Python 爬虫系列
爬虫简介
网络爬虫
爬虫指在使用程序模拟浏览器向服务端发出网络请求,以便获取服务端返回的内容。
但这些内容可能涉及到一些机密信息,所以爬虫领域目前来讲是属于灰色领域,切勿违法犯罪。
爬虫本身作为一门技术没有任何问题,关键是看人们怎么去使用它
《中华人民共和国刑法》第二百八十五条规定:非法获取计算机信息系统数据、非法控制计算机信息系统罪,是指违反国家规定,侵入国家事务、国防建设、尖端科学技术领域以外的计算机信息系统或者采用其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,情节严重的行为。刑法第285条第2款明确规定,犯本罪的,处三年以下有期徒刑或者拘役,并处或者单处罚金;情节特别严重的,处三年以上七年以下有期徒刑,并处罚金。
《反不正当竞争法》第九条规定:以不正当手段获取他人商业秘密的行为即已经构成侵犯商业秘密。而后续如果进一步利用,或者公开该等信息,则构成对他人商业秘密的披露和使用,同样构成对权利人的商业秘密的侵犯。
《刑法》第二百八十六条规定:违反国家规定,对计算机信息系统功能进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行,后果严重的,构成犯罪,处五年以下有期徒刑或者拘役;后果特别严重的,处五年以上有期徒刑。而违反国家规定,对计算机信息系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加的操作,后果严重的,也构成犯罪,依照前款的规定处罚。
《网络安全法》第四十四条规定:任何个人和组织不得窃取或者以其他非法方式获取个人信息。因此,如果爬虫在未经用户同意的情况下大量抓取用户的个人信息,则有可能构成非法收集个人信息的违法行为。
《民法总则》第111条规定:任何组织和个人需要获取他人个人信息的,应当依法取得并确保信息安全。不得非法收集、使用、加工、传输他人个人信息
爬虫分类
根据爬虫的应用范畴,可有一些三种区分:
通用爬虫
搜索引擎本质就是一个巨大的爬虫,首先该爬虫会爬取整张页面,并且对该页面做备份,之后对其进行数据内容处理如抓取关键字等,然后向用户提供检索接口。
聚焦式爬虫
只关注于页面上某一部分内容,如只关注图片、链接等。
增量式爬虫
用于检索内容是否更新,如开发了一个增量式爬虫每天查看一下云崖博客有没有更新,有更新就爬下来等等...
robots协议
robots协议是爬虫领域非常出名的一种协议,由门户网站提供。
它规定了该站点哪些内容允许爬取,哪些内容不允许爬取。
如果爬取不允许的内容,可对其追究法律责任。
requests模块
requests模块是Python中发送网络请求的一款非常简洁、高效的模块。
pip install requests
发送请求
支持所有的请求方式:
import requests
requests.get("https://www.python.org/")
requests.post("https://www.python.org/")
requests.put("https://www.python.org/")
requests.patch("https://www.python.org/")
requests.delete("https://www.python.org/")
requests.head("https://www.python.org/")
requests.options("https://www.python.org/")
# 指定请求方式
requests.request("get","https://www.python.org/")
当请求发送成功后,会返回一个response对象。
get请求
基本的get请求参数如下:
| 参数 | 描述 |
|---|---|
| params | 字典,get请求的参数,value支持字符串、字典、字节(ASCII编码内) |
| headers | 字典,本次请求携带的请求头 |
| cookies | 字典,本次请求携带的cookies |
演示如下:
import requests
res = requests.get(
url="http://127.0.0.1:5000/index",
params={"key": "value"},
cookies={"key": "value"},
)
print(res.content)
post请求
基本的post请求参数如下:
| 参数 | 描述 |
|---|---|
| data | 字典,post请求的参数,value支持文件对象、字符串、字典、字节(ASCII编码内) |
| headers | 字典,本次请求携带的请求头 |
| cookies | 字典,本次请求携带的cookies |
演示如下:
import requests
res = requests.post(
url="http://127.0.0.1:5000/index",
# 依旧可以携带 params
data={"key": "value"},
cookies={"key": "value"},
)
print(res.content)
高级参数
更多参数:
| 参数 | 描述 |
|---|---|
| json | 字典,传入json数据,将自动进行序列化,支持get/post,请求体传递 |
| files | 字典,传入文件对象,支持post |
| auth | 认证,传入HTTPDigestAuth对象,一般场景是路由器弹出的两个输入框,爬虫获取不到,将用户名和密码输入后会base64加密然后放入请求头中进行交给服务端,base64("名字:密码"),请求头名字:authorization |
| timeout | 超时时间,传入float/int/tuple类型。如果传入的是tuple,则是 (链接超时、返回超时) |
| allow_redirects | 是否允许重定向,传入bool值 |
| proxies | 开启代理,传入一个字典 |
| stream | 是否返回文件流,传入bool值 |
| cert | 证书地址,这玩意儿来自于HTTPS请求,需要传入该网站的认证证书地址,通常来讲如果是大公司的网站不会要求这玩意儿 |
演示:
def param_method_url():
# requests.request(method='get', url='http://127.0.0.1:8000/test/')
# requests.request(method='post', url='http://127.0.0.1:8000/test/')
pass
def param_param():
# - 可以是字典
# - 可以是字符串
# - 可以是字节(ascii编码以内)
# requests.request(method='get',
# url='http://127.0.0.1:8000/test/',
# params={'k1': 'v1', 'k2': '水电费'})
# requests.request(method='get',
# url='http://127.0.0.1:8000/test/',
# params="k1=v1&k2=水电费&k3=v3&k3=vv3")
# requests.request(method='get',
# url='http://127.0.0.1:8000/test/',
# params=bytes("k1=v1&k2=k2&k3=v3&k3=vv3", encoding='utf8'))
# 错误
# requests.request(method='get',
# url='http://127.0.0.1:8000/test/',
# params=bytes("k1=v1&k2=水电费&k3=v3&k3=vv3", encoding='utf8'))
pass
def param_data():
# 可以是字典
# 可以是字符串
# 可以是字节
# 可以是文件对象
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# data={'k1': 'v1', 'k2': '水电费'})
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# data="k1=v1; k2=v2; k3=v3; k3=v4"
# )
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# data="k1=v1;k2=v2;k3=v3;k3=v4",
# headers={'Content-Type': 'application/x-www-form-urlencoded'}
# )
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# data=open('data_file.py', mode='r', encoding='utf-8'), # 文件内容是:k1=v1;k2=v2;k3=v3;k3=v4
# headers={'Content-Type': 'application/x-www-form-urlencoded'}
# )
pass
def param_json():
# 将json中对应的数据进行序列化成一个字符串,json.dumps(...)
# 然后发送到服务器端的body中,并且Content-Type是 {'Content-Type': 'application/json'}
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
json={'k1': 'v1', 'k2': '水电费'})
def param_headers():
# 发送请求头到服务器端
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
json={'k1': 'v1', 'k2': '水电费'},
headers={'Content-Type': 'application/x-www-form-urlencoded'}
)
def param_cookies():
# 发送Cookie到服务器端
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
data={'k1': 'v1', 'k2': 'v2'},
cookies={'cook1': 'value1'},
)
# 也可以使用CookieJar(字典形式就是在此基础上封装)
from http.cookiejar import CookieJar
from http.cookiejar import Cookie
obj = CookieJar()
obj.set_cookie(Cookie(version=0, name='c1', value='v1', port=None, domain='', path='/', secure=False, expires=None,
discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False,
port_specified=False, domain_specified=False, domain_initial_dot=False, path_specified=False)
)
requests.request(method='POST',
url='http://127.0.0.1:8000/test/',
data={'k1': 'v1', 'k2': 'v2'},
cookies=obj)
def param_files():
# 发送文件
# file_dict = {
# 'f1': open('readme', 'rb')
# }
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# files=file_dict)
# 发送文件,定制文件名
# file_dict = {
# 'f1': ('test.txt', open('readme', 'rb'))
# }
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# files=file_dict)
# 发送文件,定制文件名
# file_dict = {
# 'f1': ('test.txt', "hahsfaksfa9kasdjflaksdjf")
# }
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# files=file_dict)
# 发送文件,定制文件名
# file_dict = {
# 'f1': ('test.txt', "hahsfaksfa9kasdjflaksdjf", 'application/text', {'k1': '0'})
# }
# requests.request(method='POST',
# url='http://127.0.0.1:8000/test/',
# files=file_dict)
pass
def param_auth():
# 认证,浏览器BOM对象弹出对话框
# 在HTML文档中是找不到该标签的,所以需要用这个对其进行传入,一般来说常见于路由器登录页面
from requests.auth import HTTPBasicAuth, HTTPDigestAuth
ret = requests.get('https://api.github.com/user', auth=HTTPBasicAuth('wupeiqi', 'sdfasdfasdf'))
print(ret.text)
# ret = requests.get('http://192.168.1.1',
# auth=HTTPBasicAuth('admin', 'admin'))
# ret.encoding = 'gbk'
# print(ret.text)
# ret = requests.get('http://httpbin.org/digest-auth/auth/user/pass', auth=HTTPDigestAuth('user', 'pass'))
# print(ret)
#
def param_timeout():
# 超时时间,如果链接时间大于1秒就返回
# ret = requests.get('http://google.com/', timeout=1)
# print(ret)
# 如果链接时间大于5秒就返回,或者响应时间大于1秒就返回
# ret = requests.get('http://google.com/', timeout=(5, 1))
# print(ret)
pass
def param_allow_redirects():
ret = requests.get('http://127.0.0.1:8000/test/', allow_redirects=False)
print(ret.text)
def param_proxies():
# 配置代理
# proxies = {
# "http": "61.172.249.96:80",
# "https": "http://61.185.219.126:3128",
# }
# proxies = {'http://10.20.1.128': 'http://10.10.1.10:5323'}
# ret = requests.get("http://www.proxy360.cn/Proxy", proxies=proxies)
# print(ret.headers)
# from requests.auth import HTTPProxyAuth
#
# proxyDict = {
# 'http': '77.75.105.165',
# 'https': '77.75.105.165'
# }
# auth = HTTPProxyAuth('username', 'mypassword')
#
# r = requests.get("http://www.google.com", proxies=proxyDict, auth=auth)
# print(r.text)
pass
def param_stream():
# 文件流,直接写入文件即可
ret = requests.get('http://127.0.0.1:8000/test/', stream=True)
print(ret.content)
ret.close()
