记一次Hadoop安装部署过程
实验名称:Hadoop安装部署
一、实验环境:
虚拟机数量:3个 (1个master,2个slave:slave01,slave02)
主节点master信息:
操作系统:CentOS7.5
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
已安装软件:无
从节点slave01信息:
操作系统:CentOS7.5
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
已安装软件:无
从节点slave02信息:
操作系统:CentOS7.5
软件包位置:/home/zkpk/tgz
数据包位置:/home/zkpk/experiment
已安装软件:无
二、实验目的:
掌握 linux系统基础
熟悉hadoop操作指令
掌握配置集群节点间免密登录
掌握配置JDK
掌握配置部署hadoop的步骤和配置相关环境文件
三、实验要求:
独立完成hadoop的安装部署。
四、实验内容:
在若干节点中,安装部署hadoop分布式集群,并会启动集群以及使用 Web
UI查看集群是否成功启动;在搭建好的hadoop分布式集群中运行PI实例检查集群是否成功;
实验内容流程图如下。
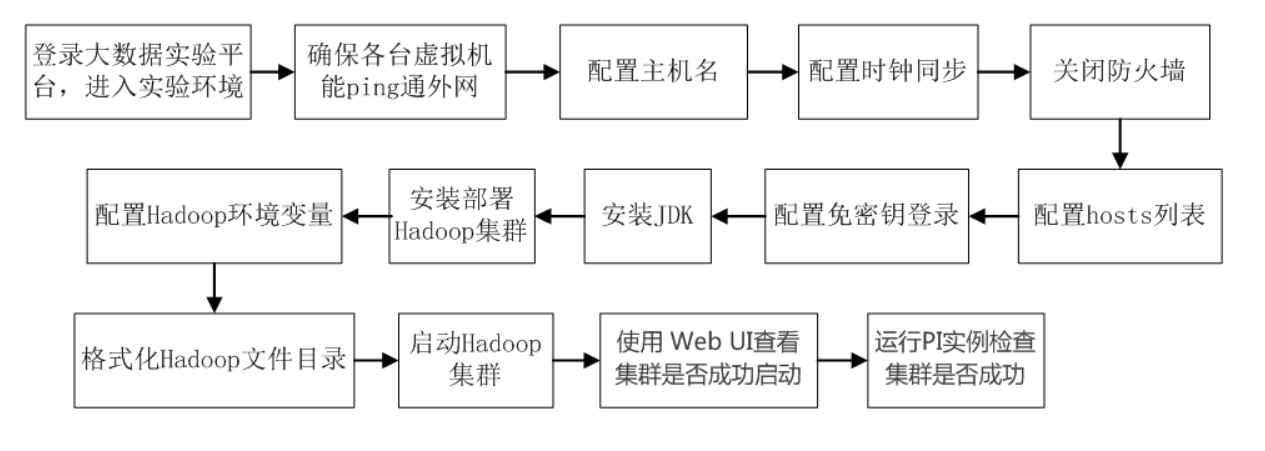
五、实验步骤:
1 登录大数据实验平台,进入实验,(界面显示为master、slave01、slave02)
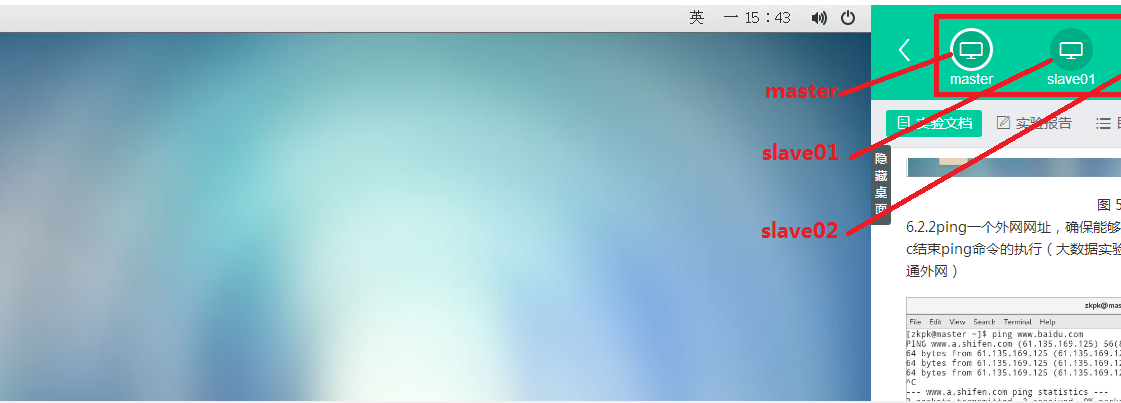
2 确保各台虚拟机能ping通外网(上图界面中master、slave01、slave02,分别对应一个虚拟机,随后简称为“界面各虚拟机”)
2.1 在桌面空白处右击鼠标,打开一个终端(下图根据centos7所使用的桌面系统不同会稍有区别,一般使用gnome或xfce)
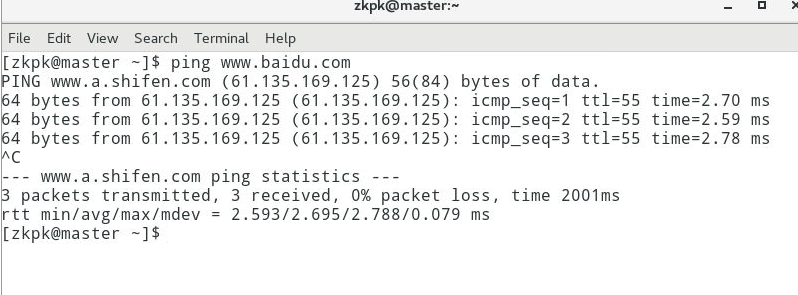
2.2ping一个外网网址,确保能够ping通,ctrl+c结束ping命令的执行(大数据实验室提供的虚拟机默认已可ping通外网)
3 配置主机名(“界面各虚拟机”分别操作此步骤,主机名分别设置为master, slave01,slave02)
说明:此处以界面虚拟机master的操作为例(默认已经配置好主机名称)
3.1 以下操作需要root权限,所以先切换成root用户
[zkpk@localhost ~]$ su root

3.2 使用gedit编辑主机名(或使用vim)
3.2.1 编辑主机名文件
[root@localhost ~]# gedit /etc/hostname
3.2.2 将原来内容替换为master
master
3.2.3 保存并退出
3.2.4 临时设置主机名为master:
[root@localhost ~]# hostname master
3.2.5 检测主机名是否修改成功:
说明:bash命令让上一步操作生效
[root@localhost zkpk]# bash
[root@master zkpk]# hostname
master

