对象
(1)介绍
Git 对象位于 .git/objects 目录下。
(2)分类
1、
数据对象(blob object):保存着文件快照。2、
树对象(tree object):记录着目录结构和数据对象的索引。
树对象将多个文件组织到一起,有点像 UNIX 的文件管理。
实际上树对象属于
默克尔树(Merkle Tree),优势是可以快速判断变化。
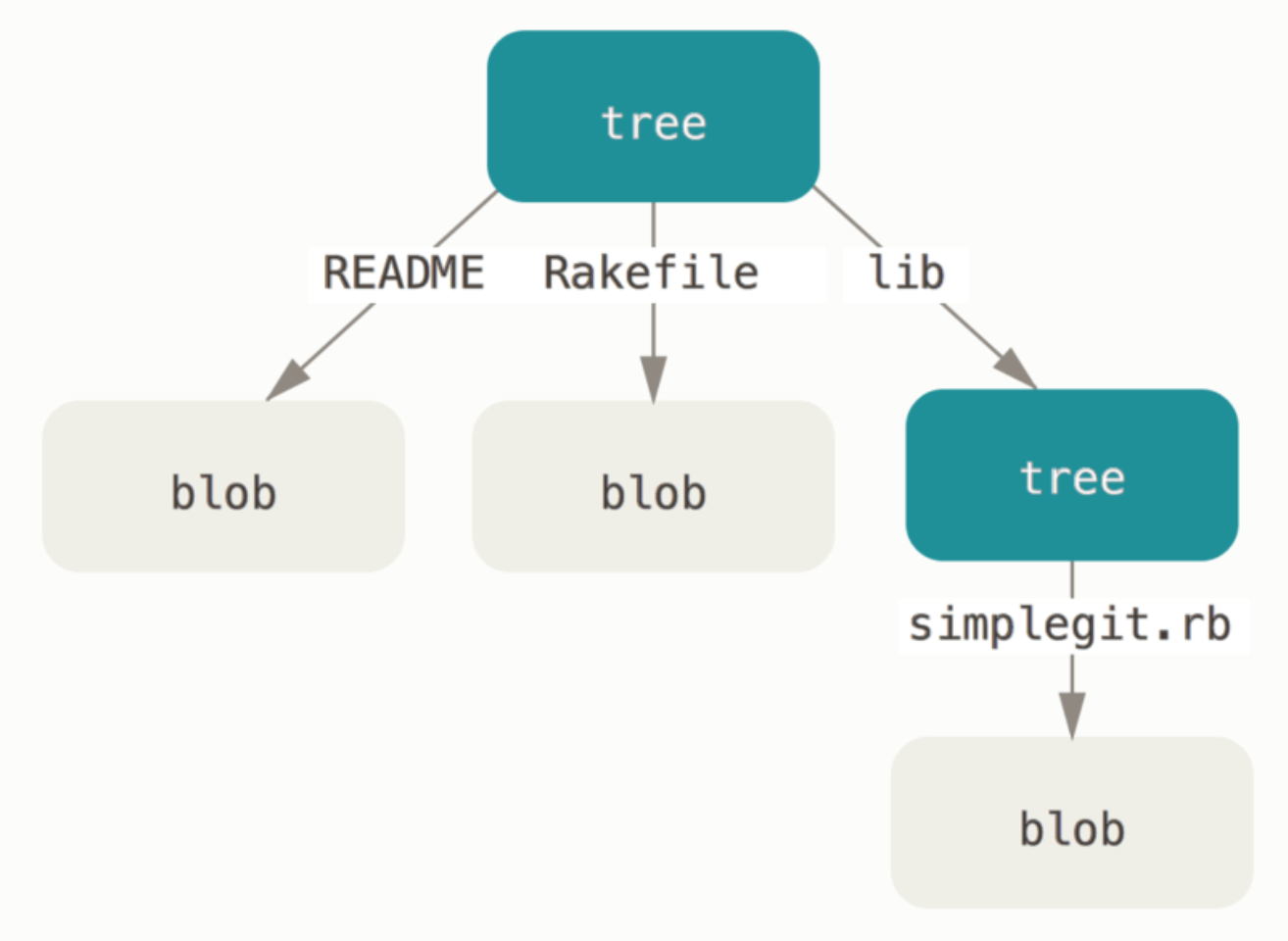
注意:数据对象并不存文件名,而是放在树对象里存储。
- 3、
提交对象(commit object):包含着指向树对象的指针,指向父提交对象的指针,和提交的元信息。
注意:其中提交对象的指向父对象的指针:首次提交没有,普通提交有一个,多个分支合并有多个。
- 4、其他对象
譬如标签对象(只针对附注标签)等……
(3)对象之间的关系
1、首次提交:
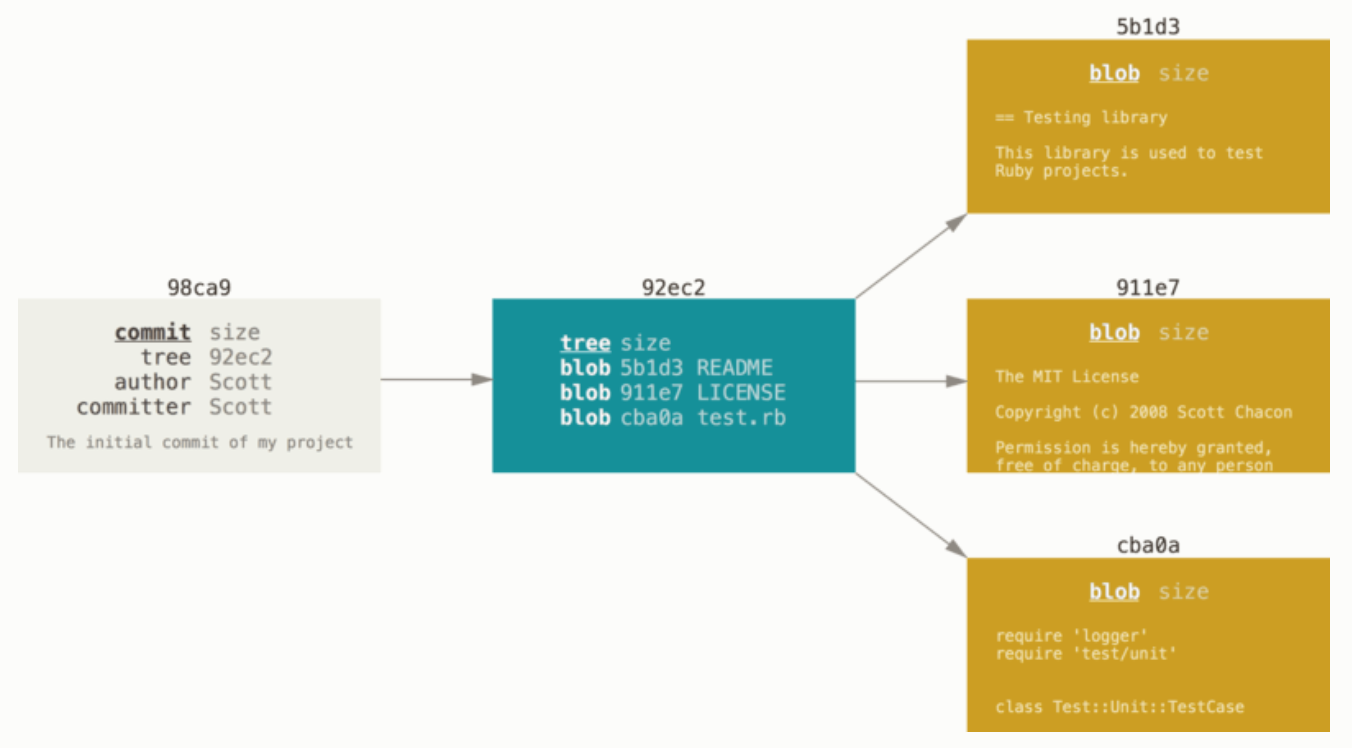
2、多次提交:
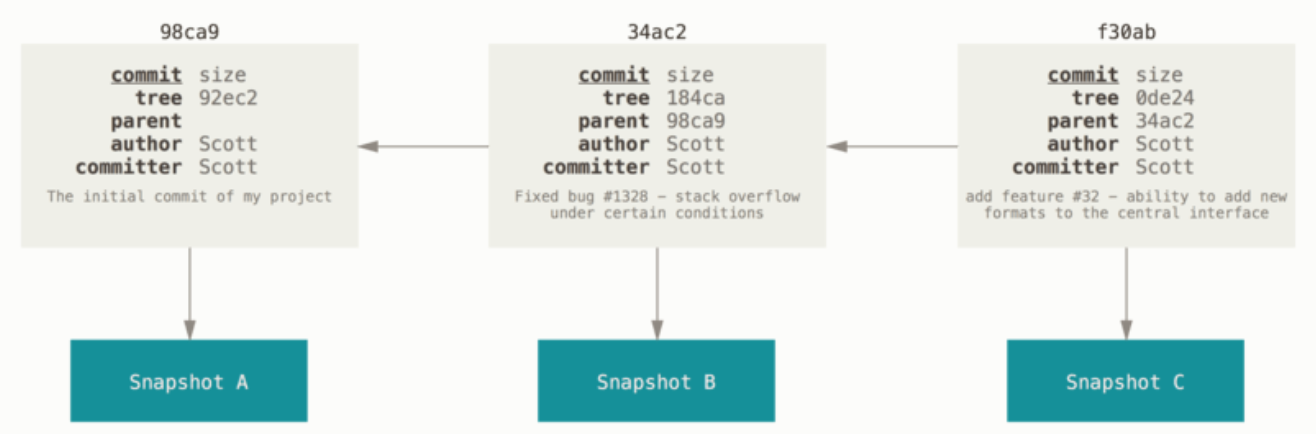
3、多次提交下,数据对象可以重用:

(4)对象的创建
- 数据对象:git add 时创建
- 树对象 + 提交对象:git commit 时创建
注:
- 每个数据对象一旦创建是不可变的,如果文件修改了,那会创造一个新的数据对象。
- 每个commit都是git仓库的一个
快照。
(5)查看对象
① 查看所有对象 - git count-objects -v
输出结果
count: 22
size: 88
in-pack: 12
packs: 1
size-pack: 4
prune-packable: 0
garbage: 0
size-garbage: 0
- count 代表对象的个数
- size 是对象们占用的空间(单位 KB)
② 查看具体对象
git show
(6)对象的清理
① 底层命令
略
② 高级命令
略
③ gc
手动执行 git gc,可以清理一些无用的对象。
git gc 还有其他功能(下面都会提到):
- 打包对象
- 清理 reflog 无用的记录
(7)对象的打包 —— 包文件
① 包文件介绍
- Git 最初向磁盘中存储对象时所使用的格式被称为
“松散(loose)”对象格式,会使用 zlib 压缩。 - 但是,Git 会时不时地将多个这些对象打包成一个称为“
包文件(packfile)”的二进制文件,以节省空间和提高效率。
② 打包原理
- 查找命名及大小相近的文件打包
- 只保存文件不同版本之间的差异内容(有可能第二个版本完整保存了文件内容,而原始的版本反而是以差异方式保存的——这是因为大部分情况下需要快速访问文件的最新版本)
③ 触发打包的条件
- 有太多的松散对象(如7000 个以上)
- 有太多的包文件(50 个包文件以上)
- 手动执行 git gc 命令
- git push 时
- ……
(8)从 Git 对象 窥视 Git 的实质
还记得在文章开头我们说过 git 是版本控制(Revision control)的软件,但这一章了解了 git 的底层原理,可以发现,从根本上来讲 Git 是一个内容寻址(content-addressable)文件系统,并在此之上提供了一个版本控制系统的用户界面。
这个内容寻址文件系统的核心部分是一个简单的键值对数据库(key-value data store)。 你可以用底层命令向 Git 仓库中插入任意类型的内容,它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容。而 Git 对象,正是这样存进去的。
4、Git 对象的 id 与 引用
(1)对象的 id
上面我们说到 Git 对象的本质是存储在键值对数据库里的,那存入的过程中一定会分配 key(即 id)。
① 提交对象的 id
1、介绍
commit id 即提交对象的id(唯一标识),用 SHA-1 表示。
SHA-1 摘要长度是 20 字节,也就是 160 位。出现重复的概率极低,为 2^80,是 1.2 x 10^24,也就是一亿亿亿。
而 SVN 是递增的整数。
2、表示 commit id 的方法
方法一:直接写全 commit id
如:ca82a6dff817ec66f44342007202690a93763949
方法二:只写 SHA-1 的前几个字符
如:ca82a6
注:
- 不得少于 4 个
- 不能有歧义,否则需要加多字符
例如,到 2019 年 2 月为止,Linux 内核这个相当大的 Git 项目, 其对象数据库中有超过 875,000 个提交,包含七百万个对象,也只需要前 12 个字符就能保证唯一性。
建议:通常用 8 到 10 个字符即可。
[拓展] git log --abbrev-commit 可以在 log 打印中把 commit id 的位数缩短。
② 其他的对象 id
略
(2)引用是什么
① 介绍
引用位于 .git 下的 .git/refs 目录。
如果我们有一个文件来保存对象的 id 值,而该文件有一个简单的名字,然后用这个名字来替代原始的难记的 id 值会更加简单。
在 Git 中,这种简单的名字被称为“引用(references,或简写为 refs)”。
② 引用 vs 指针
可以发现引用很像 c 语言里指针的概念。
可以形象的说,引用是指向 Git对象 的指针。
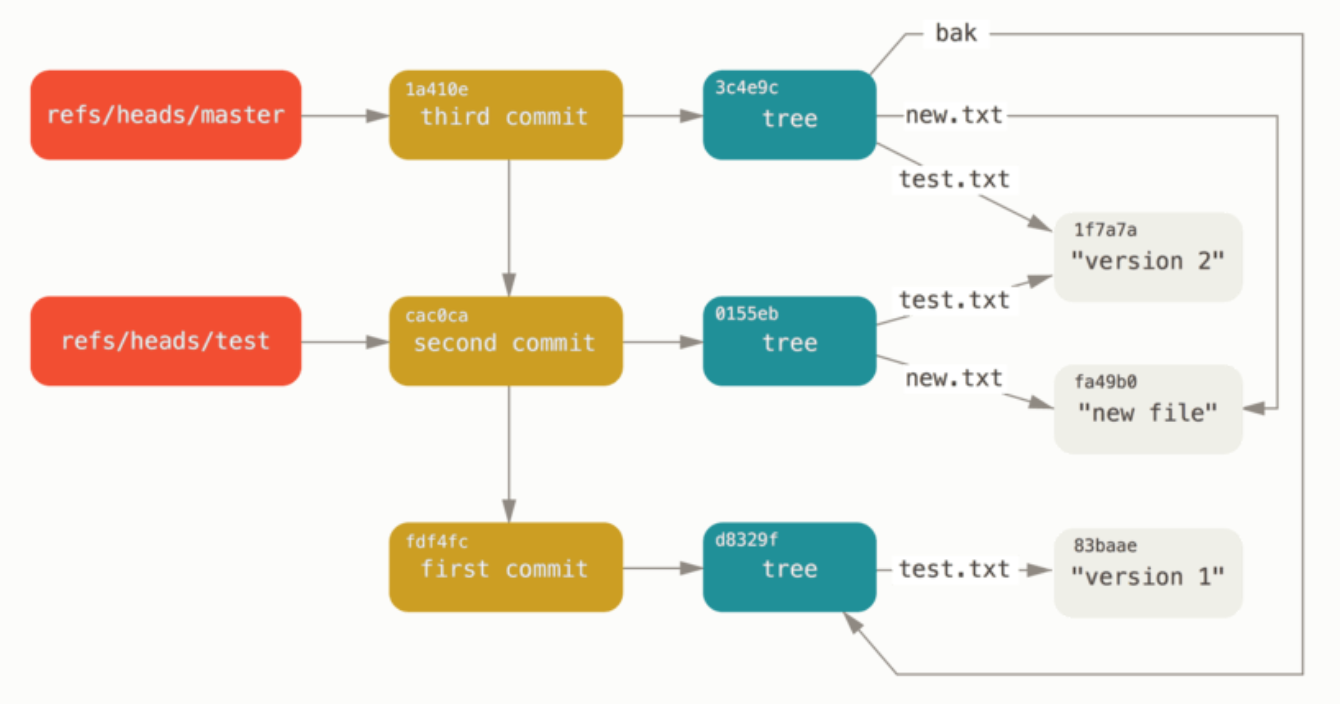
注:本文会把
指针和引用混淆使用,其实指的是一个意思。(但具体有什么细微的差别,我尝试 google 未果,于是在原书的 github 上发了问( https://github.com/progit/progit2/issues/1460 ),暂且无人回复,此处等待,待写。)
(3)引用 之 分支引用
位于:refs/heads 目录下。
① 使用
git show topic1 表示该分支顶端的提交(下同)。
② 反推
git rev-parse topic1 获取 commit id