# from contextlib import closing
# with closing(requests.get('http://httpbin.org/get', stream=True)) as r:
# # 在此处理响应。
# for i in r.iter_content():
# print(i)
session对象
如果爬取一个网站,该网站可能会返回给你一些cookies,对这个网站后续的请求每次都要带上这些cookies比较麻烦。
所以可以直接使用session对象(自动保存cookies)发送请求,它会携带当前对象中所有的cookies。
def requests_session():
import requests
# 使用session时,会携带该网站中所返回的所有cookies发送下一次请求。
# 生成session对象
session = requests.Session()
### 1、首先登陆任何页面,获取cookie
i1 = session.get(url="http://dig.chouti.com/help/service")
### 2、用户登陆,携带上一次的cookie,后台对cookie中的 gpsd 进行授权
i2 = session.post(
url="http://dig.chouti.com/login",
data={
'phone': "8615131255089",
'password': "xxxxxx",
'oneMonth': ""
}
)
i3 = session.post(
url="http://dig.chouti.com/link/vote?linksId=8589623",
)
print(i3.text)
response对象
以下是response对象的所有参数:
| 参数 | 描述 |
|---|---|
| response.text | 返回文本响应内容 |
| response.content | 返回二进制响应内容 |
| response.json | 如果返回内容是json格式,则进行序列化 |
| response.encoding | 返回响应内容的编码格式 |
| response.status_code | 状态码 |
| response.headers | 返回头 |
| response.cookies | 返回的cookies对象 |
| response.cookies.get_dict() | 以字典形式展示返回的cookies对象 |
| response.cookies.items() | 以元组形式展示返回的cookies对象 |
| response.url | 返回的url地址 |
| response.history | 这是一个列表,如果请求被重定向,则将上一次被重定向的response对象添加到该列表中 |
编码问题
并非所有网页都是utf8编码,有的网页是gbk编码。
此时如果使用txt查看响应内容就要指定编码格式:
import requests
response=requests.get('http://www.autohome.com/news')
response.encoding='gbk'
print(response.text)
下载文件
使用response.context时,会将所有内容存放至内存中。
如果访问的资源是一个大文件,而需要对其进行下载时,可使用如下方式生成迭代器下载:
import requests
response=requests.get('http://bangimg1.dahe.cn/forum/201612/10/200447p36yk96im76vatyk.jpg')
with open("res.png","wb") as f:
for line in response.iter_content():
f.write(line)
json返回内容
如果确定返回内容是json数据,则可以通过response.json进行查看:
import requests
response = requests.get("http://127.0.0.1:5000/index")
print(response.json())
历史记录
如果访问一个地址却被重定向了,被重定向的地址会被存放到response.history这个列表中:
import requests
r = requests.get('http://127.0.0.1:5000/index') # 被重定向了
print(r.status_code) # 200
print(r.url) # http://127.0.0.1:5000/new # 重定向的地址
print(r.history)
# [<Response [302]>]
如果在请求时,指定allow_redirects参数为False,则禁止重定向:
import requests
r = requests.get('http://127.0.0.1:5000/index',allow_redirects=False) # 禁止重定向
print(r.status_code) # 302
print(r.url) # http://127.0.0.1:5000/index
print(r.history)
# []
bs4模块
request模块可以发送请求,获取HTML文档内容。
而bs4模块可以解析出HTML与XML文档的内容,如快速查找标签等等。
pip3 install bs4
bs4模块只能在Python中使用
bs4依赖解析器,虽然有自带的解析器,但是目前使用最多的还是lxml:
pip3 install lxml
基本使用
将request模块请求回来的HTML文档内容转换为bs4对象,使用其下的方法进行查找:
如下示例,解析出虾米音乐中的歌曲,歌手,歌曲时长:
import requests
from bs4 import BeautifulSoup
from prettytable import PrettyTable
# 实例化表格
table = PrettyTable(['编号', '歌曲名称', '歌手', '歌曲时长'])
url = r"https://www.xiami.com/list?page=1&query=%7B%22genreType%22%3A1%2C%22genreId%22%3A%2220%22%7D&scene=genre&type=song"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",
}
response = requests.get(url=url, headers=headers)
# step01: 将文本内容实例化出bs对象
soup_obj = BeautifulSoup(response.text, "lxml")
# step02: 查找标签
main = soup_obj.find("div", attrs={"class": "table idle song-table list-song"})
# step03: 查找存放歌曲信息的tbody标签
tbody = main.select(".table-container>table>tbody")[0]
# step04: tbody标签中的每个tr都是一首歌曲
tr = tbody.find_all("tr")
# step04: 每个tr里都存放有歌曲信息,所以直接循环即可
for music in tr:
name = music.select(".song-name>a")[0].text
singer = music.select(".COMPACT>a")[0].text
time_len = music.select(".duration")[0].text
table.add_row([tr.index(music) + 1, name, singer, time_len])
# step05: 打印信息
print(table)
结果如下:
+------+--------------------------------------------------+--------------------+----------+
| 编号 | 歌曲名称 | 歌手 | 歌曲时长 |
+------+--------------------------------------------------+--------------------+----------+
| 1 | Love Story (Live from BBC 1's Radio Live Lounge) | Taylor Swift | 04:25 |
| 2 | Five Hundred Miles | Jove | 03:27 |
| 3 | I'm Gonna Getcha Good! (Red Album Version) | Shania Twain | 04:30 |
| 4 | Your Man | Josh Turner | 03:45 |
| 5 | Am I That Easy To Forget | Jim Reeves | 02:22 |
| 6 | Set for Life | Trent Dabbs | 04:23 |
| 7 | Blue Jeans | Justin Rutledge | 04:25 |
| 8 | Blind Tom | Grant-Lee Phillips | 02:59 |
| 9 | Dreams | Slaid Cleaves | 04:14 |
| 10 | Remember When | Alan Jackson | 04:31 |
| 11 | Crying in the Rain | Don Williams | 03:04 |
| 12 | Only Worse | Randy Travis | 02:53 |
| 13 | Vincent | The Sunny Cowgirls | 04:22 |
| 14 | When Your Lips Are so Close | Gord Bamford | 03:02 |
| 15 | Let It Be You | Ricky Skaggs | 02:42 |
| 16 | Steal a Heart | Tenille Arts | 03:09 |
| 17 | Rylynn | Andy McKee | 05:13 |
| 18 | Rockin' Around The Christmas Tree | Brenda Lee | 02:06 |
| 19 | Love You Like a Love Song | Megan & Liz | 03:17 |
| 20 | Tonight I Wanna Cry | Keith Urban | 04:18 |
| 21 | If a Song Could Be President | Over the Rhine | 03:09 |
| 22 | Shut'er Down | Doug Supernaw | 04:12 |
| 23 | Falling | Jamestown Story | 03:08 |
| 24 | Jim Cain | Bill Callahan | 04:40 |
| 25 | Parallel Line | Keith Urban | 04:14 |
| 26 | Jingle Bell Rock | Bobby Helms | 04:06 |
| 27 | Unsettled | Justin Rutledge | 04:01 |
| 28 | Bummin' Cigarettes | Maren Morris | 03:07 |
| 29 | Cheatin' on Her Heart | Jeff Carson | 03:18 |
| 30 | If My Heart Had a Heart | Cassadee Pope | 03:21 |
+------+--------------------------------------------------+--------------------+----------+
Process finished with exit code 0
HTML文档
准备一个HTML文档,对他进行解析:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<form action="#" method="post" enctype="multipart/form-data">
<fieldset>
<legend><h1>欢迎注册</h1></legend>
<p>头像: <input type="file" name="avatar"/></p>
<p>用户名: <input type="text" name="username" placeholder="请输入用户名"/></p>
<p>密码: <input type="text" name="pwd" placeholder="请输入密码"/></p>
<p>性别: 男<input type="radio" name="gender" value="male"/>女<input type="radio" name="gender" value="female"/></p>
<p>爱好: 篮球<input type="checkbox" name="hobby" value="basketball" checked/>足球<input type="checkbox" name="hobby"
value="football"/></p>
居住地
<select name="addr">
<optgroup label="中国">
<option value="bejing" selected>北京</option>
<option value="shanghai">上海</option>
<option value="guangzhou">广州</option>
<option value="shenzhen">深圳</option>
<option value="other">其他</option>
</optgroup>
<optgroup label="海外">
<option value="America">美国</option>
<option value="Japanese">日本</option>
<option value="England">英国</option>
<option value="Germany">德国</option>
<option value="Canada">加拿大</option>
</optgroup>
</select>
</fieldset>
<fieldset>
<legend>请填写注册理由</legend>
<p><textarea name="register_reason" cols="30" rows="10" placeholder="请填写充分理由"></textarea></p>
</fieldset>
<p><input type="reset" value="重新填写信息"/> <input type="submit" value="提交注册信息"> <input type="butoon"
value="联系客服" disabled>
</p>
</form>
</body>
</html>
基本选择器
基本选择器如下 :
| 选择器方法 | 描述 |
|---|---|
| TagName | 唯一选择器,根据标签名来选择 |
| find() | 唯一选择器,可根据标签名、属性来做选择 |
| select_one() | 唯一选择器,可根据CSS选择器语法做选择 |
| find_all() | 集合选择器,可根据标签名、属性来做选择 |
| select() | 集合选择器,可根据CSS选择器语法做选择 |
.TagName选择器只会拿出第一个匹配的内容,必须根据标签名选择:
input = soup.input
print(input)
# <input name="avatar" type="file"/>
.find()选择器只会拿出第一个匹配的内容,可根据标签名、属性来做选择
input= soup.find("input",attrs={"name":"username","type":"text"}) # attrs指定属性
print(input)
# <input name="username" placeholder="请输入用户名" type="text"/>
.select_one()根据css选择器来查找标签,只获取第一个:
input = soup.select_one("input[type=text]")
print(input)
# <input name="username" placeholder="请输入用户名" type="text"/>
.find_all()可获取所有匹配的标签,返回一个list,可根据标签名、属性来做选择