4 配置时钟同步(使用root权限;“界面各虚拟机”分别操作此步骤;若已配置过,请忽略此步骤)
说明:此处以master节点的操作为例
4.1 配置自动时钟同步
4.1.1使用Linux命令配置
[root@master zkpk]# crontab -e
4.1.2 按”i ”键,进入插入模式;输入下面的内容(星号之间和前后都有空格)
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
4.1.3 按Esc退出插入模式,然后按”: ”键,输入wq保存退出
4.2 手动同步时间,直接在Terminal运行下面的命令:
[root@master zkpk]# /usr/sbin/ntpdate cn.pool.ntp.org

5 关闭防火墙(使用root权限;“界面各虚拟机”分别操作此步骤;若已配置过,请忽略此步骤)
5.1 查看防火墙状态(默认已经关闭防火墙)
[root@master ~]# systemctl status firewalld.service

5.2 在终端中执行下面命令:
说明:两条命令分别是临时关闭防火墙和禁止开机启动防火墙
[root@master ~]# systemctl stop firewalld.service
[root@master ~]# systemctl disable firewalld.service
6 配置hosts列表(使用root权限;“界面各虚拟机”分别操作此步骤;默认已经配置)
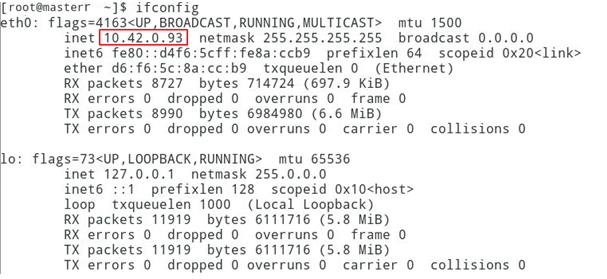
6.1 先分别在各虚拟机中运行ifconfig命令,获得当前节点的ip地址,如下图是master的ip地址
6.2 编辑主机名列表文件:
[root@master zkpk]# vi /etc/hosts
6.3 将下面三行添加到/etc/hosts文件中,保存退出:
注意:
这里master节点对应IP地址是10.42.0.93,slave01对应的IP是10.42.0.94,slave02对应的IP是10.42.0.95,而自己在做配置时,需要将IP地址改成自己的master、slave01和slave02对应的IP地址。
10.42.0.93 master
10.42.0.94 slave01
10.42.0.95 slave02
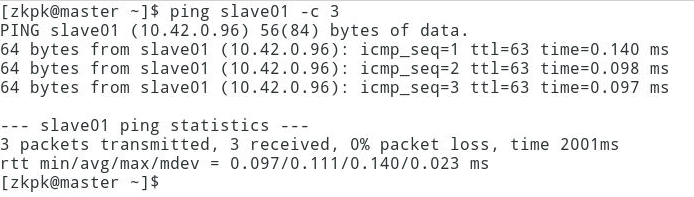
6.4 Ping主机名
[root@master ~]# ping master -c 3
[root@master ~]# ping slave01 -c 3
[root@master ~]# ping slave02 -c 3
注意:参数-c 3表示之返回三行响应就中止。
6.5 如果出现下图的信息表示配置成功:
7 免密钥登录配置(注意:使用zkpk用户)
7.1 master节点上
7.1.1 先从root用户,退回到普通用户zkpk
[root@master ~]# su zkpk
[zkpk@master ~]$
7.1.2 在终端生成密钥,命令如下(一路按回车完成密钥生成)
[zkpk@master ~]$ ssh-keygen -t rsa
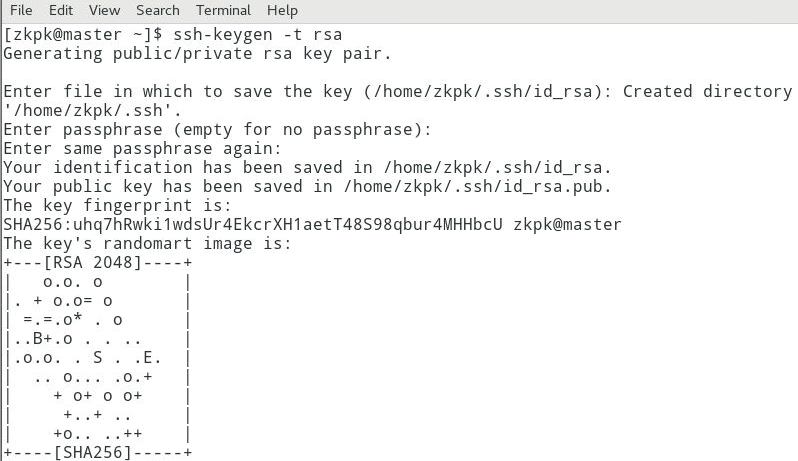
7.1.3 生成的密钥在用户根目录中的.ssh子目录中,进入.ssh目录,如下图操作:

7.1.4 进行复制公钥文件
[zkpk@master .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
7.1.5 执行ls -l命令后会看到下图的文件列表:

7.1.6 修改authorized_keys文件的权限,命令如下:
[zkpk@master .ssh]$ chmod 600 ~/.ssh/authorized_keys
7.1.7 将专用密钥添加到 ssh-agent 的高速缓存中
[zkpk@master .ssh]$ ssh-add ~/.ssh/id_rsa
7.1.8 将authorized_keys文件复制到slave01、slave02节点zkpk用户的根目录,命令如下:
说明:如果提示输入yes/no的时候,输入yes,回车。密码是:zkpk
[zkpk@master .ssh]$ scp ~/.ssh/authorized_keys zkpk@slave01:~/
[zkpk@master .ssh]$ scp ~/.ssh/authorized_keys zkpk@slave02:~/

7.2 slave01节点
7.2.1 先从root用户,退回到普通用户zkpk,
[root@slave01 ~]# su zkpk

然后在终端生成密钥,命令如下(一路点击回车生成密钥)
[zkpk@slave01 ~]$ ssh-keygen -t rsa
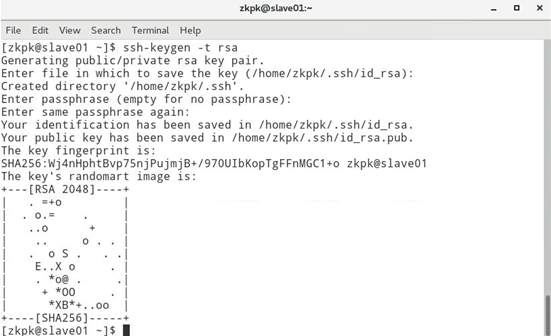
7.2.2 将authorized_keys文件移动到.ssh目录
[zkpk@slave01 ~]$ mv authorized_keys ~/.ssh/
7.3 slave02节点
7.3.1 在终端生成密钥,命令如下(一路点击回车生成密钥)
[zkpk@slave02 ~]$ ssh-keygen -t rsa
7.3.2 将authorized_keys文件移动到.ssh目录
[zkpk@slave02 ~]$ mv authorized_keys ~/.ssh/
7.4 验证免密钥登陆
7.4.1 在master机器上远程登录slave01:
[zkpk@master ~]$ ssh slave01
7.4.2 如果出现下图的内容表示免密钥配置成功:

7.4.3 退出slave01远程登录
[zkpk@slave01 ~]$ exit
[zkpk@master ~]$
7.4.4 在master机器上远程登录slave02:
[zkpk@master ~]$ ssh slave02
7.4.5 如果出现下图的内容表示免密钥配置成功:

8 安装JDK
注意:在三台节点master,slave01,slave02上分别操作此步骤
8.1 删除系统自带的jdk(如若出现下图效果,说明系统自带java,需要先卸载)
8.1.1 查看系统自带jdk
[zkpk@master ~]$ rpm -qa | grep java

在slave01上执行:
[zkpk@slave01 ~]$ rpm -qa | grep java
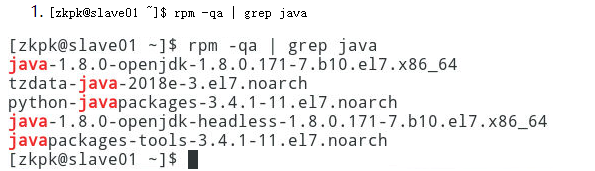
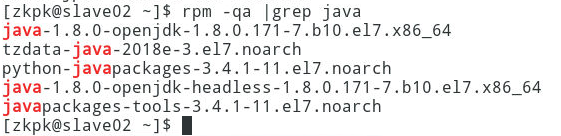
在slave02上执行:
[zkpk@slave02 ~]$ rpm -qa | grep java
8.1.2 切换root用户
[zkpk@master ~]$ su root
在slave01上执行:
[zkpk@slave01 ~]$ su root
在slave02上执行:
[zkpk@slave02 ~]$ su root
8.1.3 移除系统自带的jdk
[root@master zkpk]# yum remove java-1.*
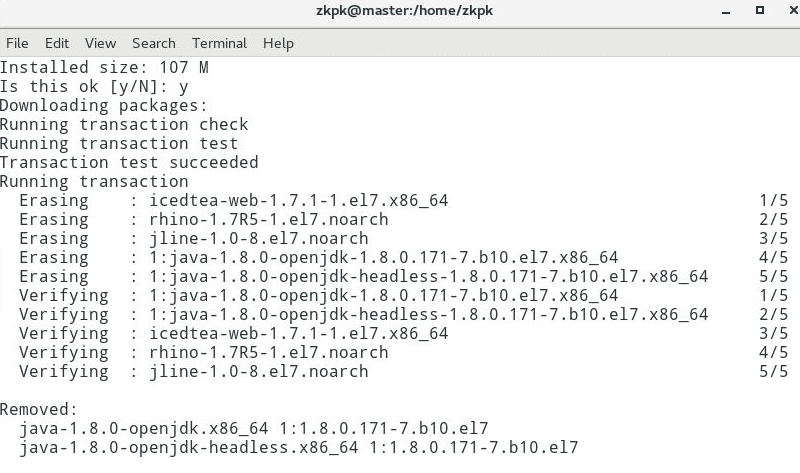
在slave01上执行:
[root@slave01 zkpk]# yum remove java-1.*
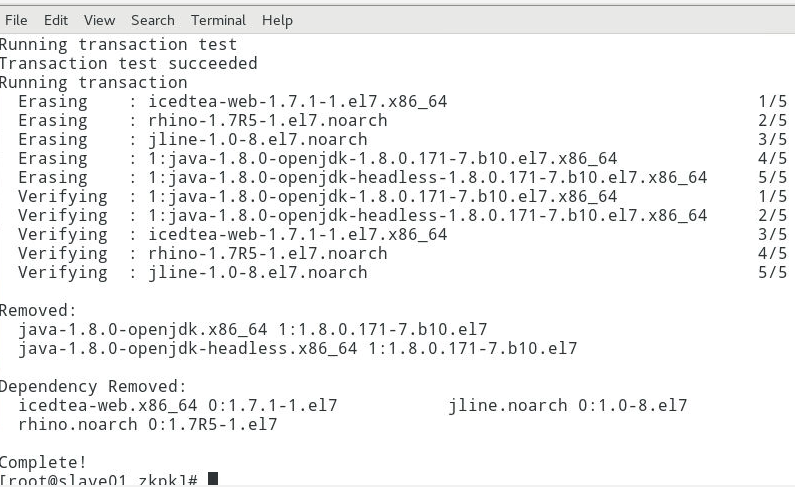
在slave02上执行:
[root@slave02 zkpk]# yum remove java-1.*
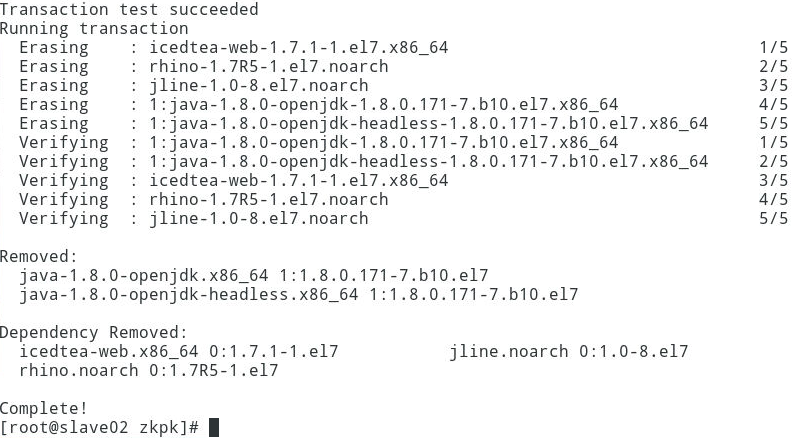
8.1.4 创建存放jdk文件目录
[root@master zkpk]# mkdir /usr/java
在slave01上执行:
[root@slave01 zkpk] # mkdir /usr/java
在slave02上执行:
[root@slave02 zkpk] # mkdir /usr/java
8.2 将/home/zkpk/tgz下的JDK压缩包解压到/usr/java目录下
[root@master zkpk]# tar -xzvf /home/zkpk/tgz/jdk-8u131-linux-x64.tar.gz -C /usr/java
在slave01上执行:
[root@slave01 zkpk]# tar -xzvf /home/zkpk/tgz/jdk-8u131-linux-x64.tar.gz -C /usr/java
在slave02上执行:
[root@slave02 zkpk]# tar -xzvf /home/zkpk/tgz/jdk-8u131-linux-x64.tar.gz -C /usr/java
8.2.1 退出root用户
[root@master zkpk]# exit
在slave01上执行:
[root@slave01 zkpk]# exit
在slave02上执行:
[root@slave02 zkpk]# exit
8.3 配置zkpk用户环境变量
8.3.1 使用gedit修改“.bash_profile”
[zkpk@master ~]$ gedit /home/zkpk/.bash_profile
8.3.2 复制粘贴以下内容添加到到上面gedit打开的文件中:
export JAVA_HOME=/usr/java/jdk1.8.0_131/
export PATH=$JAVA_HOME/bin:$PATH

