Mysql-Innodb : 从一个字节到整个数据库表了解物理存储结构和逻辑存储结构
首先要从Innodb怎么看待磁盘物理空间说起
一块原生的(Raw)物理磁盘,可以把他看成一个字节一个字节单元组成的物理存储介质
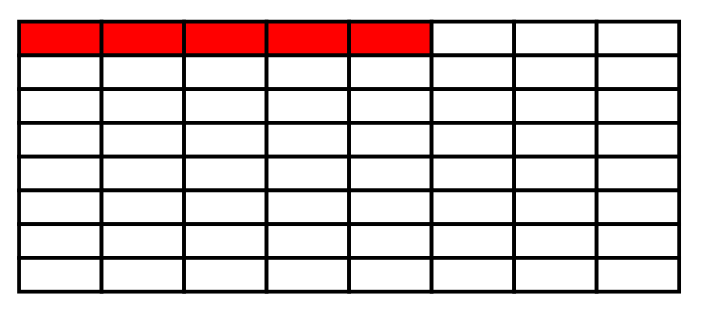
如果要在这块原生物理空间中插入一条记录,不能单单只插入数据,还需要插入一些管理记录的信息,这些管理信息被称为记录头,这里假设是5字节(compact类型记录确实记录头占用5字节,简单通俗起见,可以忽略这段括号内的解释)
然后在记录头后面插入列,假如要插入的记录的各个列是:
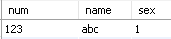
其中 num 是主键 (int类型)
name 是 varchar 类型的
sex 是 int 类型的
那么按照 int 占用 4 字节,不超过长度阈值(8000+)的 varchar 按照实际长度 ('abc' 占 3 字节) 存储的规则 把这条记录填充到 Raw物理空间中

问题来了:管理信息有什么用呢?
在存储组织上最重要的用处是找到下一条记录