(4)引用 之 标签引用
位于:refs/tags 目录下。
① 使用 + ② 反推 跟上面的分支一样,略。
本身标签跟分支就很类似。
(5)引用 之 远程引用
位于:refs/remotes 目录下。
① 使用
git show origin/master
② 反推
git rev-parse origin/master 获取 commit id
这个值 commit id 跟远程仓库对应的是一样的
(6)符号引用是什么
所谓符号引用(symbolic reference),表示它是一个指向引用的引用。
套娃
(7)符号引用 之 HEAD 引用
① 介绍
之前我们在 分支 一章介绍过 HEAD,说他是指向分支引用,代表了当前分支是哪一个。
其实 HEAD 不光可以指向分支引用,(从上面的符号引用的定义来看),HEAD 可以指向任何引用。
② HEAD 的创建
在你 init、clone 等命令来初始化项目的时候,HEAD 就会自动创建。
HEAD 无法删除。
③ HEAD 的移动
1、自动移动
- git commit 后,HEAD 前进
- git reset 后,HEAD 后退
- ……
2、手动移动
使用 checkout 命令。有如下情况:
- checkout 到具体提交对象时,HEAD 指向该提交对象(直接指向该提交)
- checkout 本地分支(包含跟踪分支)时,HEAD 指向该分支引用(间接指向该分支顶端的提交)
- checkout 标签时,HEAD 指向该标签引用(直接指向该标签引用对应的提交)
注意,这里容易理解成是间接。实际上这时 HEAD 跟标签引用是并行的指向提交对象的(不管是轻量标签还是附注标签)。
- checkout 远程跟踪分支时,HEAD 指向该远程引用(直接指向该远程跟踪引用对应的提交)
注意,这个只适用于这个远程跟踪分支没有被本地追踪。
上面的 ”直接“/”间接“ 中的 ”直接“,代表了处于 分离头指针 的状态。
[拓展] 分离头指针 detached HEAD【重点】
1、介绍
(根据上面的介绍)只有 checkout 不在 本地分支(包含跟踪分支)。 才会出现这种情况。
2、风险
拿 commit 举例。
这时候你正常的 commit 是可以的,但是这个新提交将不属于任何分支,会造成:
- 无法访问(通过 git log 无法查到,除非记得当初它的commit id 才能看到。)
- 随时有被删除的可能( git 会认为这是个没用的提交,可能在 gc 的时候删掉 )
如果你真的需要在分离头指针状态下 commit(例如你想基于这个标签的版本修复某个 bug),那么可以在此标签的基础上创建一个新分支。
④ 反推
git symbolic-ref HEAD 获取引用 name(如 refs/heads/master)
要想进一步获取引用指向的 commit id,可以再执行:
git rev-parse refs/heads/master
(8)祖先引用
① 介绍
引用(符号引用)除了可以表示自身,还能搭配 ^ 和 ~ 来进行祖先引用。
② 使用
下面以 HEAD 为例。
1、~ 表示父提交
# 父提交
git show HEAD~
# 父提交的父提交(祖父提交)
git show HEAD~~
# 父提交的父提交的父提交(以此类推)
git show HEAD~3
=
git show HEAD~~~
2、^ 表示当前分支/另一个分支下的父提交
# 当前分支
git show HEAD^
=
git show HEAD^1
# 另一个分支(在没有另一个分支的情况下(非合并提交),会失败)
git show HEAD^2
注意:HEAD^3 及其以上,略。
因为貌似 git 只支持两个分支的合并(即提交对象不会有超过两个的直接父提交),两个分支以上的合并也是基于多步骤的两两合并来的【待求证】
见下图(当 HEAD 位于不同地方):
3、^ 和 ~ 的联系
HEAD^=HEAD~- 可以组合使用
^和~(例如 HEAD~3^2、HEAD^2~3)
(9)引用日志 - git reflog
① 原理
位于 .git/logs/。
每当你的 HEAD 所指向的位置发生了变化,Git 就会将这个信息存储到引用日志这个历史记录里。
注意:引用日志只存在于本地仓库,当你从远程仓库 clone、fetch / pull、push 时,不会涉及引用日志。
② 使用
1、查看列表
git reflog
包括这些记录:
clone
checkout
commit
reset
discard
merge
rebase
等等……
输出示例:
8bd49ac HEAD@{0}: checkout: moving from third to 8bd49ac75fe6fdf0cf5aa66561ed123acb5095cb
43151e5 HEAD@{1}: checkout: moving from a6bbabe31540ca2cb4d2c3ce925e8a26616de4d1 to third
a6bbabe HEAD@{2}: commit: 222
8bd49ac HEAD@{3}: checkout: moving from c43433e2bce4b03d79367553a21dad75ddb78d6c to c43433e2bce4b03d79367553a21dad75ddb78d6c
2、查看具体
使用 @{n} 来引用 reflog 中输出的提交记录。
@{n} 有点类似 HEAD 结合 ^ 和 ~ 的用法,只是前者基于 ref(HEAD)历史,后者基于提交历史。
# 当前
$ git show HEAD@{0}
# 五次前
$ git show HEAD@{5}
③ 适用场景
- 恢复、撤销之前的操作【重点】
例如:撤销之前删除的 commit,可以用 reflog 找到 对应的 commit id,然后用
git reset --hard <commit-id>orgit branch recover-branch <commit-id>等操作创建新分支。