在slave01上执行:
[zkpk@slave01 ~]$ gedit /home/zkpk/.bash_profile
复制粘贴以下内容添加到到上面gedit打开的文件中:
export JAVA_HOME=/usr/java/jdk1.8.0_131/
export PATH=$JAVA_HOME/bin:$PATH
在slave02上执行:
[zkpk@slave02 ~]$ gedit /home/zkpk/.bash_profile
复制粘贴以下内容添加到到上面gedit打开的文件中:
export JAVA_HOME=/usr/java/jdk1.8.0_131/
export PATH=$JAVA_HOME/bin:$PATH
8.4 使环境变量生效:
[zkpk@master ~]$ source /home/zkpk/.bash_profile
在slave01上执行:
[zkpk@slave01 ~]$ source /home/zkpk/.bash_profile
在slave02上执行:
[zkpk@slave02 ~]$ source /home/zkpk/.bash_profile
8.5 查看java是否配置成功:
[zkpk@master ~]$ java -version

9 安装部署Hadoop集群(zkpk用户)
说明:每个节点上的Hadoop配置基本相同,在master节点操作,然后复制到slave01、slave02两个节点。
9.1 将/home/zkpk/tgz/hadoop目录下的Hadoop压缩包解压到/home/zkpk目录下
[zkpk@master ~]$ tar -xzvf /home/zkpk/tgz/hadoop-2.7.3.tar.gz -C /home/zkpk
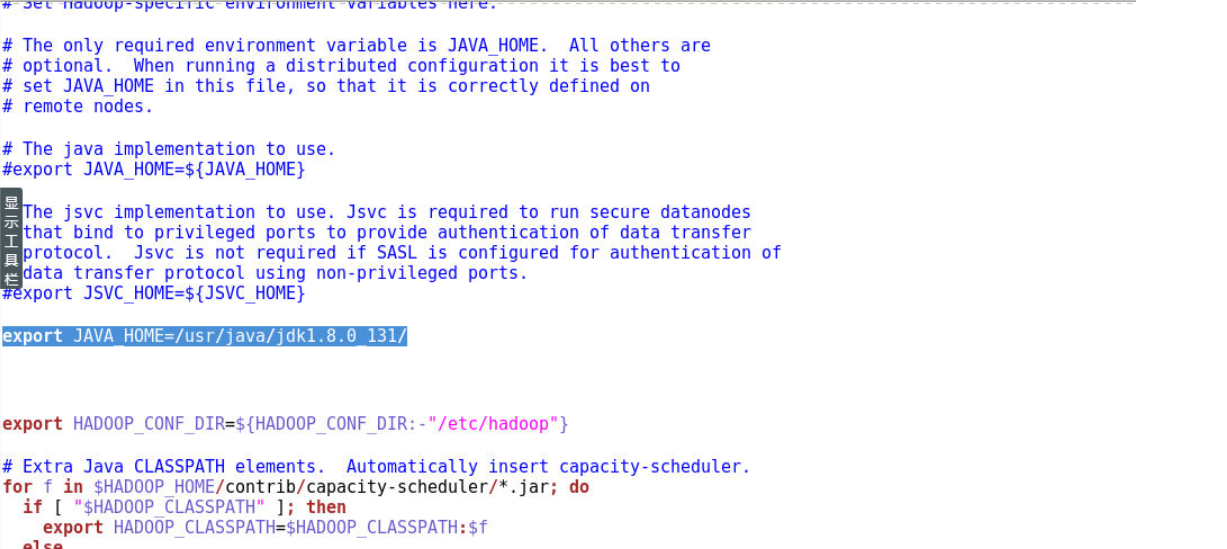
9.2 配置hadoop-env.sh文件
9.2.1 使用gedit命令修改hadoop-env.sh文件
[zkpk@master ~]$ gedit /home/zkpk/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
9.2.2 修改JAVA_HOME环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_131/
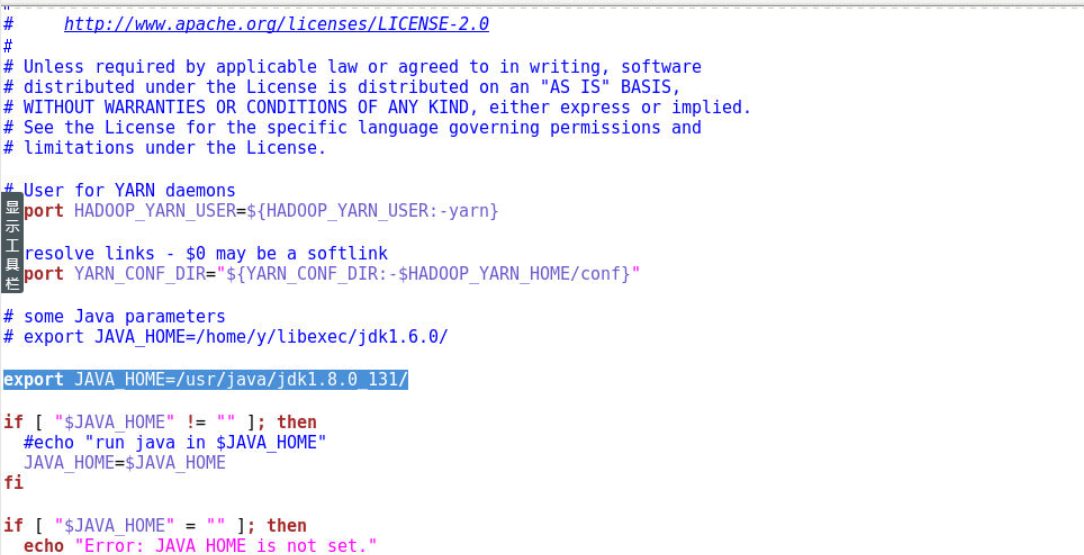
9.3 配置yarn-env.sh文件
9.3.1 使用gedit命令修改yarn-env.sh文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/yarn-env.sh
9.3.2 修改JAVA_HOME环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_131/
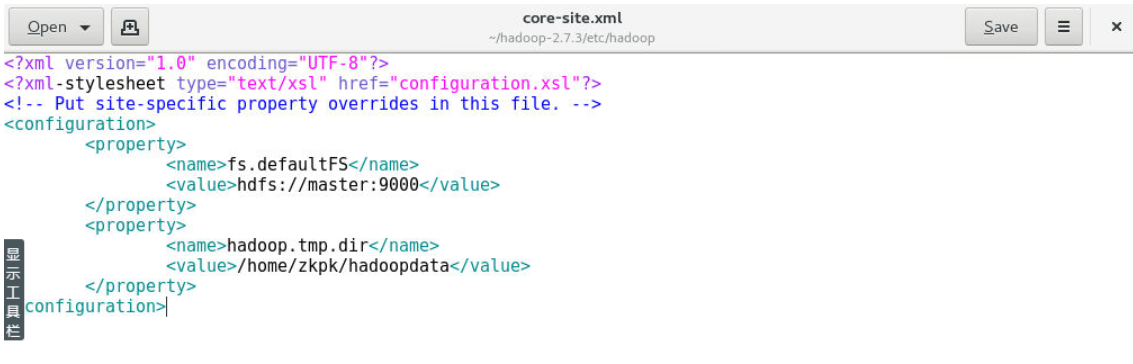