不能直接找到下一条记录吗?不能。假如我已经知道了第一条记录数据的开头部分,也就是上图第一个蓝色方格(A)的编号
现在插入多一条记录:
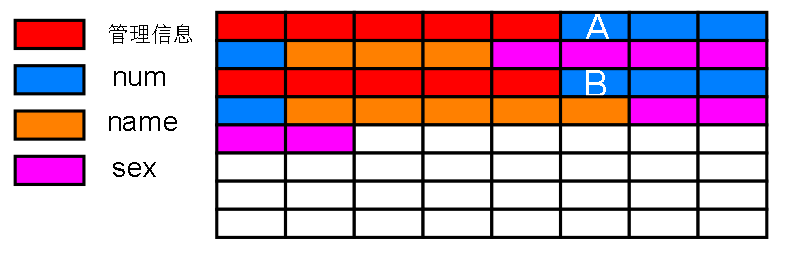
如何才能获取第二条记录的第一个蓝色方格(B)编号? 这个蓝色方格(B)就是第二条记录数据部分的起始地址
可不可以用 A 的编号加上偏移量得到呢?
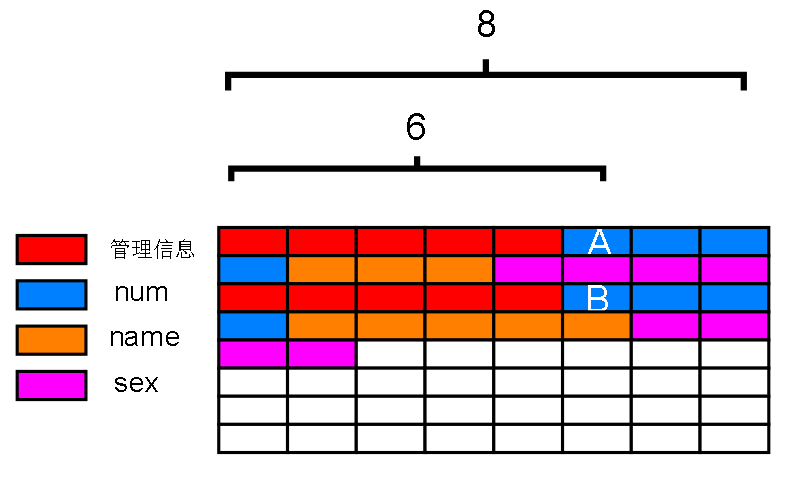
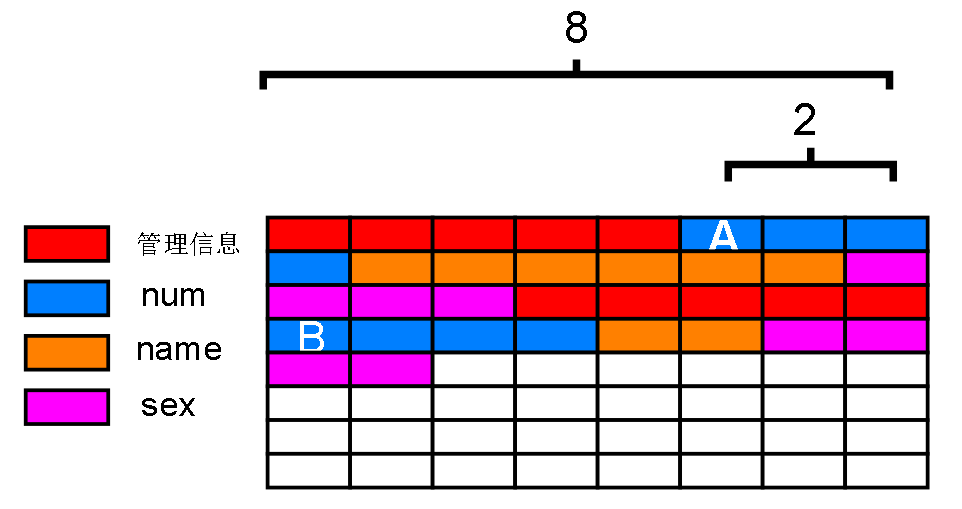
B的编号 = A 的编号 + 8 + 6 ? 实际上不行,因为黄色部分的 name 是不定长的,偏移量也不一定,就如下图,偏移量随着不定长字段长度改变而改变
管理信息可以记录下一条记录编号的偏移量
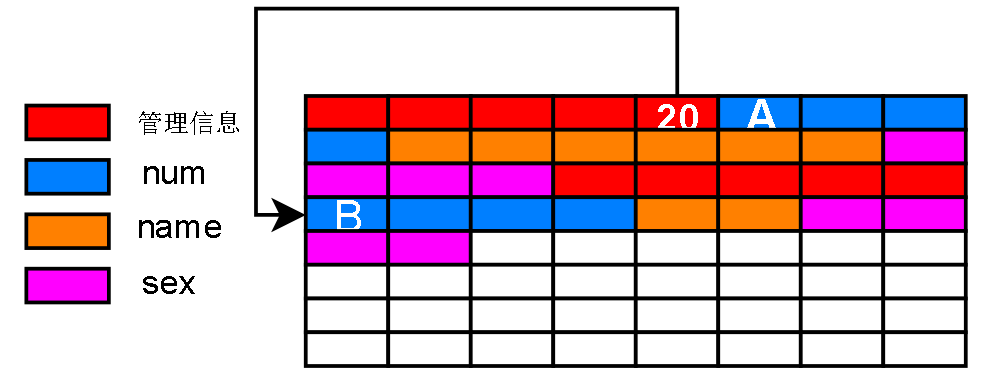
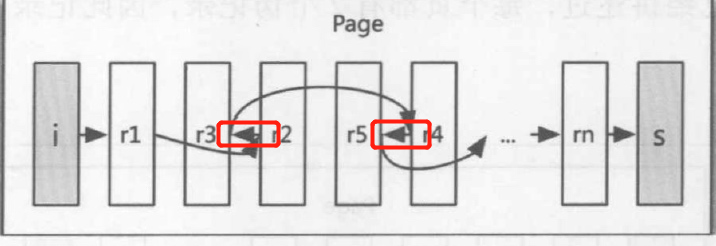
形成一种链表管理方式:每条记录的数据部分可以看成一个结点

把他抽象一下就得到了 下图这种方式
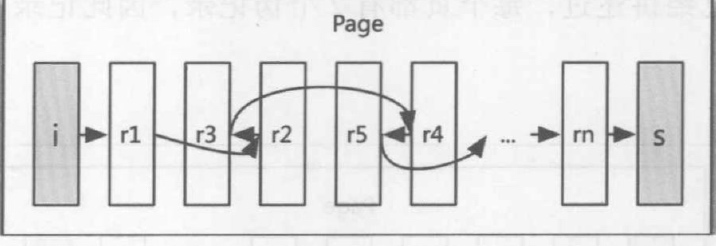
但是为什么会有倒着指的情况存在呢?