[拓展] 如果 reflog 也没有之前删掉的 commit 记录怎么办?
比如你的 reflog 记录被清了(比如 gc),那可以用 git fsck --full。
git fsck命令用来检查数据库的完整性。
输出示例:
Checking object directories: 100% (256/256), done.
Checking objects: 100% (18/18), done.
dangling blob d670460b4b4aece5915caf5c68d12f560a9fe3e4
dangling commit ab1afef80fac8e34258ff41fc1b867c702daa24b
dangling tree aea790b9a58f6cf6f2804eeac9f0abbe9631e4c9
dangling blob 7108f7ecb345ee9d0084193f147cdad4d2998293
dangling commit 后的 SHA-1 就是你要你找的 commit id,恢复办法参考 reflog 一样即可。
④ git reflog vs git log
相同点:
- git reflog 命令绝大多数使用方法跟 git log 一样(可参考)。
不同点:
- git reflog 比 git log 相比信息更丰富,可以看到所有操作记录。
从这点看,git log 是 git reflog 的子集。
联系:
- 可以运行
git log -g,查看 log 形式信息的 reflog 内容。注意:只是形式是 log ,而内容不是 log。即 git log -g 条目结果不等于 git log,而等于 git reflog。
5、替换对象
① 功能
replace 命令可以让你在 Git 中指定 某个对象 并告诉 Git:“每次遇到这个 Git 对象时,假装它是 其它对象”。
② 适用场景
在你用一个不同的提交替换历史中的一个提交而不想以 git filter-branch 之类的方式重建完整的历史时,这会非常有用。
③ 使用
略
七、关于提交对象和提交历史
1、选择提交区间
提交区间(即一个或多个提交对象),是基于分支的操作。(即使你传的不是分支名,而是别的引用,那 git 也会把它当成的假设在这个引用上创建的某分支来看待。)
下面的例子都默认为分支名
(1)双点
① 使用
git log A..B
② 原理
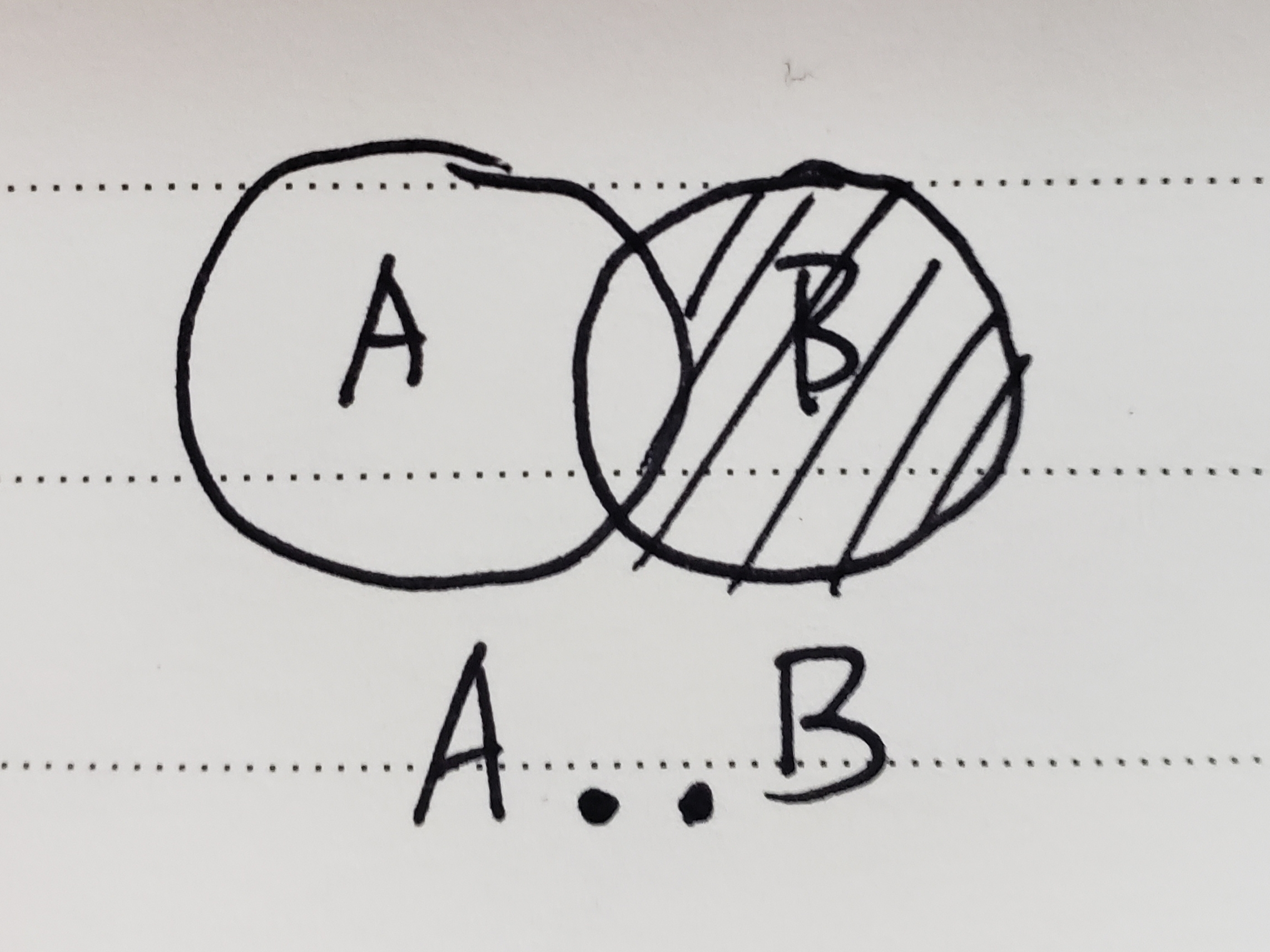
③ 适用场景
查看 B 分支中还有哪些提交尚未被合并入 A 分支。(譬如,想查看在 experiment 分支中而不在 master 分支中的提交,你可以使用
git log master..experiment。)查看即将 git push 的内容。(
git log origin/master..HEAD)注意:
git log origin/master..HEAD=git log origin/master..,如果你留空了其中的一边, Git 会默认为 HEAD。
(2)多点
① 两点是多点的特殊情况/简写形式:
$ git log refA..refB
=
$ git log refB ^refA
=
$ git log refB --not refA
② 使用
多点就是可以写多个,省略两点的同时,搭配 ^ 和 --not。
git log A B ^C
git log A B --not C
③ 原理
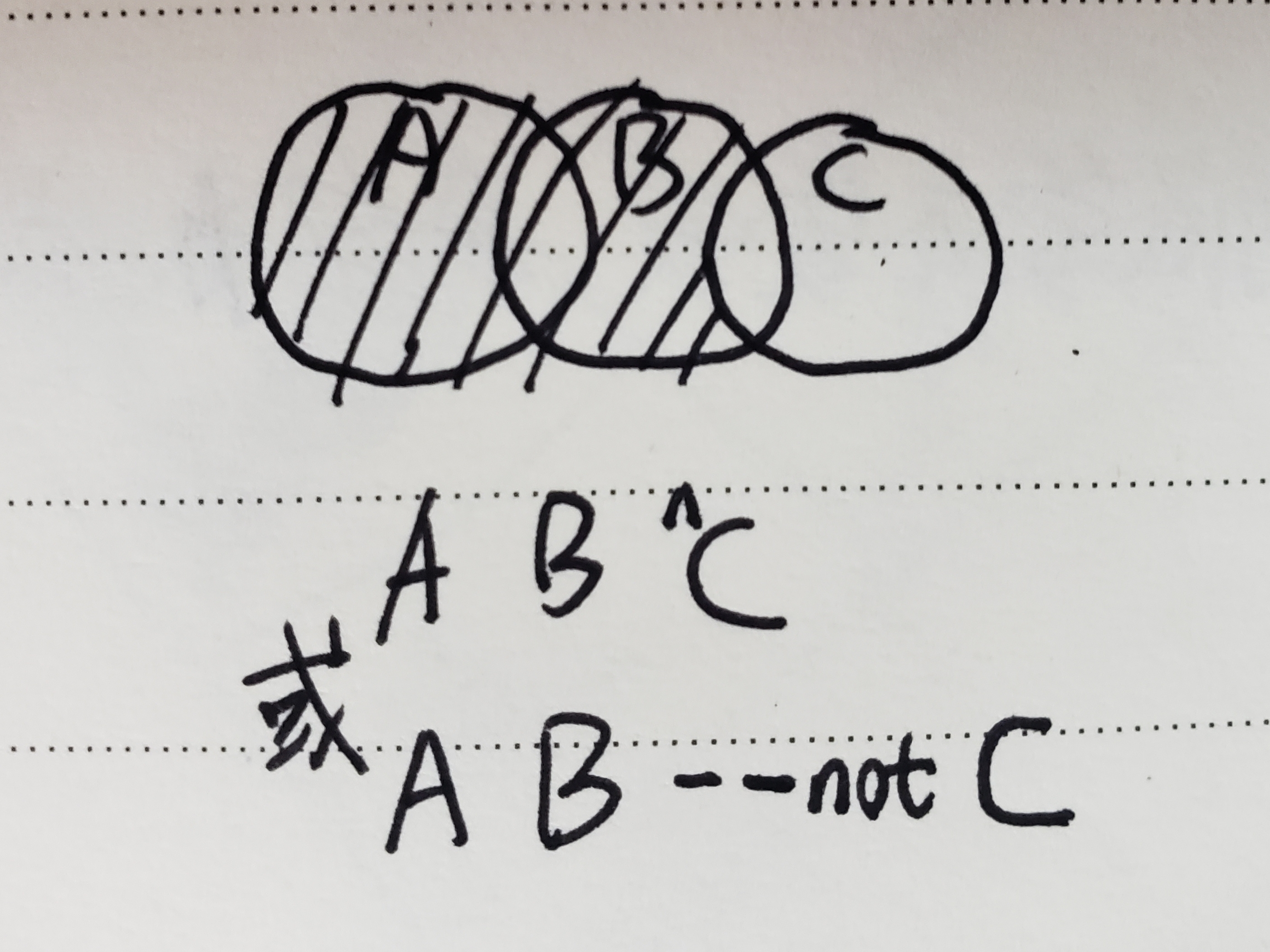
④ 适用场景
- 弥补 双点 不能基于两个以上分支选取的限制。
实例:查看所有被 refA 或 refB 包含的但是不被 refC 包含的提交
$ git log refA refB ^refC
=
$ git log refA refB --not refC
(3)三点
① 介绍
git log A...B
② 原理
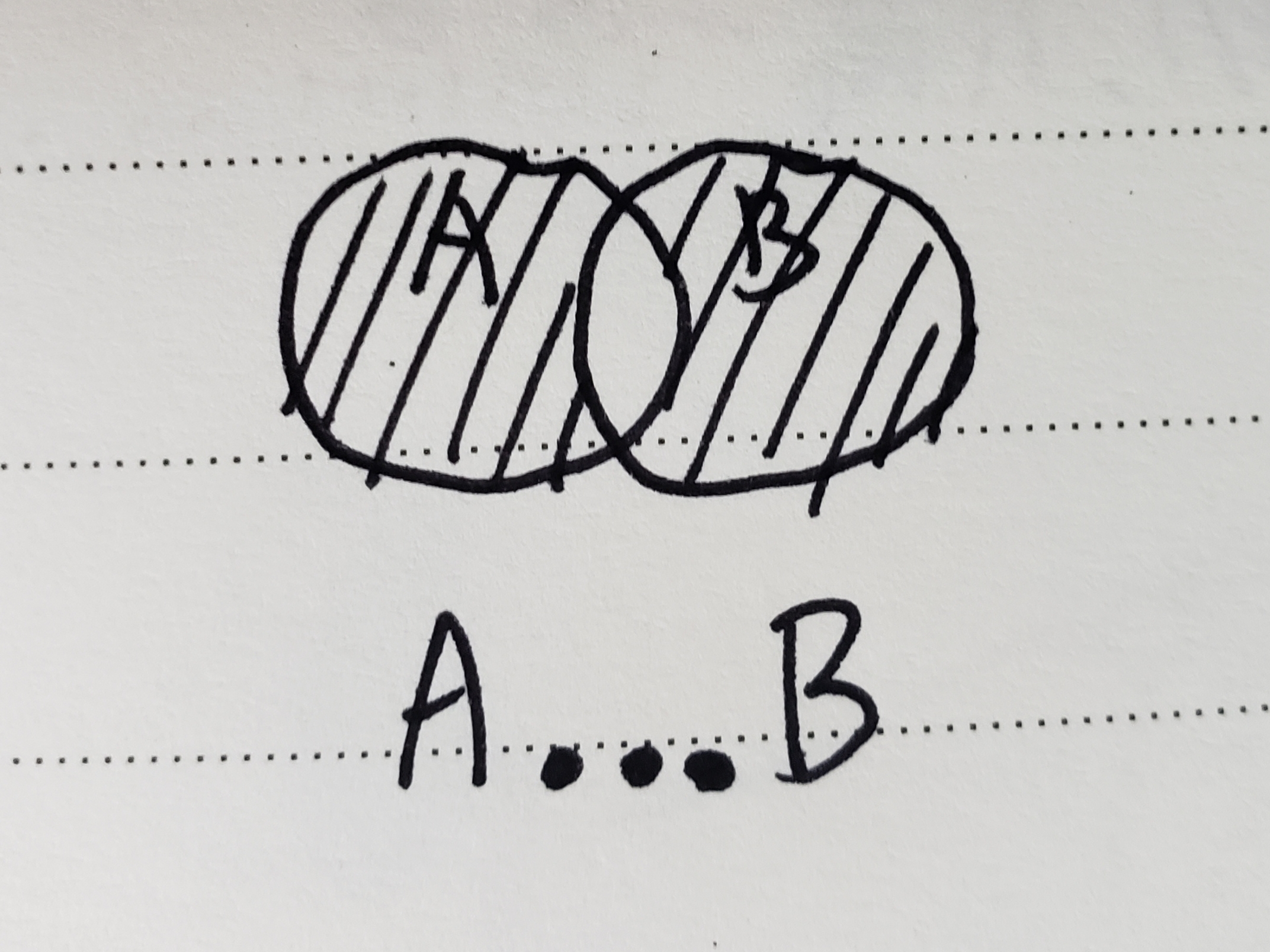
③ 适用场景
- 选出被两个引用之一包含但又不被两者同时包含的提交。(譬如
git log master...experiment) - 解决冲突的时候,回溯源头可以用到。
[拓展]
三点语法 跟 git log 的参数 --left-right 结合,可以显示提交是来源哪一边分支的。
$ git log --left-right master...experiment
< F
< E
> D
> C
2、重置揭密
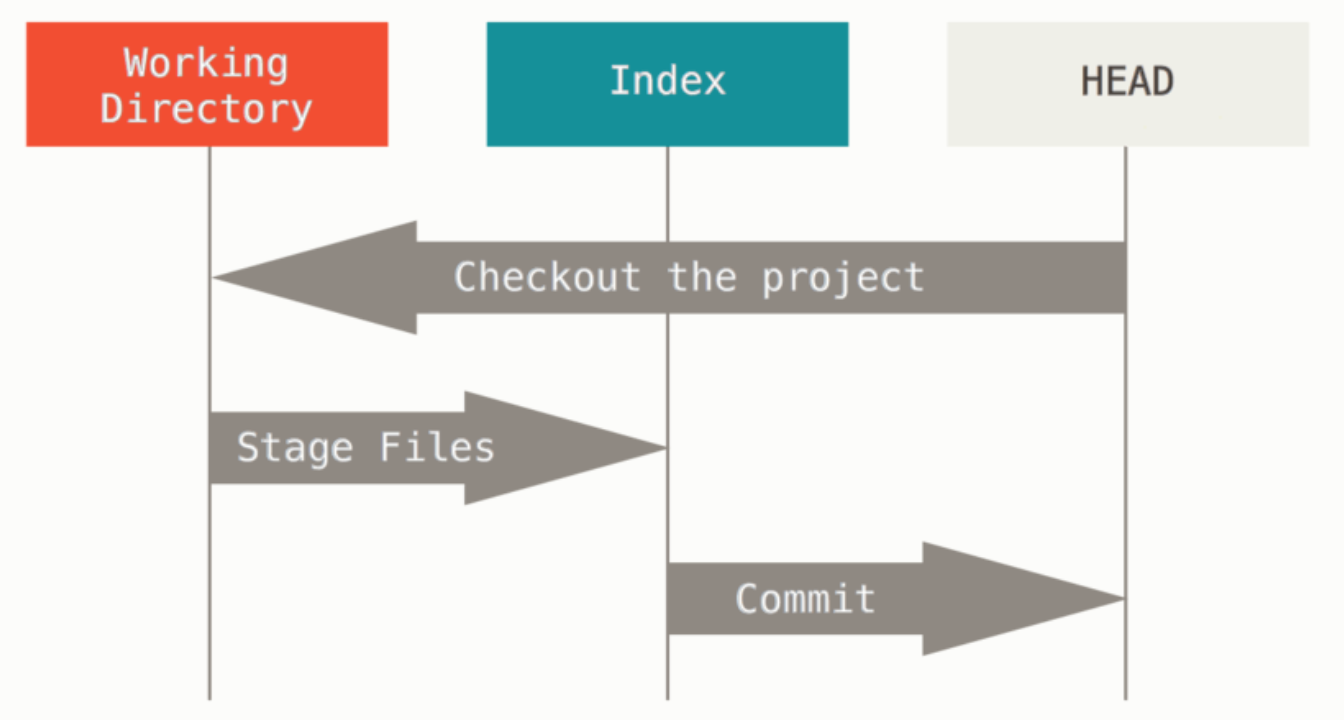
(1)Git 的三棵树
“树” 在我们这里的实际意思是“文件的集合”,而不是指特定的数据结构。
- 这里的树也只是个形象的比喻。
Git 作为一个系统,管理并操纵这三棵树:
| 树 | 用途 |
|---|---|
| HEAD | 上一次提交的快照,下一次提交的父结点 |
| Index | 预期的下一次提交的快照 |
| Directory | 沙盒 |
注:
- git 的 Index(索引),也称”暂存区“。本文两者混用。
三棵树相互关系:
(2)reset
① 无路径重置
1、参数
初始状态:

git reset --soft HEAD^:
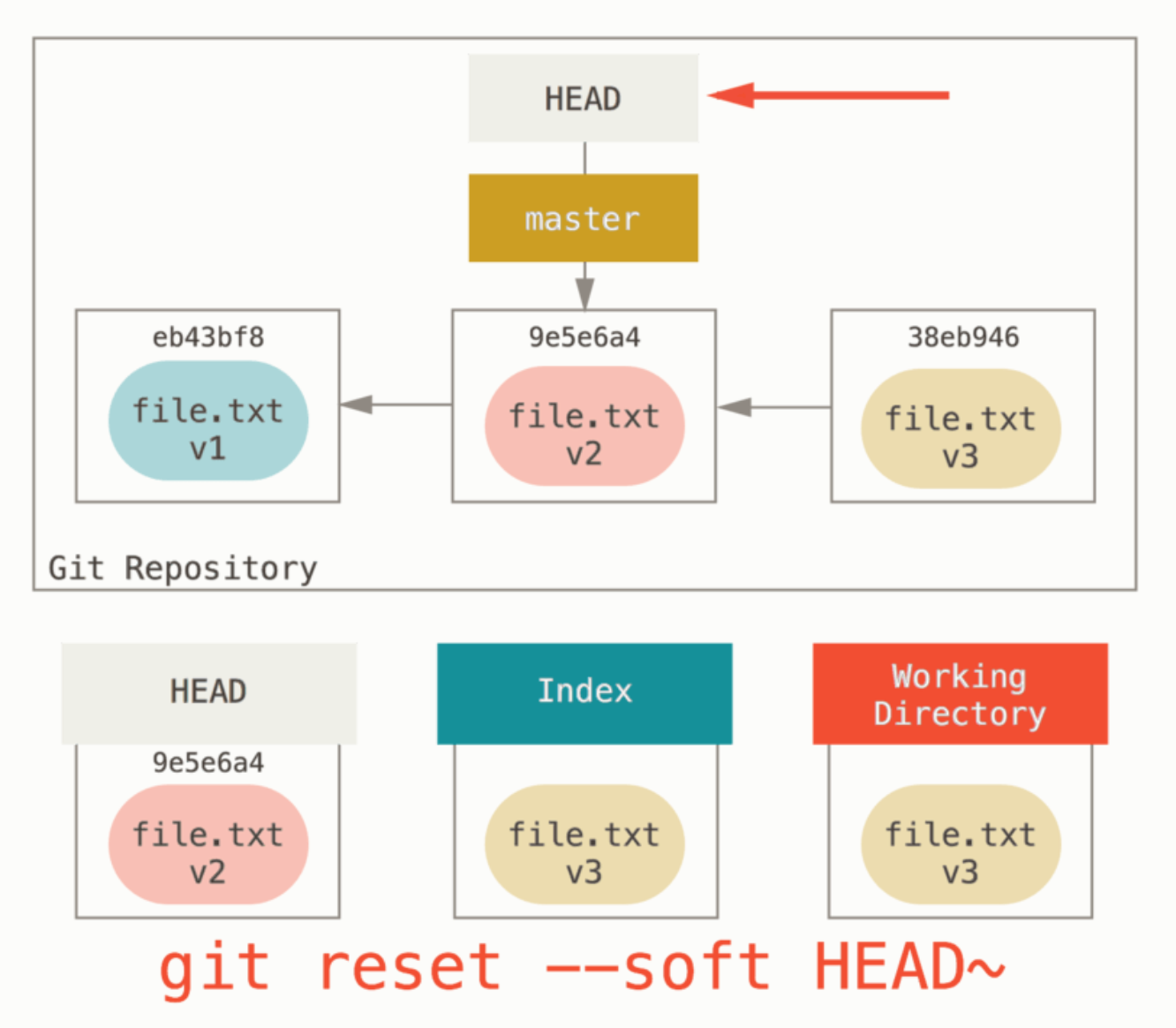
git reset [--mixed] HEAD^:
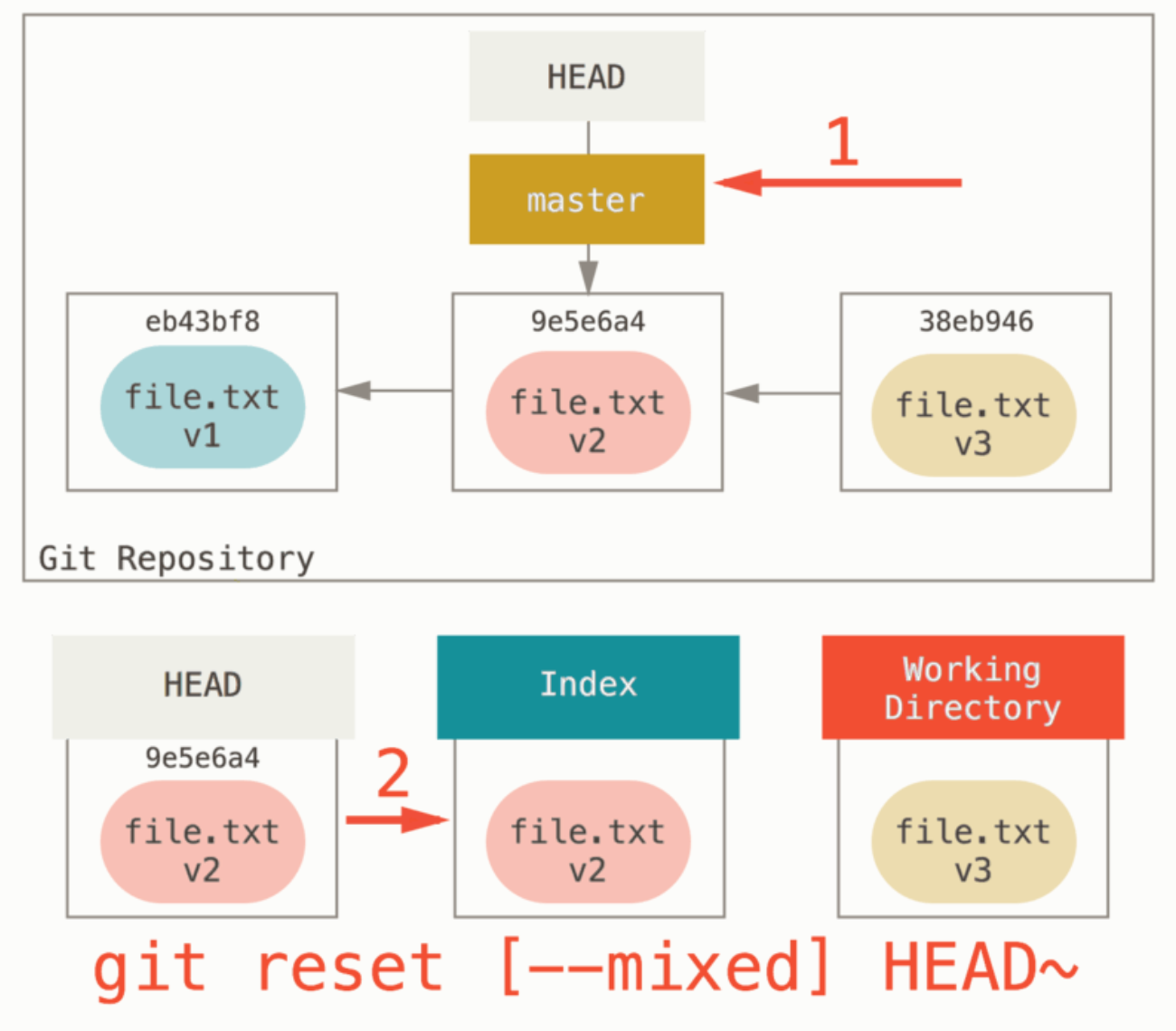
git reset --hard HEAD^:
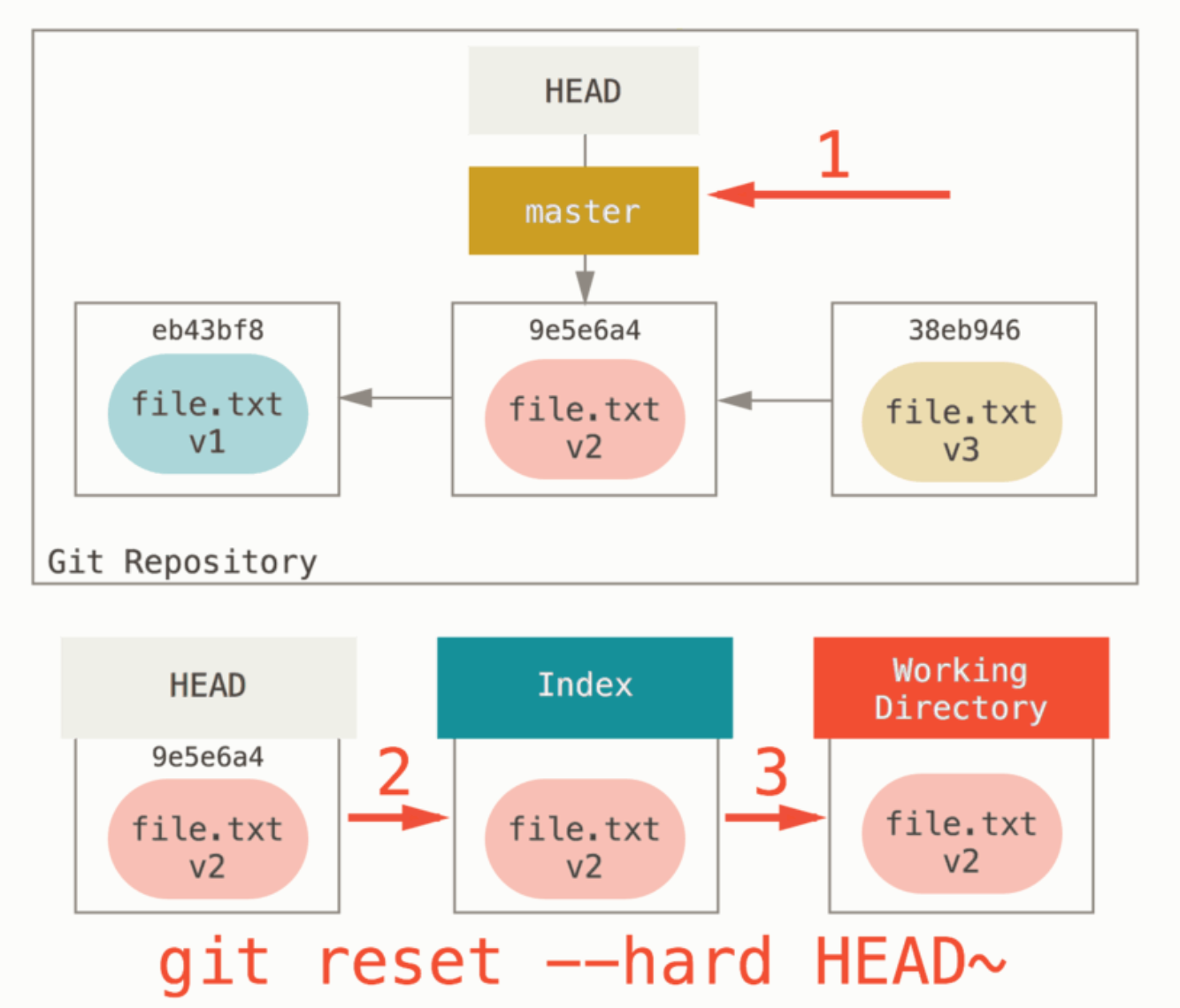
注:
- 执行此操作最好还是保持工作区和暂存区的清空(比如 stash 下),避免一些意外情况的发生。
- 注意写法:
git reset --hard HEAD^是对的,git reset HEAD^ --hard是错的(坑的是这样也是可以运行的,等于 --mixed) - --hard 是 reset 命令唯一的危险用法,它也是 Git 会真正地销毁数据的仅有的几个操作之一。(用的时候一定要小心)