9.4 配置core-site.xml 文件
9.4.1 使用gedit命令修改core-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/core-site.xml
9.4.2 用下面的代码替换core-site.xml中的内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/zkpk/hadoopdata</value>
</property>
</configuration>
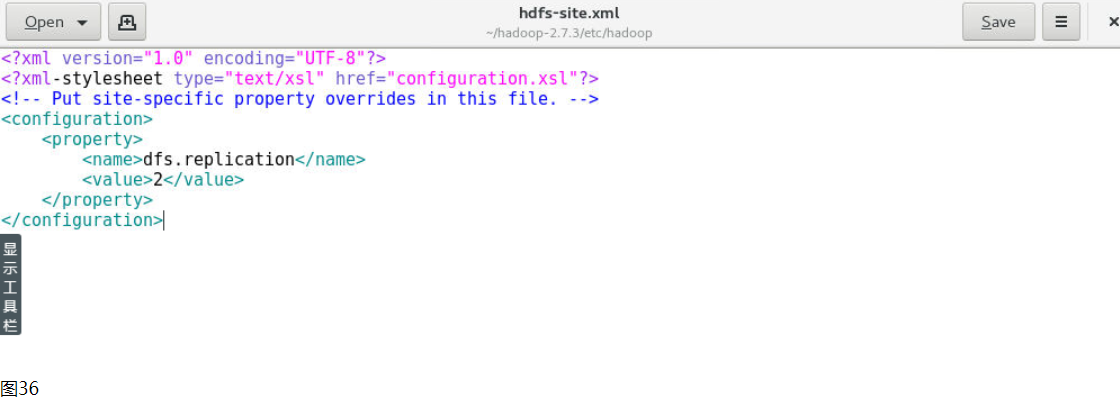
9.5 配置hdfs-site.xml文件
9.5.1 使用gedit命令修改hdfs-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
9.5.2 用下面的代码替换hdfs-site.xml中的内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
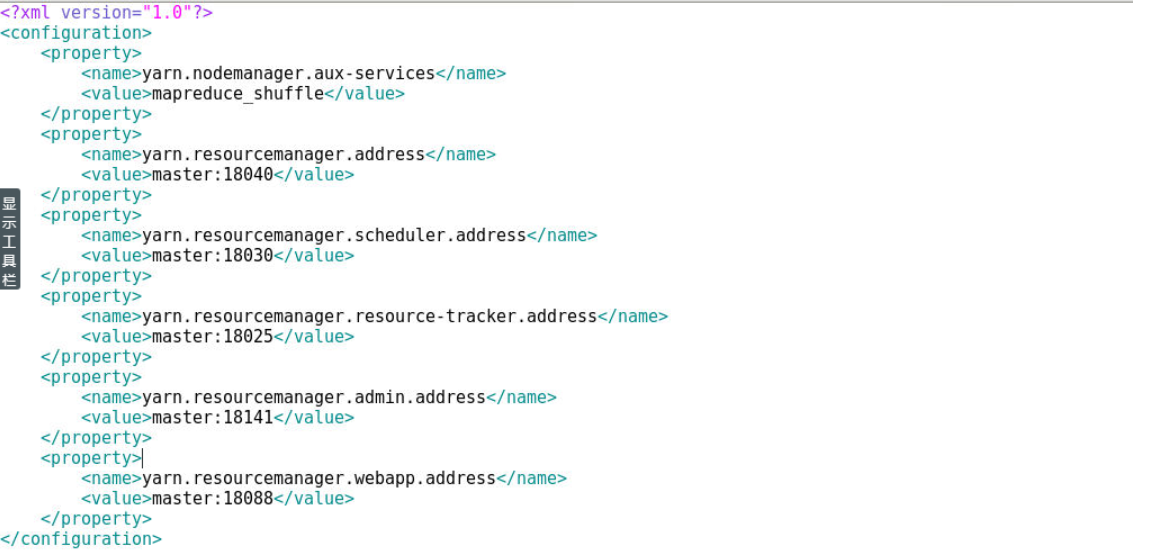
9.6 配置yarn-site.xml文件
9.6.1 使用gedit命令修改yarn-site.xml文件
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/yarn-site.xml
9.6.2 用下面的代码替换yarn-site.xml中的内容:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
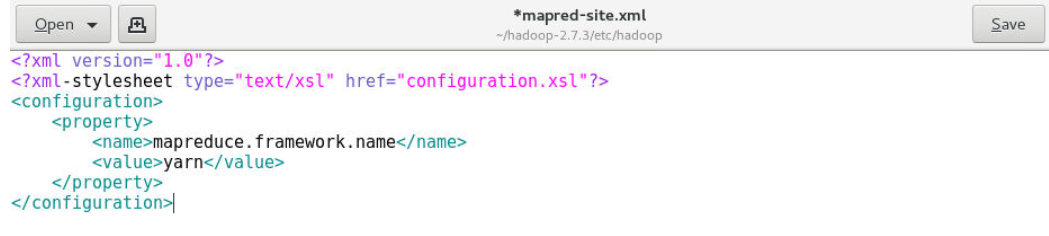
9.7 配置mapred-site.xml文件
9.7.1 复制mapred-site-template.xml文件:
[zkpk@master ~]$ cp ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml.template ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml
9.7.2 使用gedit编辑mapred-site.xml文件:
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/mapred-site.xml
9.7.3 用下面的代码替换mapred-site.xml中的内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
9.8 配置slaves文件
9.8.1 使用gedit编辑slaves文件:
[zkpk@master ~]$ gedit ~/hadoop-2.7.3/etc/hadoop/slaves
9.8.2 将slaves文件中的内容用如下代码替换
slave01
slave02

