Hive使用Calcite CBO优化流程及SQL优化实战
上一篇主要对Calcite的背景,技术特点,SQL的RBO和CBO等做了一个初步的介绍。深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
这一篇会从Hive入手,介绍Hive如何使用Calcite来优化自己的SQL,主要从源码的角度进行介绍。文末附有一篇其他博主的文章,从其他角度阐述Hive CBO的,可供参考。
另外,上一篇中有提到我整理了Calcite的各种样例,Calcite的一些使用样例整理成到github,https://github.com/shezhiming/calcite-demo。其中自定义rule,Relnode等内容有部分参照自Hive。在介绍的时候可能也会稍微讲到。
最后会从Hive这个例子延伸,看看自己可以怎么借助Calcite来优化SQL。
Hive SQL执行流程
Hive debug简单介绍
在开始介绍之前,本着授人以渔的精深,先说下如何使用Hive debug查看源码执行流程。具体流程可以参照这篇:
简单说就是搭建个hive环境,通过 hive --debug -hiveconf hive.root.logger=DEBUG,console语句开启 debug 模式,开启后 hive 会监听 8000 端口并等待输入,此时从本地的 hive 源码项目中配置远程 debug 就可以通过 debug 的方式追踪 hive 执行流程。
debug过程中,执行SQL的入口是在CliDriver.executeDriver()这个方法,可以在这个地方打一个断点,然后就可以调试跟踪了。如下图:

搭建hive服务的话,建议使用docker,搭建起来会比较方便一些。
PS:这里介绍用的Hive的版本是2.3.x。
Hive SQL执行流程
前面说到,debug输入语句的入口的类是org.apache.hadoop.hive.cli.CliDriver。而实际执行SQL语句逻辑的主要模块是ql(Query Language) 模块的Driver类(org.apache.hadoop.hive.ql.Driver)。Driver主要逻辑,是先调用compile(String command, boolean resetTaskIds, boolean deferClose)方法,对 SQL 进行编译,然后Driver调用execute()方法,执行对应的MR任务。我们的关注点主要放在compile()方法的执行过程。
在compile()方法中,整个SQL执行流程如下图:

即先将SQL解析成AST Node,然后转换成QB,再转换成Operator tree,最后进行逻辑优化和物理优化后,就编程一个可执行的MR任务了。对应阶段的入口,我也在上面的图中标注出来了。
其中较为核心的,从AST Node到Phsical Optimize这几个阶段,都是在SemanticAnalyzer.analyzeInternal()方法中进行的。这个方法中的注释已经跟我们说明了SQL执行的主要流程,我这里贴一下:
- Generate Resolved Parse tree from syntax tree
- Gen OP Tree from resolved Parse Tree
- Deduce Resultset Schema
- Generate Parse Context for Optimizer & Physical compiler
- Take care of view creation
- Generate table access stats if required
- Perform Logical optimization
- Generate column access stats if required - wait until column pruning takes place during optimization
- Optimize Physical op tree & Translate to target execution engine (MR, TEZ..)
- put accessed columns to readEntity
- if desired check we're not going over partition scan limits
大致的流程和图里面介绍的差不多,不过会多一些细节上的补充,感兴趣的童鞋可以实际执行一下看看执行流程。我这里简单介绍下,前几个步骤就是根据AST Node生成QB,然后再转换成Operator Tree,然后处理视图和生成统计信息。最后执行逻辑优化和物理优化并生成MapReduce Task。
上述流程有一个比较容易让人疑惑的点,无论是AST Node,Operator Tree都比较好理解,后面的逻辑优化和物理优化也都是SQL解析的常规套路,但为什么中间会插入一个QB的阶段?