2、原理步骤
步骤(1):移动 HEAD 指针,带着分支指针一起(若指定了 --soft,则到此停止)
结果:
- 之前 commit 的改动:打回暂存区(相当于逆操作 git commit)
- 现有改动【跟之前 commit 的改动不重叠】:暂存区和工作区不受影响;
- 现有改动【跟之前 commit 的改动重叠】:仅暂存区会自动合并文件的修改,工作区不受影响;
步骤(2):使索引看起来像 HEAD (若指定 --mixed 或 缺省,则到此停止)
结果:
- 之前 commit 的改动:打回工作区(相当于逆操作 git commit + git add)
- 现有改动【跟之前 commit 的改动不重叠】:工作区不受影响,暂存区会被打回工作区(相当于逆操作 git add)
- 现有改动【跟之前 commit 的改动重叠】:工作区+暂存区会一起自动合并文件的修改,最后落在工作区
步骤(3):使工作目录看起来像索引(若指定 --hard,则到此停止)
结果:
- 之前 commit 的改动:删除
如果针对的是
HEAD(即当前提交),那 “之前 commit 的改动” 是没有意义的,可以忽略。 - 现有改动:暂存区和工作区全部删除
这里讨论 “跟之前 commit 的改动重不重叠” 是没有意义的。
注:
- 其实删除可以理解成从工作区再往后打回,但是没有退路了,就等于删除了。
3、适用场景
(1)作用于“之前 commit 的改动”
主要是针对 HEAD~ 甚至更早的版本:
- 回退版本(常用):git reset --hard HEAD~
- 压缩提交:git reset --soft HEAD~2,然后再次运行 git commit
- 拆分提交:git reset HEAD~,然后分多次运行 git add + git commit
(2)作用于“现有改动”
主要是针对 HEAD:
- 把暂存区打回工作区(常用):git reset HEAD
即 git add 的相反操作。
- 清空暂存区和工作区:git reset --hard HEAD
git reset --hard HEAD 跟 git clean 的区别是,前者清除缓存区+工作区,后者只清除工作区。
③ 有路径重置(即针对具体文件)
1、参数
git reset file.txt
=
git reset -- file.txt
2、原理【重点】
git reset file.txt 约等于 git reset --mixed HEAD + 指定文件
为什么说约等于,具体区别看下面的介绍。
3、跟 ”无路径重置“ 的区别【重点】
区别(1):原理步骤
- 步骤1,不同。git reset file.txt 不会移动 HEAD 指针,更不会移动分支指针
- 步骤2,相同。
- 步骤3,没有。(因为 git reset file.txt 相当于 --mixed ,而不是 --hard,自然不会执行到步骤3)
区别(2):适用场景
git 把 git reset file.txt 的参数给限制死了:
- **只能是 HEAD 而不能是 HEAD~ 等其它
- 只能是 --mixed 而不能是 --hard 和 --soft 等其它
目的就是为了实现”无路径重置“适用场景中唯一的一个,即 “把暂存区打回工作区”
(3)checkout
前面介绍 “符号引用之 HEAD 引用”,也提到了 checkout 的用法,可去参考。
① 无路径重置
1、用法
git checkout [branch]git checkout [其它引用]
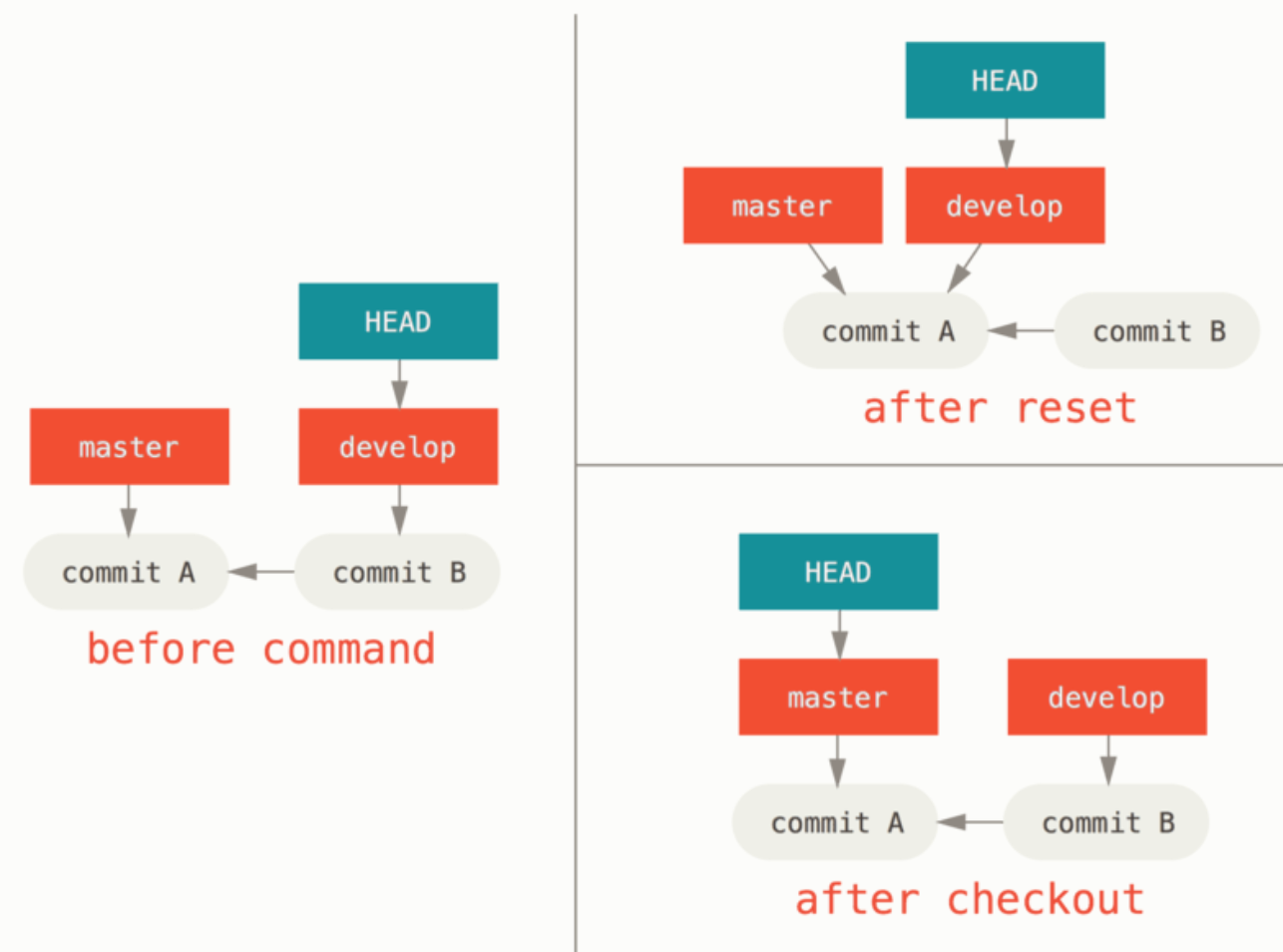
2、原理步骤
步骤:
仅移动 HEAD 指针。
而 reset 会移动 HEAD + 分支的指向
结果:
- 之前 commit 的改动:删除
这一点像 git reset --hard
- 现有改动【跟之前 commit 的改动不重叠】:暂存区和工作区不受影响;
这一点像 git reset --soft
- 现有改动【跟之前 commit 的改动重叠】:git 会 Aborting 并提醒你 commit or stash
这一点即不像 git reset --hard 那样自动删除,也不像 git reset --soft 那样自动合并。可以说非常的安全。
② 有路径重置
1、用法
git checkout file
=
git checkout -- file
=
git checkout HEAD -- file
2、原理步骤
git checkout file.txt vs git checkout(无路径) 的区别:
区别(1)原理步骤
- 不会移动 HEAD 指针,更不会移动分支指针
区别(2)结果 与 适用场景
这里就不把 checkout 有路径 跟 上面提到的 reset 无路径/有路径 和 checkout 无路径 做对比了,这会让事情变的更复杂。就直接看下面的叙述就好,简单直接。
把某个文件恢复到某个提交的样子,如果你在暂存区或者工作区对这个文件有改动,则:
- 改动会被丢失(危险)
- 会创建新的改动并自动 add 到暂存区
注:
- 可以看出 git checkout file 跟 git checkout 的差别很大,跟 git reset 和 git reset file 的差别也大。(真的服了这个设计,为了实现功能也不能把命令搞得这么分裂不统一啊…)
(4)reset vs checkout
| HEAD | Index | Workdir | WD Safe? | |
|---|---|---|---|---|
| Commit Level | ||||
reset --soft [commit] |
REF | NO | NO | YES |
reset [commit] |
REF | YES | NO | YES |
reset --hard [commit] |
REF | YES | YES | NO |
checkout <commit> |
