什么是Lambda架构
一、Lambda架构需求

Lambda架构背后的需求是由于MR架构的延迟问题。MR虽然实现了分布式、可扩展数据处理系统的目的,但是在处理数据时延迟比较严重。实际上如果内存和CPU足够强大,MR也可以实现近实时运算,但实际业务环境并非如此,因此我们需要权衡,选择实时处理和批处理所需要数据量和恰当的资源。
2012年Storm的作者Nathan Marz提出的Lambda数据处理框架。Lambda架构的目标是设计出一个能满足实时大数据系统关键特性的架构,包括有:高容错、低延时和可扩展等。Lambda架构整合离线计算和实时计算,融合不可变性(Immunability),读写分离和复杂性隔离等一系列架构原则,可集成Hadoop,Kafka,Storm,Spark,Hbase等各类大数据组件。
二、Lambda架构的关键
- 横向扩容
可扩展性意味着为满足日益增长的用户服务需求,同时不用对底层架构或者代码,可以通过现有机器添加内存或者磁盘资源来实现(垂直扩展),或者可以通过在集群中添加机器实现(水平扩展)。无论是实时或者批处理,都应该能够不停服务的情况下,可以实施水平扩展。
- 故障容错
系统需要妥善处理故障,确保系统在某些组件发生故障的情况下,整个系统服务的可用性。可能部分组件故障会导致集群中部分节点宕机,影响了整理的SLA,但是系统还是可以相应的,系统不能有单点故障。
- 低延迟
很多应用对于读和写操作的延时要求非常高,要求对更新和查询的响应是低延时的。
- 可扩展
系统需要足够灵活,能够实现新增和修改需求,又不需要重构整个系统。实时处理和批处理隔离开,能够灵活修改需求。
- 易维护
开发部署不能够太复杂。
三、Lambda架构的分层

在Lambda架构中新数据到达时,会被同时分派到批处理层和快速处理层。一旦数据到达批处理层,按照常规批处理时间间隔,每次都从头开始重新计算并生成批处理视图。类似地,只要新数据到达快速处理层,快速处理层就会使用新数据生成快速视图。在查询到达服务层时,它会合并快速视图和批处理视图来生成适当的查询结果。生成批处理视图后,快速视图将被丢弃,除非有新数据抵达,否则只需要查询批处理视图,因为此时批处理层中拥有所有的数据。
Lambda架构定义主要层以及每个组件之间的集成。注意分为以下层:
- 数据源
数据源指外部的数据库、消息队列、文件等,可以开发数据消费层,隐藏来自不同访问数据的复杂性,定义好数据格式。
- 数据消费层
负责封装不能数据源获取数据的复杂性,将其转换可由批处理或者流处理进一步使用同一的格式进行消费。
- 批处理层
这是Lambda架构核心层之一,批处理接受数据,持久化到用户定义好的数据结构中,维护着主数据。数据结构一般不做改变,只是追加数据。批处理还负责创建和维护批处理视图。比如我们常做的Hive ETL ,统计一些数据,最后将结果保存在hive表中,或者数据库中,就属于批处理层。
- 实时层
这是Lambda另一个核心层。批处理在很多场景下能够满足需求,但是随着业务需求“苛刻性”,他们希望能够及时看到数据,而不是等到第二天才看指标变化和分析结果。所以引入了实时处理。实时层解决了一个问题,即只存储可立即向用户提供的一组数据,这样就不需要对全量数据进行处理,大大提供处理效率。比如流处理仅仅存储最近5分钟的数据,处理计算并形成结果,这就是我们用spark streaming中要有的时间窗口。