(图 A )
假如删除第二条记录:
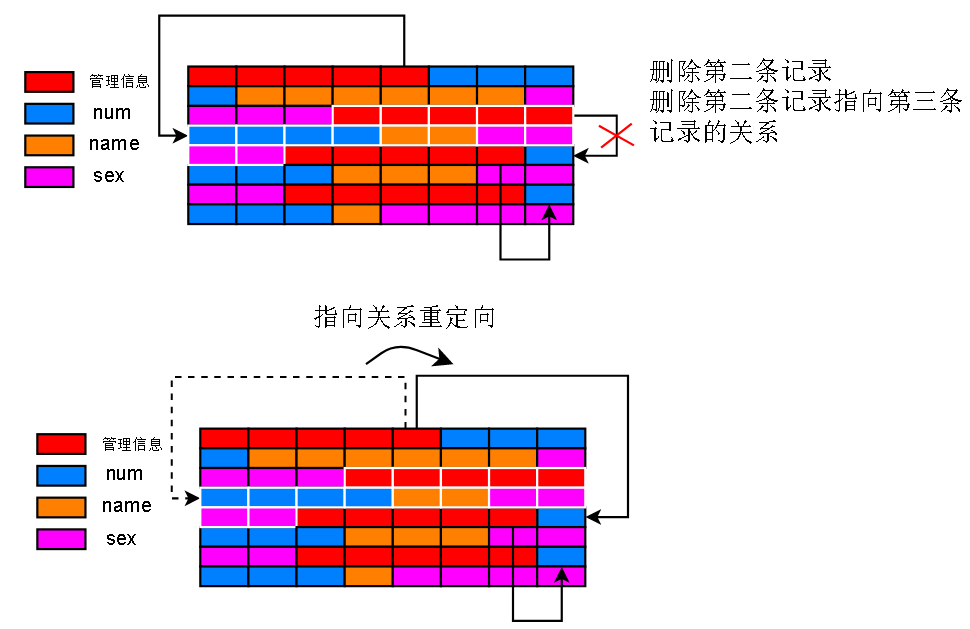
最后,被删除的第二条记录被移出了上面提到的,存储有用记录的链表
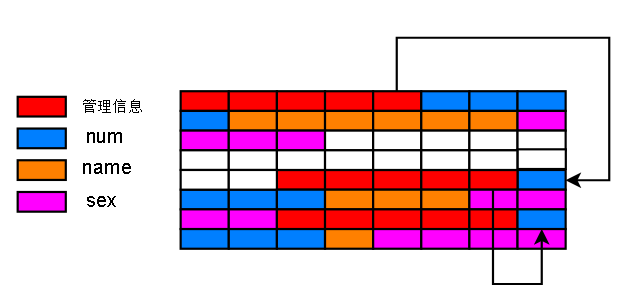
如果把整个物理空间扩大,找到其他同样也是被删除的记录。实际上这些被删除的记录,会被标记为空闲状态(管理信息中有标志位)
然后采用实际有用的数据相同的链接方式,连接成一条链表,称为空闲链表
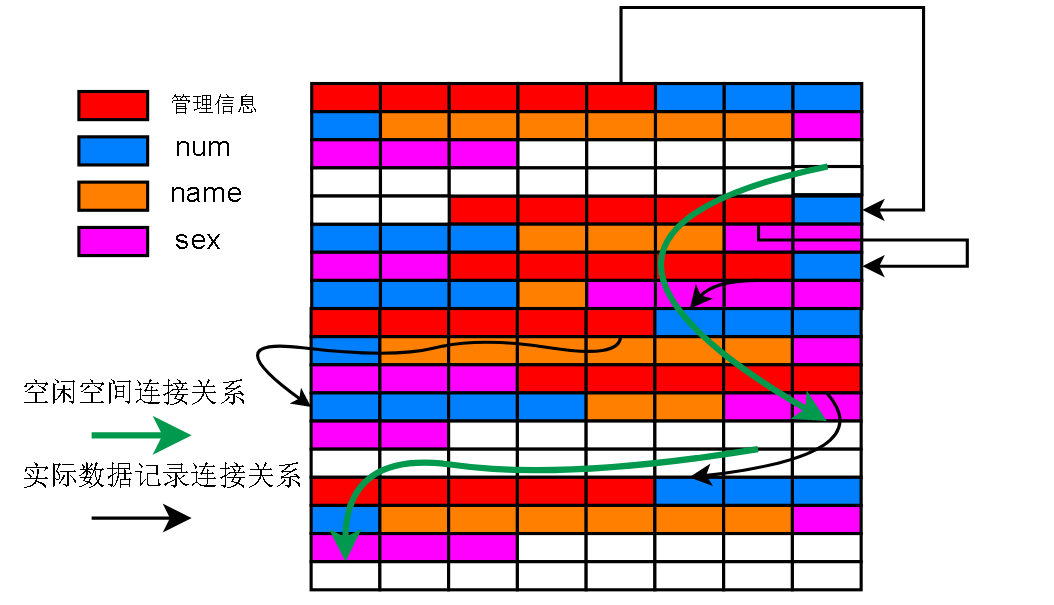
下次再插入一条数据的时候,如果从空闲链表中找到了符合要插入记录大小的空闲空间(上图白色部分)就会把这一部分分配出去
下图绿色的部分是新记录,当然新记录不一定会占满之前留下的空闲空间
蓝色的那条指向,是一条倒着的指向,也就可以解释之前图 A 上为什么有倒着的链表指向了
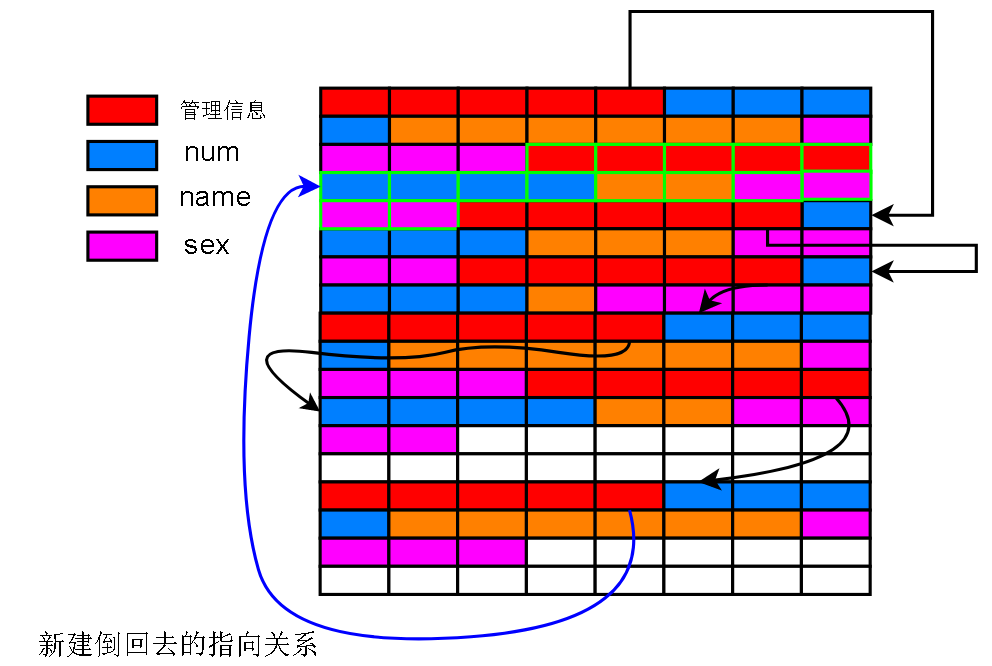
所以,一个物理上的数据中的记录是逻辑上按照链表顺序连接起来的,并且是按照主键递增的顺序连接成一条单链表