input_list = soup.find_all("input",attrs={"type":"text"})
print(input_list)
# [<input name="username" placeholder="请输入用户名" type="text"/>, <input name="pwd" placeholder="请输入密码" type="text"/>]
.select()根据css选择器获取所有匹配的标签,返回一个list
input_list = soup.select("input[type=text]")
print(input_list)
# [<input name="username" placeholder="请输入用户名" type="text"/>, <input name="pwd" placeholder="请输入密码" type="text"/>]
关系与操作
使用较少,选读:
| 属性/方法 | 描述 |
|---|---|
| children | 获取所有的后代标签,返回迭代器 |
| descendants | 获取所有的后代标签,返回生成器 |
| index() | 检查某个标签在当前标签中的索引值 |
| clear() | 删除后代标签,保留本标签,相当于清空 |
| decompose() | 删除标签本身(包括所有后代标签) |
| extract() | 同.decomponse()效果相同,但会返回被删除的标签 |
| decode() | 将当前标签与后代标签转换字符串 |
| decode_contents() | 将当前标签的后代标签转换为字符串 |
| encode() | 将当前标签与后代标签转换字节串 |
| encode_contents() | 将当前标签的后代标签转换为字节串 |
| append() | 在当前标签内部追加一个标签(无示例) |
| insert() | 在当前标签内部指定位置插入一个标签(无示例) |
| insert_before() | 在当前标签前面插入一个标签(无示例) |
| insert_after() | 在当前标签后面插入一个标签(无示例) |
| replace_with() | 将当前标签替换为指定标签(无示例) |
.children获取所有的后代标签,返回迭代器
form = soup.find("form")
print(form.children)
# <list_iterator object at 0x0000025665D5BDD8>
.descendants获取所有的后代标签,返回生成器
form = soup.find("form")
print(form.descendants)
# <generator object descendants at 0x00000271C8F0ACA8>
.index()检查某个标签在当前标签中的索引值
body = soup.find("body")
form = soup.find("form")
print(body.index(form))
# 3
.clear()删除后代标签,保留本标签,相当于清空
form = soup.find("form")
form.clear()
print(form) # None
print(soup)
# 清空了form
.decompose()删除标签本身(包括所有后代标签)
form = soup.find("form")
form..decompose()
print(form) # None
print(soup)
# 删除了form
.extract()同.decomponse()效果相同,但会返回被删除的标签
form = soup.find("form")
form..extract()
print(form) # 被删除的内容
print(soup)
# 被删除了form
.decode()将当前标签与后代标签转换字符串,.decode_contents()将当前标签的后代标签转换为字符串
form = soup.find("form")
print(form.decode()) # 包含form
print(form.decode_contents()) # 不包含form
.encode()将当前标签与后代标签转换字节串,.encode_contents()将当前标签的后代标签转换为字节串
form = soup.find("form")
print(form.encode()) # 包含form
print(form.encode_contents()) # 不包含form
标签内容
以下方法都比较常用:
| 属性/方法 | 描述 |
|---|---|
| name | 获取标签名称 |
| attrs | 获取标签属性 |
| text | 获取该标签下的所有文本内容(包括后代) |
| string | 获取该标签下的直系文本内容 |
| is_empty_element | 判断是否是空标签或者自闭合标签 |
| get_text() | 获取该标签下的所有文本内容(包括后代) |
| has_attr() | 检查标签是否具有该属性 |
.name获取标签名称
form = soup.find("form")
print(form.name)
# form
.attrs获取标签属性
form = soup.find("form")
print(form.attrs)
# {'action': '#', 'method': 'post', 'enctype': 'multipart/form-data'}
.is_empty_element判断是否是空标签或者自闭合标签
input = soup.find("input")
print(input.is_empty_element)
# True
.get_text()与text获取该标签下的所有文本内容(包括后代)
form = soup.find("form")
print(form.get_text())
print(form.text)
string获取该标签下的直系文本内容
form = soup.find("form")
print(form.get_text())
print(form.string)
.has_attr()检查标签是否具有该属性
form = soup.find("form")
print(form.has_attr("action"))
# True
xPath模块
xPath模块的作用与bs4相同,都是查找标签。
但是xPath模块的通用性更强,它的语法规则并不限于仅在Python中使用。
作为一门小型的专业化查找语言,xPath在Python中被集成在了lxml模块中,所以直接下载安装就可以开始使用了。
pip3 install lxml
加载文档:
from lxml import etree
# 解析网络爬取的html源代码
root = etree.HTML(response.text,,etree.HTMLParser()) # 加载整个HTML文档,并且返回根节点<html>
# 解析本地的html文件
root = etree.parse(fileName,etree.HTMLParser())
基本选取符
基本选取符:
| 符号 | 描述 |
|---|---|
| / | 从根节点开始选取 |
| // | 不考虑层级关系的选取节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 属性检测 |
| [num] | 选取第n个标签元素,从1开始 |
| /@attrName | 选取当前元素的某一属性 |
| * | 通配符 |
| /text() | 选取当前节点下的直系文本内容 |
| //text() | 选取当前文本下的所有文本内容 |
| | | 返回符号两侧所匹配的全部标签 |
以下是示例:
注意:xPath选择完成后,返回的始终是一个list,与jQuery类似,可以通过Index取出Element对象
from lxml import etree
root = etree.parse("./testDataDocument.html",etree.HTMLParser())
# 从根节点开始找 /
form_list = root.xpath("/html/body/form")
print(form_list) # [<Element form at 0x203bd29c188>]
# 不考虑层级关系的选择节点 //
input_list = root.xpath("//input")
print(input_list)
# 从当前的节点开始选择 即第一个form表单 ./
select_list = form_list[0].xpath("./fieldset/select")
print(select_list)
# 选择当前节点的父节点 ..
form_parent_list = form_list[0].xpath("..")
print(form_parent_list) # [<Element body at 0x1c946e4c548>]
# 属性检测 @ 选取具有name属性的input框
input_username_list = root.xpath("//input[@name='username']")
print(input_username_list)
# 属性选取 @ 获取元素的属性
attrs_list = root.xpath("//p/@title")
print(attrs_list)
# 选取第n个元素,从1开始
p_text_list = root.xpath("//p[2]/text()")
print(p_text_list)
# 通配符 * 选取所有带有属性的标签
have_attrs_ele_list = root.xpath("//*[@*]")
print(have_attrs_ele_list)
# 获取文本内容-直系
print(root.xpath("//form/text()"))
# 结果:一堆\r\n
# 获取文本内容-非直系
print(root.xpath("//form//text()"))
# 结果:本身和后代的text
# 返回所有input与p标签
ele_list = root.xpath("//input|//p")
print(ele_list)
表达式形式
你可以指定逻辑运算符,大于小于等。
from lxml import etree
root = etree.parse("./testDataDocument.html",etree.HTMLParser())
# 返回属性值price大于或等于20的标签
price_ele_list = root.xpath("//*[@price>=20]")
print(price_ele_list)
xPath轴关系
xPath中拥有轴这一概念,不过相对来说使用较少,它就是做关系用的。了解即可:
| 轴 | 示例 | 说明 |
|---|---|---|
| ancestor | xpath(‘./ancestor::*’) | 选取当前节点的所有先辈节点(父、祖父) |
| ancestor-or-self | xpath(‘./ancestor-or-self::*’) | 选取当前节点的所有先辈节点以及节点本身 |
| attribute | xpath(‘./attribute::*’) | 选取当前节点的所有属性 |
| child | xpath(‘./child::*’) | 返回当前节点的所有子节点 |
| descendant | xpath(‘./descendant::*’) | 返回当前节点的所有后代节点(子节点、孙节点) |
| following | xpath(‘./following::*’) | 选取文档中当前节点结束标签后的所有节点 |
| following-sibing | xpath(‘./following-sibing::*’) | 选取当前节点之后的兄弟节点 |
| parent | xpath(‘./parent::*’) | 选取当前节点的父节点 |
| preceding | xpath(‘./preceding::*’) | 选取文档中当前节点开始标签前的所有节点 |
| preceding-sibling | xpath(‘./preceding-sibling::*’) | 选取当前节点之前的兄弟节点 |
| self | xpath(‘./self::*’) | 选取当前节点 |
功能函数
功能函数更多的是做模糊搜索,这里举几个常见的例子,一般使用也不多:
| 函数 | 示例 | 描述 |
|---|---|---|
| starts-with | xpath(‘//div[starts-with(@id,”ma”)]‘) | 选取id值以ma开头的div节点 |
| contains | xpath(‘//div[contains(@id,”ma”)]‘) | 选取id值包含ma的div节点 |
| and | xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘) | 选取id值包含ma和in的div节点 |
| text() | xpath(‘//div[contains(text(),”ma”)]‘) | 选取节点文本包含ma的div节点 |
element对象
上面说过,使用xPath进行筛选后得到的结果都是一个list,其中的成员就是element标签对象。
以下方法都是操纵element标签对象的,比较常用。
首先是针对自身标签的操作:
| 属性 | 描述 |
|---|---|
| tag | 返回元素的标签类型 |
| text | 返回元素的直系文本 |
| tail | 返回元素的尾行 |
| attrib | 返回元素的属性(字典形式) |
演示如下:
from lxml import etree
root = etree.parse("./testDataDocument.html",etree.HTMLParser())
list(map(lambda ele:print(ele.tag),root.xpath("//option")))
list(map(lambda ele:print(ele.text),root.xpath("//option"))) # 常用
list(map(lambda ele:print(ele.tail),root.xpath("//option")))
list(map(lambda ele:print(ele.attrib),root.xpath("//option"))) # 常用
针对当前element对象属性的操作,用的不多:
| 方法 | 描述 |
|---|---|
| clear() | 清空元素的后代、属性、text和tail也设置为None |
| get() | 获取key对应的属性值,如该属性不存在则返回default值 |
| items() | 根据属性字典返回一个列表,列表元素为(key, value) |
| keys() | 返回包含所有元素属性键的列表 |
| set() | 设置新的属性键与值 |
针对当前element对象后代的操作,用的更少:
| 方法 | 描述 |
|---|---|
| append() | 添加直系子元素 |
| extend() | 增加一串元素对象作为子元素 |
| find() | 寻找第一个匹配子元素,匹配对象可以为tag或path |
| findall() | 寻找所有匹配子元素,匹配对象可以为tag或path |
| findtext() | 寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path |
| insert() | 在指定位置插入子元素 |
| iter() | 生成遍历当前元素所有后代或者给定tag的后代的迭代器 |
| iterfind() | 根据tag或path查找所有的后代 |
| itertext() | 遍历所有后代并返回text值 |
| remove() | 删除子元素 |
高性能爬虫
后端准备
Flask作为后端服务器:
from flask import Flask
import time
app = Flask(__name__,template_folder="./")
@app.route('/index',methods=["GET","POST"])
def index():
time.sleep(2)
return "index...ok!!!"
@app.route('/news')
def news():
time.sleep(2)
return "news...ok!!!"