9.9 创建Hadoop数据目录
[zkpk@master ~]$ cd
[zkpk@master ~]$ mkdir hadoopdata
9.10 将配置好的hadoop文件夹复制到从节点
9.10.1 使用scp命令将文件夹复制到slave01、slave02上:
说明:因为之前已经配置了免密钥登录,这里可以直接免密钥远程复制。
[zkpk@master ~]$ scp -r hadoop-2.7.3 zkpk@slave01:~/
[zkpk@master ~]$ scp -r hadoop-2.7.3 zkpk@slave02:~/
复制完成后,可以在slave01和slave02上检验是否复制成功。
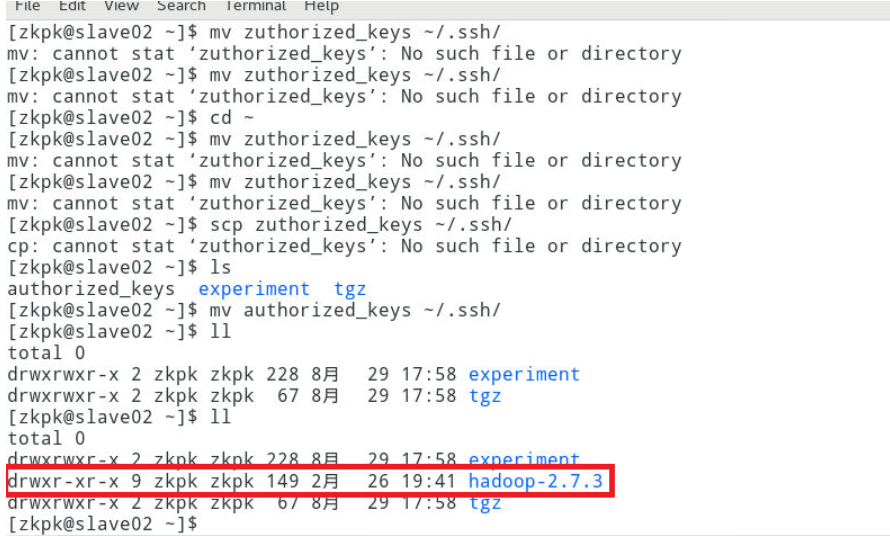
10 配置Hadoop环境变量
注意:在三台节点分别操作此步骤,使用zkpk用户权限
10.1 以master节点为例
[zkpk@master ~]$ gedit ~/.bash_profile
10.2 在.bash_profile末尾添加如下内容:
#HADOOP
export HADOOP_HOME=/home/zkpk/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
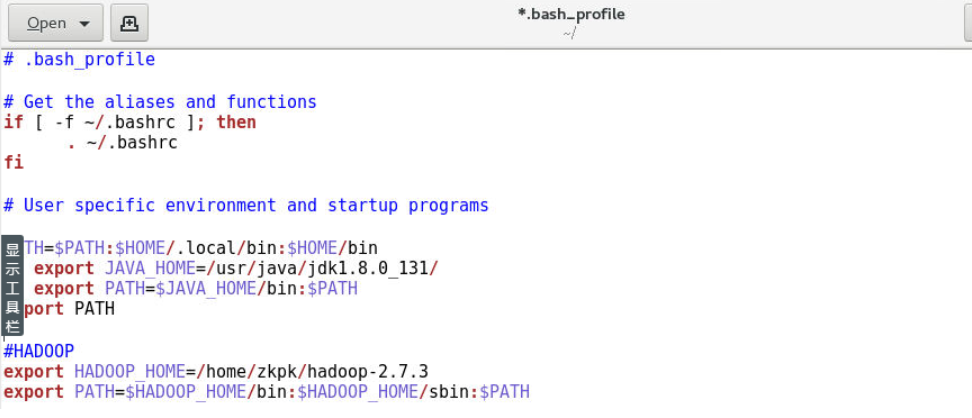
10.3 使环境变量生效:
[zkpk@master ~]$ source ~/.bash_profile
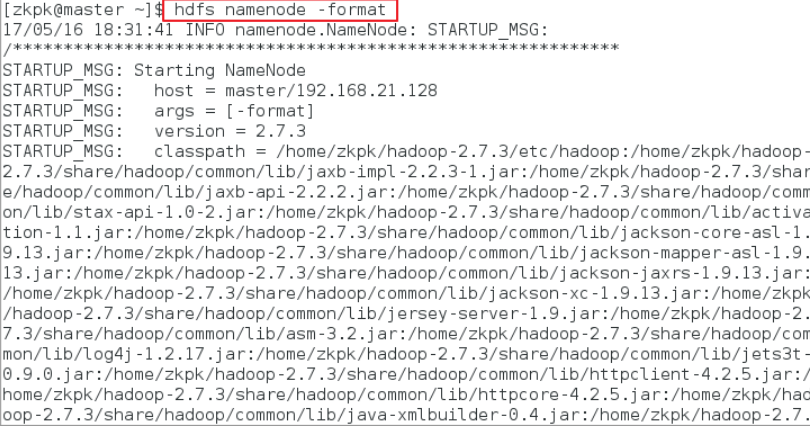
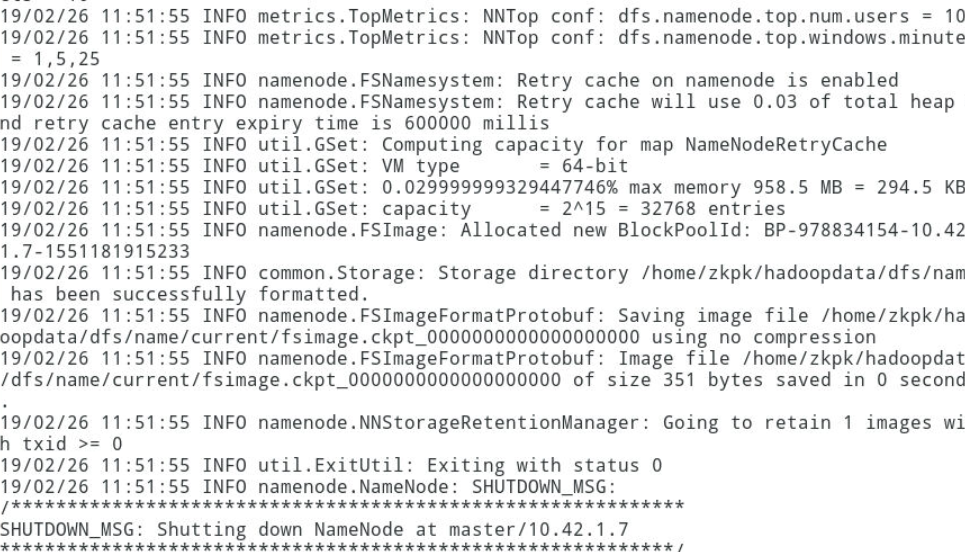
11 格式化Hadoop文件目录(在master上执行)
11.1 格式化命令如下
[zkpk@master ~]$ hdfs namenode -format
12 启动Hadoop集群(在master上执行)
12.1 运行start-all.sh命令
说明:格式化后首次执行此命令,提示输入yes/no时,输入yes。
[zkpk@master ~]$ start-all.sh
12.2 查看进程是否启动
12.2.1 在master的终端执行jps命令,出现下图效果
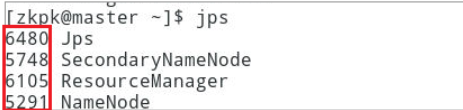
注意:前面那些数字可能因为自己的实验环境不同而不同。
12.2.2 在slave01的终端执行jps命令,出现如下效果