- 服务层
这是Lambda架构的最后一层,服务层的职责是获取批处理和流处理的结果,向用户提供统一查询视图服务。
四、Lambda架构总结
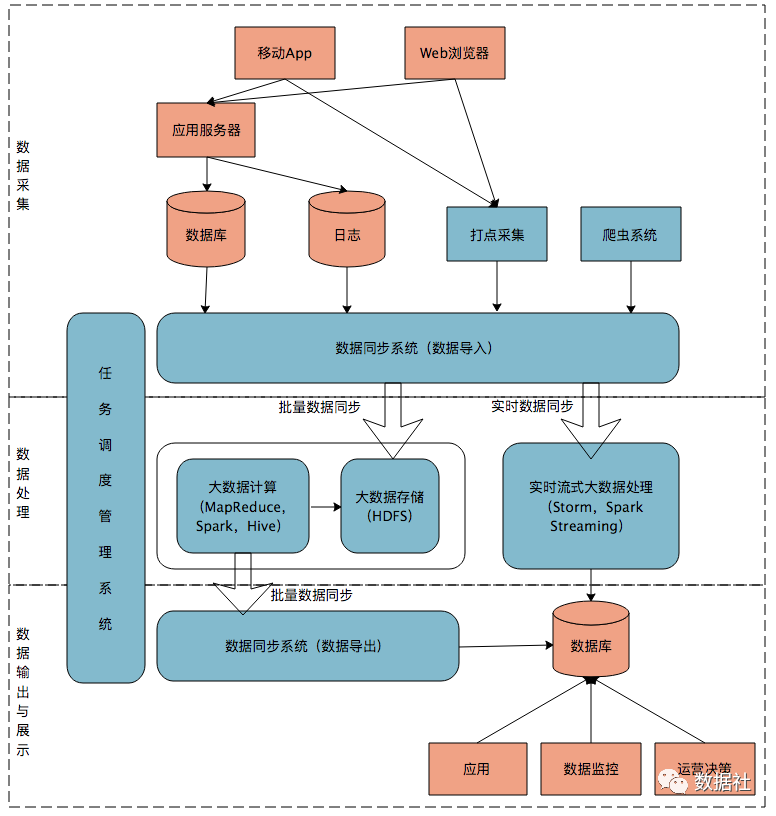
Lambda数据架构曾经成为每一个公司大数据平台必备的架构,它解决了一个公司大数据批量离线处理和实时数据处理的需求。
数据从底层的数据源开始,经过各种各样的格式进入大数据平台,在大数据平台中经过Kafka、Flume等数据组件进行收集,然后分成两条线进行计算。一条线是进入流式计算平台(例如 Storm、Flink或者Spark Streaming),去计算实时的一些指标;另一条线进入批量数据处理离线计算平台(例如Mapreduce、Hive,Spark SQL),去计算T+1的相关业务指标,这些指标需要隔日才能看见。
Lambda架构经历多年的发展,非常稳定,对于实时计算部分的计算成本可控,批量处理可以用晚上的时间来整体批量计算,这样把实时计算和离线计算高峰分开,这种架构支撑了数据行业的早期发展,但是它也有一些致命缺点:
- 实时与批量计算结果不一致
因为批量和实时计算走的是两个计算框架和计算程序,算出的结果往往不同,经常看到一个数字当天看是一个数据,第二天看昨天的数据反而发生了变化。
- 批处理的健壮性
随着数据量级越来越大,经常发现夜间只有4、5个小时的时间窗口,已经无法完成白天20多个小时累计的数据,保证早上上班前准时出数据已成为每个大数据团队头疼的问题,同时做个任务并行执行对于大数据集群的稳定性也是巨大的考验,经常会有任务因为资源不足没有定时启动或者报错。
- 开发和维护的复杂
Lambda 架构中对同样的业务逻辑进行两次编程:一次为批量计算的ETL系统,一次为流式计算的Streaming系统。针对同一个业务问题产生了两个代码库,各有不同的漏洞。
- 存储增长快
数据仓库的设计不合理,会产生大量的中间结果表,造成数据急速膨胀,加大服务器存储压力。比如我们经常纠结于数据仓库到底怎么分层,是直接ODS层到应用呢?还是ODS层要景观DWS、DW等,最后才到应用呢?
Lambda架构虽然有缺点,但是在很多公司依然适用,有时候我们没有那么大的业务量,实时业务需求并没有那么明显,用着Lambda架构依然很爽。对于超大数据量的业务或者实时业务同样多的情况,可以探索改良Lambda,业内也提出了Kappa架构,感兴趣的小伙伴可以搜索学习下。
什么是Lambda架构的更多相关文章
- 大数据Lambda架构
1 Lambda架构介绍 Lambda架构划分为三层.各自是批处理层,服务层,和加速层.终于实现的效果,能够使用以下的表达式来说明. query = function(alldata) 1.1 批处理 ...
- 大数据平台Lambda架构详解
Lambda架构由Storm的作者Nathan Marz提出.旨在设计出一个能满足.实时大数据系统关键特性的架构,具有高容错.低延时和可扩展等特. Lambda架构整合离线计算和实时计算,融合不可变( ...