@app.route('/hot')
def hot():
time.sleep(2)
return "hot...ok!!!"
if __name__ == '__main__':
app.run()
同步爬虫
如果使用同步爬虫对上述服务器的三个url进行爬取,花费的结果是六秒:
import time
from requests import Session
headers = {
"user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
urls = [
"http://127.0.0.1:5000/index",
"http://127.0.0.1:5000/news",
"http://127.0.0.1:5000/hot",
]
start = time.time()
def func(url):
session = Session()
response = session.get(url)
return response.text
# 回调函数,处理后续任务
def callback(result): # 获取结果
print(result)
for url in urls:
res = func(url)
callback(res)
end = time.time()
print("总用时:%s秒" % (end - start))
ThreadPoolExecutor
使用多线程则基本两秒左右即可完成:
import time
from concurrent.futures import ThreadPoolExecutor
from requests import Session
headers = {
"user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
urls = [
"http://127.0.0.1:5000/index",
"http://127.0.0.1:5000/news",
"http://127.0.0.1:5000/hot",
]
start = time.time()
def func(url):
session = Session()
response = session.get(url)
return response.text
# 回调函数
def callback(obj): # 期程对象
print(obj.result())
pool = ThreadPoolExecutor(max_workers=4)
for url in urls:
res = pool.submit(func, url)
# 为期程对象绑定回调
res.add_done_callback(callback)
pool.shutdown(wait=True)
end = time.time()
print("总用时:%s秒" % (end - start))
asyncio&aiohttp
线程的切换开销较大,可使用切换代价更小的协程进行实现。
由于协程中不允许同步方法的出现,requests模块下的请求方法都是同步请求方法,所以需要使用aiohttp模块下的异步请求方法完成网络请求。
现今的所谓异步,其实都是用I/O多路复用技术来完成,即在一个线程下进行where循环,监听描述符,即eventLoop。
import asyncio
import time
import aiohttp
headers = {
"user-agent": "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
urls = [
"http://127.0.0.1:5000/index",
"http://127.0.0.1:5000/news",
"http://127.0.0.1:5000/hot",
]
start = time.time()
async def func(url):
# 在async协程中,所有的阻塞方法都需要通过await手动挂起
# 并且,如果存在同步方法,则还是同步执行,必须是异步方法,所以这里使用aiohttp模块发送请求
async with aiohttp.ClientSession() as session:
async with await session.get(url) as response:
# text():返回字符串形式的响应数据
# read(): 返回二进制格式响应数据
# json(): json格式反序列化
result = await response.text() # aiohttp中是一个方法
return result
# 回调函数
def callback(obj): # 期程对象
print(obj.result())
# 创建协程任务列表
tasks = []
for url in urls:
g = func(url) # 创建协程任务g
task = asyncio.ensure_future(g) # 注册协程任务
task.add_done_callback(callback) # 绑定回调,传入期程对象
tasks.append(task) # 添加协程任务到任务列表
# 创建事件循环
loop = asyncio.get_event_loop()
# 执行任务,并且主线程会等待协程任务列表中的所有任务处理完毕后再执行
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print("总用时:%s秒" % (end - start))
selenium模块
selenium是Python实现浏览器自动化操作的一款模块。
通过它我们可以让代码控制浏览器,从而进行数据爬取,尤其在以下两个地方该模块的作用更加强大:
- 获取整张页面的数据,对有的页面来说前后端分离的API接口太难找了,使用requests模块根本找不到发送加载数据的接口
- 进行自动登录
下载安装:
pip3 install selenium
由于要操纵浏览器,所以要下载对应的驱动文件,需要注意的是驱动版本需要与浏览器版本一一对应:
如果是MAC平台,解压到如下路径,win平台解压到任意位置皆可:
/usr/local/bin
由于我们使用的是chorme浏览器,所以只需要实例化出其操纵对象即可:
from selenium import webdriver
driver = webdriver.Chrome()
以后的操纵都是操纵该实例对象,如果你使用其他版本浏览器,请自行下载驱动,支持的浏览器如下:
driver = webdriver.Firefox()
driver = webdriver.Edge()
driver = webdriver.PhantomJS()
driver = webdriver.Safari()
基本使用
以下是基本操纵实例,实例将展示如何搜索博客园:
from selenium import webdriver
import time
# 载入驱动
driver = webdriver.Chrome(r"./chromedriver.exe")
# 打开百度页面
driver.get("https://www.baidu.com")
# 找到搜索框,输入博客园
driver.find_element_by_id("kw").send_keys("博客园")
time.sleep(2)
driver.find_element_by_id('su').click()
time.sleep(2)
# 关闭浏览器
driver.quit()
元素定位
webdriver提供了很多元素定位方法,常用的如下:
driver.find_element_by_id()
driver.find_element_by_name()
driver.find_element_by_class_name()
driver.find_element_by_tag_name()
driver.find_element_by_link_text()
driver.find_element_by_partial_link_text()
driver.find_element_by_xpath()
driver.find_element_by_css_selector()
ifarme定位
对于webdriver来说,它拥有一层作用域。
默认是在顶级作用域中,如果出现了ifarme标签,则必须切换到ifarme标签的作用域才能查找其里面的元素。
如下,想查找其中的button:
<div id="modal">
<iframe id="buttonframe"name="myframe"src="https://seleniumhq.github.io">
<button>Click here</button>
</iframe>
</div>
如果直接获取button则不会生效,因为目前作用域是外部的html标签中,不能获取内部iframe的作用域:
# 这不会工作
driver.find_element(By.TAG_NAME, 'button').click()
正确的方法是找到ifarme标签,对其进行切换作用域的操作:
# 存储网页元素
iframe = driver.find_element(By.CSS_SELECTOR, "#modal > iframe")
# 切换到选择的 iframe
driver.switch_to.frame(iframe)
# 单击按钮
driver.find_element(By.TAG_NAME, 'button').click()
如果您的frame或iframe具有id或name属性,则可以使用该属性。如果名称或 id 在页面上不是唯一的, 那么将切换到找到的第一个。
# 通过 id 切换框架
driver.switch_to.frame('buttonframe')
# 单击按钮
driver.find_element(By.TAG_NAME, 'button').click()
还可以通过索引值进行切换:
# 切换到第 2 个框架
driver.switch_to.frame(1)
退出当前iframe的作用域,使用以下代码:
# 切回到默认内容
driver.switch_to.default_content()
交互相关
我们可以与浏览器BOM或者element进行交互。
如找到搜索框,使用send_keys()即可输入内容,clear()即可清空内容。
再比如找到button使用click()即可触发单击事件。
更多方法请参照官方文档,截图也在其中:
动作链
如果碰到滑动验证的操作,则需要使用动作链进行。
上述的交互中,如send_keys()与click()都是一次性完成的,如果是非一次性的操作如拖拽,滑动的就可以通过动作链完成。
动作链的官方文档,包括获取当前元素的大小,配合截图使用有奇效,举个例子,截图到当前的验证码页面,然后使用第三方打码工具进行解析验证码:
from selenium import webdriver
from time import sleep
#导入动作链对应的类
from selenium.webdriver import ActionChains
bro = webdriver.Chrome(executable_path='./chromedriver')
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
#如果定位的标签是存在于iframe标签之中的则必须通过如下操作在进行标签定位
bro.switch_to.frame('iframeResult')#切换浏览器标签定位的作用域
div = bro.find_element_by_id('draggable')
#动作链
action = ActionChains(bro)
#点击长按指定的标签
action.click_and_hold(div)
for i in range(5):
#perform()立即执行动作链操作
#move_by_offset(x,y):x水平方向 y竖直方向
action.move_by_offset(17,0).perform()
sleep(0.5)
#释放动作链
action.release()
bro.quit()
执行脚本
如果webdriver实例中没有实现某些方法,则可以通过执行Js代码来完成,比如下拉滑动条:
from selenium import webdriver
driver = webdriver.Chrome(r"./chromedriver.exe")
driver.get('https://www.jd.com/')
# 执行脚本:滑动整个页面
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
源码数据
上面提到过,如果使用requets模块访问某一url却没有拿到想要的数据,那么很可能是前后端分离通过RESTful APIs进行数据交互。
这个时候我们可以使用selenium模块来对同一url发起请求,由于是浏览器打开,所有的RESTFUL API都会进行请求,然后直接通过属性page_source解析返回的源码数据:
from selenium import webdriver
from lxml import etree
driver=webdriver.Chrome(r"./chromedriver.exe",)
driver.get('https://www.baidu.com/')
source_code = driver.page_source # 获取网页源代码
# 直接获取百度的图片地址
root = etree.HTML(source_code,parser=etree.HTMLParser())
driver.close()
img_src = "http:" + root.xpath(r"//*[@id='s_lg_img_new']")[0].attrib.get("src")
print(img_src)
节点操作
上面我们通过使用lxml模块来解析源码中的百度图片地址,其实可以不用这么麻烦。
Selenium也提供了节点操作,选取节点、获取属性等:
from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
driver = webdriver.Chrome(r"./chromedriver.exe",)
driver.get('https://www.amazon.cn/')
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.ID, 'cc-lm-tcgShowImgContainer')))
tag = driver.find_element(By.CSS_SELECTOR, '#cc-lm-tcgShowImgContainer img')
# 获取标签属性,
print(tag.get_attribute('src'))
# 获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
driver.close()
延时等待
在Selenium中,get()方法会在网页框架加载结束后结束执行,此时如果获取page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的Ajax请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待:
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。示例如下:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
driver=webdriver.Chrome(r"./chromedriver.exe",)
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
driver.implicitly_wait(10)
driver.get('https://www.baidu.com')
input_tag=driver.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
contents=driver.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents)
driver.close()
显示等待:
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
driver=webdriver.Chrome(r"./chromedriver.exe",)
driver.get('https://www.baidu.com')
input_tag=driver.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
#显式等待:显式地等待某个元素被加载
wait=WebDriverWait(driver,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
contents=driver.find_element(By.CSS_SELECTOR,'#content_left')
print(contents)
driver.close()
关于等待条件,其实还有很多,比如判断标题内容,判断某个节点内是否出现了某文字等。more
cookie操作
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
from selenium import webdriver
driver = webdriver.Chrome(r"./chromedriver.exe",)
driver.get('https://www.zhihu.com/explore')
print(driver.get_cookies())
driver.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
print(driver.get_cookies())
driver.delete_all_cookies()
print(driver.get_cookies())
异常处理
屏蔽掉所有可能出现的异常:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
try:
driver=webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.switch_to.frame('iframssseResult')
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
driver.close()
无头操作
每次使用selenium时都会打开一个浏览器,能不能有什么办法让他隐藏界面呢?