之前说过,4字节的num是主键,如果删除的是 主键 = 2 的记录,那么最后物理上看起来是这样的:
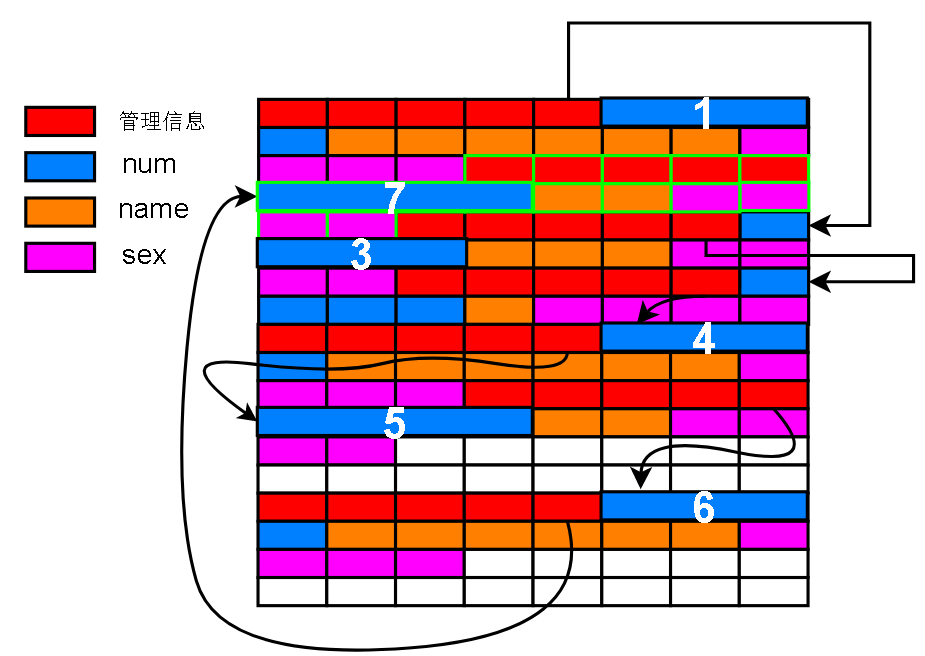
新增加的记录,主键是 7,占用了被删掉的记录(主键 = 2)的位置(不一定能占满,上图是假设占满了)
之所以说这条链表是逻辑上主键递增的,是因为在物理上这条链表并不是主键递增,上图最明显的不是递增特点表现在7插在了1和3之间
我们把下图的这一块称为一个数据页,数据页是 Innodb 磁盘存储管理的最小单位。当然,实际上数据页不会像下图这样才几条记录,下图只是一个迷你版的表示
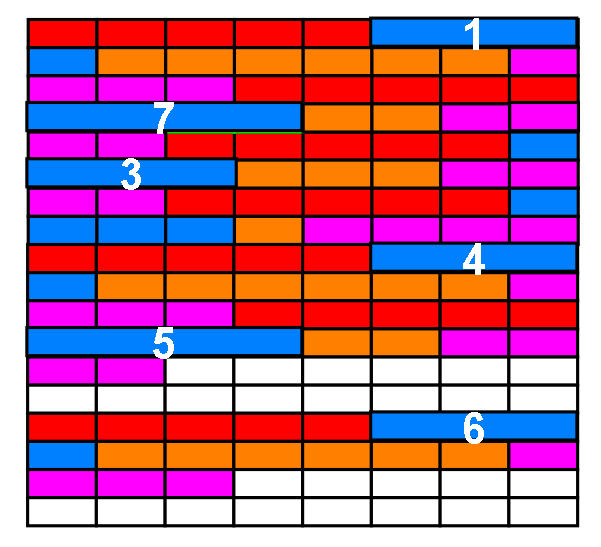
默认数据页真正大小一般是16 KB , 真正看起来可能是密密麻麻一大片:
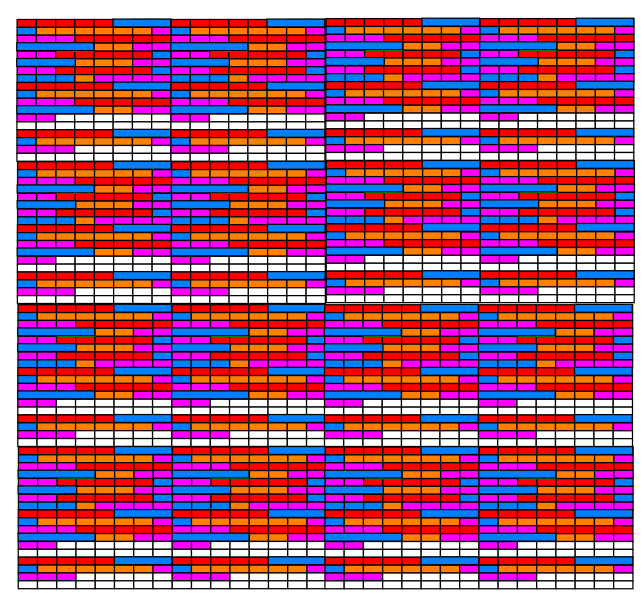
每一页都持有上一页和下一页在物理文件中的编号(地址)页和页之间可以串起来:
(实际上是页结构中的File Header部分保存了上一页/下一页在表空间文件中的偏移量(编号)
如果一个独立的表空间文件(.idb) 的大小是1GB,每个页的大小是 16KB, 那么总共有1GB / 16KB = 65536个页