HEAD | YES | YES | YES |
| File Level | ||||
reset [commit] <paths> |
NO | YES | NO | YES |
checkout [commit] <paths> |
NO | YES | YES | NO |
- HEAD 一列中的 “REF” 表示该命令移动了 HEAD 指向的分支引用,而 “HEAD” 则表示只移动了 HEAD 自身。
- Index、Workdir 列中的的 “YES”、“NO”,表示“之前 commit 的改动”是否会打回。
- WD Safe? 列,如果它标记为 “NO”,那么运行该命令之前请考虑一下。
(5)reset 和 checkout 对提交历史的影响
- reset:只有 无路径 + HEAD~ 甚至更早的版本 才会对提交历史有影响(影响的结果是提交被删除)
- checkout:不会
3、撤销提交
(1)reset
① 用法
reset + 无路径重置
详细见之前的介绍,不赘述。
(2)rebase
① 用法
使用 rebase 交互式用法
详细见之前的介绍,不赘述。
(3)revert
① 用法
git revert HEAD # 撤销前一次 commit
git revert HEAD^ # 撤销前前一次 commit
注:
- 执行 revert 前工作区和暂存区都得为空(否则 git 会提示并执行不了)
(4)reset vs rebase vs revert
相同:
- 都可以撤销某次(某些)提交
不同:
- reset 和 rebase 是去掉这次提交,revert 是保留这次提交,生成一次新的提交(内容是上一次提交的相反操作)
- reset 最不灵活,只对于撤销紧跟 HEAD 的连续着的 N 次提交比较方便,而 rebase 和 revert 可以针对位于中间的随意某个提交去撤销。
(5)reset 和 rebase 和 revert 对提交历史的影响
- reset 和 rebase 会对提交历史有影响(影响的结果是提交被删除)
- revert 会对提交历史有影响(影响的结果是提交历史又新增了)
4、复制+粘贴 提交
(1)cherry-pick
使用前:
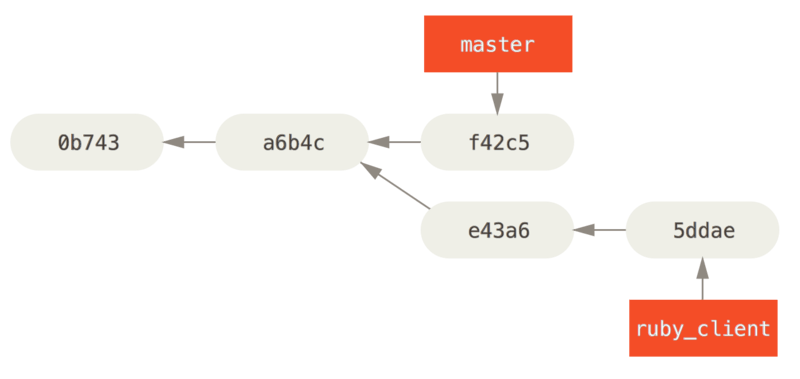
使用:
git cherry-pick e43a6
使用后:
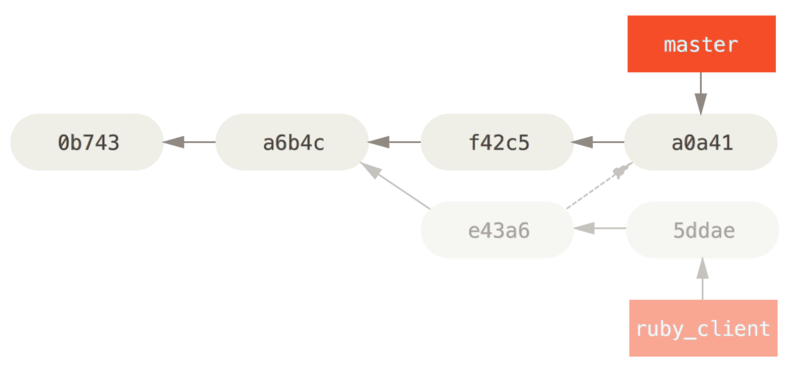
注:
- 执行 cherry-pick 前工作区和暂存区都得为空(否则 git 会提示并执行不了)
- 复制过去的新提交,粘贴的时候,因为应用的日期不同(但其他信息相同),你会得到一个新的 commit id 值。
(2)cherry-pick 对提交历史的影响
- cherry-pick 会对提交历史有影响(影响的结果是提交历史又新增了)
5、修改提交
(1)rebase
rebase 交互式 可以修改提交。
看之前的介绍,不赘述了。
(2)git commit --amend
作用:修改最后一次提交。
git commit --amend
看之前的介绍,不赘述了。
注意:因为提交对象改变了,Git 是有完整性校验的,所以会 commit id 肯定会改变。
(3)filter-branch
作用:批量提交历史改写。
注意:这个命令会修改你的历史中的每一个提交的 commit id。
① 使用建议
- 因为 filter-branch 改变的太多了,建议在一个测试分支中做这件事。
- 为了让 filter-branch 在所有分支上运行,可以给命令传递
--all选项。
② 适用场景
filter-branch 不过多介绍,略,直接说应用。
- 1、删除历史文件
有人粗心地通过 git add,提交了一个巨大的二进制文件,或者一个带密码的私密文件,需要从所有的历史提交记录里删去。
git filter-branch --tree-filter 'rm -f passwords.txt' HEAD
- 2、批量修改邮箱地址
你开始工作时忘记运行 git config 来设置你的名字与邮箱地址,或者你想要开源一个项目并且修改所有你的工作邮箱地址为你的个人邮箱地址。
git filter-branch --commit-filter '
if [ "$GIT_AUTHOR_EMAIL" = "schacon@localhost" ];
then
GIT_AUTHOR_NAME="Scott Chacon";
GIT_AUTHOR_EMAIL="schacon@example.com";
git commit-tree "$@";
else
git commit-tree "$@";
fi' HEAD
(4)rebase、git commit --amend、filter-branch 对提交历史的影响
- rebase 会对提交历史有影响(影响的结果是提交历史删除了)
- git commit --amend 会对提交历史有影响(影响的结果是提交历史删除了)
- filter-branch 会对提交历史有影响(影响的结果是提交历史删除了)
6、改变提交历史的风险
(1)有什么风险
这一章的几乎每一节,最后一块都会讨论 此操作命令 对提交历史的影响,为什么要如此重视,因为提交历史变动的风险很大。
比如你变基操作后,原有分支会的位置会不见(因为原有分支的修改和指针统统都转移到了目标分支),所以如果有别人基于原有的分支的这些提交进行开发,就会出错。
具体会造成什么样的错误,不赘述了。
(2)什么会导致风险
就是上面介绍到的关于修改提交历史的操作,涉及命令:
- reset
- rebase
- git commit --amend
- filter-branch
(3)怎么避免风险
建议在本地操作好后再推送你的工作。
git 也会有相应的保护措施,譬如你在本地变基了已经被推送的提交,继而再 push 到远程,会被拒绝。(如果确信真的没人用,可以加 -f 来强制 push)
(4)既然有风险,干脆不要改变提交历史了?