其实这里插入一个QB,一个主要的目的,是为了让Calcite来进行优化。
Hive 使用Calcite优化
Hive Calcite优化流程
在Hive中,使用Calcite来进行核心优化,它将AST Node转换成QB,又将QB转换成Calcite的RelNode,在Calcite优化完成后,又会将RelNode转换成Operator Tree,说起来很简单,但这又是一条很长的调用链。
Calcite优化的主要类是CalcitePlanner,更加细节点,是在CalcitePlannerAction.apply()这个方法,CalcitePlannerAction是一个内部类,包括将QB转换成RelNode,优化具体操作都是在这个方法中进行的。
这个方法的注释也给出了主要操作步骤,这里也贴一下流程:
- Gen Calcite Plan
- Apply pre-join order optimizations
- Apply join order optimizations: reordering MST algorithm
If join optimizations failed because of missing stats, we continue with the rest of optimizations - Run other optimizations that do not need stats
- Materialized view based rewriting
We disable it for CTAS and MV creation queries (trying to avoid any problem due to data freshness) - Run aggregate-join transpose (cost based)
If it failed because of missing stats, we continue with the rest of optimizations
7.convert Join + GBy to semijoin - Run rule to fix windowing issue when it is done over aggregation columns
- Apply Druid transformation rules
- Run rules to aid in translation from Calcite tree to Hive tree
10.1. Merge join into multijoin operators (if possible)
10.2. Introduce exchange operators below join/multijoin operators
简单说下,就是先生成RelNode(根据QB),然后进行一系列的优化。这里的优化最主要的还是跟join有关的优化,上面流程步骤中的2~7步都是join相关的优化。然后才是根据各个rule进行优化。最后再转换成Operator Tree,这就是最上面图片中QB->Operator Tree的流程。
接下来我们就深入这个流程,看看Hive是如何使用Calcite做SQL优化的。
Hive Calcite使用细则
要介绍Hive如何利用Calcite做优化,我们还是先转头看看Calcite优化需要哪些东西。先贴一下上一篇中介绍到的,Calcite的架构图:

从图中可以明显发现,跟QUery Optimizer(优化器)有关的模块有三个,Operator Expressions,Metadata Providers和Pluggable Rules,三者分别是关系表达树(由RelNode节点组成),元数据提供器,还有Rule。
其中关系表达树是Calcite将SQL解析校验后产生的一种关系树,树的节点即是RelNode(关系代数节点),RelNode又有多种类型,比如TableScan代表最底层的表输入,Filter表示Where(关系代数的过滤),Project表示select(关系代数的投影),即大部分的RelNode都会和关系代数中的操作对应。以一条SQL为例,一条简单的SQL编程RelNode就会是下面这个样子:
select * from TEST_CSV.TEST01 where TEST01.NAME1='hello';
//RelNode关系树
Project(ID=[$0], NAME1=[$1], NAME2=[$2])
Filter(condition=[=($1, 'hello')])
TableScan(table=[[TEST_CSV, TEST01]])
再来说说元数据提供器,所谓元数据,就是跟表有关的那些信息,rowcount,表字段等信息。其中rowcount这类信息跟计算cost有关,Calcite有自己的默认的元数据提供器,但做的比较粗糙,如果有需要应该自己提供一个元数据提供器提供自己的元数据信息。
最后就是Rules,这块Calcite默认已经有非常多的Rules,当然我们也可以定义自己的Rule再添加进去。不过通常基本的SQL优化使用Calcite的Rule就足够。这里说下怎么在idea里面查看Calcite提供的Rule,先找到RelOptRule这个类,然后按下查看类继承关系的快捷键(Mac上是Ctrl+h),就能看到多条Rule,如果要自己实现也可以照着其中实现。
稍微总结一下,Calcite已经基本提供了所需要的Rule,所以要使用Calcite优化SQL,我们需要的,是提供SQL对应的RelNode,以及通过元数据提供器提供自身的元数据。
Hive要使用Calcite优化,也无外乎就是提供上述的两部分内容。