下文均讨论聚簇索引

(下文的B+树都是简化的,实际上B树节点的度不会那么小)
这些页都是 Innodb 的 B+ 树存储结构中的 数据页节点,也就是叶子节点
可以加上非叶子节点(索引节点),让他成为一颗完整的 B+ 树:

现在大概有一个存储结构的大体认识了,来解决一个比较深入的问题:上图的索引节点是什么,怎么通过这些索引节点做查找
首先了解表的存储结构:如果使用独立表空间,表的索引和记录将会存储在一个独立的idb文件中
idb文件可以按照规定好的数据页大小切分成若干页

每个数据页都有自己独特的页号,其实就是页的偏移量,可以唯一表示一个数据页

需要注意的是物理页的物理顺序和逻辑顺序可能不一样,比如:
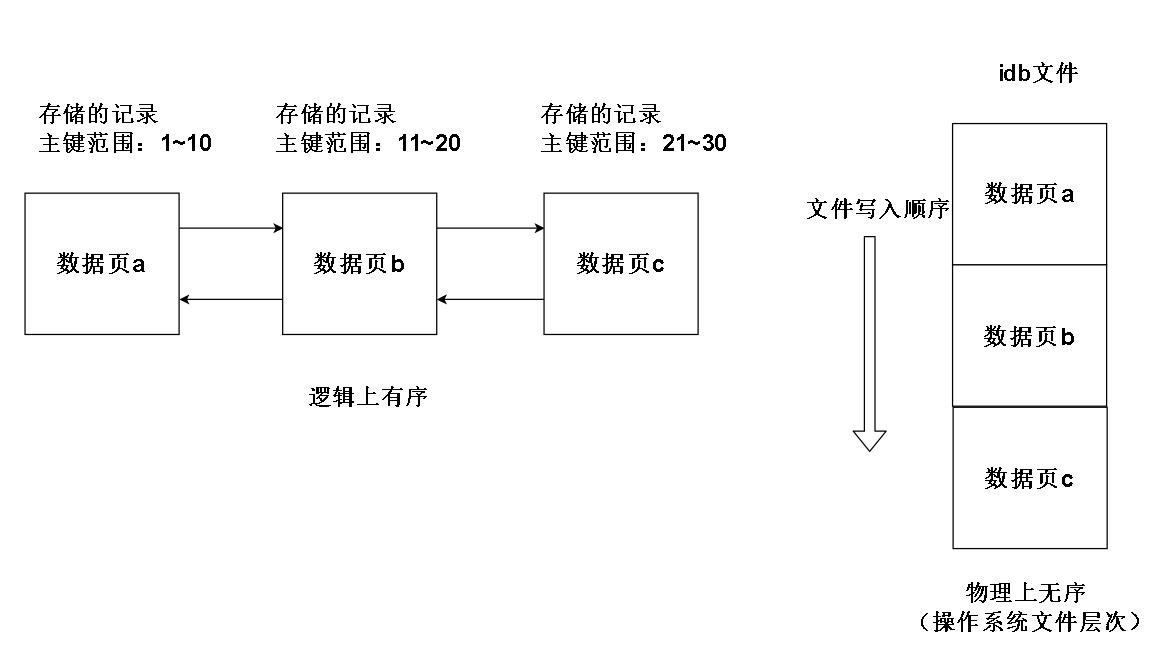
数据页无需的结果可能是这样的:

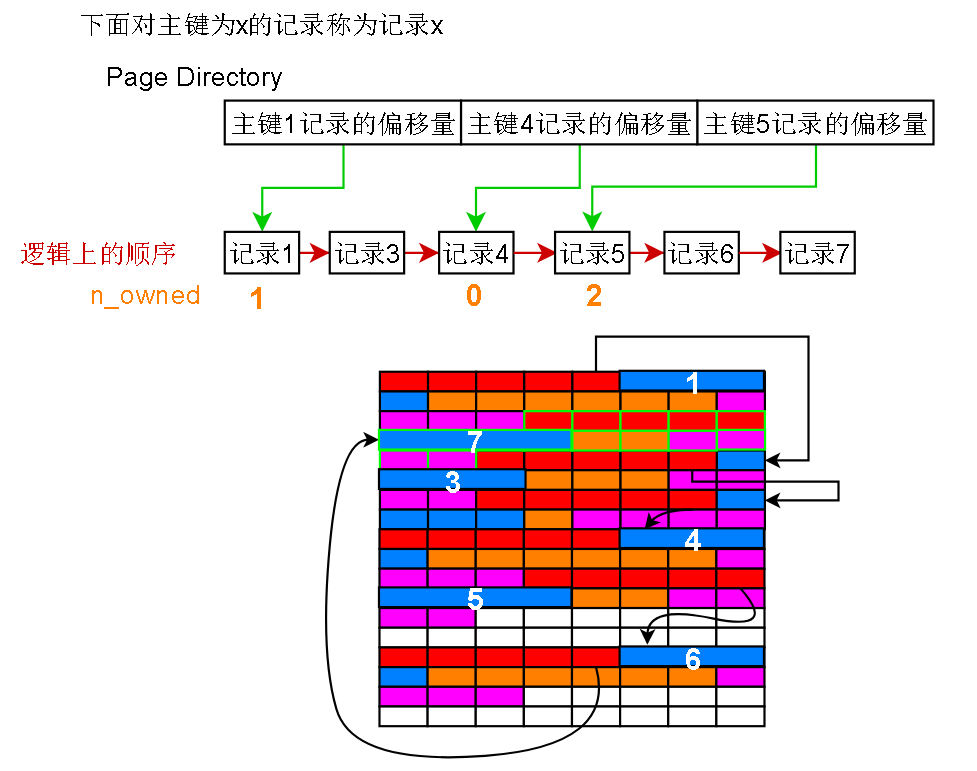
聚簇索引页的记录只是简单的把页的最小主键值和页的页号关联起来
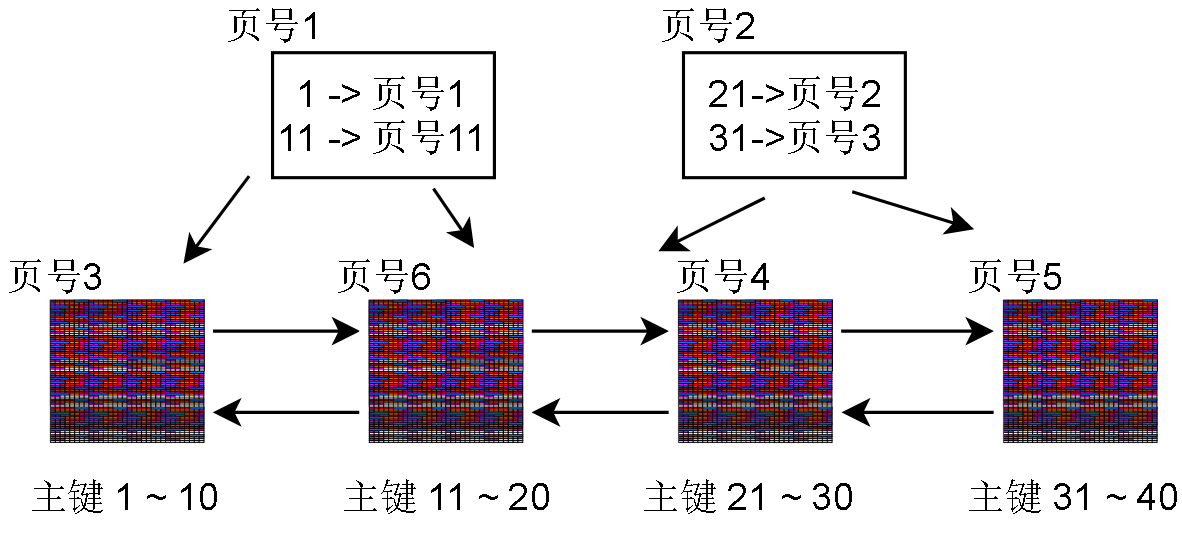
聚簇索引页的上一层索引页(逻辑上)也只是简单的记录下层索引页最小主键值和页号的映射
