用 Python 了解一下最炫国漫《雾山五行》
看动漫的小伙伴应该知道最近出了一部神漫《雾山五行》,其以极具特色的水墨画风和超燃的打斗场面广受好评,首集播出不到 24 小时登顶 B 站热搜第一,豆瓣开分 9.5,火爆程度可见一斑,就打斗场面而言,说是最炫动漫也不为过,当然唯一有一点不足之处就是集数有点少,只有 3 集。
下面放几张动图,一起欣赏一下。








看过动图之后,是不是觉得我所说的最炫动漫,并非虚言,接下来我们爬取一些评论,了解一下大家对这部动漫的看法,这里我们选取 B 站、微博和豆瓣这 3 个平台来爬取数据。
爬取 B 站
我们先来爬取 B 站弹幕数据,动漫链接为:https://www.bilibili.com/bangumi/play/ep331423,弹幕链接为:http://comment.bilibili.com/186803402.xml,爬取代码如下:
url = "http://comment.bilibili.com/218796492.xml"
req = requests.get(url)
html = req.content
html_doc = str(html, "utf-8") # 修改成utf-
# 解析
soup = BeautifulSoup(html_doc, "lxml")
results = soup.find_all('d')
contents = [x.text for x in results]
# 保存结果
dic = {"contents": contents}
df = pd.DataFrame(dic)
df["contents"].to_csv("bili.csv", encoding="utf-8", index=False)
如果对爬取 B 站弹幕数据不了解的小伙伴可以看一下:爬取 B 站弹幕。
我们接着将爬取的弹幕数据生成词云,代码实现如下:
def jieba_():
# 打开评论数据文件
content = open("bili.csv", "rb").read()
# jieba 分词
word_list = jieba.cut(content)
words = []
# 过滤掉的词
stopwords = open("stopwords.txt", "r", encoding="utf-8").read().split("\n")[:-]
for word in word_list:
if word not in stopwords:
words.append(word)
global word_cloud
# 用逗号隔开词语
word_cloud = ','.join(words) def cloud():
# 打开词云背景图
cloud_mask = np.array(Image.open("bg.png"))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color='white',
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=,
# 显示中文
font_path='./fonts/simhei.ttf',
# 最大尺寸
max_font_size=,
repeat=True
)
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file('cloud.png') jieba_()
cloud()
看一下效果:
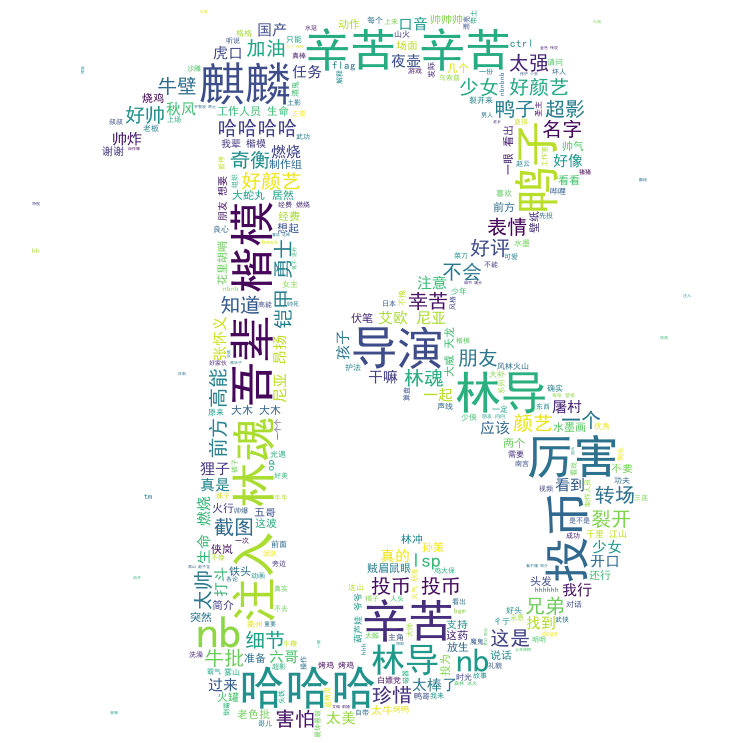
爬取微博
我们再接着爬取动漫的微博评论,我们选择的爬取目标是雾山五行官博顶置的这条微博的评论数据,如图所示:

爬取代码实现如下所示:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) # 爬取一页评论内容
def get_one_page(url):
headers = {
'User-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3880.4 Safari/537.36',
'Host' : 'weibo.cn',
'Accept' : 'application/json, text/plain, */*',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Cookie' : '自己的cookie',
'DNT' : '',
'Connection' : 'keep-alive'
}
# 获取网页 html
response = requests.get(url, headers = headers, verify=False)
# 爬取成功
if response.status_code == :
# 返回值为 html 文档,传入到解析函数当中
return response.text
return None # 解析保存评论信息
def save_one_page(html):
comments = re.findall('<span class="ctt">(.*?)</span>', html)
for comment in comments[:]:
result = re.sub('<.*?>', '', comment)
if '回复@' not in result:
with open('wx_comment.txt', 'a+', encoding='utf-8') as fp:
fp.write(result) for i in range():
url = 'https://weibo.cn/comment/Je5bqpmCn?uid=6569999648&rl=0&page='+str(i)
html = get_one_page(url)
print('正在爬取第 %d 页评论' % (i+))
save_one_page(html)
time.sleep()
对于爬取微博评论不熟悉的小伙伴可以参考:爬取微博评论。
同样的,我们还是将评论生成词云,看一下效果:

爬取豆瓣
最后,我们爬取动漫的豆瓣评论数据,动漫的豆瓣地址为:https://movie.douban.com/subject/30395914/,爬取的实现代码如下:
def spider():
url = 'https://accounts.douban.com/j/mobile/login/basic'
headers = {"User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'}
# 评论网址,为了动态翻页,start 后加了格式化数字,短评页面有 条数据,每页增加 条
url_comment = 'https://movie.douban.com/subject/30395914/comments?start=%d&limit=20&sort=new_score&status=P'
data = {
'ck': '',
'name': '用户名',
'password': '密码',
'remember': 'false',
'ticket': ''
}
session = requests.session()
session.post(url=url, headers=headers, data=data)
# 初始化 个 list 分别存用户名、评星、时间、评论文字
users = []
stars = []
times = []
content = []
# 抓取 条,每页 条,这也是豆瓣给的上限
for i in range(, , ):
# 获取 HTML
data = session.get(url_comment % i, headers=headers)
# 状态码 表是成功
print('第', i, '页', '状态码:',data.status_code)
# 暂停 - 秒时间,防止IP被封
time.sleep(random.random())
# 解析 HTML
selector = etree.HTML(data.text)
# 用 xpath 获取单页所有评论
comments = selector.xpath('//div[@class="comment"]')
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath('.//h3/span[2]/a/text()')[]
# 获取评星
star = comment.xpath('.//h3/span[2]/span[2]/@class')[][:]
# 获取时间
date_time = comment.xpath('.//h3/span[2]/span[3]/@title')
# 有的时间为空,需要判断下
if len(date_time) != :
date_time = date_time[]
date_time = date_time[:]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath('.//p/span/text()')[].strip()
# 添加所有信息到列表
users.append(user)
stars.append(star)
times.append(date_time)
content.append(comment_text)
# 用字典包装
comment_dic = {'user': users, 'star': stars, 'time': times, 'comments': content}
# 转换成 DataFrame 格式
comment_df = pd.DataFrame(comment_dic)
# 保存数据
comment_df.to_csv('db.csv')
# 将评论单独再保存下来
comment_df['comments'].to_csv('comment.csv', index=False) spider()
对于爬取豆瓣评论不熟悉的小伙伴,可以参考:爬取豆瓣评论。
看一下生成的词云效果:

用 Python 了解一下最炫国漫《雾山五行》的更多相关文章
- 介绍几种给你的Python代码加上酷炫的进度条的方式
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 大家好,在下载某些文件的时候你一定会不时盯着进度条,在写代码的时候使用进度 ...
- 教你使用Python制作酷炫二维码
这篇文章讲的是如何利用python制作狂拽酷炫吊炸天的二维码,非常有趣哦! 可能你见过的二维码大多长这样: 普普通通,平平凡凡,没什么特色... 但,如果二维码长这样呢! 或者 这样! 是不是炒鸡好看 ...