关于改变提交历史好不好,仁者见仁智者见智:
- 有一种观点认为,提交历史是真实记录实际发生过什么,不要改变它。
- 另一种观点则正好相反,他们认为提交历史是项目过程中发生的事,怎么方便后来的读者观看就怎么写。
所以在保证安全的情况下,根据自己的真实的需要,是可以改变的。
八、Git 工具
1、Git 别名
(1)方法一:git 命令 - 不加!
① 适用场景
git 有些命令太长 or 不好记,你可以自定义别名。
② 原理
简单的替换后执行命令。
③ 示例
# 当要输入 git commit 时,只需要输入 git ci。
git config --global alias.ci commit
# 当要输入 git reset HEAD -- 文件名 时,只需要输入 git unstage 文件名 即可。
git config --global alias.unstage 'reset HEAD --'
(2)方法二:系统命令 - 加!
① 适用场景
然而,你可能想要执行外部命令,而不是一个 Git 子命令,可以在命令前面加入 ! 符号。
② 原理
替换后把开头的 git 去掉,再执行命令。
③ 示例
# 当要输入 ls 路径 时,只需要输入 git visual 路径。
git config --global alias.visual '!ls'
2、调试
适用场景:如果你在追踪代码中的一个 bug,并且想知道是什么时候引入的。
(1)文件标注(当你知道问题出在哪)
① 查看每行的直接来源
1、git blame <filename>
可以看到当前版本的某个文件,每一行分别是:
- 哪个提交
- 哪个作者
2、git blame -L 69,82 <filename>
-L 可以指定行数范围
② 查看每行的间接来源(真正来源)
1、git blame -C -L 141,153 <filename>
-C 会分析你文件中从别的地方复制过来的代码片段的原始出处。
这个功能很有用。通常来说,你会认为复制代码过来的那个提交是最原始的提交,因为那是你第一次在这个文件中修改了这几行。但 Git 会告诉你,你第一次写这几行代码的那个提交才是原始提交,即使这是在另外一个文件里写的。
③ GUI(推荐)
GUI 的 file blame + file history 更直观更好用。
(2)二分查找(当你不知道问题出在哪)
① 基本用法
git bisect 命令会对你的提交历史进行二分查找来帮助你尽快找到是哪一个提交引入了问题。
使用步骤:
- 首先执行
git bisect start来启动 - 接着执行
git bisect bad来告诉系统当前你所在的提交是有问题的 - 然后你必须使用
git bisect good <good_commit>,告诉 bisect 已知的最后一次正常状态是哪次提交。这时譬如 Git 发现在你标记为正常的提交(v1.0)和当前的错误版本之间有大约12次提交,于是 Git 检出中间的那个提交。 - 现在你可以执行测试,看看在这个提交下问题是不是还是存在。然后执行
git bisect goodorgit bisect bad - 当最终找到问题后,你应该执行
git bisect reset重置你的 HEAD 指针到最开始的位置。
② 高级用法
嫌上面的手动太麻烦,可以引入 bash 脚本。
略。
3、打包
(1)适用场景
- 有可能你的网络中断了,但你又希望将你的提交传给你的合作者们(通过邮件或者闪存)。
- 可能你现在没有共享服务器的权限,
- 你又希望通过邮件将更新发送给别人, 却不希望通过 format-patch 的方式传输 40 个提交。
(2)使用
① 打包
# 打包全部
git bundle create repo.bundle HEAD master
# 打包增量(提交区间)
略
具体解释略。
② 解包
跟 clone 一样的操作。
git clone repo.bundle repo
结果:得到跟 clone 一样的结果。
4、归档
(1)适用场景
- 为那些不使用 Git 的人准备。
(2)使用
git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
参数:
- --prefix:在存档中的每个文件名前添加前缀
- --format:指定归档格式,比如 zip
结果:
解压后为项目的最新快照。
注意与”打包“的不同。
九、Git 高级用法
1、子模块
子模块允许你将一个 Git 仓库作为另一个 Git 仓库的子目录。 它能让你将另一个仓库克隆到自己的项目中,同时还保持提交的独立。
略。
十、自定义 GIT
1、Git 配置
第一章 起步 有提到一些。
略。
2、Git 属性
(1)介绍
可以针对特定的路径配置某些设置项,这样 Git 就只对特定的子目录或子文件集运用它们。这些基于路径的设置项被称为 Git 属性。
(2)配置文件
.gitattributes文件(通常是你的项目的根目录)。- 如果不想让这些属性文件与其它文件一同提交,你也可以在
.git/info/attributes文件中进行设置。
具体设置方法略。
(3)应用
① 过滤器 —— 对比 word 文件、图片 等二进制文件
1、原理
使用过滤器,把二进制文件输出成文本文件。
2、实例
- 以 .docx 结尾的文件应用“word”过滤器,即
docx2txt。 这样你的 Word 文件就能被高效地转换成文本文件并进行比较了。 - 在比较时对图像文件运用一个过滤器,提炼出 EXIF 信息——这是在大部分图像格式中都有记录的一种元数据。
② 关键字展开
借鉴的是 SVN 或 CVS 风格的关键字展开(keyword expansion)功能。
略。
3、Git 钩子
(1)介绍
钩子是什么就不赘述了。
钩子位于.git/hooks。把一个正确命名(不带扩展名)且可执行的文件放入其中即可被 Git 调用。
所有 Git 自带的示例钩子脚本都是用 Perl 或 Bash 写的。
(2)客户端钩子
① 提交工作流钩子
- pre-commit 钩子:在键入提交信息前运行,如果该钩子以非零值退出,Git 将放弃此次提交
- prepare-commit-msg 钩子:在启动提交信息编辑器之前,默认信息被创建之后运行
- commit-msg 钩子:接收一个参数,此参数即上文提到的,存有当前提交信息的临时文件的路径
- post-commit 钩子:在整个提交过程完成后运行。 它不接收任何参数
② 电子邮件工作流钩子
略
③ 其它钩子
- pre-rebase 钩子:运行于变基之前,以非零值退出可以中止变基的过程
- post-checkout 钩子:在 git checkout 成功运行后,会被调用
- post-merge 钩子:在 git merge 成功运行后,会被调用
- pre-push 钩子:在 git push 运行期间,会被调用
- 等…
(3)服务器端钩子