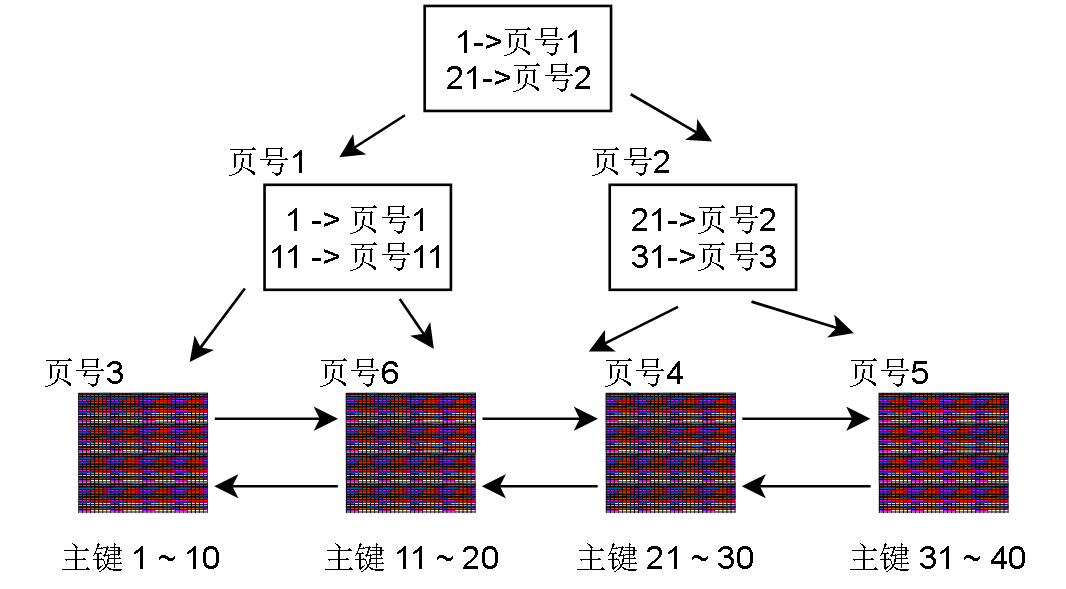
当然,Innodb的B+树的扇出度 (fan out)是很高的,像上图这样少量的数据页一般只有一层索引节点,且只有一个。
回到一开始我们的目的,假如我要查询 主键 = 25 的记录
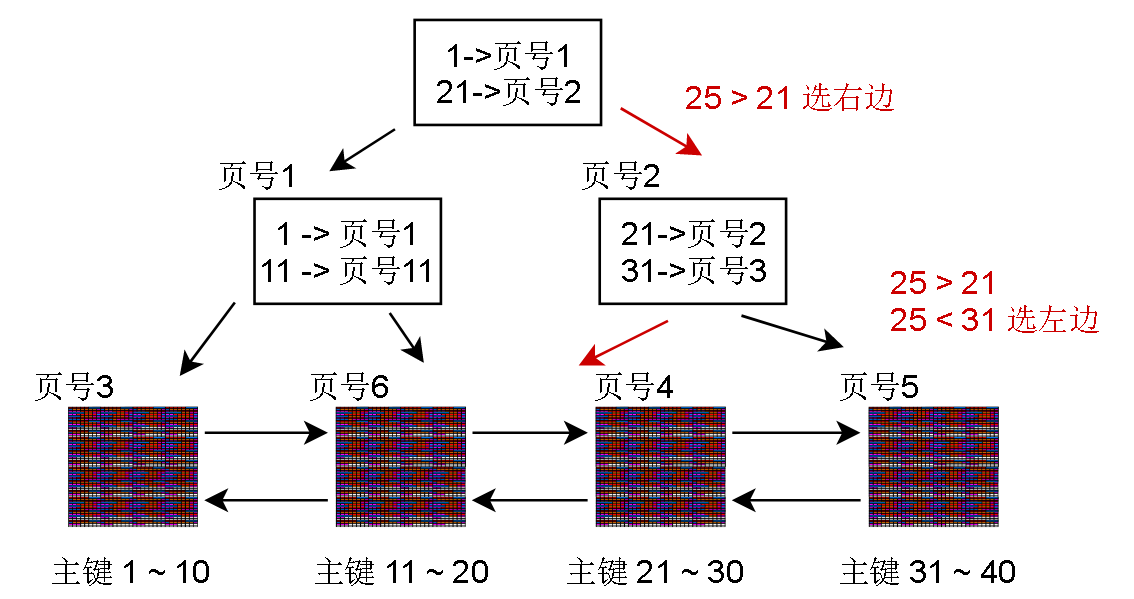
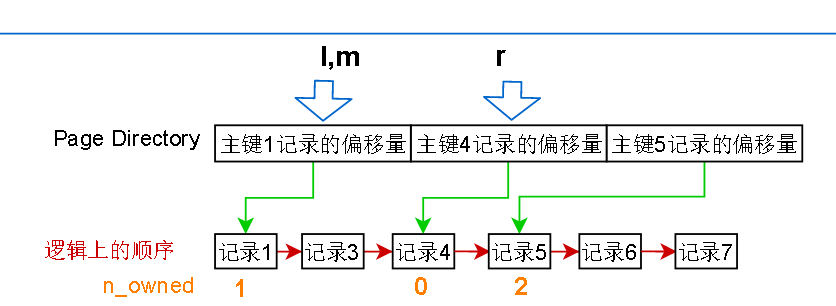
找到数据页4,但是要怎么找记录呢?innodb会把这片数据页加载入内存,根据这个数据页的page Directory进行二分查找
Page Directory 其实只是一堆偏移量而已
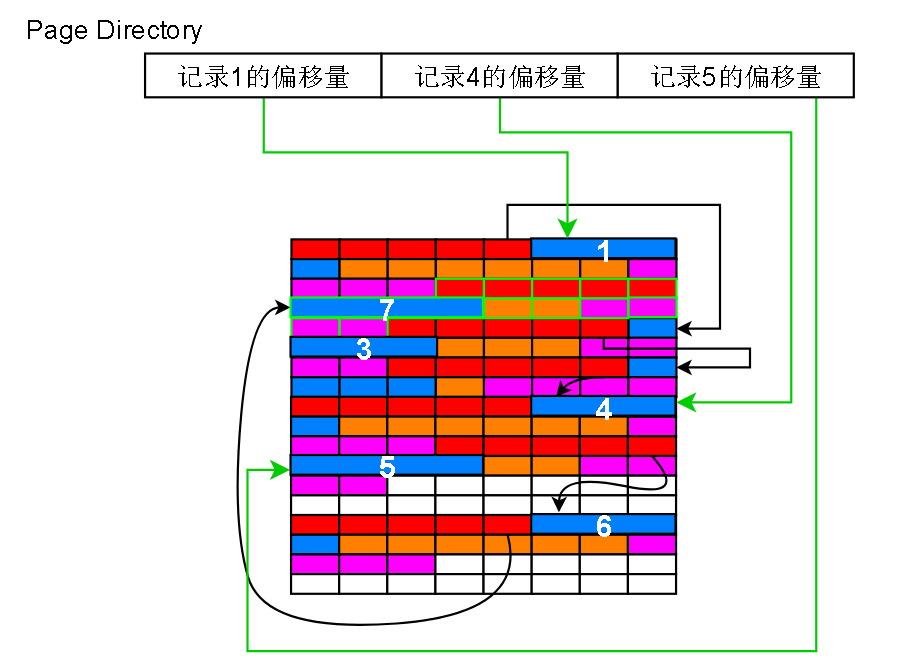
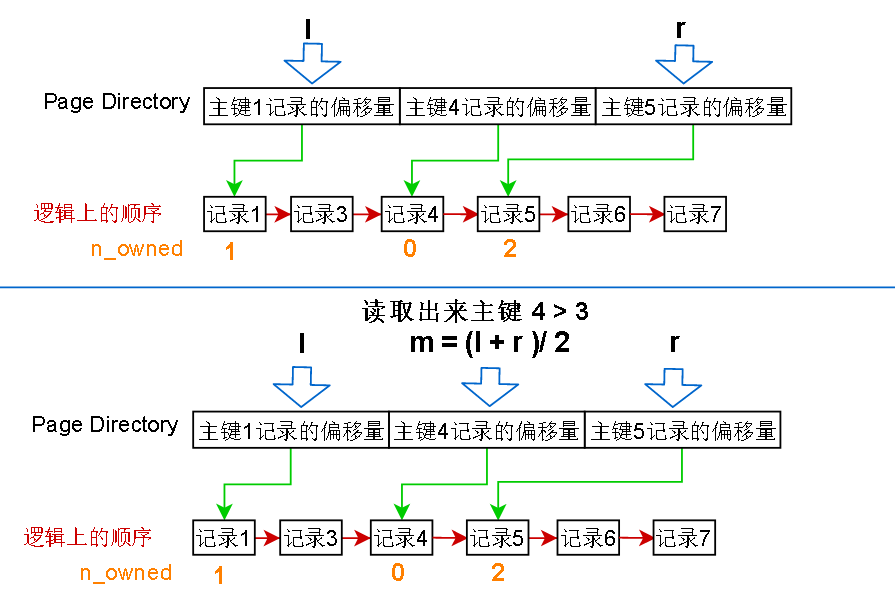
在上面的页中,如果我要查找主键 = 3 的记录,那么先设置左指针 l = 第一个page directory 项的位置,右指针 r = 最后一个 page directory项的位置
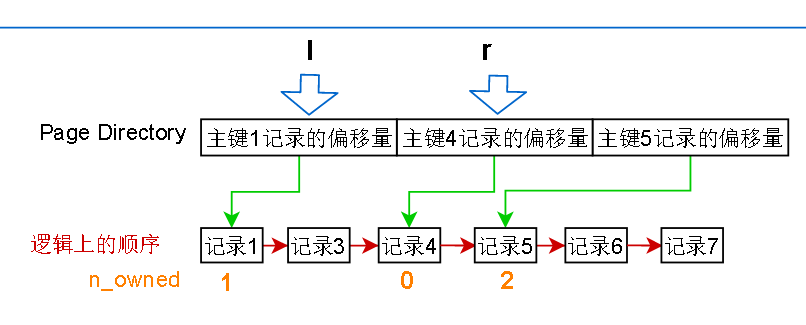