用过Hive的童鞋应该知道,Hive可以通过外部存储组件存储数据库和表元数据信息,包括rowcount,input size等(需要执行Analyze语句或DML才会计算并元数据到Mysql)。Hive要做的就是将这些信息,提供给Calcite。
Hive向Calcite提供元数据
需要先明确的一点是,元数据提供器需要提供的一个比较重要的数据,是rowcount,在进行CBO计算Cost的过程中,CPU,IO等信息也基本都是从rowcount加工而来的。且元数据重要的一个用途,也是进行CBO优化,输入的元数据可以等价于CBO要用到的Cost数据。
继续深入CBO的Cost,通过前面的例子,可以知道SQL在Calcite会被解析成RelNode树,RelNode树上层节点(Project等)的Cost信息,是由下层的信息计算而得到的。我们的目标是要自定义Cost信息,那么就需要将Hive的元数据注入最底层的TableScan的Cost信息,同时要能够自定义每个节点的Cost计算方式。
还记得前面说到Calcite默认的元数据提供器比较粗糙吗,就是体现在它的TableScan的rowcount默认是100,而每个节点的计算逻辑也比较简单。
所以重点有两个,一个是最底层TableScan的cost信息注入方式,另一个是如何每种RelNode类型定义计算逻辑的方式。
办法有两种,一种是比较上层的,通过自定义RelNode,修改其中的computeSelfCost()方法和estimateRowCount方法,这两个方法,一个是计算Cost信息,另一个是计算行数。这种办法可以直接解决TableScan的cost注入,和自定义每种RelNode类型的计算逻辑。但这种办法忽了元数据提供器,算是比较简单粗暴的方法。
就像这样:
代码见:https://github.com/shezhiming/calcite-demo/blob/master/src/main/java/pers/shezm/calcite/optimizer/reloperators/CSVTableScan.java
public class CSVTableScan extends TableScan implements CSVRel {
private RelOptCost cost;
public CSVTableScan(RelOptCluster cluster, RelTraitSet traitSet, RelOptTable table) {
super(cluster, traitSet, table);
}
@Override public double estimateRowCount(RelMetadataQuery mq) {
return 50;
}
@Override
public RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {
//return super.computeSelfCo(planner, mq);
if (cost != null) {
return cost;
}
//通过工厂生成 RelOptCost ,注入自定义 cost 值并返回
cost = planner.getCostFactory().makeCost(1, 1, 0);
return cost;
}
}
另一种方法则更加底层一些,TableScan的元数据信息,是通过内部变量RelOptTable获取,那么就自定义RelOptTable实现元数据注入。然后通过实现MetadataDef<BuiltInMetadata.RowCount>系列的接口,在其中添加自己的计算逻辑,将这些自定义的类都加载到RelMetadataProvider中(元数据提供器,可以在其中提供自定义的元数据和计算逻辑),再注入到Calcite中就可以实现自己的Cost计算逻辑。这也是Hive的实现方式。
我们从TableScan注入,和RelMetadataProvider这两方面看看Hive是怎么做。
TableScan的注入元数据
首先,Hive自定义了Calcite的TableScan,在org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveTableScan。但这里并不涉及元数据,我们观察下TableScan的源码,
public abstract class TableScan extends AbstractRelNode {
//~ Instance fields --------------------------------------------------------
/**
* The table definition.
*/
protected final RelOptTable table;
//生成 cost 信息
@Override public RelOptCost computeSelfCost(RelOptPlanner planner,
RelMetadataQuery mq) {
double dRows = table.getRowCount();
double dCpu = dRows + 1; // ensure non-zero cost
double dIo = 0;
return planner.getCostFactory().makeCost(dRows, dCpu, dIo);
}
//生成 rowcount 信息
@Override public double estimateRowCount(RelMetadataQuery mq) {
return table.getRowCount();
}
}