- 洗礼灵魂,修炼python(1)--python简介
首先,本人也是刚接触python短短几个月,没有老鸟的经验和技能,大佬勿喷,以下所有皆是本人对python的理解 python,是一种解释型(高级)的,面向对象的,带有动态语义的高级程序设计的开源语言 ...
- Python | 一行命令生成动态二维码
当我看到别人的二维码都做的这么炫酷的时候,我心动了! 我也想要一个能够吸引眼球的二维码,今天就带大家一起用 Python 来做一个炫酷的二维码! 首先要安装工具 myqr: pip install m ...
- [译] 如何像 Python 高手一样编程?
转自:http://www.liuhaihua.cn/archives/23475.html Harries 发布于 7天前 分类:编程技术 阅读(15) 评论(0) 最近在网上看到一篇介绍Pytho ...
- 《基于Python的GMSSL实现》课程设计个人报告
<基于Python的GMSSL实现>课程设计个人报告 一.基本信息 姓名:刘津甫 学号:20165234 题目:GMSSL基于python的实现 指导老师:娄嘉鹏 完成时间:2019年5月 ...
- python国内镜像源
让python pip使用国内镜像 国内源: 清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pyp ...
- 洛谷P1080 国王游戏 python解法 - 高精 贪心 排序
洛谷的题目实在是裹脚布 还编的像童话 这题要 "使得获得奖赏最多的大臣,所获奖赏尽可能的少." 看了半天都觉得不像人话 总算理解后 简单说题目的意思就是 根据既定的运算规则 如何排 ...
- Python学习从入门到放弃?我不允许!!!
嗨,大家好 这里是汐仔 很多人都说学习python学习python,打开书本,三分钟,从入门到放弃. 这怎么可以!!!大家能选择python的原因可能是看它既简单,好入门,现在俨然是语言中的一匹黑马. ...
随机推荐
- AbstractQueuedSynchronizer(AQS)抽丝剥茧深入了解JUC框架原理
目录 简介 Lock简单实用 主体框架 原理解析 独占锁 AQS数据结构 CLH数据结构 acquire实现步骤 addWaiter acquireQueued shouldParkAfterFail ...
- 深克隆(deepclone)
1.简单版: <script type="text/javascript"> const newObj = JSON.parse(JSON.stringify(oldO ...
- A Great Alchemist 最详细的解题报告
题目来源:A Great Alchemist A Great Alchemist Time limit : 2sec / Stack limit : 256MB / Memory limit : 25 ...
- 也来谈谈python编码
一.coding:utf-8 让我们先来看一个示例,源码文件是utf-8格式: print('你好 python') 当使用python2执行该程序时会收到一下报错: File "./hel ...
- bzoj4300绝世好题
bzoj4300绝世好题 题意: 给定一个长度为n的数列ai,求ai的子序列bi的最长长度,满足bi&bi-1!=0.n≤100000,ai≤10^9. 题解: 用f[i]表示当前二进制i为1 ...
- PHP 反序列化漏洞入门学习笔记
参考文章: PHP反序列化漏洞入门 easy_serialize_php wp 实战经验丨PHP反序列化漏洞总结 PHP Session 序列化及反序列化处理器设置使用不当带来的安全隐患 利用 pha ...
- iconfont - 好用免费的图标库
某里出品 打开首页???????搜索框在哪里 网站:点我
- 最小生成树的java实现
文章目录 一.概念 二.算法 2.1 Prim算法 2.2 Kruskal算法 笔记来源:中国大学MOOC王道考研 一.概念 连通图:图中任意两点都是连通的,那么图被称作连通图 生成树:连通图包含全部 ...
- 题解 洛谷 P4336 【[SHOI2016]黑暗前的幻想乡】
生成树计数的问题用矩阵树定理解决. 考虑如何解决去重的问题,也就是如何保证每个公司都修建一条道路. 用容斥来解决,为方便起见,我处理时先将\(n\)减了1. 设\(f(n)\)为用\(n\)个公司,且 ...
- 基于.Net Core的Redis实现查询附近的地理信息
1.使用的Redis客户端为:ServiceStack.Redis 2.Redis 中的 GEORedis是我们最为熟悉的K-V数据库,它常被拿来作为高性能的缓存数据库来使用,大部分项目都会用到它.从 ...