12.2.3 在slave02的终端执行jps命令,出现如下效果

12.3 Web UI查看集群是否成功启动
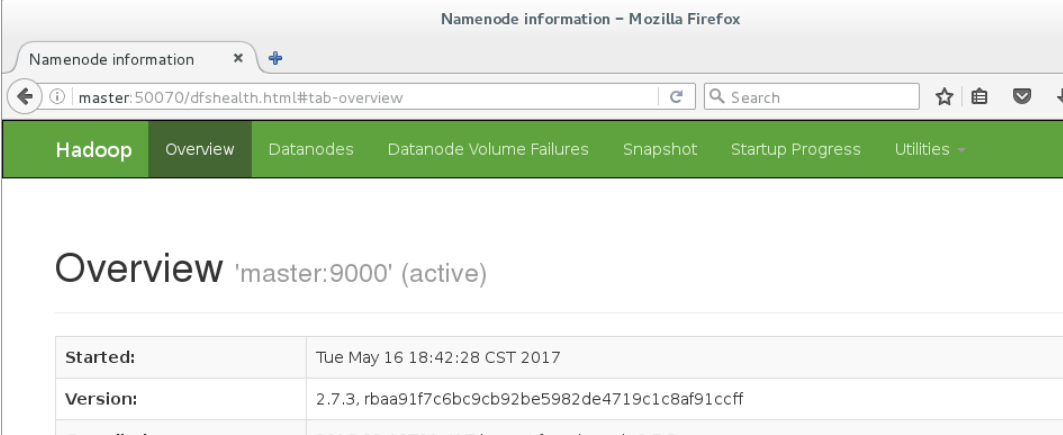
12.3.1 在master上打开Firefox浏览器,在浏览器地址栏中输入http://master:50070,检查namenode和 datanode 是否正常,如下图所示。
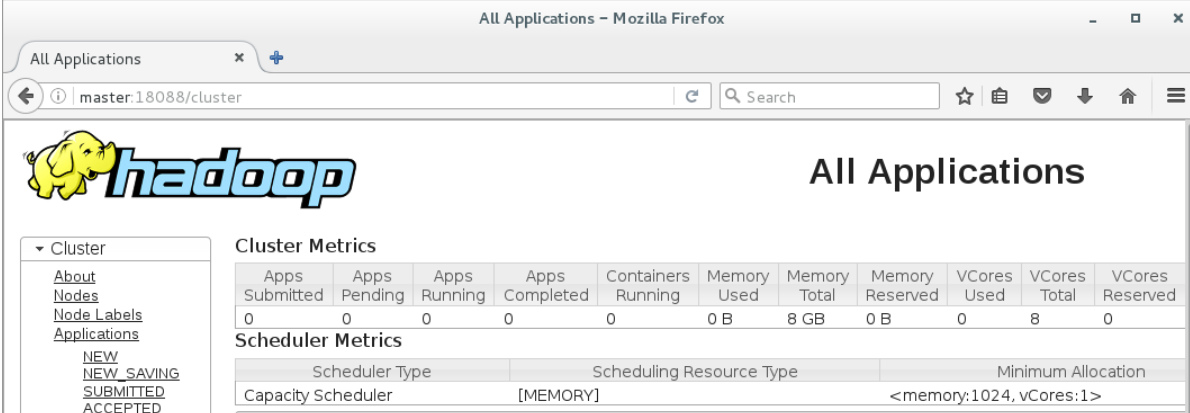
12.3.2打开浏览器新标签页,地址栏中输入http://master:18088,检查Yarn是否正常,如下图所示。
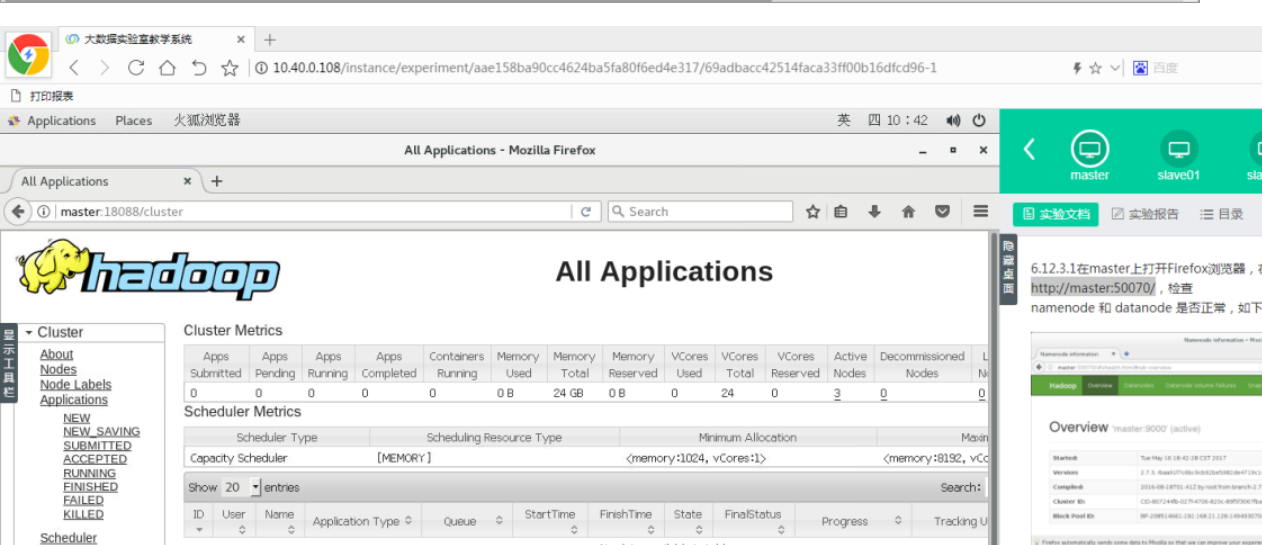
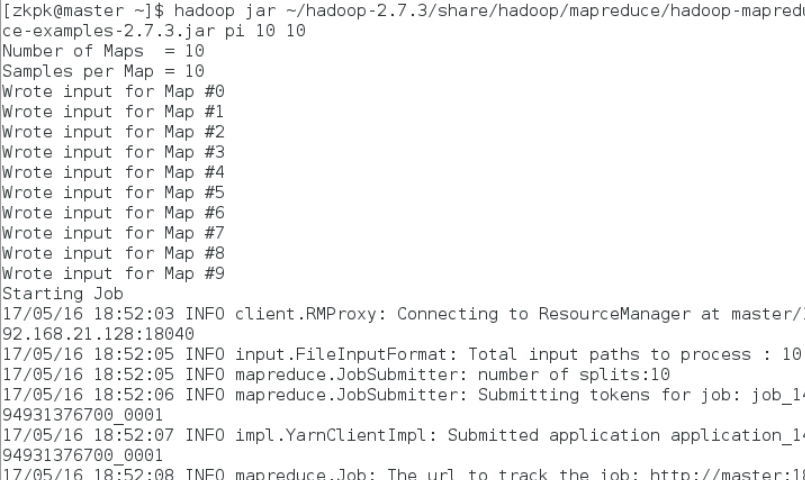
12.4运行PI实例检查集群是否成功
12.4.1执行下面的命令:
[zkpk@master~]$ hadoop jar ~/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar pi 10 10
12.4.2会看到如下的执行结果:
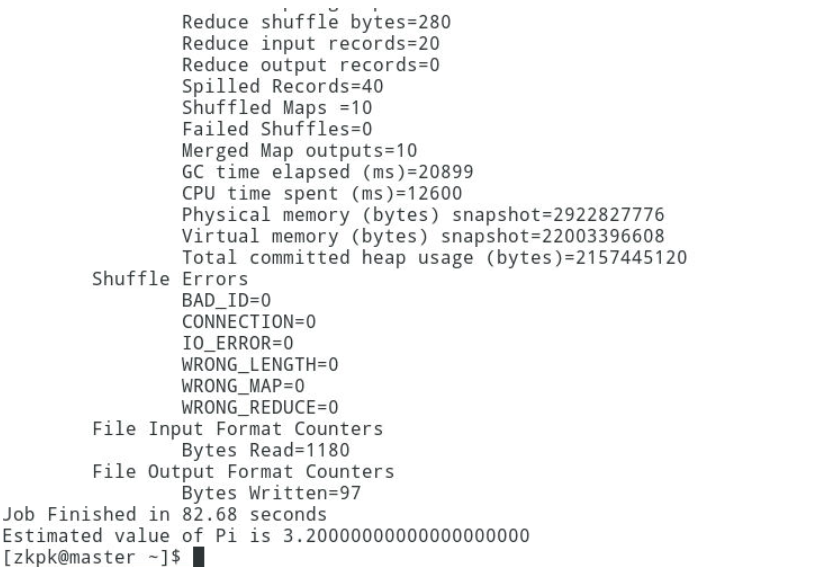
12.4.3最后输出:Estimated value of Pi is 3.20000000000000000000
记一次Hadoop安装部署过程的更多相关文章
- SCCM 2012 R2安装部署过程和问题(三)
上篇 SCCM 2012 R2安装部署过程和问题(二) 个人认为对于使用SCCM 2012的最重要的经验是耐心. SCCM采用分布式部署的架构,不同的站点角色可以部署在不同的服务器上,站点角色之间的通 ...
- SCCM 2012 R2安装部署过程和问题(二)
上篇:SCCM 2012 R2安装部署过程和问题(一) 在上篇我们已经完成了SCCM 2012 R2安装前的准备,其中有许多细节,关于数据库的准备和权限的设置是需要特别注意的.那么接下来我们开始安装S ...
- SCCM 2012 R2安装部署过程和问题(一)
在进行Windows Server 2012 R2虚拟化测试前,由于需要安装,部署和管理很多的服务器,自然会想到该如何提高效率和有效的管理.在Windows Server 2008的时代微软已经提供称 ...
- 免费开源的客服系统 Linux 服务器环境安装部署过程
最近因为项目需要,要找一款在线客服系统集成在 APP 中使用,而且涉及到生意开单,客服系统必须稳定可靠.另外甲方要求,必须支持 Linux 服务器环境. 我们以 Ubuntu 18.04 为例把安装部 ...
- 淘宝分布式 key/value 存储引擎Tair安装部署过程及Javaclient測试一例
文件夹 1. 简单介绍 2. 安装步骤及问题小记 3. 部署配置 4. Javaclient測试 5. 參考资料 声明 1. 以下的安装部署基于Linux系统环境:centos 6(64位),其他Li ...
- 记一次WordPress 安装的过程
安装WordPress你我他大家都会,记得10年的时候,哥已经玩转WordPress.dedecms.sns,那为何现在要记一次WordPress安装过程呢? 因为现在不会了! 之前安装都是在Wind ...
- k8s安装部署过程个人总结及参考文章
以下是本人安装k8s过程 一.单机配置 1. 环境准备 主机名 IP 配置 master1 192.168.1.181 1C 4G 关闭所有节点的seliux以及firewalld sed -i 's ...
- rocketmq安装部署过程(4.0.0版本)