顺便说下,上面说过,Cost信息和rowcount息息相关,这里就可以看出来了,Cpu直接就用rowcount加一。并且这里也可以看出默认的元数据提供器比较粗糙。
不过我们重点不在这,通过代码可以发现它主要是通过table这个变量获取表元数据信息。而hive也自定义了相关的类,就是继承自RelOptTable的RelOptHiveTable。这个类在HiveTableScan初始化的时候,会作为参数传递进去。而它的元数据则是通过QB获取,这个过程也是在CalcitePlannerAction.apply()中完成的,至于QB的元数据,则是在初始化的时候通过Mysql获取到的。听起来挺绕,稍微按顺序整理下:
- QB初始化的时候,通过Mysql获取元数据信息并注入
- QB转成RelNode的时候,将元数据传递到
RelOptHiveTable RelOptHiveTable作为参数新建HiveTableScan
以上就是Hive完成TableScan元数据注入的过程。
自定义RelMetadataProvider
再来说说如何提供RelMetadataProvider。这个主要是通过继承MetadataHandler实现的,这里贴一下就能清楚metadata有哪些类型,以及Hive实现了哪些:
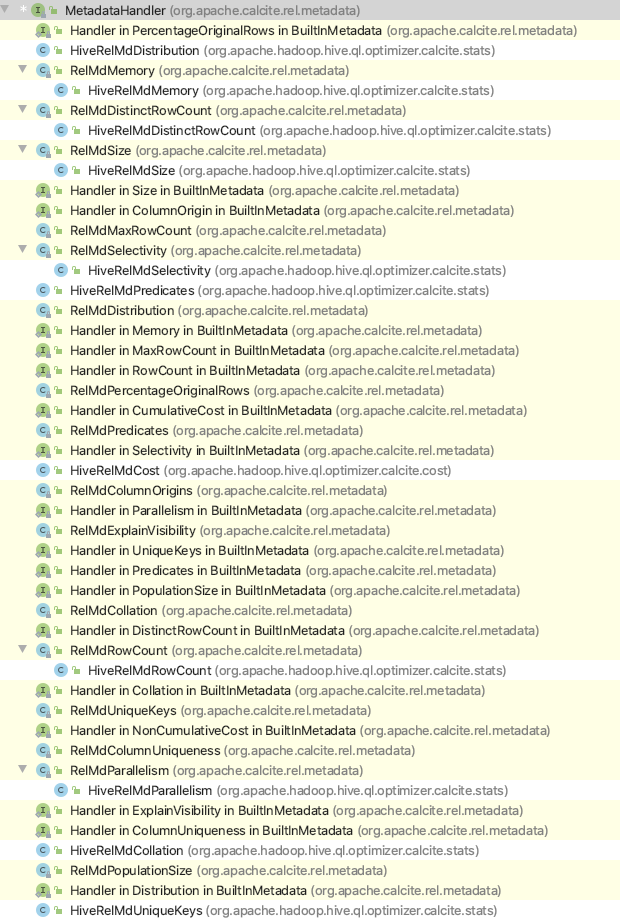
这里可以清楚看到,metadata除了之前提到的rowcount,cost,还有size,Distribution等等,其中白色的就是Hive实现的。
而之前一直提到的rowcount和cost,对应的就是HiveRelMdRowCount和HiveRelMdCost(这个真正的cost模型实现,是在HiveCostModel)。这里贴一下HiveCostModel中Join的Cost自定义计算逻辑,因为join优化是一个重点,所以这里会根据不同实现类去计算cost,相比Calcite默认实现,精细很多了。
public abstract class HiveCostModel {
......其他代码
public RelOptCost getJoinCost(HiveJoin join) {
// Select algorithm with min cost
JoinAlgorithm joinAlgorithm = null;
RelOptCost minJoinCost = null;
if (LOG.isTraceEnabled()) {
LOG.trace("Join algorithm selection for:\n" + RelOptUtil.toString(join));
}
for (JoinAlgorithm possibleAlgorithm : this.joinAlgorithms) {
if (!possibleAlgorithm.isExecutable(join)) {
continue;
}
RelOptCost joinCost = possibleAlgorithm.getCost(join);
if (LOG.isTraceEnabled()) {
LOG.trace(possibleAlgorithm + " cost: " + joinCost);
}
if (minJoinCost == null || joinCost.isLt(minJoinCost) ) {
joinAlgorithm = possibleAlgorithm;
minJoinCost = joinCost;
}
}
if (LOG.isTraceEnabled()) {
LOG.trace(joinAlgorithm + " selected");
}
join.setJoinAlgorithm(joinAlgorithm);
join.setJoinCost(minJoinCost);
return minJoinCost;
}
......其他代码
}
其他的也和这个差不多,就是更加精细的自定义Cost计算,就不多展示了。
OK,说完上面这些,Hive的优化也就差不多介绍完了,这里重点还是介绍了Hive如何向Calcite中注入元数据信息以及实现自定义的RelNode计算逻辑。至于Calcite进行RBO和CBO优化的更多细节,我上一篇有提到,也有给出相关资料,这里就不多介绍。
深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
还有另一个点是编写自定义的rule实现自定义优化,这一点以后与机会再说。
另外我最上方的github中,也有简单照着hive,实现了自己注入元数据和自定义RelNode的计算方式,基本都是从最简单的CSV的例子延伸而言,方便理解,有兴趣的朋友可以看看,如果有帮助不妨点个star。
以上~
参考文章:
Apache Hive 是怎样做基于代价的优化的?
Hive使用Calcite CBO优化流程及SQL优化实战的更多相关文章
- MySQL性能优化(四):SQL优化
原文:MySQL性能优化(四):SQL优化 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/ ...
- mysql优化方案之sql优化
优化目标 1.减少 IO 次数 IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先 ...
- (1.10)SQL优化——mysql 常见SQL优化
(1.10)常用SQL优化 insert优化.order by 优化 1.insert 优化 2.order by 优化 [2.1]mysql排序方式: (1)索引扫描排序:通过有序索引扫描直接返回有 ...