pre-receive
处理来自客户端的推送操作时,最先被调用的脚本是 pre-receive。 它从标准输入获取一系列被推送的引用。如果它以非零值退出,所有的推送内容都不会被接受。update
update 脚本和 pre-receive 脚本十分类似,不同之处在于它会为每一个准备更新的分支各运行一次。 假如推送者同时向多个分支推送内容,pre-receive 只运行一次,相比之下 update 则会为每一个被推送的分支各运行一次。post-receive
post-receive 挂钩在整个过程完结以后运行,可以用来更新其他系统服务或者通知用户。
(4)客户端钩子 和 服务器端钩子 的区别
- push/clone、打包/clone 某个版本库时,它的客户端钩子并不随同复制。 (如果需要靠这些脚本来强制维持某种策略,建议你在服务器端实现这一功能。 )
(5)实例
使用强制策略的一个例子(用 Ruby 写的):
https://git-scm.com/book/zh/v2/自定义-Git-使用强制策略的一个例子
略
十一、Git 与其他版本控制系统
1、SVN
(1)桥接
用 git svn 跟 svn 桥接使用。
略
(2)迁移
从 svn 迁移到 git。
略
十二、GitHub
1、基本功能
- Git 托管
- 问题追踪
- 代码审查
- 等……
2、GitHub Actions
(1)介绍
GitHub Actions 是 GitHub 的持续集成服务。
如果你需要某个 action,不必自己写复杂的脚本,直接引用他人写好的 action 即可,整个持续集成过程,就变成了一个 actions 的组合。这就是 GitHub Actions 最特别的地方。
(2)基本概念
- 1、workflow (工作流程):持续集成一次运行的过程,就是一个 workflow。
- 2、job (任务):一个 workflow 由一个或多个 jobs 构成,含义是一次持续集成的运行,可以完成多个任务。
- 3、step(步骤):每个 job 由多个 step 构成,一步步完成。
- 4、action (动作):每个 step 可以依次执行一个或多个命令(action)。
(3)使用
GitHub Actions 的配置文件叫做 workflow 文件,存放在代码仓库的.github/workflows目录。
略
3、GitHub Packages
类似 npm 。
略
十三、分布式 Git 的工作流(flow)
1、什么是工作流?
多人协作开发的规范的工作流程。
2、按项目复杂度划分 - 着重在角色(权限)
(1)集中式工作流
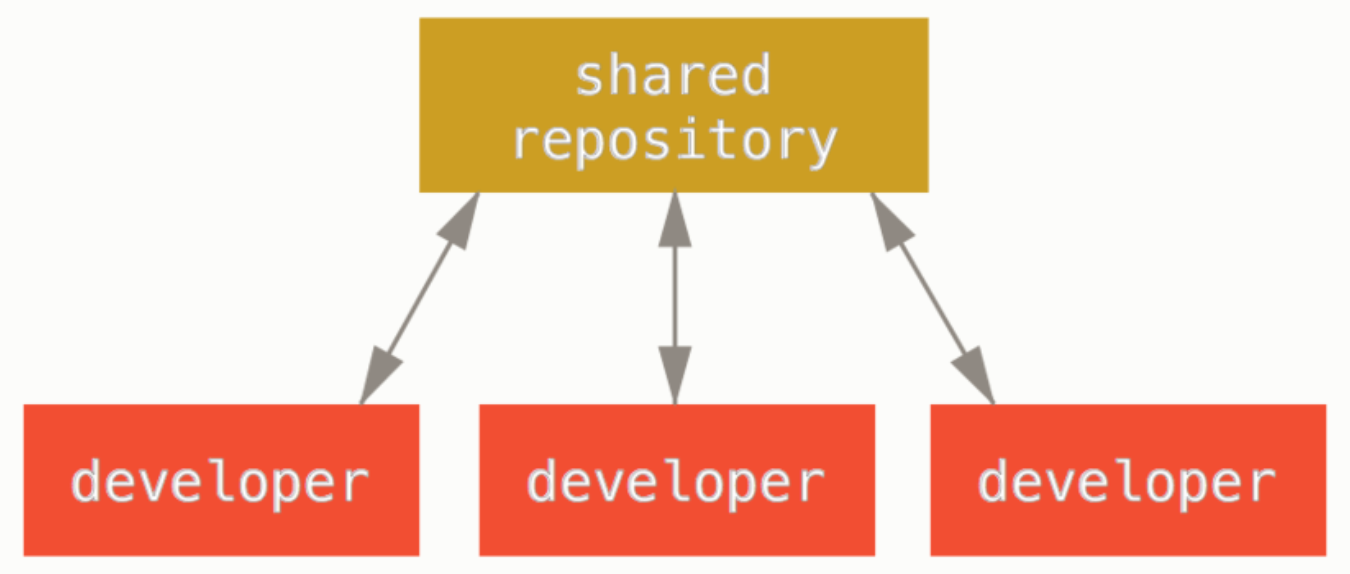
开发者在 push 之前,必须先 pull,这样才不会有冲突。(即使两个开发者并没有编辑同一个文件。)
(2)集成管理者工作流
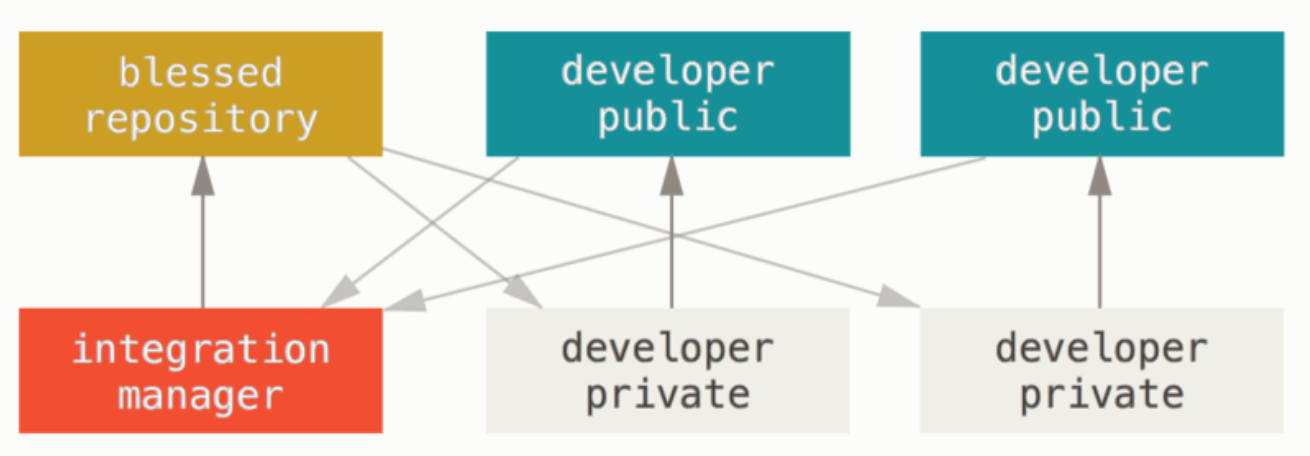
- 1、项目维护者推送到主仓库。
- 2、贡献者克隆此仓库,做出修改。
- 3、贡献者将数据推送到自己的公开仓库。
- 4、贡献者给维护者发送邮件,请求拉取自己的更新。
- 5、维护者在自己本地的仓库中,将贡献者的仓库加为远程仓库并合并修改。
- 6、维护者将合并后的修改推送到主仓库。
这是 GitHub 和 GitLab 等集线器式(hub-based)工具最常用的工作流程。
(3)主管与副主管工作流
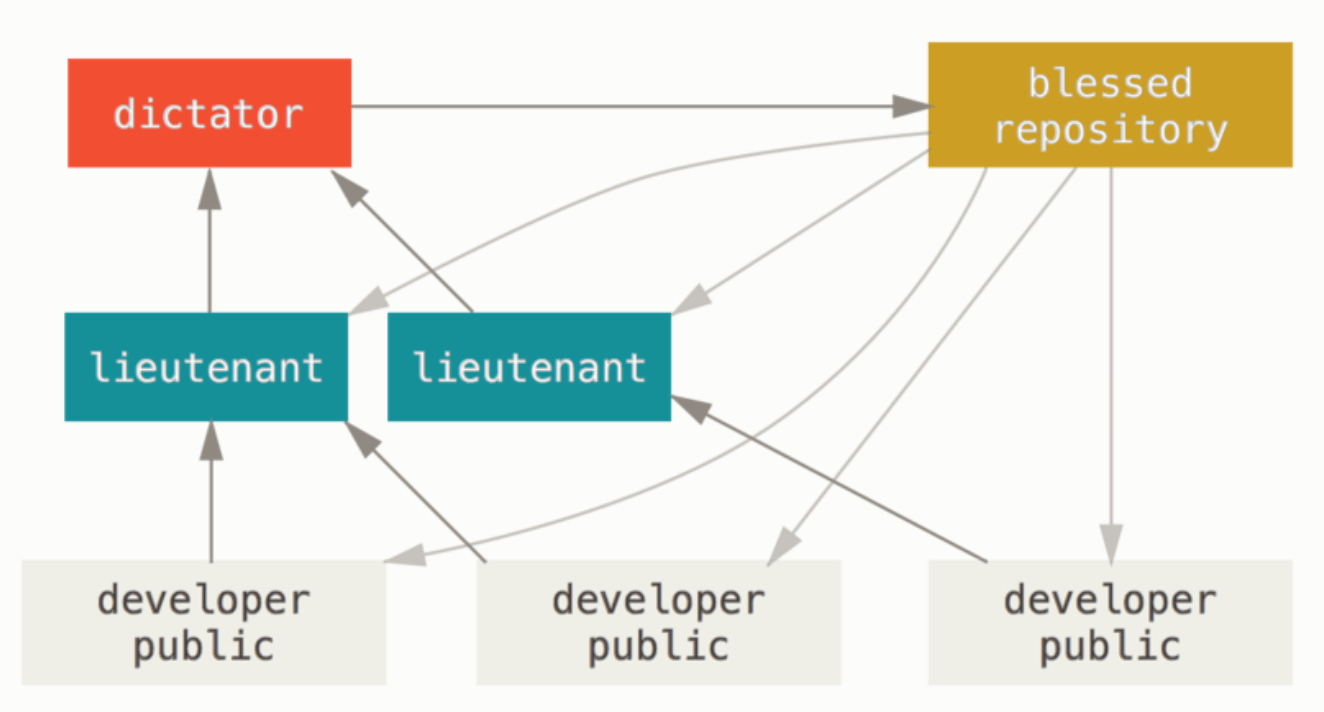
- 1、普通开发者在自己的主题分支上工作,并根据 master 分支进行变基。这里是主管推送的参考仓库的 master 分支。
- 2、副主管将普通开发者的主题分支合并到自己的 master 分支中。
- 3、主管将所有副主管的 master 分支并入自己的 master 分支中。
- 4、最后,主管将集成后的 master 分支推送到参考仓库中,以便所有其他开发者以此为基础进行变基。
这其实是多仓库工作流程的变种。一般拥有数百位协作开发者的超大型项目才会用到这样的工作方式,例如著名的 Linux 内核项目。
但这种工作流程并不常用,只有当项目极为庞杂,或者需要多级别管理时,才会体现出优势。
3、按不同产品划分 - 着重在分支
(1)Git flow
① 分支
master 分支是主分支(长期分支),因此要时刻与远程同步;develop 分支是开发分支(长期分支),团队所有成员都需要在上面工作,所以也需要与远程同步;feature 分支是开发具体功能的分支,是否推到远程,取决于你是否和你的小伙伴合作在上面开发;bug 分支只用于在本地修复 bug,就没必要推到远程了;hotfix 分支只用于紧急修复远程 master 分支的 bug;
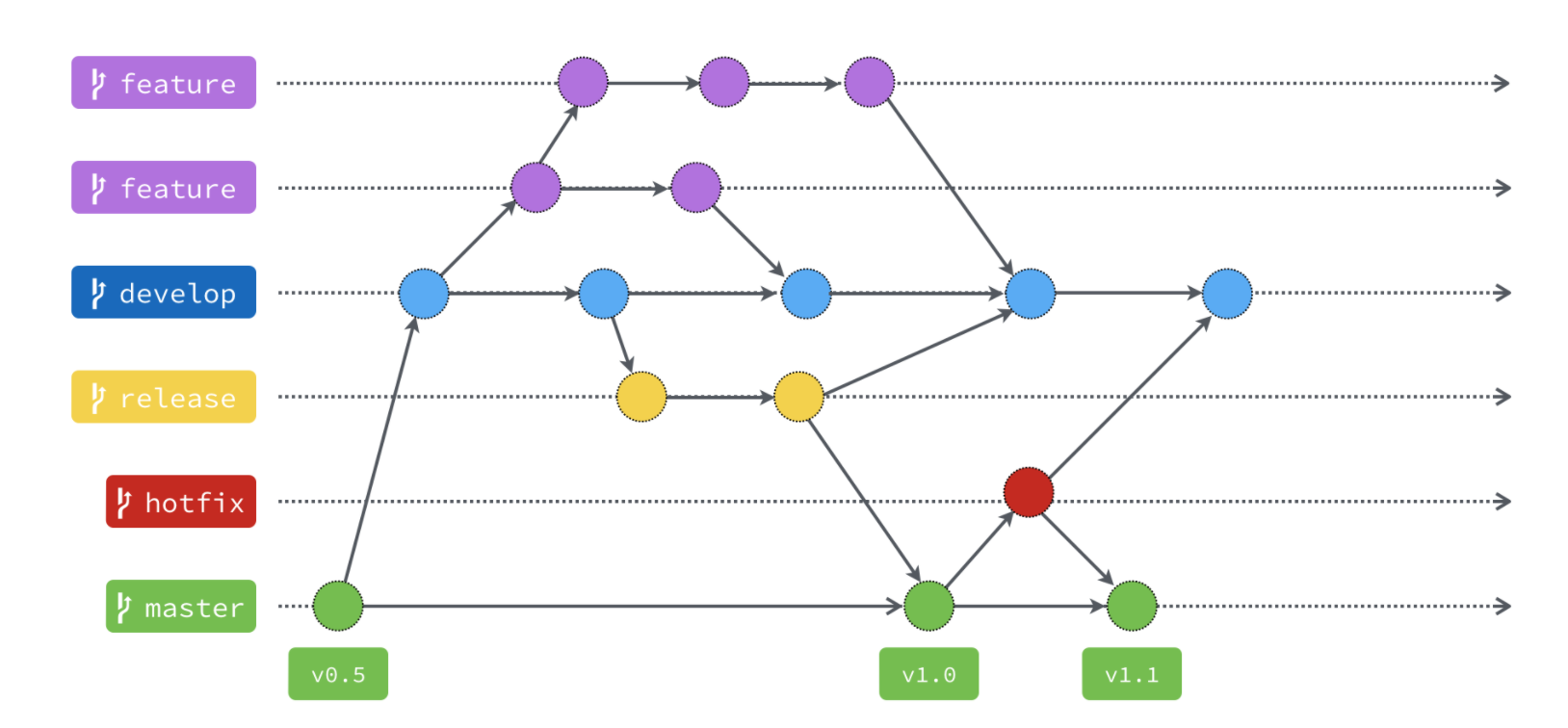
② 适用场景
这个模式是基于"版本发布"的,目标是一段时间以后产出一个新版本。
很多网站项目是"持续发布",代码一有变动,就部署一次。这时,master分支和develop分支的差别不大,没必要维护两个长期分支。
(2)Github flow
① 分支
它只有一个长期分支,就是 master,此用起来非常简单。
然后通过向 master 发起一个 pull request(简称PR)。
② pull request
pull request 的详细介绍参考:
略
[拓展] PR / MR 区别
是一样的,只是习惯的叫法不同:
- GitHub、Bitbucket 和码云(Gitee.com)选择
PR - Pull Request作为这项功能的名称 - GitLab 和 Gitorious 选择
MR - Merge Request作为这项功能的名称
③ 适用场景
适用于"持续发布"。
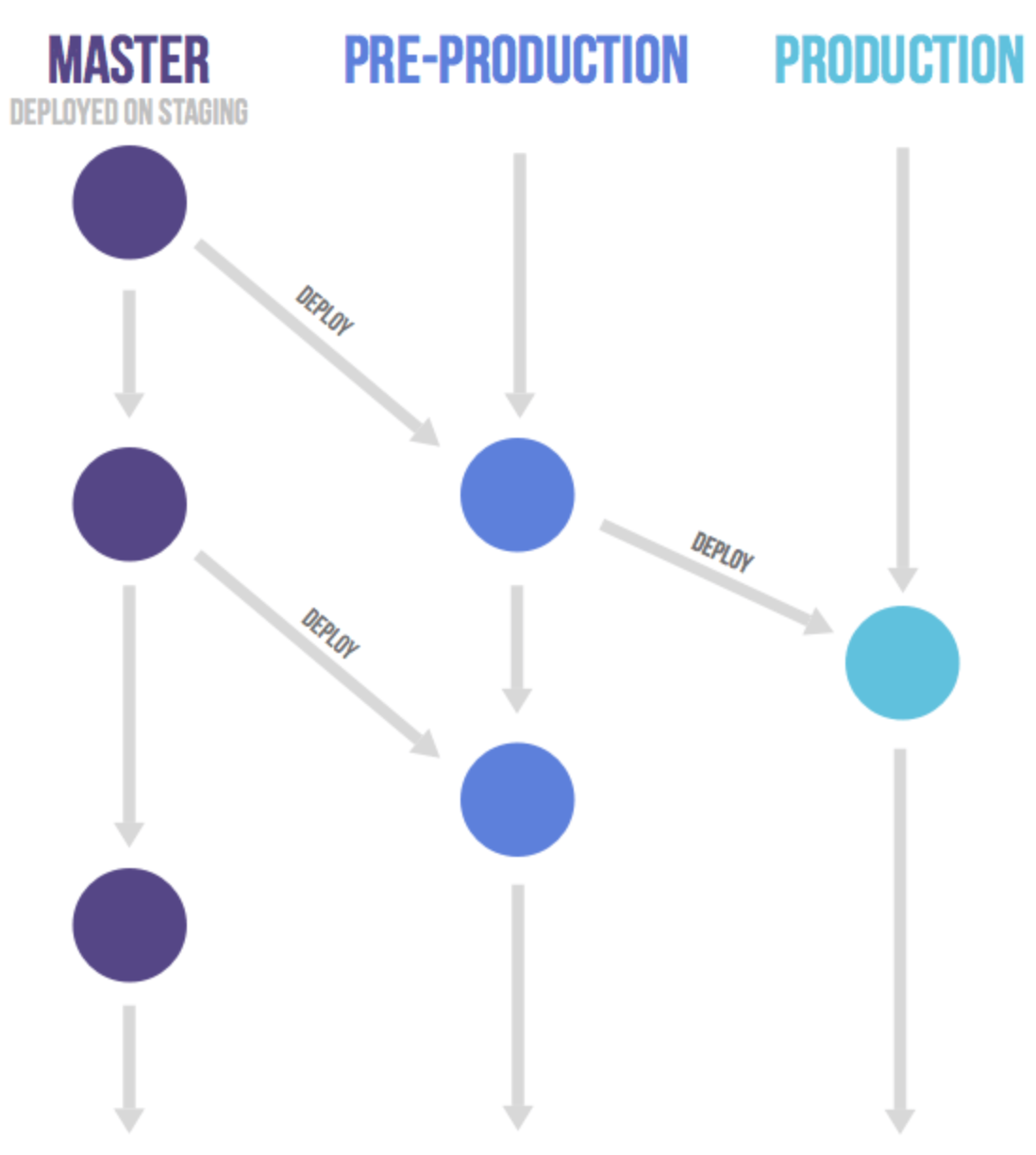
(3)Gitlab flow
① 分支
它建议在master分支以外,再建立不同的环境分支。
- "开发环境"的分支是master
- "预发环境"的分支是pre-production
- "生产环境"的分支是production
② 上游
开发分支是预发分支的"上游",预发分支又是生产分支的"上游"。只有紧急情况,才允许跳过上游,直接合并到下游分支。
上面的流程,适用于"持续发布"的项目,但对于"版本发布"的项目,也可以稍加改变 :建议的做法是每一个稳定版本,都要从master分支拉出一个分支,比如2-3-stable、2-4-stable等等。
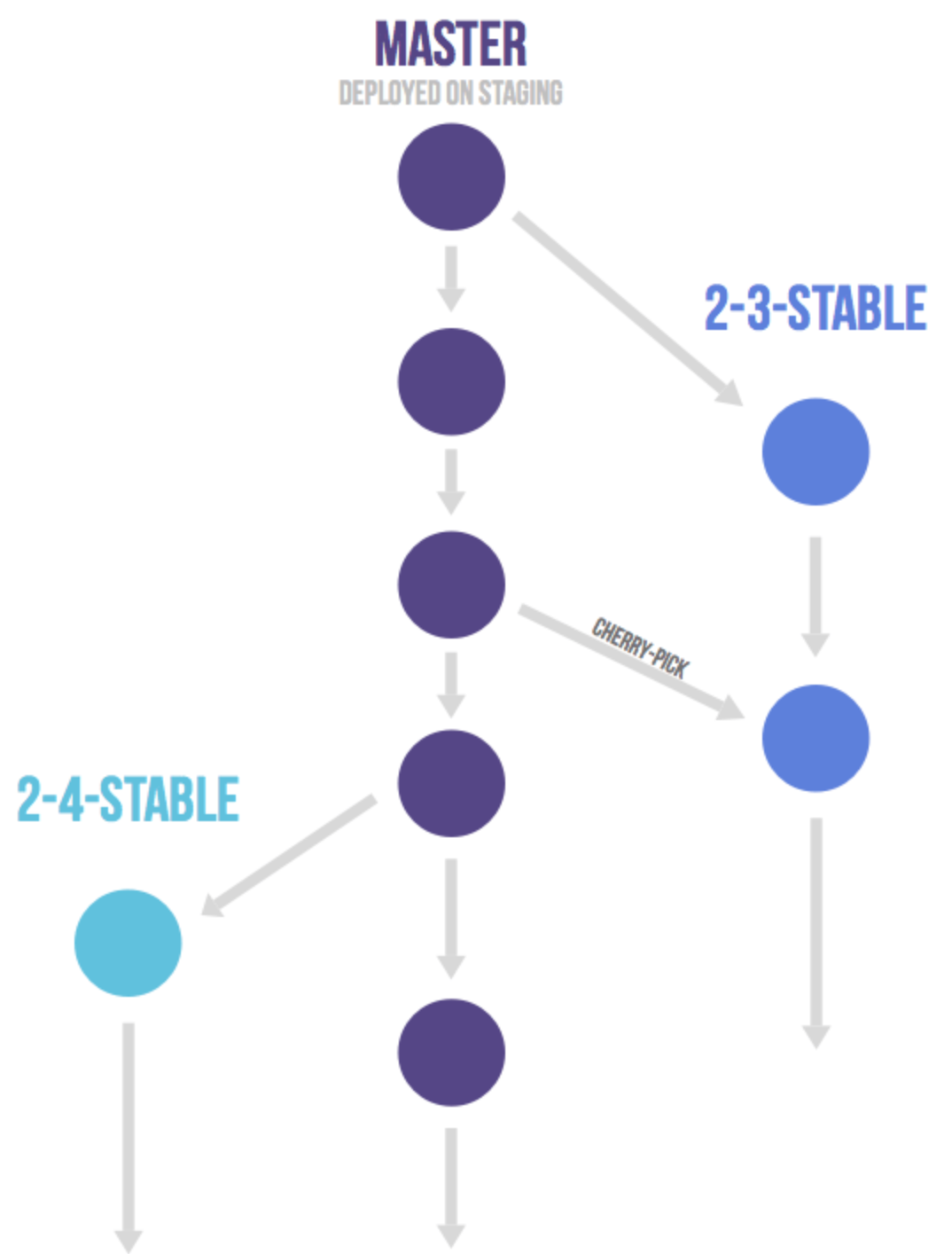
③ 适用场景
即适用于"持续发布",也适用于"版本发布"的项目(见上面刚刚的描述)。
我司用的即这种方法。
十四、GUI - gitkraken
1、安装
下载地址:https://iusethis.luo.ma/gitkraken/