指定参数即可,这种没有界面的浏览也可以称其为无头浏览器:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 设置配置项
chrome_options = Options()
chrome_options.add_argument('--headless')
# 指定配置
driver = webdriver.Chrome(r"./chromedriver.exe",chrome_options=chrome_options)
driver.get("http://www.baidu.com")
driver.close()
规避检测
可能有的门户网站已经对selenium做出了检测,如果检测到是该脚本执行可能不允许你访问API,此时就可以通过伪造信息达到潜行的效果。
将selenium伪装成人为操作:
#实现规避检测
from selenium.webdriver import ChromeOptions
#实现规避检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 指定配置
driver = webdriver.Chrome(executable_path='./chromedriver',options=option)
driver.get("http://www.baidu.com")
driver.close()
Scrapy框架基础
基本介绍
Scrapy框架是Python中最出名的一款爬虫框架,本身基于twisted异步框架封装完成。
它有着基本的五大组件,整个框架架构如下图所示:

Scrapy 组件介绍
引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见下面的数据流部分。
调度器(SCHEDULER) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
- 在将请求发送到下载器之前处理请求(即,在Scrapy将请求发送到网站之前);
- 在传递给SPIDERS之前更改收到的响应;
- 发送新的请求,而不是将收到的响应传递给SPIDERS;
- 将响应传递给SPIDERS,而无需获取网页;
- 默默地丢弃一些请求。
爬虫中间件(Spider Middlewares) 位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
整个爬取的数据流:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该Spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
下载安装
在MAC/LINUX下安装该框架十分简单:
pip3 install scrapy
如果是Windows平台,则稍微有些麻烦,因为你需要安装很多依赖库:
pip3 install wheel # 安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
pip3 install lxml
pip3 install pyopenssl
下载并安装pywin32:
pip3 install pywin32
下载并安装twisted的wheel文件,CP对应Python版本:
# 下载whell文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
安装Scrapy:
pip3 install scrapy
安装完成后,在终端输入scrapy,如果有反应则代表安装成功。
如果没有反应,重新安装scrapy:
pip uninstall scrapy
pip3 install scrapy
它会给你一个提示:
Installing collected packages: scrapy
WARNING: The script scrapy.exe is installed in 'C:\Users\yunya\AppData\Roaming\Python\Python36\Scripts' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed scrapy-2.4.1
你需要将提示中的路径加入环境变量即可。
命令行工具
以下是常用的命令行,首先是全局命令,即意味着你在终端中任何目录下都能够运行:
| 命令 | 描述 |
|---|---|
| scrapy -h | 查看帮助 |
| scrapy [command] -h | 查看某条命令的帮助 |
| scrapy startproject [ProjectName] | 创建项目 |
| scrapy genspider [SpiderName] <ur> | 创建爬虫程序 |
| scrapy settings [options] [command] | 查看爬虫的程序配置信息,如果是在项目下,则获取到项目的部署配置信息 |
| scrapy runspider [options] <spider_file> | 单独的运行某一个py文件 |
| scrapy fetch [options] <url> | 独立爬取一个页面,可以拿到请求头,如 scrapy fetch --headers http://www.baidu.com |
| scrapy shell [options] <url> | 打开shell调试,直接向某一地址发送请求 |
| scrapy view [options] <url> | 打开浏览器,发送本次请求 |
| scrapy version [-v] | 查看scrapy的版本,添加-v查看scrapy依赖库的版本 |
其次是局部命令,指只有在Scrapy项目下运行才能生效的命令:
| 命令 | 描述 |
|---|---|
| scrapy crawl [options] <spider> | 运行爬虫程序,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False |
| scrapy check [options] <spider> | 检测爬虫程序中语法是否有错误 |
| scrapy list | 获取该项目下所有爬虫程序的名称 |
| scrapy parse [options] <url> | scrapy parse url地址 --callback 回调函数以此可以验证我们的回调函数是否正确 |
| scrapy bench | 压力测试 |
一些常用的全局options:
| options | 描述 |
|---|---|
| --help, -h | 获取帮助信息 |
| --logfile=FILE | 日志文件,如果省略,将抛出stderr |
| --loglevel=LEVEL, -L LEVEL | 日志级别,默认为info |
| --nolog | 禁止显示日志信息 |
| --profile=FILE | 将python cProfile统计信息写入FILE |
| --pidfile=FILE | 将进程ID写入FILE |
| --set=NAME=VALUE, -s NAME=VALUE | 设置/替代设置(可以重复) |
| --pdb | 在失败时启用pdb |
默认的命令只能在CMD中执行,如果向在IDE中执行,则需要新建一个py文件,使用execute函数进行命令的执行。
# 在项目目录下新建:entrypoint.py
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'xiaohua'])
目录介绍
以下是一个Scrapy项目的目录:
-- ScrapyProject/ # 项目文件夹
-- scrapy.cfg # 项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
-- project_name/ # 项目全局文件夹
__init__.py
items.py # 设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py # 数据处理行为,如:一般结构化的数据持久化
settings.py # 配置文件,如:递归的层数、并发数,延迟下载等。配置变量名必须大写
-- spiders/ # 爬虫文件夹,如:创建文件,编写爬虫规则
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py
Scrapy-爬虫
基本介绍
Spiders的主要工作、进行数据爬取和数据解析。
以下是一个爬虫程序的初始代码:
import scrapy
class CnblogsSpider(scrapy.Spider): # 基础的爬虫类
name = 'cnblogs' # 爬虫程序名称,非空且唯一
allowed_domains = ['www.cnblogs.com'] # 允许网络请求的域名,一般来说直接注释即可
start_urls = ['http://www.cnblogs.com/'] # 初始的网络请求
def parse(self, response): # 数据解析函数
pass
默认情况下,当执行该爬虫程序,会从start_urls中自动发生网络请求,并将返回的信息传入parse()方法,response是一个对象,可从中进行xpath解析等工作。
parse()方法的返回值非常有趣,一般来说当我们解析工作完成后就进行持久化存储,但是也可以再次的发送网络请求,所以parse()方法的返回值是多种多样的:
- 包含解析数据的字典
- Item对象,项目管道,用于持久化存储,临时存储数据的地方
- yield新的Request对象(新的Requests也需要指定一个回调函数)
- 或者是可迭代对象(对象中只包含Items或Request)
一般来说,我们都是这么做的,但是某些情况下你可能会发现我们需要爬取多个url并且会指定不同的回调函数(默认start_urls列表中的url回调函数都是parse()方法),那么该怎么做呢?你可以书写一个名为start_requests()的方法,并且自己使用Request对象来发送请求与绑定回调函数,当有start_request()方法后,start_urls列表中的url不会被自动发送请求:
import scrapy
from scrapy.http import Request
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
# allowed_domains = ['www.cnblogs.com']
start_urls = ['http://www.cnblogs.com/'] # 具有start_request()方法,start_urls列表中的urls不会自动发起请求
def start_requests(self):
yield Request(url="http://www.baidu.com",callback=self.baidu)
yield Request(url="http://www.biying.com",callback=self.biying)
def baidu(self,response):
print("baidu爬取完成...")
def biying(self,response):
print("biying爬取完成...")
def parse(self, response): # 失效
print(response)
如果你在爬虫程序中遇到编码问题无法正常解析response的内容,则更改编码格式:
import sys,os
sys.stdout=io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')
Spiders自定制
在Spiders类中,你可以进行各种各样的自定义:
| 属性/方法 | 描述 |
|---|---|
| name = "spiderName" | 定义爬虫名,scrapy会根据该值定位爬虫程序,非空且唯一 |
| allowed_domains = ['www.cnblogs.com'] | 定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动), 那么不属于该列表的域名及其子域名都不允许爬取 |
| start_urls = ['http://www.cnblogs.cn/'] | 如果没有指定url,就从该列表中读取url来生成第一个请求 |
| custom_settings | 值为一个字典,定义一些配置信息,在运行爬虫程序时,这些配置会覆盖项目级别的配置 所以custom_settings必须被定义成一个类属性,由于settings会在类实例化前被加载 |
| settings | 通过self.settings['配置项的名字']可以访问settings.py中的配置,如果自己定义了custom_settings还是以自己的为准 |
| logger | 日志名默认为spider的名字,可通过self.settings['BOT_NAME']进行指定 |
| start_requests() | 该方法用来发起第一个Requests请求,且必须返回一个可迭代的对象。它在爬虫程序打开时就被Scrapy调用,Scrapy只调用它一次。 默认从start_urls里取出每个url来生成Request(url, dont_filter=True) |
| closed(reason) | 爬虫程序结束时自动触发的方法 |
Request请求
发送请求时,如何指定cookies或这请求头呢?其实在Request对象中拥有很多参数:
| 参数 | 描述 |
|---|---|
| url | str或者bytes类型,发送请求的地址 |
| callback | 回调函数,必须是一个可调用对象 |
| method | str类型,发送请求的方式 |
| header | dict类型,本次请求所携带的请求头 |
| body | str类型或者bytes类型,发送的请求体 |
| cookies | dict类型,本次请求所携带的cookies |
| meta | dict类型,如当前的request对象指定meta是{"name":"test"},则后面的response对象可通过response.meta.get("name")获得该值,主要用于不同组件之间的数据传递 |
| encoding | str类型,编码方式,默认为utf8 |
| priority | int类型,请求优先级,优先级高的先执行 |
| dont_filter | bool类型,取消过滤?默认是false,当多次请求的地址、参数均相同时,默认后面的请求将取消 |
| errback | 请求出现异常时的回调函数 |
meta是一个值得注意的地方:
import scrapy
from scrapy.http import Request
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
# allowed_domains = ['www.cnblogs.com']
def start_requests(self):
yield Request(url="https://www.cnblogs.com",meta={"name":"博客园"},callback=self.parse,dont_filter=True)
yield Request(url="https://www.baidu.com",meta={"name":"百度"},callback=self.parse,dont_filter=True)
def parse(self, response):
print(response.meta.get("name"))
# 博客园
# 百度
# meta通常传递跨组件数据
Response返回
来看一下response对象中的一些基本方法/属性:
| 属性 | 描述 |
|---|---|
| url | 获取本次request请求的url地址 |
| status | 获取本次request请求的状态码 |
| body | 获取HTML响应正文,返回的是bytes格式内容,因此如果请求的是图片,可直接拿到它进行写入 |
| text | 获取HTML响应正文,返回的是str格式内容 |
| encoding | 获取本次请求的编码格式,你也可以对本次请求的编码格式进行设定 |
| request | 获取发送本次请求的request对象,如:response.request.method进行获取本次的请求方式 |
| meta | 获取本次request请求中传递的一些参数 |
数据解析
在response对象中,会包含xpath()方法与css()方法。他们本身都是属于response.selector中的方法,完整写法与简写形式如下:
response.selector.css()
response.css()
response.selector.xpath()
response.xpath()
注意这里的xpath()方法返回的不是一个单纯的List,而是selector的List:
def parse(self, response):
print(response.xpath("//title"))
# [<Selector xpath='//title' data='<title>博客园 - 开发者的网上家园</title>'>]
下面是一些xpath返回列表的常用方法:
| 方法 | 描述 |
|---|---|
| extract() | 从返回的selector列表中拿到全部的元素的xpath选取内容 |
| extract_first() | 从返回的selector列表中拿到第一个元素的xpath选取内容 |
如果是css语法进行选择,则更多的是在选择器中拿到想要的东西:
| 选取符 | 描述 |
|---|---|
| ::text | 拿到文本 |
| ::attr(attrName) | 获取属性 |
| extract() | 从返回的selector列表中拿到全部的元素的xpath选取内容 |
| extract_first() | 从返回的selector列表中拿到第一个元素的xpath选取内容 |
示例如下:
print(response.css("a::text"))
print(response.css("a::attr(href)"))
去重规则
去重规则的意思就是说如果一个爬虫程序已经爬取过该URL,则其他的爬虫程序就不要继续爬取了。
默认为指定去重:
import scrapy
from scrapy.http import Request
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
def start_requests(self):
# dont_filter=False为开启去重
yield Request("http://www.cnblogs.com/",callback=self.parse,dont_filter=False)
yield Request("http://www.cnblogs.com/",callback=self.parse,dont_filter=False)
def parse(self, response):
print("爬取...")