准备工作 3个虚拟机节点的构成如下 : 安装步骤 操作过程 1.安装包已经上传至其中1个节点. 2.解压缩安装包 命令:unzip rocketmq-all-4.0.0-incubating-bin- ...
- VS2013安装部署过程详解
注意:缺少安装部署的小伙伴,看上一篇有详细介绍 程序在“Release”平台下编译运行没有错误 第一步:“新建”------“项目”------“其他项目类型”------“安装部署”------“I ...
随机推荐
- 第15.3节 PyCharm程序调试功能介绍
一. 代码调试 点击工具栏的调试按钮(如下图蓝色圈标记按钮)可以进行程序调试,可以在调试前先设置断点,断点设置就是在打开文件的行与前面的行号之间用鼠标单击进行设置和取消(如下图蓝色下划线上面的实体圆点 ...
- PyQt学习随笔:使用PyCharm+PyQt开发遇到的坑
最近三天,老猿都在使用PyCharm+QtDesigner工具,通过xlwings读取Excel的数据到TableView中显示的练习,本以为很容易的一件事,断断续续持续了三天时间才终于成功.在这个过 ...
- jenkins+git部署环境,出现Failed to connect to repository : Command "git ls-remote -h http://gitlab.xxxxx.git HEAD" returned status code 128stdout: stderr: fatal: repository 'http://gitlab.xxxxx.git' not fou
1.部署jenkins+git源码管理的方式,源码管理报128stdout 源码管理出现如下错误: Failed to connect to repository : Command "gi ...
- python调用jar包
工作项目中用jmeter做接口测试,想尝试用python写接口测试(练习下python), 接口中好多字段都需要加密,而加密方法是java开发写的,打的jar包,这就需要考虑python调用java: ...
- deepFM(原理和pytorch理解)
参考(推荐):https://blog.csdn.net/w55100/article/details/90295932 要点: 其中的计算优化值得注意 K代表隐向量维数 n可以代表离散值one-ho ...
- 算法——K 个一组翻转链表
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表. k 是一个正整数,它的值小于或等于链表的长度. 如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序. 示例: 给你这个 ...
- Json处理方式记录
1.可以直接使用Parse方法 JObject jObject = JObject.Parse(res); string mediaId = jObject["media_id"] ...
- Python高级语法-对象实例对象属性-Property总结(4.6.2)
@ 目录 1.说明 2.代码 关于作者 1.说明 property属性,返回的是值 不是callable的,也就是不能使用方法来调用 只能传入self,不能传入其他 用处,能返回局部数据,比如当分页的 ...
- 第 12 章 JVM执行引擎
目录 第 12 章 执行引擎 1.执行引擎概述 1.1.执行引擎概述 1.2.执行引擎工作过程 2.Java 代码编译和执行过程 2.1.解释执行和即时编译 2.2.解释器和编译器 3.机器码 指令 ...
- s2-061 漏洞复现
0x00 漏洞简介 Apache Struts2框架是一个用于开发Java EE网络应用程序的Web框架.Apache Struts于2020年12月08日披露 S2-061 Struts 远程代码执 ...