Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware
通过scrapy官网最新的架构图来理解:
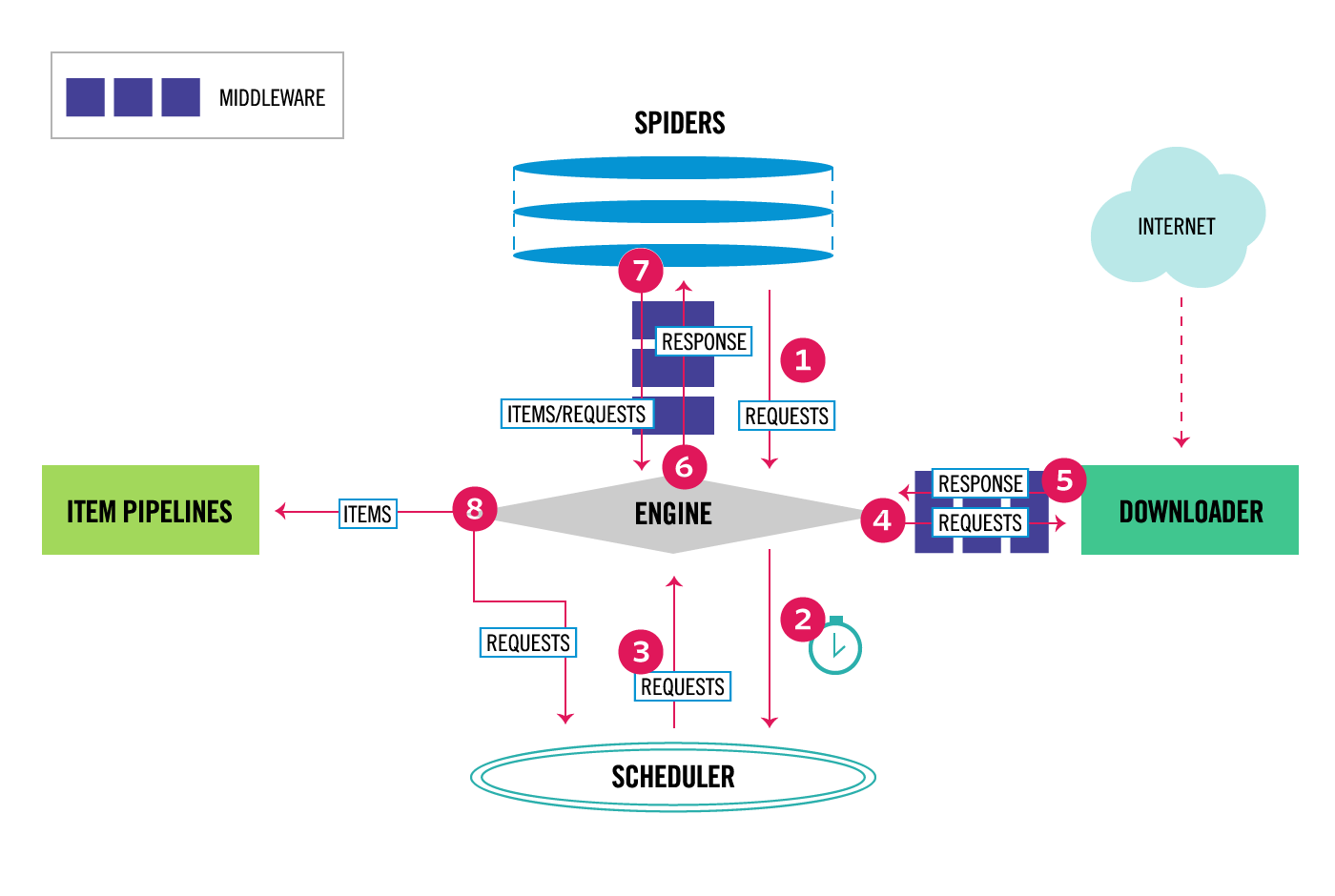
这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可以设置中间件,两者是双向的,并且是可以设置多层.