# 只运行一次
如果想要修改去重规则,如第一次访问被拒绝后尝试更换代理继续访问,就可以进行自定制:
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter' # 默认的去重规则帮我们去重,去重规则在内存中维护了一个set,当请求成功Response后就会将URL进行记录,如果再次爬取该URL就直接跳过
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen,去重规则放文件中
自己写一个类:
class MyDupeFilter:
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
# 书写去重规则,如果返回False则代表没有重复,如果返回True则代表有重复,取消本次请求
return False
def open(self): # can return deferred
pass
def close(self, reason): # can return a deferred
pass
def log(self, request, spider): # log that a request has been filtered
pass
最后记得在settings.py中修改配置项为自己的类。
headers&cookies
在scrapy中,cookies都是默认携带的,就像requests模块的session一样。
在settings.py中可以将其干掉。
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
处了在发送Request对象时指定headers,也可以在settings.py中进行,配置完成后所有的Request都会携带该请求头字典:
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
Scrapy-持久化
Item对象
在数据解析paser()方法完成后,可以返回一个Item对象。
Item对象你可以将它理解为在内存中临时存储一组数据的地方,因为每次爬取的字段都是有限的,如歌曲名与歌手。
所以我们可以将每一次的数据解析出的歌曲名和歌手返回给Item对象,由Item对象交给PIPE对象进行持久化存储。
可以这么认为,一共分为三部分:
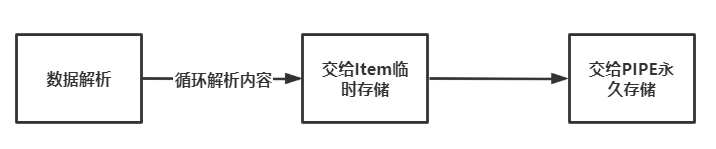
一般来讲,前两步都很简单,以下以爬取网易云音乐TOP100为例:
第一步,书写Spider内容:
import scrapy
from ..items import WangyiMusic
class WangyimusicSpider(scrapy.Spider):
name = 'wangyiMusic'
# allowed_domains = ['music.163.com']
start_urls = ['https://music.163.com/discover/toplist']
def parse(self, response):
message = response.xpath("//textarea[@id='song-list-pre-data']/text()").extract()[0]
import json
result = json.loads(message)
for row in result:
item = WangyiMusic() # 实例化Item对象
item["name"] = row.get("album").get("name") # 解析出的歌曲名字
item["singer"] = row.get("artists")[0].get("name") # 解析出歌手的名字
yield item
第二步,书写Item.py,新建一个类:
import scrapy
class WangyiMusic(scrapy.Item):
name = scrapy.Field()
singer = scrapy.Field()
现在,当我们运行爬虫程序,它就会将每一次循环到的歌曲和歌手信息放入Item对象中做临时存储了。
PIPE对象
光有临时存储还不够,我们需要指定永久存储,而PIPE则是从Item中取出临时数据进行永久存储的。
当我们打开pipelines.py后,会发现它给定了一个类:
class ProjectNamePipeline:
def process_item(self, item, spider):
# spider是爬虫对象,可通过settings拿到配置文件,将是一个字典
# 如 spider.settings.get("xxx")等等...
return item
其实,该类可以指定很多钩子函数:
class ProjectNamePipeline(object):
def __init__(self,v):
# 正常实例化执行,一般不会走,如果走只执行一次,在美哟㐉form_crawler方法是才会走它
self.value = v
@classmethod
def from_crawler(cls, crawler):
"""
# 通过配置文件进行实例化的过程,一般都是走这个方法,只执行一次
"""
val = crawler.settings.getint('MMMM')
return cls(val)
def open_spider(self,spider):
"""
# 爬虫刚启动时执行一次
"""
print('start')
def close_spider(self,spider):
"""
# 爬虫关闭时执行一次
"""
print('close')
def process_item(self, item, spider):
# 操作并进行持久化逻辑函数
# return item表示会被后续的pipeline继续处理。可进行多方存储,MySQL、Redis等地方
return item
# 如果抛出异常,则表示将item丢弃,
# from scrapy.exceptions import DropItem
# raise DropItem()
这里的process_item()方法和open_spider()以及close_spider()方法比较常用。
注意,持久化存储可以存入多个地方,如MySQL/Redis/Files中,前提是上一个类的process_item()方法必须将item对象返回。
光看了这些还不够,你需要在配置文件中配置默认的持久化存储方案类:
ITEM_PIPELINES = {
'scrapyProject01.pipelines.FilesPipeline': 300,
'scrapyProject01.pipelines.RedisPipeline': 200, # 优先级小的先进行存储
}
尝试一下,将爬取到的歌手信息和歌曲名称存放到Redis/Fiels中:
注意:持久化存储对应的文本文件的类型只可以为:'json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle'
from itemadapter import ItemAdapter
# 从Item中提取数据存储到文件 优先级300 后
class FilesPipeline:
def open_spider(self,spider):
self.f = open(file="./MusicTop100.cvs",mode="a+",encoding="utf-8")
def process_item(self, item, spider):
name = item["name"]
singer = item["singer"]
self.f.write("歌曲名:%s 歌手:%s\n"%(name,singer))
return item
def close_spider(self,spider):
self.f.close()
# 从Item中提取数据存储到Redis 优先级200 先
class RedisPipeline:
def open_spider(self,spider):
import redis
self.conn = redis.Redis(host="localhost", port=6379)
def process_item(self, item, spider):
name = item["name"]
singer = item["singer"]
self.conn.lpush(singer,name)
return item
def close_spider(self,spider):
self.conn.close()
图片存储
如果是爬取的图片,则数据直接处理出img的src属性,交给Item,再由Item交由一个继承于ImagesPipline的类直接存储即可。
依赖于pillow模块:
pip3 install pillow
如下所示,爬取B站的封面图,首先第一步是要确定爬取下来的图片存放路径:
# settings.py
# 图片存储的路径
IMAGES_STORE = './BiliBiliimages'
接下来就要书写spider爬虫程序:
import scrapy
from scrapy.http import Request
class BilibiliSpider(scrapy.Spider):
name = 'bilibili'
def start_requests(self):
# 取消去重规则,每次爬取到的图片都不一样
yield Request(url="https://manga.bilibili.com/twirp/comic.v1.Comic/GetRecommendComics", method="POST",
callback=self.parse, dont_filter=True)
def parse(self, response):
import json
result = json.loads(response.text).get("data").get("comics")
for img_message in result:
img_title = img_message.get("title")
img_src = img_message.get("vertical_cover")
# 将图片名字和src传入item对象
from ..items import BiliBiliImageItem
item = BiliBiliImageItem()
item["title"] = img_title
item["src"] = img_src
yield item
Item十分简单:
import scrapy
class BiliBiliImageItem(scrapy.Item):
title = scrapy.Field()
src = scrapy.Field()
最后是pipelines的书写,取出src并进行下载:
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class DownloadImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 下载图片
yield scrapy.Request(url=item["src"],method="GET",meta={"filename":item["title"]})
def file_path(self, request, response=None, info=None):
# 设定保存图片的名称
filename = request.meta.get('filename')
return filename + ".jpg"
def item_completed(self, results, item, info):
# 请求发送后执行的函数,用于执行后续操作,如返回Item对象等
"""
:returns :
[
(True,
{
'url': 'http://i0.hdslb.com/bfs/manga-static/9351bbb71a9726af47e3abce3ce8f3cecbed5b08.jpg',
'path': '新世纪福音战士.jpg', 'checksum': '95ce0e970b7198f23c4d67687bd56ba6',
'status': 'downloaded'
}
)
]
"""
if results[0][0] == True:
print("下载图片并保存成功...")
return item
else:
print("下载图片并保存失败...")