- Others-大数据平台Lambda架构浅析(全量计算+增量计算)
大数据平台Lambda架构浅析(全量计算+增量计算) 2016年12月23日 22:50:53 scuter_victor 阅读数:1642 标签: spark大数据lambda 更多 个人分类: 造 ...
- Lambda架构
转载:https://blog.csdn.net/brucesea/article/details/45937875 1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan M ...
- 【大数据】大数据处理-Lambda架构-Kappa架构
大数据处理-Lambda架构-Kappa架构 elasticsearch-head Elasticsearch-sql client NLPchina/elasticsearch-sql: Use S ...
- lambda架构简介
1.Lambda架构背景介绍 Lambda架构是由Storm的作者Nathan Marz提出的一个实时大数据处理框架.Marz在Twitter工作期间开发了著名的实时大数据处理框架Storm,Lamb ...
- 带有Apache Spark的Lambda架构
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 目标 市场上的许多玩家已经建立了成功的MapReduce工作流程来每天处理以TB计的历史数据.但是谁愿意等待24小时才能获得最新的分析结果? ...
- 大数据处理中的Lambda架构和Kappa架构
首先我们来看一个典型的互联网大数据平台的架构,如下图所示: 在这张架构图中,大数据平台里面向用户的在线业务处理组件用褐色标示出来,这部分是属于互联网在线应用的部分,其他蓝色的部分属于大数据相关组件,使 ...
- 深入理解大数据架构之——Lambda架构
目录 传统系统的问题 Lambda架构简介 Lambda架构关键特性 数据系统的本质 Lambda的三层架构 Lambda架构组件选型 总结 原文链接:https://jiang-hao.com/ar ...
- 聊聊Lambda架构
定义 在数据分析场景中,我们可能会遇到这样的问题.例如,我们要做一个推荐系统,如果我们用批处理任务去做,一天或者一小时的推荐频次明显延迟太大.如果用流处理任务,虽然延迟的问题解决了,然而只用实时数据而 ...
随机推荐
- SpringMVC接受表单数据
@ 目录 pojo addProduct.jsp ProductController showProduct.jsp 测试结果 pojo 新建实体类Product package pojo; publ ...
- JavaScript学习系列博客_20_JavaScript 作用域
作用域 - 作用域指一个变量的作用的范围 - 在JS中一共有两种作用域 1.全局作用域 - 直接编写在script标签中的JS代码,都在全局作用域- 全局作用域在页面打开时创建,在页面关闭时销毁 - ...
- 自动化项目Jenkins持续集成
一.Jenkins的优点 1.传统网站部署流程 一般网站部署的流程 这边是完整流程而不是简化的流程 需求分析—原型设计—开发代码—内网部署-提交测试—确认上线—备份数据—外网更新-最终测试 ,如果 ...
- elementUI table怎么实现点击上移下移
其实炒鸡简单... <el-table :data='tableData' > ... ... <el-table-column label="操作" al ...
- CSP 202006-1 线性分类器python实现
思路 这题问题是对于这一群点和一条直线,我们也不知道直线上方的是A类还是直线下方的是A类.其实对于这个二分类问题,我们也没必要知道.我们只需要判断直线每一测的点是不是一类(A类或B类)就可以了. 至于 ...
- url_for函数——快速寻找url
我们已经知道,知道了url就可以找到对应的视图函数,那么现在问题来了,如果我们知道了视图函数,要怎么找到url呢?这时候我们就需要url_for函数了. # coding: utf-8from fla ...
- python123期末四题编程题 -无空隙回声输出-文件关键行数-字典翻转输出-《沉默的羔羊》之最多单词
1. 无空隙回声输出 描述 获得用户输入,去掉其中全部空格,将其他字符按收入顺序打印输出. ...
- Android开发之java代码工具类。判断当前网络是否连接并请求下载图片
package cc.jiusan.www.utils; import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; ...
- JAVA中 错误代码是 the public type must be defined in its own file 解决方法 android开发 java编程
一般是由于定义的JAVA类同文件名不一致: 解决方法: 1.把文件名修改同XYZ一样的名字: 2.把类名修改成同文件名:
- WebStorm下ReactNative代码提示设置
ReactNative 代码智能提醒 (Webstrom live template) https://github.com/virtoolswebplayer/ReactNative-LiveTe ...