关于Downloader Middleware我在http://www.cnblogs.com/zhaof/p/7198407.html 这篇博客中已经写了详细的使用介绍。
如何实现随机更换User-Agent
这里要做的是通过自己在Downlaoder Middleware中定义一个类来实现随机更换User-Agent,但是我们需要知道的是scrapy其实本身提供了一个user-agent这个我们在源码中可以看到如下图:
- from scrapy import signals
- class UserAgentMiddleware(object):
- """This middleware allows spiders to override the user_agent"""
- def __init__(self, user_agent='Scrapy'):
- self.user_agent = user_agent
- @classmethod
- def from_crawler(cls, crawler):
- o = cls(crawler.settings['USER_AGENT'])
- crawler.signals.connect(o.spider_opened, signal=signals.spider_opened)
- return o
- def spider_opened(self, spider):
- self.user_agent = getattr(spider, 'user_agent', self.user_agent)
- def process_request(self, request, spider):
- if self.user_agent:
- request.headers.setdefault(b'User-Agent', self.user_agent)
从源代码中可以知道,默认scrapy的user_agent=‘Scrapy’,并且这里在这个类里有一个类方法from_crawler会从settings里获取USER_AGENT这个配置,如果settings配置文件中没有配置,则会采用默认的Scrapy,process_request方法会在请求头中设置User-Agent.
关于随机切换User-Agent的库
github地址为:https://github.com/hellysmile/fake-useragent
安装:pip install fake-useragent
基本的使用例子:
- from fake_useragent import UserAgent
- ua = UserAgent()
- print(ua.ie)
- print(ua.chrome)
- print(ua.Firefox)
- print(ua.random)
- print(ua.random)
- print(ua.random)
这里可以获取我们想要的常用的User-Agent,并且这里提供了一个random方法可以直接随机获取,上述代码的结果为:

关于配置和代码
这里我找了一个之前写好的爬虫,然后实现随机更换User-Agent,在settings配置文件如下:
- DOWNLOADER_MIDDLEWARES = {
- 'jobboleSpider.middlewares.RandomUserAgentMiddleware': 543,
- 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
- }
- RANDOM_UA_TYPE= 'random'
这里我们要将系统的UserAgent中间件设置为None,这样就不会启用,否则默认系统的这个中间会被启用
定义RANDOM_UA_TYPE这个是设置一个默认的值,如果这里不设置我们会在代码中进行设置,在middleares.py中添加如下代码:
- class RandomUserAgentMiddleware(object):
- '''
- 随机更换User-Agent
- '''
- def __init__(self,crawler):
- super(RandomUserAgentMiddleware, self).__init__()
- self.ua = UserAgent()
- self.ua_type = crawler.settings.get('RANDOM_UA_TYPE','random')
- @classmethod
- def from_crawler(cls,crawler):
- return cls(crawler)
- def process_request(self,request,spider):
- def get_ua():
- return getattr(self.ua,self.ua_type)
- request.headers.setdefault('User-Agent',get_ua())
上述代码的一个简单分析描述:
1. 通过crawler.settings.get来获取配置文件中的配置,如果没有配置则默认是random,如果配置了ie或者chrome等就会获取到相应的配置
2. 在process_request方法中我们嵌套了一个get_ua方法,get_ua其实就是为了执行ua.ua_type,但是这里无法使用self.ua.self.us_type,所以利用了getattr方法来直接获取,最后通过request.heasers.setdefault来设置User-Agent
通过上面的配置我们就实现了每次请求随机更换User-Agent
Python之爬虫(二十五) Scrapy的中间件Downloader Middleware实现User-Agent随机切换的更多相关文章
- scrapy的中间件Downloader Middleware实现User-Agent随机切换
scrapy的中间件Download Middleware实现User-Agent随机切换 总架构理解Middleware 通过scrapy官网最新的架构图来理解: 从图中我们可以看出,在spid ...