from scrapy.exceptions import DropItem
raise DropItem("download img fail,url\n%s"%results[0][1].get("url"))
别忘记在settings.py中指定PIPE:
ITEM_PIPELINES = {
'scrapyProject01.pipelines.DownloadImagesPipeline': 200,
}
Scrapy-中间件
配置中间件
settings.py中进行配置即可,优先级越小执行越靠前:
# 爬虫中间件
SPIDER_MIDDLEWARES = {
'spider1.middlewares.Spider1SpiderMiddleware': 543,
}
# 下载中间件
DOWNLOADER_MIDDLEWARES = {
'spider1.middlewares.Spider1DownloaderMiddleware': 543,
}
如果要进行自定制,就将自定制的类按照字符串的形式进行添加。
多个中间件的拦截方式同Falsk相同,并非同级返回。
如,下载中间件A/B/C,在执行A的process_start_request()时候抛出了错误,此时就执行C/B/A的process_spider_exception()方法。
爬虫中间件
以下是爬虫中间件的钩子函数,是Spiders和引擎的中间件,一般来讲不会涉及到网络:
from scrapy import signals
class Spider1SpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
# 创建spider(爬虫对象)的时候,注册一个信号
# 信号: 当爬虫的打开的时候 执行 spider_opened 这个方法
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# 下载完成后,执行,然后交给parse处理
return None
def process_spider_output(self, response, result, spider):
"""
经历过parse函数之后执行
:param response: 上一次请求返回的结果
:param result: yield的对象 包含 [item/Request] 对象的可迭代对象
:param spider: 当前爬虫对象
:return: 返回Request对象 或 Item对象
"""
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
"""如果执行parse抛出异常的话 会执行这个函数 默认不对异常处理交给下一个中间件处理"""
pass
def process_start_requests(self, start_requests, spider):
"""
爬虫启动时调用
:param start_requests: 包含 Request 对象的可迭代对象
:param spider:
:return: Request 对象
"""
for r in start_requests:
yield r
def spider_opened(self, spider):
# 生成爬虫日志
spider.logger.info('Spider opened: %s' % spider.name)
下载中间件
下面是下载中间的钩子函数,下载中间件是Download与引擎中的中间件,涉及网络,因此代理等相关配置应该在下载中间件中进行:
class Spider1DownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
# 这个方法同上,和爬虫中间件一样的功能
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
"""
# 可进行UA伪装,user-agent
请求需要被下载时,经过所有下载中间件的process_request调用
spider处理完成,返回时调用
:param request:
:param spider:
:return:
None,继续往下执行,去下载
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新放到调度器中
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
return None
def process_response(self, request, response, spider):
"""
下载得到响应后,执行
:param request: 请求对象
:param response: 响应对象
:param spider: 爬虫对象
:return:
返回request对象,停止中间件,将Request对象重新放到调度器中
返回response对象,转交给其他中间件process_response
raise IgnoreRequest 异常: 调用Request.errback
"""
return response
def process_exception(self, request, exception, spider):
"""当下载处理器(download handler)或process_request() (下载中间件)抛出异常
:return
None: 继续交给后续中间件处理异常
Response对象: 停止后续process_exception方法
Request对象: 停止中间件,request将会被重新调用下载
"""
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
操纵cookie
可能有的页面需要你手动携带一个cookie,比如token验证等,此时就可以在下载中间件的process_request()方法中手动携带,
如下所示:
def process_request(self, request, spider):
# 先获取token token = ....
request.cookies.update({"token":"xxx"})
print(request.cookies)
return None
代理设置
为下载中间件中添加代理:
def get_proxy():
"""获取代理的函数"""
response = requests.get('http://134.175.188.27:5010/get/')
data = response.json()
return data["proxy"]
class ProxyDownloaderMiddleware(object):
"""下载中间件中的代理中间件"""
def process_request(self, request, spider):
request.meta['proxy'] = get_proxy()
return None
如果代理不可用,配置文件中设置重试:
RETRY_ENABLED = True # 是否开启超时重试
RETRY_TIMES = 2 # initial response + 2 retries = 3 requests 重试次数
RETRY_HTTP_CODES = [500, 502, 503, 504, 522, 524, 408, 429] # 重试的状态码
DOWNLOAD_TIMEOUT = 1 # 1秒没有请求到数据,主动放弃
Scrapy-settings.py
基本配置
配置文件中的配置项:
# -*- coding: utf-8 -*-
# Scrapy settings for step8_king project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
# 1. 爬虫名称
BOT_NAME = 'step8_king'
# 1.2 日志级别,强烈建议
LOG_LEVEL = "ERROR"
# 2. 爬虫应用路径
SPIDER_MODULES = ['step8_king.spiders']
NEWSPIDER_MODULE = 'step8_king.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 3. 客户端 user-agent请求头
# USER_AGENT = 'step8_king (+http://www.yourdomain.com)'
# Obey robots.txt rules
# 4. 禁止爬虫配置
# ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 5. 并发请求数
# CONCURRENT_REQUESTS = 4
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 6. 延迟下载秒数
# DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
# 7. 单域名访问并发数,并且延迟下次秒数也应用在每个域名
# CONCURRENT_REQUESTS_PER_DOMAIN = 2
# 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP
# CONCURRENT_REQUESTS_PER_IP = 3
# Disable cookies (enabled by default)
# 8. 是否支持cookie,cookiejar进行操作cookie
# COOKIES_ENABLED = True
# COOKIES_DEBUG = True
# Disable Telnet Console (enabled by default)
# 9. Telnet用于查看当前爬虫的信息,操作爬虫等...
# 使用telnet ip port ,然后通过命令操作
# TELNETCONSOLE_ENABLED = True
# TELNETCONSOLE_HOST = '127.0.0.1'
# TELNETCONSOLE_PORT = [6023,]
# 命令est()
# 10. 默认请求头(优先级低于request对象中的请求头)
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 11. 定义pipeline处理请求 值越小优先级越高 0-1000
# ITEM_PIPELINES = {
# 'step8_king.pipelines.JsonPipeline': 700,
# 'step8_king.pipelines.FilePipeline': 500,
# }
# 12. 自定义扩展,基于信号进行调用
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# # 'step8_king.extensions.MyExtension': 500,
# }
# 13. 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3
# 14. 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo
# 后进先出,深度优先
# DEPTH_PRIORITY = 0
# 基于硬盘的 DISK
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# 基于内存的 MEMORY
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先
# DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
# 15. 调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler' 这是一个类
# from scrapy.core.scheduler import Scheduler
# 16. 访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl'
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
"""
18. 启用缓存 一般不太用
目的用于将已经发送的请求或相应缓存下来,以便以后使用,
from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True
# 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
# 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0
# 缓存保存路径
# HTTPCACHE_DIR = 'httpcache'
# 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
爬虫速率
如果请求过于频繁,可能会遭遇封禁,因此可以设定爬虫的频次:
"""
17. 自动限速算法
from scrapy.contrib.throttle import AutoThrottle
自动限速设置
1. 获取最小延迟 DOWNLOAD_DELAY
2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY
3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY
4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间
5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY
target_delay = latency / self.target_concurrency
new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间
new_delay = max(target_delay, new_delay)
new_delay = min(max(self.mindelay, new_delay), self.maxdelay)
slot.delay = new_delay
"""
# 开始自动限速
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# 初始下载延迟
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# 最大下载延迟
# AUTOTHROTTLE_MAX_DELAY = 10
# The average number of requests Scrapy should be sending in parallel to each remote server
# 平均每秒并发数
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# 是否显示
# AUTOTHROTTLE_DEBUG = True
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
"""
代理相关
默认代理,一般放在环境变量中,即os.environ里,用的时候取就好了:
# 一般不用,取代理费事
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
方式一:使用默认
os.environ =
{
http_proxy:http://root:woshiniba@192.168.11.11:9999/
https_proxy:http://192.168.11.11:9999/
}
自定义代理配置:
def to_bytes(text, encoding=None, errors='strict'):
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors)
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 这里是写死的代理,可以通过一个函数获取
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': ''},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
# 随机取出一组代理
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
print "**************ProxyMiddleware have pass************" + proxy['ip_port']
else:
print "**************ProxyMiddleware no pass************" + proxy['ip_port']
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
# 在配置文件中注册中间件
DOWNLOADER_MIDDLEWARES = {
'step8_king.middlewares.ProxyMiddleware': 500,
}
Scrapy高级
全站爬取
上面的Scrapy都是基于spiders这个类,而全站爬取则是基于CrawlSpider这个类。
全站爬取的意思就是说将该网站所有的数据爬取下来,如下实例,爬取虾米音乐的目前所有动漫游戏相关曲目,共十条:
from prettytable import PrettyTable
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
table = PrettyTable(['歌曲名称', "专辑"])
# 全站爬取
class XiamiSpider(CrawlSpider):
name = 'xiami'
start_urls = [
'https://www.xiami.com/list?page=1&query=%7B%22genreType%22%3A2%2C%22genreId%22%3A%223344%22%7D&scene=genre&type=song']
# 链接提取器:根据指定规则(allow="正则")进行指定链接的提取
link = LinkExtractor(allow=r'page=\d+')
rules = (
# 规则解析器:将链接提取器提取到的链接进行指定规则(callback)的解析操作
# 自动发送请求
# 如果 follow 为True,则可以将链接提取器 继续作用到 连接提取器提取到的链接 所对应的页面中
Rule(link, callback="parse", follow=True), # 自动匹配 a标签,page自动翻页,自动执行回调
)
def parse(self, response, *args, **kwargs):
music_name_list = response.xpath(
"//*[@id='app']//div[@class='table-container'][1]//tr[@class]//div[@class='song-name em']//text()").extract()
music_album_list = response.xpath(
"//*[@id='app']//div[@class='table-container'][1]//tr[@class]//div[@class='album']//text()").extract()
for index in range(len(music_name_list)):
table.add_row([music_name_list[index].strip(), music_album_list[index].strip()])
def close(spider, reason):
print(table)
分布式爬虫
分布式爬虫就是在一台远程的机器上存储爬取的地址,以及爬取的结果。
由多台计算机在远程计算机上拿到爬取地址进行爬取,并且将爬取结果存储到远程计算机上。
单纯的Scrapy框架不能实现分布式,所以要用到scrapy-redis这个第三方模块实现:
- 如何实现分布式?
- 安装一个scrapy-redis的组件
- 原生的scarapy是不可以实现分布式爬虫,必须要让scrapy结合着scrapy-redis组件一起实现分布式爬虫。
- 为什么原生的scrapy不可以实现分布式?