- MySQL优化(二):SQL优化
一.SQL优化 1.优化SQL一般步骤 1.1 查看SQL执行频率 SHOW STATUS LIKE 'Com_%'; Com_select:执行SELECT操作的次数,一次查询累加1.其他类似 以下 ...
- mysql实战优化之一:sql优化
1.选取最适用的字段属性 MySQL 可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得 ...
- 深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
目录 Calcite简介与CBO介绍 Calcite背景与介绍 SQL优化与CBO Calcite优化器 HepPlanner优化器与VolcanoPlanner优化器 Calcite优化样例代码介绍 ...
- 基于Oracle的SQL优化(社区万众期待 数据库优化扛鼎巨著)
基于Oracle的SQL优化(社区万众期待数据库优化扛鼎巨著) 崔华 编 ISBN 978-7-121-21758-6 2014年1月出版 定价:128.00元 856页 16开 编辑推荐 本土O ...
- 面试题: 数据库 sql优化 sql练习题 有用 学生表,课程表,成绩表,教师表 练习
什么是存储过程?有哪些优缺点? 什么是存储过程?有哪些优缺点? 存储过程就像我们编程语言中的函数一样,封装了我们的代码(PLSQL.T-SQL). 存储过程的优点: 能够将代码封装起来 保存在数据库之 ...
- 【重磅干货】看了此文,Oracle SQL优化文章不必再看!
目录 SQL优化的本质 SQL优化Road Map 2.1 制定SQL优化目标 2.2 检查执行计划 2.3 检查统计信息 2.4 检查高效访问结构 2.5 检查影响优化器的参数 2.6 SQL语句编 ...
随机推荐
- Java中实现十进制数转换为二进制的三种方法
第一种:除基倒取余法 这是最符合我们平时的数学逻辑思维的,即输入一个十进制数n,每次用n除以2,把余数记下来,再用商去除以2...依次循环,直到商为0结束,把余数倒着依次排列,就构成了转换后的二进制数 ...
- Jmeter 常用函数(18)- 详解 __isDefined
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.htm 作用 判断 Jmeter 变量是否存在,1 就 ...
- Python 控制台输出时刷新当前行内容而不是输出新行
需求目标 执行Python程序的时候在控制台输出内容的时候只显示一行,然后自动刷新内容,像这样: Downloading File FooFile.txt [%] 而不是这样: Downloading ...
- Vue管理系统前端系列六动态路由-权限管理实现
目录 为什么要使用动态路由? 主流的两种实现方式 前端控制 后端控制 后端控制路由 实现 添加菜单接口 及 菜单状态管理 根据得到的菜单生成动态路由 根据 vuex 中的暂存的菜单生成侧边菜单栏 退出 ...
- First-Spike-Based Visual Categorization Using Reward-Modulated STDP
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 强化学习(RL)最近以击败欧洲围棋冠军等重大成就重新受到欢迎.在这里,我们第一次表明,RL可以有效地用于训练一个脉冲神经 ...
- poi解析Excel内容
poi可以将指定目录下的Excel中的内容解析.读取到java程序中.下面是一个Demo: 使用poi需要导下包,如下: 首先是准备读取的Excel表,存放在"E:\programming\ ...
- 轻松应对并发,Newbe.Claptrap 框架入门,第四步 —— 利用 Minion,商品下单
接上一篇 Newbe.Claptrap 框架入门,第三步 —— 定义 Claptrap,管理商品库存 ,我们继续要了解一下如何使用 Newbe.Claptrap 框架开发业务.通过本篇阅读,您便可以开 ...
- 使用tensorflow2识别4位验证码及思考总结
在学习了CNN之后,自己想去做一个验证码识别,网上找了很多资料,杂七杂八的一大堆,但是好多是tf1写的,对tf1不太熟悉,有点看不懂,于是自己去摸索吧. 摸索的过程是异常艰难呀,一开始我直接用capt ...
- CKA认证经验贴(认证日期:20200817)
一.背景 由于年初疫情影响,身处传统IT行业且兼职出差全国各地“救火”的我有幸被领导选中调研私有云平台,这就给我后来的认证之路做下了铺垫.之前调研kubernetes的v1.17版本自带kubeadm ...
- Inno Setup Compiler 中文使用教程
一.概要 该文章主要解决,Inno Setup Compiler工具的使用问题. 如有什么建议欢迎提出,本人及时修改.[如有任何疑惑可以加Q群:580749909] 二.步骤 (1)下载地址:http ...