- Python之爬虫(十五) Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
- Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python 爬虫(二十五) Cookie的处理--cookielib库的使用
Python中cookielib库(python3中为http.cookiejar)为存储和管理cookie提供客户端支持. 该模块主要功能是提供可存储cookie的对象.使用此模块捕获cookie并 ...
- Py修行路 python基础 (二十五)线程与进程
操作系统是用户和硬件沟通的桥梁 操作系统,位于底层硬件与应用软件之间的一层 工作方式:向下管理硬件,向上提供接口 操作系统进行切换操作: 把CPU的使用权切换给不同的进程. 1.出现IO操作 2.固定 ...
- Appium+python自动化(二十五)- 那些让人抓耳挠腮、揪头发和掉头发的事 - 获取控件ID(超详解)
简介 在前边的第二十二篇文章里,已经分享了通过获取控件的坐标点来获取点击事件的所需要的点击位置,那么还有没有其他方法来获取控件点击事件所需要的点击位置呢?答案是:Yes!因为在不同的大小屏幕的手机上获 ...
- Python学习(二十五)—— Python连接MySql数据库
转载自http://www.cnblogs.com/liwenzhou/p/8032238.html 一.Python3连接MySQL PyMySQL 是在 Python3.x 版本中用于连接 MyS ...
- Python学习札记(二十五) 函数式编程6 匿名函数
参考:匿名函数 NOTE 1.Python对匿名函数提供了有限的支持. eg. #!/usr/bin/env python3 def main(): lis = list(map(lambda x: ...
- Python学习日记(二十五) 接口类、抽象类、多态
接口类 继承有两种用途:继承基类的方法,并且做出自己的改变或扩展(代码重用)和声明某个子类兼容于某基类,定义一个接口类interface,接口类中定义了一些接口名(就是函数名)且并未实现接口的功能,子 ...
随机推荐
- Linux中tomcat的部署
红帽7如何配置tomcat 1.下载tomcat9.0和java-1.8 tomcat的下载地址: https://tomcat.apache.org/ java1.8是radhat7自带: [roo ...
- 如何在python列表中查找某个元素的索引
如何在python列表中查找某个元素的索引 2019-03-15 百度上回复别人的问题,几种方式的回答: 1) print('*'*15,'想找出里面有重复数据的索引值','*'*15) listA ...
- Codeforce Round #643 #645 #646 (Div2)
codeforce Round #643 #645 #646 div2 Round #643 problem A #include<bits/stdc++.h> using namespa ...
- Phoenix入门到实战(一)
问题导读1.你认为Apache Phoenix与HBase的关系是什么?2.Phoenix安装需要哪些软件?3.如何部署Phoenix? Introduction Apache Phoenix i ...
- Dubbo——服务发布原理
引言 在使用Dubbo的时候你一定会好奇它是怎么实现RPC的,而要了解它的调用过程,必然需要先了解其服务发布/订阅的过程,本篇将详细讨论Dubbo的发布过程. 源码分析 发布服务 新学Dubbo大都会 ...
- Quartz.Net系列(七):Trigger之SimpleScheduleBuilder详解
所有方法图 1.SimpleScheduleBuilder RepeatForever:指定触发器将无限期重复. WithRepeatCount:指定重复次数 var trigger = Trigge ...
- mongodb 数据库 增删改查
mongodb 数据库 增删改查 增: // 引入express 模块 var express = require('express'); // 路由var router = expr ...
- druid18.1版本sing-server启动报错
正文 昨天下载了一个18版本的driud打算在虚拟机探究一下,然后按照官网的启动方式启动了,每个失败.官网是/bin/start-micro-quickstart,我们去看他的单机启动配置 http: ...
- 组合注解(Annotation)
import java.lang.annotation.Documented; import java.lang.annotation.ElementType; import java.lang.an ...
- RocketMQ入门到入土(一)新手也能看懂的原理和实战!
学任何技术都是两步骤: 搭建环境 helloworld 我也不例外,直接搞起来. 一.RocketMQ的安装 1.文档 官方网站 http://rocketmq.apache.org GitHub h ...