- 调度器不可以被分布式机群共享
- 管道不可以被分布式机群共享
- scrapy-redis组件作用:
- 可以给原生的scrapy框架提供可以被共享的管道和调度器
- 实现流程
- 创建一个工程
- 创建一个基于CrawlSpider的爬虫文件
- 修改当前的爬虫文件:
- 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 将start_urls和allowed_domains进行注释
- 添加一个新属性:redis_key = 'sun' 可以被共享的调度器队列的名称
- 编写数据解析相关的操作
- 将当前爬虫类的父类修改成RedisCrawlSpider
- 修改配置文件settings
- 指定使用可以被共享的管道:
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 指定调度器:
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据(去重规则), 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定redis服务器:
- redis相关操作配置:
- 配置redis的配置文件:
- linux或者mac:redis.conf
- windows:redis.windows.conf
- 代开配置文件修改:
- 将bind 127.0.0.1进行删除
- 关闭保护模式:protected-mode yes改为no
- 结合着配置文件开启redis服务
- redis-server 配置文件
- 启动客户端:
- redis-cli
- 执行工程:
- scrapy runspider xxx.py
- 向调度器的队列中放入一个起始的url:
- 调度器的队列在redis的客户端中
- lpush xxx www.xxx.com
- 爬取到的数据存储在了redis的proName:items这个数据结构中
首先第一步:
pip install scrapy-redis
代码如下:
# 爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from fbsPro.items import FbsproItem
from scrapy_redis.spiders import RedisCrawlSpider
class FbsSpider(RedisCrawlSpider):
name = 'fbs'
redis_key = 'sun' # 从sun这个队列中取出url
rules = (
Rule(LinkExtractor(allow=r'type=4&page=\d+'), callback='parse_item', follow=True),
)
def parse_item(self, response):
tr_list = response.xpath('//*[@id="morelist"]/div/table[2]//tr/td/table//tr')
for tr in tr_list:
new_num = tr.xpath('./td[1]/text()').extract_first()
new_title = tr.xpath('./td[2]/a[2]/@title').extract_first()
item = FbsproItem()
item['title'] = new_title
item['new_num'] = new_num
yield item
然后是items.py:
import scrapy
class FbsproItem(scrapy.Item):
title = scrapy.Field()
new_num = scrapy.Field()
需要在settings.py中做配置:
#指定管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
#指定调度器
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
#指定redis
REDIS_HOST = '127.0.0.1' #redis远程服务器的ip(修改)
REDIS_PORT = 6379
增量式爬虫
增量式爬虫也非常简单,维护一个set(可以是redis),将每次爬取的url进行检测。
如果该url未被爬取,则爬取完成后将url放入set中,下次启动爬虫程序时就会检测,如果url在set中,就跳过本次爬取。
增量式就是在原本的数据基础上做增加。
反反扒策略
代理
如果一个网站对IP进行了频率限制,可以在发送请求时指定一个代理,由代理帮助你发送本次请求,且将返回结果交给你。
而使用代理又有以下三个名词:
透明:被请求服务器明确知道本次请求是由代理发起,并且也知道真实请求的IP地址
匿名:被请求服务器明确知道本次请求是由代理发起,但是不知道真实请求的IP地址
高匿:被请求服务器不知道本次请求是由代理发起,并且也不知道真实请求的IP地址
常用的代理相关网站:
- 快代理
- 西祠代理
- www.goubanjia.com
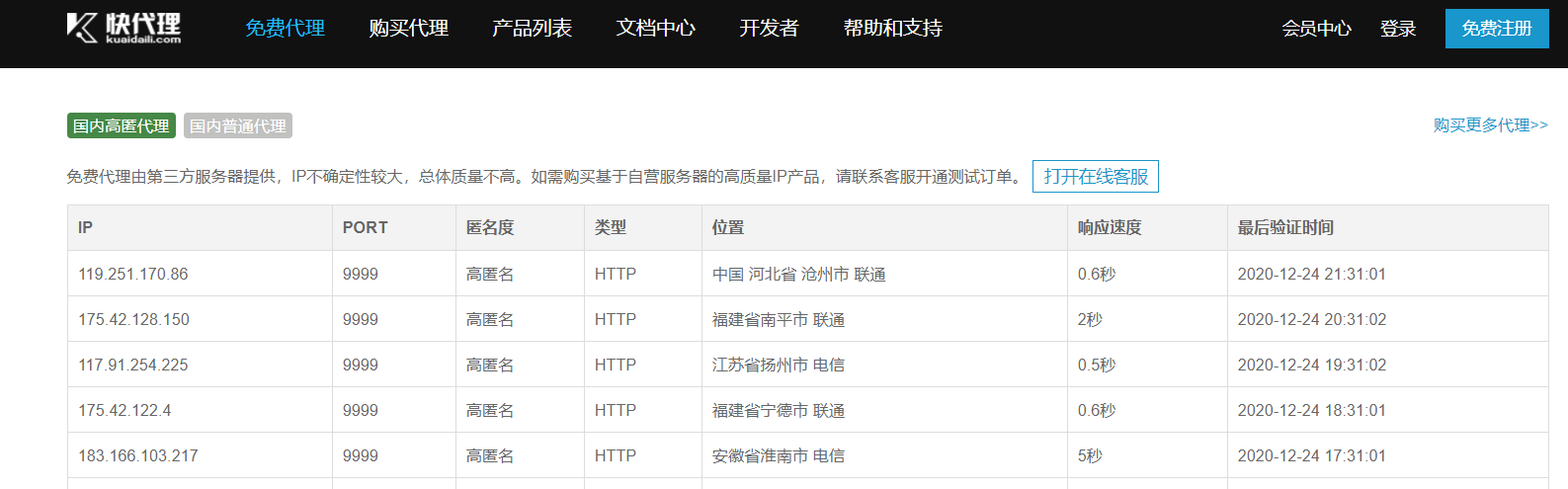
代理的类型一般有HTTP代理和HTTPS代理,我们在使用requests模块发送请求时可指定代理:
如下所示:
from requests import Session
headers = {
"user-agent":"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
proxies = {
"http": "36.230.165.45:8088",
}
session = Session()
response = session.get("https://www.baidu.com/s?wd=ip",headers=headers,proxies=proxies)
print(response.status_code)
with open(file="./testDataDocument.html",mode="w",encoding="utf-8") as f:
f.write(response.text)
验证码
自动登陆时碰到验证码认证,则可以借助第三方工具超级鹰,新用户会获取1000题分。
headers
一般来说,发起请求时我们要观察NETWORK的变化,除了User-Agent之外,如果有以下的请求头也可以对其添加上:
Host
Referer
token
尤其注意token,他的命名可能不太一样如xsrf-token,或者jwt等等字样的都应该带上。
这是为用户登录之后保存状态得到的随机字符串。
一般都会在登录成功后通过cookie进行返回,可以先从cookie中get获取,再添加到请求头中。
Python 爬虫系列的更多相关文章
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
- python爬虫系列(2)—— requests和BeautifulSoup
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
- Python爬虫系列(七):提高解析效率
如果仅仅因为想要查找文档中的<a>标签而将整片文档进行解析,实在是浪费内存和时间.最快的方法是从一开始就把<a>标签以外的东西都忽略掉. SoupStrainer 类可以定义文 ...
- 【数量技术宅 | Python爬虫系列分享】实时监控股市重大公告的Python爬虫
实时监控股市重大公告的Python爬虫小技巧 精力有限的我们,如何更加有效率地监控信息? 很多时候特别是交易时,我们需要想办法监控一些信息,比如股市的公告.如果现有的软件没有办法实现我们的需求,那么就 ...
- Python爬虫系列(三):requests高级耍法
昨天,我们更多的讨论了request的基础API,让我们对它有了基础的认知.学会上一课程,我们已经能写点基本的爬虫了.但是还不够,因为,很多站点是需要登录的,在站点的各个请求之间,是需要保持回话状态的 ...
- Python爬虫系列(一):从零开始,安装环境
在上一个系列,我们学会使用rabbitmq.本来接着是把公司的celery分享出来,但是定睛一看,celery4.0已经不再支持Windows.公司也逐步放弃了服役多年的celery项目.恰好,公司找 ...
- python爬虫系列之初识爬虫
前言 我们这里主要是利用requests模块和bs4模块进行简单的爬虫的讲解,让大家可以对爬虫有了初步的认识,我们通过爬几个简单网站,让大家循序渐进的掌握爬虫的基础知识,做网络爬虫还是需要基本的前端的 ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
随机推荐
- R语言无网络安装R包,彻底解决依赖问题!
R version: 3.5.3, 3.6.3 更新日期: 2020-9-10 大家测试后多提建议哈, 有问题我会持续更新的 在工作中,我们使用的服务器通常是不能联外网的,这在安装R包的时候产生了巨大 ...
- 学习工具---maven
写在前面 为什么要用maven? 作为一跨平台的项目管理工具,它有着以下丰富的应用场景: 作为程序员,有相当一部分时间花在编译.运行单元测试.生成文档.打包.部署和发布等不起眼的工作上,而maven将 ...
- 第二十八章、containers容器类部件QStackedWidget堆叠窗口部件详解
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 一.概述 StackedWidget堆叠窗口部件为一系列窗口部件的堆叠,对应类为QStackedWi ...
- PyQt(Python+Qt)学习随笔:model/view架构中的QStandardItemModel使用案例
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 1.案例说明 在应用中展示指定目录的图标文件的文件名和图标,界面就是一个简单的窗口上面放置一名为li ...
- Scrum 冲刺 第七篇
Scrum 冲刺 第七篇 每日会议照片 昨天已完成工作 队员 昨日完成任务 黄梓浩 初步完成app首页模块的搭建 黄清山 完成部分个人界面模块数据库的接口 邓富荣 完成部分个人界面接口 钟俊豪 完成部 ...
- Scrum 冲刺 第四篇
Scrum 冲刺 第四篇 每日会议照片 昨天已完成工作 队员 昨日完成任务 黄梓浩 初步完成app项目架构搭建 黄清山 完成部分个人界面模块数据库的接口 邓富荣 完成部分后台首页模块数据库的接口 钟俊 ...
- Panda 交易所热点关注:股权交易中心+区块链试点将开始
近期,Panda 交易所注意到,中国证监会已同意北京.上海等5家区域性股权市场参与区块链建设试点工作.Panda 交易所获悉的具体情况是,北京股权交易中心曾联合其他单位共同推出区域性股权市场中介机构征 ...
- 【adb命令的使用,及logcat日志的分析】
实时记录日志: adb logcat -v time >D:\maimang.txtadb logcat -v threadtime > E:\Desktop\SSGame_log.txt ...
- 实验楼表关系建立 (课程模块·5张表)
实验楼表关系图 from utils.MyBaseModel import Base from django.db import models # # Create your models here. ...
- Jmeter之登录接口参数化实战
为了纪念我走过的坑(为什么有些简单的问题就是绊住我了,还是不够细啊) Jmeter之接口登录参数化实战 因为想要在登录时使用不同的数据进行测试,所以我选择了将数据进行参数化.因为涉及到新建一个接口的功 ...