根据二分查找,求出中间的位置,然后把中间的 page directory 项读出来,发现记录的主键是4,比要找的 3 大,那就缩小范围,把右指针 r 设置成刚才
算出来的中间项的位置,l 和 r 之间已经没有没有page director的项 了,所以从 l 指针指向的记录开始,一条条往后读,最多读取其实记录的n_owned次
读不到就表示目标不存在,n_owned其实表示的就是当前记录到下一个Page Directory有指向的记录之间有多少条记录,这些记录的查询都是归当前记录管
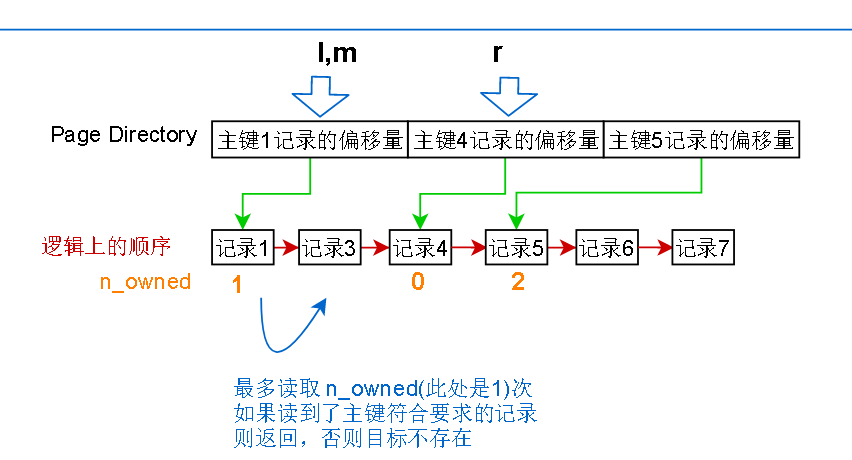
所以根据索引只能查到数据页,把页读进内存在进行二分查找,因为是在内存中操作,相比于索引查找时的磁盘操作,可以忽略
Mysql-Innodb : 从一个字节到整个数据库表了解物理存储结构和逻辑存储结构的更多相关文章
- MySQL基于左右值编码的树形数据库表结构设计
MySQL基于左右值编码的树形数据库表结构设计 在关系型数据库中设计树形的数据结构一直是一个十分考验开发者能力的,最常用的方案有主从表方案和继承关系(parent_id)方案.主从表方案的最大缺点 ...