推荐安装 v6.5.1。因为更新的版本加了对免费版的限制(例如不能open私有仓库了,这基本上不升级pro就用不了了)
记得把
127.0.0.1 release.gitkraken.com写入你的 host 文件,这样就不会自动更新了。
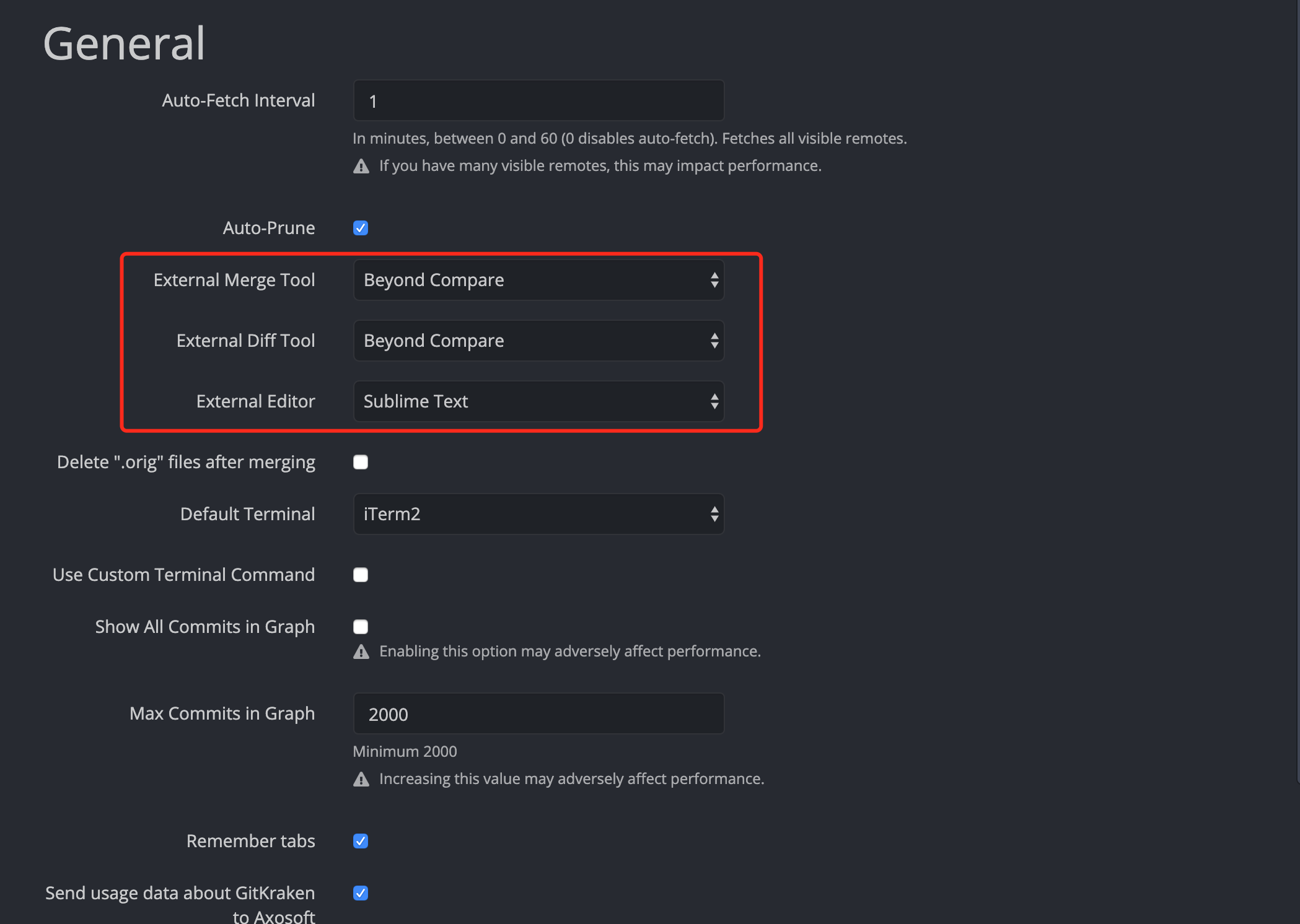
2、配置
(1)配置外部程序
gitkraken 也可以跟 git 一样,在设置里配置 open、diff、merge 的外部程序。
3、操作
(1)快捷操作的按钮
① undo + redo。
这个超好用,可以根据你上一次的操作,软件就会自动算出对应的撤销和重做需要执行的命令是啥,而你只需要点击按钮就行。

不过也不是万能的,有的复杂操作,undo + redo 是灰掉得(既不支持)。
(2)文件浏览
注意:如果你是在历史的 commit 里对文件做如下(画红框的)操作,针对的不是历史的文件,还是最新(HEAD 或者说 检出工作区)的文件。
这点有点反直觉。

4、其他更多
上文也穿插着介绍不少 Gitkraken 的用法。
十五、写在最后
1、Git 的缺点
这里更多的是我自己的“吐槽“,供抛砖引玉。
- git 重置那块,git reset 和 git reset file 和 git checkout 和 git checkout file,原理都不是相通的,真的是服了。
2、我之前关于 git 的文章
Git、Github、Gitkraken 学习笔记的更多相关文章
- 【原】《Git教程》学习笔记
[TOC] 1 创建版本库 1.1 初始化 初始化一个Git仓库,使用 git init 命令. 添加文件到Git仓库,分两步: 第一步,使用命令git add <file> ,注意,可反 ...
- git的使用学习笔记3---关于项目分支创建克隆拉取推送
一.创建项目 1.打开官网 2.填写相关内容 查看新创建的项目 3.选择方式 4.在git上新建文件夹 1)克隆: mkdir workspace 将代码克隆到本地,取本地配置的.ssh的文件 git ...
- 【Git和GitHub】学习笔记
1. 书籍推荐: 先看一本比较简单并且好的入门书籍 Git - Book https://git-scm.com/book/zh/v2 2. 书籍理解: Git 有三种状态,你的文件可能处于其中之一: ...
- Git版本控制管理学习笔记5-提交
这个标题其实有些让人费解,因为会想这个提交是动词还是名称? 提交动作是通过git commit命令来实现的,提交之后会在对象库中新增一个提交对象.提交过程中会发生哪些变化,在上一篇笔记 ...
- Git版本控制管理学习笔记3-基本的Git概念
为了更近一步的学习和理解Git的理念,这一节介绍一下Git中的一些基本概念. 基本概念 对象库图示 Git在工作时的概念 一.基本概念: 1.版本库: Git的版本库就是一个简单的数据库,其中 ...
- Git 版本控制工具(学习笔记)
GIT(分布式) 一.Git 初始版本控制工具 1. 安装Git Ubuntu系统下,打开shell界面,输入: sudo apt-get install git-core 之后回车输入密码,即可完 ...
- 《廖雪峰Git教程》学习笔记
原文链接 一.创建版本库 ①初始化一个Git仓库:git init ②添加文件到Git仓库:1.git add<file> ; 2.git commit 二.时光机穿梭 ①查看工作区状态 ...
- Git 版本管理器学习笔记
难点:使用 git revert <commit_id> 操作实现以退为进, git revert 不同于 git reset 它不会擦除"回退"之后的 commit_ ...
- git的使用学习笔记
一.git Git 是一个开源的分布式版本控制系统,项目版本管理工具,可以在本地提交修改再合并到主分支上,最为出色的是它的合并跟踪(merge tracing)能力. 可以通过Linux命令进行增加, ...
随机推荐
- 解决mysql插入数据l出现"the table is full"的问题
需要修改Mysql的配置文件my.ini,在[mysqld]下添加/修改两行:tmp_table_size = 256Mmax_heap_table_size = 256M
- vue父路由高亮不显示
vue父路由高亮不显示 首页和考试中心作为父路由,点击时发现不高亮,是因为路由配置有问题 因为首页和考试中心已经重定向到homepage和tpersonal-data这两个路由,当点击首页和考试中心的 ...
- SSM-框架搭建-tank后台学习系统
一.前言 最近收到很多网友给我私信,学习软件开发有点吃力,不知道从何处开始学习,会点基础但是做不出来什么项目, 都想放弃了.我就回复道:当下互联网飞速发展,软件开发行业非常吃香而且前景相当不错.希望能 ...
- weblogic高级进阶之ssl配置证书
1.首先需要明白ssl的原理 这里我们使用keytool的方式为AdminServer配置ssl证书 配置证书的方式如下所示: C:\Users\Administrator\Desktop\mykey ...
- 05.DBUnit的使用
相信做过单元测试的人都会对JUnit 非常的熟悉了,今天要介绍的DbUnit(http://dbunit.sourceforge.net/ ) 则是专门针对数据库测试的对JUnit 的一个扩展,它可以 ...
- mysql replace替换某字段的值
由于最近我们的一个网站回购了一个很好的域名所有与之相关的项目都需要修改: 今天接到一个任务将我们会员开通的个人网站的二级域名换成新域名,看了一下库已开通的还很少才2w多,且要换的和之前库中的数据很规则 ...
- xdebug调试代码常用操作
xdebug调试代码常用操作 1.查看变量中的值 2.常用快捷键 ①F8单步调试 ②F9可以直接快速结束调试 ③F7 可以进入调试代码的底层方法,我觉得查看底层代码时,这个特别的方便!
- 删库吧,Bug浪——我们在同一家摸鱼的公司
那些口口声声, Bug越来越难写人的,应该盯着你们: 像我一样,我盯着你们,满眼恨意. IT积攒了几十年的漏洞, 所有的死机.溢出.404和超时, 像是专门为你们准备的礼物. 圈复杂度.魔鬼变量.内存 ...
- 在Github上建立自己的个人主页
目录 注册Github账号 登录Github账号 建立新仓库 选择个人主页的主题 注册Github账号 首先打开Github的主页(https://github.com/),点击右上角的sign up ...
- CListCtrl 控件即使跟新数据,即时刷新以及属性设置
用 m_CtrItem.Update( i );来即使跟新每行的数据,因为有时用某些函数如SetItemText()来设置某一行一列的数据是,控件上面的显示数据没有即使跟新,这是就有update来跟新 ...