- Atitit.数据库表的物理存储结构原理与架构设计与实践
Atitit.数据库表的物理存储结构原理与架构设计与实践 1. Oracle和DB2数据库的存储模型如图: 1 1.1. 2. 表数据在块中的存储以及RowId信息3 2. 数据表的物理存储结构 自然 ...
- mysql中查询一个字段属于哪一个数据库中的哪一个表的方式
mysql中查询一个字段具体是属于哪一个数据库的那一张表:用这条语句就能查询出来,其中 table_schema 是所在库, table_name 是所在表 --mysql中查询某一个字段名属于哪一个 ...
- 开源一个适用iOS的数据库表结构更新机制的代码
将前段时间开源的代码.公布一下: ARDBConfig On the iOS, provide a database table structure update mechanism, ensure ...
- mysql从只有一个备份文件(多个数据库的备份)中恢复数据到指定数据库
mysql -uroot -p 要恢复的数据库的名字 --one-database<备份文件
- mysql数据库连接状态,不要做修改数据库表结构的操作;数据库迁移操作;
在开发过程中,python的flask框架使用sqlalmysql连接mysql数据库. 在程序连接数据量过程中,不要修改数据表的结构.比如在连接状态中使用下面的软件修改数据表结构,这个软件立即就会卡 ...
- mysql增加远程连接用户及查看数据库表结构
一.增加远程连接用户 1.用root权限登录数据库 2.加用户:grant all privileges on *.* to '111'@'192.168.1.%' identified by '2 ...
- Mysql InnoDB行锁不使用索引锁表的时候会锁整张表
原文:http://www.thinkphp.cn/topic/41577.html 如果使用针对InnoDB的表使用行锁,被锁定字段不是主键,也没有针对它建立索引的话.行锁锁定的也是整张表.锁整张表 ...
- 给mysql数据添加一个只拥有一张表的权限
grant all privileges on [database].* to 'database'@'localhost' identified by 'password' 例如: grant al ...
随机推荐
- 牛客网PAT练兵场-科学计数法
题目地址:https://www.nowcoder.com/pat/6/problem/4050 题解:模拟题 /** * Copyright(c) * All rights reserved. * ...
- 如何利用微博客进行seo赚钱营销
http://www.wocaoseo.com/thread-130-1-1.html 我们知道做SEO就是用人的思维来模仿搜索引擎的习惯,尽量适应seo的规则,并按照搜索引擎的规则和习惯 ...
- openCV - 5~7 图像混合、调整图像亮度与对比度、绘制形状与文字
5. 图像混合 理论-线性混合操作.相关API(addWeighted) 理论-线性混合操作 用到的公式 (其中 α 的取值范围为0~1之间) 相关API(addWeighted) 参数1:输入图像M ...
- 关于windou环境下使用http或者ftp搭建网络hu共享
第一步 右键此电脑进入控制面 第二步:进入程序点击启用或关闭windous功能 第三步进入服务开启界面 点击让windows更新为你下载文件,并保存更改完,然后关闭 四:邮件我的电脑进入管理 四右键添 ...
- java里equals和hashCode之间什么关系
如果要比较实际内存中的内容,那就要用equals方法,但是!!! 如果是你自己定义的一个类,比较自定义类用equals和==是一样的,都是比较句柄地址,因为自定义的类是继承于object,而objec ...
- Spring Validation-用注解代替代码参数校验
Spring Validation 概念 在原先的编码中,我们如果要验证前端传递的参数,一般是在接受到传递过来的参数后,手动在代码中做 if-else 判断,这种编码方式会带来大量冗余代码,十分的不优 ...
- 获取android手机的屏幕分辨率 android开发
/** * 获取屏幕分辨率 */ private void getResolution() { // TODO Auto-generated method stub Display display = ...
- kotlin 作用域函数 : let、run、with、apply、 also、takeIf、takeUnless
1.官方文档 英文: https://kotlinlang.org/docs/reference/scope-functions.html 中文: https://www.kotlincn.net/d ...
- Java 中基本数据类型的变量的转换规则
基本数据类型之间的转换 变量之间的转换规则 布尔型变量在和其他 7 种基本数据类型做运算时,无法转化为其他的数据类型,所以下面所说的运算都是除了布尔型的其他 7 种基本数据类型之间的转换. 1.自动类 ...
- 2020重新出发,NOSQL,MongoDB是什么?
什么是MongoDB ? MongoDB 是一个开源的文档数据库,它基于 C++ 语言编写,性能高,可用性强,能够自动扩展. MongoDB 是最流行的 NoSQL 数据库之一,原生支持分布式集群架构 ...